Khi triển khai mô hình ngôn ngữ lớn (LLM), những người thực hành máy học (ML) thường quan tâm đến hai phép đo về hiệu suất phân phát mô hình: độ trễ, được xác định bằng thời gian cần thiết để tạo một mã thông báo và thông lượng, được xác định bởi số lượng mã thông báo được tạo môi giây. Mặc dù một yêu cầu duy nhất tới điểm cuối được triển khai sẽ thể hiện thông lượng xấp xỉ bằng nghịch đảo của độ trễ mô hình, nhưng điều này không nhất thiết xảy ra khi nhiều yêu cầu đồng thời được gửi đồng thời đến điểm cuối. Do các kỹ thuật phân phối mô hình, chẳng hạn như phân nhóm liên tục các yêu cầu đồng thời phía máy khách, độ trễ và thông lượng có mối quan hệ phức tạp và thay đổi đáng kể dựa trên kiến trúc mô hình, cấu hình phân phối, phần cứng loại phiên bản, số lượng yêu cầu đồng thời và các biến thể trong tải trọng đầu vào, chẳng hạn như dưới dạng số lượng mã thông báo đầu vào và mã thông báo đầu ra.
Bài đăng này khám phá những mối quan hệ này thông qua điểm chuẩn toàn diện của LLM có sẵn trong Amazon SageMaker JumpStart, bao gồm các biến thể Llama 2, Falcon và Mistral. Với SageMaker JumpStart, những người thực hành ML có thể chọn từ rất nhiều mô hình nền tảng có sẵn công khai để triển khai cho các mô hình chuyên dụng Amazon SageMaker các trường hợp trong môi trường cách ly mạng. Chúng tôi cung cấp các nguyên tắc lý thuyết về cách các thông số kỹ thuật của máy gia tốc tác động đến việc đánh giá điểm chuẩn LLM. Chúng tôi cũng chứng minh tác động của việc triển khai nhiều phiên bản đằng sau một điểm cuối duy nhất. Cuối cùng, chúng tôi cung cấp các đề xuất thiết thực để điều chỉnh quy trình triển khai SageMaker JumpStart cho phù hợp với yêu cầu của bạn về độ trễ, thông lượng, chi phí và các hạn chế đối với các loại phiên bản có sẵn. Tất cả các kết quả đo điểm chuẩn cũng như các đề xuất đều dựa trên một phương pháp linh hoạt máy tính xách tay mà bạn có thể thích ứng với trường hợp sử dụng của mình.
Điểm chuẩn điểm cuối đã triển khai
Hình sau đây hiển thị các giá trị độ trễ thấp nhất (trái) và thông lượng cao nhất (phải) cho các cấu hình triển khai trên nhiều loại mô hình và loại phiên bản khác nhau. Điều quan trọng là mỗi hoạt động triển khai mô hình này đều sử dụng cấu hình mặc định do SageMaker JumpStart cung cấp với ID mô hình và loại phiên bản mong muốn để triển khai.
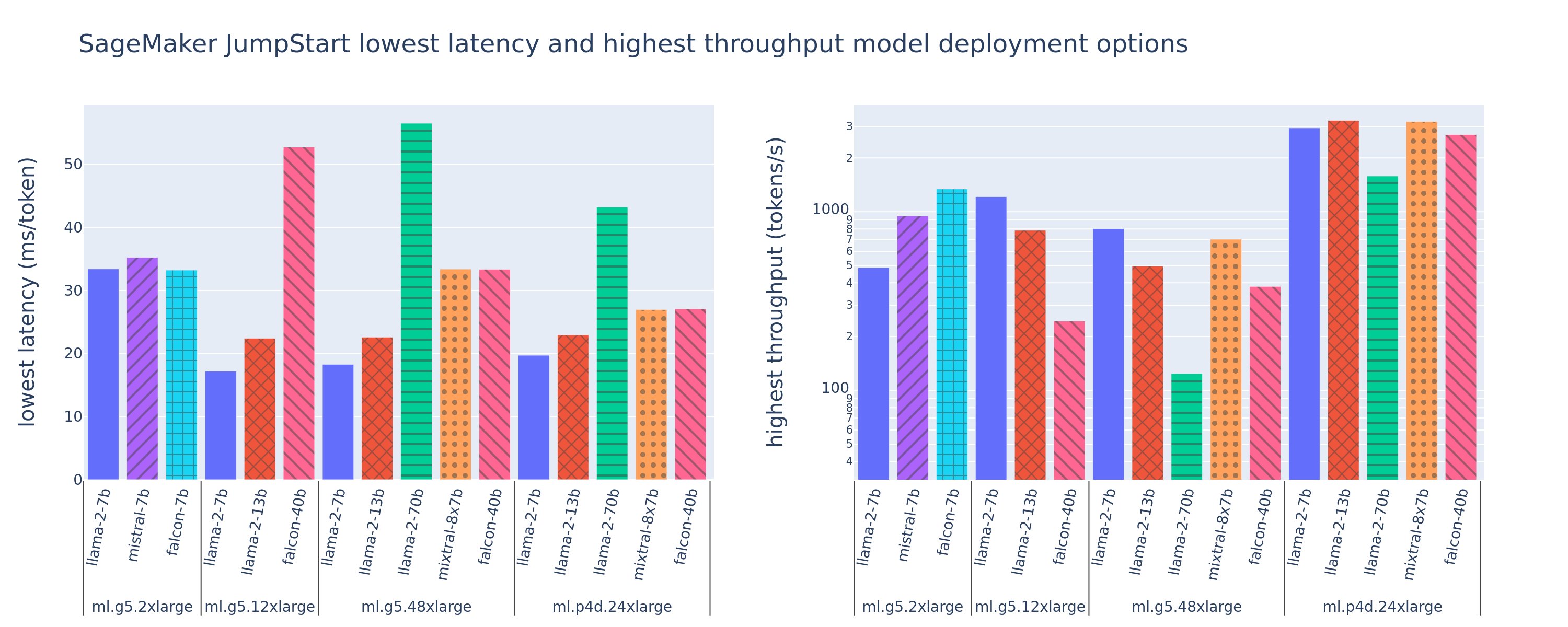
Các giá trị độ trễ và thông lượng này tương ứng với tải trọng có 256 mã thông báo đầu vào và 256 mã thông báo đầu ra. Mô hình giới hạn cấu hình có độ trễ thấp nhất phục vụ cho một yêu cầu đồng thời và cấu hình thông lượng cao nhất sẽ tối đa hóa số lượng yêu cầu đồng thời có thể có. Như chúng ta có thể thấy trong điểm chuẩn của mình, việc tăng các yêu cầu đồng thời sẽ tăng thông lượng một cách đơn điệu trong khi mức cải thiện giảm dần đối với các yêu cầu đồng thời lớn. Ngoài ra, các mô hình được phân chia hoàn toàn trên phiên bản được hỗ trợ. Ví dụ: vì phiên bản ml.g5.48xlarge có 8 GPU nên tất cả các mô hình SageMaker JumpStart sử dụng phiên bản này đều được phân chia bằng cách sử dụng cơ chế song song tensor trên tất cả tám bộ tăng tốc có sẵn.
Chúng ta có thể lưu ý một số điều rút ra từ con số này. Đầu tiên, không phải tất cả các mô hình đều được hỗ trợ trên mọi phiên bản; một số mô hình nhỏ hơn, chẳng hạn như Falcon 7B, không hỗ trợ phân mảnh mô hình, trong khi các mô hình lớn hơn có yêu cầu tài nguyên điện toán cao hơn. Thứ hai, khi sharding tăng lên, hiệu suất thường cải thiện nhưng có thể không nhất thiết phải cải thiện đối với các mô hình nhỏ. Điều này là do các mô hình nhỏ như 7B và 13B phải gánh chịu chi phí liên lạc đáng kể khi được phân chia trên quá nhiều máy gia tốc. Chúng ta sẽ thảo luận vấn đề này sâu hơn sau. Cuối cùng, các phiên bản ml.p4d.24xlarge có xu hướng có thông lượng tốt hơn đáng kể nhờ những cải tiến về băng thông bộ nhớ của A100 so với GPU A10G. Như chúng ta sẽ thảo luận sau, quyết định sử dụng một loại phiên bản cụ thể tùy thuộc vào yêu cầu triển khai của bạn, bao gồm độ trễ, thông lượng và hạn chế về chi phí.
Làm cách nào bạn có thể nhận được các giá trị cấu hình có độ trễ thấp nhất và thông lượng cao nhất này? Hãy bắt đầu bằng cách vẽ đồ thị độ trễ so với thông lượng cho điểm cuối Llama 2 7B trên phiên bản ml.g5.12xlarge cho tải trọng có 256 mã thông báo đầu vào và 256 mã thông báo đầu ra, như được thấy trong đường cong sau. Một đường cong tương tự tồn tại cho mọi điểm cuối LLM được triển khai.

Khi tính đồng thời tăng lên, thông lượng và độ trễ cũng tăng lên một cách đơn điệu. Do đó, điểm có độ trễ thấp nhất xảy ra ở giá trị yêu cầu đồng thời là 1 và bạn có thể tăng thông lượng hệ thống một cách hiệu quả về mặt chi phí bằng cách tăng các yêu cầu đồng thời. Tồn tại một “điểm uốn” riêng biệt trong đường cong này, trong đó rõ ràng là mức tăng thông lượng liên quan đến hoạt động đồng thời bổ sung không lớn hơn mức tăng độ trễ liên quan. Vị trí chính xác của đầu gối này tùy theo từng trường hợp sử dụng; một số người thực hành có thể xác định điểm chuẩn tại điểm vượt quá yêu cầu về độ trễ được chỉ định trước (ví dụ: 100 ms/mã thông báo), trong khi những người khác có thể sử dụng điểm chuẩn kiểm tra tải và các phương pháp lý thuyết xếp hàng như quy tắc nửa độ trễ và những người khác có thể sử dụng Thông số lý thuyết của máy gia tốc.
Chúng tôi cũng lưu ý rằng số lượng yêu cầu đồng thời tối đa bị giới hạn. Trong hình trước, dấu vết dòng kết thúc với 192 yêu cầu đồng thời. Nguồn gốc của giới hạn này là do giới hạn thời gian chờ của lệnh gọi SageMaker, trong đó SageMaker chấm dứt thời gian chờ phản hồi lệnh gọi sau 60 giây. Cài đặt này dành riêng cho tài khoản và không thể định cấu hình cho một điểm cuối riêng lẻ. Đối với LLM, việc tạo số lượng lớn mã thông báo đầu ra có thể mất vài giây hoặc thậm chí vài phút. Do đó, tải trọng đầu vào hoặc đầu ra lớn có thể khiến yêu cầu gọi không thành công. Hơn nữa, nếu số lượng yêu cầu đồng thời rất lớn thì nhiều yêu cầu sẽ có thời gian xếp hàng lớn, dẫn đến giới hạn thời gian chờ 60 giây này. Với mục đích của nghiên cứu này, chúng tôi sử dụng giới hạn thời gian chờ để xác định thông lượng tối đa có thể có cho việc triển khai mô hình. Điều quan trọng là, mặc dù điểm cuối SageMaker có thể xử lý một số lượng lớn yêu cầu đồng thời mà không quan sát thời gian chờ phản hồi lệnh gọi, bạn có thể muốn xác định các yêu cầu đồng thời tối đa liên quan đến đầu gối trong đường cong thông lượng độ trễ. Đây có thể là điểm mà bạn bắt đầu cân nhắc việc mở rộng theo chiều ngang, trong đó một điểm cuối duy nhất cung cấp nhiều phiên bản với các bản sao mô hình và cân bằng tải cho các yêu cầu đến giữa các bản sao để hỗ trợ nhiều yêu cầu đồng thời hơn.
Tiến thêm một bước nữa, bảng sau đây chứa kết quả đo điểm chuẩn cho các cấu hình khác nhau cho mô hình Llama 2 7B, bao gồm số lượng mã thông báo đầu vào và đầu ra khác nhau, loại phiên bản và số lượng yêu cầu đồng thời. Lưu ý rằng hình trên chỉ vẽ một hàng duy nhất của bảng này.
| . | Thông lượng (mã thông báo/giây) | Độ trễ (ms/mã thông báo) | ||||||||||||||||||
| Yêu cầu đồng thời | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Tổng số token: 512, Số lượng token đầu ra: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xlarge | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xlarge | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Tổng số token: 4096, Số lượng token đầu ra: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xlarge | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xlarge | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
Chúng tôi quan sát thấy một số mẫu bổ sung trong dữ liệu này. Khi tăng kích thước ngữ cảnh, độ trễ tăng và thông lượng giảm. Ví dụ: trên ml.g5.2xlarge có giá trị đồng thời là 1, thông lượng là 30 mã thông báo/giây khi tổng số mã thông báo là 512, so với 20 mã thông báo/giây nếu tổng số mã thông báo là 4,096. Điều này là do phải mất nhiều thời gian hơn để xử lý đầu vào lớn hơn. Chúng ta cũng có thể thấy rằng việc tăng khả năng GPU và phân mảnh sẽ tác động đến thông lượng tối đa và các yêu cầu đồng thời được hỗ trợ tối đa. Bảng cho thấy Llama 2 7B có các giá trị thông lượng tối đa khác nhau đáng kể cho các loại phiên bản khác nhau và các giá trị thông lượng tối đa này xảy ra ở các giá trị khác nhau của các yêu cầu đồng thời. Những đặc điểm này sẽ thúc đẩy người thực hành ML cân nhắc chi phí của phiên bản này so với phiên bản khác. Ví dụ: với yêu cầu về độ trễ thấp, người thực hành có thể chọn một phiên bản ml.g5.12xlarge (4 GPU A10G) thay vì một phiên bản ml.g5.2xlarge (1 GPU A10G). Nếu được yêu cầu thông lượng cao, việc sử dụng phiên bản ml.p4d.24xlarge (8 GPU A100) với phân đoạn đầy đủ sẽ chỉ hợp lý khi có tính đồng thời cao. Tuy nhiên, hãy lưu ý rằng thay vào đó, việc tải nhiều thành phần suy luận của mô hình 7B trên một phiên bản ml.p4d.24xlarge thường sẽ có lợi; hỗ trợ đa mô hình như vậy sẽ được thảo luận sau trong bài viết này.
Các quan sát trước đây được thực hiện cho mô hình Llama 2 7B. Tuy nhiên, mô hình tương tự vẫn đúng với các mô hình khác. Điểm đáng chú ý chính là các con số về độ trễ và hiệu suất thông lượng phụ thuộc vào tải trọng, loại phiên bản và số lượng yêu cầu đồng thời, do đó, bạn sẽ cần tìm cấu hình lý tưởng cho ứng dụng cụ thể của mình. Để tạo các số trước cho trường hợp sử dụng của bạn, bạn có thể chạy liên kết máy tính xách tay, nơi bạn có thể định cấu hình bản phân tích kiểm tra tải này cho mô hình, loại phiên bản và tải trọng của mình.
Tìm hiểu thông số kỹ thuật của máy gia tốc
Việc lựa chọn phần cứng phù hợp cho suy luận LLM phụ thuộc rất nhiều vào các trường hợp sử dụng cụ thể, mục tiêu trải nghiệm người dùng và LLM đã chọn. Phần này cố gắng tạo ra sự hiểu biết về đầu gối trong đường cong độ trễ-thông lượng liên quan đến các nguyên tắc cấp cao dựa trên thông số kỹ thuật của máy gia tốc. Chỉ những nguyên tắc này thôi thì không đủ để đưa ra quyết định: cần phải có những tiêu chuẩn thực sự. Thuật ngữ thiết bị được sử dụng ở đây để bao gồm tất cả các bộ tăng tốc phần cứng ML. Chúng tôi khẳng định điểm yếu trong đường cong độ trễ-thông lượng được điều khiển bởi một trong hai yếu tố:
- Bộ tăng tốc đã cạn kiệt bộ nhớ để lưu các ma trận KV vào bộ đệm, do đó các yêu cầu tiếp theo sẽ được xếp hàng đợi
- Bộ tăng tốc vẫn còn bộ nhớ dự phòng cho bộ đệm KV nhưng đang sử dụng kích thước lô đủ lớn để thời gian xử lý bị chi phối bởi độ trễ hoạt động điện toán thay vì băng thông bộ nhớ
Chúng tôi thường muốn bị giới hạn bởi yếu tố thứ hai vì điều này ngụ ý rằng tài nguyên máy gia tốc đã bão hòa. Về cơ bản, bạn đang tối đa hóa nguồn lực mà bạn đã trả tiền. Chúng ta hãy khám phá khẳng định này một cách chi tiết hơn.
Bộ nhớ đệm KV và bộ nhớ thiết bị
Cơ chế chú ý của máy biến áp tiêu chuẩn tính toán sự chú ý cho từng mã thông báo mới so với tất cả các mã thông báo trước đó. Hầu hết các máy chủ ML hiện đại đều lưu trữ các khóa và giá trị chú ý trong bộ nhớ thiết bị (DRAM) để tránh tính toán lại ở mỗi bước. Đây được gọi là cái này Bộ đệm KVvà nó phát triển theo kích thước lô và độ dài chuỗi. Nó xác định số lượng yêu cầu của người dùng có thể được phân phát song song và sẽ xác định điểm giới hạn trong đường cong độ trễ-thông lượng nếu chế độ giới hạn tính toán trong kịch bản thứ hai được đề cập trước đó chưa được đáp ứng, dựa trên DRAM có sẵn. Công thức sau đây là giá trị gần đúng cho kích thước bộ đệm KV tối đa.

Trong công thức này, B là cỡ lô và N là số máy gia tốc. Ví dụ: mô hình Llama 2 7B trong FP16 (2 byte/tham số) được phân phát trên GPU A10G (DRAM 24 GB) tiêu thụ khoảng 14 GB, để lại 10 GB cho bộ nhớ đệm KV. Khi thêm chiều dài ngữ cảnh đầy đủ của mô hình (N = 4096) và các tham số còn lại (n_layers=32, n_kv_attention_heads=32 và d_attention_head=128), biểu thức này cho thấy chúng tôi bị giới hạn trong việc phục vụ song song một nhóm gồm bốn người dùng do hạn chế về DRAM . Nếu bạn quan sát các điểm chuẩn tương ứng trong bảng trước thì đây là một giá trị gần đúng phù hợp cho điểm yếu được quan sát trong đường cong thông lượng độ trễ này. Các phương pháp như sự chú ý truy vấn được nhóm (GQA) có thể giảm kích thước bộ đệm KV, trong trường hợp của GQA với cùng một yếu tố, nó làm giảm số lượng đầu KV.
Cường độ số học và băng thông bộ nhớ thiết bị
Sự tăng trưởng về sức mạnh tính toán của máy gia tốc ML đã vượt xa băng thông bộ nhớ của chúng, nghĩa là chúng có thể thực hiện nhiều phép tính hơn trên mỗi byte dữ liệu trong khoảng thời gian cần thiết để truy cập byte đó.
Sản phẩm cường độ số học, hoặc tỷ lệ của các thao tác điện toán với quyền truy cập bộ nhớ, đối với một thao tác sẽ xác định xem liệu thao tác đó có bị giới hạn bởi băng thông bộ nhớ hoặc công suất tính toán trên phần cứng đã chọn hay không. Ví dụ: GPU A10G (dòng phiên bản g5) có 70 TFLOPS FP16 và băng thông 600 GB/giây có thể tính toán khoảng 116 ops/byte. GPU A100 (dòng phiên bản p4d) có thể tính toán khoảng 208 op/byte. Nếu cường độ số học của một mô hình máy biến áp nằm dưới giá trị đó thì nó bị giới hạn bộ nhớ; nếu nó ở trên thì nó bị giới hạn tính toán. Cơ chế chú ý cho Llama 2 7B yêu cầu 62 ops/byte cho kích thước lô 1 (để biết giải thích, hãy xem Hướng dẫn về suy luận và hiệu suất LLM), có nghĩa là nó bị ràng buộc bởi bộ nhớ. Khi cơ chế chú ý bị ràng buộc bởi bộ nhớ, các FLOPS đắt tiền sẽ không được sử dụng.
Có hai cách để sử dụng tốt hơn bộ tăng tốc và tăng cường độ số học: giảm số lần truy cập bộ nhớ cần thiết cho thao tác (đây là cách Đèn FlashChú Ý tập trung vào) hoặc tăng kích thước lô. Tuy nhiên, chúng tôi có thể không tăng kích thước lô đủ để đạt được chế độ giới hạn tính toán nếu DRAM của chúng tôi quá nhỏ để chứa bộ nhớ đệm KV tương ứng. Giá trị gần đúng thô của kích thước lô quan trọng B* phân biệt chế độ giới hạn tính toán với chế độ giới hạn bộ nhớ cho suy luận của bộ giải mã GPT tiêu chuẩn được mô tả bằng biểu thức sau, trong đó A_mb là băng thông bộ nhớ của bộ tăng tốc, A_f là FLOPS của bộ tăng tốc và N là số của các máy gia tốc. Kích thước lô quan trọng này có thể được tính bằng cách tìm nơi thời gian truy cập bộ nhớ bằng thời gian tính toán. tham khảo bài viết trên blog này để hiểu phương trình 2 và các giả định của nó một cách chi tiết hơn.
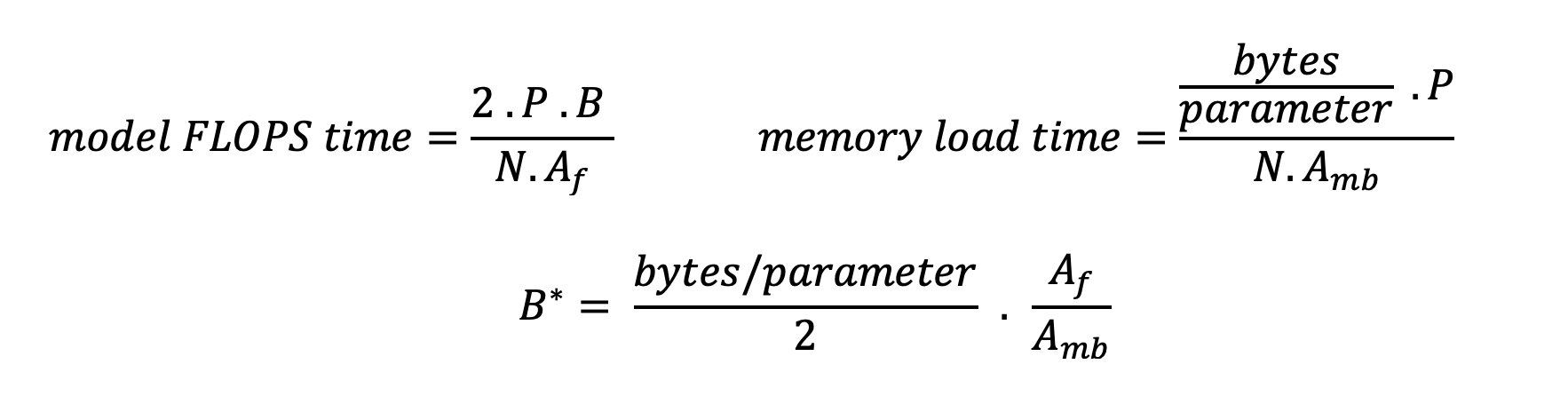
Đây chính là tỷ lệ op/byte mà chúng tôi đã tính trước đây cho A10G, vì vậy kích thước lô quan trọng trên GPU này là 116. Một cách để tiếp cận kích thước lô quan trọng về mặt lý thuyết này là tăng phân mảnh mô hình và phân chia bộ nhớ đệm cho nhiều bộ tăng tốc N hơn. Điều này làm tăng hiệu quả dung lượng bộ đệm KV cũng như kích thước lô giới hạn bộ nhớ.
Một lợi ích khác của phân mảnh mô hình là phân chia tham số mô hình và công việc tải dữ liệu trên các máy gia tốc N. Loại sharding này là một loại mô hình song song còn được gọi là tính song song tensor. Ngây thơ, tổng cộng có N lần băng thông bộ nhớ và sức mạnh tính toán. Giả sử không có bất kỳ loại chi phí nào (giao tiếp, phần mềm, v.v.), điều này sẽ làm giảm độ trễ giải mã trên mỗi mã thông báo xuống N nếu chúng tôi bị giới hạn bộ nhớ, vì độ trễ giải mã mã thông báo trong chế độ này bị ràng buộc bởi thời gian cần thiết để tải mô hình trọng lượng và bộ đệm. Tuy nhiên, trong thực tế, việc tăng mức độ phân mảnh dẫn đến tăng cường giao tiếp giữa các thiết bị để chia sẻ các kích hoạt trung gian ở mọi lớp mô hình. Tốc độ liên lạc này bị giới hạn bởi băng thông kết nối thiết bị. Thật khó để ước tính tác động của nó một cách chính xác (để biết chi tiết, xem Mô hình song song), nhưng điều này cuối cùng có thể ngừng mang lại lợi ích hoặc làm giảm hiệu suất — điều này đặc biệt đúng đối với các kiểu máy nhỏ hơn vì tốc độ truyền dữ liệu nhỏ hơn dẫn đến tốc độ truyền thấp hơn.
Để so sánh các trình tăng tốc ML dựa trên thông số kỹ thuật của chúng, chúng tôi khuyên bạn nên làm như sau. Đầu tiên, tính toán kích thước lô tới hạn gần đúng cho từng loại máy gia tốc theo phương trình thứ hai và kích thước bộ nhớ đệm KV cho cỡ lô tới hạn theo phương trình thứ nhất. Sau đó, bạn có thể sử dụng DRAM có sẵn trên bộ tăng tốc để tính toán số lượng bộ tăng tốc tối thiểu cần thiết để phù hợp với các tham số mô hình và bộ đệm KV. Nếu quyết định giữa nhiều bộ tăng tốc, hãy ưu tiên các bộ tăng tốc theo thứ tự chi phí trên mỗi GB/giây băng thông bộ nhớ thấp nhất. Cuối cùng, đánh giá các cấu hình này và xác minh chi phí/mã thông báo tốt nhất cho giới hạn trên của độ trễ mong muốn của bạn là bao nhiêu.
Chọn cấu hình triển khai điểm cuối
Nhiều LLM do SageMaker JumpStart phân phối sử dụng suy luận tạo văn bản (TGI) Vùng chứa SageMaker để phục vụ người mẫu. Bảng sau đây thảo luận cách điều chỉnh nhiều tham số phân phát mô hình khác nhau để tác động đến việc phân phát mô hình, tác động đến đường cong thông lượng độ trễ hoặc bảo vệ điểm cuối trước các yêu cầu có thể làm điểm cuối bị quá tải. Đây là những tham số chính mà bạn có thể sử dụng để định cấu hình triển khai điểm cuối cho trường hợp sử dụng của mình. Trừ khi có quy định khác, chúng tôi sử dụng mặc định tham số tải trọng tạo văn bản và Biến môi trường TGI.
| Biến môi trường | Mô tả | Giá trị mặc định của SageMaker JumpStart |
| Cấu hình phục vụ mô hình | . | . |
MAX_BATCH_PREFILL_TOKENS |
Giới hạn số lượng mã thông báo trong thao tác điền trước. Thao tác này tạo ra bộ nhớ đệm KV cho chuỗi dấu nhắc đầu vào mới. Nó tiêu tốn nhiều bộ nhớ và bị giới hạn tính toán, vì vậy giá trị này giới hạn số lượng mã thông báo được phép trong một thao tác điền trước. Các bước giải mã cho các truy vấn khác tạm dừng trong khi quá trình điền trước đang diễn ra. | 4096 (mặc định TGI) hoặc độ dài ngữ cảnh được hỗ trợ tối đa theo mô hình cụ thể (được cung cấp SageMaker JumpStart), tùy theo giá trị nào lớn hơn. |
MAX_BATCH_TOTAL_TOKENS |
Kiểm soát số lượng mã thông báo tối đa cần đưa vào trong một lô trong quá trình giải mã hoặc chuyển tiếp một lần qua mô hình. Lý tưởng nhất là điều này được thiết lập để tối đa hóa việc sử dụng tất cả phần cứng có sẵn. | Không được chỉ định (mặc định TGI). TGI sẽ đặt giá trị này đối với bộ nhớ CUDA còn lại trong quá trình khởi động mô hình. |
SM_NUM_GPUS |
Số lượng mảnh được sử dụng. Tức là số lượng GPU được sử dụng để chạy mô hình sử dụng cơ chế song song tensor. | Tùy thuộc vào phiên bản (SageMaker JumpStart được cung cấp). Đối với mỗi phiên bản được hỗ trợ cho một mô hình nhất định, SageMaker JumpStart cung cấp cài đặt tốt nhất cho tính song song tensor. |
| Các cấu hình để bảo vệ điểm cuối của bạn (đặt những cấu hình này cho trường hợp sử dụng của bạn) | . | . |
MAX_TOTAL_TOKENS |
Điều này giới hạn ngân sách bộ nhớ của một yêu cầu khách hàng bằng cách giới hạn số lượng mã thông báo trong chuỗi đầu vào cộng với số lượng mã thông báo trong chuỗi đầu ra ( max_new_tokens tham số tải trọng). |
Độ dài ngữ cảnh được hỗ trợ tối đa dành riêng cho từng mô hình. Ví dụ: 4096 cho Llama 2. |
MAX_INPUT_LENGTH |
Xác định số lượng mã thông báo tối đa được phép trong chuỗi đầu vào cho một yêu cầu của khách hàng. Những điều cần cân nhắc khi tăng giá trị này bao gồm: chuỗi đầu vào dài hơn yêu cầu nhiều bộ nhớ hơn, điều này ảnh hưởng đến việc tạo khối liên tục và nhiều mô hình có độ dài ngữ cảnh được hỗ trợ không được vượt quá. | Độ dài ngữ cảnh được hỗ trợ tối đa dành riêng cho từng mô hình. Ví dụ: 4095 cho Llama 2. |
MAX_CONCURRENT_REQUESTS |
Số lượng yêu cầu đồng thời tối đa được điểm cuối triển khai cho phép. Các yêu cầu mới vượt quá giới hạn này sẽ ngay lập tức gây ra lỗi quá tải mô hình để tránh độ trễ kém cho các yêu cầu xử lý hiện tại. | 128 (mặc định TGI). Cài đặt này cho phép bạn đạt được thông lượng cao cho nhiều trường hợp sử dụng khác nhau, nhưng bạn nên ghim cho phù hợp để giảm thiểu lỗi hết thời gian chờ của lệnh gọi SageMaker. |
Máy chủ TGI sử dụng tính năng phân nhóm liên tục, tự động phân nhóm các yêu cầu đồng thời lại với nhau để chia sẻ một lượt chuyển tiếp suy luận mô hình duy nhất. Có hai loại chuyển tiếp: điền trước và giải mã. Mỗi yêu cầu mới phải chạy một lượt chuyển tiếp điền trước duy nhất để điền vào bộ đệm KV cho mã thông báo chuỗi đầu vào. Sau khi bộ đệm KV được điền, chuyển tiếp giải mã sẽ thực hiện một dự đoán mã thông báo tiếp theo duy nhất cho tất cả các yêu cầu theo lô, được lặp lại nhiều lần để tạo ra chuỗi đầu ra. Khi các yêu cầu mới được gửi đến máy chủ, bước giải mã tiếp theo phải đợi để bước điền trước có thể chạy cho các yêu cầu mới. Điều này phải xảy ra trước khi những yêu cầu mới đó được đưa vào các bước giải mã theo đợt liên tục tiếp theo. Do hạn chế về phần cứng, việc phân nhóm liên tục được sử dụng để giải mã có thể không bao gồm tất cả các yêu cầu. Tại thời điểm này, các yêu cầu được đưa vào hàng đợi xử lý và độ trễ suy luận bắt đầu tăng đáng kể chỉ với mức tăng thông lượng nhỏ.
Có thể tách các phân tích điểm chuẩn độ trễ LLM thành độ trễ điền trước, độ trễ giải mã và độ trễ hàng đợi. Thời gian tiêu thụ của mỗi thành phần này về cơ bản là khác nhau về bản chất: điền trước là tính toán một lần, quá trình giải mã diễn ra một lần cho mỗi mã thông báo trong chuỗi đầu ra và việc xếp hàng liên quan đến các quy trình xử lý khối của máy chủ. Khi nhiều yêu cầu đồng thời đang được xử lý, việc giải quyết độ trễ khỏi từng thành phần này trở nên khó khăn vì độ trễ mà bất kỳ yêu cầu khách hàng cụ thể nào gặp phải đều liên quan đến độ trễ hàng đợi do nhu cầu điền trước các yêu cầu đồng thời mới cũng như độ trễ hàng đợi do việc đưa vào tạo ra của yêu cầu trong quá trình giải mã hàng loạt. Vì lý do này, bài đăng này tập trung vào độ trễ xử lý từ đầu đến cuối. Điểm uốn trong đường cong độ trễ-thông lượng xảy ra tại điểm bão hòa, nơi độ trễ của hàng đợi bắt đầu tăng đáng kể. Hiện tượng này xảy ra đối với bất kỳ máy chủ suy luận mô hình nào và được điều khiển bởi các thông số kỹ thuật của bộ tăng tốc.
Các yêu cầu chung trong quá trình triển khai bao gồm đáp ứng thông lượng yêu cầu tối thiểu, độ trễ tối đa cho phép, chi phí mỗi giờ tối đa và chi phí tối đa để tạo ra 1 triệu mã thông báo. Bạn nên đưa ra các yêu cầu này đối với tải trọng đại diện cho yêu cầu của người dùng cuối. Một thiết kế để đáp ứng các yêu cầu này cần xem xét nhiều yếu tố, bao gồm kiến trúc mô hình cụ thể, kích thước của mô hình, loại phiên bản và số lượng phiên bản (tỷ lệ theo chiều ngang). Trong các phần sau, chúng tôi tập trung vào việc triển khai các điểm cuối để giảm thiểu độ trễ, tối đa hóa thông lượng và giảm thiểu chi phí. Phân tích này xem xét tổng số 512 mã thông báo và 256 mã thông báo đầu ra.
Giảm thiểu độ trễ
Độ trễ là một yêu cầu quan trọng trong nhiều trường hợp sử dụng thời gian thực. Trong bảng sau, chúng tôi xem xét độ trễ tối thiểu cho từng mô hình và từng loại phiên bản. Bạn có thể đạt được độ trễ tối thiểu bằng cách cài đặt MAX_CONCURRENT_REQUESTS = 1.
| Độ trễ tối thiểu (ms/mã thông báo) | |||||
| ID mô hình | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lạc đà 2 7B | 33 | 17 | 18 | 20 | - |
| Llama 2 7B Trò chuyện | 33 | 17 | 18 | 20 | - |
| Lạc đà 2 13B | - | 22 | 23 | 23 | - |
| Llama 2 13B Trò chuyện | - | 23 | 23 | 23 | - |
| Lạc đà 2 70B | - | - | 57 | 43 | - |
| Llama 2 70B Trò chuyện | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Hướng dẫn Mistral 7B | 35 | - | - | - | - |
| Hỗn hợp 8x7B | - | - | 33 | 27 | - |
| Chim Ưng 7B | 33 | - | - | - | - |
| Falcon 7B Hướng dẫn | 33 | - | - | - | - |
| Chim Ưng 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Hướng dẫn | - | 53 | 33 | 28 | - |
| Chim Ưng 180B | - | - | - | - | 42 |
| Trò chuyện Falcon 180B | - | - | - | - | 42 |
Để đạt được độ trễ tối thiểu cho một mô hình, bạn có thể sử dụng mã sau đây trong khi thay thế ID mô hình và loại phiên bản mong muốn:
Lưu ý rằng số lượng độ trễ thay đổi tùy thuộc vào số lượng mã thông báo đầu vào và đầu ra. Tuy nhiên quá trình triển khai vẫn giữ nguyên ngoại trừ các biến môi trường MAX_INPUT_TOKENS và MAX_TOTAL_TOKENS. Ở đây, các biến môi trường này được đặt để giúp đảm bảo các yêu cầu về độ trễ của điểm cuối vì các chuỗi đầu vào lớn hơn có thể vi phạm yêu cầu về độ trễ. Lưu ý rằng SageMaker JumpStart đã cung cấp các biến môi trường tối ưu khác khi chọn loại phiên bản; ví dụ: sử dụng ml.g5.12xlarge sẽ đặt SM_NUM_GPUS đến 4 trong môi trường mô hình.
Tối đa hóa thông lượng
Trong phần này, chúng tôi tối đa hóa số lượng mã thông báo được tạo mỗi giây. Điều này thường đạt được ở mức tối đa các yêu cầu đồng thời hợp lệ cho mô hình và loại phiên bản. Trong bảng sau, chúng tôi báo cáo thông lượng đạt được ở giá trị yêu cầu đồng thời lớn nhất đạt được trước khi gặp phải thời gian chờ gọi SageMaker cho bất kỳ yêu cầu nào.
| Thông lượng tối đa (mã thông báo/giây), Yêu cầu đồng thời | |||||
| ID mô hình | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| Lạc đà 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Llama 2 7B Trò chuyện | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lạc đà 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Llama 2 13B Trò chuyện | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lạc đà 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Llama 2 70B Trò chuyện | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Hướng dẫn Mistral 7B | 986 (128) | - | - | - | - |
| Hỗn hợp 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Chim Ưng 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Hướng dẫn | 1313 (128) | - | - | - | - |
| Chim Ưng 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Hướng dẫn | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Chim Ưng 180B | - | - | - | - | 1100 (128) |
| Trò chuyện Falcon 180B | - | - | - | - | 1081 (128) |
Để đạt được thông lượng tối đa cho một mô hình, bạn có thể sử dụng mã sau:
Lưu ý rằng số lượng yêu cầu đồng thời tối đa tùy thuộc vào loại mô hình, loại phiên bản, số lượng mã thông báo đầu vào tối đa và số lượng mã thông báo đầu ra tối đa. Vì vậy, bạn nên thiết lập các thông số này trước khi thiết lập MAX_CONCURRENT_REQUESTS.
Cũng lưu ý rằng người dùng quan tâm đến việc giảm thiểu độ trễ thường mâu thuẫn với người dùng quan tâm đến việc tối đa hóa thông lượng. Cái trước quan tâm đến phản hồi theo thời gian thực, trong khi cái sau quan tâm đến việc xử lý hàng loạt sao cho hàng đợi điểm cuối luôn bão hòa, do đó giảm thiểu thời gian ngừng xử lý. Người dùng muốn tối đa hóa thông lượng dựa trên yêu cầu về độ trễ thường quan tâm đến việc vận hành ở đầu gối trong đường cong thông lượng có độ trễ.
Giảm thiểu chi phí
Tùy chọn đầu tiên để giảm thiểu chi phí liên quan đến việc giảm thiểu chi phí mỗi giờ. Với điều này, bạn có thể triển khai mô hình đã chọn trên phiên bản SageMaker với chi phí mỗi giờ thấp nhất. Để biết giá theo thời gian thực của phiên bản SageMaker, hãy tham khảo Định giá của Amazon SageMaker. Nói chung, loại phiên bản mặc định cho SageMaker JumpStart LLM là tùy chọn triển khai có chi phí thấp nhất.
Tùy chọn thứ hai để giảm thiểu chi phí liên quan đến việc giảm thiểu chi phí để tạo ra 1 triệu token. Đây là một phép biến đổi đơn giản của bảng mà chúng ta đã thảo luận trước đó để tối đa hóa thông lượng, trong đó trước tiên bạn có thể tính toán thời gian tính bằng giờ để tạo ra 1 triệu mã thông báo (1e6 / thông lượng / 3600). Sau đó, bạn có thể nhân thời gian này để tạo ra 1 triệu mã thông báo với mức giá mỗi giờ của phiên bản SageMaker được chỉ định.
Lưu ý rằng các phiên bản có chi phí mỗi giờ thấp nhất sẽ không giống với các phiên bản có chi phí tạo ra 1 triệu mã thông báo thấp nhất. Ví dụ: nếu các yêu cầu gọi không thường xuyên thì phiên bản có chi phí mỗi giờ thấp nhất có thể là tối ưu, trong khi đó trong các trường hợp điều tiết, chi phí thấp nhất để tạo ra một triệu mã thông báo có thể phù hợp hơn.
Sự cân bằng song song giữa Tensor và đa mô hình
Trong tất cả các phân tích trước đây, chúng tôi đã cân nhắc việc triển khai một bản sao mô hình duy nhất có mức độ song song tensor bằng với số lượng GPU trên loại phiên bản triển khai. Đây là hành vi SageMaker JumpStart mặc định. Tuy nhiên, như đã lưu ý trước đó, việc phân chia mô hình chỉ có thể cải thiện độ trễ và thông lượng của mô hình đến một giới hạn nhất định, vượt quá yêu cầu giao tiếp giữa các thiết bị sẽ chi phối thời gian tính toán. Điều này ngụ ý rằng việc triển khai nhiều mô hình có mức độ song song tensor thấp hơn trên một phiên bản thường có lợi hơn là một mô hình duy nhất có mức độ song song tensor cao hơn.
Tại đây, chúng tôi triển khai các điểm cuối Llama 2 7B và 13B trên các phiên bản ml.p4d.24xlarge với độ song song tensor (TP) là 1, 2, 4 và 8. Để rõ ràng về hành vi của mô hình, mỗi điểm cuối này chỉ tải một mô hình duy nhất.
| . | Thông lượng (mã thông báo/giây) | Độ trễ (ms/mã thông báo) | ||||||||||||||||||
| Yêu cầu đồng thời | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Bằng cấp TP | Lạc đà 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lạc đà 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Các phân tích trước đây của chúng tôi đã cho thấy lợi thế đáng kể về thông lượng trên các phiên bản ml.p4d.24xlarge, điều này thường dẫn đến hiệu suất tốt hơn về mặt chi phí để tạo ra 1 triệu mã thông báo trên dòng phiên bản g5 trong điều kiện tải yêu cầu đồng thời cao. Phân tích này chứng minh rõ ràng rằng bạn nên xem xét sự cân bằng giữa việc phân chia mô hình và sao chép mô hình trong một phiên bản duy nhất; nghĩa là, một mô hình được phân chia hoàn toàn thường không phải là cách sử dụng tài nguyên điện toán ml.p4d.24xlarge tốt nhất cho các dòng mô hình 7B và 13B. Trên thực tế, đối với dòng mô hình 7B, bạn có được thông lượng tốt nhất cho một bản sao mô hình duy nhất có độ song song tensor là 4 thay vì 8.
Từ đây, bạn có thể ngoại suy rằng cấu hình thông lượng cao nhất cho mô hình 7B bao gồm mức song song tensor là 1 với tám bản sao mô hình và cấu hình thông lượng cao nhất cho mô hình 13B có thể là mức song song tensor là 2 với bốn bản sao mô hình. Để tìm hiểu thêm về cách thực hiện điều này, hãy tham khảo Giảm chi phí triển khai mô hình trung bình 50% bằng cách sử dụng các tính năng mới nhất của Amazon SageMaker, thể hiện việc sử dụng các điểm cuối dựa trên thành phần suy luận. Do các kỹ thuật cân bằng tải, định tuyến máy chủ và chia sẻ tài nguyên CPU, bạn có thể không đạt được mức cải thiện thông lượng hoàn toàn bằng số lượng bản sao nhân với thông lượng cho một bản sao.
Chia tỷ lệ ngang
Như đã quan sát trước đó, mỗi hoạt động triển khai điểm cuối đều có giới hạn về số lượng yêu cầu đồng thời tùy thuộc vào số lượng mã thông báo đầu vào và đầu ra cũng như loại phiên bản. Nếu điều này không đáp ứng yêu cầu về thông lượng hoặc yêu cầu đồng thời, bạn có thể mở rộng quy mô để sử dụng nhiều phiên bản phía sau điểm cuối đã triển khai. SageMaker tự động thực hiện cân bằng tải các truy vấn giữa các phiên bản. Ví dụ: đoạn mã sau triển khai một điểm cuối được hỗ trợ bởi ba phiên bản:
Bảng sau đây cho thấy mức tăng thông lượng theo hệ số số phiên bản của mô hình Llama 2 7B.
| . | . | Thông lượng (mã thông báo/giây) | Độ trễ (ms/mã thông báo) | ||||||||||||||
| . | Yêu cầu đồng thời | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Số lượng phiên bản | Loại sơ thẩm | Tổng số token: 512, Số lượng token đầu ra: 256 | |||||||||||||||
| 1 | ml.g5.2xlarge | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xlarge | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xlarge | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Đáng chú ý, điểm yếu trong đường cong độ trễ-thông lượng dịch chuyển sang phải vì số lượng phiên bản cao hơn có thể xử lý số lượng yêu cầu đồng thời lớn hơn trong điểm cuối nhiều phiên bản. Đối với bảng này, giá trị yêu cầu đồng thời dành cho toàn bộ điểm cuối chứ không phải số lượng yêu cầu đồng thời mà mỗi phiên bản riêng lẻ nhận được.
Bạn cũng có thể sử dụng tính năng tự động điều chỉnh quy mô, một tính năng để giám sát khối lượng công việc của mình và tự động điều chỉnh công suất nhằm duy trì hiệu suất ổn định và có thể dự đoán được với chi phí thấp nhất có thể. Điều này nằm ngoài phạm vi của bài viết này. Để tìm hiểu thêm về tính năng tự động chia tỷ lệ, hãy tham khảo Định cấu hình điểm cuối suy luận tự động thay đổi quy mô trong Amazon SageMaker.
Gọi điểm cuối với các yêu cầu đồng thời
Giả sử bạn có một loạt truy vấn lớn mà bạn muốn sử dụng để tạo phản hồi từ mô hình đã triển khai trong điều kiện thông lượng cao. Ví dụ: trong khối mã sau, chúng tôi biên soạn danh sách 1,000 tải trọng, với mỗi tải trọng yêu cầu tạo 100 mã thông báo. Tổng cộng, chúng tôi đang yêu cầu tạo ra 100,000 token.
Khi gửi một số lượng lớn yêu cầu tới API thời gian chạy SageMaker, bạn có thể gặp phải lỗi điều tiết. Để giảm thiểu điều này, bạn có thể tạo ứng dụng khách thời gian chạy SageMaker tùy chỉnh để tăng số lần thử lại. Bạn có thể cung cấp đối tượng phiên SageMaker kết quả cho JumpStartModel nhà xây dựng hoặc sagemaker.predictor.retrieve_default nếu bạn muốn đính kèm một yếu tố dự đoán mới vào điểm cuối đã được triển khai. Trong đoạn mã sau, chúng tôi sử dụng đối tượng phiên này khi triển khai mô hình Llama 2 với cấu hình SageMaker JumpStart mặc định:
Điểm cuối được triển khai này có MAX_CONCURRENT_REQUESTS = 128 theo mặc định. Trong khối tiếp theo, chúng tôi sử dụng thư viện tương lai đồng thời để lặp lại việc gọi điểm cuối cho tất cả các tải trọng có 128 luồng công việc. Tối đa, điểm cuối sẽ xử lý 128 yêu cầu đồng thời và bất cứ khi nào yêu cầu trả về phản hồi, người thực thi sẽ ngay lập tức gửi yêu cầu mới đến điểm cuối.
Điều này dẫn đến việc tạo ra tổng cộng 100,000 mã thông báo với thông lượng 1255 mã thông báo/giây trên một phiên bản ml.g5.2xlarge duy nhất. Việc này mất khoảng 80 giây để xử lý.
Lưu ý rằng giá trị thông lượng này khác biệt đáng kể so với thông lượng tối đa cho Llama 2 7B trên ml.g5.2xlarge trong các bảng trước của bài đăng này (486 mã thông báo/giây ở 64 yêu cầu đồng thời). Điều này là do tải trọng đầu vào sử dụng 8 mã thông báo thay vì 256, số lượng mã thông báo đầu ra là 100 thay vì 256 và số lượng mã thông báo nhỏ hơn cho phép thực hiện 128 yêu cầu đồng thời. Đây là lời nhắc nhở cuối cùng rằng tất cả các số liệu về độ trễ và thông lượng đều phụ thuộc vào tải trọng! Việc thay đổi số lượng mã thông báo tải trọng sẽ ảnh hưởng đến quy trình tạo khối trong quá trình phân phối mô hình, do đó sẽ ảnh hưởng đến thời gian điền trước, giải mã và xếp hàng mới nổi cho ứng dụng của bạn.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày điểm chuẩn của LLM SageMaker JumpStart, bao gồm Llama 2, Mistral và Falcon. Chúng tôi cũng đã trình bày hướng dẫn để tối ưu hóa độ trễ, thông lượng và chi phí cho cấu hình triển khai điểm cuối của bạn. Bạn có thể bắt đầu bằng cách chạy sổ tay liên quan để đánh giá trường hợp sử dụng của bạn.
Về các tác giả
 Tiến sĩ Kyle Ulrich là Nhà khoa học ứng dụng của nhóm Amazon SageMaker JumpStart. Lĩnh vực nghiên cứu của ông bao gồm các thuật toán học máy có thể mở rộng, thị giác máy tính, chuỗi thời gian, phi tham số Bayesian và quy trình Gaussian. Tiến sĩ của anh ấy đến từ Đại học Duke và anh ấy đã xuất bản các bài báo trên NeurIPS, Cell và Neuron.
Tiến sĩ Kyle Ulrich là Nhà khoa học ứng dụng của nhóm Amazon SageMaker JumpStart. Lĩnh vực nghiên cứu của ông bao gồm các thuật toán học máy có thể mở rộng, thị giác máy tính, chuỗi thời gian, phi tham số Bayesian và quy trình Gaussian. Tiến sĩ của anh ấy đến từ Đại học Duke và anh ấy đã xuất bản các bài báo trên NeurIPS, Cell và Neuron.
 Dr. Vivek Madan là một Nhà Khoa học Ứng dụng của nhóm Amazon SageMaker JumpStart. Ông lấy bằng Tiến sĩ tại Đại học Illinois tại Urbana-Champaign và là Nhà nghiên cứu Sau Tiến sĩ tại Georgia Tech. Anh ấy là một nhà nghiên cứu tích cực về học máy và thiết kế thuật toán và đã xuất bản các bài báo trong các hội nghị EMNLP, ICLR, COLT, FOCS và SODA.
Dr. Vivek Madan là một Nhà Khoa học Ứng dụng của nhóm Amazon SageMaker JumpStart. Ông lấy bằng Tiến sĩ tại Đại học Illinois tại Urbana-Champaign và là Nhà nghiên cứu Sau Tiến sĩ tại Georgia Tech. Anh ấy là một nhà nghiên cứu tích cực về học máy và thiết kế thuật toán và đã xuất bản các bài báo trong các hội nghị EMNLP, ICLR, COLT, FOCS và SODA.
 Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao của Amazon SageMaker JumpStart và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
Tiến sĩ Ashish Khetan là Nhà khoa học ứng dụng cấp cao của Amazon SageMaker JumpStart và giúp phát triển các thuật toán máy học. Ông lấy bằng Tiến sĩ tại Đại học Illinois Urbana-Champaign. Ông là một nhà nghiên cứu tích cực về học máy và suy luận thống kê, đồng thời đã xuất bản nhiều bài báo tại các hội nghị NeurIPS, ICML, ICLR, JMLR, ACL và EMNLP.
 João Moura là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao tại AWS. João giúp khách hàng của AWS – từ các công ty khởi nghiệp nhỏ đến doanh nghiệp lớn – đào tạo và triển khai các mô hình lớn một cách hiệu quả, đồng thời xây dựng nền tảng ML trên AWS một cách rộng rãi hơn.
João Moura là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao tại AWS. João giúp khách hàng của AWS – từ các công ty khởi nghiệp nhỏ đến doanh nghiệp lớn – đào tạo và triển khai các mô hình lớn một cách hiệu quả, đồng thời xây dựng nền tảng ML trên AWS một cách rộng rãi hơn.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

