Tìm kiếm mở là bộ phần mềm nguồn mở có thể mở rộng, linh hoạt và có thể mở rộng dành cho các ứng dụng tìm kiếm, phân tích, giám sát bảo mật và khả năng quan sát, được cấp phép theo giấy phép Apache 2.0. Nó bao gồm một công cụ tìm kiếm, OpenSearch, cung cấp khả năng tìm kiếm và tổng hợp có độ trễ thấp, Bảng điều khiển OpenSearch, một công cụ trực quan hóa và bảng điều khiển cũng như một bộ plugin cung cấp các khả năng nâng cao như cảnh báo, kiểm soát truy cập chi tiết, khả năng quan sát, giám sát an ninh và lưu trữ và xử lý véc tơ. Dịch vụ Tìm kiếm Mở của Amazon là một dịch vụ được quản lý toàn phần giúp việc triển khai, thay đổi quy mô và vận hành OpenSearch trong Đám mây AWS trở nên đơn giản.
Là người dùng cuối, khi bạn sử dụng các khả năng tìm kiếm của OpenSearch, bạn thường có mục tiêu trong đầu—điều gì đó bạn muốn hoàn thành. Đồng thời, bạn sử dụng OpenSearch để thu thập thông tin hỗ trợ đạt được mục tiêu đó (hoặc có thể thông tin là mục tiêu ban đầu). Tất cả chúng ta đã quen với giao diện “hộp tìm kiếm”, nơi bạn nhập một số từ và công cụ tìm kiếm sẽ trả lại kết quả dựa trên kết hợp từ với từ. Giả sử bạn muốn mua một chiếc ghế dài để dành những buổi tối ấm cúng với gia đình quanh đống lửa. Bạn truy cập Amazon.com và gõ “một nơi ấm cúng để ngồi bên đống lửa”. Thật không may, nếu bạn chạy tìm kiếm đó trên Amazon.com, bạn sẽ nhận được các mặt hàng như hố lửa, quạt sưởi và đồ trang trí nhà cửa—không như ý muốn của bạn. Vấn đề là các nhà sản xuất đi văng có thể đã không sử dụng các từ “ấm cúng”, “nơi chốn”, “ngồi” và “cháy” trong tiêu đề hoặc mô tả sản phẩm của họ.
Trong những năm gần đây, các kỹ thuật học máy (ML) ngày càng trở nên phổ biến để tăng cường tìm kiếm. Trong số đó có việc sử dụng các mô hình nhúng, một loại mô hình có thể mã hóa một lượng lớn dữ liệu vào không gian n chiều trong đó mỗi thực thể được mã hóa thành một vectơ, một điểm dữ liệu trong không gian đó và được tổ chức sao cho các thực thể tương tự được gần nhau hơn nữa. Ví dụ, một mô hình nhúng có thể mã hóa ngữ nghĩa của một văn bản. Bằng cách tìm kiếm các vectơ gần nhất với tài liệu được mã hóa — tìm kiếm k-láng giềng gần nhất (k-NN) — bạn có thể tìm thấy các tài liệu giống nhau nhất về mặt ngữ nghĩa. Ví dụ, các mô hình nhúng tinh vi có thể hỗ trợ nhiều phương thức, mã hóa hình ảnh và văn bản của danh mục sản phẩm và cho phép khớp tương tự trên cả hai phương thức.
Cơ sở dữ liệu vectơ cung cấp tìm kiếm tương tự vectơ hiệu quả bằng cách cung cấp các chỉ mục chuyên biệt như chỉ mục k-NN. Nó cũng cung cấp chức năng cơ sở dữ liệu khác như quản lý dữ liệu vectơ cùng với các loại dữ liệu khác, quản lý khối lượng công việc, kiểm soát truy cập, v.v. Plugin k-NN của OpenSearch cung cấp chức năng cơ sở dữ liệu vector cốt lõi cho OpenSearch, vì vậy, khi khách hàng của bạn tìm kiếm "một nơi ấm cúng để ngồi bên lò sưởi" trong danh mục của bạn, bạn có thể mã hóa lời nhắc đó và sử dụng OpenSearch để thực hiện truy vấn hàng xóm gần nhất để hiển thị chiếc ghế dài 8 foot, màu xanh lam đó với các bức ảnh được nhà thiết kế sắp xếp ở phía trước của lò sưởi.
Sử dụng OpenSearch Service làm cơ sở dữ liệu vectơ
Với khả năng cơ sở dữ liệu véc tơ của Dịch vụ tìm kiếm mở, bạn có thể triển khai tìm kiếm ngữ nghĩa, Thế hệ tăng cường truy xuất (RAG) với LLM, công cụ đề xuất và tìm kiếm đa phương tiện.
Tìm kiếm ngữ nghĩa
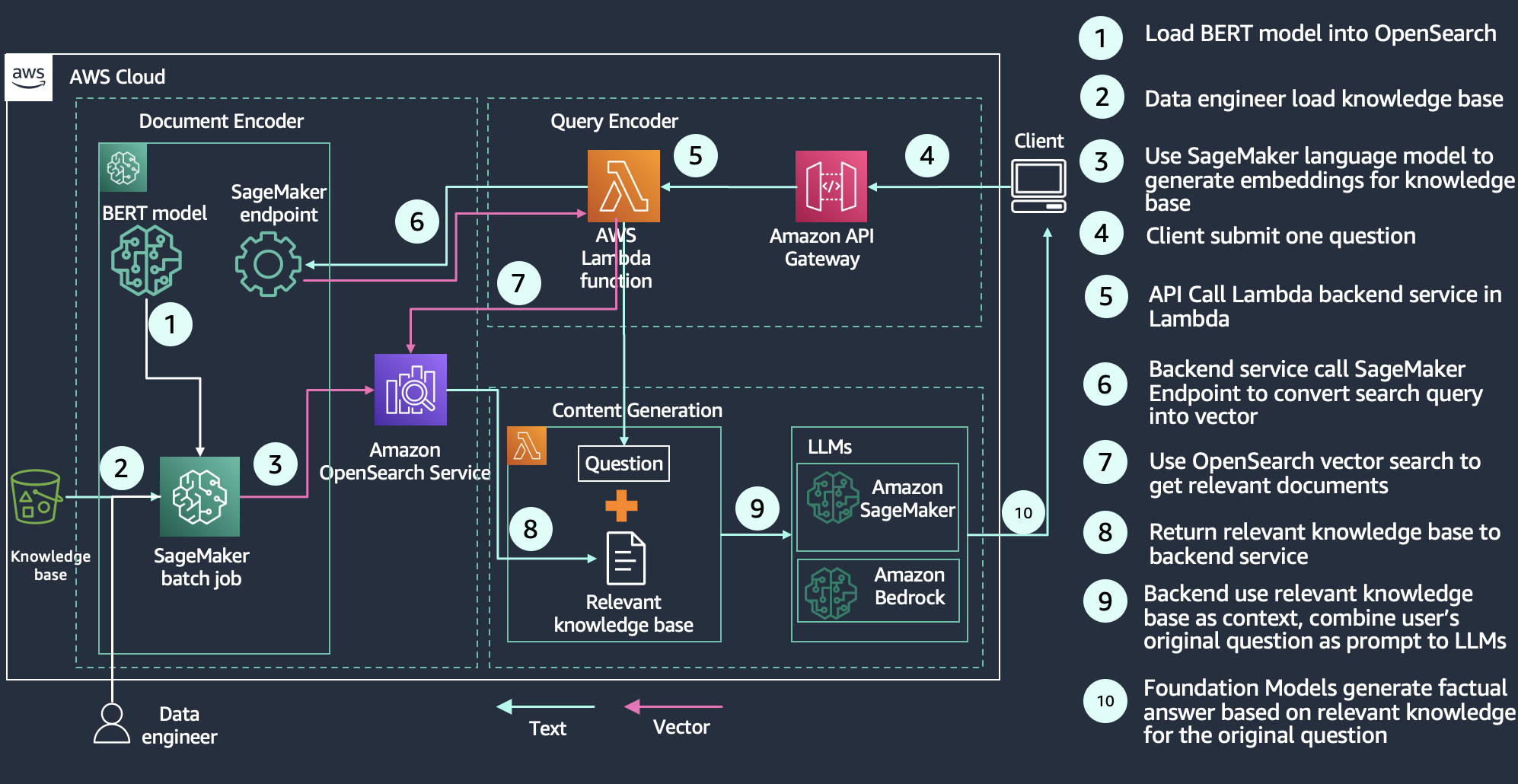
Với tìm kiếm ngữ nghĩa, bạn cải thiện mức độ liên quan của các kết quả đã truy xuất bằng cách sử dụng các nhúng dựa trên ngôn ngữ trên các tài liệu tìm kiếm. Bạn cho phép khách hàng tìm kiếm của mình sử dụng các truy vấn bằng ngôn ngữ tự nhiên, chẳng hạn như “một nơi ấm cúng để ngồi bên lò sưởi” để tìm chiếc ghế dài màu xanh lam dài 8 foot của họ. Để biết thêm thông tin, hãy tham khảo Xây dựng công cụ tìm kiếm ngữ nghĩa trong OpenSearch để tìm hiểu cách tìm kiếm ngữ nghĩa có thể cải thiện mức độ liên quan 15%, được đo bằng mức tăng tích lũy được chiết khấu chuẩn hóa (nDCG) số liệu so với tìm kiếm từ khóa. Ví dụ cụ thể, chúng tôi Cải thiện mức độ liên quan của tìm kiếm với ML trong Amazon OpenSearch Service hội thảo khám phá sự khác biệt giữa tìm kiếm từ khóa và ngữ nghĩa, dựa trên một Biểu diễn mã hóa hai chiều từ Máy biến áp (BERT) mô hình, được tổ chức bởi Amazon SageMaker để tạo các vectơ và lưu trữ chúng trong OpenSearch. Hội thảo sử dụng các câu trả lời cho câu hỏi về sản phẩm làm ví dụ để cho thấy cách tìm kiếm từ khóa bằng cách sử dụng các từ khóa/cụm từ của truy vấn dẫn đến một số kết quả không liên quan. Tìm kiếm theo ngữ nghĩa có thể truy xuất các tài liệu phù hợp hơn bằng cách khớp với ngữ cảnh và ngữ nghĩa của truy vấn. Sơ đồ sau đây cho thấy một kiến trúc ví dụ cho ứng dụng tìm kiếm ngữ nghĩa với OpenSearch Service làm cơ sở dữ liệu vectơ.

Truy xuất thế hệ tăng cường với LLM
RAG là một phương pháp để xây dựng các chatbot AI tổng quát đáng tin cậy bằng cách sử dụng các LLM tổng quát như OpenAI, ChatGPT hoặc Văn bản Amazon Titan. Với sự gia tăng của các LLM tổng quát, các nhà phát triển ứng dụng đang tìm cách tận dụng lợi thế của công nghệ tiên tiến này. Một trường hợp sử dụng phổ biến liên quan đến việc cung cấp trải nghiệm đàm thoại thông qua các tác nhân thông minh. Có lẽ bạn là nhà cung cấp phần mềm có cơ sở kiến thức về thông tin sản phẩm, khách hàng tự phục vụ hoặc kiến thức về lĩnh vực ngành như quy tắc báo cáo thuế hoặc thông tin y tế về bệnh tật và phương pháp điều trị. Trải nghiệm tìm kiếm đàm thoại cung cấp giao diện trực quan để người dùng sàng lọc thông tin thông qua hộp thoại và Hỏi & Đáp. Bản thân các LLM tạo ra có xu hướng ảo giác—một tình huống trong đó mô hình tạo ra phản hồi đáng tin cậy nhưng thực tế không chính xác. RAG giải quyết vấn đề này bằng cách bổ sung cho các LLM tổng quát với cơ sở kiến thức bên ngoài thường được xây dựng bằng cách sử dụng cơ sở dữ liệu vectơ chứa đầy các bài viết kiến thức được mã hóa bằng vectơ.
Như được minh họa trong sơ đồ sau, quy trình truy vấn bắt đầu bằng một câu hỏi được mã hóa và sử dụng để truy xuất các bài viết trong cơ sở kiến thức có liên quan từ cơ sở dữ liệu vectơ. Những kết quả đó được gửi đến LLM chung có nhiệm vụ bổ sung những kết quả đó, thường bằng cách tóm tắt kết quả dưới dạng phản hồi đàm thoại. Bằng cách bổ sung cho mô hình tổng quát một cơ sở tri thức, RAG đặt mô hình dựa trên các sự kiện để giảm thiểu ảo giác. Bạn có thể tìm hiểu thêm về cách xây dựng giải pháp RAG trong Mô-đun Thế hệ Tăng cường Truy xuất của hội thảo tìm kiếm ngữ nghĩa của chúng tôi.
Công cụ đề xuất
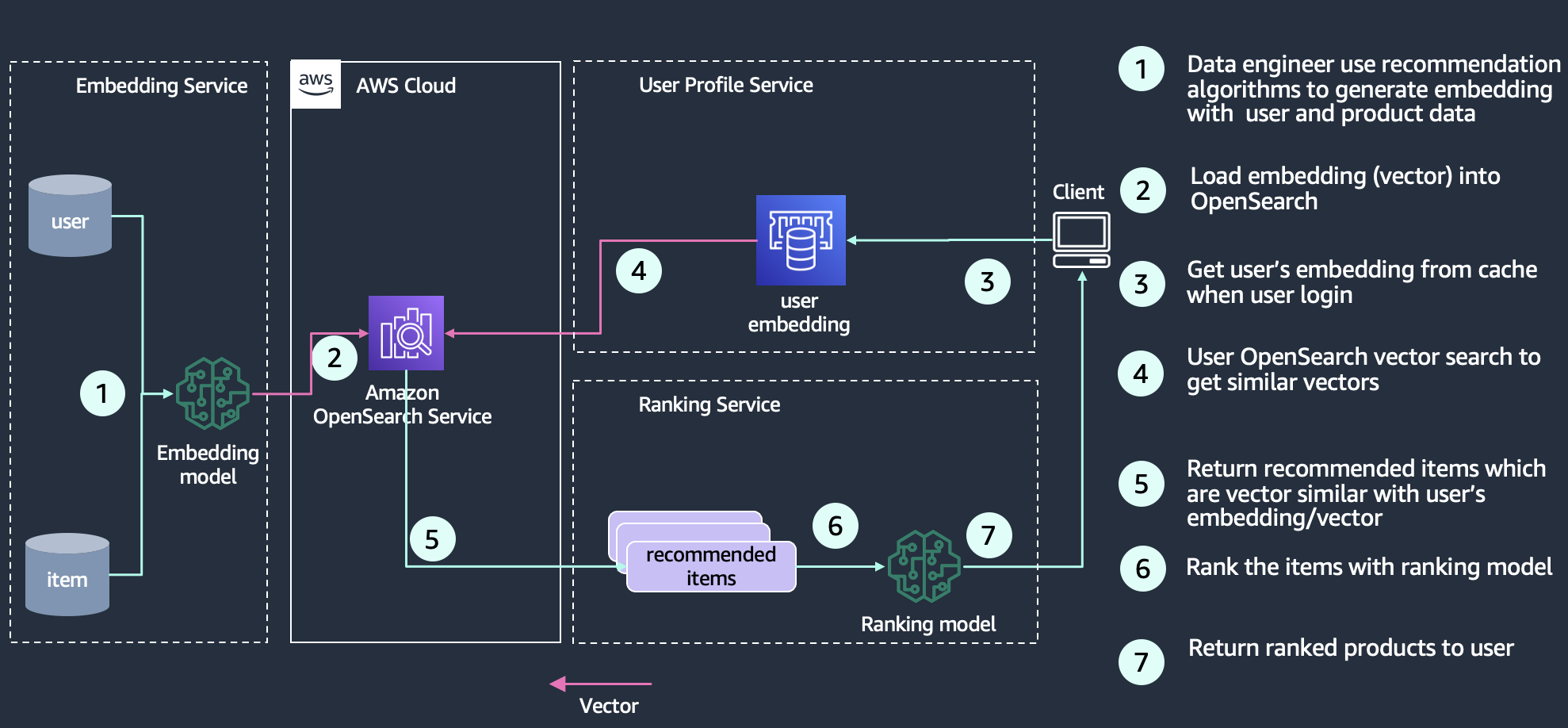
Đề xuất là một thành phần phổ biến trong trải nghiệm tìm kiếm, đặc biệt đối với các ứng dụng thương mại điện tử. Việc thêm tính năng trải nghiệm người dùng như “thích cái này hơn” hoặc “khách hàng đã mua cái này cũng đã mua cái kia” có thể tăng thêm doanh thu thông qua việc cung cấp cho khách hàng những gì họ muốn. Kiến trúc sư tìm kiếm sử dụng nhiều kỹ thuật và công nghệ để xây dựng đề xuất, bao gồm Mạng lưới thần kinh sâu (DNN) các thuật toán đề xuất dựa trên như mô hình mạng nơ-ron hai tháp, YoutubeDNN. Ví dụ: một mô hình nhúng được đào tạo sẽ mã hóa các sản phẩm vào một không gian nhúng nơi các sản phẩm thường được mua cùng nhau được coi là giống nhau hơn và do đó được biểu diễn dưới dạng các điểm dữ liệu gần nhau hơn trong không gian nhúng. Khả năng khác
là việc nhúng sản phẩm dựa trên sự tương đồng về đồng xếp hạng thay vì hoạt động mua hàng. Bạn có thể sử dụng dữ liệu mối quan hệ này thông qua việc tính toán độ tương tự vectơ giữa cách nhúng của một người dùng cụ thể và vectơ trong cơ sở dữ liệu để trả về các mục được đề xuất. Sơ đồ sau đây cho thấy một ví dụ về kiến trúc xây dựng công cụ đề xuất với OpenSearch dưới dạng kho lưu trữ vectơ.
tìm kiếm phương tiện
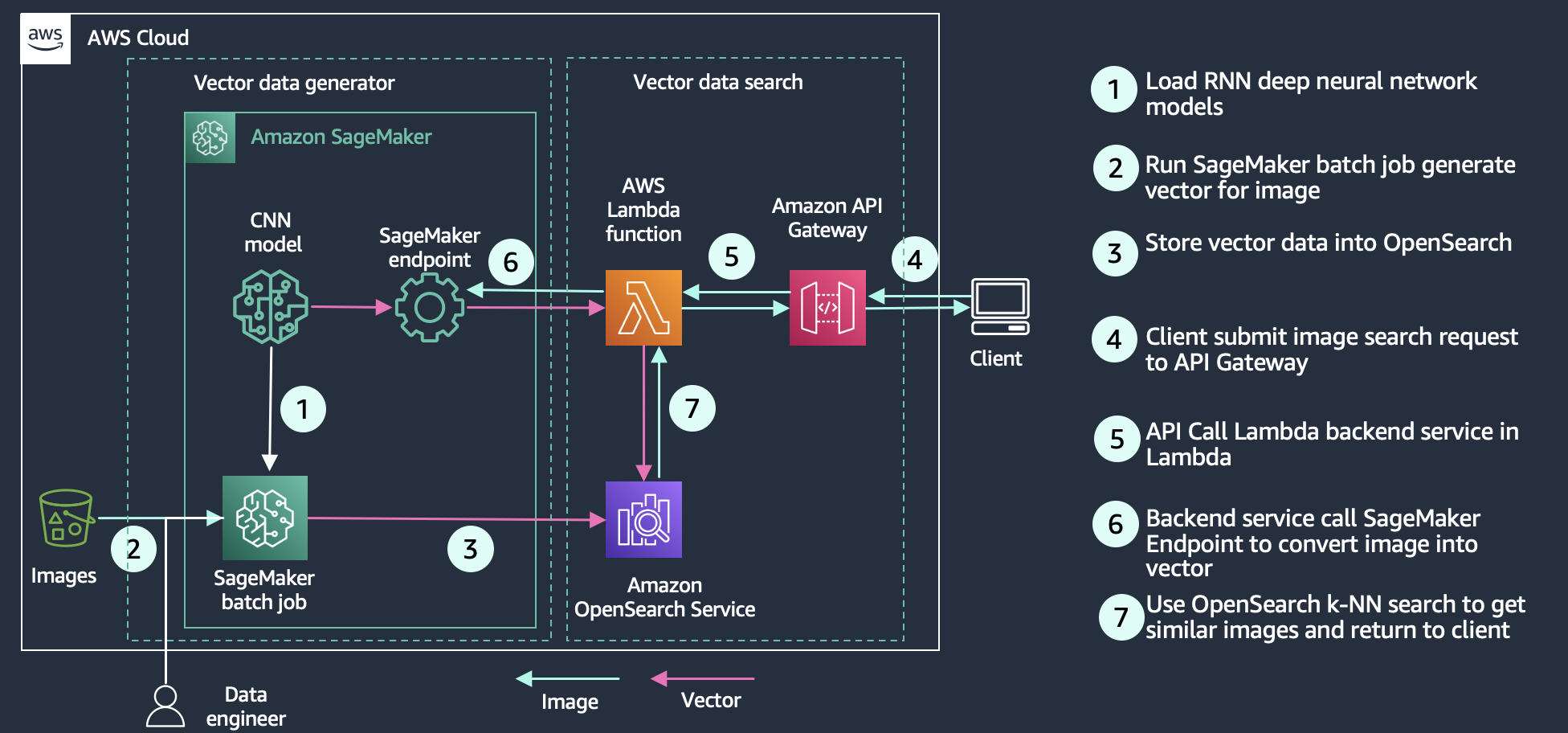
Tìm kiếm phương tiện cho phép người dùng truy vấn công cụ tìm kiếm bằng đa phương tiện như hình ảnh, âm thanh và video. Việc triển khai nó tương tự như tìm kiếm ngữ nghĩa—bạn tạo các nhúng vectơ cho các tài liệu tìm kiếm của mình và sau đó truy vấn Dịch vụ Tìm kiếm Mở bằng một vectơ. Sự khác biệt là bạn sử dụng mạng thần kinh sâu về thị giác máy tính (ví dụ: Mạng thần kinh chuyển đổi (CNN)) chẳng hạn như ResNet để chuyển đổi hình ảnh thành vectơ. Sơ đồ sau đây cho thấy một ví dụ về cấu trúc xây dựng tìm kiếm hình ảnh với OpenSearch làm kho lưu trữ vectơ.
Hiểu biết về công nghệ
OpenSearch sử dụng các thuật toán hàng xóm gần nhất (ANN) gần đúng từ NMSLIB, THẤT BẠIvà Lucene các thư viện để hỗ trợ tìm kiếm k-NN. Các phương pháp tìm kiếm này sử dụng ANN để cải thiện độ trễ tìm kiếm cho các bộ dữ liệu lớn. Trong số ba phương pháp tìm kiếm mà plugin k-NN cung cấp, phương pháp này mang lại khả năng mở rộng tìm kiếm tốt nhất cho các tập dữ liệu lớn. Chi tiết động cơ như sau:
- Thư viện không gian phi số liệu (NMSLIB) – NMSLIB triển khai thuật toán HNSW ANN
- Tìm kiếm tương đồng AI trên Facebook (FAISS) – FAISS triển khai cả thuật toán HNSW và IVF ANN
- Lucene – Lucene thực hiện thuật toán HNSW
Mỗi công cụ trong số ba công cụ được sử dụng để tìm kiếm k-NN gần đúng đều có các thuộc tính riêng giúp sử dụng một công cụ hợp lý hơn các công cụ khác trong một tình huống nhất định. Bạn có thể theo dõi thông tin chung trong phần này để giúp xác định động cơ nào sẽ đáp ứng tốt nhất các yêu cầu của bạn.
Nói chung, nên chọn NMSLIB và FAISS cho các trường hợp sử dụng quy mô lớn. Lucene là một lựa chọn tốt cho các triển khai nhỏ hơn, nhưng cung cấp các lợi ích như lọc thông minh trong đó chiến lược lọc tối ưu—lọc trước, lọc sau hoặc k-NN chính xác—được tự động áp dụng tùy theo tình huống. Bảng sau đây tóm tắt sự khác biệt giữa mỗi tùy chọn.
| . |
NMSLIB-HNSW |
FAISS-HNSW |
FAISS-IVF |
Lucene-HNSW |
|
Kích thước tối đa |
16,000 |
16,000 |
16,000 |
1024 |
|
Lọc |
Bộ lọc bài đăng |
Bộ lọc bài đăng |
Bộ lọc bài đăng |
Lọc trong khi tìm kiếm |
|
Cần đào tạo |
Không |
Không |
Có |
Không |
|
Số liệu tương tự |
l2, sản phẩm bên trong, cosinesimil, l1, linf |
l2, sản phẩm bên trong |
l2, sản phẩm bên trong |
l2, cosinsimil |
|
khối lượng véc tơ |
hàng chục tỷ |
hàng chục tỷ |
hàng chục tỷ |
< Mười triệu |
|
Độ trễ lập chỉ mục |
Thấp |
Thấp |
Giá thấp nhất |
Thấp |
|
Độ trễ & Chất lượng truy vấn |
Độ trễ thấp & chất lượng cao |
Độ trễ thấp & chất lượng cao |
Độ trễ thấp & chất lượng thấp |
Độ trễ cao & chất lượng cao |
|
nén véc tơ |
Bằng phẳng |
Bằng phẳng Lượng tử hóa sản phẩm |
Bằng phẳng Lượng tử hóa sản phẩm |
Bằng phẳng |
|
Tiêu thụ bộ nhớ |
Cao |
Cao PQ thấp |
Trung bình PQ thấp |
Cao |
Tìm kiếm hàng xóm gần nhất và chính xác
Plugin k-NN của Dịch vụ tìm kiếm mở hỗ trợ ba phương pháp khác nhau để có được k-hàng xóm gần nhất từ một chỉ số vectơ: k-NN gần đúng, tập lệnh điểm (k-NN chính xác) và tiện ích mở rộng không gây đau đớn (k-NN chính xác).
xấp xỉ k-NN
Phương pháp đầu tiên sử dụng cách tiếp cận gần đúng với hàng xóm gần nhất—phương thức này sử dụng một trong số các thuật toán để trả về k-láng giềng gần nhất gần đúng cho một vectơ truy vấn. Thông thường, các thuật toán này hy sinh tốc độ lập chỉ mục và độ chính xác của tìm kiếm để đổi lấy các lợi ích về hiệu suất chẳng hạn như độ trễ thấp hơn, dung lượng bộ nhớ nhỏ hơn và khả năng tìm kiếm có thể mở rộng hơn. K-NN gần đúng là lựa chọn tốt nhất cho các tìm kiếm trên các chỉ mục lớn (nghĩa là hàng trăm nghìn vectơ trở lên) yêu cầu độ trễ thấp. Bạn không nên sử dụng k-NN gần đúng nếu bạn muốn áp dụng bộ lọc trên chỉ mục trước khi tìm kiếm k-NN, điều này làm giảm đáng kể số lượng vectơ được tìm kiếm. Trong trường hợp này, bạn nên sử dụng phương pháp tập lệnh điểm số hoặc tiện ích mở rộng không gây đau đớn.
kịch bản tỷ số
Phương pháp thứ hai mở rộng chức năng tập lệnh điểm của Dịch vụ Tìm kiếm Mở chạy vũ phu thì chính xác k-NN search hết knn_vector các trường hoặc các trường có thể đại diện cho các đối tượng nhị phân. Với phương pháp này, bạn có thể chạy tìm kiếm k-NN trên một tập hợp con các vectơ trong chỉ mục của mình (đôi khi được gọi là tìm kiếm trước bộ lọc). Cách tiếp cận này được ưu tiên cho các tìm kiếm trên các phần tài liệu nhỏ hơn hoặc khi cần bộ lọc trước. Sử dụng phương pháp này trên các chỉ mục lớn có thể dẫn đến độ trễ cao.
tiện ích mở rộng không đau
Phương pháp thứ ba bổ sung các hàm khoảng cách dưới dạng tiện ích mở rộng dễ dàng mà bạn có thể sử dụng trong các kết hợp phức tạp hơn. Tương tự như tập lệnh điểm k-NN, bạn có thể sử dụng phương pháp này để thực hiện tìm kiếm k-NN chính xác, mạnh mẽ trên một chỉ mục, cũng hỗ trợ lọc trước. Cách tiếp cận này có hiệu suất truy vấn chậm hơn một chút so với tập lệnh điểm k-NN. Nếu trường hợp sử dụng của bạn yêu cầu nhiều tùy chỉnh hơn đối với điểm số cuối cùng, thì bạn nên sử dụng phương pháp này đối với tập lệnh điểm số k-NN.
Thuật toán tìm kiếm vectơ
Cách đơn giản để tìm các vectơ tương tự là sử dụng k-hàng xóm gần nhất (k-NN) các thuật toán tính toán khoảng cách giữa một vectơ truy vấn và các vectơ khác trong cơ sở dữ liệu vectơ. Như chúng tôi đã đề cập trước đó, tập lệnh điểm số k-NN và các phương pháp tìm kiếm tiện ích mở rộng không gây đau đớn sử dụng các thuật toán k-NN chính xác. Tuy nhiên, trong trường hợp tập dữ liệu cực lớn với số chiều cao, điều này tạo ra vấn đề mở rộng làm giảm hiệu quả tìm kiếm. Các phương pháp tìm kiếm hàng xóm gần nhất (ANN) có thể khắc phục điều này bằng cách sử dụng các công cụ tái cấu trúc các chỉ mục hiệu quả hơn và giảm kích thước của các vectơ có thể tìm kiếm. Có các thuật toán tìm kiếm ANN khác nhau; ví dụ: băm nhạy cảm cục bộ, dựa trên cây, dựa trên cụm và dựa trên biểu đồ. OpenSearch triển khai hai thuật toán ANN: Thế giới nhỏ có thể điều hướng theo cấp bậc (HNSW) và Hệ thống tệp đảo ngược (IVF). Để có giải thích chi tiết hơn về cách các thuật toán HNSW và IVF hoạt động trong OpenSearch, hãy xem bài đăng trên blog “Chọn thuật toán k-NN cho trường hợp sử dụng quy mô hàng tỷ của bạn với OpenSearch".
Thế giới nhỏ có thể điều hướng theo cấp bậc
Thuật toán HNSW là một trong những thuật toán phổ biến nhất hiện có để tìm kiếm ANN. Ý tưởng cốt lõi của thuật toán là xây dựng một đồ thị với các cạnh nối các vectơ chỉ số gần nhau. Sau đó, khi tìm kiếm, biểu đồ này được duyệt qua một phần để tìm các lân cận gần đúng nhất với vectơ truy vấn. Để điều khiển quá trình truyền tải tới các hàng xóm gần nhất của truy vấn, thuật toán luôn truy cập ứng cử viên gần nhất với vectơ truy vấn tiếp theo.
Tập tin đảo ngược
Thuật toán IVF phân tách các vectơ chỉ mục của bạn thành một tập hợp các nhóm, sau đó, để giảm thời gian tìm kiếm của bạn, chỉ tìm kiếm thông qua một tập hợp con của các nhóm này. Tuy nhiên, nếu thuật toán chỉ phân chia ngẫu nhiên các vectơ của bạn thành các nhóm khác nhau và chỉ tìm kiếm một tập hợp con trong số chúng, thì nó sẽ mang lại kết quả gần đúng kém. Thuật toán IVF sử dụng một cách tiếp cận tao nhã hơn. Đầu tiên, trước khi bắt đầu lập chỉ mục, nó gán cho mỗi nhóm một vectơ đại diện. Khi một vectơ được lập chỉ mục, nó sẽ được thêm vào nhóm có vectơ đại diện gần nhất. Bằng cách này, các vectơ gần nhau hơn được đặt đại khái trong cùng một nhóm hoặc gần đó.
Số liệu độ tương tự vectơ
Tất cả các công cụ tìm kiếm đều sử dụng số liệu tương tự để xếp hạng và sắp xếp kết quả và đưa các kết quả phù hợp nhất lên đầu. Khi bạn sử dụng truy vấn văn bản thuần túy, chỉ số tương tự được gọi là TF-IDF, đo lường tầm quan trọng của các thuật ngữ trong truy vấn và tạo điểm số dựa trên số lượng văn bản khớp. Khi truy vấn của bạn bao gồm một vectơ, thì các số liệu tương tự có bản chất là không gian, tận dụng lợi thế của khoảng cách gần trong không gian vectơ. OpenSearch hỗ trợ một số thước đo độ tương tự hoặc khoảng cách:
- Khoảng cách Euclide - Khoảng cách đường thẳng giữa các điểm.
- Khoảng cách L1 (Manhattan) – Tổng hiệu của tất cả các thành phần vectơ. Khoảng cách L1 đo bạn cần đi qua bao nhiêu khối thành phố trực giao từ điểm A đến điểm B.
- Khoảng cách L-vô cực (bàn cờ) – Số nước đi mà một quân Vua sẽ thực hiện trên bàn cờ n chiều. Nó khác với khoảng cách Euclide trên các đường chéo—một bước chéo trên bàn cờ 2 chiều cách 1.41 đơn vị Euclide, nhưng cách 2 L đơn vị vô cực.
- Sản phẩm bên trong – Tích độ lớn của hai vectơ và cosin của góc giữa chúng. Thường được sử dụng cho tính tương tự của vectơ xử lý ngôn ngữ tự nhiên (NLP).
- Tương tự cosine – Côsin của góc giữa hai vectơ trong một không gian vectơ.
- Khoảng cách hamming – Đối với vectơ được mã hóa nhị phân, số bit khác nhau giữa hai vectơ.
Lợi thế của OpenSearch dưới dạng cơ sở dữ liệu vectơ
Khi bạn sử dụng OpenSearch Service làm cơ sở dữ liệu vectơ, bạn có thể tận dụng các tính năng của dịch vụ như khả năng sử dụng, khả năng mở rộng, tính khả dụng, khả năng tương tác và bảo mật. Quan trọng hơn, bạn có thể sử dụng các tính năng tìm kiếm của OpenSearch để nâng cao trải nghiệm tìm kiếm. Ví dụ: bạn có thể sử dụng Học xếp hạng trong OpenSearch để tích hợp dữ liệu hành vi nhấp qua của người dùng vào ứng dụng tìm kiếm của bạn và cải thiện mức độ liên quan của tìm kiếm. Bạn cũng có thể kết hợp các khả năng tìm kiếm văn bản và tìm kiếm vectơ của OpenSearch để tìm kiếm các tài liệu có sự tương đồng về từ khóa và ngữ nghĩa. Bạn cũng có thể sử dụng các trường khác trong chỉ mục để lọc tài liệu nhằm cải thiện mức độ liên quan. Đối với người dùng nâng cao, bạn có thể sử dụng mô hình tính điểm kết hợp để kết hợp Điểm liên quan dựa trên văn bản của OpenSearch, được tính bằng hàm Okapi BM25 và điểm tìm kiếm vectơ của nó để cải thiện xếp hạng kết quả tìm kiếm của bạn.
Quy mô và giới hạn
OpenSearch dưới dạng cơ sở dữ liệu vectơ hỗ trợ hàng tỷ bản ghi vectơ. Hãy ghi nhớ máy tính sau đây về số lượng vectơ và kích thước để định kích thước cụm của bạn.
Số vectơ
OpenSearch VectorDB tận dụng khả năng phân mảnh của OpenSearch và có thể mở rộng thành hàng tỷ vectơ ở độ trễ một phần nghìn giây bằng cách phân đoạn vectơ và chia tỷ lệ theo chiều ngang bằng cách thêm nhiều nút hơn. Số lượng vectơ có thể vừa trong một máy đơn lẻ là một chức năng của bộ nhớ ngoài heap khả dụng trên máy. Số nút được yêu cầu sẽ phụ thuộc vào dung lượng bộ nhớ có thể được sử dụng cho thuật toán trên mỗi nút và tổng dung lượng bộ nhớ mà thuật toán yêu cầu. Càng nhiều nút, bộ nhớ càng nhiều và hiệu suất càng tốt. Dung lượng bộ nhớ khả dụng trên mỗi nút được tính là memory_available = (node_memory – jvm_size) * circuit_breaker_limit, với các thông số sau:
- nút_memory - Tổng bộ nhớ của phiên bản.
- jvm_size – Kích thước heap OpenSearch JVM. Giá trị này được đặt thành một nửa RAM của phiên bản, giới hạn ở mức xấp xỉ 32 GB.
- ngắt mạch_limit – Ngưỡng sử dụng bộ nhớ riêng cho bộ ngắt mạch. Điều này được đặt thành 0.5.
Ước tính tổng bộ nhớ cụm phụ thuộc vào tổng số bản ghi vectơ và thuật toán. HNSW và IVF có các yêu cầu về bộ nhớ khác nhau. bạn có thể tham khảo Ước tính bộ nhớ để biết thêm chi tiết.
Số thứ nguyên
Giới hạn kích thước hiện tại của OpenSearch cho trường vectơ knn_vector là 16,000 chiều. Mỗi thứ nguyên được biểu diễn dưới dạng float 32 bit. Càng nhiều kích thước, bạn càng cần nhiều bộ nhớ để lập chỉ mục và tìm kiếm. Số lượng thứ nguyên thường được xác định bởi các mô hình nhúng dịch thực thể thành một vectơ. Có rất nhiều tùy chọn để lựa chọn khi xây dựng knn_vector cánh đồng. Để xác định các phương pháp và thông số chính xác để chọn, hãy tham khảo Lựa chọn đúng phương pháp.
Câu chuyện của khách hàng:
Amazon Âm nhạc
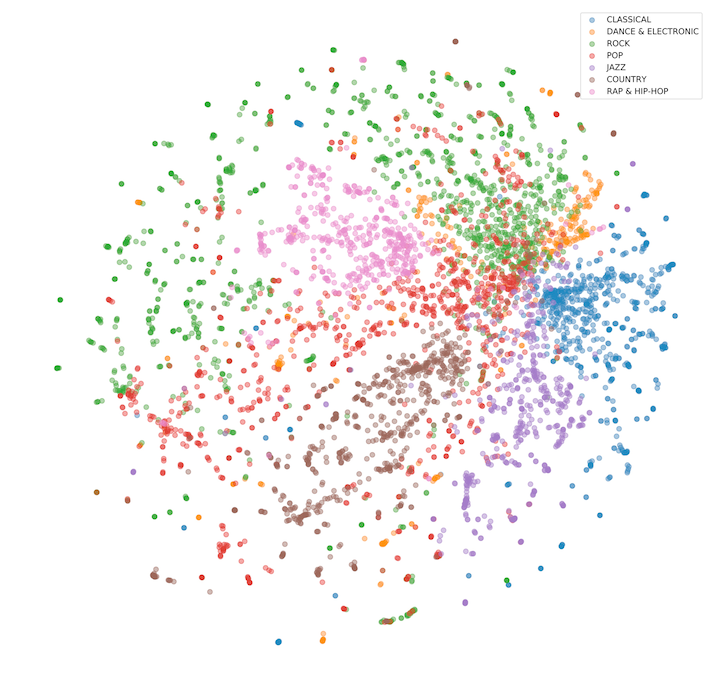
Amazon Music luôn đổi mới để cung cấp cho khách hàng những trải nghiệm độc đáo và được cá nhân hóa. Một trong những cách tiếp cận đề xuất âm nhạc của Amazon Music là bản phối lại của một cải tiến cổ điển của Amazon, lọc cộng tác từng mục, và cơ sở dữ liệu vector. Bằng cách sử dụng dữ liệu được tổng hợp dựa trên hành vi nghe của người dùng, Amazon Music đã tạo một mô hình nhúng giúp mã hóa các bản nhạc và phần trình bày của khách hàng vào một không gian vectơ trong đó các vectơ lân cận biểu thị các bản nhạc giống nhau. 100 triệu bài hát được mã hóa thành các vectơ, được lập chỉ mục trong OpenSearch và được phân phối trên nhiều khu vực địa lý để cung cấp các đề xuất theo thời gian thực. OpenSearch hiện đang quản lý 1.05 tỷ vectơ và hỗ trợ tải tối đa 7,100 truy vấn vectơ mỗi giây để hỗ trợ các đề xuất của Amazon Music.
Bộ lọc cộng tác giữa các mặt hàng tiếp tục là một trong những phương pháp phổ biến nhất để đề xuất sản phẩm trực tuyến vì tính hiệu quả của nó trong việc mở rộng quy mô cho các cơ sở khách hàng lớn và danh mục sản phẩm. OpenSearch giúp vận hành dễ dàng hơn và nâng cao khả năng mở rộng của trình giới thiệu bằng cách cung cấp cơ sở hạ tầng mở rộng quy mô và các chỉ mục k-NN phát triển tuyến tính đối với số lượng rãnh và tìm kiếm tương tự trong thời gian logarit.
Hình dưới đây trực quan hóa không gian nhiều chiều được tạo bởi phép nhúng vectơ.
Bảo vệ thương hiệu tại Amazon
Amazon cố gắng mang đến trải nghiệm mua sắm đáng tin cậy nhất thế giới, mang đến cho khách hàng nhiều lựa chọn nhất có thể về sản phẩm đích thực. Để giành được và duy trì lòng tin của khách hàng, chúng tôi nghiêm cấm việc bán các sản phẩm giả mạo và chúng tôi tiếp tục đầu tư vào những đổi mới để đảm bảo chỉ những sản phẩm chính hãng mới đến tay khách hàng của chúng tôi. Các chương trình bảo vệ thương hiệu của Amazon xây dựng niềm tin với các thương hiệu bằng cách đại diện chính xác và bảo vệ hoàn toàn thương hiệu của họ. Chúng tôi cố gắng đảm bảo rằng nhận thức của công chúng phản ánh trải nghiệm đáng tin cậy mà chúng tôi mang lại. Chiến lược bảo vệ thương hiệu của chúng tôi tập trung vào bốn trụ cột: (1) Chủ động kiểm soát (2) Công cụ mạnh mẽ để bảo vệ thương hiệu (3) Buộc những kẻ xấu phải chịu trách nhiệm (4) Bảo vệ và giáo dục khách hàng. Amazon OpenSearch Service là một phần quan trọng trong Kiểm soát chủ động của Amazon.
Vào năm 2022, công nghệ tự động của Amazon đã quét hơn 8 tỷ nỗ lực thay đổi hàng ngày đối với các trang chi tiết sản phẩm để tìm dấu hiệu lạm dụng tiềm ẩn. Các biện pháp kiểm soát chủ động của chúng tôi đã tìm thấy hơn 99% danh sách bị chặn hoặc bị xóa trước khi một thương hiệu phải tìm và báo cáo. Những danh sách này bị nghi ngờ là gian lận, vi phạm, giả mạo hoặc có nguy cơ bị lạm dụng dưới các hình thức khác. Để thực hiện những lần quét này, Amazon đã tạo ra công cụ sử dụng các kỹ thuật tiên tiến và sáng tạo, bao gồm cả việc sử dụng các mô hình máy học tiên tiến để tự động phát hiện các hành vi vi phạm quyền sở hữu trí tuệ trong danh sách trên khắp các cửa hàng của Amazon trên toàn cầu. Một thách thức kỹ thuật quan trọng trong việc triển khai hệ thống tự động như vậy là khả năng tìm kiếm tài sản trí tuệ được bảo vệ trong kho văn bản hàng tỷ vectơ một cách nhanh chóng, có thể mở rộng và tiết kiệm chi phí. Tận dụng khả năng cơ sở dữ liệu vectơ có thể thay đổi quy mô của Dịch vụ Amazon OpenSearch và kiến trúc phân tán, chúng tôi đã phát triển thành công một quy trình nhập đã lập chỉ mục tổng cộng 68 tỷ vectơ, 128 và 1024 chiều vào Dịch vụ OpenSearch để cho phép các thương hiệu và hệ thống tự động tiến hành phát hiện vi phạm, trong thực tế -time, thông qua API tìm kiếm (dưới giây) có sẵn cao và nhanh chóng.
Kết luận
Cho dù bạn đang xây dựng một giải pháp AI tổng quát, tìm kiếm đa phương tiện và âm thanh hay mang lại nhiều tìm kiếm ngữ nghĩa hơn cho ứng dụng dựa trên tìm kiếm hiện tại của mình, OpenSearch là một cơ sở dữ liệu vectơ có khả năng. OpenSearch hỗ trợ nhiều công cụ, thuật toán và thước đo khoảng cách mà bạn có thể sử dụng để xây dựng giải pháp phù hợp. OpenSearch cung cấp một công cụ có khả năng mở rộng có thể hỗ trợ tìm kiếm vectơ ở độ trễ thấp và lên tới hàng tỷ vectơ. Với OpenSearch và khả năng DB vector của nó, người dùng của bạn có thể dễ dàng tìm thấy chiếc ghế dài 8 foot màu xanh đó và thư giãn bên ngọn lửa ấm cúng.
Về các tác giả
 Jon xử lý là Kiến trúc sư giải pháp chính cấp cao tại Amazon Web Services có trụ sở tại Palo Alto, CA. Jon hợp tác chặt chẽ với OpenSearch và Amazon OpenSearch Service, cung cấp trợ giúp và hướng dẫn cho nhiều khách hàng có khối lượng công việc phân tích nhật ký và tìm kiếm muốn chuyển sang Đám mây AWS. Trước khi gia nhập AWS, sự nghiệp phát triển phần mềm của Jon bao gồm XNUMX năm viết mã cho công cụ tìm kiếm Thương mại điện tử quy mô lớn. Jon có bằng Cử nhân Nghệ thuật của Đại học Pennsylvania, bằng Thạc sĩ Khoa học và bằng Tiến sĩ về Khoa học Máy tính và Trí tuệ Nhân tạo của Đại học Northwestern.
Jon xử lý là Kiến trúc sư giải pháp chính cấp cao tại Amazon Web Services có trụ sở tại Palo Alto, CA. Jon hợp tác chặt chẽ với OpenSearch và Amazon OpenSearch Service, cung cấp trợ giúp và hướng dẫn cho nhiều khách hàng có khối lượng công việc phân tích nhật ký và tìm kiếm muốn chuyển sang Đám mây AWS. Trước khi gia nhập AWS, sự nghiệp phát triển phần mềm của Jon bao gồm XNUMX năm viết mã cho công cụ tìm kiếm Thương mại điện tử quy mô lớn. Jon có bằng Cử nhân Nghệ thuật của Đại học Pennsylvania, bằng Thạc sĩ Khoa học và bằng Tiến sĩ về Khoa học Máy tính và Trí tuệ Nhân tạo của Đại học Northwestern.
 Kiến Vệ Lý là Chuyên gia phân tích chính TAM tại Amazon Web Services. Jianwei cung cấp dịch vụ tư vấn cho khách hàng để giúp khách hàng thiết kế và xây dựng nền tảng dữ liệu hiện đại. Jianwei đã làm việc trong lĩnh vực dữ liệu lớn với tư cách là nhà phát triển phần mềm, nhà tư vấn và lãnh đạo công nghệ.
Kiến Vệ Lý là Chuyên gia phân tích chính TAM tại Amazon Web Services. Jianwei cung cấp dịch vụ tư vấn cho khách hàng để giúp khách hàng thiết kế và xây dựng nền tảng dữ liệu hiện đại. Jianwei đã làm việc trong lĩnh vực dữ liệu lớn với tư cách là nhà phát triển phần mềm, nhà tư vấn và lãnh đạo công nghệ.
 Dylan Tống là Giám đốc sản phẩm cấp cao tại AWS. Anh ấy làm việc với khách hàng để giúp thúc đẩy thành công của họ trên nền tảng AWS thông qua khả năng lãnh đạo tư duy và hướng dẫn thiết kế các giải pháp có kiến trúc tốt. Anh ấy đã dành phần lớn sự nghiệp của mình để xây dựng kiến thức chuyên môn về quản lý và phân tích dữ liệu bằng cách làm việc cho các nhà lãnh đạo và nhà đổi mới trong lĩnh vực này.
Dylan Tống là Giám đốc sản phẩm cấp cao tại AWS. Anh ấy làm việc với khách hàng để giúp thúc đẩy thành công của họ trên nền tảng AWS thông qua khả năng lãnh đạo tư duy và hướng dẫn thiết kế các giải pháp có kiến trúc tốt. Anh ấy đã dành phần lớn sự nghiệp của mình để xây dựng kiến thức chuyên môn về quản lý và phân tích dữ liệu bằng cách làm việc cho các nhà lãnh đạo và nhà đổi mới trong lĩnh vực này.
 Vamshi Vijay Nakkirtha là Giám đốc Kỹ thuật Phần mềm làm việc trong Dự án Tìm kiếm Mở và Dịch vụ Tìm kiếm Mở của Amazon. Mối quan tâm chính của anh ấy bao gồm các hệ thống phân tán. Anh ấy là người đóng góp tích cực cho nhiều plugin khác nhau, như k-NN, GeoSpatial và bảng điều khiển-bản đồ.
Vamshi Vijay Nakkirtha là Giám đốc Kỹ thuật Phần mềm làm việc trong Dự án Tìm kiếm Mở và Dịch vụ Tìm kiếm Mở của Amazon. Mối quan tâm chính của anh ấy bao gồm các hệ thống phân tán. Anh ấy là người đóng góp tích cực cho nhiều plugin khác nhau, như k-NN, GeoSpatial và bảng điều khiển-bản đồ.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- EVM tài chính. Giao diện hợp nhất cho tài chính phi tập trung. Truy cập Tại đây.
- Tập đoàn truyền thông lượng tử. Khuếch đại IR/PR. Truy cập Tại đây.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/amazon-opensearch-services-vector-database-capabilities-explained/

