Các mô hình ngôn ngữ sáng tạo đã được chứng minh là có kỹ năng đáng kể trong việc giải quyết các nhiệm vụ xử lý ngôn ngữ tự nhiên (NLP) mang tính logic và phân tích. Hơn nữa, việc sử dụng kỹ thuật nhanh chóng có thể nâng cao đáng kể hiệu suất của họ. Ví dụ, chuỗi suy nghĩ (CoT) được biết là cải thiện năng lực của mô hình cho các vấn đề phức tạp gồm nhiều bước. Để tăng thêm độ chính xác cho các nhiệm vụ liên quan đến lý luận, tự nhất quán cách tiếp cận nhắc nhở đã được đề xuất, thay thế việc giải mã tham lam bằng giải mã ngẫu nhiên trong quá trình tạo ngôn ngữ.
nền tảng Amazon là một dịch vụ được quản lý hoàn toàn cung cấp nhiều lựa chọn mô hình nền tảng hiệu suất cao từ các công ty AI hàng đầu và Amazon thông qua một API duy nhất, cùng với một loạt khả năng để xây dựng trí tuệ nhân tạo các ứng dụng có tính bảo mật, quyền riêng tư và AI có trách nhiệm. Với suy luận hàng loạt API, bạn có thể sử dụng Amazon Bedrock để chạy suy luận với các mô hình nền tảng theo đợt và nhận phản hồi hiệu quả hơn. Bài đăng này trình bày cách triển khai tính năng nhắc nhở tự thống nhất thông qua suy luận hàng loạt trên Amazon Bedrock để nâng cao hiệu suất mô hình trong các tác vụ lý luận số học và trắc nghiệm.
Tổng quan về giải pháp
Việc nhắc nhở tính tự thống nhất của các mô hình ngôn ngữ dựa vào việc tạo ra nhiều câu trả lời được tổng hợp thành câu trả lời cuối cùng. Ngược lại với các phương pháp tiếp cận thế hệ đơn lẻ như CoT, quy trình lấy mẫu và biên chế tự thống nhất tạo ra một loạt các bước hoàn thiện mô hình dẫn đến giải pháp nhất quán hơn. Có thể tạo ra các phản hồi khác nhau cho một lời nhắc nhất định nhờ sử dụng chiến lược giải mã ngẫu nhiên, thay vì tham lam.
Hình dưới đây cho thấy tính tự nhất quán khác với CoT tham lam ở chỗ nó tạo ra một tập hợp các đường dẫn lý luận đa dạng và tổng hợp chúng để tạo ra câu trả lời cuối cùng.

Chiến lược giải mã để tạo văn bản
Văn bản được tạo bởi các mô hình ngôn ngữ chỉ có bộ giải mã sẽ mở ra từng từ, với mã thông báo tiếp theo được dự đoán dựa trên ngữ cảnh trước đó. Đối với một lời nhắc nhất định, mô hình sẽ tính toán phân bố xác suất cho biết khả năng mỗi mã thông báo xuất hiện tiếp theo trong chuỗi. Giải mã liên quan đến việc dịch các phân bố xác suất này thành văn bản thực tế. Việc tạo văn bản được trung gian bởi một tập hợp tham số suy luận thường là các siêu tham số của chính phương pháp giải mã. Một ví dụ là nhiệt độ, điều chỉnh phân phối xác suất của mã thông báo tiếp theo và ảnh hưởng đến tính ngẫu nhiên của đầu ra của mô hình.
Giải mã tham lam là một chiến lược giải mã xác định mà ở mỗi bước sẽ chọn mã thông báo có xác suất cao nhất. Mặc dù đơn giản và hiệu quả, cách tiếp cận này có nguy cơ rơi vào các mô hình lặp đi lặp lại vì nó bỏ qua không gian xác suất rộng hơn. Việc đặt tham số nhiệt độ về 0 tại thời điểm suy luận về cơ bản tương đương với việc thực hiện giải mã tham lam.
Lấy mẫu đưa tính ngẫu nhiên vào quá trình giải mã bằng cách chọn ngẫu nhiên từng mã thông báo tiếp theo dựa trên phân phối xác suất được dự đoán. Tính ngẫu nhiên này dẫn đến sự biến thiên đầu ra lớn hơn. Giải mã ngẫu nhiên tỏ ra thành thạo hơn trong việc nắm bắt sự đa dạng của các kết quả đầu ra tiềm năng và thường mang lại nhiều phản hồi giàu trí tưởng tượng hơn. Giá trị nhiệt độ cao hơn tạo ra nhiều biến động hơn và tăng tính sáng tạo trong phản ứng của mô hình.
Kỹ thuật nhắc nhở: CoT và tính tự nhất quán
Khả năng suy luận của các mô hình ngôn ngữ có thể được tăng cường thông qua kỹ thuật nhanh chóng. Đặc biệt, CoT đã được chứng minh là gợi ra lý luận trong các nhiệm vụ NLP phức tạp. Một cách để thực hiện một không bắn CoT thông qua tăng cường nhanh chóng với hướng dẫn “suy nghĩ từng bước”. Một cách khác là đưa mô hình ra các ví dụ về các bước suy luận trung gian trong nhắc nhở vài lần bắn thời trang. Cả hai kịch bản thường sử dụng giải mã tham lam. CoT giúp tăng hiệu suất đáng kể so với hướng dẫn đơn giản về các nhiệm vụ lý luận số học, thông thường và ký hiệu.
Nhắc nhở tính nhất quán của bản thân dựa trên giả định rằng việc đưa tính đa dạng vào quá trình suy luận có thể mang lại lợi ích trong việc giúp các mô hình hội tụ được câu trả lời đúng. Kỹ thuật này sử dụng giải mã ngẫu nhiên để đạt được mục tiêu này theo ba bước:
- Nhắc mô hình ngôn ngữ với các mẫu CoT để suy luận.
- Thay thế giải mã tham lam bằng chiến lược lấy mẫu để tạo ra một tập hợp các đường dẫn lý luận đa dạng.
- Tổng hợp các kết quả để tìm ra câu trả lời nhất quán nhất trong bộ phản hồi.
Tính tự nhất quán được chứng minh là vượt trội so với việc nhắc nhở CoT về các tiêu chuẩn lý luận thông thường và số học phổ biến. Hạn chế của phương pháp này là chi phí tính toán lớn hơn.
Bài đăng này cho thấy cách nhắc nhở tự thống nhất nâng cao hiệu suất của các mô hình ngôn ngữ tổng quát trên hai nhiệm vụ lý luận NLP: giải quyết vấn đề số học và trả lời câu hỏi theo miền cụ thể theo nhiều lựa chọn. Chúng tôi chứng minh phương pháp này bằng cách sử dụng suy luận hàng loạt trên Amazon Bedrock:
- Chúng tôi truy cập SDK Python của Amazon Bedrock trong JupyterLab trên Amazon SageMaker ví dụ máy tính xách tay.
- Để suy luận số học, chúng tôi nhắc Lệnh mạch lạc trên tập dữ liệu GSM8K về các bài toán cấp lớp.
- Đối với lý luận trắc nghiệm, chúng tôi nhắc Phòng thí nghiệm AI21 Jurassic-2 Mid trên một mẫu câu hỏi nhỏ từ kỳ thi Kiến trúc sư giải pháp được chứng nhận AWS – Hội viên.
Điều kiện tiên quyết
Hướng dẫn này giả định các điều kiện tiên quyết sau:

Chi phí ước tính để chạy mã hiển thị trong bài đăng này là 100 USD, giả sử bạn chạy lời nhắc tự thống nhất một lần với 30 đường dẫn lý luận sử dụng một giá trị để lấy mẫu dựa trên nhiệt độ.
Bộ dữ liệu để thăm dò khả năng suy luận số học
GSM8K là một tập dữ liệu gồm các bài toán cấp lớp do con người lắp ráp có tính đa dạng ngôn ngữ cao. Mỗi bài toán cần 2–8 bước để giải và yêu cầu thực hiện một chuỗi các phép tính cơ bản với các phép tính số học cơ bản. Dữ liệu này thường được sử dụng để đánh giá khả năng suy luận số học nhiều bước của các mô hình ngôn ngữ tổng quát. Các Bộ tàu GSM8K bao gồm 7,473 hồ sơ. Sau đây là một ví dụ:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Thiết lập để chạy suy luận hàng loạt với Amazon Bedrock
Suy luận hàng loạt cho phép bạn thực hiện nhiều lệnh gọi suy luận tới Amazon Bedrock một cách không đồng bộ và cải thiện hiệu suất suy luận mô hình trên các tập dữ liệu lớn. Dịch vụ này đang ở trạng thái xem trước tại thời điểm viết bài này và chỉ khả dụng thông qua API. tham khảo Chạy suy luận hàng loạt để truy cập API suy luận hàng loạt thông qua SDK tùy chỉnh.
Sau khi tải về và giải nén xong SDK Python trong phiên bản sổ ghi chép SageMaker, bạn có thể cài đặt nó bằng cách chạy mã sau trong ô sổ ghi chép Jupyter:
Định dạng và tải dữ liệu đầu vào lên Amazon S3
Dữ liệu đầu vào cho suy luận hàng loạt cần được chuẩn bị ở định dạng JSONL với recordId và modelInput phím. Cái sau phải khớp với trường nội dung của mô hình sẽ được gọi trên Amazon Bedrock. Đặc biệt, một số các tham số suy luận được hỗ trợ cho Lệnh Cohere đang temperature vì sự ngẫu nhiên, max_tokens cho độ dài đầu ra, và num_generations để tạo ra nhiều phản hồi, tất cả đều được chuyển cùng với prompt as modelInput:
Xem Các thông số suy luận cho mô hình nền móng để biết thêm chi tiết, bao gồm các nhà cung cấp mô hình khác.
Các thử nghiệm của chúng tôi về lý luận số học được thực hiện trong cài đặt vài lần chụp mà không cần tùy chỉnh hoặc tinh chỉnh Lệnh Cohere. Chúng tôi sử dụng cùng một bộ tám ví dụ về vài cảnh quay từ chuỗi suy nghĩ (Bảng 20) và tính tự đồng nhất (Bảng 17) giấy tờ. Lời nhắc được tạo bằng cách ghép các mẫu với mỗi câu hỏi từ bộ dữ liệu GSM8K.
Chúng tôi thiết lập max_tokens để 512 và num_generations đến 5, mức tối đa được Cohere Command cho phép. Để giải mã tham lam, chúng tôi đặt temperature về 0 và để tự thống nhất, chúng tôi chạy ba thử nghiệm ở nhiệt độ 0.5, 0.7 và 1. Mỗi cài đặt mang lại dữ liệu đầu vào khác nhau tùy theo các giá trị nhiệt độ tương ứng. Dữ liệu được định dạng dưới dạng JSONL và được lưu trữ trong Amazon S3.
Tạo và chạy các công việc suy luận hàng loạt trong Amazon Bedrock
Tạo tác vụ suy luận hàng loạt cần có ứng dụng khách Amazon Bedrock. Chúng tôi chỉ định đường dẫn đầu vào và đầu ra của S3 và đặt cho mỗi công việc gọi một tên duy nhất:
Việc làm là tạo ra bằng cách chuyển vai trò IAM, ID mẫu, tên công việc và cấu hình đầu vào/đầu ra dưới dạng tham số cho API Amazon Bedrock:
Liệt kê, giám sátvà dừng lại công việc suy luận hàng loạt được hỗ trợ bởi các lệnh gọi API tương ứng. Khi tạo, việc làm xuất hiện đầu tiên dưới dạng Submitted, thì như InProgress, và cuối cùng là Stopped, Failed, hoặc là Completed.
Nếu công việc hoàn tất thành công, nội dung được tạo có thể được truy xuất từ Amazon S3 bằng cách sử dụng vị trí đầu ra duy nhất của nó.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Tính tự thống nhất nâng cao độ chính xác của mô hình trong các nhiệm vụ số học
Tính tự nhắc nhở của Cohere Command vượt trội so với đường cơ sở CoT tham lam về độ chính xác trên tập dữ liệu GSM8K. Để tự thống nhất, chúng tôi lấy mẫu 30 cách suy luận độc lập ở ba nhiệt độ khác nhau, với topP và topK đặt thành của họ giá trị mặc định. Các giải pháp cuối cùng được tổng hợp bằng cách chọn sự xuất hiện nhất quán nhất thông qua biểu quyết đa số. Trong trường hợp hòa, chúng tôi chọn ngẫu nhiên một trong các câu trả lời đa số. Chúng tôi tính toán các giá trị độ chính xác và độ lệch chuẩn trung bình trên 100 lần chạy.
Hình dưới đây cho thấy độ chính xác trên tập dữ liệu GSM8K từ Cohere Command được nhắc nhở bằng CoT tham lam (màu xanh lam) và tính tự nhất quán ở các giá trị nhiệt độ 0.5 (màu vàng), 0.7 (màu xanh lá cây) và 1.0 (màu cam) dưới dạng hàm của số lượng mẫu được lấy mẫu các lối suy luận.
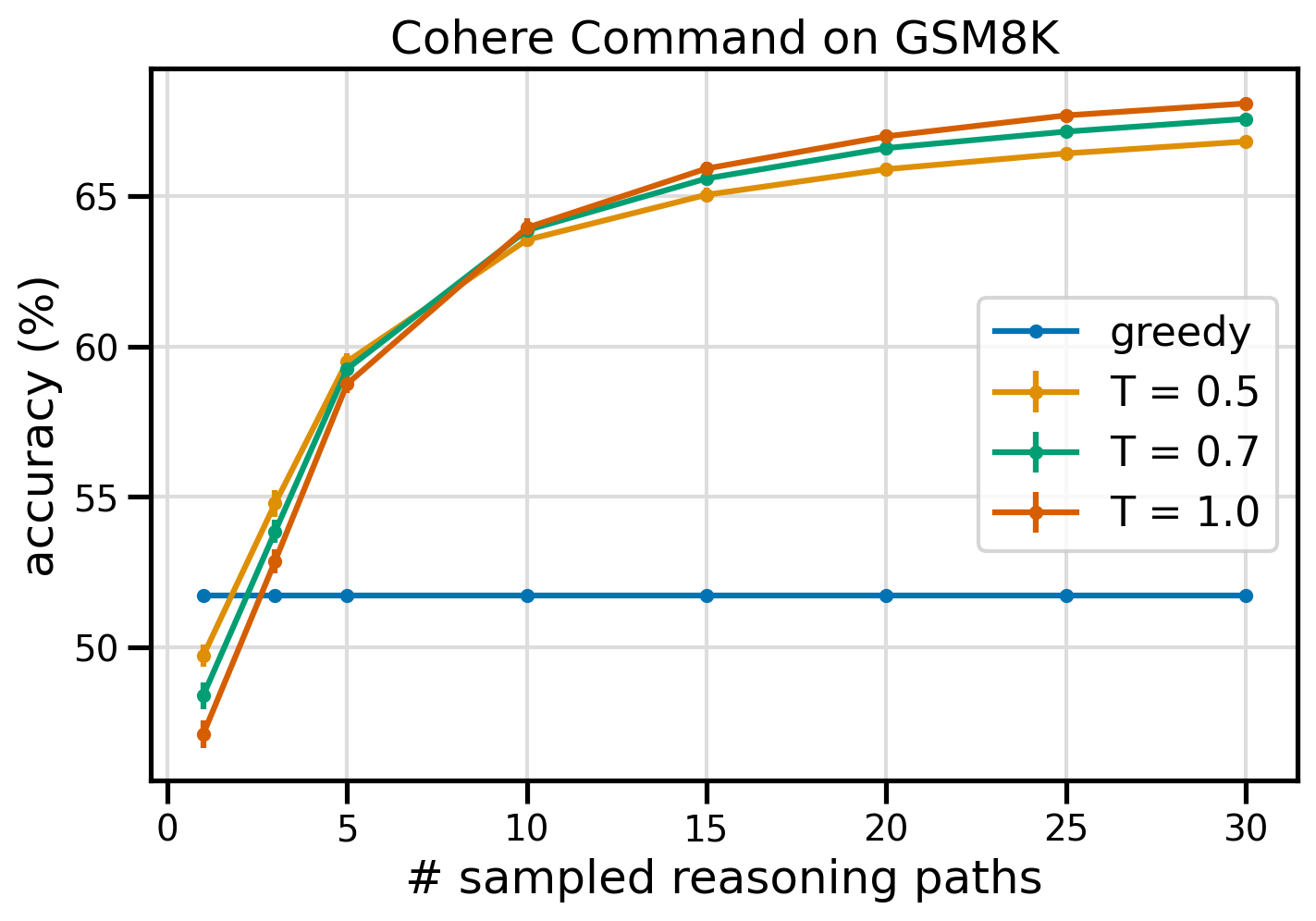
Hình trước cho thấy tính tự nhất quán giúp nâng cao độ chính xác số học so với CoT tham lam khi số lượng đường dẫn được lấy mẫu thấp đến ba. Hiệu suất tăng lên một cách nhất quán với các lộ trình lý luận sâu hơn, khẳng định tầm quan trọng của việc giới thiệu tính đa dạng trong quá trình hình thành tư duy. Cohere Command giải quyết bộ câu hỏi GSM8K với độ chính xác 51.7% khi được nhắc bằng CoT so với 68% với 30 đường dẫn lý luận tự nhất quán ở T=1.0. Tất cả ba giá trị nhiệt độ được khảo sát đều mang lại kết quả tương tự, trong đó nhiệt độ thấp hơn sẽ mang lại hiệu quả tương đối cao hơn ở những đường dẫn ít mẫu hơn.
Những cân nhắc thực tế về hiệu quả và chi phí
Tính tự nhất quán bị hạn chế bởi thời gian phản hồi tăng lên và chi phí phát sinh khi tạo nhiều đầu ra cho mỗi lời nhắc. Như một minh họa thực tế, suy luận hàng loạt cho thế hệ tham lam với Cohere Command trên 7,473 bản ghi GSM8K đã hoàn thành trong vòng chưa đầy 20 phút. Công việc lấy 5.5 triệu mã thông báo làm đầu vào và tạo ra 630,000 mã thông báo đầu ra. Hiện tại Giá suy luận của Amazon Bedrock, tổng chi phí phát sinh là khoảng 9.50 USD.
Để tự thống nhất với Cohere Command, chúng tôi sử dụng tham số suy luận num_generations để tạo nhiều lần hoàn thành cho mỗi lời nhắc. Theo văn bản này, Amazon Bedrock cho phép tối đa năm thế hệ và ba thế hệ đồng thời Submitted công việc suy luận hàng loạt. Công việc tiến tới InProgress trạng thái một cách tuần tự, do đó việc lấy mẫu nhiều hơn năm đường dẫn yêu cầu nhiều lệnh gọi.
Hình dưới đây hiển thị thời gian chạy của Cohere Command trên tập dữ liệu GSM8K. Tổng thời gian chạy được hiển thị trên trục x và thời gian chạy trên mỗi đường dẫn lý luận được lấy mẫu trên trục y. Thế hệ tham lam chạy trong thời gian ngắn nhất nhưng phải chịu chi phí thời gian cao hơn trên mỗi đường dẫn được lấy mẫu.

Quá trình tạo tham lam hoàn thành trong vòng chưa đầy 20 phút cho bộ GSM8K đầy đủ và lấy mẫu một đường dẫn lý luận duy nhất. Tính tự nhất quán với năm mẫu cần thời gian hoàn thành lâu hơn khoảng 50% và chi phí khoảng 14.50 USD nhưng tạo ra năm đường dẫn (trên 500%) trong thời gian đó. Tổng thời gian chạy và chi phí tăng dần theo từng đường dẫn được lấy mẫu thêm. Phân tích chi phí-lợi ích cho thấy rằng 1–2 công việc suy luận hàng loạt với 5–10 đường dẫn được lấy mẫu là cài đặt được đề xuất để triển khai thực tế tính tự nhất quán. Điều này giúp nâng cao hiệu suất mô hình trong khi vẫn giữ được chi phí và độ trễ ở mức thấp.
Tính tự nhất quán nâng cao hiệu suất của mô hình ngoài lý luận số học
Một câu hỏi quan trọng để chứng minh tính phù hợp của việc nhắc nhở tính nhất quán là liệu phương pháp này có thành công trong các nhiệm vụ NLP và mô hình ngôn ngữ tiếp theo hay không. Là một phần mở rộng cho trường hợp sử dụng liên quan đến Amazon, chúng tôi thực hiện phân tích quy mô nhỏ về các câu hỏi mẫu từ Chứng chỉ liên kết kiến trúc sư giải pháp AWS. Đây là bài kiểm tra trắc nghiệm về công nghệ và dịch vụ AWS yêu cầu kiến thức về miền cũng như khả năng suy luận và quyết định giữa một số lựa chọn.
Chúng tôi chuẩn bị một bộ dữ liệu từ SAA-C01 và SAA-C03 câu hỏi trắc nghiệm mẫu. Từ 20 câu hỏi có sẵn, chúng tôi sử dụng 4 câu hỏi đầu tiên làm ví dụ cho một vài lần quay và nhắc mô hình trả lời 16 câu hỏi còn lại. Lần này, chúng tôi chạy suy luận với mô hình Jurassic-21 Mid của AI2 Labs và tạo ra tối đa 10 đường dẫn lý luận tại nhiệt độ 0.7. Kết quả cho thấy tính tự nhất quán giúp nâng cao hiệu suất: mặc dù CoT tham lam đưa ra 11 câu trả lời đúng nhưng tính tự nhất quán lại thành công với 2 câu trả lời nữa.
Bảng sau đây hiển thị kết quả chính xác cho 5 và 10 đường dẫn được lấy mẫu tính trung bình trên 100 lần chạy.
| . | Giải mã tham lam | T = 0.7 |
| # đường dẫn được lấy mẫu: 5 | 68.6 | 74.1 0.7 ± |
| # đường dẫn được lấy mẫu: 10 | 68.6 | 78.9 ± 0.3 |
Trong bảng sau, chúng tôi trình bày hai câu hỏi thi được CoT tham lam trả lời sai trong khi tính tự nhất quán thành công, nêu bật trong mỗi trường hợp các dấu vết lý luận đúng (màu xanh lá cây) hoặc không chính xác (màu đỏ) đã khiến mô hình tạo ra phản hồi đúng hoặc sai. Mặc dù không phải mọi đường dẫn được lấy mẫu do tính tự nhất quán tạo ra đều chính xác nhưng phần lớn đều hội tụ về câu trả lời đúng khi số lượng đường dẫn được lấy mẫu tăng lên. Chúng tôi nhận thấy rằng 5–10 đường dẫn thường đủ để cải thiện kết quả tham lam, với lợi nhuận giảm dần về mặt hiệu quả vượt quá các giá trị đó.
| câu hỏi |
Một ứng dụng web cho phép khách hàng tải đơn hàng lên vùng lưu trữ S3. Các sự kiện Amazon S3 thu được sẽ kích hoạt hàm Lambda để chèn thông báo vào hàng đợi SQS. Một phiên bản EC2 duy nhất đọc thông báo từ hàng đợi, xử lý và lưu trữ chúng trong bảng DynamoDB được phân chia theo ID đơn hàng duy nhất. Lưu lượng truy cập trong tháng tới dự kiến sẽ tăng theo hệ số 10 và Kiến trúc sư giải pháp đang xem xét kiến trúc để tìm các vấn đề có thể xảy ra khi mở rộng quy mô. Thành phần nào có nhiều khả năng cần được kiến trúc lại nhất để có thể mở rộng quy mô nhằm đáp ứng lưu lượng truy cập mới? A. Hàm Lambda |
Một ứng dụng chạy trên AWS sử dụng triển khai cụm cơ sở dữ liệu Amazon Aurora Multi-AZ cho cơ sở dữ liệu của ứng dụng đó. Khi đánh giá các số liệu hiệu suất, một kiến trúc sư giải pháp đã phát hiện ra rằng việc đọc cơ sở dữ liệu đang gây ra I/O cao và tăng thêm độ trễ cho các yêu cầu ghi đối với cơ sở dữ liệu. Kiến trúc sư giải pháp nên làm gì để tách yêu cầu đọc khỏi yêu cầu ghi? A. Bật bộ nhớ đệm đọc qua trên cơ sở dữ liệu Aurora. |
| Câu trả lời chính xác | C – Một phiên bản EC2 sẽ không mở rộng quy mô và là một điểm lỗi duy nhất trong kiến trúc. Một giải pháp tốt hơn nhiều là có các phiên bản EC2 trong nhóm Auto Scaling trên 2 vùng khả dụng để đọc tin nhắn từ hàng đợi. Các phản hồi khác là tất cả các dịch vụ được quản lý có thể được đặt cấu hình để mở rộng quy mô hoặc sẽ tự động mở rộng quy mô. | C – Bản sao Aurora cung cấp một cách để giảm tải lưu lượng đọc. Bản sao Aurora chia sẻ cùng bộ lưu trữ cơ bản với cơ sở dữ liệu chính nên thời gian trễ thường rất thấp. Bản sao Aurora có điểm cuối riêng nên ứng dụng sẽ cần được đặt cấu hình để hướng lưu lượng đọc đến điểm cuối mới. |
| Giải mã tham lam | Có thể không thực hiện được việc mở rộng quy mô trực tiếp phiên bản EC2 vì có thể không thay đổi được kích thước phiên bản. Việc mở rộng quy mô hàm Lambda có thể không đủ, vì các hàm Lambda có giới hạn phân bổ bộ nhớ là 6 GB. Mở rộng hàng đợi SQS có thể không đủ, vì SQS có giới hạn 10,000 tin nhắn. Bảng DynamoDB có thể được mở rộng quy mô bằng cách cung cấp thêm đơn vị dung lượng. Câu trả lời đúng là D. | Sửa đổi ứng dụng để đọc từ phiên bản dự phòng Multi-AZ (tùy chọn B) là cách tiếp cận tốt nhất. Phiên bản dự phòng được sao chép không đồng bộ từ phiên bản chính, do đó các thao tác đọc sẽ không ảnh hưởng đến các thao tác ghi. Bật bộ nhớ đệm đọc qua (tùy chọn A) hoặc việc tạo bản sao Aurora (tùy chọn C) sẽ không giải quyết được vấn đề tranh chấp I/O. Việc tạo cơ sở dữ liệu Aurora thứ hai và liên kết nó dưới dạng bản sao đọc (tùy chọn D) cũng sẽ không giải quyết được vấn đề tranh chấp I/O. Câu trả lời đúng là B. |
| Đường dẫn mẫu số 1 | Việc mở rộng quy mô phiên bản EC2 lên gấp 10 lần kích thước hiện tại của nó có thể không khả thi, xét từ góc độ chi phí hoặc hiệu suất. Nó sẽ yêu cầu một phiên bản lớn hơn và có thể tốn kém. Một cách tiếp cận hiệu quả hơn về mặt chi phí có thể là sử dụng một loạt các phiên bản nhỏ hơn (ví dụ: Auto Scaling Group) để chia sẻ tải. Trong trường hợp này, phiên bản EC2 có thể cần phải được cấu trúc lại. Câu trả lời đúng là c. | Việc sửa đổi ứng dụng để sử dụng các điểm cuối thích hợp không phải là một giải pháp thực tế vì nó sẽ yêu cầu thay đổi mã ứng dụng. Câu trả lời đúng là C: Tạo bản sao Aurora và sửa đổi ứng dụng để sử dụng các điểm cuối thích hợp. |
| Đường dẫn mẫu số 2 | Việc thay đổi quy mô một phiên bản EC2 khó khăn và rắc rối hơn so với việc thay đổi quy mô các thành phần dịch vụ khác. Amazon SQS, Lambda và DynamoDB đều có thể tự động mở rộng quy mô để đối phó với tải tăng lên. Câu trả lời đúng là c. |
(C) Tạo bản sao Aurora và sửa đổi ứng dụng để sử dụng các điểm cuối thích hợp. Bằng cách định cấu hình Bản sao Aurora, bạn có thể tách lưu lượng đọc khỏi lưu lượng ghi. Bản sao Aurora sử dụng các URL điểm cuối khác nhau, cho phép bạn hướng lưu lượng đọc đến bản sao thay vì cơ sở dữ liệu chính. Bản sao có thể xử lý các yêu cầu đọc song song với yêu cầu ghi vào cơ sở dữ liệu chính, giảm I/O và độ trễ. |
Làm sạch
Việc chạy suy luận hàng loạt trong Amazon Bedrock phải chịu phí theo Bảng giá của Amazon Bedrock. Khi bạn hoàn thành hướng dẫn này, hãy xóa phiên bản sổ ghi chép SageMaker của bạn và xóa tất cả dữ liệu khỏi bộ chứa S3 của bạn để tránh phát sinh các khoản phí trong tương lai.
Những cân nhắc
Mặc dù giải pháp đã được chứng minh cho thấy hiệu suất được cải thiện của các mô hình ngôn ngữ khi được nhắc nhở về tính tự nhất quán, nhưng điều quan trọng cần lưu ý là hướng dẫn này chưa sẵn sàng cho sản xuất. Trước khi triển khai vào sản xuất, bạn nên điều chỉnh bằng chứng khái niệm này cho phù hợp với cách triển khai của riêng mình, đồng thời lưu ý các yêu cầu sau:
- Hạn chế truy cập vào API và cơ sở dữ liệu để ngăn chặn việc sử dụng trái phép.
- Tuân thủ các biện pháp bảo mật tốt nhất của AWS liên quan đến các nhóm bảo mật và quyền truy cập vai trò IAM.
- Xác thực và dọn dẹp dữ liệu đầu vào của người dùng để ngăn chặn các cuộc tấn công tiêm nhiễm ngay lập tức.
- Giám sát và ghi nhật ký các quy trình được kích hoạt để cho phép kiểm tra và kiểm tra.
Kết luận
Bài đăng này cho thấy rằng việc nhắc nhở tự thống nhất giúp nâng cao hiệu suất của các mô hình ngôn ngữ tổng quát trong các nhiệm vụ NLP phức tạp đòi hỏi kỹ năng logic số học và trắc nghiệm. Tính tự nhất quán sử dụng giải mã ngẫu nhiên dựa trên nhiệt độ để tạo ra các đường lý luận khác nhau. Điều này làm tăng khả năng của mô hình trong việc khơi gợi những suy nghĩ đa dạng và hữu ích để đi đến câu trả lời chính xác.
Với suy luận hàng loạt của Amazon Bedrock, mô hình ngôn ngữ Cohere Command được nhắc tạo ra các câu trả lời tự nhất quán cho một tập hợp các bài toán số học. Độ chính xác cải thiện từ 51.7% với giải mã tham lam lên 68% với lấy mẫu tự thống nhất 30 đường dẫn lý luận ở T=1.0. Việc lấy mẫu năm đường dẫn đã nâng cao độ chính xác thêm 7.5 điểm phần trăm. Phương pháp này có thể được áp dụng cho các mô hình ngôn ngữ và nhiệm vụ suy luận khác, như được thể hiện qua kết quả của mô hình AI21 Labs Jurassic-2 Mid trong bài kiểm tra Chứng chỉ AWS. Trong một bộ câu hỏi có quy mô nhỏ, tính tự nhất quán với năm đường dẫn được lấy mẫu sẽ tăng độ chính xác lên 5 điểm phần trăm so với CoT tham lam.
Chúng tôi khuyến khích bạn triển khai tính năng nhắc nhở tự thống nhất để nâng cao hiệu suất trong các ứng dụng của riêng bạn bằng các mô hình ngôn ngữ tổng quát. Học nhiều hơn về Lệnh mạch lạc và Phòng thí nghiệm AI21 kỷ Jura các mẫu có sẵn trên Amazon Bedrock. Để biết thêm thông tin về suy luận hàng loạt, hãy tham khảo Chạy suy luận hàng loạt.
Lời cảm ơn
Tác giả cảm ơn các nhà đánh giá kỹ thuật Amin Tajgardoon và Patrick McSweeney vì những phản hồi hữu ích.
Lưu ý

Lucia Santamaría là Nhà khoa học ứng dụng cấp cao tại Đại học ML của Amazon, nơi cô tập trung vào việc nâng cao trình độ năng lực ML trong toàn công ty thông qua giáo dục thực hành. Lucía có bằng Tiến sĩ về vật lý thiên văn và đam mê dân chủ hóa khả năng tiếp cận kiến thức và công cụ công nghệ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

