포스트 pg_partman 및 Amazon S3를 사용하여 PostgreSQL용 Amazon RDS 및 PostgreSQL과 호환되는 Amazon Aurora의 데이터 보관 및 제거 데이터 관리의 중요한 부분으로 데이터 보관을 제안하고 PostgreSQL의 기본 범위 파티션을 효율적으로 사용하여 현재(핫) 데이터를 분할하는 방법을 보여줍니다. pg_partman 기록(콜드) 데이터를 아마존 단순 스토리지 서비스 (아마존 S3). 고객은 데이터베이스에서 기록 데이터를 보관하기 위해 클라우드 네이티브 자동화 솔루션이 필요합니다. 고객은 데이터베이스 서버의 컴퓨팅 부하를 줄이기 위해 데이터베이스 외부에서 비즈니스 로직을 유지 관리하고 실행하기를 원합니다. 이 게시물은 다음을 사용하여 자동화된 솔루션을 제안합니다. AWS 접착제 PostgreSQL 데이터 보관 및 복원 프로세스를 자동화하여 전체 절차를 간소화합니다.
AWS Glue는 분석, 기계 학습(ML) 및 애플리케이션 개발을 위해 여러 소스의 데이터를 더 쉽게 검색, 준비, 이동 및 통합할 수 있게 해주는 서버리스 데이터 통합 서비스입니다. 인프라를 사전 프로비저닝, 구성 또는 관리할 필요가 없습니다. 또한 데이터 처리 작업의 요구 사항을 충족하도록 리소스를 자동으로 확장하여 높은 수준의 추상화와 편의성을 제공할 수 있습니다. AWS Glue는 Amazon S3와 같은 AWS 서비스와 원활하게 통합됩니다. Amazon 관계형 데이터베이스 서비스 (아마존 RDS), 아마존 레드 시프트, 아마존 DynamoDB, Amazon Kinesis 데이터 스트림및 Amazon DocumentDB(MongoDB 호환성 포함) 강력한 클라우드 네이티브 데이터 통합 솔루션을 제공합니다.
작업 자동화를 위한 스케줄러, ETL(추출, 변환 및 로드) 프로세스를 위한 코드 생성, 대화형 개발 및 디버깅을 위한 노트북 통합, 강력한 보안 및 규정 준수 조치를 포함하는 AWS Glue의 기능은 편리하고 보관 및 복원 요구를 위한 비용 효율적인 솔루션입니다.
솔루션 개요
이 솔루션은 PostgreSQL의 기본 범위 파티셔닝 기능을 pg_partman, Amazon RDS의 Amazon S3 내보내기 및 가져오기 기능, 자동화 도구인 AWS Glue와 결합합니다.
솔루션에는 다음 단계가 포함됩니다.
- 제공된 서비스를 사용하여 필요한 AWS 서비스 및 워크플로를 프로비저닝합니다. AWS 클라우드 개발 키트 (AWS CDK) 프로젝트.
- 데이터베이스를 설정하세요.
- 이전 테이블 파티션을 Amazon S3에 보관하고 AWS Glue를 사용하여 데이터베이스에서 제거합니다.
- 비즈니스에서 이전 테이블 파티션을 다시 로드해야 하는 경우 AWS Glue를 사용하여 Amazon S3에서 데이터베이스로 보관된 데이터를 복원합니다.
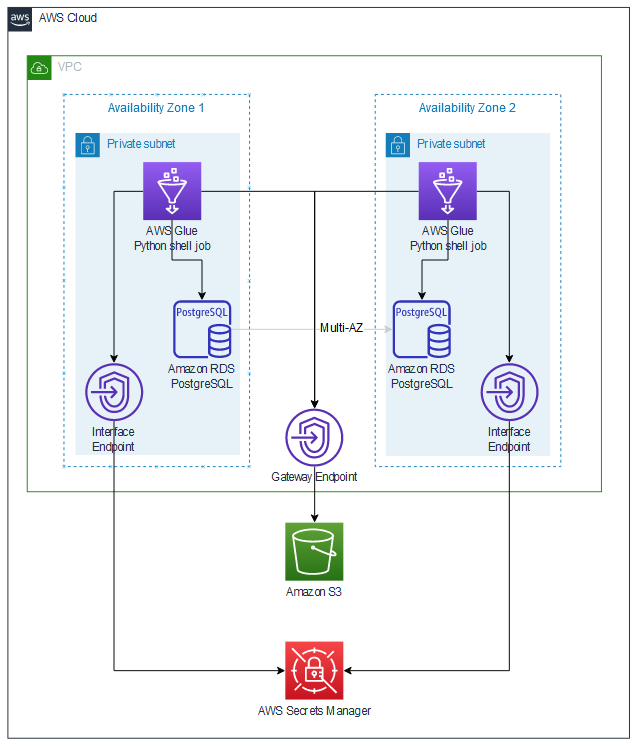
이 솔루션은 가용 영역 중복성을 통해 데이터베이스 보관 및 복원을 처리하는 AWS Glue를 기반으로 합니다. 이 솔루션은 다음 기술 구성 요소로 구성됩니다.
- An PostgreSQL 용 Amazon RDS 다중 AZ 데이터베이스는 두 개의 프라이빗 서브넷에서 실행됩니다.
- AWS 비밀 관리자 데이터베이스 자격 증명을 저장합니다.
- S3 버킷은 Python 스크립트와 데이터베이스 아카이브를 저장합니다.
- S3 게이트웨이 엔드포인트를 사용하면 Amazon RDS 및 AWS Glue가 Amazon S3와 비공개로 통신할 수 있습니다.
- AWS Glue는 Secrets Manager 인터페이스 엔드포인트를 사용하여 Secrets Manager에서 데이터베이스 암호를 검색합니다.
- AWS Glue ETL 작업은 프라이빗 서브넷에서 실행됩니다. S3 엔드포인트를 사용하여 Python 스크립트를 검색합니다. AWS Glue 작업은 Secrets Manager에서 데이터베이스 자격 증명을 읽어 데이터베이스에 대한 JDBC 연결을 설정합니다.
당신은 만들 수 있습니다 AWS 클라우드9 Amazon RDS에서 테스트 데이터를 설정하기 위해 AWS 계정에서 사용할 수 있는 프라이빗 서브넷 중 하나의 환경. 다음 다이어그램은 솔루션 아키텍처를 보여줍니다.
사전 조건
이 게시물에서 제안한 솔루션을 구현하기 위한 환경 설정 지침은 다음을 참조하십시오. 애플리케이션 배포 GitHub 레포에서.
AWS CDK를 사용하여 필요한 AWS 리소스 프로비저닝
필요한 AWS 리소스를 프로비저닝하려면 다음 단계를 완료하십시오.
CDK 프로젝트에는 세 가지 스택이 포함되어 있습니다., dbstack 및 gluestack, 에서 구현 vpc_stack.py, db_stack.py및 glue_stack.py 모듈, 각각.
이러한 스택에는 사전 구성된 종속성이 있어 프로세스를 단순화합니다. app.py는 Python 모듈을 중첩 스택 세트로 선언합니다. vpcstack에서 dbstack으로 참조를 전달하고 vpcstack과 dbstack 모두에서 참조를 gluestack으로 전달합니다.
gluestack은 상위 스택에서 다음 속성을 읽습니다.
- vpcstack의 S3 버킷, VPC 및 서브넷
- 비밀, 보안 그룹, 데이터베이스 끝점 및 dbstack의 데이터베이스 이름
XNUMX개 스택의 배포는 이 게시물의 앞부분에 나열된 기술 구성 요소를 생성합니다.
데이터베이스 설정
제공된 정보를 사용하여 데이터베이스를 준비하십시오. 테스트 데이터 채우기 및 구성 GitHub에.
기록 테이블 파티션을 Amazon S3에 보관하고 AWS Glue를 사용하여 데이터베이스에서 제거
"유지 및 보관" AWS Glue 워크 플로 첫 번째 단계에서 생성된 작업은 “Partman run maintenance”와 “Archive Cold Tables”의 두 가지 작업으로 구성됩니다.
"Partman 실행 유지 관리" 작업은 Partman.run_maintenance_proc() 프로시저를 실행하여 구성된 테이블에 대한 이전 단계의 보존 설정을 기반으로 새 파티션을 생성하고 이전 파티션을 분리합니다. "아카이브 콜드 테이블" 작업은 분리된 이전 파티션을 식별하고 다음을 사용하여 기록 데이터를 Amazon S3 대상으로 내보냅니다. aws_s3.query_export_to_s3. 결국 작업은 데이터베이스에서 보관된 파티션을 삭제하여 스토리지 공간을 확보합니다. 다음 스크린샷은 AWS Glue 콘솔에서 요청 시 이 워크플로를 실행한 결과를 보여줍니다.
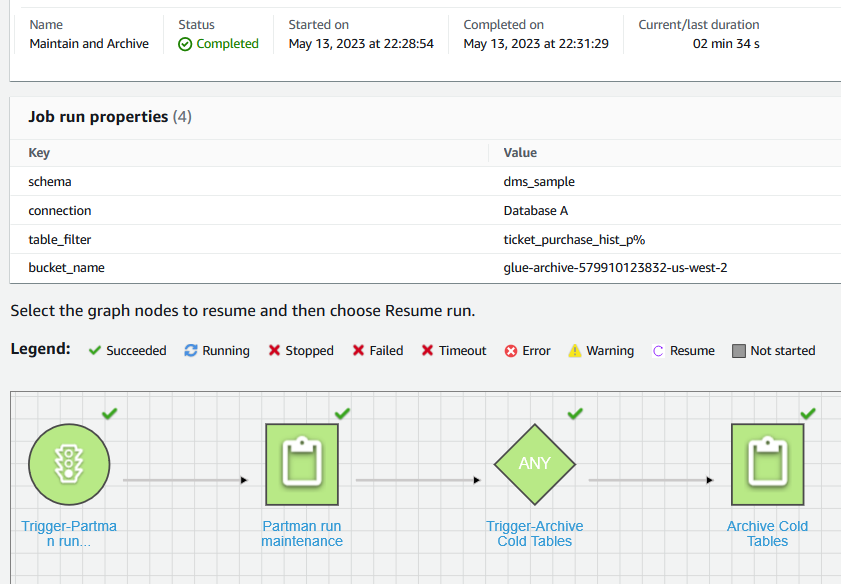
또한 이 AWS Glue 워크플로가 일정, 요청 시 또는 아마존 이벤트 브리지 이벤트. 올바른 트리거를 선택하려면 비즈니스 요구 사항을 사용해야 합니다.
Amazon S3에서 데이터베이스로 보관된 데이터 복원
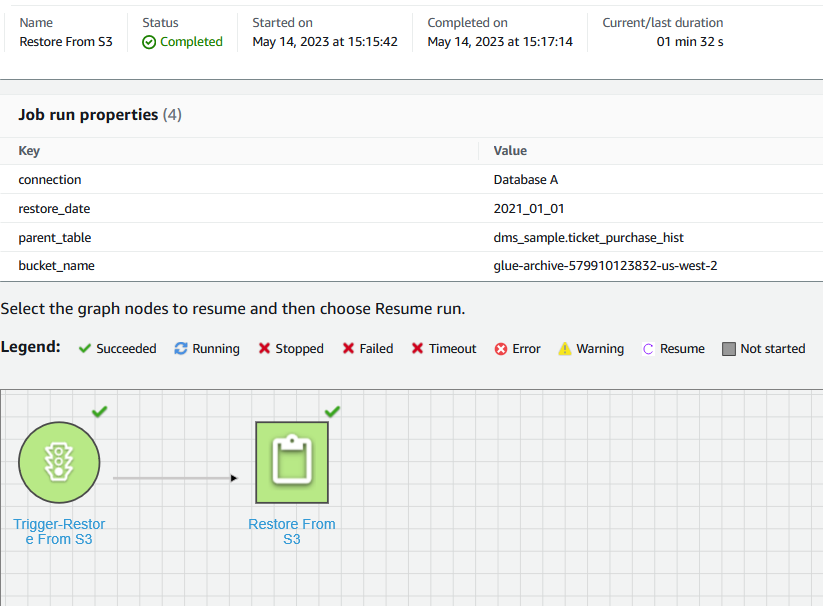
첫 번째 단계에서 생성된 "S3에서 복원" Glue 워크플로는 "S3에서 복원"이라는 하나의 작업으로 구성됩니다.
이 작업은 partman.create_partition_time 프로시저의 실행을 시작하여 지정된 월을 기준으로 새 테이블 파티션을 생성합니다. 이후 호출 aws_s3.table_import_from_s3 일치하는 데이터를 Amazon S3에서 새로 생성된 테이블 파티션으로 복원합니다.
"S3에서 복원" 워크플로를 시작하려면 AWS Glue 콘솔에서 워크플로로 이동하고 선택합니다. 달리기.
다음 스크린샷은 "S3에서 복원" 워크플로 실행 세부 정보를 보여줍니다.
결과 검증
이 게시물에서 제공하는 솔루션은 AWS Glue를 사용하여 PostgreSQL 데이터 보관 및 복원 프로세스를 자동화했습니다.
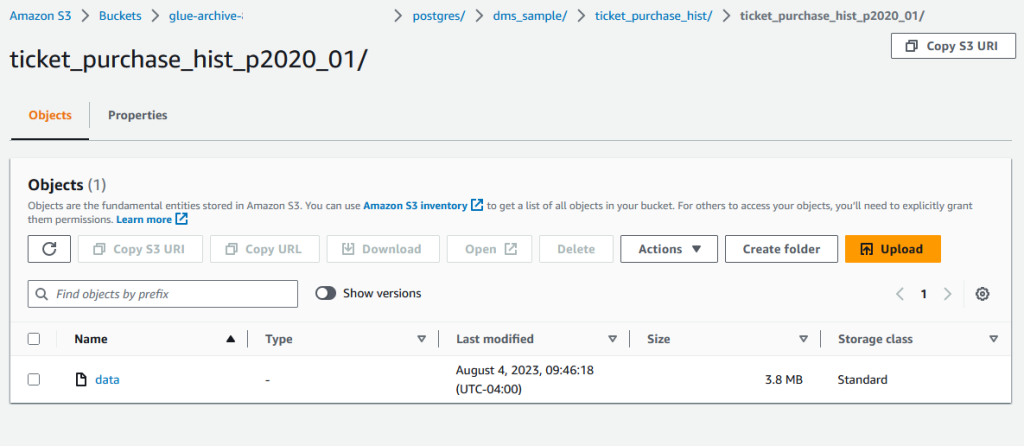
다음 단계를 사용하여 "유지 관리 및 보관" AWS Glue 워크플로를 실행한 후 데이터베이스의 기록 데이터가 성공적으로 보관되었는지 확인할 수 있습니다.
- Amazon S3 콘솔에서 S3 버킷으로 이동합니다.
- 다음 스크린샷과 같이 보관된 데이터가 S3 객체에 저장되었는지 확인합니다.
- 에서 psql 명령줄 도구를 사용하려면
dt사용 가능한 테이블을 나열하고 보관된 테이블을 확인하는 명령ticket_purchase_hist_p2020_01데이터베이스에 존재하지 않습니다.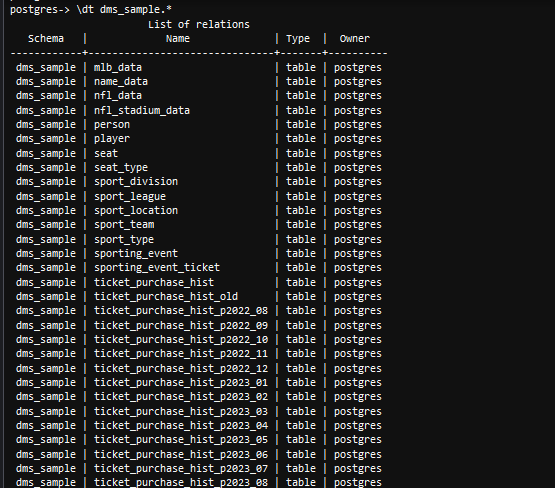
다음 단계를 사용하여 "S3에서 복원" AWS Glue 워크플로를 실행한 후 보관된 데이터가 데이터베이스에 성공적으로 복원되었는지 확인할 수 있습니다.
- psql 명령줄 도구에서 다음을 사용합니다.
dt사용 가능한 테이블을 나열하고 보관된 테이블을 확인하는 명령ticket_history_hist_p2020_01데이터베이스에 복원됩니다.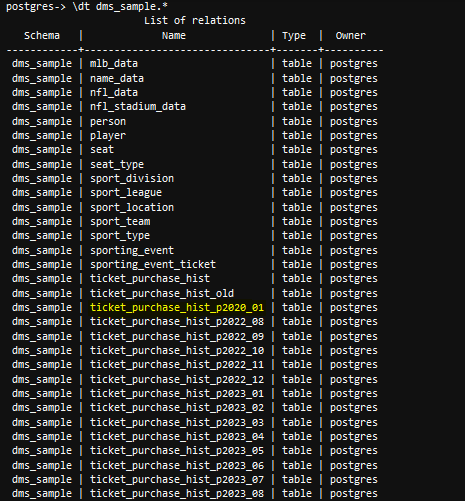
정리
제공된 정보를 사용하십시오. 대청소 이 게시물에서 제안한 솔루션을 테스트하기 위해 만든 테스트 환경을 정리합니다.
요약
이 게시물에서는 AWS Glue 워크플로를 사용하여 Amazon S3를 아카이브 스토리지로 사용하여 PostgreSQL 데이터베이스 테이블 파티션용 RDS에서 아카이브 및 복원 프로세스를 자동화하는 방법을 보여주었습니다. 자동화는 요청 시 실행되지만 반복 일정에 따라 트리거되도록 설정할 수 있습니다. 이를 통해 작업의 순서와 종속성을 정의하고, 각 워크플로 작업의 진행 상황을 추적하고, 실행 로그를 보고, 작업의 전반적인 상태와 성능을 모니터링할 수 있습니다. 예를 들어 PostgreSQL용 Amazon RDS를 사용했지만 동일한 솔루션이 작동합니다. Amazon Aurora-PostgreSQL 호환 에디션 또한. 이 게시물과 GitHub 레포. 다음 실습을 통해 AWS Glue 및 해당 구성 요소에 대한 높은 수준의 이해를 얻으세요. 작업장.
저자에 관하여
 아난드 코만두루 AWS의 선임 클라우드 설계자입니다. 그는 2021년에 AWS Professional Services 조직에 합류했으며 고객이 AWS 클라우드에서 클라우드 네이티브 애플리케이션을 구축하도록 돕습니다. 그는 20년 이상의 소프트웨어 구축 경험이 있으며 그가 가장 좋아하는 Amazon 리더십 원칙은 "리더의 말은 많이 옳다. "
아난드 코만두루 AWS의 선임 클라우드 설계자입니다. 그는 2021년에 AWS Professional Services 조직에 합류했으며 고객이 AWS 클라우드에서 클라우드 네이티브 애플리케이션을 구축하도록 돕습니다. 그는 20년 이상의 소프트웨어 구축 경험이 있으며 그가 가장 좋아하는 Amazon 리더십 원칙은 "리더의 말은 많이 옳다. "
 리 리우 Amazon Web Services 전문 서비스 팀의 선임 데이터베이스 전문 설계자입니다. 그녀는 고객이 기존 온프레미스 데이터베이스를 AWS 클라우드로 마이그레이션하도록 돕습니다. 그녀는 데이터베이스 디자인, 아키텍처 및 성능 튜닝을 전문으로 합니다.
리 리우 Amazon Web Services 전문 서비스 팀의 선임 데이터베이스 전문 설계자입니다. 그녀는 고객이 기존 온프레미스 데이터베이스를 AWS 클라우드로 마이그레이션하도록 돕습니다. 그녀는 데이터베이스 디자인, 아키텍처 및 성능 튜닝을 전문으로 합니다.
 닐 포터 AWS의 선임 클라우드 애플리케이션 설계자입니다. 그는 AWS 고객과 협력하여 워크로드를 AWS 클라우드로 마이그레이션하도록 돕습니다. 그는 애플리케이션 현대화 및 클라우드 네이티브 설계를 전문으로 하며 뉴저지에 거주하고 있습니다.
닐 포터 AWS의 선임 클라우드 애플리케이션 설계자입니다. 그는 AWS 고객과 협력하여 워크로드를 AWS 클라우드로 마이그레이션하도록 돕습니다. 그는 애플리케이션 현대화 및 클라우드 네이티브 설계를 전문으로 하며 뉴저지에 거주하고 있습니다.
 비벡 슈리바스타바 AWS Professional Services의 Data Lake 수석 데이터 설계자입니다. 그는 빅 데이터 애호가이며 14개의 AWS 인증을 보유하고 있습니다. 그는 고객이 클라우드에서 확장 가능한 고성능 데이터 분석 솔루션을 구축하도록 돕는 데 열정적입니다. 여가 시간에는 독서를 좋아하고 홈 오토메이션 분야를 찾습니다.
비벡 슈리바스타바 AWS Professional Services의 Data Lake 수석 데이터 설계자입니다. 그는 빅 데이터 애호가이며 14개의 AWS 인증을 보유하고 있습니다. 그는 고객이 클라우드에서 확장 가능한 고성능 데이터 분석 솔루션을 구축하도록 돕는 데 열정적입니다. 여가 시간에는 독서를 좋아하고 홈 오토메이션 분야를 찾습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 차트프라임. ChartPrime으로 트레이딩 게임을 향상시키십시오. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/automate-the-archive-and-purge-data-process-for-amazon-rds-for-postgresql-using-pg_partman-amazon-s3-and-aws-glue/

