
Hình ảnh của Tác giả
Mistral AI, một trong những công ty nghiên cứu AI hàng đầu thế giới, gần đây đã phát hành mô hình cơ sở cho Mistral 7B v0.2.
Mô hình ngôn ngữ nguồn mở này đã được ra mắt trong sự kiện hackathon của công ty vào ngày 23 tháng 2024 năm XNUMX.
Các mẫu Mistral 7B có 7.3 tỷ thông số khiến chúng trở nên cực kỳ mạnh mẽ. Chúng vượt trội hơn Llama 2 13B và Llama 1 34B trên hầu hết các điểm chuẩn. Mẫu V0.2 mới nhất giới thiệu cửa sổ ngữ cảnh 32k cùng với những cải tiến khác, nâng cao khả năng xử lý và tạo văn bản.
Ngoài ra, phiên bản được công bố gần đây là mẫu cơ sở của biến thể được điều chỉnh theo hướng dẫn, “Mistral-7B-Instruct-V0.2,” được phát hành vào đầu năm ngoái.
Trong hướng dẫn này, tôi sẽ hướng dẫn bạn cách truy cập và tinh chỉnh mô hình ngôn ngữ này trên Ôm Mặt.
Chúng tôi sẽ tinh chỉnh mô hình cơ sở Mistral 7B-v0.2 bằng chức năng AutoTrain của Hugging Face.
Ôm mặt nổi tiếng vì dân chủ hóa quyền truy cập vào các mô hình học máy, cho phép người dùng hàng ngày phát triển các giải pháp AI tiên tiến.
AutoTrain, một tính năng của Ôm mặt, tự động hóa quá trình đào tạo mô hình, giúp quá trình này trở nên dễ tiếp cận và hiệu quả.
Nó giúp người dùng chọn các thông số và kỹ thuật đào tạo tốt nhất khi tinh chỉnh mô hình, đây là một nhiệm vụ có thể gây khó khăn và tốn thời gian.
Dưới đây là 5 bước để tinh chỉnh mẫu Mistral-7B của bạn:
1. Thiết lập môi trường
Trước tiên, bạn phải tạo một tài khoản với Ôm Mặt, sau đó tạo kho lưu trữ mô hình.
Để đạt được điều này, chỉ cần làm theo các bước được cung cấp trong này Link và quay lại hướng dẫn này.
Chúng tôi sẽ đào tạo mô hình bằng Python. Khi cần chọn môi trường sổ ghi chép để đào tạo, bạn có thể sử dụng Sổ tay Kaggle or google colab, cả hai đều cung cấp quyền truy cập miễn phí vào GPU.
Nếu quá trình đào tạo mất quá nhiều thời gian, bạn có thể muốn chuyển sang nền tảng đám mây như AWS Sagemaker hoặc Azure ML.
Cuối cùng, thực hiện cài đặt pip sau trước khi bạn bắt đầu viết mã theo hướng dẫn này:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Chuẩn bị tập dữ liệu của bạn
Trong hướng dẫn này, chúng tôi sẽ sử dụng Tập dữ liệu Alpaca trên Khuôn mặt ôm, trông như thế này:
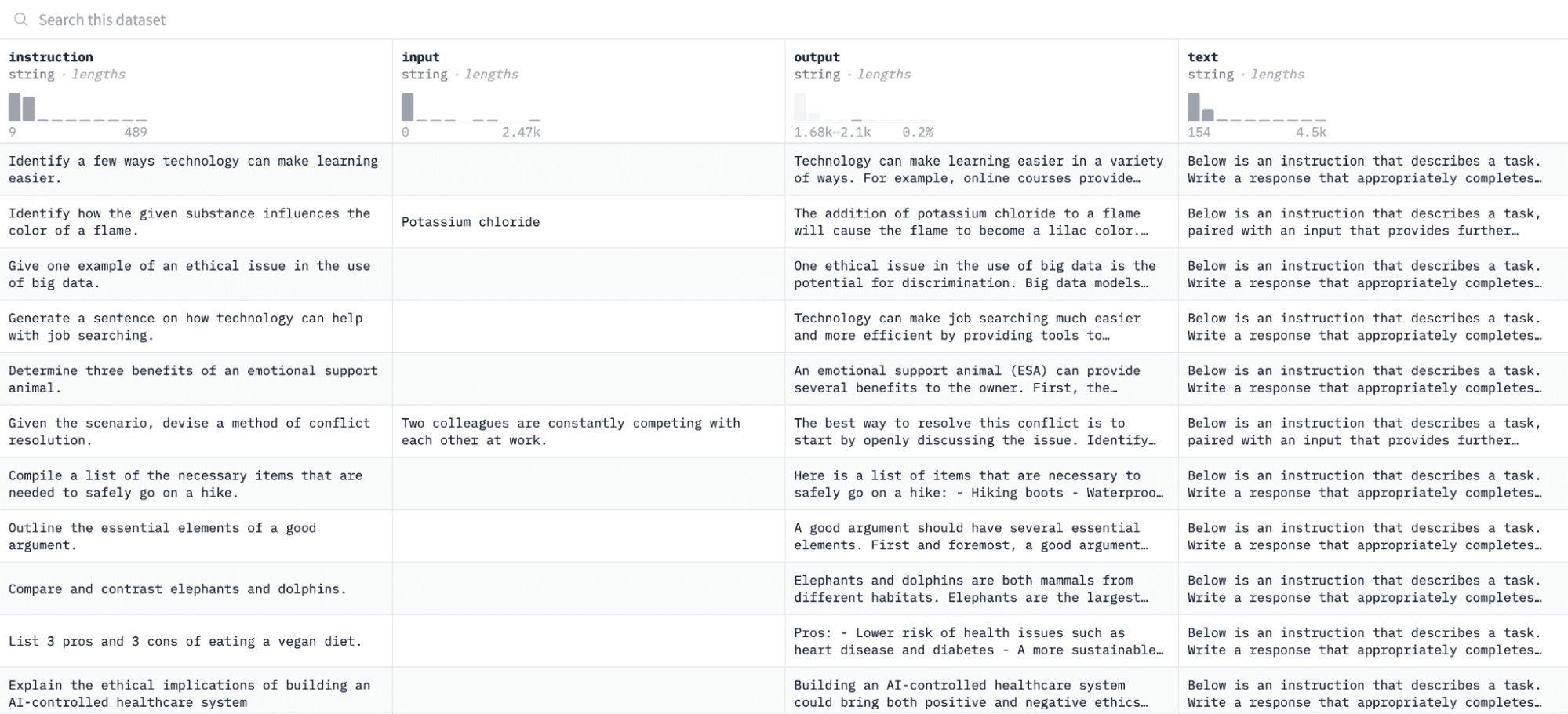
Chúng tôi sẽ tinh chỉnh mô hình theo các cặp lệnh và đầu ra, đồng thời đánh giá khả năng đáp ứng của nó với lệnh đã cho trong quá trình đánh giá.
Để truy cập và chuẩn bị tập dữ liệu này, hãy chạy các dòng mã sau:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")Hàm đầu tiên sẽ tải tập dữ liệu Alpaca bằng thư viện “bộ dữ liệu” và làm sạch nó để đảm bảo rằng chúng tôi không bao gồm bất kỳ hướng dẫn trống nào. Hàm thứ hai cấu trúc dữ liệu của bạn theo định dạng mà AutoTrain có thể hiểu được.
Sau khi chạy đoạn mã trên, tập dữ liệu sẽ được tải, định dạng và lưu vào đường dẫn đã chỉ định. Khi mở tập dữ liệu đã định dạng, bạn sẽ thấy một cột duy nhất có nhãn “văn bản được định dạng”.
3. Thiết lập môi trường đào tạo của bạn
Bây giờ bạn đã chuẩn bị thành công tập dữ liệu, hãy tiến hành thiết lập môi trường đào tạo mô hình của bạn.
Để làm điều này, bạn phải xác định các tham số sau:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Dưới đây là bảng phân tích các thông số kỹ thuật trên:
- Bạn có thể chỉ định bất kỳ Tên dự án. Đây là nơi tất cả các tệp dự án và đào tạo của bạn sẽ được lưu trữ.
- Sản phẩm tên_người mẫu tham số là mô hình bạn muốn tinh chỉnh. Trong trường hợp này, tôi đã chỉ định đường dẫn đến Mẫu cơ bản Mistral-7B v0.2 trên Ôm Mặt.
- Sản phẩm hf_token biến phải được đặt thành mã thông báo Ôm mặt của bạn, có thể lấy được bằng cách điều hướng đến liên kết này.
- trên màn hình repo_id phải được đặt thành kho lưu trữ mô hình Khuôn mặt ôm mà bạn đã tạo ở bước đầu tiên của hướng dẫn này. Ví dụ: ID kho lưu trữ của tôi là NatashaS/Model2.
4. Cấu hình các tham số mô hình
Trước khi tinh chỉnh mô hình của mình, chúng ta phải xác định các tham số huấn luyện kiểm soát các khía cạnh của hành vi mô hình như thời gian đào tạo và tính chính quy.
Các tham số này ảnh hưởng đến các khía cạnh chính như thời gian đào tạo của mô hình, cách mô hình học từ dữ liệu và cách tránh điều chỉnh quá mức.
Bạn có thể đặt các tham số sau cho mô hình của mình:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Đặt biến môi trường
Bây giờ chúng ta hãy chuẩn bị môi trường đào tạo của mình bằng cách đặt một số biến môi trường.
Bước này đảm bảo rằng tính năng AutoTrain sử dụng các cài đặt mong muốn để tinh chỉnh mô hình, chẳng hạn như tên dự án và tùy chọn đào tạo của chúng tôi:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Bắt đầu đào tạo người mẫu
Cuối cùng, hãy bắt đầu huấn luyện mô hình bằng cách sử dụng tàu tự động yêu cầu. Bước này bao gồm việc chỉ định mô hình, tập dữ liệu và cấu hình đào tạo của bạn, như được hiển thị bên dưới:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Đảm bảo thay đổi đường dẫn dữ liệu đến nơi tập dữ liệu đào tạo của bạn được đặt.
7. Đánh giá mô hình
Khi mô hình của bạn đã đào tạo xong, bạn sẽ thấy một thư mục xuất hiện trong thư mục có cùng tiêu đề với tên dự án của bạn.
Trong trường hợp của tôi, thư mục này có tiêu đề “sai lầm,” như được thấy trong hình ảnh dưới đây:
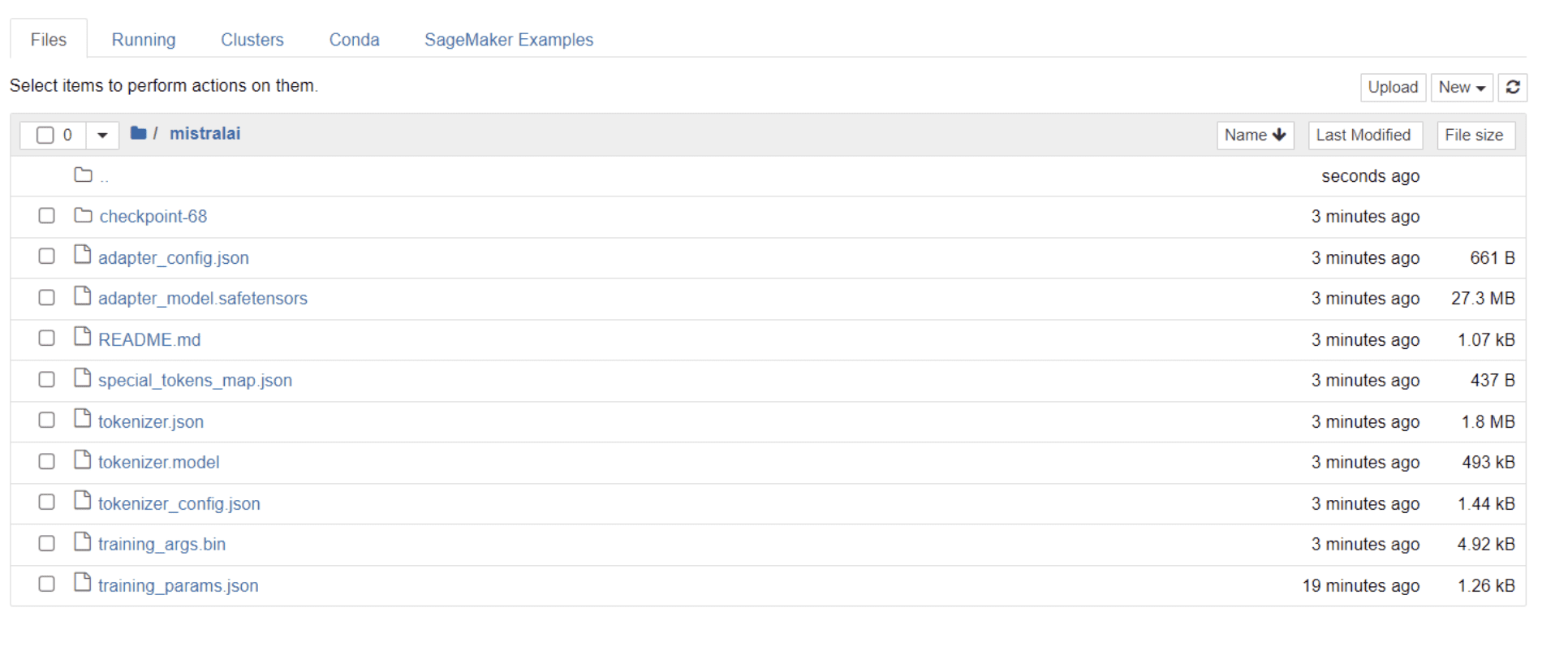
Trong thư mục này, bạn có thể tìm thấy các tệp bao gồm trọng lượng mô hình, siêu tham số và chi tiết kiến trúc của bạn.
Bây giờ hãy kiểm tra xem mô hình tinh chỉnh này có thể phản hồi chính xác cho câu hỏi trong tập dữ liệu của chúng tôi hay không. Để đạt được điều này, trước tiên chúng tôi cần chạy các dòng mã sau để tạo 5 đầu vào và đầu ra mẫu từ tập dữ liệu của mình:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")Bạn sẽ thấy phản hồi giống như thế này, hiển thị 5 điểm dữ liệu mẫu:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Chúng ta sẽ nhập một trong các hướng dẫn trên vào mô hình và kiểm tra xem nó có tạo ra đầu ra chính xác hay không. Đây là một chức năng cung cấp hướng dẫn cho mô hình và nhận phản hồi từ nó:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerCuối cùng, nhập câu hỏi vào chức năng này như hiển thị bên dưới:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Mô hình của bạn sẽ tạo ra phản hồi giống hệt với đầu ra tương ứng của nó trong tập dữ liệu huấn luyện, như được hiển thị bên dưới:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andXin lưu ý rằng phản hồi có thể dường như không đầy đủ hoặc bị cắt bớt do số lượng mã thông báo mà chúng tôi đã chỉ định. Vui lòng điều chỉnh giá trị “max_length” để cho phép phản hồi mở rộng hơn.
Nếu bạn đã đi xa đến mức này, xin chúc mừng!
Bạn đã tinh chỉnh thành công mô hình ngôn ngữ tiên tiến, tận dụng sức mạnh của Mistral 7B v-0.2 cùng với khả năng của Ôm Mặt.
Nhưng cuộc hành trình không kết thúc ở đây.
Bước tiếp theo, tôi khuyên bạn nên thử nghiệm với các bộ dữ liệu khác nhau hoặc điều chỉnh các tham số huấn luyện nhất định để tối ưu hóa hiệu suất mô hình. Việc tinh chỉnh các mô hình ở quy mô lớn hơn sẽ nâng cao tiện ích của chúng, vì vậy hãy thử thử nghiệm với các tập dữ liệu lớn hơn hoặc các định dạng khác nhau, chẳng hạn như tệp PDF và tệp văn bản.
Kinh nghiệm như vậy trở nên vô giá khi làm việc với dữ liệu thực tế trong các tổ chức, vốn thường lộn xộn và không có cấu trúc.
Natasha Selvaraj là một nhà khoa học dữ liệu tự học với niềm đam mê viết lách. Natasha viết về mọi thứ liên quan đến khoa học dữ liệu, một bậc thầy thực sự về tất cả các chủ đề dữ liệu. Bạn có thể kết nối với cô ấy trên LinkedIn hoặc kiểm tra cô ấy Kênh YouTube.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

