Giới thiệu
Google cho biết BERT là một bước tiến lớn, một trong những cải tiến lớn nhất trong lịch sử Tìm kiếm. Nó giúp Google hiểu chính xác hơn những gì mọi người đang tìm kiếm. Khả năng làm chủ Visual BERT rất đặc biệt vì nó có thể hiểu các từ trong câu bằng cách nhìn vào các từ trước và sau chúng. Điều này giúp nó hiểu ý nghĩa của câu tốt hơn. Giống như khi chúng ta hiểu một câu bằng cách xem xét tất cả các từ trong đó.

BERT giúp máy tính hiểu được ý nghĩa của văn bản trong các tình huống khác nhau. Ví dụ: nó có thể giúp phân loại văn bản, hiểu cảm xúc của mọi người trong tin nhắn, trả lời các câu hỏi được nhận dạng và tên của sự vật hoặc con người. Việc sử dụng BERT trong Google Tìm kiếm cho thấy các mô hình ngôn ngữ đã tiến bộ rất nhiều và giúp cho việc tương tác của chúng ta với máy tính trở nên tự nhiên và hữu ích hơn.
Mục tiêu học tập
- Tìm hiểu BERT là viết tắt của từ gì (Biểu diễn bộ mã hóa hai chiều từ Transformers).
- Kiến thức về cách BERT được đào tạo trên một lượng lớn dữ liệu văn bản.
- Hiểu khái niệm đào tạo trước và cách nó giúp BERT phát triển khả năng hiểu ngôn ngữ.
- Nhận biết rằng BERT xem xét cả ngữ cảnh bên trái và bên phải của các từ trong câu.
- Sử dụng BERT trong công cụ tìm kiếm để hiểu truy vấn của người dùng tốt hơn.
- Khám phá mô hình ngôn ngữ ẩn và các nhiệm vụ dự đoán câu tiếp theo được sử dụng trong chương trình đào tạo của BERT.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Bert là gì?
Chứng nhận là viết tắt của Đại diện Bộ mã hóa hai chiều từ Transformers. Đó là một mẫu máy tính đặc biệt giúp máy tính hiểu và xử lý ngôn ngữ của con người. Nó là một công cụ thông minh có thể đọc và hiểu văn bản như của chúng ta.
Điều khiến BERT trở nên đặc biệt là nó có thể hiểu nghĩa của các từ trong câu bằng cách nhìn vào các từ trước và sau chúng. Nó giống như đọc một câu và hiểu ý nghĩa của nó bằng cách xem xét tất cả các từ cùng nhau.

BERT được đào tạo bằng cách sử dụng văn bản từ sách, bài báo và trang web. Điều này giúp nó học các mẫu và kết nối giữa các từ. Vì vậy, khi chúng ta đưa ra một câu cho BERT, nó có thể tìm ra nghĩa và ngữ cảnh của từng từ dựa trên cách huấn luyện của nó.
Khả năng hiểu ngôn ngữ mạnh mẽ này của BERT được sử dụng theo nhiều cách khác nhau. Nó cũng có thể trợ giúp thực hiện các tác vụ như phân loại văn bản, hiểu tình cảm hoặc cảm xúc trong tin nhắn và trả lời các câu hỏi.
Bộ dữ liệu SST2
Liên kết tập dữ liệu: https://github.com/clairett/pytorch-sentiment-classification/tree/master/data/SST2
Trong bài viết này, chúng tôi sẽ sử dụng tập dữ liệu trên, bao gồm các câu được trích từ các bài đánh giá phim. Giá trị 1 đại diện cho nhãn tích cực và 0 đại diện cho nhãn tiêu cực cho mỗi câu.
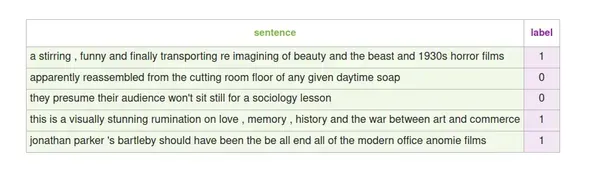
Bằng cách đào tạo mô hình trên tập dữ liệu này, chúng ta có thể dạy mô hình phân loại các câu mới là tích cực hoặc tiêu cực dựa trên các mẫu mà nó học được từ dữ liệu được gắn nhãn.
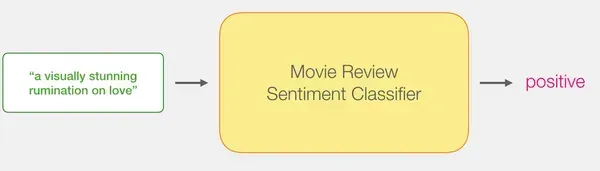
Mô hình: Phân loại cảm xúc câu
Chúng tôi mong muốn tạo ra một Phân tích tâm lý mô hình để phân loại câu là tích cực hay tiêu cực.
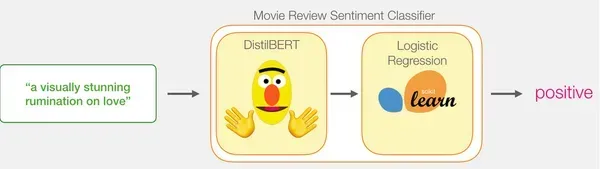
Bằng cách kết hợp sức mạnh của khả năng xử lý câu của DistilBERT với khả năng phân loại của hồi quy logistic, chúng tôi có thể xây dựng mô hình phân tích cảm tính hiệu quả và chính xác.
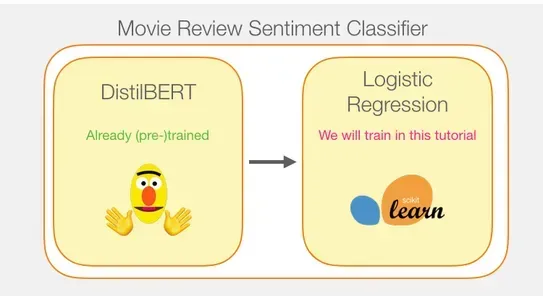
Tạo nội dung nhúng câu bằng DistilBERT: Sử dụng mô hình DistilBERT được đào tạo trước để tạo nội dung nhúng câu cho 2,000 câu.
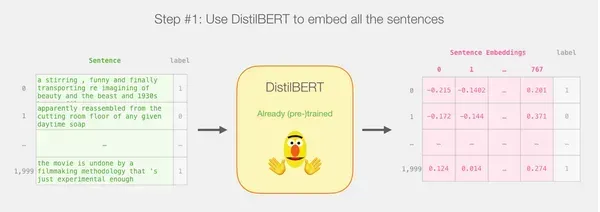
Những phần nhúng câu này nắm bắt thông tin quan trọng về ý nghĩa và ngữ cảnh của câu.
Thực hiện phân tách đào tạo/kiểm tra: Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra.
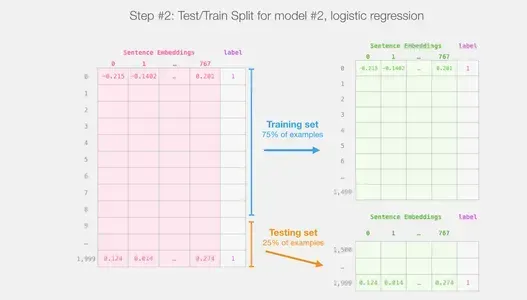
Sử dụng tập huấn luyện để huấn luyện mô hình hồi quy logistic, còn tập kiểm tra sẽ dùng để đánh giá.
Huấn luyện mô hình hồi quy logistic: Sử dụng tập huấn luyện để huấn luyện mô hình hồi quy logistic bằng scikit-learn.
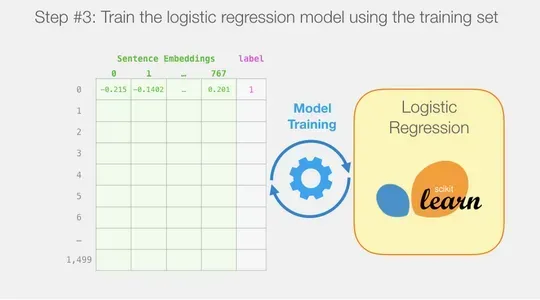
Mô hình hồi quy logistic học cách phân loại các câu là tích cực hoặc tiêu cực dựa trên các phần nhúng câu.
Bằng cách làm theo kế hoạch này, chúng tôi có thể tận dụng sức mạnh của DistilBERT để tạo ra các phần nhúng câu mang tính thông tin, sau đó huấn luyện mô hình hồi quy logistic để thực hiện phân loại cảm tính. Bước đánh giá cho phép chúng tôi đánh giá hiệu suất của mô hình trong việc dự đoán cảm xúc của các câu mới.
Làm thế nào một dự đoán duy nhất được tính toán?
Dưới đây là giải thích về cách một mô hình được đào tạo tính toán dự đoán của nó bằng cách sử dụng câu ví dụ “một suy ngẫm gây ấn tượng về tình yêu”:
Mã hóa: Mỗi từ trong cụm từ được chia thành các thành phần nhỏ hơn được gọi là mã thông báo. Trình mã thông báo còn chèn thêm các mã thông báo cụ thể như 'CLS' ở đầu và 'SEP' ở cuối.

Chuyển đổi mã thông báo sang ID: Sau đó, trình mã thông báo sẽ thay thế từng mã thông báo bằng ID tương ứng từ bảng nhúng. Bảng nhúng là một thành phần đi kèm với mô hình được đào tạo và ánh xạ các mã thông báo tới các biểu diễn số của chúng.
Hình dạng của đầu vào: Sau khi mã hóa và chuyển đổi, DistilBERT sẽ chuyển đổi câu đầu vào thành hình dạng thích hợp để xử lý. Nó thể hiện câu dưới dạng một chuỗi ID mã thông báo có thêm các mã thông báo duy nhất.

Lưu ý rằng bạn có thể thực hiện tất cả các bước này, bao gồm mã thông báo và chuyển đổi ID, bằng cách sử dụng một dòng mã với trình mã thông báo do thư viện cung cấp.
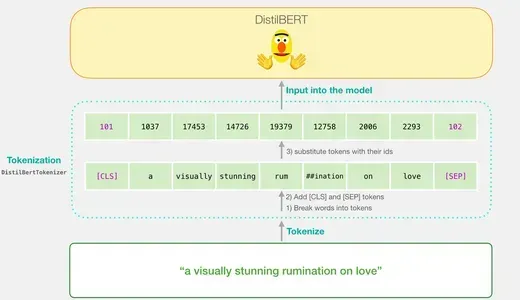
Chảy Qua Chưng CấtBERT
Thật vậy, việc truyền vectơ đầu vào qua DistilBERT tuân theo quy trình tương tự như với BERT. Đầu ra sẽ bao gồm một vectơ cho mỗi mã thông báo đầu vào, trong đó mỗi vectơ chứa 768 số (số float).
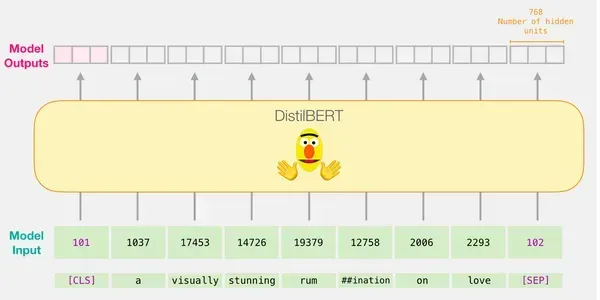
Trong trường hợp phân loại câu, chúng tôi chỉ tập trung vào vectơ đầu tiên tương ứng với mã thông báo [CLS]. Mã thông báo [CLS] được thiết kế để nắm bắt bối cảnh tổng thể của toàn bộ chuỗi, do đó, chỉ sử dụng vectơ đầu tiên (mã thông báo [CLS]) để phân loại câu trong các mô hình như BERT sẽ hoạt động. Vị trí của mã thông báo này, chức năng của nó trong quá trình đào tạo trước và kỹ thuật tổng hợp đều góp phần vào khả năng mã hóa thông tin quan trọng cho các nhiệm vụ phân loại. Hơn nữa, việc chỉ sử dụng mã thông báo [CLS] giúp giảm độ phức tạp tính toán và yêu cầu bộ nhớ, đồng thời cho phép mô hình đưa ra dự đoán chính xác cho nhiều nhiệm vụ phân loại. Vectơ này được truyền làm đầu vào cho mô hình hồi quy logistic.
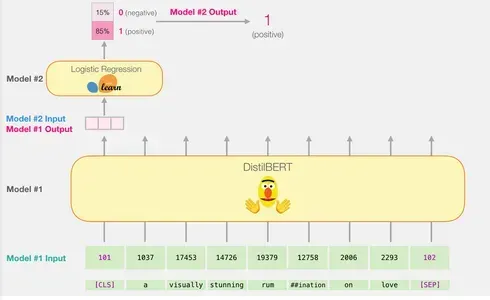
Vai trò của mô hình hồi quy logistic là phân loại vectơ này dựa trên những gì nó học được trong giai đoạn huấn luyện. Chúng ta có thể hình dung cách tính toán dự đoán như sau:
- Mô hình hồi quy logistic lấy vectơ đầu vào (được liên kết với mã thông báo [CLS]) làm đầu vào.
- Nó áp dụng một tập hợp các trọng số đã học cho mỗi số trong số 768 số trong vectơ.
- Các số có trọng số được tính tổng và một thuật ngữ sai lệch bổ sung được thêm vào.
Cuối cùng, kết quả tổng hợp được chuyển qua hàm sigmoid để tạo ra điểm dự đoán.
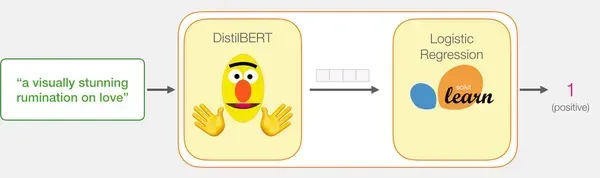
Giai đoạn huấn luyện của mô hình hồi quy logistic và mã hoàn chỉnh cho toàn bộ quá trình sẽ được thảo luận trong phần tiếp theo.
Triển khai từ đầu
Phần này sẽ nêu bật đoạn mã để huấn luyện mô hình phân loại câu này.
Tải thư viện
Hãy bắt đầu bằng cách nhập các công cụ giao dịch. Chúng ta có thể sử dụng df.head() để xem năm hàng đầu tiên của khung dữ liệu để xem dữ liệu trông như thế nào.

Nhập mô hình DistilBERT và mã thông báo được đào tạo trước
Chúng tôi sẽ mã hóa tập dữ liệu nhưng có một chút khác biệt so với ví dụ trước. Thay vì mã hóa và xử lý từng câu một, chúng tôi sẽ xử lý tất cả các câu cùng nhau dưới dạng một đợt.
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased') ## Want BERT instead of distilBERT? ##Uncomment the following line:
#model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased') # Load pre-trained model/tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
Ví dụ: giả sử chúng tôi có tập dữ liệu về các bài đánh giá phim và chúng tôi muốn mã hóa và xử lý 2,000 bài đánh giá cùng một lúc. Chúng tôi sẽ sử dụng mã thông báo có tên là DistilBertTokenizer, một công cụ được thiết kế đặc biệt để mã hóa văn bản bằng mô hình DistilBERT.
Trình mã thông báo lấy toàn bộ loạt câu và thực hiện mã thông báo, bao gồm việc chia các câu thành các đơn vị nhỏ hơn gọi là mã thông báo. Nó cũng thêm các mã thông báo đặc biệt, như [CLS] ở đầu và [SEP] ở cuối mỗi câu.
Mã thông báo
Kết quả là mỗi câu sẽ trở thành một danh sách id. Tập dữ liệu bao gồm một danh sách các danh sách (hoặc Chuỗi/DataFrame của gấu trúc). Các cụm từ ngắn hơn phải được đệm bằng mã thông báo id 0 để làm cho tất cả các vectơ có cùng độ dài. Bây giờ chúng ta có một ma trận/tensor có thể được cung cấp cho BERT sau phần đệm:
tokenized = df[0].apply((lambda x: tokenizer. encode(x, add_special_tokens=True)))

Xử lý bằng DistilBERT
Ma trận mã thông báo đệm hiện được chuyển thành một tenxơ đầu vào mà chúng tôi gửi tới DistilBERT.
input_ids = torch.tensor(np.array(padded)) with torch.no_grad(): last_hidden_states = model(input_ids)
Kết quả đầu ra của DistilBERT được lưu trữ trong Last_hidden_states sau khi hoàn thành bước này. Vì chúng tôi chỉ xem xét 2000 trường hợp nên trong kịch bản của chúng tôi, con số này sẽ là 2000 (số lượng mã thông báo trong chuỗi dài nhất từ 2000 ví dụ) và 768 (số lượng đơn vị ẩn trong mô hình DistilBERT).
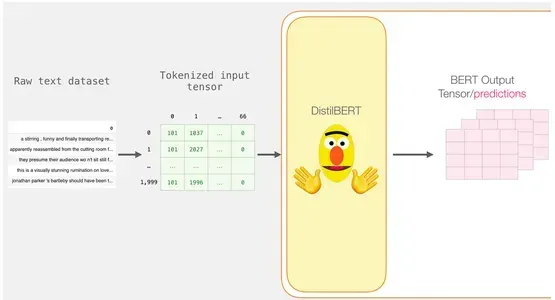
Giải nén Tensor đầu ra BERT
Hãy kiểm tra kích thước của tenxơ đầu ra 3D và trích xuất nó. Giả sử bạn có biến Last_hidden_states chứa tensor đầu ra DistilBERT.
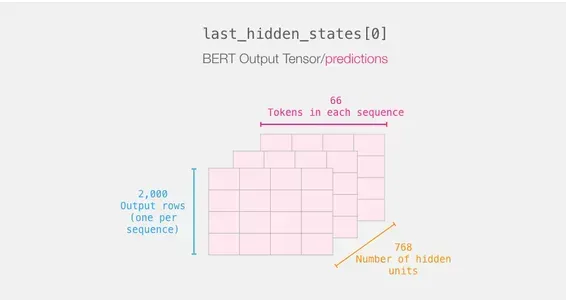
Tóm tắt hành trình của một câu
Mỗi hàng có một văn bản từ tập dữ liệu của chúng tôi được đính kèm. Để xem lại quy trình xử lý của câu đầu tiên, hãy hình dung nó như sau:

Cắt phần quan trọng
Chúng tôi chỉ chọn phần khối lập phương đó để phân loại câu vì chúng tôi chỉ quan tâm đến kết quả của BERT cho mã thông báo [CLS].
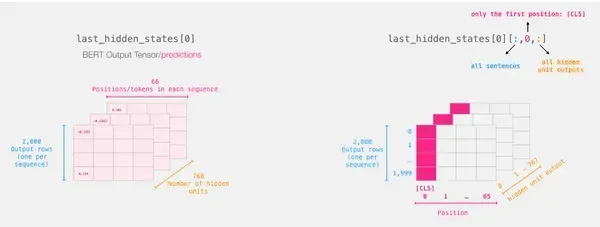
Để có được tensor 2d mà chúng ta quan tâm từ tensor 3d đó, chúng ta cắt nó như sau:
# Slice the output for the first position for all the sequences, take all hidden unit outputs
features = last_hidden_states[0][:,0,:].numpy()Cuối cùng, tính năng này là một mảng dạng khối 2 chiều bao gồm tất cả các phần nhúng câu của các câu từ tập dữ liệu của chúng tôi.
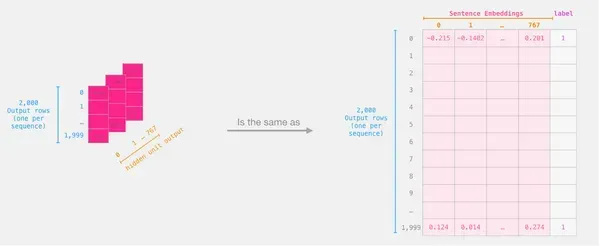
Áp dụng hồi quy logistic
Bây giờ chúng tôi có tập dữ liệu cần thiết để huấn luyện mô hình hồi quy logistic khi chúng tôi có đầu ra BERT. 768 cột trong tập dữ liệu đầu tiên của chúng tôi bao gồm các đặc điểm và nhãn.

Chúng tôi có thể xác định và huấn luyện mô hình Hồi quy logistic của mình trên tập dữ liệu sau khi thực hiện phân tách đào tạo/kiểm tra thông thường của học máy.
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
Sử dụng điều này, tập dữ liệu được chia thành các tập huấn luyện và kiểm tra:
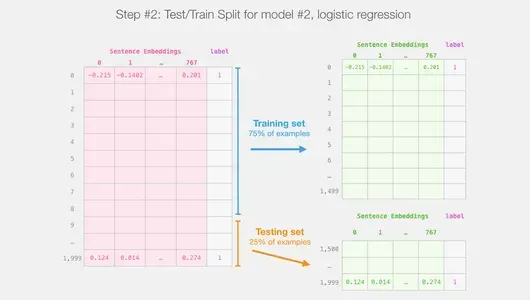
Mô hình hồi quy logistic sau đó được đào tạo bằng cách sử dụng tập huấn luyện.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
Sau khi mô hình đã được huấn luyện, chúng ta có thể so sánh kết quả của nó với tập kiểm tra:
lr_clf.score(test_features, test_labels)Điều này mang lại cho mô hình độ chính xác khoảng 81%.
Kết luận
Tóm lại, BERT là một mô hình ngôn ngữ mạnh mẽ giúp máy tính hiểu ngôn ngữ con người tốt hơn. Bằng cách xem xét ngữ cảnh của từ và đào tạo về lượng lớn dữ liệu văn bản, BERT có thể nắm bắt được ý nghĩa và cải thiện khả năng hiểu ngôn ngữ.
Chìa khóa chính
- BERT là mô hình ngôn ngữ giúp máy tính hiểu ngôn ngữ con người tốt hơn.
- Nó xem xét ngữ cảnh của các từ trong câu, giúp nó hiểu ý nghĩa một cách thông minh hơn.
- BERT được đào tạo trên nhiều dữ liệu văn bản để tìm hiểu các mẫu ngôn ngữ.
- Nó có thể được tinh chỉnh cho các tác vụ cụ thể như phân loại văn bản hoặc trả lời câu hỏi.
- BERT cải thiện kết quả tìm kiếm và hiểu ngôn ngữ trong ứng dụng.
- Nó xử lý những từ không quen thuộc bằng cách chia chúng thành những phần nhỏ hơn.
- TensorFlow và PyTorch được sử dụng với BERT.
BERT đã cải tiến các ứng dụng như công cụ tìm kiếm và phân loại văn bản, khiến chúng thông minh hơn và hữu ích hơn. Nhìn chung, BERT là một bước quan trọng trong việc giúp máy tính hiểu ngôn ngữ con người hiệu quả hơn.
Những câu hỏi thường gặp
Câu trả lời 1: BERT có thể được sử dụng cho nhiều nhiệm vụ liên quan đến ngôn ngữ, bao gồm phân loại văn bản, hiểu tình cảm hoặc cảm xúc, trả lời câu hỏi và nhận dạng các thực thể được đặt tên.
Câu trả lời 2: BERT được sử dụng trong Google Tìm kiếm để hiểu rõ hơn các truy vấn của người dùng và cung cấp kết quả tìm kiếm phù hợp hơn. Nó cũng được sử dụng trong các ứng dụng khác để nâng cao khả năng hiểu ngôn ngữ và xử lý ngôn ngữ tự nhiên.
Câu trả lời 3: Quá trình mã hóa bao gồm việc chia các câu thành các đơn vị nhỏ hơn gọi là mã thông báo. Mỗi mã thông báo sau đó được chuyển đổi thành ID số tương ứng bằng bảng nhúng. Các mã thông báo đặc biệt như [CLS] (bắt đầu) và [SEP] (kết thúc) cũng được thêm vào.
Câu trả lời 4: DistilBERT tạo ra các phần nhúng câu bằng cách xử lý các câu được mã hóa thông qua mô hình của nó. Việc nhúng tương ứng với mã thông báo [CLS] được sử dụng làm cách nhúng câu, nắm bắt ý nghĩa tổng thể của câu.
Câu trả lời 5: Hồi quy logistic được sử dụng để phân loại các phần nhúng câu do DistilBERT tạo ra theo cảm tính tích cực hoặc tiêu cực. Nó áp dụng các trọng số đã học cho các phần nhúng, tổng hợp chúng, thêm thuật ngữ sai lệch và chuyển kết quả qua hàm sigmoid để tạo ra điểm dự đoán.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/08/visual-bert-mastery/

