SmugMug operates two very large online photo platforms, SmugMug and Flickr, enabling more than 100 million customers to safely store, search, share, and sell tens of billions of photos. Customers uploading and searching through decades of photos helped turn search into critical infrastructure, growing steadily since SmugMug first used Amazon CloudSearch in 2012, followed by Amazon OpenSearch Service since 2018, after reaching billions of documents and terabytes of search storage.
Here, Lee Shepherd, SmugMug Staff Engineer, shares SmugMug’s search architecture used to publish, backfill, and mirror live traffic to multiple clusters. SmugMug uses these pipelines to benchmark, validate, and migrate to new configurations, including Graviton based r6gd.2xlarge instances from i3.2xlarge, along with testing Amazon OpenSearch Serverless. We cover three pipelines used for publishing, backfilling, and querying without introducing spiky unrealistic traffic patterns, and without any impact on production services.
There are two main architectural pieces critical to the process:
- A durable source of truth for index data. It’s best practice and part of our backup strategy to have a durable store beyond the OpenSearch index, and Amazon DynamoDB provides scalability and integration with AWS Lambda that simplifies a lot of the process. We use DynamoDB for other non-search services, so this was a natural fit.
- A Lambda function for publishing data from the source of truth into OpenSearch. Using function aliases helps run multiple configurations of the same Lambda function at the same time and is key to keeping data in sync.
Publishing
The publishing pipeline is driven from events like a user entering keywords or captions, new uploads, or label detection through Amazon Rekognition. These events are processed, combining data from a few other asset stores like Amazon Aurora MySQL Compatible Edition and Amazon Simple Storage Service (Amazon S3), before writing a single item into DynamoDB.
Writing to DynamoDB invokes a Lambda publishing function, through the DynamoDB Streams Kinesis Adapter, that takes a batch of updated items from DynamoDB and indexes them into OpenSearch. There are other benefits to using the DynamoDB Streams Kinesis Adapter such as reducing the number of concurrent Lambdas required.
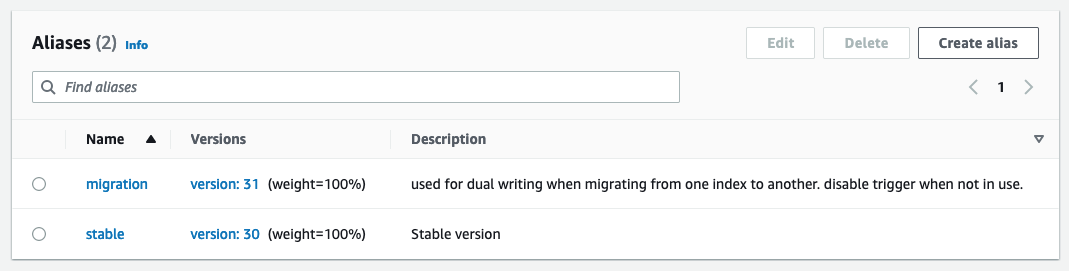
The publishing Lambda function uses environment variables to determine what OpenSearch domain and index to publish to. A production alias is configured to write to the production OpenSearch domain, off of the DynamoDB table or Kinesis Stream
When testing new configurations or migrating, a migration alias is configured to write to the new OpenSearch domain but use the same trigger as the production alias. This enables dual indexing of data to both OpenSearch Service domains simultaneously.

Here’s an example of the DynamoDB table schema:
The ‘LastUpdated’ value is used as the document version when indexing, allowing OpenSearch to reject any out-of-order updates.
Backfilling
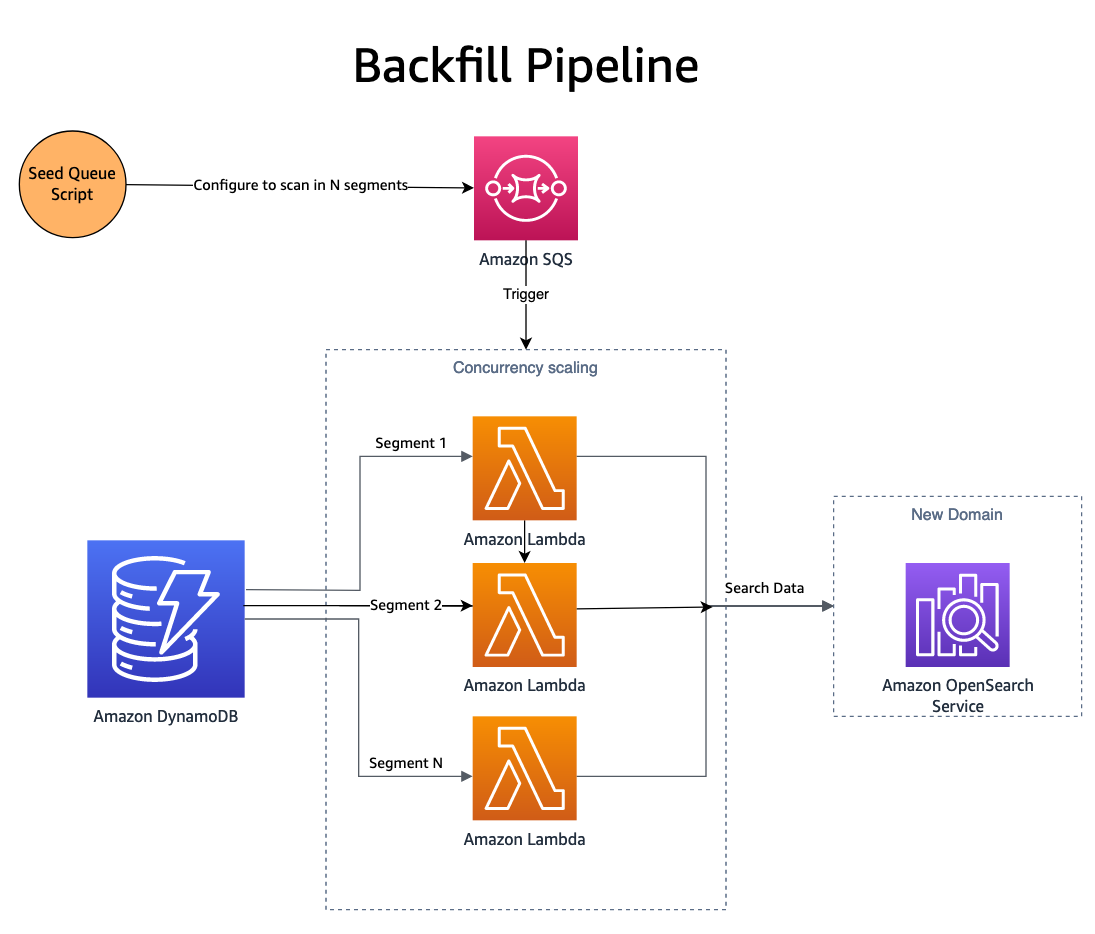
Now that changes are being published to both domains, the new domain (index) needs to be backfilled with historical data. To backfill a newly created index, a combination of Amazon Simple Queue Service (Amazon SQS) and DynamoDB is used. A script populates an SQS queue with messages that contain instructions for parallel scanning a segment of the DynamoDB table.
The SQS queue launches a Lambda function that reads the message instructions, fetches a batch of items from the corresponding segment of the DynamoDB table, and writes them into an OpenSearch index. New messages are written to the SQS queue to keep track of progress through the segment. After the segment completes, no more messages are written to the SQS queue and the process stops itself.
Concurrency is determined by the number of segments, with additional controls provided by Lambda concurrency scaling. SmugMug is able to index more than 1 billion documents per hour on their OpenSearch configuration while incurring zero impact to the production domain.
A NodeJS AWS-SDK based script is used to seed the SQS queue. Here’s a snippet of the SQS configuration script’s options:
Along with the format of the resulting SQS message:
Mirroring
Last, our mirrored search query results run by sending an OpenSearch query to an SQS queue, in addition to our production domain. The SQS queue launches a Lambda function that replays the query to the replica domain. The search results from these requests are not sent to any user but allow replicating production load on the OpenSearch service under test without impact to production systems or customers.

Conclusion
When evaluating a new OpenSearch domain or configuration, the main metrics we are interested in are query latency performance, namely the took latencies (latencies per time), and most importantly latencies for searching. In our move to Graviton R6gd, we saw about 40 percent lower P50-P99 latencies, along with similar gains in CPU usage compared to i3’s (ignoring Graviton’s lower costs). Another welcome benefit was the more predictable and monitorable JVM memory pressure with the garbage collection changes from the addition of G1GC on R6gd and other new instances.
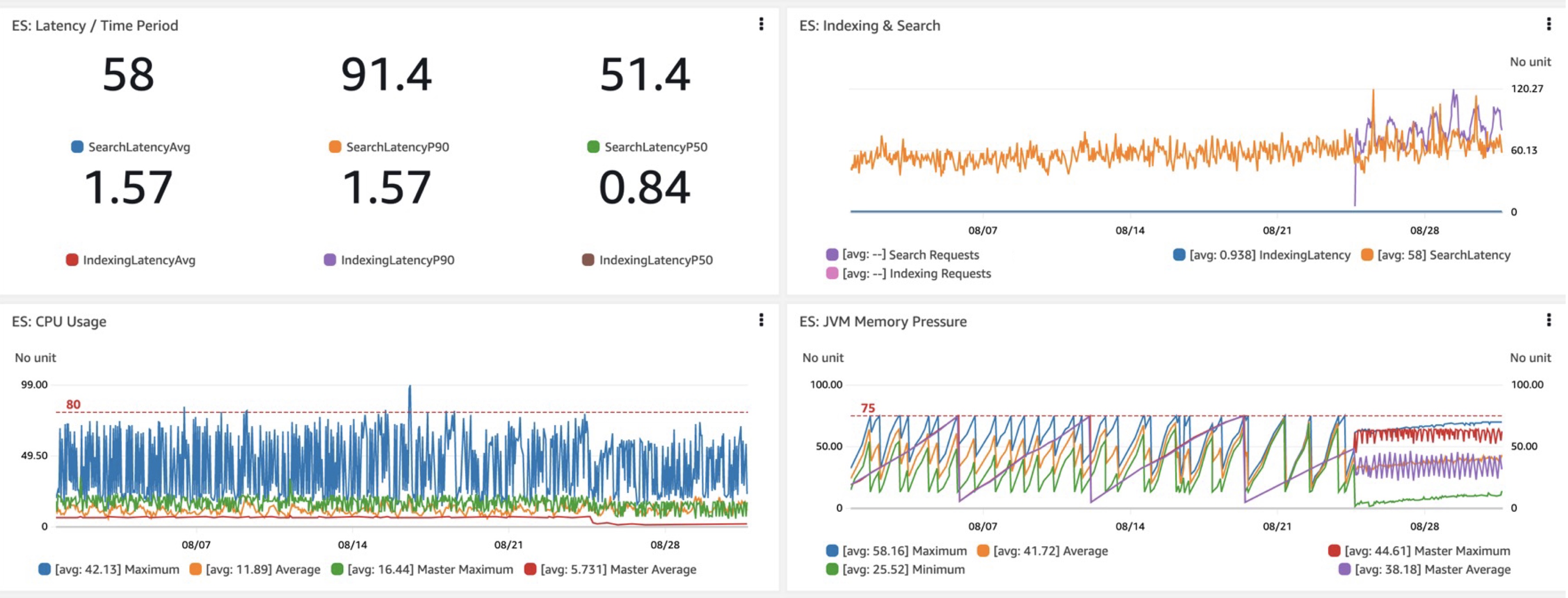
Using this pipeline, we’re also testing OpenSearch Serverless and finding its best use-cases. We’re excited about that service and fully intend to have an entirely serverless architecture in time. Stay tuned for results.
About the Authors
Lee Shepherd is a SmugMug Staff Software Engineer
Aydn Bekirov is an Amazon Web Services Principal Technical Account Manager
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/smugmugs-durable-search-pipelines-for-amazon-opensearch-service/

