
Giới thiệu
Chào mừng đến với toàn diện của chúng tôi phân tích dữ liệu blog đi sâu vào thế giới của Netflix. Là một trong những nền tảng phát trực tuyến hàng đầu trên toàn cầu, Netflix đã cách mạng hóa cách chúng ta tiêu thụ nội dung giải trí. Với thư viện phim và chương trình truyền hình khổng lồ, nó mang đến vô số lựa chọn cho người xem trên khắp thế giới.
Phạm vi tiếp cận toàn cầu của Netflix
Netflix đã có sự tăng trưởng vượt bậc và mở rộng sự hiện diện của mình để trở thành thế lực thống trị trong ngành phát trực tuyến. Dưới đây là một số thống kê đáng chú ý thể hiện tác động toàn cầu của nó:
- Cơ sở người dùng: Đến đầu quý 2022 năm XNUMX, Netflix đã tích lũy được khoảng 222 triệu thuê bao quốc tế, trải rộng trên 190 quốc gia (không bao gồm Trung Quốc, Crimea, Bắc Triều Tiên, Nga và Syria). Những con số ấn tượng này nhấn mạnh sự chấp nhận và phổ biến rộng rãi của nền tảng đối với người xem trên toàn thế giới.
- Sự mở rộng quốc tế: Với tính khả dụng ở hơn 190 quốc gia, Netflix đã thiết lập thành công sự hiện diện toàn cầu. Công ty đã có những nỗ lực đáng kể để bản địa hóa nội dung của mình bằng cách cung cấp phụ đề và lồng tiếng bằng nhiều ngôn ngữ khác nhau, đảm bảo khả năng tiếp cận với nhiều đối tượng khác nhau.
Trong blog này, chúng tôi bắt đầu một hành trình thú vị để khám phá các mô hình, xu hướng và thông tin chi tiết hấp dẫn ẩn trong bối cảnh nội dung của Netflix. Tận dụng sức mạnh của Python và của mình phân tích dữ liệu thư viện, chúng tôi đi sâu vào bộ sưu tập khổng lồ các dịch vụ của Netflix để khám phá thông tin có giá trị giúp làm sáng tỏ nội dung bổ sung, phân bổ thời lượng, mối tương quan giữa các thể loại và thậm chí cả những từ được sử dụng phổ biến nhất trong tiêu đề và mô tả.
Thông qua các đoạn mã chi tiết và hình dung, chúng tôi bóc tách các lớp trong hệ sinh thái nội dung của Netflix để cung cấp góc nhìn mới về cách nền tảng này đã phát triển. Bằng cách phân tích các mẫu phát hành, xu hướng theo mùa và sở thích của khán giả, chúng tôi mong muốn hiểu rõ hơn về động lực nội dung trong thế giới rộng lớn của Netflix.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Chuẩn bị dữ liệu
Dữ liệu được sử dụng trong nghiên cứu điển hình này được lấy từ Kaggle, một nền tảng phổ biến dành cho những người đam mê khoa học dữ liệu và máy học. Bộ dữ liệu, có tiêu đề “Phim và chương trình truyền hình Netflix,” được cung cấp công khai trên Kaggle và cung cấp thông tin có giá trị về các bộ phim và chương trình truyền hình trên nền tảng phát trực tuyến Netflix.
Bộ dữ liệu bao gồm một định dạng bảng chứa nhiều cột khác nhau mô tả các khía cạnh khác nhau của từng bộ phim hoặc chương trình truyền hình. Đây là bảng tóm tắt các cột và mô tả của chúng:
| Tên cột dọc | Mô tả |
|---|---|
| show_id | ID duy nhất cho mọi Phim/Chương trình truyền hình |
| kiểu | Mã định danh – Phim hoặc Chương trình truyền hình |
| tiêu đề | Tên phim/chương trình truyền hình |
| Giám đốc | Đạo diễn phim |
| đúc | Diễn viên tham gia Movie/Show |
| đất nước | Quốc gia sản xuất Phim/Chương trình |
| ngày_đã thêm | Ngày nó được thêm vào Netflix |
| năm phát hành | Năm phát hành thực tế của Phim/Chương trình |
| giá | Xếp hạng truyền hình của Phim / Chương trình |
| thời gian | Tổng thời lượng – tính bằng phút hoặc số mùa |
Trong phần này, chúng tôi sẽ thực hiện các tác vụ chuẩn bị dữ liệu trên bộ dữ liệu Netflix để đảm bảo tính sạch sẽ và phù hợp để phân tích. Chúng tôi sẽ xử lý các giá trị bị thiếu và trùng lặp, đồng thời thực hiện chuyển đổi loại dữ liệu nếu cần. Hãy đi sâu vào mã và khám phá từng bước.
Nhập thư viện
Để bắt đầu, chúng tôi nhập các thư viện cần thiết để phân tích và trực quan hóa dữ liệu. Các thư viện này bao gồm gấu trúc, numpy và matplotlib. pyplot và seaborn. Chúng cung cấp các chức năng và công cụ cần thiết để thao tác và trực quan hóa dữ liệu một cách hiệu quả.
# Importing necessary libraries for data analysis and visualization
import pandas as pd # pandas for data manipulation and analysis
import numpy as np # numpy for numerical operations
import matplotlib.pyplot as plt # matplotlib for data visualization
import seaborn as sns # seaborn for enhanced data visualizationĐang tải tập dữ liệu
Tiếp theo, chúng tôi tải tập dữ liệu Netflix bằng hàm pd.read_csv(). Tập dữ liệu được lưu trữ trong tệp 'netflix.csv'. Hãy xem năm bản ghi đầu tiên của tập dữ liệu để hiểu cấu trúc của nó.
# Loading the dataset from a CSV file
df = pd.read_csv('netflix.csv') # Displaying the first few rows of the dataset
df.head()Thống kê mô tả
Điều quan trọng là phải hiểu các đặc điểm tổng thể của bộ dữ liệu thông qua thống kê mô tả. Chúng ta có thể hiểu sâu hơn về các thuộc tính số như số lượng, giá trị trung bình, độ lệch chuẩn, tối thiểu, tối đa và phần tư.
# Computing descriptive statistics for the dataset
df.describe()Tóm tắt ngắn gọn
Để có được một bản tóm tắt ngắn gọn về tập dữ liệu, chúng tôi sử dụng hàm df.info(). Nó cung cấp thông tin về số lượng giá trị khác null và kiểu dữ liệu của mỗi cột. Bản tóm tắt này giúp xác định các giá trị còn thiếu và các vấn đề tiềm ẩn với các loại dữ liệu.
# Obtaining information about the dataset
df.info()Xử lý các giá trị bị thiếu
Thiếu giá trị có thể cản trở phân tích chính xác. Tập dữ liệu này khám phá các giá trị còn thiếu trong mỗi cột bằng cách sử dụng df. isnull().sum(). Mục tiêu của chúng tôi là xác định các cột có giá trị bị thiếu và xác định tỷ lệ phần trăm dữ liệu bị thiếu trong mỗi cột.
# Checking for missing values in the dataset
df.isnull().sum()Để xử lý các giá trị bị thiếu, chúng tôi sử dụng các chiến lược khác nhau cho các cột khác nhau. Hãy đi qua từng bước:
Trùng lặp
Các bản sao có thể làm sai lệch kết quả phân tích, vì vậy điều cần thiết là phải giải quyết chúng. Chúng tôi xác định và xóa các bản ghi trùng lặp bằng cách sử dụng df.duplicated().sum().
# Checking for duplicate rows in the dataset
df.duplicated().sum()Xử lý các giá trị bị thiếu trong các cột cụ thể
Đối với các cột "đạo diễn" và "truyền", chúng tôi thay thế các giá trị bị thiếu bằng "Không có dữ liệu" để duy trì tính toàn vẹn của dữ liệu và tránh mọi sai lệch trong phân tích.
# Replacing missing values in the 'director' column with 'No Data'
df['director'].replace(np.nan, 'No Data', inplace=True) # Replacing missing values in the 'cast' column with 'No Data'
df['cast'].replace(np.nan, 'No Data', inplace=True)Trong cột "quốc gia", chúng tôi điền các giá trị còn thiếu bằng chế độ (giá trị xảy ra thường xuyên nhất) để đảm bảo tính nhất quán và giảm thiểu mất dữ liệu.
# Filling missing values in the 'country' column with the mode value
df['country'] = df['country'].fillna(df['country'].mode()[0])Đối với cột "xếp hạng", chúng tôi điền các giá trị còn thiếu dựa trên "loại" của chương trình. Chúng tôi chỉ định riêng chế độ 'xếp hạng' cho phim và chương trình truyền hình.
# Finding the mode rating for movies and TV shows
movie_rating = df.loc[df['type'] == 'Movie', 'rating'].mode()[0]
tv_rating = df.loc[df['type'] == 'TV Show', 'rating'].mode()[0] # Filling missing rating values based on the type of content
df['rating'] = df.apply(lambda x: movie_rating if x['type'] == 'Movie' and pd.isna(x['rating']) else tv_rating if x['type'] == 'TV Show' and pd.isna(x['rating']) else x['rating'], axis=1)Đối với cột "thời lượng", chúng tôi điền các giá trị còn thiếu dựa trên "loại" của chương trình. Chúng tôi chỉ định riêng chế độ 'thời lượng' cho phim và chương trình truyền hình.
# Finding the mode duration for movies and TV shows
movie_duration_mode = df.loc[df['type'] == 'Movie', 'duration'].mode()[0]
tv_duration_mode = df.loc[df['type'] == 'TV Show', 'duration'].mode()[0] # Filling missing duration values based on the type of content
df['duration'] = df.apply(lambda x: movie_duration_mode if x['type'] == 'Movie' and pd.isna(x['duration']) else tv_duration_mode if x['type'] == 'TV Show' and pd.isna(x['duration']) else x['duration'], axis=1)Giảm các giá trị còn thiếu
Sau khi xử lý các giá trị bị thiếu trong các cột cụ thể, chúng tôi loại bỏ mọi hàng còn lại có giá trị bị thiếu để đảm bảo tập dữ liệu rõ ràng cho việc phân tích.
# Dropping rows with missing values
df.dropna(inplace=True)Xử lý ngày
Chúng tôi chuyển đổi cột 'date_added' sang định dạng ngày giờ bằng cách sử dụng pd.to_datetime() để cho phép phân tích thêm dựa trên các thuộc tính liên quan đến ngày.
# Converting the 'date_added' column to datetime format
df["date_added"] = pd.to_datetime(df['date_added'])Chuyển đổi dữ liệu bổ sung
Chúng tôi trích xuất các thuộc tính bổ sung từ cột 'date_added' để nâng cao khả năng phân tích của mình. Chúng tôi xóa các giá trị tháng và năm để phân tích xu hướng dựa trên các khía cạnh thời gian này.
# Extracting month, month name, and year from the 'date_added' column
df['month_added'] = df['date_added'].dt.month
df['month_name_added'] = df['date_added'].dt.month_name()
df['year_added'] = df['date_added'].dt.yearChuyển đổi dữ liệu: Diễn viên, Quốc gia, Được niêm yết và Giám đốc
Để phân tích các thuộc tính phân loại hiệu quả hơn, chúng tôi chuyển đổi chúng thành các khung dữ liệu riêng biệt, cho phép khám phá và phân tích nhàn nhã hơn.
Đối với các cột 'cast', 'country', 'listed_in' và 'director', chúng tôi phân chia các giá trị dựa trên dấu phân cách dấu phẩy và tạo các hàng riêng biệt cho từng giá trị. Sự chuyển đổi này cho phép chúng tôi phân tích dữ liệu ở cấp độ chi tiết hơn.
# Splitting and expanding the 'cast' column
df_cast = df['cast'].str.split(',', expand=True).stack()
df_cast = df_cast.reset_index(level=1, drop=True).to_frame('cast')
df_cast['show_id'] = df['show_id'] # Splitting and expanding the 'country' column
df_country = df['country'].str.split(',', expand=True).stack()
df_country = df_country.reset_index(level=1, drop=True).to_frame('country')
df_country['show_id'] = df['show_id'] # Splitting and expanding the 'listed_in' column
df_listed_in = df['listed_in'].str.split(',', expand=True).stack()
df_listed_in = df_listed_in.reset_index(level=1, drop=True).to_frame('listed_in')
df_listed_in['show_id'] = df['show_id'] # Splitting and expanding the 'director' column
df_director = df['director'].str.split(',', expand=True).stack()
df_director = df_director.reset_index(level=1, drop=True).to_frame('director')
df_director['show_id'] = df['show_id']Sau khi hoàn thành các bước chuẩn bị dữ liệu này, chúng tôi có một bộ dữ liệu sạch và đã chuyển đổi sẵn sàng để phân tích thêm. Những thao tác dữ liệu ban đầu này đặt nền tảng cho việc khám phá bộ dữ liệu Netflix và khám phá thông tin chuyên sâu về các chiến lược dựa trên dữ liệu của nền tảng phát trực tuyến.
Phân tích dữ liệu thăm dò
Phân phối các loại nội dung
Để xác định phân phối nội dung trong thư viện Netflix, chúng tôi có thể tính phần trăm phân phối của các loại nội dung (phim và chương trình truyền hình) bằng cách sử dụng mã sau:
# Calculate the percentage distribution of content types
x = df.groupby(['type'])['type'].count()
y = len(df)
r = ((x/y) * 100).round(2) # Create a DataFrame to store the percentage distribution
mf_ratio = pd.DataFrame(r)
mf_ratio.rename({'type': '%'}, axis=1, inplace=True) # Plot the 3D-effect pie chart
plt.figure(figsize=(12, 8))
colors = ['#b20710', '#221f1f']
explode = (0.1, 0)
plt.pie(mf_ratio['%'], labels=mf_ratio.index, autopct='%1.1f%%', colors=colors, explode=explode, shadow=True, startangle=90, textprops={'color': 'white'}) plt.legend(loc='upper right')
plt.title('Distribution of Content Types')
plt.show()
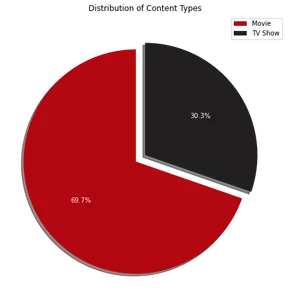
Biểu đồ hình tròn cho thấy khoảng 70% nội dung trên Netflix bao gồm phim, trong khi 30% còn lại là chương trình truyền hình. Tiếp theo, để xác định 10 quốc gia hàng đầu nơi Netflix phổ biến, chúng ta có thể sử dụng đoạn mã sau:
10 quốc gia hàng đầu nơi Netflix phổ biến
Tiếp theo, để xác định 10 quốc gia hàng đầu nơi Netflix phổ biến, chúng ta có thể sử dụng đoạn mã sau:
# Remove white spaces from 'country' column
df_country['country'] = df_country['country'].str.rstrip() # Find value counts
country_counts = df_country['country'].value_counts() # Select the top 10 countries
top_10_countries = country_counts.head(10) # Plot the top 10 countries
plt.figure(figsize=(16, 10))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_countries) - 1)
bar_plot = sns.barplot(x=top_10_countries.index, y=top_10_countries.values, palette=colors) plt.xlabel('Country')
plt.ylabel('Number of Titles')
plt.title('Top 10 Countries Where Netflix is Popular') # Add count values on top of each bar
for index, value in enumerate(top_10_countries.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()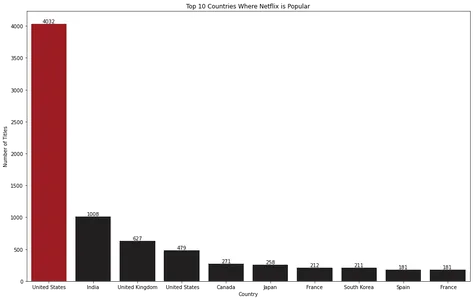
Hình ảnh biểu đồ thanh cho thấy Hoa Kỳ là quốc gia hàng đầu nơi Netflix phổ biến.
10 diễn viên hàng đầu theo số lượng phim/chương trình truyền hình
Để xác định 10 diễn viên hàng đầu có số lần xuất hiện nhiều nhất trong các bộ phim và chương trình truyền hình, bạn có thể sử dụng mã sau:
# Count the occurrences of each actor
cast_counts = df_cast['cast'].value_counts()[1:] # Select the top 10 actors
top_10_cast = cast_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_cast) - 1)
bar_plot = sns.barplot(x=top_10_cast.index, y=top_10_cast.values, palette=colors) plt.xlabel('Actor')
plt.ylabel('Number of Appearances')
plt.title('Top 10 Actors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_cast.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()
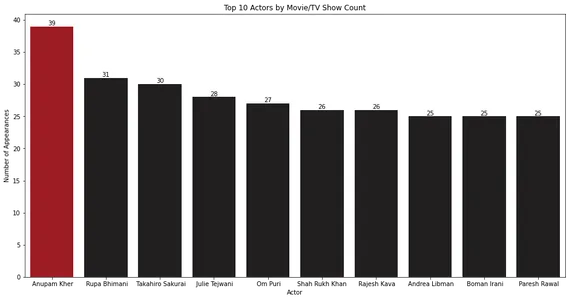
Biểu đồ thanh cho thấy Anupam Kher có tần suất xuất hiện nhiều nhất trong các bộ phim và chương trình truyền hình.
10 đạo diễn hàng đầu theo số lượng phim/chương trình truyền hình
Để xác định 10 đạo diễn hàng đầu đã chỉ đạo số lượng phim hoặc chương trình truyền hình cao nhất, bạn có thể sử dụng mã sau:
# Count the occurrences of each actor
director_counts = df_director['director'].value_counts()[1:] # Select the top 10 actors
top_10_directors = director_counts.head(10) plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(top_10_directors) - 1)
bar_plot = sns.barplot(x=top_10_directors.index, y=top_10_directors.values, palette=colors) plt.xlabel('Director')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Directors by Movie/TV Show Count') # Add count values on top of each bar
for index, value in enumerate(top_10_directors.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') plt.show()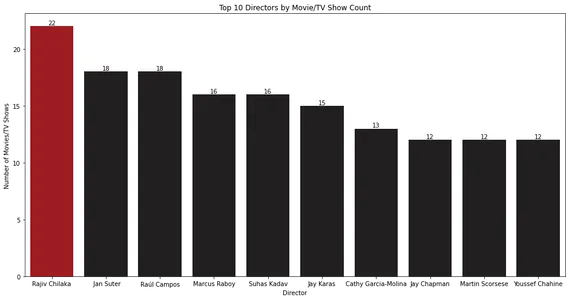
Biểu đồ thanh hiển thị 10 đạo diễn hàng đầu có nhiều phim hoặc chương trình truyền hình nhất. Rajiv Chilaka dường như đã chỉ đạo nhiều nội dung nhất trong thư viện Netflix.
10 hạng mục hàng đầu theo số lượng Phim/Chương trình truyền hình
Để phân tích việc phân phối nội dung trong các danh mục khác nhau, bạn có thể sử dụng đoạn mã sau:
df_listed_in['listed_in'] = df_listed_in['listed_in'].str.strip() # Count the occurrences of each actor
listed_in_counts = df_listed_in['listed_in'].value_counts() # Select the top 10 actors
top_10_listed_in = listed_in_counts.head(10) plt.figure(figsize=(12, 8))
bar_plot = sns.barplot(x=top_10_listed_in.index, y=top_10_listed_in.values, palette=colors) # Customize the plot
plt.xlabel('Category')
plt.ylabel('Number of Movies/TV Shows')
plt.title('Top 10 Categories by Movie/TV Show Count')
plt.xticks(rotation=45) # Add count values on top of each bar
for index, value in enumerate(top_10_listed_in.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Show the plot
plt.show()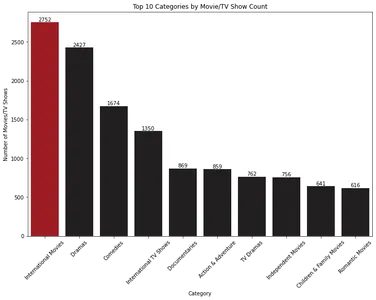
Biểu đồ thanh hiển thị 10 danh mục phim và chương trình truyền hình hàng đầu dựa trên số lượng của chúng. “Phim quốc tế” là hạng mục chiếm ưu thế nhất, tiếp theo là “Phim truyền hình”.
Phim và chương trình truyền hình được thêm theo thời gian
Để phân tích việc bổ sung phim và chương trình truyền hình theo thời gian, bạn có thể sử dụng mã sau:
# Filter the DataFrame to include only Movies and TV Shows
df_movies = df[df['type'] == 'Movie']
df_tv_shows = df[df['type'] == 'TV Show'] # Group the data by year and count the number of Movies and TV Shows # added in each year
movies_count = df_movies['year_added'].value_counts().sort_index()
tv_shows_count = df_tv_shows['year_added'].value_counts().sort_index() # Create a line chart to visualize the trends over time
plt.figure(figsize=(16, 8))
plt.plot(movies_count.index, movies_count.values, color='#b20710', label='Movies', linewidth=2)
plt.plot(tv_shows_count.index, tv_shows_count.values, color='#221f1f', label='TV Shows', linewidth=2) # Fill the area under the line charts
plt.fill_between(movies_count.index, movies_count.values, color='#b20710')
plt.fill_between(tv_shows_count.index, tv_shows_count.values, color='#221f1f') # Customize the plot
plt.xlabel('Year')
plt.ylabel('Count')
plt.title('Movies & TV Shows Added Over Time')
plt.legend() # Show the plot
plt.show()
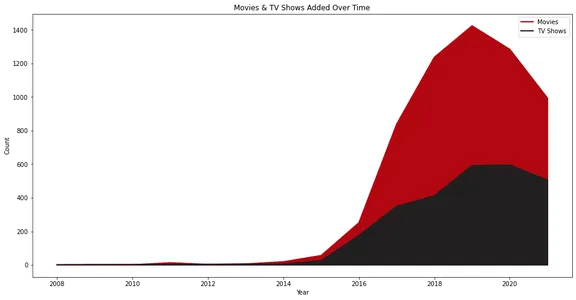
Biểu đồ đường minh họa số lượng phim và chương trình truyền hình được thêm vào Netflix theo thời gian. Nó thể hiện trực quan sự phát triển và xu hướng bổ sung nội dung, với các dòng riêng biệt cho phim và chương trình truyền hình.
Netflix đã chứng kiến sự tăng trưởng thực sự của mình bắt đầu từ năm 2015 và chúng ta có thể thấy nó đã thêm nhiều Phim hơn là Chương trình truyền hình trong những năm qua.
Ngoài ra, điều thú vị là việc bổ sung nội dung đã giảm vào năm 2020. Điều này có thể là do tình hình đại dịch.
Tiếp theo, chúng tôi khám phá việc phân phối nội dung bổ sung qua các tháng khác nhau. Phân tích này giúp chúng tôi xác định các mẫu và hiểu thời điểm Netflix giới thiệu nội dung mới.
Nội dung được thêm vào theo tháng
Để điều tra vấn đề này, chúng tôi trích xuất tháng từ cột 'date_added' và đếm số lần xuất hiện của mỗi tháng. Trực quan hóa dữ liệu này dưới dạng biểu đồ thanh cho phép chúng tôi nhanh chóng xác định các tháng có nội dung bổ sung cao nhất.
# Extract the month from the 'date_added' column
df['month_added'] = pd.to_datetime(df['date_added']).dt.month_name() # Define the order of the months
month_order = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December'] # Count the number of shows added in each month
monthly_counts = df['month_added'].value_counts().loc[month_order] # Determine the maximum count
max_count = monthly_counts.max() # Set the color for the highest bar and the rest of the bars
colors = ['#b20710' if count == max_count else '#221f1f' for count in monthly_counts] # Create the bar chart
plt.figure(figsize=(16, 8))
bar_plot = sns.barplot(x=monthly_counts.index, y=monthly_counts.values, palette=colors) # Customize the plot
plt.xlabel('Month')
plt.ylabel('Count')
plt.title('Content Added by Month') # Add count values on top of each bar
for index, value in enumerate(monthly_counts.values): bar_plot.text(index, value, str(value), ha='center', va='bottom') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()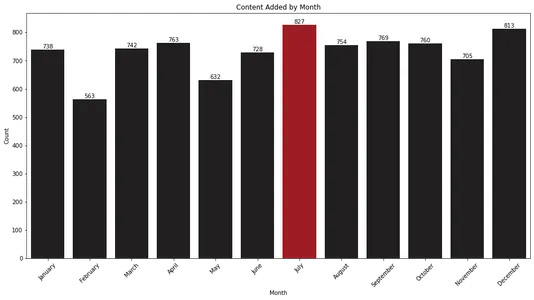
Biểu đồ thanh cho thấy tháng XNUMX và tháng XNUMX là những tháng Netflix bổ sung nhiều nội dung nhất vào thư viện của mình. Thông tin này có thể có giá trị đối với những người xem muốn đón xem các bản phát hành mới trong những tháng này.
Một khía cạnh quan trọng khác trong phân tích nội dung của Netflix là hiểu được sự phân bổ xếp hạng. Bằng cách kiểm tra số lượng của từng danh mục xếp hạng, chúng tôi có thể xác định loại nội dung phổ biến nhất trên nền tảng.
Phân phối xếp hạng
Chúng tôi bắt đầu bằng cách tính toán số lần xuất hiện của từng loại xếp hạng và trực quan hóa chúng bằng biểu đồ thanh. Hình ảnh trực quan này cung cấp một cái nhìn tổng quan rõ ràng về phân phối xếp hạng.
# Count the occurrences of each rating
rating_counts = df['rating'].value_counts() # Create a bar chart to visualize the ratings
plt.figure(figsize=(16, 8))
colors = ['#b20710'] + ['#221f1f'] * (len(rating_counts) - 1)
sns.barplot(x=rating_counts.index, y=rating_counts.values, palette=colors) # Customize the plot
plt.xlabel('Rating')
plt.ylabel('Count')
plt.title('Distribution of Ratings') # Rotate x-axis labels for better readability
plt.xticks(rotation=45) # Show the plot
plt.show()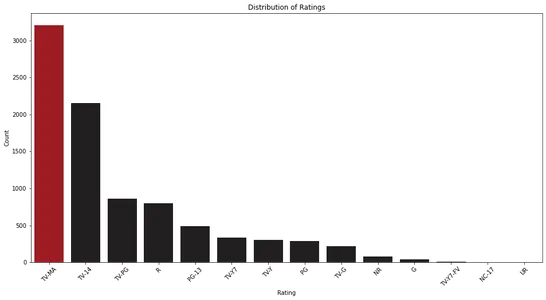
Khi phân tích biểu đồ thanh, chúng ta có thể quan sát sự phân bổ xếp hạng trên Netflix. Nó giúp chúng tôi xác định các danh mục xếp hạng phổ biến nhất và tần suất tương đối của chúng.
Bản đồ nhiệt tương quan thể loại
Thể loại đóng một vai trò quan trọng trong việc phân loại và sắp xếp nội dung trên Netflix. Phân tích mối tương quan giữa các thể loại có thể tiết lộ mối quan hệ thú vị giữa các loại nội dung khác nhau.
Chúng tôi tạo DataFrame dữ liệu thể loại để điều tra mối tương quan giữa thể loại và điền vào nó bằng số không. Bằng cách lặp qua từng hàng trong DataFrame gốc, chúng tôi cập nhật DataFrame dữ liệu thể loại dựa trên các thể loại được liệt kê. Sau đó, chúng tôi tạo một ma trận tương quan bằng cách sử dụng dữ liệu thể loại này và trực quan hóa nó dưới dạng bản đồ nhiệt.
# Extracting unique genres from the 'listed_in' column
genres = df['listed_in'].str.split(', ', expand=True).stack().unique() # Create a new DataFrame to store the genre data
genre_data = pd.DataFrame(index=genres, columns=genres, dtype=float) # Fill the genre data DataFrame with zeros
genre_data.fillna(0, inplace=True) # Iterate over each row in the original DataFrame and update the genre data DataFrame
for _, row in df.iterrows(): listed_in = row['listed_in'].split(', ') for genre1 in listed_in: for genre2 in listed_in: genre_data.at[genre1, genre2] += 1 # Create a correlation matrix using the genre data
correlation_matrix = genre_data.corr() # Create the heatmap
plt.figure(figsize=(20, 16))
sns.heatmap(correlation_matrix, annot=False, cmap='coolwarm') # Customize the plot
plt.title('Genre Correlation Heatmap')
plt.xticks(rotation=90)
plt.yticks(rotation=0) # Show the plot
plt.show()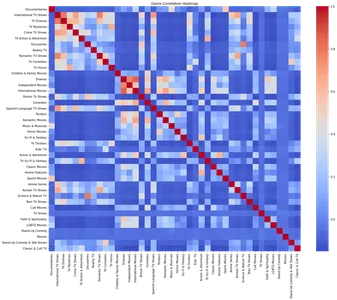
Bản đồ nhiệt thể hiện mối tương quan giữa các thể loại khác nhau. Bằng cách phân tích bản đồ nhiệt, chúng tôi có thể xác định mối tương quan tích cực mạnh mẽ giữa các thể loại cụ thể, chẳng hạn như Phim truyền hình và Chương trình truyền hình quốc tế, Chương trình truyền hình lãng mạn và Chương trình truyền hình quốc tế.
Phân phối thời lượng phim và số tập chương trình truyền hình
Việc hiểu thời lượng của phim và chương trình truyền hình cung cấp thông tin chi tiết về thời lượng của nội dung và giúp người xem lên kế hoạch cho thời gian xem của họ. Bằng cách kiểm tra sự phân bổ thời lượng phim và thời lượng chương trình truyền hình, chúng tôi có thể hiểu rõ hơn về nội dung có sẵn trên Netflix.
Để đạt được điều này, chúng tôi trích xuất thời lượng phim và số tập của chương trình truyền hình từ cột "thời lượng". Sau đó, chúng tôi vẽ biểu đồ biểu đồ và biểu đồ hộp để hình dung sự phân bổ thời lượng phim và thời lượng chương trình truyền hình.
# Extract the movie lengths and TV show episode counts
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Plot the histogram
plt.figure(figsize=(10, 6))
plt.hist(movie_lengths, bins=10, color='#b20710', label='Movies')
plt.hist(tv_show_episodes, bins=10, color='#221f1f', label='TV Shows') # Customize the plot
plt.xlabel('Duration/Episode Count')
plt.ylabel('Frequency')
plt.title('Distribution of Movie Lengths and TV Show Episode Counts')
plt.legend() # Show the plot
plt.show()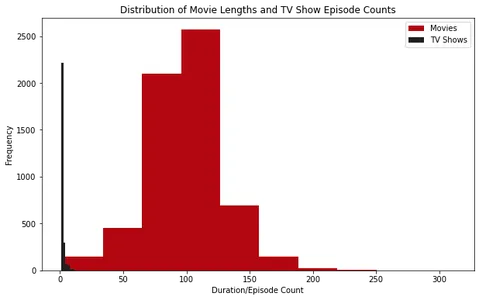
Phân tích biểu đồ, chúng ta có thể nhận thấy rằng hầu hết các bộ phim trên Netflix đều có thời lượng khoảng 100 phút. Mặt khác, hầu hết các chương trình truyền hình trên Netflix chỉ có một mùa.
Ngoài ra, bằng cách kiểm tra các ô hình hộp, chúng ta có thể thấy rằng các bộ phim dài hơn khoảng 2.5 giờ được coi là ngoại lệ. Đối với các chương trình truyền hình, việc tìm kiếm những chương trình có hơn bốn mùa là không phổ biến.
Xu hướng thời lượng phim/chương trình truyền hình qua các năm
Chúng ta có thể vẽ biểu đồ đường để hiểu thời lượng phim và số tập chương trình truyền hình đã phát triển như thế nào trong những năm qua. Xác định các mẫu hoặc sự thay đổi trong thời lượng nội dung bằng cách phân tích các xu hướng này.
Chúng tôi bắt đầu bằng cách trích xuất thời lượng phim và số tập chương trình truyền hình từ cột 'thời lượng'. Sau đó, chúng tôi tạo các biểu đồ đường để trực quan hóa những thay đổi về thời lượng phim và các tập chương trình truyền hình trong những năm qua.
import seaborn as sns
import matplotlib.pyplot as plt # Extract the movie lengths and TV show episodes from the 'duration' column
movie_lengths = df_movies['duration'].str.extract('(d+)', expand=False).astype(int)
tv_show_episodes = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Create line plots for movie lengths and TV show episodes
plt.figure(figsize=(16, 8)) plt.subplot(2, 1, 1)
sns.lineplot(data=df_movies, x='release_year', y=movie_lengths, color=colors[0])
plt.xlabel('Release Year')
plt.ylabel('Movie Length')
plt.title('Trend of Movie Lengths Over the Years') plt.subplot(2, 1, 2)
sns.lineplot(data=df_tv_shows, x='release_year', y=tv_show_episodes,color=colors[1])
plt.xlabel('Release Year')
plt.ylabel('TV Show Episodes')
plt.title('Trend of TV Show Episodes Over the Years') # Adjust the layout and spacing
plt.tight_layout() # Show the plots
plt.show()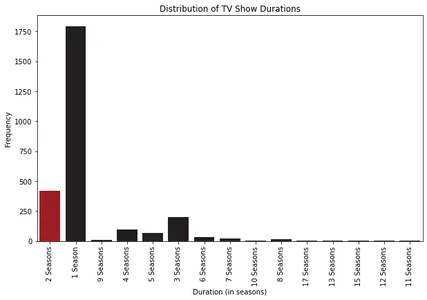
Phân tích các biểu đồ đường, chúng tôi quan sát các mẫu thú vị. Ta có thể thấy rằng thời lượng phim ban đầu tăng lên cho đến khoảng 1963-1964 rồi giảm dần, ổn định ở mức trung bình khoảng 100 phút. Điều này cho thấy sự thay đổi trong sở thích của khán giả theo thời gian.
Về các tập chương trình truyền hình, chúng tôi đã nhận thấy một xu hướng nhất quán kể từ đầu những năm 2000, khi hầu hết các chương trình truyền hình trên Netflix có từ một đến ba phần. Điều này cho thấy người xem ưa thích các định dạng sê-ri ngắn hơn hoặc định dạng sê-ri hạn chế.
Các từ phổ biến nhất trong tiêu đề và mô tả
Phân tích các từ phổ biến nhất được sử dụng trong tiêu đề và mô tả có thể cung cấp thông tin chi tiết về các chủ đề và nội dung tập trung vào Netflix. Chúng tôi có thể tạo các đám mây từ để khám phá các mẫu này dựa trên tiêu đề và mô tả nội dung của Netflix.
from wordcloud import WordCloud # Concatenate all the titles into a single string
text = ' '.join(df['title']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show() # Concatenate all the titles into a single string
text = ' '.join(df['description']) wordcloud = WordCloud(width = 800, height = 800, background_color ='white', min_font_size = 10).generate(text) # plot the WordCloud image
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad = 0) plt.show()
Kiểm tra đám mây từ cho các tiêu đề, chúng tôi nhận thấy rằng các thuật ngữ như “Tình yêu”, “Cô gái”, “Người đàn ông”, “Cuộc sống” và “Thế giới” thường được sử dụng, cho thấy sự hiện diện của sự lãng mạn, tuổi mới lớn và kịch tính. thể loại trong thư viện nội dung của Netflix.
Phân tích đám mây từ để mô tả, chúng tôi nhận thấy những từ chủ đạo như “cuộc sống”, “tìm kiếm” và “gia đình”, gợi ý các chủ đề về hành trình cá nhân, các mối quan hệ và động lực gia đình phổ biến trong nội dung của Netflix.
Phân phối thời lượng cho phim và chương trình truyền hình
Phân tích phân bổ thời lượng cho phim và chương trình truyền hình cho phép chúng tôi hiểu được thời lượng điển hình của nội dung có sẵn trên Netflix. Chúng tôi có thể tạo các biểu đồ hộp để trực quan hóa các bản phân phối này và xác định các giá trị ngoại lệ hoặc thời lượng tiêu chuẩn.
# Extracting and converting the duration for movies
df_movies['duration'] = df_movies['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for movie duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_movies, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for Movies')
plt.show() # Extracting and converting the duration for TV shows
df_tv_shows['duration'] = df_tv_shows['duration'].str.extract('(d+)', expand=False).astype(int) # Creating a boxplot for TV show duration
plt.figure(figsize=(10, 6))
sns.boxplot(data=df_tv_shows, x='type', y='duration')
plt.xlabel('Content Type')
plt.ylabel('Duration')
plt.title('Distribution of Duration for TV Shows')
plt.show()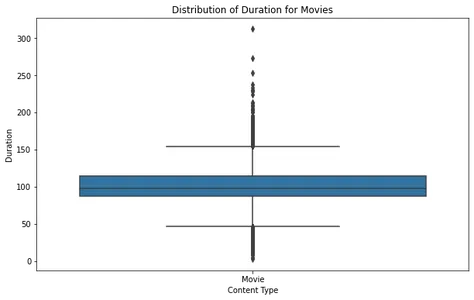
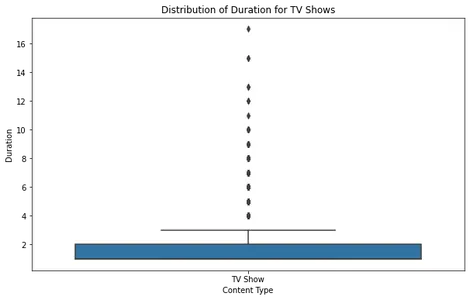
Phân tích cốt truyện của hộp phim, chúng ta có thể thấy rằng hầu hết các bộ phim đều nằm trong khoảng thời lượng hợp lý, với một số ngoại lệ vượt quá khoảng 2.5 giờ. Điều này cho thấy rằng hầu hết các bộ phim trên Netflix được thiết kế để phù hợp với thời gian xem tiêu chuẩn.
Đối với các chương trình truyền hình, cốt truyện cho thấy hầu hết các chương trình có từ một đến bốn phần, rất ít phần ngoại lệ có thời lượng dài hơn. Điều này phù hợp với các xu hướng trước đó, cho thấy Netflix tập trung vào các định dạng sê-ri ngắn hơn.
Kết luận
Với sự giúp đỡ của bài viết này, chúng tôi đã có thể tìm hiểu về-
- Số lượng: Phân tích của chúng tôi cho thấy Netflix đã thêm nhiều phim hơn chương trình truyền hình, phù hợp với kỳ vọng rằng phim sẽ thống trị thư viện nội dung của họ.
- Bổ sung nội dung: Tháng XNUMX nổi lên là tháng Netflix bổ sung nhiều nội dung nhất, theo sát là tháng XNUMX, cho thấy một cách tiếp cận chiến lược để phát hành nội dung.
- Tương quan thể loại: Mối liên hệ tích cực mạnh mẽ đã được quan sát giữa các thể loại khác nhau, chẳng hạn như phim truyền hình và chương trình truyền hình quốc tế, chương trình truyền hình lãng mạn và quốc tế cũng như phim điện ảnh và phim truyền hình độc lập. Những mối tương quan này cung cấp thông tin chi tiết về sở thích của người xem và các kết nối nội dung.
- Thời lượng phim: Việc phân tích thời lượng phim cho thấy mức cao nhất vào khoảng những năm 1960, sau đó là sự ổn định khoảng 100 phút, làm nổi bật xu hướng về thời lượng phim theo thời gian.
- Các tập của chương trình truyền hình: Hầu hết các chương trình truyền hình trên Netflix đều có một phần, cho thấy người xem ưa thích các loạt phim ngắn hơn.
- Chủ đề phổ biến: Những từ như tình yêu, cuộc sống, gia đình và phiêu lưu thường xuất hiện trong tiêu đề và phần mô tả, nắm bắt các chủ đề lặp đi lặp lại trong nội dung Netflix.
- Phân phối xếp hạng: Việc phân phối xếp hạng qua các năm cung cấp thông tin chi tiết về bối cảnh nội dung đang phát triển và mức độ tiếp nhận của khán giả.
- Thông tin chi tiết dựa trên dữ liệu: Hành trình phân tích dữ liệu của chúng tôi cho thấy sức mạnh của dữ liệu trong việc làm sáng tỏ những bí ẩn về bối cảnh nội dung của Netflix, cung cấp thông tin chi tiết có giá trị cho người xem và người tạo nội dung.
- Mức độ liên quan liên tục: Khi ngành phát trực tuyến phát triển, việc hiểu các mô hình và xu hướng này ngày càng trở nên cần thiết để điều hướng bối cảnh năng động của Netflix và thư viện rộng lớn của nó.
- Phát trực tuyến vui vẻ: Chúng tôi hy vọng blog này là một hành trình khai sáng và thú vị vào thế giới Netflix, đồng thời chúng tôi khuyến khích bạn khám phá những câu chuyện hấp dẫn trong các dịch vụ nội dung luôn thay đổi của nó. Hãy để dữ liệu hướng dẫn cuộc phiêu lưu phát trực tuyến của bạn!
Tài liệu và tài nguyên chính thức
Vui lòng tìm bên dưới các liên kết chính thức tới các thư viện được sử dụng trong phân tích của chúng tôi. Bạn có thể tham khảo các liên kết này để biết thêm thông tin về các phương pháp và chức năng được cung cấp bởi các thư viện này:
- Gấu trúc: https://pandas.pydata.org/
- NumPy: https://numpy.org/
- matplotlib: https://matplotlib.org/
- Khoa học viễn tưởng: https://scipy.org/
- sinh ra biển: https://seaborn.pydata.org/
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoAiStream. Thông minh dữ liệu Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Đúc kết tương lai với Adryenn Ashley. Truy cập Tại đây.
- Mua và bán cổ phần trong các công ty PRE-IPO với PREIPO®. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/06/netflix-case-study-eda-unveiling-data-driven-strategies-for-streaming/

