Temel modeller (FM'ler), geniş bir etiketlenmemiş ve genelleştirilmiş veri kümeleri yelpazesi üzerinde eğitilmiş büyük makine öğrenimi (ML) modelleridir. Adından da anlaşılacağı gibi FM'ler, daha özelleştirilmiş alt uygulamalar oluşturmak için temel sağlar ve uyarlanabilirlikleri açısından benzersizdir. Doğal dil işleme, görüntüleri sınıflandırma, eğilimleri tahmin etme, duyarlılığı analiz etme ve soruları yanıtlama gibi çok çeşitli farklı görevleri gerçekleştirebilirler. Bu ölçek ve genel amaçlı uyarlanabilirlik, FM'leri geleneksel makine öğrenimi modellerinden farklı kılan şeydir. FM'ler çok modludur; metin, video, ses ve resim gibi farklı veri türleriyle çalışırlar. Büyük dil modelleri (LLM'ler) bir FM türüdür ve çok miktarda metin verisi üzerinde önceden eğitilir ve genellikle metin oluşturma, akıllı sohbet robotları veya özetleme gibi uygulama kullanımlarına sahiptir.
Veri akışı, çeşitli ve güncel bilgilerin sürekli akışını kolaylaştırarak modellerin uyum sağlama ve daha doğru, bağlamsal olarak anlamlı çıktılar üretme yeteneğini geliştirir. Akış verilerinin bu dinamik entegrasyonu, üretken yapay zeka uygulamaların değişen koşullara anında yanıt vermesini, uyarlanabilirliğini ve çeşitli görevlerdeki genel performansını artırmasını sağlar.
Bunu daha iyi anlamak için gezginlerin seyahat rezervasyonlarına yardımcı olan bir sohbet robotu hayal edin. Bu senaryoda, sohbet robotunun havayolu envanterine, uçuş durumuna, otel envanterine, en son fiyat değişikliklerine ve daha fazlasına gerçek zamanlı erişmesi gerekiyor. Bu veriler genellikle üçüncü taraflardan gelir ve geliştiricilerin bu verileri almanın ve veri değişikliklerini gerçekleştiği anda işlemenin bir yolunu bulması gerekir.
Toplu işleme bu senaryoya en uygun seçenek değildir. Veriler hızlı bir şekilde değiştiğinde, bunların toplu olarak işlenmesi eski verilerin chatbot tarafından kullanılmasına neden olabilir ve bu da müşteriye yanlış bilgiler sunarak genel müşteri deneyimini etkileyebilir. Ancak akış işleme, sohbet robotunun gerçek zamanlı verilere erişmesini ve kullanılabilirlik ve fiyattaki değişikliklere uyum sağlamasını sağlayarak müşteriye en iyi rehberliği sağlayabilir ve müşteri deneyimini geliştirebilir.
Başka bir örnek, FM'lerin bir sistemin gerçek zamanlı dahili ölçümlerini izlediği ve uyarılar ürettiği yapay zeka odaklı gözlemlenebilirlik ve izleme çözümüdür. Model bir anormallik veya anormal bir metrik değer bulduğunda derhal bir uyarı üretmeli ve operatörü bilgilendirmelidir. Ancak bu kadar önemli verilerin değeri zamanla önemli ölçüde azalır. Bu bildirimlerin ideal olarak saniyeler içinde veya hatta gerçekleşirken alınması gerekir. Operatörler bu bildirimleri olay gerçekleştikten dakikalar veya saatler sonra alırsa, bu tür bir analiz eyleme geçirilemez ve potansiyel olarak değerini kaybetmiş olur. Benzer kullanım örneklerini perakende, otomobil üretimi, enerji ve finans sektörü gibi diğer sektörlerde de bulabilirsiniz.
Bu yazıda, gerçek zamanlı doğası nedeniyle veri akışının neden üretken yapay zeka uygulamalarının önemli bir bileşeni olduğunu tartışıyoruz. Aşağıdaki gibi AWS veri akışı hizmetlerinin değerini tartışıyoruz: Apache Kafka için Amazon Tarafından Yönetilen Akış (Amazon MSK), Amazon Kinesis Veri Akışları, Apache Flink için Amazon Yönetilen Hizmeti, ve Amazon Kinesis Veri İtfaiyesi üretken yapay zeka uygulamaları oluşturmada.
Bağlam içi öğrenme
Yüksek Lisans'lar belirli bir noktaya ait verilerle eğitilir ve çıkarım zamanında yeni verilere erişme konusunda doğal bir yeteneğe sahip değildir. Yeni veriler ortaya çıktıkça, modele sürekli olarak ince ayar yapmanız veya daha fazla eğitim vermeniz gerekecektir. Bu sadece pahalı bir işlem değil, aynı zamanda pratikte çok sınırlayıcıdır çünkü yeni veri üretim hızı, ince ayar hızının çok üstündedir. Ek olarak, Yüksek Lisans'lar bağlamsal anlayıştan yoksundur ve yalnızca eğitim verilerine güvenirler ve bu nedenle halüsinasyonlara eğilimlidirler. Bu, akıcı, tutarlı ve sözdizimsel olarak sağlam ancak gerçekte yanlış bir yanıt üretebilecekleri anlamına gelir. Ayrıca alakadan, kişiselleştirmeden ve bağlamdan da yoksundurlar.
Bununla birlikte LLM'ler, model ağırlıklarını değiştirmeden daha doğru yanıt vermek için bağlamdan aldıkları verilerden öğrenme kapasitesine sahiptir. Buna denir bağlam içi öğrenmeve kişiselleştirilmiş yanıtlar üretmek veya kuruluş politikaları bağlamında doğru yanıtlar sağlamak için kullanılabilir.
Örneğin, bir sohbet robotunda veri olayları, bir uçuş ve otel envanteriyle veya sürekli olarak bir akışlı depolama motoruna alınan fiyat değişiklikleriyle ilgili olabilir. Ayrıca veri olayları, bir akış işlemcisi kullanılarak filtrelenir, zenginleştirilir ve tüketilebilir bir formata dönüştürülür. Sonuç, en son anlık görüntü sorgulanarak uygulamaya sunulur. Anlık görüntü, akış işleme yoluyla sürekli olarak güncellenir; bu nedenle güncel veriler, modele gönderilen kullanıcı istemi bağlamında sağlanır. Bu, modelin fiyat ve bulunabilirlikteki en son değişikliklere uyum sağlamasına olanak tanır. Aşağıdaki şemada temel bir bağlam içi öğrenme iş akışı gösterilmektedir.
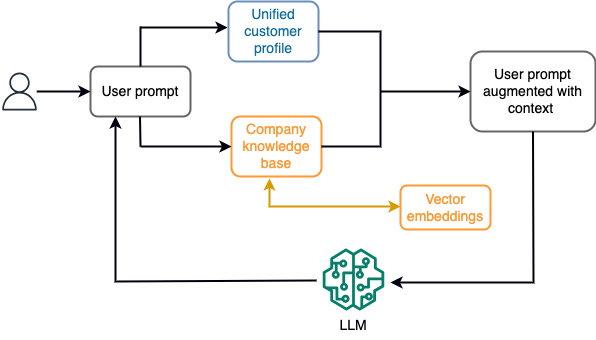
Yaygın olarak kullanılan bağlam içi öğrenme yaklaşımı, Alma Artırılmış Üretim (RAG) adı verilen bir tekniğin kullanılmasıdır. RAG'da, kullanıcı sorusuyla birlikte en alakalı politika ve müşteri kayıtları gibi ilgili bilgileri istemlere sunarsınız. Bu şekilde LLM, bağlam olarak sağlanan ek bilgileri kullanarak kullanıcı sorusuna bir yanıt üretir. RAG hakkında daha fazla bilgi edinmek için bkz. Amazon SageMaker JumpStart'ta temel modellerle Retrieval Augmented Generation kullanarak soru yanıtlama.
RAG tabanlı bir üretken yapay zeka uygulaması, yalnızca eğitim verilerine ve bilgi tabanındaki ilgili belgelere dayalı olarak genel yanıtlar üretebilir. Uygulamadan neredeyse gerçek zamanlı kişiselleştirilmiş bir yanıt beklendiğinde bu çözüm yetersiz kalıyor. Örneğin, bir seyahat sohbet robotunun kullanıcının mevcut rezervasyonlarını, mevcut otel ve uçuş envanterini ve daha fazlasını dikkate alması beklenir. Ayrıca, ilgili müşteri kişisel verileri (genellikle birleşik müşteri profili) genellikle değişebilir. Üretken yapay zekanın kullanıcı profili veritabanını güncellemek için bir toplu işlem kullanılırsa müşteri, eski verilere dayalı olarak tatmin edici olmayan yanıtlar alabilir.
Bu yazıda, gerçek zamanlı erişimden birleşik müşteri profillerine ve kurumsal bilgi tabanına kadar bağlamla soru yanıtlama aracıları oluşturmak için kullanılan bir RAG çözümünü geliştirmek amacıyla akış işlemenin uygulanmasını tartışıyoruz.
Gerçek zamanlıya yakın müşteri profili güncellemeleri
Müşteri kayıtları genellikle bir kuruluş içindeki veri depolarına dağıtılır. Üretken yapay zeka uygulamanızın ilgili, doğru ve güncel bir müşteri profili sağlaması için, dağıtılmış veri depolarında kimlik çözümlemesi ve profil toplama gerçekleştirebilecek akışlı veri hatları oluşturmak hayati önem taşır. Akış işleri, sistemler arasında senkronize etmek için sürekli olarak yeni verileri alır ve zaman aralıklarında zenginleştirme, dönüşüm, birleştirme ve toplama işlemlerini daha verimli bir şekilde gerçekleştirebilir. Değişiklik verisi yakalama (CDC) olayları, kaynak kaydı, güncellemeler ve zaman, kaynak, sınıflandırma (ekleme, güncelleme veya silme) ve değişikliği başlatan kişi gibi meta veriler hakkında bilgiler içerir.
Aşağıdaki şemada, birleştirilmiş müşteri profilleri için CDC akış alımı ve işlenmesine yönelik örnek bir iş akışı gösterilmektedir.

Bu bölümde, RAG tabanlı üretken yapay zeka uygulamalarını desteklemek için gereken bir CDC akış modelinin ana bileşenlerini tartışıyoruz.
CDC akış alımı
CDC çoğaltıcı, bir kaynak sistemden veri değişikliklerini toplayan (genellikle işlem günlüklerini veya binlog'ları okuyarak) ve CDC olaylarını akışlı bir veri akışında veya konuda meydana geldikleri sırayla yazan bir işlemdir. Bu, aşağıdaki gibi araçlarla günlük tabanlı bir yakalamayı içerir: AWS Veritabanı Geçiş Hizmeti (AWS DMS) veya Apache Kafka bağlantısı için Debezium gibi açık kaynaklı bağlayıcılar. Apache Kafka Connect, Apache Kafka ortamının bir parçasıdır ve verilerin çeşitli kaynaklardan alınmasına ve çeşitli hedeflere teslim edilmesine olanak tanır. Apache Kafka bağlayıcınızı çalıştırabilirsiniz Amazon MSK Bağlantısı Apache Kafka kümesini yapılandırma, kurma ve çalıştırma konusunda endişelenmenize gerek kalmadan birkaç dakika içinde. Bağlayıcınızın derlenmiş kodunu yalnızca şuraya yüklemeniz gerekir: Amazon Basit Depolama Hizmeti (Amazon S3) ve bağlayıcınızı iş yükünüzün özel yapılandırmasıyla ayarlayın.
Veri değişikliklerini yakalamak için başka yöntemler de vardır. Örneğin, Amazon DinamoDB CDC verilerinin akışı için bir özellik sağlar Amazon DynamoDB Akışları veya Kinesis Veri Akışları. Amazon S3, bir çağrıyı başlatmak için bir tetikleyici sağlar AWS Lambda yeni bir belge kaydedildiğinde işlev görür.
Akış depolama
Akışlı depolama, CDC olaylarını işlenmeden önce depolamak için bir ara arabellek işlevi görür. Akış depolama, akış verileri için güvenilir depolama sağlar. Tasarım gereği, donanım veya düğüm arızalarına karşı yüksek oranda kullanılabilir ve dayanıklıdır ve olayların yazıldığı sırayı korur. Akış depolama, veri olaylarını kalıcı olarak veya belirli bir süre boyunca saklayabilir. Bu, bir arıza veya yeniden işleme ihtiyacı olması durumunda akış işlemcilerinin akışın bir kısmından okuma yapmasına olanak tanır. Kinesis Data Streams, veri akışlarını uygun ölçekte yakalamayı, işlemeyi ve depolamayı kolaylaştıran sunucusuz bir akış veri hizmetidir. Amazon MSK, Apache Kafka'yı çalıştırmak için AWS tarafından sağlanan, tam olarak yönetilen, yüksek düzeyde erişilebilir ve güvenli bir hizmettir.
Akış işleme
Akış işleme sistemleri, yüksek veri akışını yönetebilmek için paralellik sağlayacak şekilde tasarlanmalıdır. Giriş akışını birden çok işlem düğümünde çalışan birden çok görev arasında bölmeleri gerekir. Görevler bir işlemin sonucunu ağ üzerinden diğerine gönderebilmeli, birleştirme, filtreleme, zenginleştirme, toplama gibi işlemler yapılırken verilerin paralel olarak işlenmesi mümkün olmalıdır. Akış işleme uygulamaları, olayların geç gelebileceği veya doğru hesaplamanın sistem zamanından ziyade olayların meydana gelme zamanına dayandığı kullanım durumları için olayları olay zamanına göre işleyebilmelidir. Daha fazla bilgi için bkz. Zaman Kavramları: Olay Zamanı ve İşlem Süresi.
Akış süreçleri, sürekli olarak hedef sisteme çıktı olarak verilmesi gereken veri olayları biçiminde sonuçlar üretir. Hedef sistem, doğrudan süreçle veya aracı olarak depolama akışı yoluyla entegre olabilen herhangi bir sistem olabilir. Akış işleme için seçtiğiniz çerçeveye bağlı olarak, mevcut havuz konnektörlerine bağlı olarak hedef sistemler için farklı seçeneklere sahip olacaksınız. Sonuçları bir ara akış depolama alanına yazmaya karar verirseniz, olayları okuyan ve değişiklikleri hedef sisteme uygulayan (örneğin, Apache Kafka havuz bağlayıcısını çalıştıran) ayrı bir süreç oluşturabilirsiniz. Hangi seçeneği seçerseniz seçin, CDC verileri doğası gereği ekstra işlem gerektirir. CDC olayları güncellemeler veya silmeler hakkında bilgi taşıdığından bunların hedef sistemde doğru sırayla birleştirilmesi önemlidir. Değişiklikler yanlış sırayla uygulanırsa hedef sistem, kaynağıyla senkronize olmayacaktır.
Apache Flink'i düşük gecikme süresi ve yüksek verim yetenekleriyle bilinen güçlü bir akış işleme çerçevesidir. Olay zamanı işlemeyi, tam olarak bir kez işleme semantiğini ve yüksek hata toleransını destekler. Ayrıca CDC verilerine yerel destek olarak adlandırılan özel bir yapı aracılığıyla da destek sağlar. dinamik tablolar. Dinamik tablolar, kaynak veritabanı tablolarını taklit eder ve akış verilerinin sütunlu bir temsilini sağlar. Dinamik tablolardaki veriler, işlenen her olayla birlikte değişir. Yeni kayıtlar herhangi bir zamanda eklenebilir, güncellenebilir veya silinebilir. Dinamik tablolar, her kayıt işlemi (ekleme, güncelleme, silme) için ayrı ayrı uygulamanız gereken ekstra mantığı ortadan kaldırır. Daha fazla bilgi için bkz. Dinamik Tablolar.
İle Apache Flink için Amazon Yönetilen Hizmetiile Apache Flink işlerini çalıştırabilir ve diğer AWS hizmetleriyle entegrasyon sağlayabilirsiniz. Yönetilmesi gereken sunucular ve kümeler yok, kurulacak bilgi işlem ve depolama altyapısı da yok.
AWS Tutkal tamamen yönetilen bir çıkarma, dönüştürme ve yükleme (ETL) hizmetidir; bu, AWS'nin sizin için altyapı sağlama, ölçeklendirme ve bakım işlemlerini üstlendiği anlamına gelir. Her ne kadar öncelikle ETL yetenekleriyle bilinse de AWS Glue, Spark akış uygulamaları için de kullanılabilir. AWS Glue, CDC verilerini işlemek ve dönüştürmek için Kinesis Data Streams ve Amazon MSK gibi veri akışı hizmetleriyle etkileşime girebilir. AWS Glue ayrıca Lambda gibi diğer AWS hizmetleriyle de sorunsuz bir şekilde entegre olabilir. AWS Basamak İşlevlerive veri işleme işlem hatlarını oluşturmak ve yönetmek için size kapsamlı bir ekosistem sağlayan DynamoDB.
Birleşik müşteri profili
Müşteri profilinin çeşitli kaynak sistemlerde birleştirilmesinin üstesinden gelmek, sağlam veri hatlarının geliştirilmesini gerektirir. Tüm kayıtları tek bir veri deposuna getirip senkronize edebilecek veri hatlarına ihtiyacınız var. Bu veri deposu, kuruluşunuza RAG tabanlı üretken yapay zeka uygulamalarının operasyonel verimliliği için gereken bütünsel müşteri kayıtları görünümünü sağlar. Böyle bir veri deposu oluşturmak için yapılandırılmamış bir veri deposu en iyisi olacaktır.
Kimlik grafiği, çeşitli kaynaklardan gelen müşteri verilerini birleştirip bütünleştirdiği, veri doğruluğunu ve tekilleştirmeyi sağladığı, gerçek zamanlı güncellemeler sunduğu, sistemler arası içgörüleri birbirine bağladığı, kişiselleştirmeyi mümkün kıldığı, müşteri deneyimini geliştirdiği ve Mevzuat uyumluluğunu destekler. Bu birleştirilmiş müşteri profili, üretken yapay zeka uygulamasının müşterileri etkili bir şekilde anlayıp onlarla etkileşime geçmesini ve veri gizliliği düzenlemelerine uymasını sağlayarak sonuçta müşteri deneyimlerini geliştirir ve iş büyümesini hızlandırır. Kimlik grafiği çözümünüzü kullanarak oluşturabilirsiniz. Amazon Neptün, hızlı, güvenilir, tam olarak yönetilen bir grafik veritabanı hizmeti.
AWS, yapılandırılmamış anahtar/değer nesneleri için birkaç başka yönetilen ve sunucusuz NoSQL depolama hizmeti teklifi sunar. Amazon BelgesiDB (MongoDB uyumluluğuyla) hızlı, ölçeklenebilir, yüksek düzeyde kullanılabilir ve tam olarak yönetilen bir kuruluştur belge veritabanı yerel JSON iş yüklerini destekleyen hizmet. DynamoDB, kusursuz ölçeklenebilirlik ile hızlı ve öngörülebilir performans sağlayan, tam olarak yönetilen bir NoSQL veritabanı hizmetidir.
Gerçek zamanlıya yakın kurumsal bilgi tabanı güncellemeleri
Müşteri kayıtlarına benzer şekilde, şirket politikaları ve organizasyonel belgeler gibi dahili bilgi havuzları da depolama sistemleri arasında depolanır. Bu genellikle yapılandırılmamış verilerdir ve artımlı olmayan bir şekilde güncellenir. Yapay zeka uygulamaları için yapılandırılmamış verilerin kullanımı, metin dosyaları, görüntüler ve ses dosyaları gibi yüksek boyutlu verileri çok boyutlu sayısal olarak temsil etme tekniği olan vektör yerleştirmelerin kullanılmasıyla etkilidir.
AWS birkaç tane sağlar vektör motor hizmetleriGibi Amazon OpenSearch Sunucusuz, Amazon Kendrası, ve Amazon Aurora PostgreSQL-Uyumlu Sürüm vektör yerleştirmelerini depolamak için pgvector uzantısıyla. Üretken yapay zeka uygulamaları, kullanıcı istemini bir vektöre dönüştürerek ve bunu bağlamsal olarak ilgili bilgileri almak üzere vektör motorunu sorgulamak için kullanarak kullanıcı deneyimini geliştirebilir. Daha sonra hem bilgi istemi hem de alınan vektör verileri, daha kesin ve kişiselleştirilmiş bir yanıt almak için LLM'ye iletilir.
Aşağıdaki diyagramda vektör yerleştirmeleri için örnek bir akış işleme iş akışı gösterilmektedir.
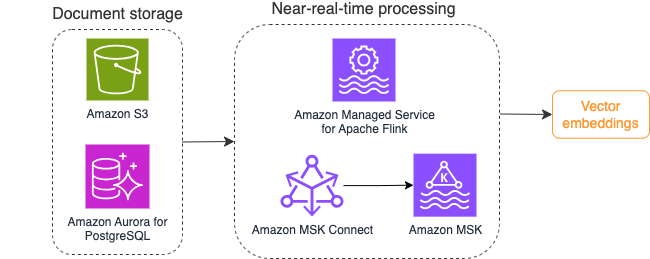
Bilgi tabanı içeriklerinin, vektör veri deposuna yazılmadan önce vektör yerleştirmelerine dönüştürülmesi gerekir. Amazon Ana Kayası or Amazon Adaçayı Yapıcı seçtiğiniz modele erişmenize ve bu dönüşüm için özel bir uç noktayı kullanıma sunmanıza yardımcı olabilir. Ayrıca bu uç noktalarla entegrasyon için LangChain gibi kütüphaneleri kullanabilirsiniz. Toplu işlem oluşturmak, bilgi tabanı içeriğinizi vektör verilerine dönüştürmenize ve bunu başlangıçta bir vektör veritabanında saklamanıza yardımcı olabilir. Ancak, vektör veritabanınızı bilgi tabanı içeriğinizdeki değişikliklerle senkronize etmek amacıyla belgeleri yeniden işlemek için bir aralığa güvenmeniz gerekir. Çok sayıda belge olduğunda bu süreç verimsiz olabilir. Bu aralıklar arasında, üretken AI uygulama kullanıcılarınız eski içeriğe göre yanıtlar alacak veya yeni içerik henüz vektörleştirilmediği için hatalı yanıt alacaktır.
Akış işleme bu zorluklar için ideal bir çözümdür. Başlangıçta mevcut belgelere göre olay üretir ve kaynak sistemi daha sonra izleyerek, meydana geldiği anda belge değişikliği olayı oluşturur. Bu olaylar akış deposunda saklanabilir ve bir akış işi tarafından işlenmeyi bekleyebilir. Bir akış işi bu olayları okur, belgenin içeriğini yükler ve içerikleri ilgili sözcük belirteçleri dizisine dönüştürür. Her jeton ayrıca, yerleşik bir FM'ye yapılan API çağrısı yoluyla vektör verilerine dönüşür. Sonuçlar depolama için bir havuz operatörü aracılığıyla vektör depolama alanına gönderilir.
Belgelerinizi depolamak için Amazon S3 kullanıyorsanız Lambda için S3 nesne değişikliği tetikleyicilerini temel alan bir olay kaynağı mimarisi oluşturabilirsiniz. Lambda işlevi, istenen formatta bir etkinlik oluşturabilir ve bunu akış depolama alanınıza yazabilir.
Akış işi olarak çalıştırmak için Apache Flink'i de kullanabilirsiniz. Apache Flink, başlangıçta mevcut dosyaları keşfedebilen ve içeriklerini okuyabilen yerel FileSystem kaynak bağlayıcısını sağlar. Bundan sonra, dosya sisteminizi yeni dosyalar için sürekli olarak izleyebilir ve içeriklerini yakalayabilir. Bağlayıcı, düz metin, Avro, CSV, Parquet ve daha fazlası biçimindeki Amazon S3 veya HDFS gibi dağıtılmış dosya sistemlerinden bir dizi dosyanın okunmasını destekler ve bir akış kaydı üretir. Tamamen yönetilen bir hizmet olarak Apache Flink için Yönetilen Hizmet, Flink işlerinin dağıtımı ve bakımının operasyonel yükünü ortadan kaldırarak akış uygulamalarınızı oluşturmaya ve ölçeklendirmeye odaklanmanıza olanak tanır. Amazon MSK veya Kinesis Data Streams gibi AWS akış hizmetlerine kusursuz entegrasyon sayesinde otomatik ölçeklendirme, güvenlik ve esneklik gibi özellikler sunarak gerçek zamanlı akış verilerinin işlenmesi için güvenilir ve verimli Flink uygulamaları sağlar.
DevOps tercihinize bağlı olarak akış kayıtlarını depolamak için Kinesis Veri Akışları veya Amazon MSK arasında seçim yapabilirsiniz. Kinesis Data Streams, özel akışlı veri uygulamaları oluşturma ve yönetmenin karmaşıklığını basitleştirerek altyapı bakımı yerine verilerinizden içgörü elde etmeye odaklanmanıza olanak tanır. Apache Kafka kullanan müşteriler, AWS ortamında Apache Kafka kümelerinin denetlenmesindeki basitlik, ölçeklenebilirlik ve güvenilirlik nedeniyle sıklıkla Amazon MSK'yı tercih ediyor. Tam olarak yönetilen bir hizmet olarak Amazon MSK, Apache Kafka kümelerinin dağıtımı ve bakımıyla ilgili operasyonel karmaşıklıkları üstlenerek akış uygulamalarınızı oluşturmaya ve genişletmeye odaklanmanıza olanak tanır.
RESTful API entegrasyonu bu sürecin doğasına uygun olduğundan, hataları izlemek ve başarısız isteği yeniden denemek için RESTful API çağrıları aracılığıyla durum bilgisi olan bir zenginleştirme modelini destekleyen bir çerçeveye ihtiyacınız vardır. Apache Flink yine bellek hızında durum bilgisi olan işlemler yapabilen bir çerçevedir. Apache Flink aracılığıyla API çağrıları yapmanın en iyi yollarını anlamak için bkz. Amazon Kinesis Data Analytics for Apache Flink'te yaygın akış verisi zenginleştirme kalıpları.
Apache Flink, pgvector veya PostgreSQL için Amazon Aurora gibi vektör veri depolarına veri yazmak için yerel havuz bağlayıcıları sağlar. Amazon Açık Arama Hizmeti VectorDB ile. Alternatif olarak Flink işinin çıktısını (vektörleştirilmiş veriler) bir MSK konusuna veya Kinesis veri akışına yerleştirebilirsiniz. OpenSearch Hizmeti, Kinesis veri akışlarından veya MSK konularından yerel alım için destek sağlar. Daha fazla bilgi için bkz. Amazon OpenSearch Ingestion için kaynak olarak Amazon MSK'yı tanıtıyoruz ve Amazon Kinesis Data Streams'ten akış verileri yükleniyor.
Geri bildirim analitiği ve ince ayar
Veri operasyon yöneticilerinin ve AI/ML geliştiricilerinin, üretken AI uygulamasının ve kullanımdaki FM'lerin performansı hakkında fikir sahibi olması önemlidir. Bunu başarmak için, kullanıcı geri bildirimlerine ve çeşitli uygulama günlükleri ve ölçümlerine dayalı olarak önemli temel performans göstergesi (KPI) verilerini hesaplayan veri hatları oluşturmanız gerekir. Bu bilgi, paydaşların FM performansı, uygulama ve uygulamanızdan aldıkları desteğin kalitesine ilişkin genel kullanıcı memnuniyeti hakkında gerçek zamanlı bilgi edinmeleri açısından faydalıdır. Ayrıca FM'lerinizin etki alanına özel görevleri yerine getirme yeteneklerini geliştirmek amacıyla daha fazla ince ayar yapmak için konuşma geçmişini toplamanız ve saklamanız gerekir.
Bu kullanım durumu akış analitiği alanına çok iyi uyuyor. Uygulamanız her görüşmeyi akış depolama alanında saklamalıdır. Uygulamanız, kullanıcılara her yanıtın doğruluğuna ilişkin derecelendirmeleri ve genel memnuniyetleri hakkında bilgi verebilir. Bu veriler ikili seçim biçiminde veya serbest biçimli metin biçiminde olabilir. Bu veriler bir Kinesis veri akışında veya MSK konusunda saklanabilir ve gerçek zamanlı olarak KPI'lar oluşturmak için işlenebilir. Kullanıcıların duygu analizi için FM'leri kullanabilirsiniz. FM'ler her yanıtı analiz edebilir ve bir kullanıcı memnuniyeti kategorisi atayabilir.
Apache Flink'in mimarisi, zaman aralıklarında karmaşık veri toplamaya olanak tanır. Ayrıca veri olaylarının akışı üzerinden SQL sorgulama desteği de sağlar. Bu nedenle Apache Flink'i kullanarak ham kullanıcı girişlerini hızlı bir şekilde analiz edebilir ve tanıdık SQL sorguları yazarak gerçek zamanlı KPI'lar oluşturabilirsiniz. Daha fazla bilgi için bkz. Tablo API'si ve SQL.
İle Apache Flink Studio için Amazon Yönetilen Hizmetietkileşimli bir not defterinde standart SQL, Python ve Scala kullanarak Apache Flink akış işleme uygulamalarını oluşturabilir ve çalıştırabilirsiniz. Studio dizüstü bilgisayarlar Apache Zeppelin tarafından desteklenmektedir ve akış işleme motoru olarak Apache Flink'i kullanmaktadır. Studio dizüstü bilgisayarlar, veri akışlarındaki gelişmiş analitiği tüm beceri gruplarındaki geliştiricilerin erişimine açmak için bu teknolojileri sorunsuz bir şekilde birleştirir. Kullanıcı tanımlı işlevler (UDF'ler) desteğiyle Apache Flink, duygu analizi gibi karmaşık görevleri gerçekleştirmek için FM'ler gibi harici kaynaklarla entegre olacak özel operatörler oluşturmanıza olanak tanır. Çeşitli ölçümleri hesaplamak veya kullanıcı geri bildirimi ham verilerini kullanıcı duyarlılığı gibi ek bilgilerle zenginleştirmek için UDF'leri kullanabilirsiniz. Bu model hakkında daha fazla bilgi edinmek için bkz. GenAI, Flink, Apache Kafka ve Kinesis ile müşteri endişelerini gerçek zamanlı olarak proaktif bir şekilde ele alma.
Apache Flink Studio için Yönetilen Hizmet ile Studio dizüstü bilgisayarınızı tek tıklamayla bir akış işi olarak dağıtabilirsiniz. Çıktıyı tercih ettiğiniz depolama birimine göndermek veya bunu bir Kinesis veri akışında veya MSK konusunda hazırlamak için Apache Flink tarafından sağlanan yerel havuz bağlayıcılarını kullanabilirsiniz. Amazon Kırmızıya Kaydırma ve OpenSearch Hizmetinin her ikisi de analitik verileri depolamak için idealdir. Her iki motor da analiz için ayrı bir akış hattı aracılığıyla bir veri gölüne veya veri ambarına Kinesis Data Streams ve Amazon MSK'dan yerel alım desteği sağlar.
Amazon Redshift, geniş ölçekte en iyi fiyat-performans oranını sunmak için AWS tasarımlı donanım ve makine öğrenimini kullanarak veri ambarları ve veri gölleri genelinde yapılandırılmış ve yarı yapılandırılmış verileri analiz etmek için SQL'i kullanıyor. OpenSearch Hizmeti, OpenSearch Kontrol Panelleri ve Kibana (1.5 ila 7.10 sürümleri) tarafından desteklenen görselleştirme yetenekleri sunar.
Gerektiğinde FM'de ince ayar yapmak için bu analizin sonucunu kullanıcı istemi verileriyle birlikte kullanabilirsiniz. SageMaker, FM'lerinize ince ayar yapmanın en kolay yoludur. Amazon S3'ü SageMaker ile kullanmak, modellerinize ince ayar yapmak için güçlü ve kusursuz bir entegrasyon sağlar. Amazon S3, ölçeklenebilir ve dayanıklı bir nesne depolama çözümü olarak hizmet vererek büyük veri kümelerinin, eğitim verilerinin ve model yapılarının basit bir şekilde depolanmasına ve alınmasına olanak tanır. SageMaker, tüm makine öğrenimi yaşam döngüsünü basitleştiren, tam olarak yönetilen bir makine öğrenimi hizmetidir. Amazon S3'ü SageMaker için depolama arka ucu olarak kullanarak Amazon S3'ün ölçeklenebilirliğinden, güvenilirliğinden ve maliyet etkinliğinden faydalanabilir ve bunu SageMaker eğitim ve dağıtım yetenekleriyle sorunsuz bir şekilde entegre edebilirsiniz. Bu kombinasyon, verimli veri yönetimi sağlar, işbirliğine dayalı model geliştirmeyi kolaylaştırır ve makine öğrenimi iş akışlarının kolaylaştırılmış ve ölçeklenebilir olmasını sağlayarak, sonuçta makine öğrenimi sürecinin genel çevikliğini ve performansını artırır. Daha fazla bilgi için bkz. @remote dekoratörüyle Amazon SageMaker'da Falcon 7B ve diğer LLM'lere ince ayar yapın.
Apache Flink işleri, bir dosya sistemi havuzu bağlayıcısıyla verileri Amazon S3'e açık formattaki (JSON, Avro, Parquet ve daha fazlası gibi) veri nesneleri olarak teslim edebilir. Veri gölünüzü işlemsel bir veri gölü çerçevesi (Apache Hudi, Apache Iceberg veya Delta Lake gibi) kullanarak yönetmeyi tercih ederseniz, bu çerçevelerin tümü Apache Flink için özel bir bağlayıcı sağlar. Daha fazla ayrıntı için bkz. Amazon MSK Connect, Apache Flink ve Apache Hudi'yi kullanarak düşük gecikmeli bir kaynaktan veri gölü işlem hattı oluşturun.
Özet
RAG modelini temel alan üretken bir yapay zeka uygulaması için iki veri depolama sistemi oluşturmayı düşünmeniz ve bunları tüm kaynak sistemlerle güncel tutacak veri operasyonları oluşturmanız gerekir. Geleneksel toplu işler, üretken yapay zeka uygulamanızla entegre etmeniz gereken verilerin boyutunu ve çeşitliliğini işlemek için yeterli değildir. Kaynak sistemlerdeki değişikliklerin işlenmesindeki gecikmeler, hatalı yanıtlara neden olur ve üretken yapay zeka uygulamanızın verimliliğini azaltır. Veri akışı, çeşitli sistemlerdeki çeşitli veritabanlarından veri almanızı sağlar. Ayrıca birçok kaynaktaki verileri neredeyse gerçek zamanlı olarak verimli bir şekilde dönüştürmenize, zenginleştirmenize, birleştirmenize ve toplamanıza olanak tanır. Veri akışı, kullanıcıların uygulama yanıtlarına ilişkin gerçek zamanlı tepkilerini veya yorumlarını toplamak ve dönüştürmek için basitleştirilmiş bir veri mimarisi sağlayarak, modelin ince ayarı için sonuçları bir veri gölünde sunmanıza ve saklamanıza yardımcı olur. Veri akışı ayrıca yalnızca değişiklik olaylarını işleyerek veri hatlarını optimize etmenize yardımcı olur ve veri değişikliklerine daha hızlı ve verimli bir şekilde yanıt vermenize olanak tanır.
Hakkında daha fazla bilgi alın AWS veri akışı hizmetleri ve kendi veri akışı çözümünüzü oluşturmaya başlayın.
Yazarlar Hakkında
 Ali Alem AWS'de Akış Uzmanı Çözüm Mimarıdır. Ali, AWS müşterilerine en iyi mimari uygulamalar konusunda tavsiyelerde bulunur ve güvenilir, güvenli, verimli ve uygun maliyetli gerçek zamanlı analitik veri sistemleri tasarlamalarına yardımcı olur. Müşterinin kullanım durumlarından geriye doğru çalışır ve iş sorunlarını çözmek için veri çözümleri tasarlar. Ali, AWS'ye katılmadan önce, uygulama modernizasyon yolculuklarında ve Bulut'a geçişlerinde birçok kamu sektörü müşterisini ve AWS danışmanlık iş ortağını destekledi.
Ali Alem AWS'de Akış Uzmanı Çözüm Mimarıdır. Ali, AWS müşterilerine en iyi mimari uygulamalar konusunda tavsiyelerde bulunur ve güvenilir, güvenli, verimli ve uygun maliyetli gerçek zamanlı analitik veri sistemleri tasarlamalarına yardımcı olur. Müşterinin kullanım durumlarından geriye doğru çalışır ve iş sorunlarını çözmek için veri çözümleri tasarlar. Ali, AWS'ye katılmadan önce, uygulama modernizasyon yolculuklarında ve Bulut'a geçişlerinde birçok kamu sektörü müşterisini ve AWS danışmanlık iş ortağını destekledi.
 İmtiaz (Taz) Sayed AWS'de Analitik Alanında Dünya Çapında Teknoloji Lideridir. Veri ve analitikle ilgili her konuda toplulukla etkileşimde bulunmaktan hoşlanıyor. Kendisine şu adresten ulaşılabilir: LinkedIn.
İmtiaz (Taz) Sayed AWS'de Analitik Alanında Dünya Çapında Teknoloji Lideridir. Veri ve analitikle ilgili her konuda toplulukla etkileşimde bulunmaktan hoşlanıyor. Kendisine şu adresten ulaşılabilir: LinkedIn.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

