Bài đăng này được đồng viết với Santosh Waddi và Nanda Kishore Thatikonda từ BigBasket.
BigBasket là cửa hàng tạp hóa và thực phẩm trực tuyến lớn nhất Ấn Độ. Họ hoạt động trên nhiều kênh thương mại điện tử như thương mại nhanh, giao hàng theo thời gian và đăng ký hàng ngày. Bạn cũng có thể mua từ các cửa hàng thực tế và máy bán hàng tự động của họ. Họ cung cấp một lượng lớn hơn 50,000 sản phẩm trên 1,000 thương hiệu và đang hoạt động tại hơn 500 thành phố và thị trấn. BigBasket phục vụ hơn 10 triệu khách hàng.
Trong bài đăng này, chúng tôi thảo luận về cách BigBasket sử dụng Amazon SageMaker để đào tạo mô hình thị giác máy tính của họ để nhận dạng sản phẩm Hàng tiêu dùng nhanh (FMCG), giúp họ giảm thời gian đào tạo khoảng 50% và tiết kiệm chi phí 20%.
thách thức khách hàng
Ngày nay, hầu hết các siêu thị và cửa hàng thực tế ở Ấn Độ đều cung cấp dịch vụ thanh toán thủ công tại quầy thanh toán. Điều này có hai vấn đề:
- Việc này đòi hỏi thêm nhân lực, trọng lượng và đào tạo lặp đi lặp lại cho đội ngũ vận hành tại cửa hàng khi họ mở rộng quy mô.
- Ở hầu hết các cửa hàng, quầy thanh toán khác với quầy cân, điều này làm tăng thêm rắc rối trong hành trình mua hàng của khách hàng. Khách hàng thường làm mất tem cân và phải quay lại quầy cân để lấy lại trước khi tiến hành quá trình tính tiền.
Quy trình tự kiểm tra
BigBasket đã giới thiệu hệ thống thanh toán được hỗ trợ bởi AI trong các cửa hàng thực tế của họ, sử dụng camera để phân biệt các mặt hàng một cách duy nhất. Hình dưới đây cung cấp cái nhìn tổng quan về quá trình thanh toán.
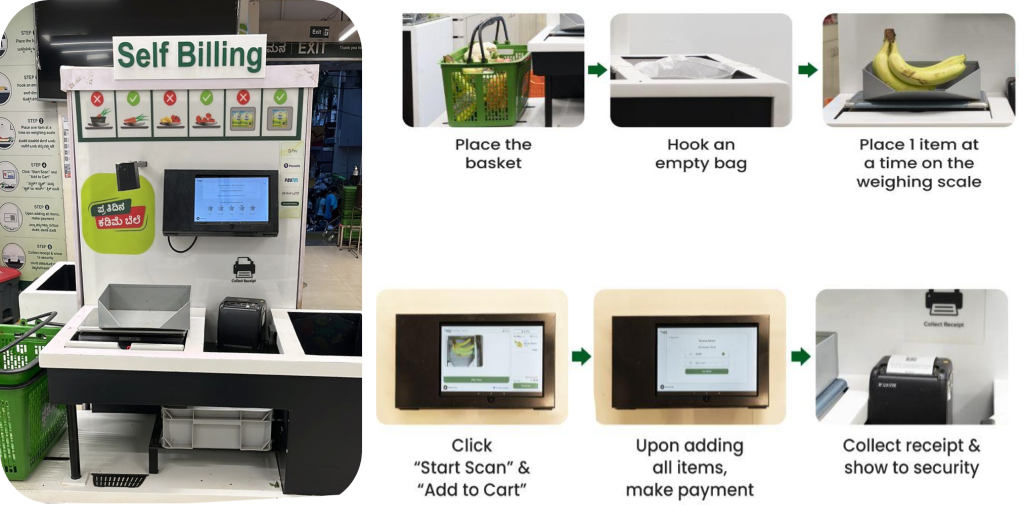
Nhóm BigBasket đang chạy các thuật toán ML nội bộ, mã nguồn mở để nhận dạng đối tượng thị giác máy tính nhằm hỗ trợ quá trình thanh toán hỗ trợ AI tại Tươi cửa hàng (vật lý). Chúng tôi đang phải đối mặt với những thách thức sau để vận hành thiết lập hiện tại của họ:
- Với việc liên tục giới thiệu các sản phẩm mới, mô hình thị giác máy tính cần liên tục kết hợp thông tin sản phẩm mới. Hệ thống cần xử lý một danh mục lớn gồm hơn 12,000 Đơn vị lưu kho (SKU), với các SKU mới liên tục được bổ sung với tốc độ trên 600 mỗi tháng.
- Để bắt kịp với các sản phẩm mới, mỗi tháng một mô hình mới được sản xuất bằng cách sử dụng dữ liệu đào tạo mới nhất. Việc đào tạo người mẫu thường xuyên để thích ứng với các sản phẩm mới rất tốn kém và mất thời gian.
- BigBasket cũng muốn giảm thời gian chu kỳ đào tạo để cải thiện thời gian tiếp thị. Do số lượng SKU tăng lên, thời gian thực hiện của mô hình tăng tuyến tính, điều này ảnh hưởng đến thời gian đưa ra thị trường của họ vì tần suất đào tạo rất cao và mất nhiều thời gian.
- Việc tăng cường dữ liệu để đào tạo mô hình và quản lý thủ công toàn bộ chu trình đào tạo từ đầu đến cuối đã bổ sung thêm chi phí đáng kể. BigBasket đang chạy ứng dụng này trên nền tảng của bên thứ ba, điều này phát sinh chi phí đáng kể.
Tổng quan về giải pháp
Chúng tôi khuyên BigBasket nên thiết kế lại giải pháp phát hiện và phân loại sản phẩm FMCG hiện có của họ bằng SageMaker để giải quyết những thách thức này. Trước khi chuyển sang sản xuất toàn diện, BigBasket đã thử nghiệm SageMaker để đánh giá các chỉ số hiệu suất, chi phí và sự tiện lợi.
Mục tiêu của họ là tinh chỉnh mô hình học máy thị giác máy tính (ML) hiện có để phát hiện SKU. Chúng tôi đã sử dụng kiến trúc mạng nơ ron tích chập (CNN) với ResNet152 để phân loại hình ảnh. Một tập dữ liệu khá lớn gồm khoảng 300 hình ảnh trên mỗi SKU đã được ước tính để đào tạo mô hình, tạo ra tổng số hơn 4 triệu hình ảnh đào tạo. Đối với một số SKU nhất định, chúng tôi đã tăng cường dữ liệu để bao gồm nhiều điều kiện môi trường hơn.
Sơ đồ sau minh họa kiến trúc giải pháp.

Quá trình hoàn chỉnh có thể được tóm tắt thành các bước cấp cao sau:
- Thực hiện làm sạch dữ liệu, chú thích và tăng cường.
- Lưu trữ dữ liệu trong một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) xô.
- Sử dụng SageMaker và Amazon FSx cho ánh để tăng cường dữ liệu hiệu quả.
- Chia dữ liệu thành các tập huấn luyện, xác thực và kiểm tra. Chúng tôi đã sử dụng FSx cho Lustre và Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) để truy cập dữ liệu song song nhanh chóng.
- Sử dụng tùy chỉnh Kim tự tháp Docker container bao gồm các thư viện nguồn mở khác.
- Sử dụng Tính song song của dữ liệu phân tán SageMaker (SMDDP) để đào tạo phân tán cấp tốc.
- Đăng nhập số liệu đào tạo mô hình.
- Sao chép mô hình cuối cùng vào vùng lưu trữ S3.
BigBasket đã qua sử dụng sổ ghi chép SageMaker để đào tạo các mô hình ML của họ và có thể dễ dàng chuyển PyTorch nguồn mở hiện có của họ cũng như các phần phụ thuộc nguồn mở khác sang vùng chứa SageMaker PyTorch và chạy quy trình một cách liền mạch. Đây là lợi ích đầu tiên mà nhóm BigBasket nhận thấy vì hầu như không có bất kỳ thay đổi nào cần thiết đối với mã để khiến mã tương thích chạy trên môi trường SageMaker.
Mạng mô hình bao gồm kiến trúc ResNet 152, theo sau là các lớp được kết nối đầy đủ. Chúng tôi đã cố định các lớp tính năng cấp thấp và giữ lại trọng số thu được thông qua quá trình học chuyển từ mô hình ImageNet. Tổng số tham số của mô hình là 66 triệu, bao gồm 23 triệu tham số có thể huấn luyện được. Cách tiếp cận dựa trên học chuyển này đã giúp họ sử dụng ít hình ảnh hơn tại thời điểm đào tạo, đồng thời cho phép hội tụ nhanh hơn và giảm tổng thời gian đào tạo.
Xây dựng và đào tạo mô hình trong Xưởng sản xuất Amazon SageMaker đã cung cấp một môi trường phát triển tích hợp (IDE) với mọi thứ cần thiết để chuẩn bị, xây dựng, đào tạo và điều chỉnh các mô hình. Việc tăng cường dữ liệu huấn luyện bằng cách sử dụng các kỹ thuật như cắt xén, xoay và lật hình ảnh đã giúp cải thiện dữ liệu huấn luyện mô hình và độ chính xác của mô hình.
Quá trình đào tạo mô hình đã được tăng tốc 50% thông qua việc sử dụng thư viện SMDDP, bao gồm các thuật toán giao tiếp được tối ưu hóa được thiết kế dành riêng cho cơ sở hạ tầng AWS. Để cải thiện hiệu suất đọc/ghi dữ liệu trong quá trình đào tạo mô hình và tăng cường dữ liệu, chúng tôi đã sử dụng FSx cho Lustre để có thông lượng hiệu suất cao.
Kích thước dữ liệu đào tạo ban đầu của họ là hơn 1.5 TB. Chúng tôi đã sử dụng hai Đám mây điện toán đàn hồi Amazon (Amazon EC2) p4d.24 phiên bản lớn với 8 GPU và bộ nhớ GPU 40 GB. Đối với hoạt động đào tạo phân tán của SageMaker, các phiên bản cần phải ở cùng Khu vực AWS và Vùng sẵn sàng. Ngoài ra, dữ liệu đào tạo được lưu trữ trong bộ chứa S3 cần phải nằm trong cùng Vùng sẵn sàng. Kiến trúc này cũng cho phép BigBasket thay đổi sang các loại phiên bản khác hoặc thêm nhiều phiên bản hơn vào kiến trúc hiện tại để đáp ứng mọi nhu cầu tăng trưởng dữ liệu đáng kể hoặc giảm thêm thời gian đào tạo.
Thư viện SMDDP đã giúp giảm thời gian, chi phí và độ phức tạp đào tạo như thế nào
Trong đào tạo dữ liệu phân tán truyền thống, khung đào tạo chỉ định cấp bậc cho GPU (công nhân) và tạo bản sao mô hình của bạn trên mỗi GPU. Trong mỗi lần lặp đào tạo, lô dữ liệu toàn cầu được chia thành các phần (phân đoạn lô) và một phần được phân phối cho mỗi nhân viên. Sau đó, mỗi nhân viên sẽ tiến hành chuyển tiếp và chuyển ngược được xác định trong tập lệnh đào tạo của bạn trên mỗi GPU. Cuối cùng, trọng số và độ dốc của mô hình từ các bản sao mô hình khác nhau được đồng bộ hóa vào cuối quá trình lặp thông qua hoạt động giao tiếp chung có tên AllReduce. Sau khi mỗi Worker và GPU có bản sao được đồng bộ hóa của mô hình, lần lặp tiếp theo sẽ bắt đầu.
Thư viện SMDDP là thư viện giao tiếp tập thể giúp cải thiện hiệu suất của quá trình đào tạo song song dữ liệu phân tán này. Thư viện SMDDP giảm chi phí liên lạc của các hoạt động liên lạc tập thể quan trọng như AllReduce. Việc triển khai AllReduce được thiết kế cho cơ sở hạ tầng AWS và có thể tăng tốc độ đào tạo bằng cách chồng chéo hoạt động AllReduce với quá trình truyền ngược. Cách tiếp cận này đạt được hiệu quả mở rộng gần như tuyến tính và tốc độ đào tạo nhanh hơn bằng cách tối ưu hóa hoạt động kernel giữa CPU và GPU.
Lưu ý các tính toán sau:
- Kích thước của lô toàn cầu là (số nút trong một cụm) * (số GPU trên mỗi nút) * (mỗi phân đoạn lô)
- Phân đoạn lô (lô nhỏ) là tập hợp con của tập dữ liệu được gán cho mỗi GPU (worker) trên mỗi lần lặp
BigBasket đã sử dụng thư viện SMDDP để giảm thời gian đào tạo tổng thể. Với FSx for Lustre, chúng tôi đã giảm thông lượng đọc/ghi dữ liệu trong quá trình đào tạo mô hình và tăng cường dữ liệu. Với tính năng song song dữ liệu, BigBasket có thể đạt được tốc độ đào tạo nhanh hơn gần 50% và rẻ hơn 20% so với các giải pháp thay thế khác, mang lại hiệu suất tốt nhất trên AWS. SageMaker tự động tắt quy trình đào tạo sau khi hoàn thành. Dự án đã hoàn thành thành công với thời gian đào tạo trên AWS nhanh hơn 50% (4.5 ngày trên AWS so với 9 ngày trên nền tảng cũ của họ).
Tại thời điểm viết bài này, BigBasket đã chạy giải pháp sản xuất hoàn chỉnh trong hơn 6 tháng và mở rộng hệ thống bằng cách cung cấp dịch vụ cho các thành phố mới và chúng tôi đang bổ sung thêm các cửa hàng mới mỗi tháng.
“Sự hợp tác của chúng tôi với AWS về việc chuyển sang đào tạo phân tán bằng cách sử dụng sản phẩm SMDDP của họ đã mang lại thắng lợi lớn. Nó không chỉ giúp chúng tôi giảm 50% thời gian đào tạo mà còn rẻ hơn 20%. Trong toàn bộ mối quan hệ đối tác của chúng tôi, AWS đã đặt ra tiêu chuẩn cho sự quan tâm của khách hàng và mang lại kết quả—làm việc với chúng tôi một cách toàn diện để nhận ra những lợi ích đã hứa.”
– Keshav Kumar, Trưởng phòng Kỹ thuật tại BigBasket.
Kết luận
Trong bài đăng này, chúng tôi đã thảo luận về cách BigBasket sử dụng SageMaker để đào tạo mô hình thị giác máy tính của họ để nhận dạng sản phẩm FMCG. Việc triển khai hệ thống tự thanh toán tự động được hỗ trợ bởi AI mang lại trải nghiệm khách hàng bán lẻ được cải thiện thông qua đổi mới, đồng thời loại bỏ các lỗi của con người trong quy trình thanh toán. Đẩy nhanh quá trình giới thiệu sản phẩm mới bằng cách sử dụng chương trình đào tạo được phân phối của SageMaker giúp giảm thời gian và chi phí giới thiệu SKU. Việc tích hợp FSx for Lustre cho phép truy cập dữ liệu song song nhanh chóng để đào tạo lại mô hình hiệu quả với hàng trăm SKU mới hàng tháng. Nhìn chung, giải pháp tự thanh toán dựa trên AI này mang lại trải nghiệm mua sắm nâng cao mà không có lỗi thanh toán ở giao diện người dùng. Việc tự động hóa và đổi mới đã thay đổi hoạt động thanh toán bán lẻ và triển khai của họ.
SageMaker cung cấp khả năng phát triển, triển khai và giám sát ML từ đầu đến cuối, chẳng hạn như môi trường sổ ghi chép SageMaker Studio để viết mã, thu thập dữ liệu, gắn thẻ dữ liệu, đào tạo mô hình, điều chỉnh mô hình, triển khai, giám sát, v.v. Nếu doanh nghiệp của bạn đang gặp phải bất kỳ thách thức nào được mô tả trong bài đăng này và muốn tiết kiệm thời gian tiếp thị cũng như cải thiện chi phí, hãy liên hệ với nhóm tài khoản AWS tại Khu vực của bạn và bắt đầu với SageMaker.
Về các tác giả
 Santosh Waddi là Kỹ sư chính tại BigBasket, có hơn một thập kỷ chuyên môn trong việc giải quyết các thách thức về AI. Với nền tảng vững chắc về thị giác máy tính, khoa học dữ liệu và học sâu, anh có bằng sau đại học của IIT Bombay. Santosh là tác giả của các ấn phẩm đáng chú ý của IEEE và, với tư cách là một tác giả blog công nghệ dày dạn kinh nghiệm, ông cũng đã có những đóng góp đáng kể cho việc phát triển các giải pháp thị giác máy tính trong thời gian làm việc tại Samsung.
Santosh Waddi là Kỹ sư chính tại BigBasket, có hơn một thập kỷ chuyên môn trong việc giải quyết các thách thức về AI. Với nền tảng vững chắc về thị giác máy tính, khoa học dữ liệu và học sâu, anh có bằng sau đại học của IIT Bombay. Santosh là tác giả của các ấn phẩm đáng chú ý của IEEE và, với tư cách là một tác giả blog công nghệ dày dạn kinh nghiệm, ông cũng đã có những đóng góp đáng kể cho việc phát triển các giải pháp thị giác máy tính trong thời gian làm việc tại Samsung.
 Nanda Kishore Thatikonda là Giám đốc Kỹ thuật phụ trách Kỹ thuật Dữ liệu và Phân tích tại BigBasket. Nanda đã xây dựng nhiều ứng dụng để phát hiện sự bất thường và đã được cấp bằng sáng chế trong lĩnh vực tương tự. Anh đã làm việc trong việc xây dựng các ứng dụng cấp doanh nghiệp, xây dựng nền tảng dữ liệu trong nhiều tổ chức và nền tảng báo cáo để hợp lý hóa các quyết định được hỗ trợ bởi dữ liệu. Nanda có hơn 18 năm kinh nghiệm làm việc trong Java/J2EE, công nghệ Spring và khung dữ liệu lớn sử dụng Hadoop và Apache Spark.
Nanda Kishore Thatikonda là Giám đốc Kỹ thuật phụ trách Kỹ thuật Dữ liệu và Phân tích tại BigBasket. Nanda đã xây dựng nhiều ứng dụng để phát hiện sự bất thường và đã được cấp bằng sáng chế trong lĩnh vực tương tự. Anh đã làm việc trong việc xây dựng các ứng dụng cấp doanh nghiệp, xây dựng nền tảng dữ liệu trong nhiều tổ chức và nền tảng báo cáo để hợp lý hóa các quyết định được hỗ trợ bởi dữ liệu. Nanda có hơn 18 năm kinh nghiệm làm việc trong Java/J2EE, công nghệ Spring và khung dữ liệu lớn sử dụng Hadoop và Apache Spark.
 Sudhanshu Ghét là Chuyên gia AI & ML chính của AWS và làm việc với khách hàng để tư vấn cho họ về MLOps và hành trình AI tổng hợp của họ. Trong vai trò trước đây của mình, anh đã lên ý tưởng, sáng tạo và lãnh đạo các nhóm xây dựng nền tảng trò chơi và AI dựa trên nguồn mở, cơ bản, đồng thời thương mại hóa thành công nền tảng này với hơn 100 khách hàng. Sudhanshu có một vài bằng sáng chế; đã viết 2 cuốn sách, một số bài báo và blog; và đã trình bày quan điểm của mình trên nhiều diễn đàn khác nhau. Ông là nhà lãnh đạo tư tưởng và diễn giả và đã làm việc trong ngành này gần 25 năm. Anh ấy đã làm việc với các khách hàng Fortune 1000 trên toàn cầu và gần đây nhất là làm việc với các khách hàng kỹ thuật số bản địa ở Ấn Độ.
Sudhanshu Ghét là Chuyên gia AI & ML chính của AWS và làm việc với khách hàng để tư vấn cho họ về MLOps và hành trình AI tổng hợp của họ. Trong vai trò trước đây của mình, anh đã lên ý tưởng, sáng tạo và lãnh đạo các nhóm xây dựng nền tảng trò chơi và AI dựa trên nguồn mở, cơ bản, đồng thời thương mại hóa thành công nền tảng này với hơn 100 khách hàng. Sudhanshu có một vài bằng sáng chế; đã viết 2 cuốn sách, một số bài báo và blog; và đã trình bày quan điểm của mình trên nhiều diễn đàn khác nhau. Ông là nhà lãnh đạo tư tưởng và diễn giả và đã làm việc trong ngành này gần 25 năm. Anh ấy đã làm việc với các khách hàng Fortune 1000 trên toàn cầu và gần đây nhất là làm việc với các khách hàng kỹ thuật số bản địa ở Ấn Độ.
 Ayush Kumar là Kiến trúc sư giải pháp tại AWS. Anh đang làm việc với nhiều khách hàng AWS khác nhau, giúp họ áp dụng các ứng dụng hiện đại mới nhất và đổi mới nhanh hơn nhờ các công nghệ dựa trên nền tảng đám mây. Bạn sẽ thấy anh ấy đang thử nghiệm trong bếp khi rảnh rỗi.
Ayush Kumar là Kiến trúc sư giải pháp tại AWS. Anh đang làm việc với nhiều khách hàng AWS khác nhau, giúp họ áp dụng các ứng dụng hiện đại mới nhất và đổi mới nhanh hơn nhờ các công nghệ dựa trên nền tảng đám mây. Bạn sẽ thấy anh ấy đang thử nghiệm trong bếp khi rảnh rỗi.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

