Amazon RedShift là kho dữ liệu đám mây có tốc độ nhanh, quy mô petabyte mà hàng chục nghìn khách hàng dựa vào để hỗ trợ khối lượng công việc phân tích của họ. Hàng nghìn khách hàng sử dụng tính năng chia sẻ dữ liệu đọc của Amazon Redshift để cho phép truy cập dữ liệu tức thì, chi tiết và nhanh chóng trên các cụm được cung cấp Redshift và các nhóm làm việc không có máy chủ. Điều này cho phép bạn mở rộng quy mô khối lượng công việc đọc của mình cho hàng nghìn người dùng đồng thời mà không cần phải di chuyển hoặc sao chép dữ liệu.
Hiện tại, tại Amazon Redshift, chúng tôi sẽ công bố tính năng ghi kho đa dữ liệu thông qua chia sẻ dữ liệu ở bản xem trước công khai. Điều này cho phép bạn đạt được hiệu suất tốt hơn cho khối lượng công việc trích xuất, chuyển đổi và tải (ETL) bằng cách sử dụng các kho khác nhau thuộc các loại và kích cỡ khác nhau dựa trên nhu cầu khối lượng công việc của bạn. Ngoài ra, điều này cho phép bạn dễ dàng duy trì các công việc ETL của mình chạy dễ dự đoán hơn vì bạn có thể phân chia chúng giữa các kho chỉ bằng vài cú nhấp chuột, theo dõi và kiểm soát chi phí vì mỗi kho có giám sát và kiểm soát chi phí riêng, đồng thời thúc đẩy sự cộng tác khi bạn có thể hỗ trợ các nhóm khác nhau để ghi vào cơ sở dữ liệu của nhóm khác chỉ bằng vài cú nhấp chuột.
Dữ liệu được hiển thị trực tuyến và có sẵn trên tất cả các kho ngay khi được cam kết, ngay cả khi dữ liệu được ghi vào nhiều tài khoản hoặc giữa các khu vực. Để xem trước, bạn có thể sử dụng kết hợp các cụm ra3.4xl, cụm ra3.16xl hoặc nhóm làm việc không có máy chủ.
Trong bài đăng này, chúng tôi thảo luận về thời điểm bạn nên cân nhắc sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu, giải thích cách hoạt động của tính năng ghi nhiều kho thông qua chia sẻ dữ liệu và hướng dẫn bạn một ví dụ về cách sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu.
Lý do sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu
Trong phần này, chúng tôi thảo luận về một số lý do tại sao bạn nên cân nhắc việc sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu.
Hiệu suất và khả năng dự đoán tốt hơn cho khối lượng công việc hỗn hợp
Khách hàng thường bắt đầu với một nhà kho có quy mô phù hợp với nhu cầu khối lượng công việc ban đầu của họ. Ví dụ: nếu bạn cần hỗ trợ các truy vấn không thường xuyên của người dùng và nhập 10 triệu hàng dữ liệu mua hàng hàng đêm thì nhóm làm việc 32 RPU có thể hoàn toàn phù hợp với nhu cầu của bạn. Tuy nhiên, việc thêm 400 triệu hàng tương tác với ứng dụng và trang web của người dùng vào mỗi giờ có thể làm chậm thời gian phản hồi của người dùng hiện tại vì khối lượng công việc mới tiêu tốn tài nguyên đáng kể. Bạn có thể thay đổi kích thước thành một nhóm làm việc lớn hơn để khối lượng công việc đọc và ghi được hoàn thành nhanh chóng mà không phải tranh giành tài nguyên. Tuy nhiên, điều này có thể cung cấp năng lượng và chi phí không cần thiết cho khối lượng công việc hiện tại. Ngoài ra, do khối lượng công việc chia sẻ điện toán nên mức tăng đột biến của một khối lượng công việc có thể ảnh hưởng đến khả năng đáp ứng SLA của các khối lượng công việc khác.
Sơ đồ sau đây minh họa kiến trúc một kho.
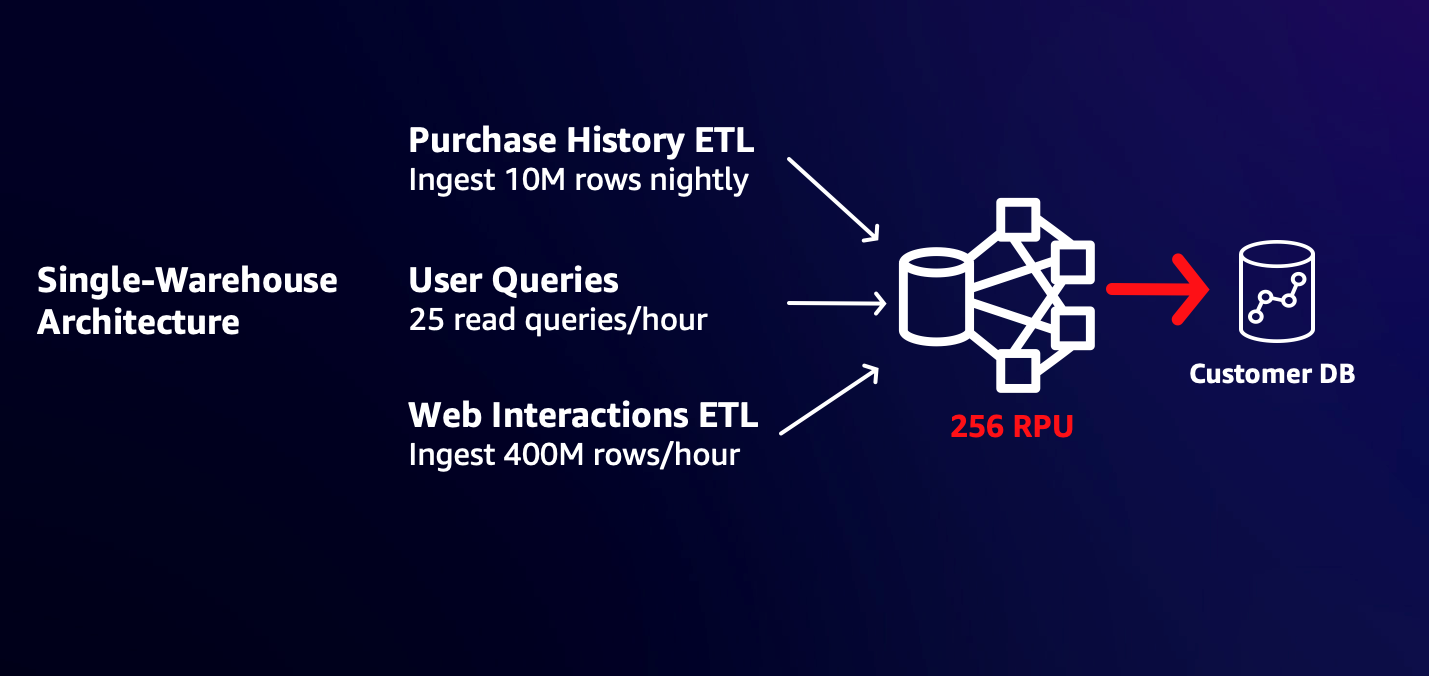
Với khả năng ghi thông qua chia sẻ dữ liệu, giờ đây bạn có thể tách ETL tương tác với trang web và ứng dụng của người dùng mới thành một nhóm làm việc riêng biệt, lớn hơn để nhóm hoàn thành nhanh chóng với hiệu suất bạn cần mà không ảnh hưởng đến chi phí hoặc thời gian hoàn thành khối lượng công việc hiện tại của bạn. Sơ đồ sau minh họa kiến trúc đa kho này.

Kiến trúc nhiều kho cho phép bạn hoàn thành tất cả khối lượng công việc ghi đúng thời gian với ít điện toán kết hợp hơn và do đó chi phí thấp hơn so với một kho duy nhất hỗ trợ tất cả khối lượng công việc.
Kiểm soát và giám sát chi phí
Khi bạn sử dụng một kho duy nhất cho tất cả công việc ETL của mình, có thể khó hiểu khối lượng công việc nào đang đóng góp vào chi phí của bạn. Ví dụ: bạn có thể có một nhóm chạy khối lượng công việc ETL nhập dữ liệu từ hệ thống CRM trong khi một nhóm khác đang nhập dữ liệu từ hệ thống vận hành nội bộ. Bạn khó có thể giám sát và kiểm soát chi phí cho khối lượng công việc vì các truy vấn đang chạy cùng nhau bằng cùng một tính toán trong kho. Bằng cách chia khối lượng công việc ghi thành các kho riêng biệt, bạn có thể giám sát và kiểm soát chi phí một cách riêng biệt đồng thời đảm bảo khối lượng công việc có thể tiến triển độc lập mà không bị xung đột tài nguyên.
Cộng tác trên dữ liệu trực tiếp một cách dễ dàng
Đôi khi, hai nhóm sử dụng các kho khác nhau để quản lý dữ liệu, tính toán hiệu suất hoặc lý do chi phí, nhưng đôi khi cũng cần ghi vào cùng một dữ liệu được chia sẻ. Ví dụ: bạn có thể có một bộ bảng 360 khách hàng cần được cập nhật trực tiếp khi khách hàng tương tác với nhóm tiếp thị, bán hàng và dịch vụ khách hàng của bạn. Khi các nhóm này sử dụng các kho khác nhau, việc duy trì dữ liệu này trực tuyến có thể khó khăn vì bạn có thể phải xây dựng quy trình ETL đa dịch vụ bằng các công cụ như Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3), Dịch vụ thông báo đơn giản của Amazon (SNS của Amazon), Dịch vụ xếp hàng đơn giản trên Amazon (Amazon SQS) và AWS Lambda để theo dõi những thay đổi trực tiếp trong dữ liệu của mỗi nhóm và nhập dữ liệu đó vào một nguồn duy nhất.
Với khả năng ghi thông qua chia sẻ dữ liệu, bạn có thể cấp các quyền chi tiết trên các đối tượng cơ sở dữ liệu của mình (ví dụ: CHỌN trên một bảng và CHỌN, CHÈN và TRUNCATE trên một bảng khác) cho các nhóm khác nhau bằng cách sử dụng các kho khác nhau chỉ bằng vài cú nhấp chuột. Điều này cho phép các nhóm bắt đầu ghi vào các đối tượng được chia sẻ bằng kho riêng của họ. Dữ liệu được cung cấp trực tiếp và có sẵn cho tất cả các kho ngay khi được cam kết và điều này thậm chí còn có tác dụng nếu các kho đang sử dụng các tài khoản và khu vực khác nhau.
Trong các phần sau, chúng tôi sẽ hướng dẫn bạn cách sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu thông qua chia sẻ dữ liệu.
Tổng quan về giải pháp
Chúng tôi sử dụng thuật ngữ sau trong giải pháp này:
- Không gian tên – Một vùng chứa logic cho các đối tượng cơ sở dữ liệu, người dùng và vai trò, quyền của họ trên các đối tượng cơ sở dữ liệu và điện toán (nhóm làm việc không có máy chủ và cụm được cung cấp).
- Chia sẻ dữ liệu – Đơn vị chia sẻ để chia sẻ dữ liệu. Bạn cấp quyền trên các đối tượng để chia sẻ dữ liệu.
- Nhà sản xuất – Kho tạo chia sẻ dữ liệu, cấp quyền cho các đối tượng được chia sẻ dữ liệu và cấp cho các kho và tài khoản khác quyền truy cập vào chia sẻ dữ liệu.
- Người tiêu dùng – Kho được cấp quyền truy cập vào chia sẻ dữ liệu. Bạn có thể coi người tiêu dùng là người thuê chia sẻ dữ liệu.
Trường hợp sử dụng này liên quan đến một khách hàng có hai kho: một kho chính được sử dụng để gắn vào không gian tên chính cho hầu hết các truy vấn đọc và ghi và một kho phụ được gắn vào một không gian tên phụ chủ yếu được sử dụng để ghi vào không gian tên chính. Chúng tôi sử dụng thông tin có sẵn công khai Bộ dữ liệu TPCH 10 GB từ AWS Labs, được lưu trữ trong bộ chứa S3. Bạn có thể sao chép và dán nhiều lệnh để làm theo. Mặc dù có kích thước nhỏ đối với kho dữ liệu nhưng bộ dữ liệu này cho phép dễ dàng kiểm tra chức năng của tính năng này.
Sơ đồ sau minh họa kiến trúc giải pháp của chúng tôi.

Chúng tôi thiết lập không gian tên chính bằng cách kết nối với nó thông qua kho của nó, tạo cơ sở dữ liệu tiếp thị trong đó với một prod và staging lược đồ và tạo ba bảng trong prod lược đồ được gọi là region, nationvà af_customer. Sau đó chúng tôi tải dữ liệu vào region và nation bảng sử dụng kho. Chúng tôi không nhập dữ liệu vào af_customer bảng.
Sau đó, chúng tôi tạo một chia sẻ dữ liệu trong không gian tên chính. Chúng tôi cấp cho dữ liệu chia sẻ khả năng tạo các đối tượng trong staging lược đồ và khả năng chọn, chèn, cập nhật và xóa khỏi các đối tượng trong prod lược đồ. Sau đó, chúng tôi cấp quyền sử dụng lược đồ cho một vùng tên khác trong tài khoản.
Tại thời điểm đó, chúng tôi kết nối với kho thứ cấp. Chúng tôi tạo cơ sở dữ liệu từ một cơ sở dữ liệu chia sẻ trong kho đó cũng như một người dùng mới. Sau đó, chúng tôi cấp quyền trên đối tượng chia sẻ dữ liệu cho người dùng mới. Sau đó, chúng tôi kết nối lại với kho thứ cấp với tư cách là người dùng mới.
Sau đó, chúng tôi tạo một bảng khách hàng trong phần chia sẻ dữ liệu staging lược đồ và sao chép dữ liệu từ tập dữ liệu khách hàng TPCH 10 vào bảng phân tầng. Chúng tôi chèn dữ liệu bảng khách hàng theo giai đoạn vào phần chia sẻ af_customer bảng sản xuất, sau đó cắt bớt bảng.
Tại thời điểm này, ETL đã hoàn tất và bạn có thể đọc dữ liệu trong không gian tên chính, được chèn bởi kho ETL phụ, từ cả kho chính và kho ETL phụ.
Điều kiện tiên quyết
Để làm theo bài đăng này, bạn phải có các điều kiện tiên quyết sau:
- Hai nhà kho được tạo bằng
PREVIEW_2023theo dõi. Kho có thể là sự kết hợp của các nhóm làm việc không có máy chủ, cụm ra3.4xl và cụm ra3.16xl. - Truy cập vào một superuser ở cả hai kho.
- An Quản lý truy cập và nhận dạng AWS (IAM) có khả năng nhập dữ liệu từ Amazon Redshift sang Amazon S3 (Amazon Redshift tạo một vai trò theo mặc định khi bạn tạo một cụm hoặc nhóm làm việc không có máy chủ).
- Chỉ đối với nhiều tài khoản, bạn cần có quyền truy cập vào người dùng IAM hoặc vai trò được phép ủy quyền chia sẻ dữ liệu. Để biết chính sách IAM, hãy tham khảo Chia sẻ dữ liệu chia sẻ.
Tham khảo Chia sẻ cả dữ liệu đọc và ghi trong tài khoản AWS hoặc giữa các tài khoản (bản xem trước) để có thông tin cập nhật nhất.
Thiết lập không gian tên chính (nhà sản xuất)
Trong phần này, chúng tôi trình bày cách thiết lập không gian tên chính (nhà sản xuất) mà chúng tôi sẽ sử dụng để lưu trữ dữ liệu của mình.
Kết nối với nhà sản xuất
Hoàn thành các bước sau để kết nối với nhà sản xuất:
- Trên bảng điều khiển Amazon Redshift, hãy chọn Trình chỉnh sửa truy vấn v2 trong khung điều hướng.

Trong trình soạn thảo truy vấn v2, bạn có thể thấy tất cả các kho mà bạn có quyền truy cập ở khung bên trái. Bạn có thể mở rộng chúng để xem cơ sở dữ liệu của chúng.
- Kết nối với kho chính của bạn bằng siêu người dùng.
- Chạy lệnh sau để tạo
marketingcơ sở dữ liệu:
Tạo các đối tượng cơ sở dữ liệu để chia sẻ
Hoàn thành các bước sau để tạo đối tượng cơ sở dữ liệu của bạn để chia sẻ:
- Sau khi bạn tạo
marketingcơ sở dữ liệu, hãy chuyển kết nối cơ sở dữ liệu của bạn sangmarketingcơ sở dữ liệu.
Bạn có thể cần phải làm mới trang của mình để có thể xem nó.
- Chạy các lệnh sau để tạo hai lược đồ bạn định chia sẻ:
- Tạo các bảng để chia sẻ với đoạn mã sau. Đây là các câu lệnh DDL tiêu chuẩn đến từ tệp DDL AWS Labs có tên bảng được sửa đổi.
Sao chép dữ liệu vào region và nation bảng
Chạy các lệnh sau để sao chép dữ liệu từ bộ chứa AWS Labs S3 vào region và nation những cái bàn. Nếu bạn đã tạo một cụm trong khi vẫn giữ vai trò IAM được tạo mặc định, bạn có thể sao chép và dán các lệnh sau để tải dữ liệu vào bảng của mình:
Tạo chia sẻ dữ liệu
Tạo datashare bằng lệnh sau:
Sản phẩm publicaccessible cài đặt chỉ định liệu người tiêu dùng có thể sử dụng chia sẻ dữ liệu với các cụm được cung cấp và nhóm làm việc không có máy chủ có thể truy cập công khai hay không. Nếu kho của bạn không thể truy cập công khai, bạn có thể bỏ qua trường đó.
Cấp quyền trên các lược đồ cho việc chia sẻ dữ liệu
Để thêm các đối tượng có quyền vào chia sẻ dữ liệu, hãy sử dụng cú pháp cấp, chỉ định chia sẻ dữ liệu mà bạn muốn cấp quyền cho:
Điều này cho phép người tiêu dùng chia sẻ dữ liệu sử dụng các đối tượng được thêm vào prod lược đồ và sử dụng cũng như tạo các đối tượng được thêm vào staging lược đồ. Để duy trì khả năng tương thích ngược, nếu bạn sử dụng alter datashare lệnh thêm một lược đồ, nó sẽ tương đương với việc cấp quyền sử dụng lược đồ.
Cấp quyền trên các bảng để chia sẻ dữ liệu
Bây giờ bạn có thể cấp quyền truy cập vào các bảng để chia sẻ dữ liệu bằng cách sử dụng cú pháp cấp, chỉ định các quyền và chia sẻ dữ liệu. Đoạn mã sau cấp tất cả các đặc quyền trên af_customer bảng vào chia sẻ dữ liệu:
Để duy trì khả năng tương thích ngược, nếu bạn sử dụng lệnh chia sẻ dữ liệu thay đổi để thêm bảng, nó sẽ tương đương với việc cấp quyền chọn trên bảng.
Ngoài ra, chúng tôi đã thêm các quyền có phạm vi cho phép bạn cấp cùng một quyền cho tất cả các đối tượng hiện tại và tương lai trong chia sẻ dữ liệu. Chúng tôi thêm quyền chọn phạm vi trên sản phẩm bảng lược đồ vào chia sẻ dữ liệu:
Sau lần cấp phép này, khách hàng sẽ có quyền chọn trên tất cả các bảng hiện tại và tương lai trong lược đồ sản phẩm. Điều này cho phép họ truy cập chọn lọc trên region và nation bảng.
Xem quyền được cấp cho chia sẻ dữ liệu
Bạn có thể xem các quyền được cấp cho chia sẻ dữ liệu bằng cách chạy lệnh sau:
Cấp quyền cho không gian tên ETL phụ
Bạn có thể cấp quyền cho không gian tên ETL phụ bằng cú pháp hiện có. Bạn thực hiện việc này bằng cách chỉ định ID vùng tên. Bạn có thể tìm thấy vùng tên trên trang chi tiết vùng tên nếu vùng tên ETL phụ của bạn không có máy chủ, như một phần của ID vùng tên trong trang chi tiết cụm nếu vùng tên ETL phụ của bạn được cung cấp hoặc bằng cách kết nối với kho ETL thứ cấp trong trình soạn thảo truy vấn v2 và chạy select current_namespace. Sau đó, bạn có thể cấp quyền truy cập vào không gian tên khác bằng lệnh sau (thay đổi không gian tên người tiêu dùng thành UID không gian tên của kho ETL phụ của riêng bạn):
Thiết lập không gian tên ETL phụ (người tiêu dùng)
Tại thời điểm này, bạn đã sẵn sàng thiết lập kho ETL thứ cấp (tiêu dùng) của mình để bắt đầu ghi vào dữ liệu được chia sẻ.
Tạo cơ sở dữ liệu từ datashare
Hoàn thành các bước sau để tạo cơ sở dữ liệu của bạn:
- Trong trình soạn thảo truy vấn v2, hãy chuyển sang kho ETL thứ cấp.
- Chạy lệnh
show datasharesđể xem chia sẻ dữ liệu tiếp thị cũng như không gian tên của nhà sản xuất chia sẻ dữ liệu. - Sử dụng không gian tên đó để tạo cơ sở dữ liệu từ chia sẻ dữ liệu, như minh họa trong đoạn mã sau:
Chỉ định with permissions cho phép bạn cấp quyền chi tiết cho từng người dùng và vai trò cơ sở dữ liệu. Nếu không có điều này, nếu bạn cấp quyền sử dụng trên cơ sở dữ liệu chia sẻ dữ liệu, người dùng và vai trò sẽ nhận được tất cả các quyền trên tất cả các đối tượng trong cơ sở dữ liệu chia sẻ dữ liệu.
Tạo người dùng và cấp quyền cho người dùng đó
Tạo người dùng bằng cách sử dụng TẠO NGƯỜI DÙNG chỉ huy:
Với những khoản trợ cấp này, bạn đã cấp cho người dùng data_engineer tất cả các quyền trên tất cả các đối tượng trong chia sẻ dữ liệu. Ngoài ra, bạn đã cấp tất cả các quyền có sẵn trong lược đồ dưới dạng các quyền có phạm vi cho data_engineer. Mọi quyền đối với bất kỳ đối tượng nào được thêm vào các lược đồ đó sẽ tự động được cấp cho data_engineer.
Tại thời điểm này, bạn có thể tiếp tục các bước bằng cách sử dụng người dùng quản trị mà bạn hiện đang đăng nhập hoặc data_engineer.
Các tùy chọn để ghi vào cơ sở dữ liệu chia sẻ dữ liệu
Bạn có thể ghi dữ liệu vào cơ sở dữ liệu chia sẻ dữ liệu theo ba cách.
Sử dụng ký hiệu ba phần trong khi kết nối với cơ sở dữ liệu cục bộ
Giống như chia sẻ dữ liệu đã đọc, bạn có thể sử dụng ký hiệu ba phần để tham chiếu các đối tượng cơ sở dữ liệu chia sẻ dữ liệu. Ví dụ, insert into marketing_ds_db.prod.customer. Lưu ý rằng bạn không thể sử dụng các giao dịch nhiều câu lệnh để ghi vào các đối tượng trong cơ sở dữ liệu chia sẻ dữ liệu như thế này.
Kết nối trực tiếp với cơ sở dữ liệu chia sẻ dữ liệu
Bạn có thể kết nối trực tiếp với cơ sở dữ liệu chia sẻ dữ liệu thông qua trình điều khiển Redshift JDBC, ODBC hoặc Python, ngoài API dữ liệu Amazon Redshift (mới). Để kết nối như thế này, hãy chỉ định tên cơ sở dữ liệu chia sẻ dữ liệu trong chuỗi kết nối. Điều này cho phép bạn ghi vào cơ sở dữ liệu chia sẻ dữ liệu bằng cách sử dụng ký hiệu hai phần và sử dụng các giao dịch nhiều câu lệnh để ghi vào cơ sở dữ liệu chia sẻ dữ liệu. Lưu ý rằng một số bảng hệ thống và danh mục không có sẵn theo cách này.
Chạy lệnh sử dụng
Bây giờ bạn có thể chỉ định rằng bạn muốn sử dụng cơ sở dữ liệu khác bằng lệnh use <database_name>. Điều này cho phép bạn ghi vào cơ sở dữ liệu chia sẻ dữ liệu bằng cách sử dụng ký hiệu hai phần và sử dụng các giao dịch nhiều câu lệnh để ghi vào cơ sở dữ liệu chia sẻ dữ liệu. Lưu ý rằng một số bảng hệ thống và danh mục không có sẵn theo cách này. Ngoài ra, khi truy vấn bảng hệ thống và danh mục, bạn sẽ truy vấn bảng hệ thống và danh mục của cơ sở dữ liệu mà bạn được kết nối chứ không phải cơ sở dữ liệu bạn đang sử dụng.
Để thử phương pháp này, hãy chạy lệnh sau:
Bắt đầu ghi vào cơ sở dữ liệu chia sẻ dữ liệu
Trong phần này, chúng tôi trình bày cách ghi vào cơ sở dữ liệu chia sẻ dữ liệu bằng cách sử dụng tùy chọn thứ hai và thứ ba mà chúng tôi đã thảo luận (kết nối trực tiếp hoặc sử dụng lệnh). Chúng tôi sử dụng AWS Labs cung cấp SQL để ghi vào cơ sở dữ liệu chia sẻ dữ liệu.
Tạo một bảng phân tầng
Tạo một bảng trong lược đồ phân tầng vì bạn đã được cấp đặc quyền tạo. Chúng tôi tạo một bảng trong chia sẻ dữ liệu staging lược đồ với câu lệnh DDL sau:
Bạn có thể sử dụng ký hiệu hai phần vì bạn đã sử dụng lệnh USE hoặc được kết nối trực tiếp với cơ sở dữ liệu chia sẻ dữ liệu. Nếu không, bạn cũng cần chỉ định tên cơ sở dữ liệu chia sẻ dữ liệu.
Sao chép dữ liệu vào bảng phân tầng
Sao chép dữ liệu TPCH 10 của khách hàng từ bộ chứa S3 công khai của AWS Labs vào bảng bằng lệnh sau:
Như trước đây, điều này yêu cầu bạn phải thiết lập vai trò IAM mặc định khi tạo kho này.
Nhập dữ liệu khách hàng Châu Phi vào bảng prod.af_customer
Chạy lệnh sau để chỉ nhập dữ liệu khách hàng Châu Phi vào bảng prod.af_customer:
Điều này yêu cầu bạn phải tham gia vào các bảng quốc gia và khu vực mà bạn có quyền chọn.
Cắt ngắn bảng phân tầng
Bạn có thể cắt bớt dàn dựng table để bạn có thể ghi vào đó mà không cần tạo lại nó trong công việc sau này. Hành động cắt ngắn sẽ chạy theo giao dịch và có thể được khôi phục nếu bạn được kết nối trực tiếp với cơ sở dữ liệu chia sẻ dữ liệu hoặc bạn đang sử dụng lệnh use (ngay cả khi bạn không sử dụng cơ sở dữ liệu chia sẻ dữ liệu). Sử dụng mã sau đây:
Tại thời điểm này, bạn đã hoàn tất việc nhập dữ liệu vào không gian tên chính. Bạn có thể truy vấn af_customer bảng từ cả kho chính và kho ETL phụ và xem cùng một dữ liệu.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách sử dụng nhiều kho để ghi vào cùng một cơ sở dữ liệu. Giải pháp này có những lợi ích sau:
- Bạn có thể sử dụng các cụm được cung cấp và nhóm làm việc không có máy chủ có quy mô khác nhau để ghi vào cùng một cơ sở dữ liệu
- Bạn có thể viết trên các tài khoản và khu vực
- Dữ liệu được cung cấp trực tiếp và có sẵn cho tất cả các kho ngay khi được cam kết
- Ghi hoạt động ngay cả khi kho của nhà sản xuất (kho sở hữu cơ sở dữ liệu) bị tạm dừng
Để tìm hiểu thêm về tính năng này, hãy xem Chia sẻ cả dữ liệu đọc và ghi trong tài khoản AWS hoặc giữa các tài khoản (bản xem trước). Ngoài ra, nếu bạn có bất kỳ phản hồi nào, vui lòng gửi email cho chúng tôi theo địa chỉ dsw-feedback@amazon.com.
Giới thiệu về tác giả
 Ryan Waldorf là Giám đốc sản phẩm cấp cao tại Amazon Redshift. Ryan tập trung vào các tính năng cho phép khách hàng xác định và mở rộng quy mô điện toán bao gồm chia sẻ dữ liệu và mở rộng quy mô đồng thời.
Ryan Waldorf là Giám đốc sản phẩm cấp cao tại Amazon Redshift. Ryan tập trung vào các tính năng cho phép khách hàng xác định và mở rộng quy mô điện toán bao gồm chia sẻ dữ liệu và mở rộng quy mô đồng thời.
 Harshida Patel là Kiến trúc sư giải pháp chính chuyên môn về phân tích, làm việc tại Amazon Web Services (AWS).
Harshida Patel là Kiến trúc sư giải pháp chính chuyên môn về phân tích, làm việc tại Amazon Web Services (AWS).
 Sudipto Das là Kỹ sư chính cấp cao tại Amazon Web Services (AWS). Ông lãnh đạo chiến lược và kiến trúc kỹ thuật của nhiều dịch vụ cơ sở dữ liệu và phân tích trong AWS, đặc biệt tập trung vào Amazon Redshift và Amazon Aurora.
Sudipto Das là Kỹ sư chính cấp cao tại Amazon Web Services (AWS). Ông lãnh đạo chiến lược và kiến trúc kỹ thuật của nhiều dịch vụ cơ sở dữ liệu và phân tích trong AWS, đặc biệt tập trung vào Amazon Redshift và Amazon Aurora.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/improve-your-etl-performance-using-multiple-redshift-warehouses-for-writes/

