Vandaag kondigen we met trots aan dat de Mistral 7B-funderingsmodellen, ontwikkeld door Mistral AI, beschikbaar zijn voor klanten via Amazon SageMaker JumpStart om met één klik te implementeren voor het uitvoeren van gevolgtrekkingen. Met 7 miljard parameters kan Mistral 7B eenvoudig worden aangepast en snel worden ingezet. Je kunt dit model uitproberen met SageMaker JumpStart, een machine learning (ML) hub die toegang biedt tot algoritmen en modellen, zodat je snel aan de slag kunt met ML. In dit bericht bespreken we hoe u het Mistral 7B-model kunt ontdekken en implementeren.
Wat is Mistral 7B
Mistral 7B is een basismodel ontwikkeld door Mistral AI, dat mogelijkheden voor het genereren van Engelse tekst en code ondersteunt. Het ondersteunt een verscheidenheid aan gebruiksscenario's, zoals tekstsamenvatting, classificatie, tekstaanvulling en code-aanvulling. Om de gemakkelijke aanpasbaarheid van het model te demonstreren, heeft Mistral AI ook een Mistral 7B Instruct-model uitgebracht voor chatgebruik, verfijnd met behulp van een verscheidenheid aan openbaar beschikbare conversatiedatasets.
Mistral 7B is een transformatormodel en maakt gebruik van aandacht voor gegroepeerde zoekopdrachten en aandacht voor een schuifvenster om snellere gevolgtrekkingen (lage latentie) te bereiken en langere reeksen te verwerken. Aandacht voor groepsquery's is een architectuur die multi-query- en multi-head-aandacht combineert om een uitvoerkwaliteit te bereiken die dicht bij multi-head-aandacht ligt en een vergelijkbare snelheid als multi-query-aandacht. Sliding-window-aandacht maakt gebruik van de gestapelde lagen van een transformator om naar het verleden te kijken buiten de venstergrootte om de contextlengte te vergroten. Mistral 7B heeft een contextlengte van 8,000 tokens, vertoont een lage latentie en hoge doorvoer, en levert sterke prestaties in vergelijking met grotere modelalternatieven, en biedt lage geheugenvereisten bij een 7B-modelgrootte. Het model wordt beschikbaar gesteld onder de toestemming Apache 2.0-licentie, voor gebruik zonder beperkingen.
Wat is SageMaker JumpStart
Met SageMaker JumpStart kunnen ML-beoefenaars kiezen uit een groeiende lijst met best presterende basismodellen. ML-beoefenaars kunnen basismodellen inzetten voor specifieke toepassingen Amazon Sage Maker instances binnen een netwerkgeïsoleerde omgeving, en pas modellen aan met SageMaker voor modeltraining en implementatie.
U kunt Mistral 7B nu met een paar klikken ontdekken en implementeren Amazon SageMaker Studio of programmatisch via de SageMaker Python SDK, zodat u modelprestaties en MLOps-besturingselementen kunt afleiden met SageMaker-functies zoals Amazon SageMaker-pijpleidingen, Amazon SageMaker-foutopsporingof containerlogboeken. Het model wordt geïmplementeerd in een AWS-beveiligde omgeving en onder uw VPC-controle, waardoor de gegevensbeveiliging wordt gewaarborgd.
Ontdek modellen
U hebt toegang tot Mistral 7B-basismodellen via SageMaker JumpStart in de SageMaker Studio UI en de SageMaker Python SDK. In deze sectie bespreken we hoe u de modellen in SageMaker Studio kunt ontdekken.
SageMaker Studio is een geïntegreerde ontwikkelomgeving (IDE) die een enkele webgebaseerde visuele interface biedt waar u toegang hebt tot speciaal gebouwde tools om alle ML-ontwikkelingsstappen uit te voeren, van het voorbereiden van gegevens tot het bouwen, trainen en implementeren van uw ML-modellen. Raadpleeg voor meer informatie over hoe u aan de slag kunt gaan en SageMaker Studio kunt instellen Amazon SageMaker Studio.
In SageMaker Studio heeft u toegang tot SageMaker JumpStart, dat vooraf getrainde modellen, notebooks en vooraf gebouwde oplossingen bevat onder Kant-en-klare en geautomatiseerde oplossingen.

Vanaf de startpagina van SageMaker JumpStart kunt u zoeken naar oplossingen, modellen, notebooks en andere bronnen. Je vindt Mistral 7B in de Basismodellen: tekstgeneratie carrousel

Door te kiezen, kunt u ook andere modelvarianten vinden Ontdek alle tekstmodellen of zoeken naar 'Mistral'.

U kunt de modelkaart kiezen om details over het model te bekijken, zoals licentie, gegevens die zijn gebruikt om te trainen en hoe u deze moet gebruiken. U vindt ook twee knoppen, Implementeren en Notitieblok openen, waarmee u het model kunt gebruiken (de volgende schermafbeelding toont de Implementeren keuze).
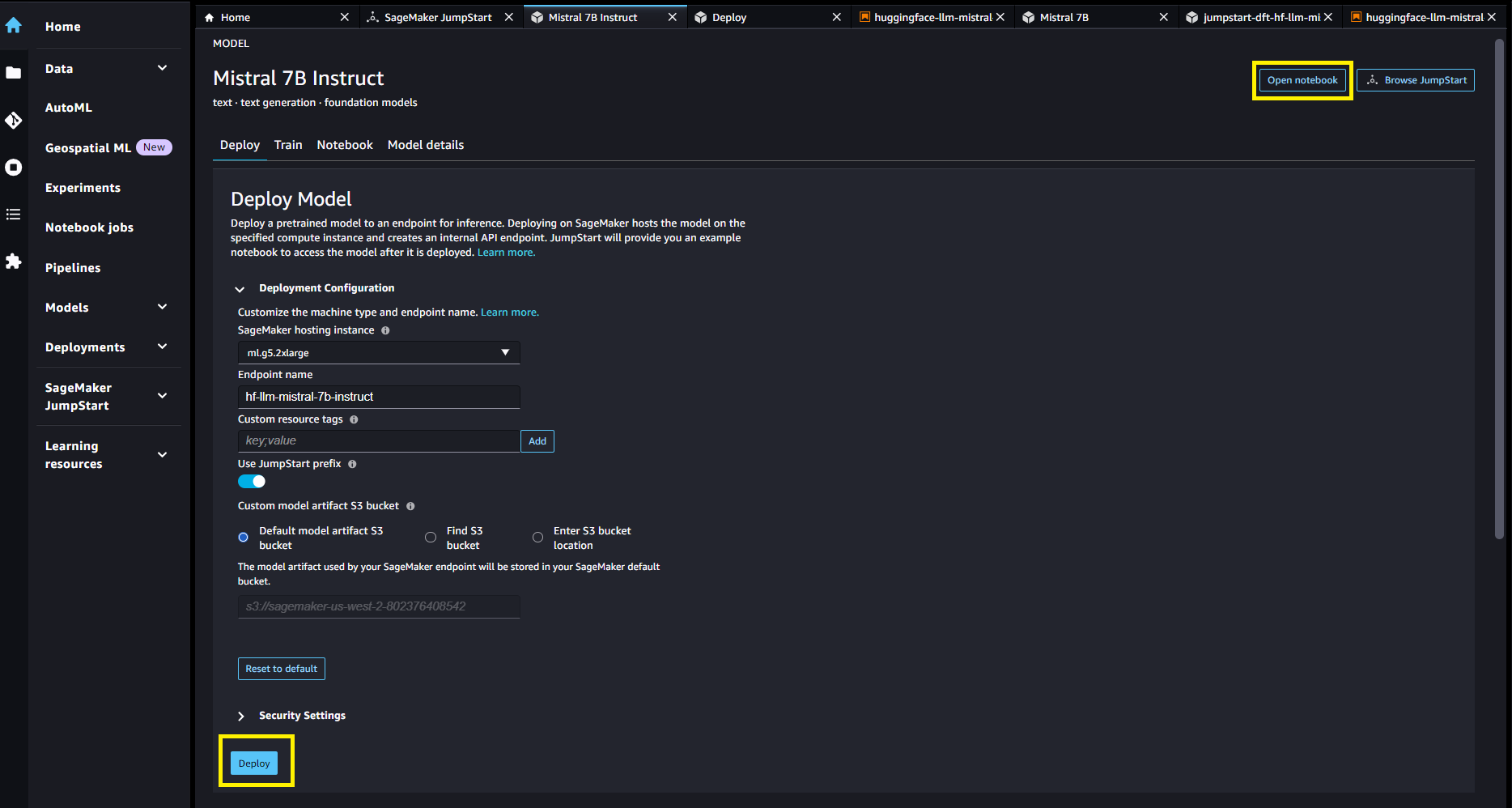
Modellen implementeren
De implementatie begint wanneer u dat wilt Implementeren. Als alternatief kunt u implementeren via het voorbeeldnotebook dat verschijnt wanneer u dat wilt Notitieblok openen. Het voorbeeldnotitieblok biedt end-to-end-richtlijnen voor het implementeren van het model voor deductie en het opschonen van bronnen.
Om te implementeren met behulp van een notebook, beginnen we met het selecteren van het Mistral 7B-model, gespecificeerd door de model_id. U kunt elk van de geselecteerde modellen op SageMaker implementeren met de volgende code:
Hiermee wordt het model op SageMaker geïmplementeerd met standaardconfiguraties, inclusief het standaardinstantietype (ml.g5.2xlarge) en standaard VPC-configuraties. U kunt deze configuraties wijzigen door niet-standaardwaarden op te geven in JumpStart-model. Nadat het is geïmplementeerd, kunt u deductie uitvoeren tegen het geïmplementeerde eindpunt via de SageMaker-voorspeller:
Het optimaliseren van de implementatieconfiguratie
Mistral-modellen maken gebruik van het Text Generation Inference-model (TGI versie 1.1). Wanneer u modellen implementeert met de TGI deep learning container (DLC), kunt u er verschillende configureren launcher-argumenten via omgevingsvariabelen bij het implementeren van uw eindpunt. Om de contextlengte van 8,000 token van Mistral 7B-modellen te ondersteunen, heeft SageMaker JumpStart een aantal van deze parameters standaard geconfigureerd: we stellen MAX_INPUT_LENGTH en MAX_TOTAL_TOKENS tot respectievelijk 8191 en 8192. U kunt de volledige lijst bekijken door uw modelobject te inspecteren:
Standaard houdt SageMaker JumpStart geen gelijktijdige gebruikers vast via de omgevingsvariabele MAX_CONCURRENT_REQUESTS kleiner dan de TGI-standaardwaarde van 128. De reden is dat sommige gebruikers typische werkbelastingen hebben met een kleine payload-contextlengte en een hoge mate van gelijktijdigheid willen. Houd er rekening mee dat de SageMaker TGI DLC meerdere gelijktijdige gebruikers ondersteunt via rollende batches. Wanneer u uw eindpunt voor uw toepassing implementeert, kunt u overwegen of u dit moet afklemmen MAX_TOTAL_TOKENS or MAX_CONCURRENT_REQUESTS voorafgaand aan de implementatie om de beste prestaties voor uw werklast te bieden:
Hier laten we zien hoe de modelprestaties kunnen verschillen voor uw typische eindpuntwerkbelasting. In de volgende tabellen kunt u zien dat kleine zoekopdrachten (128 invoerwoorden en 128 uitvoertokens) behoorlijk presteren onder een groot aantal gelijktijdige gebruikers, waarbij de tokendoorvoer wordt bereikt in de orde van grootte van 1,000 tokens per seconde. Naarmate het aantal invoerwoorden echter toeneemt tot 512 invoerwoorden, verzadigt het eindpunt zijn batchcapaciteit (het aantal gelijktijdige verzoeken dat tegelijkertijd mag worden verwerkt), wat resulteert in een doorvoerplateau en aanzienlijke vertragingen in de latentie vanaf ongeveer 16 gelijktijdige gebruikers. Ten slotte, wanneer het eindpunt tegelijkertijd met grote invoercontexten (bijvoorbeeld 6,400 woorden) door meerdere gelijktijdige gebruikers wordt bevraagd, treedt dit doorvoerplateau relatief snel op, tot het punt waarop uw SageMaker-account te maken krijgt met responstime-outlimieten van 60 seconden voor uw overbelaste verzoeken .
| . | doorvoer (tokens/s) | ||||||||||
| gelijktijdige gebruikers | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |||
| model | instantietype | woorden invoeren | uitvoertokens | . | |||||||
| mistral-7b-instruct | ml.g5.2xgroot | 128 | 128 | 30 | 54 | 89 | 166 | 287 | 499 | 793 | 1030 |
| 512 | 128 | 29 | 50 | 80 | 140 | 210 | 315 | 383 | 458 | ||
| 6400 | 128 | 17 | 25 | 30 | 35 | - | - | - | - | ||
| . | p50-latentie (ms/token) | ||||||||||
| gelijktijdige gebruikers | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | |||
| model | instantietype | woorden invoeren | uitvoertokens | . | |||||||
| mistral-7b-instruct | ml.g5.2xgroot | 128 | 128 | 32 | 33 | 34 | 36 | 41 | 46 | 59 | 88 |
| 512 | 128 | 34 | 36 | 39 | 43 | 54 | 71 | 112 | 213 | ||
| 6400 | 128 | 57 | 71 | 98 | 154 | - | - | - | - | ||
Inferentie- en voorbeeldprompts
Mistral 7B
U kunt communiceren met een Mistral 7B-basismodel zoals elk standaardmodel voor het genereren van tekst, waarbij het model een invoerreeks verwerkt en de voorspelde volgende woorden in de reeks uitvoert. Het volgende is een eenvoudig voorbeeld met multi-shot learning, waarbij het model is voorzien van verschillende voorbeelden en het uiteindelijke voorbeeldantwoord wordt gegenereerd met contextuele kennis van deze eerdere voorbeelden:
Mistral 7B instrueren
De op instructies afgestemde versie van Mistral accepteert opgemaakte instructies waarbij de gespreksrollen moeten beginnen met een gebruikersprompt en afwisselend tussen gebruiker en assistent. Een eenvoudige gebruikersprompt kan er als volgt uitzien:
Een multi-turn-prompt ziet er als volgt uit:
Dit patroon herhaalt zich, ongeacht hoeveel beurten er in het gesprek zijn.
In de volgende secties verkennen we enkele voorbeelden met behulp van het Mistral 7B Instruct-model.
Kennis ophalen
Het volgende is een voorbeeld van het ophalen van kennis:
Beantwoording van grote contextvragen
Om te demonstreren hoe dit model kan worden gebruikt om grote invoercontextlengten te ondersteunen, wordt in het volgende voorbeeld een passage ingesloten, getiteld "Rats" door Robert Sullivan (referentie), van de MCAS Grade 10 English Language Arts Reading Comprehension-test naar de invoerprompt-instructie en stelt het model een gerichte vraag over de tekst:
Wiskunde en redeneren
De Mistral-modellen rapporteren ook sterke punten op het gebied van wiskundige nauwkeurigheid. Mistral kan begrip bieden, zoals de volgende wiskundige logica:
codering
Hier volgt een voorbeeld van een coderingsprompt:
Opruimen
Nadat u klaar bent met het uitvoeren van de notebook, moet u ervoor zorgen dat u alle bronnen verwijdert die u tijdens het proces hebt gemaakt, zodat de facturering wordt stopgezet. Gebruik de volgende code:
Conclusie
In dit bericht hebben we u laten zien hoe u aan de slag kunt gaan met Mistral 7B in SageMaker Studio en het model kunt inzetten voor gevolgtrekking. Omdat basismodellen vooraf zijn getraind, kunnen ze de training- en infrastructuurkosten helpen verlagen en maatwerk voor uw gebruiksscenario mogelijk maken. Bezoek Amazon SageMaker JumpStart nu om te beginnen.
Resources
Over de auteurs
 Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
 Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
 Vivek Singh is productmanager bij Amazon SageMaker JumpStart. Hij richt zich erop klanten in staat te stellen SageMaker JumpStart te gebruiken om hun ML-traject te vereenvoudigen en te versnellen om generatieve AI-applicaties te bouwen.
Vivek Singh is productmanager bij Amazon SageMaker JumpStart. Hij richt zich erop klanten in staat te stellen SageMaker JumpStart te gebruiken om hun ML-traject te vereenvoudigen en te versnellen om generatieve AI-applicaties te bouwen.
 Roy Allela is een Senior AI/ML Specialist Solutions Architect bij AWS, gevestigd in München, Duitsland. Roy helpt AWS-klanten (van kleine startups tot grote ondernemingen) bij het efficiënt trainen en implementeren van grote taalmodellen op AWS. Roy heeft een passie voor computationele optimalisatieproblemen en het verbeteren van de prestaties van AI-workloads.
Roy Allela is een Senior AI/ML Specialist Solutions Architect bij AWS, gevestigd in München, Duitsland. Roy helpt AWS-klanten (van kleine startups tot grote ondernemingen) bij het efficiënt trainen en implementeren van grote taalmodellen op AWS. Roy heeft een passie voor computationele optimalisatieproblemen en het verbeteren van de prestaties van AI-workloads.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/mistral-7b-foundation-models-from-mistral-ai-are-now-available-in-amazon-sagemaker-jumpstart/

