Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.

Giới thiệu
Đây là một dự án phân loại nhiều lớp để phân loại mức độ nghiêm trọng của tai nạn đường bộ thành ba loại. Dự án này dựa trên dữ liệu trong thế giới thực và bộ dữ liệu cũng rất mất cân bằng. Có ba loại thương tích trong một biến mục tiêu: nhẹ, nghiêm trọng và tử vong.
Tai nạn giao thông là nguyên nhân chính gây ra những cái chết bất thường trên khắp thế giới. Tất cả các chính phủ đều nỗ lực nâng cao nhận thức về các quy định và quy định phải tuân thủ khi điều khiển phương tiện trên đường nhằm giảm thiểu số ca tử vong. Vì vậy, cần phải có cơ chế dự đoán mức độ nghiêm trọng của những vụ tai nạn như vậy và giúp giảm thiểu tử vong.
Trong bài viết này, chúng tôi sẽ làm việc với dự án đầu cuối mà chúng tôi đã phát triển một giải pháp học máy để dự đoán mức độ nghiêm trọng của các vụ tai nạn đường bộ nhằm thực hiện các biện pháp phòng ngừa cần thiết của cơ quan điều tra. Vì vậy, hãy bắt đầu với mô tả dự án và tuyên bố vấn đề.
Hiểu giải pháp học máy
Bộ dữ liệu này được thu thập từ Tiểu thành phố Addis Ababa, Ethiopia, các sở cảnh sát cho công việc nghiên cứu của học viên cao học. Bộ dữ liệu được chuẩn bị từ các tài liệu thủ công về tai nạn giao thông đường bộ trong các năm 2017–20. Tất cả thông tin nhạy cảm đã bị loại trừ trong quá trình mã hóa dữ liệu và cuối cùng, nó có 32 tính năng và 12316 hàng ngẫu nhiên. Sau đó, nó được xử lý trước để xác định các nguyên nhân chính gây ra tai nạn bằng cách phân tích nó bằng các thuật toán phân loại khác nhau. Các mô hình học máy sẽ được đánh giá và sau đó được triển khai trên nền tảng dựa trên đám mây để người dùng cuối có thể sử dụng chúng.
Báo cáo vấn đề
Tính năng mục tiêu là “Accident_severity”, là một biến số nhiều lớp. Nhiệm vụ là phân loại biến này dựa trên 31 tính năng khác theo từng bước bằng cách thực hiện từng quy trình và nhiệm vụ khoa học dữ liệu. Số liệu của chúng tôi để đánh giá sẽ là “điểm F1” của bạn.
Điều kiện tiên quyết
Đây là một dự án trung cấp với một vấn đề phân loại đa lớp không cân bằng. một số điều kiện tiên quyết cho dự án này.
- Cần có hiểu biết về các thuật toán học máy phân loại.
- Cần có kiến thức về ngôn ngữ lập trình Python và các framework python như Pandas, NumPy, Matplotlib và Scikit-Learn, cũng như kiến thức cơ bản về thư viện streamlit.
Mô tả tập dữ liệu
- Thời gian — thời điểm xảy ra tai nạn (Ở định dạng 24 giờ)
- Day_of_week — Ngày xảy ra tai nạn
- Age_band_of_driver —Nhóm tuổi của người lái xe
- Sex_of_driver — Giới tính của tài xế
- Educational_level — Trình độ học vấn cao nhất của người lái xe
- Vehical_driver_relation — Mối quan hệ của người lái xe với phương tiện là gì
- Driving_experience — Người lái xe có bao nhiêu năm kinh nghiệm lái xe
- Type_of_vehicle — Loại phương tiện là gì
- Owner_of_vehicle — Ai là chủ sở hữu của phương tiện
- Service_year_of_vehicle — Năm dịch vụ cuối cùng của phương tiện
- Defect_of_vehicle — Có lỗi nào trên xe hay không?
- Area_accident_occured — Địa điểm xảy ra tai nạn
- Lanes_or_Medians — Có làn đường hoặc dải phân cách nào tại địa điểm xảy ra tai nạn không?
- Road_allignment — Căn đường với địa hình khu đất
- Type_of_junction — Loại đường giao nhau tại nơi xảy ra tai nạn
- Road_surface_type — Loại bề mặt của đường
- Road_surface_conditions — Tình trạng của mặt đường là gì?
- Light_conditions — Điều kiện ánh sáng tại hiện trường
- Weather_conditions — Tình hình thời tiết tại nơi xảy ra tai nạn
- Type_of_collision — Loại va chạm là gì
- Number_of_vehicles_involved — Tổng số phương tiện liên quan đến một vụ tai nạn
- Number_of_casualties — Tổng số thương vong trong một vụ tai nạn
- Vehicle_movement — Cách phương tiện di chuyển trước khi tai nạn xảy ra
- Casualty_class — Một người bị giết trong một vụ tai nạn
- Sex_of_casualty — Giới tính của người bị giết
- Age_band_of_casualty — Nhóm tuổi của nạn nhân
- Casualty_severtiy — Nạn nhân bị thương nặng đến mức nào
- Work_of_casualty — Công việc của nạn nhân là gì
- Fitness_of_casualty — Mức độ khỏe mạnh của nạn nhân
- Pedestrain_movement — Có bất kỳ chuyển động nào của người đi bộ trên đường không?
- Nguyên nhân của tai nạn — Nguyên nhân của tai nạn là gì?
- Accident_severity — Tai nạn nghiêm trọng đến mức nào? (Biến mục tiêu)
Cho đến nay, chúng tôi đã hiểu được tuyên bố vấn đề và mô tả dữ liệu. Bây giờ chúng ta sẽ xem xét việc triển khai mã từ đầu đến cuối để giải quyết các vấn đề về phân tích dự đoán và triển khai các giải pháp máy học trên đám mây được chiếu sáng.
Phân tích bộ dữ liệu trong giải pháp học máy
Bây giờ chúng ta đã xem xét tuyên bố vấn đề và mô tả dữ liệu, chúng ta sẽ bắt đầu tải tập dữ liệu vào môi trường phát triển của mình và bắt đầu phân tích dữ liệu để tìm ra những hiểu biết quan trọng cho các giai đoạn chuẩn bị và lập mô hình dữ liệu.
Nguồn của tập dữ liệu — Bấm vào đây
Liên kết tập dữ liệu Kaggle — Bấm vào đây
- Nhập tập dữ liệu
Tôi đã sử dụng môi trường Kaggle để thực hiện dự án này. Bạn có thể sử dụng tập dữ liệu này trong môi trường cục bộ của mình hoặc bất kỳ IDE dựa trên đám mây ưa thích nào để hoàn thành công việc trong dự án này bằng cách làm theo mã từng bước.
# nhập gấu trúc nhập gấu trúc dưới dạng pd # sử dụng hàm pandas read_csv để tải tập dữ liệu df = pd.read_csv("/kaggle/input/road-traffic-severity-classification/RTA Dataset.csv") df.head()
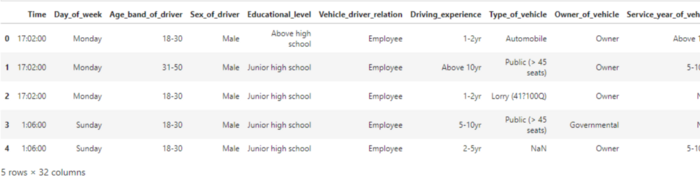
Lưu ý: Do tập dữ liệu lớn, đầu ra của đoạn mã trên không hiển thị đầy đủ trong ảnh chụp màn hình.
2. Siêu dữ liệu của tập dữ liệu
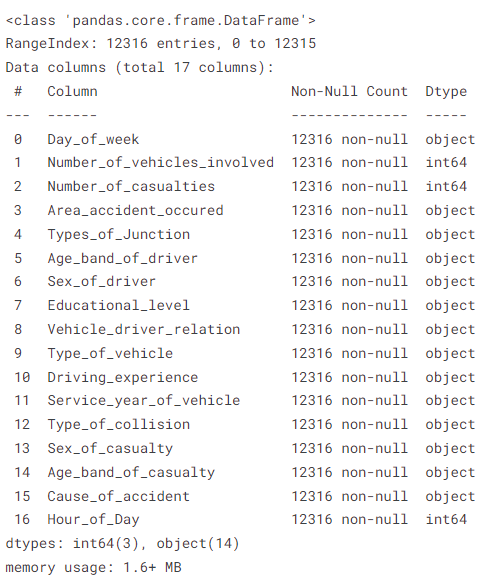
# in thông tin tập dữ liệu df.info()
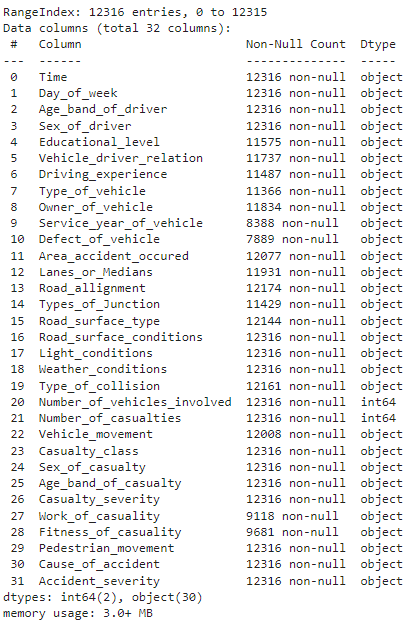
Phương pháp trên hiển thị thông tin siêu dữ liệu chẳng hạn như giá trị khác null, kiểu dữ liệu của từng cột, số hàng và cột có trong tập dữ liệu và mức sử dụng bộ nhớ của tập dữ liệu.
3. Tìm số giá trị còn thiếu trong mỗi cột
# Tìm số giá trị bị thiếu có trong mỗi cột df.isnull().sum()
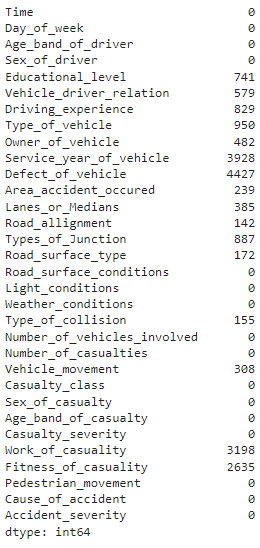
đầu ra của mã trên
Phương pháp này cho chúng ta biết có bao nhiêu giá trị bị thiếu trong mỗi cột. “Defect_of_Vehicle” hiển thị số lượng giá trị bị thiếu cao nhất, là 4427 trong số 12316 trường hợp.
4. Phân phối và trực quan hóa các lớp biến mục tiêu
# lớp biến mục tiêu đếm và in biểu đồ thanh(df['Accident_severity'].value_counts()) df['Accident_severity'].value_counts().plot(kind='bar')

đầu ra của mã trên
Như chúng ta đã thấy trước đó trong tuyên bố vấn đề, các lớp biến mục tiêu rất mất cân bằng và chúng ta sẽ giải quyết vấn đề này trong giai đoạn chuẩn bị dữ liệu để phát triển các mô hình học máy tổng quát và chính xác.
5. Phân tích dữ liệu khám phá của bộ dữ liệu
Cùng tìm hiểu trình độ học vấn của các tài xế
# Trình độ học vấn của tài xế ô tô df['Educational_level'].value_counts().plot(kind='bar')
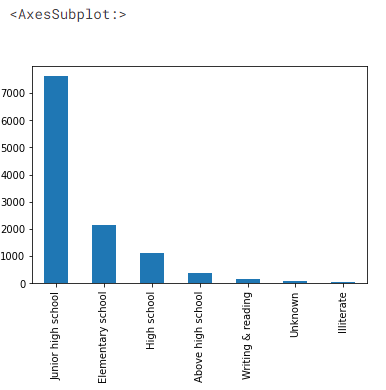
đầu ra của tập dữ liệu
Chúng ta có thể thấy hơn 7000 tài xế có trình độ học vấn đến trung học cơ sở và chỉ một phần nhỏ tài xế có trình độ học vấn trên trung học phổ thông.
- Tự động hiển thị dữ liệu bằng thư viện 'dabl'
# Trực quan hóa tập dữ liệu bằng thư viện dabl pip install dabl
nhập khẩu dabl
dabl.plot(df, target_col='Accident_severity')

đầu ra của mã trên
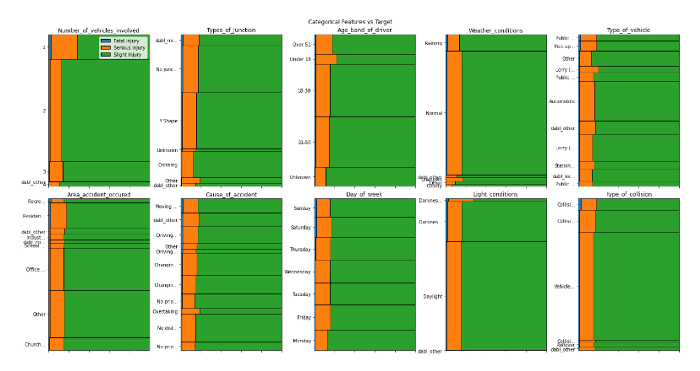
đầu ra của mã trên
Chỉ sử dụng một dòng mã, chúng ta có thể hình dung mối quan hệ giữa các tính năng đầu vào và một biến mục tiêu. Từ phân tích của chúng tôi cho đến nay, chúng tôi có thể rút ra những hiểu biết sau:
- Số thương vong càng nhiều, khả năng tử vong tại nơi xảy ra tai nạn càng cao
- Càng nhiều phương tiện liên quan thì khả năng bị thương nặng càng cao
- Light_conditions là bóng tối có thể gây thương tích nghiêm trọng cao hơn
- Dữ liệu mất cân bằng cao
- Các tính năng như
area_accident_occured,Cause_of_accident,Day_of_week,type_of_junctiondường như là các tính năng thiết yếu gây thương tích chết người - Road_surface và điều kiện đường xá dường như không ảnh hưởng đến các vụ tai nạn nghiêm trọng hoặc gây tử vong
(Lưu ý: Tôi sẽ đính kèm một liên kết kho github của dự án này ở cuối bài viết này, để bạn có thể tìm thấy thông tin chi tiết về mã)
- Liên kết giữa cột 'loại mặt đường' và mục tiêu 'mức độ nghiêm trọng của tai nạn'
# vẽ sơ đồ thanh của road_surface_type và đặc điểm mức độ nghiêm trọng của tai nạn plt.figure(figsize=(6,5)) sns.countplot(x='Road_surface_type', hue='Accident_severity', data=df) plt.xlabel('Rode surafce gõ') plt.xticks(xoay vòng=60) plt.show
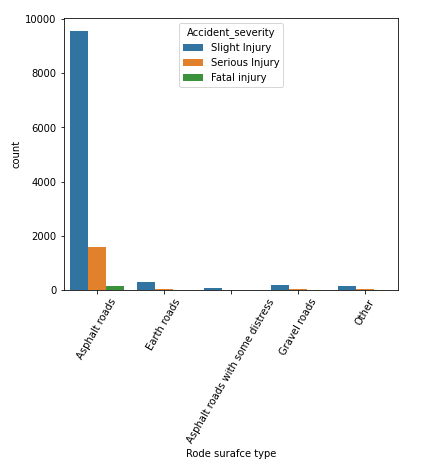
đầu ra của mã trên
Chúng ta có thể biết rằng hầu hết các vụ tai nạn xảy ra trên “đường nhựa” trong bộ dữ liệu của chúng tôi, tiếp theo là “đường đất”. Ở đây chúng ta có thể nói rằng hầu hết các thương tích gây tử vong xảy ra trên đường trải nhựa, vì vậy chúng có thể không phải là một biến số quan trọng để dự đoán nhóm mục tiêu.
Bây giờ, dựa trên những phát hiện trên, chúng tôi sẽ xử lý trước dữ liệu thô cho mục đích lập mô hình và đánh giá.
Chuẩn bị dữ liệu
Chúng tôi sẽ bắt đầu xử lý trước tập dữ liệu bằng cách thay đổi kiểu dữ liệu cột “Thời gian” thành kiểu dữ liệu “ngày giờ”. Sau đó, chúng tôi sẽ trích xuất tính năng giờ trong ngày để chuẩn bị dữ liệu cho việc lập mô hình.
# chuyển đổi cột loại đối tượng thành cột kiểu dữ liệu ngày giờ df['Time'] = pd.to_datetime(df['Time']) # Trích xuất tính năng 'Giờ_của_Ngày' từ cột Thời gian new_df = df.copy() new_df['Hour_of_Day'] = new_df['Time'].dt.hour n_df = new_df.drop('Time', axis=1) n_df.head()
đầu ra của mã trên
Thiếu giá trị điều trị
Vào thời điểm này, chúng tôi sẽ có một tập hợp con các tính năng được chọn để xử lý thêm dựa trên thông tin chi tiết thu được từ giai đoạn trước. Chúng tôi sẽ chọn một tập hợp con các tính năng và sau đó xử lý các giá trị còn thiếu bằng cách sử dụng phương thức “fillna()” của thư viện Pandas.
Trong bối cảnh của chúng tôi, chúng tôi sẽ xử lý các giá trị bị thiếu bằng cách điền "không xác định" làm giá trị, giả sử rằng các giá trị bị thiếu có thể không được tìm thấy trong quá trình điều tra.
# NaN bị thiếu vì có thể không có thông tin dịch vụ, chúng tôi sẽ điền là 'Không xác định' '].fillna('Không xác định') Feature_df['Khu vực_tai nạn_đã xảy ra'] = Feature_df['Khu vực_tai nạn_đã xảy ra'].fillna('Không xác định') Feature_df['Trải nghiệm_lái xe'] = Feature_df['Trải nghiệm_lái xe'].fillna('Không xác định') Feature_df ['Type_of_vehicle'] = Feature_df['Type_of_vehicle'].fillna('Khác') Feature_df['Vehicle_driver_relation'] = Feature_df['Vehicle_driver_relation'].fillna('Không xác định') Feature_df['Educational_level'] = Feature_df['Educational_level '].fillna('Unknown') feature_df['Type_of_collision'] = feature_df['Type_of_collision'].fillna('Unknown') # thông tin về tính năng feature_df.info()
đầu ra của khung dữ liệu
Như chúng ta có thể thấy, bộ tính năng của chúng ta hiện không có giá trị null so với tập dữ liệu thô trước đó. Bây giờ hãy chuyển sang các bước tiền xử lý dữ liệu khác.
Mã hóa One-Hot sử dụng phương thức 'get_dummies()'
Pandas' 'get_dummies()' có thể được sử dụng để chuyển đổi các cột phân loại thành các đối tượng số. hãy xem đoạn mã dưới đây:
# Các tính năng phân loại để mã hóa bằng một tính năng mã hóa hấp dẫn = ['Day_of_week','Number_of_vehicles_involved','Number_of_casualties','Khu vực_tai nạn_xảy ra', 'Type_of_Junction','Tuổi_band_of_driver','Sex_of_driver','Educational_level', 'Vehicle_driver_relation','Type_of_vehicle ','Trải_nghiệm_lái_xe','Dịch_vụ_năm_của_phương_tiện','Loại_va chạm', 'Giới tính_của_sự_thường','Độ_tuổi_của_sự_thường','Nguyên nhân_của_tai nạn','Giờ_của_ngày'] # cài đặt tính năng đầu vào X và mục tiêu y X = tính năng_df[tính năng] # ở đây các tính năng được chọn từ kiểu dữ liệu 'đối tượng' y = n_df['Accident_severity'] # chúng tôi sẽ sử dụng phương pháp pandas get_dummies để mã hóa nóng encoded_df = pd.get_dummies(X, drop_first=True) encoded_df.shape ----------- ------------------------[Đầu ra]----------------------- ------------ (12316, 106)
Do mã hóa, chúng tôi hiện có 106 cột trong khung dữ liệu được mã hóa, chúng tôi sẽ tiếp tục xử lý trước để chỉ giữ lại các tính năng quan trọng cho mục đích lập mô hình.
Mã hóa mục tiêu bằng phương thức 'LabelEncoder()'
# nhập bộ mã hóa nhãn từ sklearn.preprocessing từ sklearn.preprocessing nhập LabelEncoder # tạo đối tượng bộ mã hóa nhãn lb = LabelEncoder() lb.fit(y) y_encoded = lb.transform(y) print("Nhãn được mã hóa:",lb.classes_) y_en = pd.Series(y_encoded) ------------------------------------[Đầu ra]------ ---------------------------- Nhãn được mã hóa: ['Chấn thương chết người' 'Chấn thương nghiêm trọng' 'Chấn thương nhẹ']
Bây giờ, chúng tôi có “encoded_df” làm đối tượng khung dữ liệu được mã hóa và “y_en” làm cột mục tiêu được mã hóa để chọn thêm các tính năng “Kbest” và xử lý tập dữ liệu không cân bằng.
Lựa chọn tính năng bằng Thống kê 'Chi2'
# phương pháp chọn tính năng sử dụng chi2 cho đầu ra phân loại, đầu vào phân loại từ sklearn.feature_selection import SelectKBest, chi2 fs = SelectKBest(chi2, k=50) X_new = fs.fit_transform(encoded_df, y_en) # Lấy các tính năng đã chọn cols = fs.get_feature_names_out () # chuyển đổi các tính năng đã chọn thành khung dữ liệu fs_df = pd.DataFrame(X_new, cột=cols)
Chúng tôi đang chọn 50 tính năng hàng đầu trong số 106 tính năng từ khung dữ liệu được mã hóa và lưu trữ chúng trong một đối tượng khung dữ liệu mới có tên là “fs_df”. Thống kê “Chi2” được sử dụng khi đối tượng địa lý đích là một biến phân loại và “hệ số Pearson” được sử dụng khi đối tượng địa lý đích là một biến liên tục. Bây giờ, hãy lấy mẫu dữ liệu để cân bằng các tính năng phân loại.
Xử lý dữ liệu mất cân bằng bằng kỹ thuật 'SMOTENC'
Thư viện scikit-learning có một thư viện mở rộng gọi là “Học không cân bằng,” trong đó có nhiều phương pháp khác nhau để xử lý dữ liệu mất cân bằng. (Tài liệu chính thức — Bấm vào đây).
Để upsample và các mẫu lớp thiểu số, chúng tôi sẽ sử dụng “Kỹ thuật lấy mẫu quá mức thiểu số tổng hợp cho danh nghĩa và liên tục” (SMOTENC) trong dự án của chúng tôi. Phương pháp này được thiết kế cho các tính năng phân loại và liên tục để lấy mẫu chính xác tập dữ liệu.
# nhập đối tượng SMOTENC từ thư viện imblearn từ imblearn.over_sampling import SMOTENC # các tính năng phân loại cho kỹ thuật SMOTENC cho các tính năng phân loại n_cat_index = np.array(range(3,50)) # tạo đối tượng smote với lớp SMOTENC smote = SMOTENC(categorical_features=n_cat_index , random_state=42, n_jobs=True) X_n, y_n = smote.fit_resample(fs_df,y_en) # in hình dạng của tập dữ liệu được lấy mẫu mới X_n.shape, y_n.shape -------------- --------------------- [Đầu ra] -------------------------- -------- ((31245, 50), (31245,)) # in phân bố của các lớp mục tiêu print(y_n.value_counts()) ---------------- -------------------- [Đầu ra] -------------------------- ------ 2 10415 1 10415 0 10415 dtype: int64
Như bạn có thể thấy bây giờ, chúng tôi có một tập dữ liệu mới được lấy mẫu với tổng số 31245 mẫu. Mỗi lớp mục tiêu của chúng tôi có 10415 các mẫu và tập dữ liệu hiện được cân bằng cho các nhiệm vụ lập mô hình.
Mô hình học máy
Bây giờ, hãy phát triển mô hình học máy phân loại bằng thuật toán học máy rừng ngẫu nhiên. Chúng tôi sẽ nhập các lớp khác nhau của thư viện Scikit-Learn để phát triển mô hình ML và đánh giá nó trong bước tiếp theo.
# nhập thư viện cần thiết từ sklearn.model_selection nhập train_test_split từ sklearn.ensemble nhập RandomForestClassifier từ sklearn.metrics nhập nhầm lẫn_matrix, phân loại_report, f1_score # đào tạo và thử nghiệm phân chia và xây dựng mô hình cơ sở để dự đoán các tính năng mục tiêu X_trn, X_tst, y_trn, y_tst = train_test_split( X_n, y_n, test_size=0.2, random_state=42) # lập mô hình sử dụng đường cơ sở của rừng ngẫu nhiên rf = RandomForestClassifier(n_estimators=800, max_depth=20, random_state=42) rf.fit(X_trn, y_trn) # dự đoán dựa trên dự đoán dữ liệu thử nghiệm = rf .predict(X_tst) # điểm huấn luyện rf.score(X_trn, y_trn) ---------------------------------- -[Đầu ra]---------------------------------- 0.9416306609057449
Bây giờ, chúng tôi đã phát triển một mô hình rừng ngẫu nhiên với n_estimators = 800 và max_depth = 20. Chúng tôi sẽ đánh giá mô hình này trên dữ liệu thử nghiệm để xác thực kết quả và đưa ra dự đoán dựa trên dữ liệu đầu vào mới.
Hãy in báo cáo phân loại trên tập dữ liệu thử nghiệm.
# báo cáo phân loại về tập dữ liệu thử nghiệm classif_re = classif_report(y_tst,predics) print(classif_re) -------------------------------- ---[Đầu ra]---------------------------------- thu hồi chính xác hỗ trợ điểm f1 0 0.94 0.96 0.95 2085 1 0.84 0.83 0.84 2100 2 0.86 0.87 0.86 2064 Độ chính xác 0.88 6249 Macro AVG 0.88 0.88 0.88 6249 AVG 0.88 0.88 0.88 6249 # F1_Score -------------------------- [Đầu ra] ---------- --------------------- 1
Chúng ta có thể thấy rằng mô hình lưu trữ độ chính xác 88% trên dữ liệu thử nghiệm so với 94% trên tập dữ liệu huấn luyện. Mô hình của chúng tôi dường như hoạt động tốt trên tập dữ liệu thử nghiệm và chúng tôi rất sẵn lòng triển khai mô hình trên đám mây được chiếu sáng để giúp người dùng cuối có thể truy cập mô hình.
Triển khai Bộ dữ liệu bằng Streamlit
Bây giờ chúng ta đã phân tích dữ liệu và xây dựng một mô hình máy học với 88% f1_score trên tập dữ liệu thử nghiệm, chúng ta sẽ tiếp tục với quy trình ML để phát triển giao diện web bằng thư viện streamlit. Tạo các ứng dụng web hỗ trợ máy học bằng Streamlit cực kỳ dễ dàng vì bạn không cần phải biết bất kỳ công nghệ ngoại vi nào. Hơn nữa, Streamlit cung cấp triển khai đám mây miễn phí với các tên miền phụ tùy chỉnh, khiến nó trở thành một tùy chọn thích hợp hơn để triển khai các ứng dụng hỗ trợ ML.
Hãy bắt đầu với việc lưu đối tượng mô hình và chọn các tính năng đầu vào. Chúng tôi đã chọn 10 tính năng để xây dựng ứng dụng web để suy ra mô hình máy học từ ứng dụng web. Ngoài ra, chúng tôi cũng sẽ lưu đối tượng bộ mã hóa thứ tự để chuyển đổi đầu vào phân loại thành mã hóa tương ứng của chúng.
# chọn 7 tính năng phân loại từ khung dữ liệu nhập joblib từ sklearn.preprocessing nhập OrdinalEncoder new_fea_df = feature_df[['Type_of_collision','Age_band_of_driver','Sex_of_driver', 'Educational_level','Service_year_of_vehicle','Day_of_week','Area_accident_occured']] oencoder2 = OrdinalEncoder() encoded_df3 = pd.DataFrame(oencoder2.fit_transform(new_fea_df)) encoded_df3.columns = new_fea_df.columns # lưu đối tượng bộ mã hóa thứ tự cho đường dẫn suy luận joblib.dump(oencoder, "ordinal_encoder2.joblib")
Bây giờ, chúng tôi sẽ kết hợp bảy tính năng phân loại với ba tính năng số để đào tạo mô hình cuối cùng để suy luận.
# khung dữ liệu cuối cùng sẽ được đào tạo để suy luận mô hình s_final_df = pd.concat([feature_df[['Number_of_vehicles_involved','Number_of_casualties','Hour_of_Day']],encoded_df3], axis=1) # đào tạo và thử nghiệm phân tách và xây dựng mô hình cơ sở để dự đoán các tính năng đích X_trn2, X_tst2, y_trn2, y_tst2 = train_test_split(s_final_df, y_en, test_size=0.2, random_state=42) # lập mô hình sử dụng đường cơ sở rừng ngẫu nhiên rf = RandomForestClassifier(n_estimators=700, max_depth=20, random_state=42) rf.fit (X_trn2, y_trn2) # lưu đối tượng mô hình joblib.dump(rf, "rta_model_deploy3.joblib", nén=9)
Chúng tôi sẽ tải bốn tệp bên dưới vào kho lưu trữ dự án của chúng tôi:
- Yêu cầu.txt
- ứng dụng
- ordinal_encoding2.joblib
- rta_model_deploy3.joblib
Tải tất cả các phụ thuộc trong tests.txt
pandas numpy streamlit scikit-learning joblib shap matplotlib ipython Gối
Tạo một tệp app.py và viết một quy trình suy luận với giao diện người dùng dựa trên biểu mẫu để lấy thông tin đầu vào từ người dùng cuối để dự đoán mức độ nghiêm trọng của các vụ tai nạn trên đường.
# nhập tất cả các phần phụ thuộc của ứng dụng nhập gấu trúc dưới dạng pd nhập numpy dưới dạng np nhập sklearn nhập streamlit dưới dạng st nhập joblib nhập shap nhập matplotlib từ IPython nhập get_ipython từ PIL nhập Hình ảnh # tải bộ mã hóa và đối tượng mô hình model = joblib.load("rta_model_deploy3. joblib") encoder = joblib.load("ordinal_encoder2.joblib") st.set_option('deprecation.showPyplotGlobalUse', False) # 1: thương tích nghiêm trọng, 2: Thương tích nhẹ, 0: Thương tích nghiêm trọng st.set_page_config(page_title="Tai nạn Ứng dụng dự đoán mức độ nghiêm trọng", page_icon="🚧", layout="wide") #tạo danh sách tùy chọn cho menu thả xuống options_day = ['Chủ nhật', "Thứ hai", "Thứ ba", "Thứ tư", "Thứ năm", "Thứ sáu" , "Saturday"] options_age = ['18-30', '31-50', 'Over 51', 'Unknown', 'Dưới 18'] # số phương tiện tham gia: phạm vi từ 1 đến 7 # số thương vong: phạm vi từ 1 đến 8 # giờ trong ngày: phạm vi từ 0 đến 23 options_types_collision = ['Xe va chạm với phương tiện','Va chạm với vật thể bên đường', 'Va chạm với người đi bộ','Lăn over','Va chạm với động vật', 'Không xác định','Va chạm với phương tiện đỗ bên đường','Ngã từ phương tiện', 'Khác','Với tàu hỏa'] options_sex = ['Nam','Nữ','Không xác định '] options_education_level = ['Trung học cơ sở','Tiểu học','Trung học phổ thông', 'Không biết','Trên trung học phổ thông','Viết và đọc','Mù chữ'] options_services_year = ['Không biết','2 -5yrs','Trên 10 năm','5-10 năm','1-2 năm','Dưới 1 năm'] options_acc_area = ['Khác', 'Khu văn phòng', 'Khu dân cư', ' Khu nhà thờ', ' Khu công nghiệp khu vực', 'Khu vực trường học', ' Khu vực giải trí', ' Khu vực ngoại thành', ' Khu vực bệnh viện', ' Khu vực chợ', 'Khu vực làng quê', 'Không xác định', 'Khu vực làng quê Khu vực văn phòng', 'Khu vực giải trí' ] # tính năng liệt kê các tính năng = ['Số_phương_tiện_tham_gia','Số_trường_hợp','Giờ_của_ngày','Loại_va chạm','Độ_tuổi_của_người_lái xe','Giới tính_của_người lái xe', 'Trình độ_học vấn','Năm_phục vụ_của_phương tiện','Ngày_trong_tuần','Khu vực_xảy ra tai nạn']
Sau khi xác định tất cả các đầu vào sẽ được lấy từ người dùng, chúng tôi có thể xác định chức năng 'main()' để phát triển giao diện người dùng sẽ được hiển thị ở giao diện người dùng.
# Đặt tiêu đề cho ứng dụng web bằng cú pháp html st.markdown("
Ứng dụng dự đoán mức độ nghiêm trọng của tai nạn 🚧
", safe_allow_html=True) # xác định một hàm main() để nhận dữ liệu đầu vào từ người dùng ở dạng phê duyệt dựa trên biểu mẫu def main(): với st.form("road_traffic_severity_form"): st.subheader("Vui lòng nhập các đầu vào sau:") No_vehicles = st.slider("Số phương tiện liên quan:",1,7, value=0, format="%d") No_casualties = st.slider("Số người thương vong:",1,8, value=0, format="%d") Giờ = st.slider("Giờ trong ngày:", 0, 23, giá trị=0, định dạng="%d") va chạm = st.selectbox("Loại va chạm:",tùy chọn =options_types_collision) Age_band = st.selectbox("Nhóm tuổi của tài xế?:", options=options_age) Sex = st.selectbox("Giới tính của tài xế:", options=options_sex) Education = st.selectbox("Trình độ của tài xế: ",options=options_education_level) service_vehicle = st.selectbox("Năm dịch vụ của xe:", options=options_services_year) Day_week = st.selectbox("Ngày trong tuần:", options=options_day) Accident_area = st.selectbox("Khu vực của tai nạn:", options=options_acc_area) gửi = st.form_submit_button("Dự đoán") # enc ode sử dụng bộ mã hóa thứ tự và dự đoán nếu gửi: input_array = np.array([collision, Age_band,Sex,Education,service_vehicle, Day_week,Accident_area], ndmin=2) encoded_arr = list(encoder.transform(input_array).ravel()) num_arr = [No_vehicles,No_casualties,Hour] pred_arr = np.array(num_arr + encoded_arr).reshape(1,-1) # dự đoán mục tiêu từ tất cả các tính năng đầu vào st.write(f"Dự đoán mức độ nghiêm trọng là thương tích nghiêm trọng⚠") elif dự đoán == 0: st.write(f"Dự đoán mức độ nghiêm trọng là chấn thương nghiêm trọng") other: st.write(f"Dự đoán mức độ nghiêm trọng là chấn thương nhẹ" ) st.subheader("AI có thể giải thích (XAI) để hiểu các dự đoán") # AI có thể giải thích bằng cách sử dụng thư viện shap shap.initjs() shap_values = shap.TreeExplainer(model).shap_values(pred_arr) st.write(f"Dành cho dự đoán {prediction }") shap.force_plot(shap.TreeExplainer(model).expected_value[1], shap_values[0], pred_arr, feature_names=features, matplotlib=True,show=False).savefig("pred_force_plot.jpg", bbox_inches='strict') img = Image.open("pred_force_plot.jpg") # hiển thị biểu đồ shap trên giao diện người dùng để giải thích các dự đoán st.image(img, caption='Giải thích mô hình sử dụng shap') st.write(" Nhà phát triển: Avi kumar Talaviya") st.markdown("""Hãy liên hệ với tôi trên: [Twitter](https://twitter.com/avikumart_) | [Linkedin](https://www.linkedin.com/in/avi-kumar-talaviya-0/) | [Kaggle](https://www.kaggle.com/avikumart) """)
Cuối cùng, hãy viết ra phần mô tả dự án và tuyên bố vấn đề ở mặt trước để giới thiệu rõ ràng về dự án mà bạn đã thực hiện.
a,b,c = st.columns([0.2,0.6,0.2]) with b: st.image("vllkyt19n98psusds8.jpg", use_column_width=True) # mô tả về dự án và các tệp mã st.subheader("🧾Description :") st.text("""Bộ dữ liệu này được thu thập từ các sở cảnh sát thành phố Addis Ababa cho công việc nghiên cứu của thạc sĩ. Bộ dữ liệu được chuẩn bị từ các tài liệu thủ công về các vụ tai nạn giao thông đường bộ của năm 2017-20. Tất cả các thông tin nhạy cảm thông tin đã bị loại trừ trong quá trình mã hóa dữ liệu và cuối cùng nó có 32 tính năng và 12316 trường hợp xảy ra sự cố. Sau đó, nó được xử lý trước và để xác định các nguyên nhân chính gây ra sự cố bằng cách phân tích nó bằng các thuật toán phân loại học máy khác nhau. """) st.markdown ("Nguồn của tập dữ liệu: [Nhấp vào đây](https://www.narcis.nl/dataset/RecordID/oai%3Aeasy.dans.knaw.nl%3Aeasy-dataset%3A191591)") st.subheader("🧭 Báo cáo sự cố:") st.text("""Tính năng mục tiêu là Accident_severity là một biến nhiều lớp. Nhiệm vụ là phân loại biến này dựa trên 31 biến khác tính năng từng bước bằng cách đi qua nhiệm vụ của mỗi ngày. Số liệu để đánh giá sẽ là điểm f1 """) st.markdown("Vui lòng tìm liên kết kho lưu trữ GitHub của dự án: [Nhấp vào đây](https://github.com/avikumart/Road-Traffic-Severity-Classification-Project )") # chạy chức năng chính nếu __name__ == '__main__': main()
Đó là nó! Chỉ cần đẩy các tệp dự án vào repo github và đăng nhập vào tài khoản streamlit của bạn để khởi chạy ứng dụng streamlit chỉ bằng một cú nhấp chuột!
Để biết thêm thông tin về cách triển khai ứng dụng trên streamlit, hãy xem bài viết trước của tôi được xuất bản trên Analytics Vidhya — Bấm vào đây
Bạn có thể truy cập kho dự án tại đây
Bạn có thể xem ứng dụng web đã triển khai tại đây
Kết luận
Tóm lại, dự án máy học và khoa học dữ liệu đầu cuối đã thể hiện thành công tiềm năng sử dụng phân tích và dự đoán dữ liệu để hỗ trợ ngăn ngừa tử vong do tai nạn đường bộ. Bằng cách phân tích kỹ lưỡng dữ liệu được cung cấp và đào tạo một mô hình máy học để dự đoán mức độ nghiêm trọng của các tai nạn tiềm ẩn, cơ quan điều tra có thể ưu tiên các nỗ lực và nguồn lực của mình cho các tình huống có rủi ro cao nhất. Dự án này nêu bật giá trị của việc sử dụng các phương pháp tiếp cận dựa trên dữ liệu để giải quyết các vấn đề phức tạp và tầm quan trọng của việc tiếp tục đầu tư vào các sáng kiến này. Hãy xem xét những điểm chính từ bài viết này.
- Để thực hiện phân tích dự đoán, cần có sự hiểu biết thấu đáo về vấn đề và dữ liệu cơ bản của nó.
- Phân tích dữ liệu khám phá để tìm thông tin chuyên sâu và xử lý trước tập dữ liệu để phát triển các mô hình máy học.
- Phát triển quy trình học máy và triển khai quy trình này trên đám mây được chiếu sáng hợp lý chỉ bằng một cú nhấp chuột
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/01/machine-learning-solution-predicting-road-accident-severity/

