Điều chỉnh mô hình là quá trình thử nghiệm để tìm các tham số và cấu hình tối ưu cho mô hình máy học (ML) mang lại kết quả mong muốn tốt nhất có thể với tập dữ liệu xác thực. Tối ưu hóa một mục tiêu với chỉ số hiệu suất là cách tiếp cận phổ biến nhất để điều chỉnh các mô hình ML. Tuy nhiên, ngoài hiệu suất dự đoán, có thể có nhiều mục tiêu cần được xem xét cho các ứng dụng nhất định. Ví dụ,
- Công bằng – Mục đích ở đây là khuyến khích các mô hình giảm thiểu sai lệch trong kết quả mô hình giữa các nhóm phụ nhất định trong dữ liệu, đặc biệt là khi con người phải tuân theo các quyết định của thuật toán. Ví dụ, một hồ sơ vay vốn tín dụng không chỉ cần chính xác mà còn phải không thiên vị đối với các nhóm dân cư khác nhau.
- Thời gian suy luận - Mục đích ở đây là giảm thời gian suy luận trong quá trình gọi mô hình. Ví dụ: một hệ thống nhận dạng giọng nói không chỉ phải hiểu chính xác các phương ngữ khác nhau của cùng một ngôn ngữ mà còn phải hoạt động trong một giới hạn thời gian cụ thể được quy trình kinh doanh chấp nhận.
- Hiệu quả năng lượng – Mục đích ở đây là đào tạo các mô hình tiết kiệm năng lượng nhỏ hơn. Ví dụ: các mô hình mạng thần kinh được nén để sử dụng trên thiết bị di động và do đó giảm mức tiêu thụ năng lượng của chúng một cách tự nhiên bằng cách giảm số lượng FLOPS cần thiết để truyền qua mạng.
Các phương pháp tối ưu hóa đa mục tiêu thể hiện sự đánh đổi khác nhau giữa các số liệu mong muốn. Điều này có thể liên quan đến việc tìm mức tối thiểu toàn cầu của hàm mục tiêu tuân theo một tập hợp các ràng buộc đối với các số liệu khác nhau được thỏa mãn đồng thời.
Điều chỉnh mô hình tự động Amazon SageMaker (AMT) tìm phiên bản tốt nhất của mô hình bằng cách chạy nhiều công việc đào tạo SageMaker trên tập dữ liệu của bạn bằng cách sử dụng thuật toán và phạm vi siêu đường kính. Sau đó, nó chọn các giá trị siêu tham số dẫn đến một mô hình hoạt động tốt nhất, được đo bằng một số liệu (ví dụ: độ chính xác, auc, thu hồi) mà bạn xác định. Với tính năng điều chỉnh mô hình tự động của Amazon SageMaker, bạn có thể tìm thấy phiên bản tốt nhất cho mô hình của mình bằng cách chạy các tác vụ đào tạo trên tập dữ liệu của bạn với một số chiến lược tìm kiếm, chẳng hạn như Bayesian, Tìm kiếm ngẫu nhiên, Tìm kiếm theo lưới và Hyperband.
Làm rõ Amazon SageMaker có thể phát hiện xu hướng tiềm ẩn trong quá trình chuẩn bị dữ liệu, sau khi đào tạo mô hình và trong mô hình đã triển khai của bạn. Hiện tại, nó cung cấp 21 số liệu khác nhau để lựa chọn. Các số liệu này cũng có sẵn công khai với làm sáng tỏ gói python và kho lưu trữ github tại đây. Bạn có thể tìm hiểu thêm về cách đo lường độ lệch bằng các chỉ số từ Amazon SageMaker Clarify tại Tìm hiểu cách Amazon SageMaker Clarify giúp phát hiện thành kiến.
Trong blog này, chúng tôi hướng dẫn bạn cách tự động điều chỉnh mô hình ML với Amazon SageMaker AMT cho cả mục tiêu chính xác và công bằng bằng cách tạo một chỉ số kết hợp duy nhất. Chúng tôi chứng minh trường hợp sử dụng dịch vụ tài chính về dự đoán rủi ro tín dụng với chỉ số chính xác là Diện tích dưới đường cong (AUC) để đo lường hiệu suất và một số liệu thiên vị của Sự khác biệt về Tỷ lệ Tích cực trong Nhãn Dự đoán (DPPL) từ SageMaker Làm rõ để đo lường sự mất cân bằng trong dự đoán mô hình cho các nhóm nhân khẩu học khác nhau. Mã cho ví dụ này có sẵn trên GitHub.
Công bằng trong dự báo rủi ro tín dụng
Ngành cho vay tín dụng chủ yếu dựa vào điểm tín dụng để xử lý các đơn xin vay. Nói chung, điểm tín dụng phản ánh lịch sử vay và trả lại tiền của người nộp đơn, và những người cho vay tham khảo chúng khi xác định mức độ tin cậy của một cá nhân. Các công ty thanh toán và ngân hàng quan tâm đến việc xây dựng các hệ thống có thể giúp xác định rủi ro liên quan đến một ứng dụng cụ thể và cung cấp các sản phẩm tín dụng cạnh tranh. Các mô hình máy học (ML) có thể được sử dụng để xây dựng một hệ thống xử lý dữ liệu lịch sử của người nộp đơn và dự đoán hồ sơ rủi ro tín dụng. Dữ liệu có thể bao gồm lịch sử tài chính và việc làm của người nộp đơn, nhân khẩu học của họ và bối cảnh tín dụng/khoản vay mới. Luôn có một số sự không chắc chắn về mặt thống kê với bất kỳ mô hình nào dự đoán liệu một người nộp đơn cụ thể có vỡ nợ trong tương lai hay không. Các hệ thống cần cung cấp sự cân bằng giữa việc từ chối các ứng dụng có thể bị vỡ nợ theo thời gian và chấp nhận các ứng dụng cuối cùng đáng tin cậy.
Chủ sở hữu doanh nghiệp của một hệ thống như vậy cần đảm bảo tính hợp lệ và chất lượng của các mô hình theo các yêu cầu tuân thủ quy định hiện có và sắp tới. Họ có nghĩa vụ đối xử công bằng với khách hàng và cung cấp sự minh bạch trong quá trình ra quyết định của họ. Họ có thể muốn đảm bảo rằng các dự đoán của mô hình tích cực không bị mất cân bằng giữa các nhóm khác nhau (ví dụ: giới tính, chủng tộc, sắc tộc, tình trạng nhập cư và các nhóm khác). Sau khi dữ liệu bắt buộc được thu thập, quá trình đào tạo mô hình ML thường tối ưu hóa cho hiệu suất dự đoán như một mục tiêu chính với chỉ số như độ chính xác của phân loại hoặc điểm AUC. Ngoài ra, một mô hình với mục tiêu hiệu suất nhất định có thể được hạn chế bằng thước đo công bằng để đảm bảo các yêu cầu nhất định được duy trì. Một kỹ thuật như vậy để hạn chế mô hình là điều chỉnh siêu tham số nhận biết sự công bằng. Bằng cách áp dụng các chiến lược này, mô hình ứng cử viên tốt nhất có thể có độ chệch thấp hơn so với mô hình không bị giới hạn trong khi vẫn duy trì hiệu suất dự đoán cao.
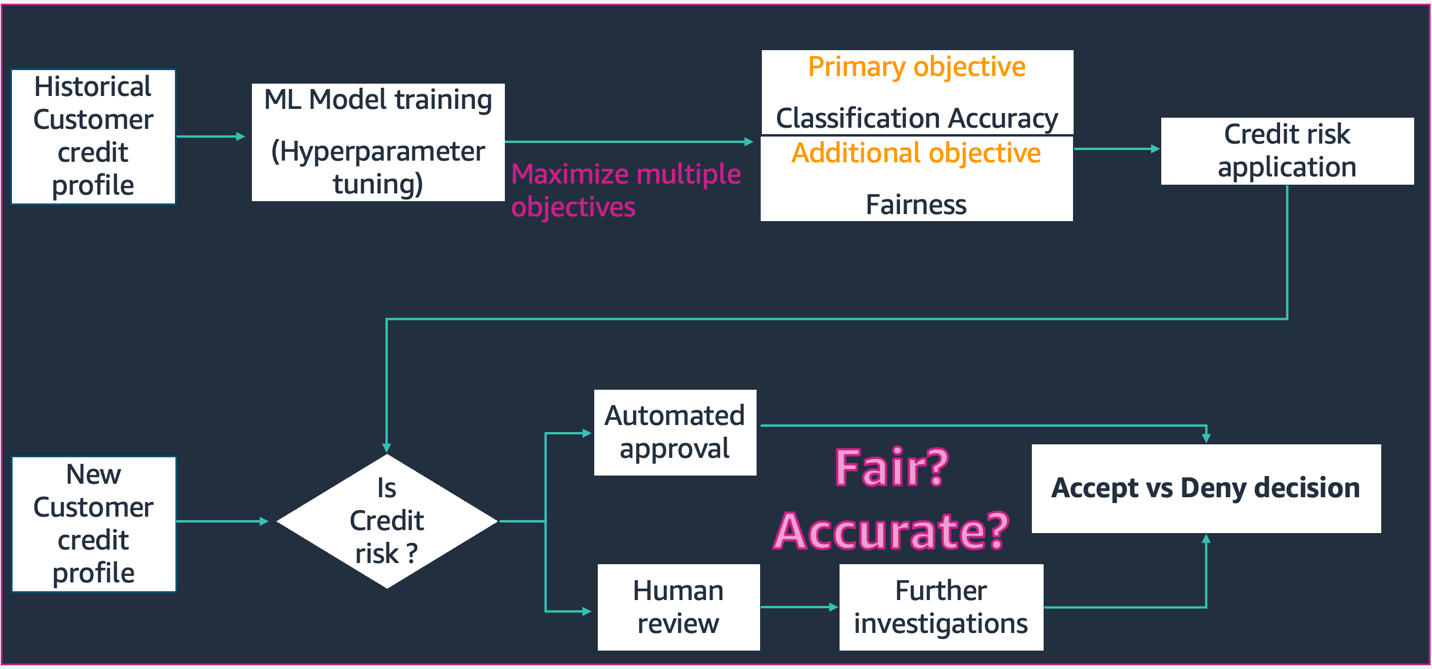
Trong kịch bản được mô tả trong sơ đồ này,
- Mô hình ML được xây dựng với dữ liệu lịch sử hồ sơ tín dụng của khách hàng. Quá trình đào tạo mô hình và điều chỉnh siêu tham số tối đa hóa cho nhiều mục tiêu bao gồm độ chính xác và công bằng của phân loại. Mô hình được triển khai cho một quy trình kinh doanh hiện có trong một hệ thống sản xuất.
- Một hồ sơ tín dụng khách hàng mới được đánh giá rủi ro tín dụng. Nếu rủi ro thấp, nó có thể trải qua một quy trình tự động. Các ứng dụng rủi ro cao có thể bao gồm đánh giá của con người trước khi đưa ra quyết định chấp nhận hoặc từ chối cuối cùng.
Các quyết định và số liệu được thu thập trong quá trình thiết kế và phát triển, triển khai và vận hành có thể được ghi lại bằng Thẻ mô hình SageMaker và chia sẻ với các bên liên quan.
Trường hợp sử dụng này minh họa cách giảm độ lệch của mô hình đối với một nhóm cụ thể bằng cách tinh chỉnh siêu tham số để có chỉ số khách quan kết hợp về cả độ chính xác và công bằng với Điều chỉnh mô hình tự động của SageMaker. Chúng tôi sử dụng bộ dữ liệu Tín dụng Nam Đức (Tập dữ liệu tín dụng Nam Đức).
Dữ liệu ứng viên có thể được chia thành các loại sau:
- Nhân khẩu học
- Dữ liệu tài chính
- Quá trình công tác
- Mục đích vay vốn
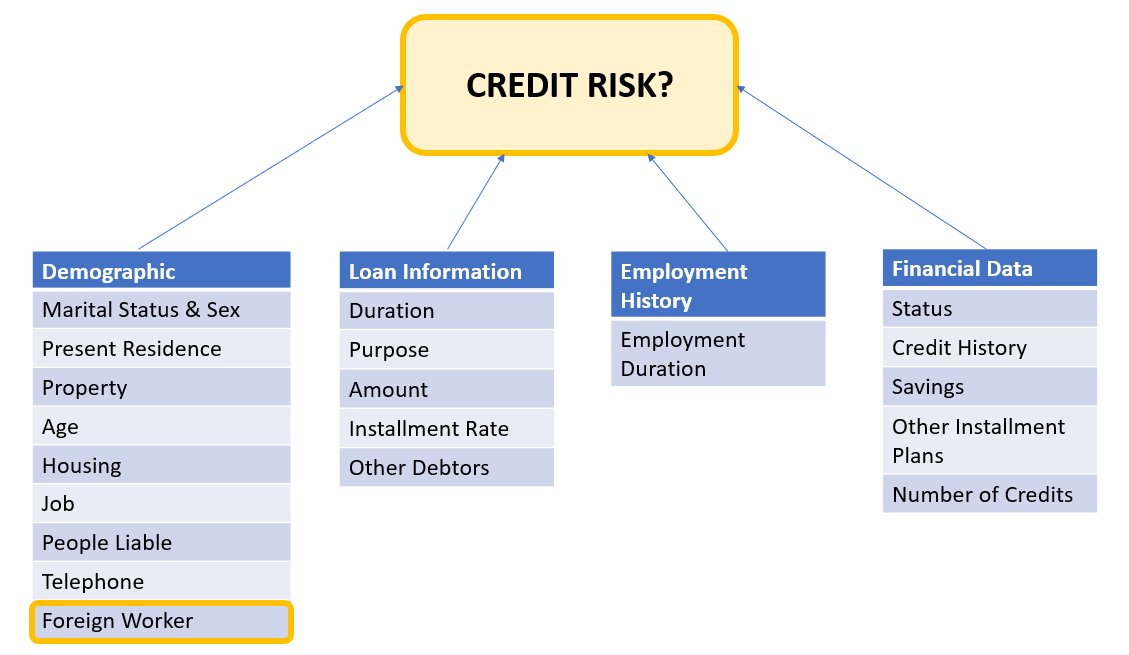
Trong ví dụ này, chúng tôi đặc biệt xem xét nhân khẩu học 'Người lao động nước ngoài' và điều chỉnh một mô hình dự đoán các quyết định đăng ký tín dụng với độ chính xác cao và ít sai lệch đối với nhóm phụ cụ thể đó.
Có nhiều số liệu thiên vị có thể được sử dụng để đánh giá tính công bằng của hệ thống đối với các nhóm phụ cụ thể trong dữ liệu. Ở đây, chúng tôi sử dụng giá trị tuyệt đối của Sự khác biệt về Tỷ lệ Tích cực trong Nhãn Dự đoán (ĐPPL) từ SageMaker Làm rõ. Nói một cách đơn giản, DPPL đo lường sự khác biệt trong phân công công việc có đẳng cấp tích cực (tín nhiệm tốt) giữa người lao động không phải là người nước ngoài và người lao động nước ngoài.
Ví dụ: nếu 4.5% tổng số lao động nước ngoài được gán nhãn tích cực theo mô hình và 13.7% tổng số lao động không phải người nước ngoài được gán nhãn tích cực, thì DPPL = 0.137 – 0.045 = 0.092.
giải pháp xây dựng
Hình bên dưới hiển thị tổng quan cấp cao về kiến trúc của công việc Automatic Model Tuning với XGBoost trên Amazon SageMaker.

Trong giải pháp, SageMaker Xử lý xử lý trước tập dữ liệu đào tạo từ Amazon S3. Amazon SageMaker Automatic Tuning khởi tạo nhiều tác vụ đào tạo SageMaker với các phiên bản EC2 và ổ đĩa EBS liên quan. Bộ chứa thuật toán (XGBoost) được tải từ Amazon ECR trong mỗi công việc. SageMaker AMT tìm phiên bản tốt nhất của mô hình bằng cách chạy nhiều công việc đào tạo trên tập dữ liệu được xử lý trước bằng cách sử dụng tập lệnh thuật toán được chỉ định và phạm vi siêu tham số. Các số liệu đầu ra được ghi vào Amazon CloudWatch để theo dõi.
Các siêu đường kính mà chúng tôi đang điều chỉnh trong trường hợp sử dụng này như sau:
- eta – Thu hẹp kích thước bước được sử dụng trong các bản cập nhật để tránh trang bị quá mức.
- trọng lượng tối thiểu_trẻ_con – Tổng trọng lượng cá thể tối thiểu (bao bố) cần có ở trẻ em.
- gamma – Giảm tổn thất tối thiểu cần thiết để tạo phân vùng tiếp theo trên một nút lá của cây.
- max_deep – Độ sâu tối đa của cây.
Có thể tìm thấy định nghĩa của các siêu đường kính này và các siêu đường kính khác có sẵn với SageMaker AMT tại đây.
Đầu tiên, chúng tôi chứng minh một kịch bản cơ sở của một chỉ số mục tiêu hiệu suất duy nhất để điều chỉnh siêu tham số bằng Điều chỉnh mô hình tự động. Sau đó, chúng tôi chứng minh kịch bản được tối ưu hóa của chỉ số đa mục tiêu được chỉ định là sự kết hợp giữa chỉ số hiệu suất và chỉ số công bằng.
Điều chỉnh siêu tham số đơn lẻ (Đường cơ sở)
Có thể lựa chọn nhiều số liệu cho một công việc điều chỉnh để đánh giá các công việc đào tạo riêng lẻ. Theo đoạn mã bên dưới, chúng tôi chỉ định chỉ số mục tiêu duy nhất là objective_metric_name. Công việc điều chỉnh siêu tham số trả về công việc đào tạo mang lại giá trị tốt nhất cho chỉ số mục tiêu đã chọn.
Trong kịch bản cơ sở này, chúng tôi đang điều chỉnh cho Diện tích dưới đường cong (AUC) như bên dưới. Điều quan trọng cần lưu ý là chúng tôi chỉ tối ưu hóa AUC và không tối ưu hóa cho các số liệu khác như tính công bằng.
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)Trong ngữ cảnh này max jobs cho phép chúng tôi chỉ định số lần một công việc đào tạo sẽ được điều chỉnh và tìm công việc đào tạo tốt nhất từ đó.
Điều chỉnh siêu tham số đa mục tiêu (Tối ưu hóa độ công bằng)
Chúng tôi muốn tối ưu hóa nhiều chỉ số khách quan bằng cách điều chỉnh siêu tham số như được mô tả trong phần này giấy. Tuy nhiên, SageMaker AMT vẫn chỉ chấp nhận một số liệu duy nhất làm đầu vào.
Để giải quyết thách thức này, chúng tôi biểu thị nhiều chỉ số dưới dạng một hàm chỉ số và tối ưu hóa chỉ số này:
- cực đạiM(y1,y2,θ)
- y1,y2 là các chỉ số khác nhau. Ví dụ: điểm AUC và DPPL.
- M(⋅,⋅,θ) là một hàm vô hướng và được tham số hóa bởi một tham số cố định
Trọng lượng cao hơn ủng hộ mục tiêu cụ thể đó trong điều chỉnh mô hình. Trọng lượng có thể thận trọng trong từng trường hợp và bạn có thể cần thử các trọng lượng khác nhau cho trường hợp sử dụng của mình. Trong ví dụ này, trọng số cho AUC và DPPL đã được đặt theo kinh nghiệm. Hãy cùng xem nó trông như thế nào trong mã. Bạn có thể thấy công việc đào tạo trả về một số liệu duy nhất dựa trên chức năng kết hợp của Điểm AUC cho hiệu suất và DPPL cho sự công bằng. Phạm vi tối ưu hóa siêu tham số cho nhiều mục tiêu giống như một mục tiêu. Chúng tôi đang chuyển chỉ số xác thực là “auc” nhưng đằng sau hậu trường, chúng tôi đang trả về kết quả của hàm chỉ số kết hợp như được mô tả cuối cùng trong danh sách các hàm bên dưới:
Đây là chức năng Tối ưu hóa đa mục tiêu:
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)Đây là hàm tính điểm AUC:
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_scoreĐây là hàm tính điểm DPPL:
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))Đây là chức năng cho Số liệu kết hợp:
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metricThử nghiệm & Kết quả
Tạo dữ liệu tổng hợp cho tập dữ liệu sai lệch
Bộ dữ liệu Tín dụng gốc của Nam Đức chứa 1000 bản ghi và chúng tôi đã tạo thêm 100 bản ghi theo cách tổng hợp để tạo một bộ dữ liệu trong đó sự thiên vị trong các dự đoán của mô hình không có lợi cho Người lao động nước ngoài. Điều này được thực hiện để mô phỏng sự thiên vị có thể tự biểu hiện trong thế giới thực. Hồ sơ mới về người lao động nước ngoài bị dán nhãn là người nộp đơn “tín dụng xấu” được ngoại suy từ những người lao động nước ngoài hiện tại có cùng nhãn.
Có nhiều thư viện/kỹ thuật để tạo dữ liệu tổng hợp và chúng tôi sử dụng Kho dữ liệu tổng hợp (ĐPPLV).
Từ đoạn mã sau, chúng ta có thể thấy cách dữ liệu tổng hợp được tạo bằng DPPLV với Tập dữ liệu tín dụng Nam Đức:
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)Chúng tôi đã tạo 100 bản ghi tổng hợp mới về Người lao động nước ngoài dựa trên những Người lao động nước ngoài đã được chấp nhận trong tập dữ liệu gốc. Bây giờ chúng tôi sẽ lấy những bản ghi đó và chuyển nhãn “rủi ro tín dụng” thành 0 (tín dụng xấu). Điều này sẽ đánh dấu không công bằng những Người lao động nước ngoài này là tín dụng xấu, do đó chèn sai lệch vào tập dữ liệu của chúng tôi
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0Chúng tôi khám phá sự thiên vị trong tập dữ liệu thông qua các biểu đồ bên dưới.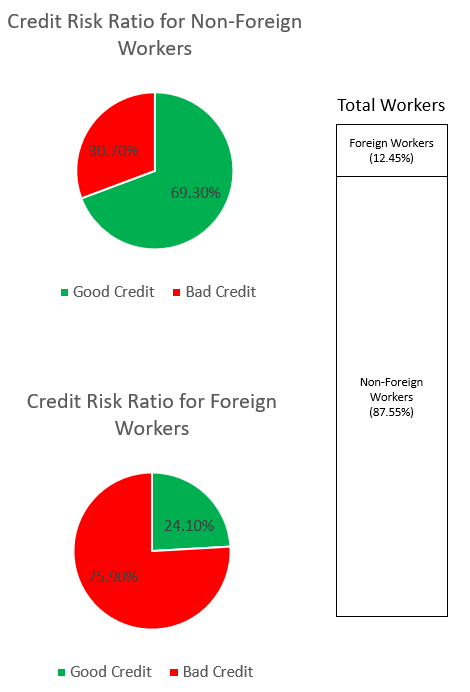
Biểu đồ hình tròn trên cùng cho thấy tỷ lệ phần trăm Người lao động không phải là người nước ngoài được dán nhãn là tín dụng tốt hoặc tín dụng xấu và biểu đồ hình tròn dưới cùng cho thấy điều tương tự đối với Người lao động nước ngoài. Tỷ lệ người lao động nước ngoài bị dán nhãn là “tín dụng xấu” là 75.90% và vượt xa tỷ lệ 30.70% của người lao động không phải là người nước ngoài bị dán nhãn tương tự. Thanh ngăn xếp hiển thị phân tích tỷ lệ phần trăm gần như tương tự của tổng số người lao động trong danh mục Người lao động nước ngoài và không phải người nước ngoài.
Chúng tôi muốn tránh để mô hình ML học được thành kiến mạnh mẽ đối với Người lao động nước ngoài thông qua các tính năng rõ ràng hoặc các tính năng proxy ngầm trong dữ liệu. Với mục tiêu công bằng bổ sung, chúng tôi hướng dẫn mô hình ML để giảm thiểu sự thiên vị về mức độ tín nhiệm thấp hơn đối với Người lao động nước ngoài.
Hiệu suất mô hình sau khi điều chỉnh cho cả hiệu suất và sự công bằng
Biểu đồ này mô tả biểu đồ mật độ của tối đa 100 công việc điều chỉnh do SageMaker AMT điều hành và các giá trị chỉ số mục tiêu kết hợp tương ứng của chúng. Mặc dù chúng tôi đã thiết lập max jobs đến 100, nó có thể thay đổi theo quyết định của người dùng. Số liệu kết hợp là sự kết hợp của AUC và DPPL với chức năng: (3*AUC + (1-DPPL)) / 4. Lý do chúng tôi sử dụng (1-DPPL) thay vì (DPPL) là vì chúng tôi muốn tối đa hóa mục tiêu kết hợp để có DPPL thấp nhất có thể (DPPL thấp hơn có nghĩa là ít thiên vị hơn đối với người lao động nước ngoài). Biểu đồ cho thấy cách AMT giúp xác định siêu tham số tốt nhất cho mô hình XGBoost trả về giá trị chỉ số đánh giá kết hợp cao nhất là 0.68.
Hiệu suất mô hình với chỉ số kết hợp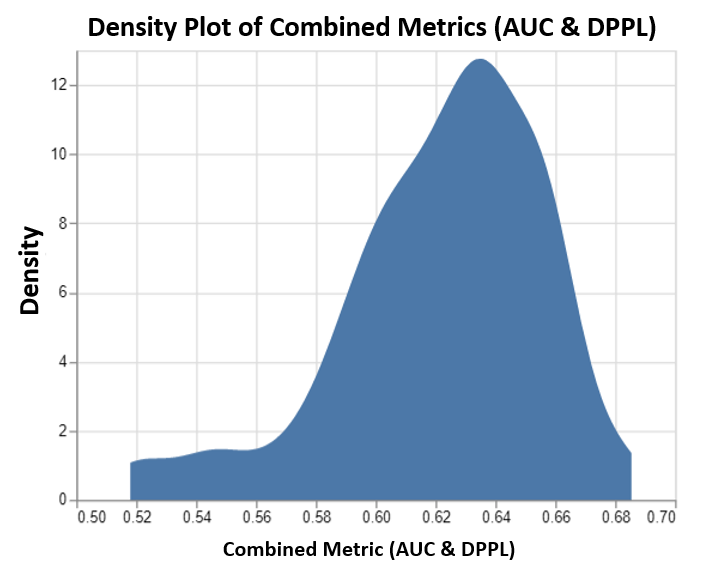
Dưới đây, chúng ta hãy xem biểu đồ phía trước pareto cho các số liệu riêng lẻ của AUC và DPPL. Biểu đồ Pareto Front được sử dụng ở đây để thể hiện trực quan sự đánh đổi giữa nhiều mục tiêu, trong trường hợp này là hai giá trị chỉ số (AUC & DPPL). Các điểm trên mặt trước của đường cong được coi là tốt như nhau và một chỉ số không thể được cải thiện mà không làm giảm giá trị kia. Biểu đồ Pareto cho phép chúng tôi xem các công việc khác nhau được thực hiện như thế nào so với đường cơ sở (vòng tròn màu đỏ) về cả hai số liệu. Nó cũng cho chúng ta thấy công việc tối ưu nhất (hình tam giác màu xanh lá cây). Vị trí của hình tròn màu đỏ và hình tam giác màu xanh lá cây rất quan trọng vì nó cho phép chúng tôi hiểu liệu số liệu kết hợp của chúng tôi có thực sự hoạt động như mong đợi và thực sự tối ưu hóa cho cả hai số liệu hay không. Mã để tạo biểu đồ phía trước pareto được bao gồm trong sổ ghi chép trong GitHub.
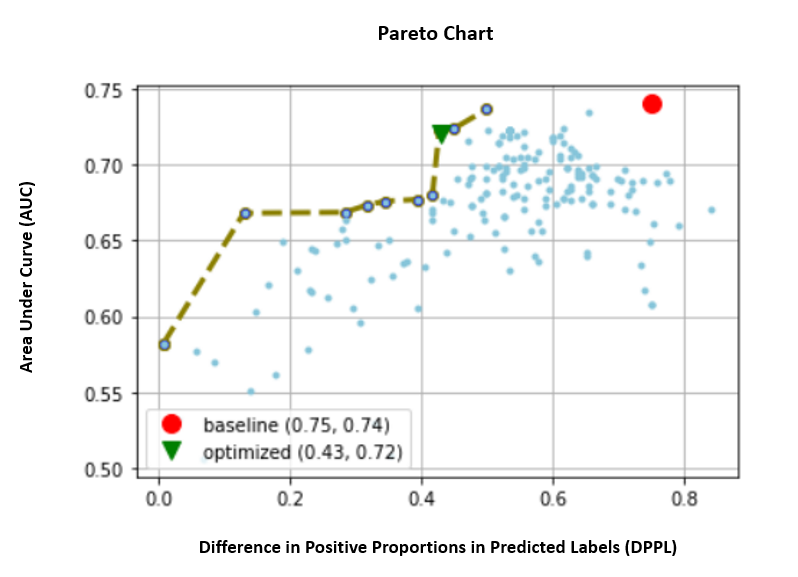
Trong trường hợp này, giá trị DPPL thấp hơn sẽ tốt hơn (ít sai lệch hơn), trong khi AUC cao hơn sẽ tốt hơn (tăng hiệu suất).
Ở đây, đường cơ sở (vòng tròn màu đỏ) biểu thị kịch bản trong đó chỉ số mục tiêu chỉ là AUC. Nói cách khác, đường cơ sở hoàn toàn không xem xét DPPL và chỉ tối ưu hóa cho AUC (không tinh chỉnh cho công bằng). Chúng tôi thấy đường cơ sở có điểm AUC tốt là 0.74, nhưng không hoạt động tốt về tính công bằng với điểm DPPL là 0.75.
Mô hình Tối ưu hóa (hình tam giác màu xanh lá cây) đại diện cho mô hình ứng viên tốt nhất khi được tinh chỉnh cho chỉ số kết hợp với tỷ lệ trọng số là 3:1 cho AUC:DPPL. Chúng tôi thấy mô hình được tối ưu hóa có điểm AUC tốt là 0.72 và điểm DPPL thấp là 0.43 (độ lệch thấp). Công việc điều chỉnh này đã tìm thấy một cấu hình mô hình trong đó DPPL có thể thấp hơn đáng kể so với đường cơ sở mà AUC không giảm đáng kể. Có thể xác định các mô hình có điểm số DPPL thậm chí còn thấp hơn bằng cách di chuyển hình tam giác màu xanh lá cây sang trái xa hơn dọc theo Pareto Front. Do đó, chúng tôi đã đạt được mục tiêu kết hợp của một mô hình hoạt động tốt với sự công bằng cho các nhóm nhỏ Người lao động nước ngoài.
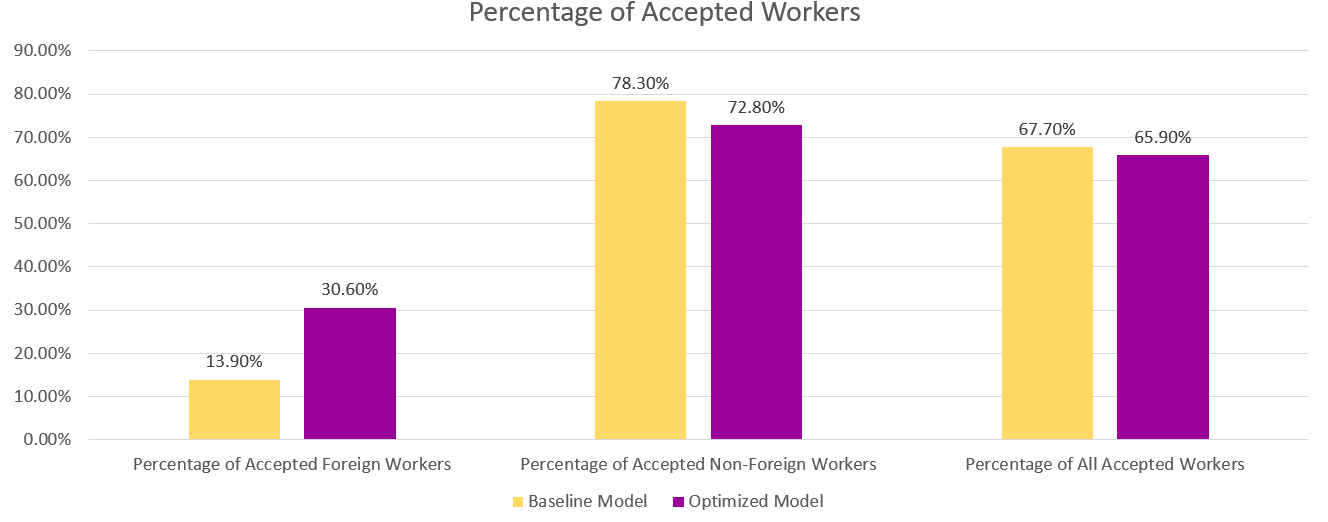
Trong biểu đồ bên dưới, chúng ta có thể thấy kết quả dự đoán từ mô hình cơ sở và mô hình được tối ưu hóa. Mô hình được tối ưu hóa với mục tiêu kết hợp giữa hiệu suất và sự công bằng dự đoán kết quả tích cực cho 30.6% Lao động nước ngoài so với 13.9% từ mô hình cơ sở. Do đó, mô hình được tối ưu hóa làm giảm độ lệch của mô hình đối với nhóm phụ này.
Kết luận
Blog hướng dẫn bạn triển khai tối ưu hóa đa mục tiêu với Điều chỉnh mô hình tự động của SageMaker cho các ứng dụng trong thế giới thực. Trong nhiều trường hợp, dữ liệu được thu thập trong thế giới thực có thể bị sai lệch so với các nhóm con nhất định. Tối ưu hóa đa mục tiêu bằng cách sử dụng điều chỉnh mô hình tự động cho phép khách hàng xây dựng các mô hình ML một cách dễ dàng nhằm tối ưu hóa tính công bằng và độ chính xác. Chúng tôi trình bày một ví dụ về dự đoán rủi ro tín dụng và đặc biệt xem xét sự công bằng cho người lao động nước ngoài. Chúng tôi cho thấy rằng có thể tối đa hóa cho một số liệu khác như tính công bằng trong khi tiếp tục đào tạo các mô hình có hiệu suất cao. Nếu những gì bạn đã đọc thu hút sự quan tâm của bạn, bạn có thể dùng thử ví dụ về mã được lưu trữ trên Github tại đây.
Giới thiệu về tác giả
 Munish Dabra là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services (AWS). Các lĩnh vực trọng tâm hiện tại của anh ấy là AI/ML, Phân tích dữ liệu và Khả năng quan sát. Anh ấy có nền tảng vững chắc về thiết kế và xây dựng các hệ thống phân tán có thể mở rộng. Anh ấy thích giúp khách hàng đổi mới và chuyển đổi hoạt động kinh doanh của họ trong AWS. LinkedIn: /mdabra
Munish Dabra là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services (AWS). Các lĩnh vực trọng tâm hiện tại của anh ấy là AI/ML, Phân tích dữ liệu và Khả năng quan sát. Anh ấy có nền tảng vững chắc về thiết kế và xây dựng các hệ thống phân tán có thể mở rộng. Anh ấy thích giúp khách hàng đổi mới và chuyển đổi hoạt động kinh doanh của họ trong AWS. LinkedIn: /mdabra
 Hasan Poonawala là Kiến trúc sư Giải pháp Chuyên gia về AI / ML Cấp cao tại AWS, Hasan giúp khách hàng thiết kế và triển khai các ứng dụng học máy trong sản xuất trên AWS. Anh ấy có hơn 12 năm kinh nghiệm làm việc với tư cách là nhà khoa học dữ liệu, người thực hành máy học và nhà phát triển phần mềm. Khi rảnh rỗi, Hasan thích khám phá thiên nhiên và dành thời gian cho bạn bè và gia đình.
Hasan Poonawala là Kiến trúc sư Giải pháp Chuyên gia về AI / ML Cấp cao tại AWS, Hasan giúp khách hàng thiết kế và triển khai các ứng dụng học máy trong sản xuất trên AWS. Anh ấy có hơn 12 năm kinh nghiệm làm việc với tư cách là nhà khoa học dữ liệu, người thực hành máy học và nhà phát triển phần mềm. Khi rảnh rỗi, Hasan thích khám phá thiên nhiên và dành thời gian cho bạn bè và gia đình.
 Mohamad (Moh) Tahsin là cộng sự Kiến trúc sư giải pháp chuyên gia AI/ML cho AWS. Moh có kinh nghiệm giảng dạy sinh viên về các khái niệm AI có trách nhiệm và đam mê truyền đạt các khái niệm này thông qua các kiến trúc dựa trên đám mây. Khi rảnh rỗi, anh ấy thích nâng tạ, chơi trò chơi và khám phá thiên nhiên.
Mohamad (Moh) Tahsin là cộng sự Kiến trúc sư giải pháp chuyên gia AI/ML cho AWS. Moh có kinh nghiệm giảng dạy sinh viên về các khái niệm AI có trách nhiệm và đam mê truyền đạt các khái niệm này thông qua các kiến trúc dựa trên đám mây. Khi rảnh rỗi, anh ấy thích nâng tạ, chơi trò chơi và khám phá thiên nhiên.
 Tinh Thần Mã là Nhà khoa học ứng dụng tại AWS. Anh ấy làm việc trong nhóm dịch vụ cho SageMaker Automatic Model Tuning.
Tinh Thần Mã là Nhà khoa học ứng dụng tại AWS. Anh ấy làm việc trong nhóm dịch vụ cho SageMaker Automatic Model Tuning.
 Rahul Sureka là một Kiến trúc sư giải pháp doanh nghiệp tại AWS có trụ sở ở Ấn Độ. Rahul có hơn 22 năm kinh nghiệm trong việc thiết kế kiến trúc và dẫn dắt các chương trình chuyển đổi doanh nghiệp lớn trên nhiều phân khúc ngành. Lĩnh vực anh ấy quan tâm là dữ liệu và phân tích, phát trực tuyến và các ứng dụng AI/ML.
Rahul Sureka là một Kiến trúc sư giải pháp doanh nghiệp tại AWS có trụ sở ở Ấn Độ. Rahul có hơn 22 năm kinh nghiệm trong việc thiết kế kiến trúc và dẫn dắt các chương trình chuyển đổi doanh nghiệp lớn trên nhiều phân khúc ngành. Lĩnh vực anh ấy quan tâm là dữ liệu và phân tích, phát trực tuyến và các ứng dụng AI/ML.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/

