이 글은 Meta의 PyTorch 팀과 공동으로 작성한 게스트 포스트이며, 파트 1 이 시리즈에서는 AWS에서 PyTorch 2.0을 실행하는 성능과 용이성을 보여줍니다.
기계 학습(ML) 연구에서는 상당히 큰 데이터 세트로 훈련된 대규모 언어 모델(LLM)이 모델 품질을 향상시키는 것으로 나타났습니다. 지난 몇 년 동안 현재 세대 모델의 규모가 크게 증가했으며 효율적이고 대규모로 교육하려면 최신 도구와 인프라가 필요합니다. PyTorch 분산 데이터 병렬 처리(DDP)는 간단하고 강력한 방식으로 대규모 데이터를 처리하는 데 도움이 되지만 모델이 하나의 GPU에 적합해야 합니다. PyTorch FSDP(Fully Sharded Data Parallel) 라이브러리는 모델 샤딩을 활성화하여 데이터 병렬 작업자 전체에 걸쳐 대규모 모델을 교육함으로써 이러한 장벽을 허물었습니다.
분산 모델 훈련에는 확장 가능한 작업자 노드 클러스터가 필요합니다. Amazon Elastic Kubernetes 서비스 (Amazon EKS)는 AI/ML 워크로드 실행 프로세스를 크게 단순화하여 관리하기 쉽고 시간 소모를 줄이는 인기 있는 Kubernetes 호환 서비스입니다.
이 블로그 게시물에서 AWS는 Meta의 PyTorch 팀과 협력하여 PyTorch FSDP 라이브러리를 사용하여 Amazon EKS와 AWS에서 딥 러닝 모델의 선형 확장을 원활하게 달성하는 방법을 논의합니다. AWS 딥 러닝 컨테이너 (DLC). 우리는 7개의 Amazon EKS를 사용하여 13B, 70B 및 2B Llama16 모델 교육의 단계별 구현을 통해 이를 보여줍니다. 아마존 엘라스틱 컴퓨트 클라우드 (아마존 EC2) p4de.24xlarge 인스턴스(각각 NVIDIA A8 Tensor Core GPU 100개 및 각 GPU에 80GB HBM2e 메모리 포함) 또는 EC16 2개 p5.48xlarge 인스턴스(각각 NVIDIA H8 Tensor Core GPU 100개 및 각 GPU에 80GB HBM3 메모리 포함)를 사용하여 처리량을 선형에 가깝게 확장하고 궁극적으로 훈련 시간을 단축합니다.
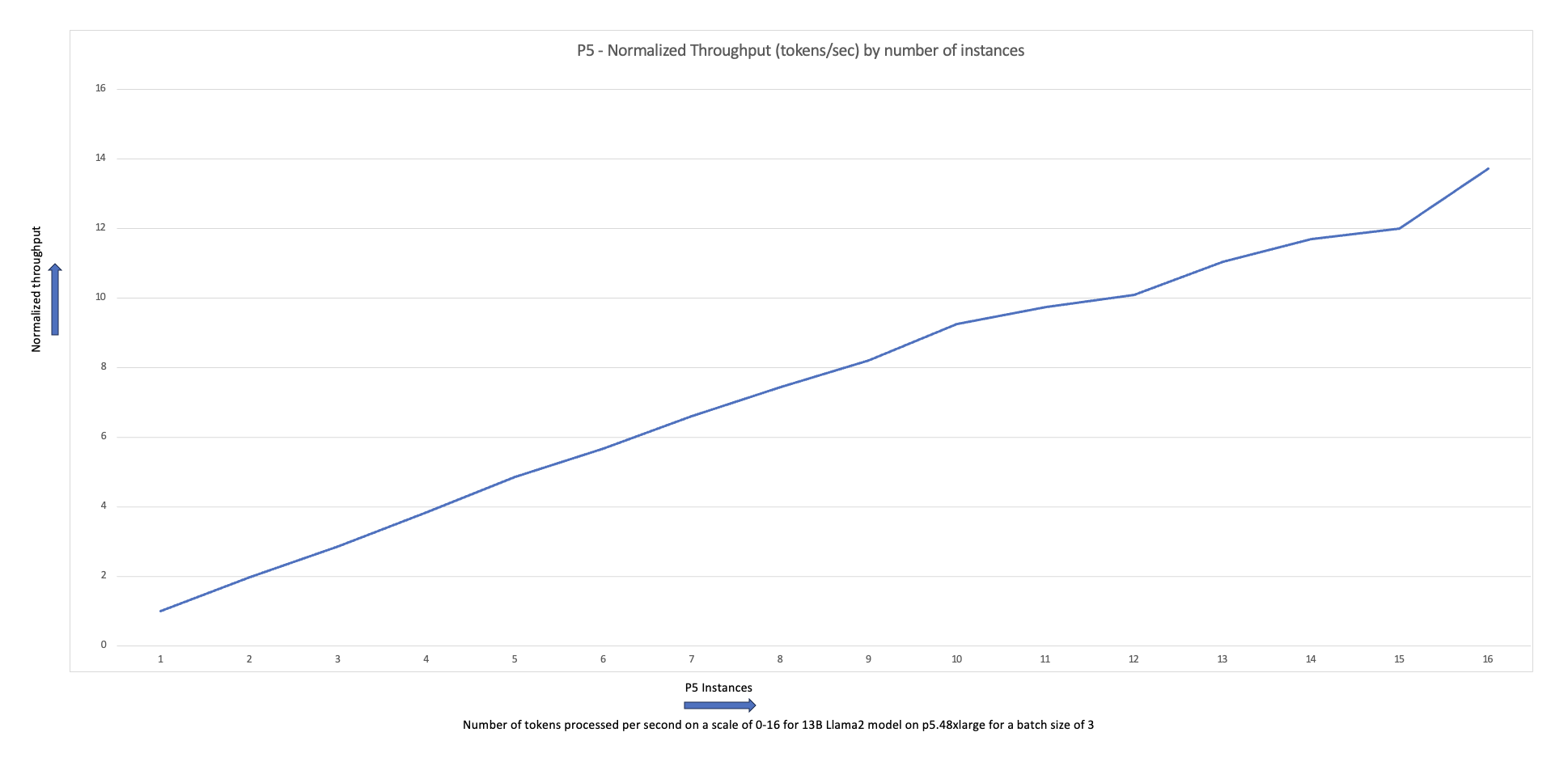
다음 확장 차트는 p5.48xlarge 인스턴스가 87노드 클러스터 구성에서 FSDP Llama2 미세 조정을 통해 16%의 확장 효율성을 제공한다는 것을 보여줍니다.
LLM 교육의 과제
다양한 응용 분야의 효율성과 정확성을 높이기 위해 가상 비서, 번역, 콘텐츠 제작, 컴퓨터 비전 등 다양한 작업에 LLM을 채택하는 기업이 점점 늘어나고 있습니다.
그러나 맞춤형 사용 사례에 맞게 이러한 대규모 모델을 훈련하거나 미세 조정하려면 대량의 데이터와 컴퓨팅 성능이 필요하며, 이는 ML 스택의 전반적인 엔지니어링 복잡성을 가중시킵니다. 이는 또한 단일 GPU에서 사용할 수 있는 제한된 메모리로 인해 훈련할 수 있는 모델의 크기가 제한되고 훈련 중에 사용되는 GPU당 배치 크기도 제한되기 때문입니다.
이 문제를 해결하기 위해 다음과 같은 다양한 모델 병렬화 기술이 필요합니다. 딥스피드 제로 과 파이토치 FSDP 제한된 GPU 메모리라는 장벽을 극복할 수 있도록 만들어졌습니다. 이는 각 가속기가 하나의 슬라이스만 보유하는 샤딩된 데이터 병렬 기술을 채택하여 수행됩니다. 사금파리) 전체 모델 복제본 대신 모델 복제본을 사용하므로 훈련 작업의 메모리 사용량이 크게 줄어듭니다.
이 게시물에서는 PyTorch FSDP를 사용하여 Amazon EKS를 사용하여 Llama2 모델을 미세 조정하는 방법을 보여줍니다. 우리는 모델 요구 사항을 해결하기 위해 컴퓨팅 및 GPU 용량을 확장하여 이를 달성합니다.
FSDP 개요
PyTorch DDP 훈련에서 각 GPU( 노동자 PyTorch의 맥락에서)는 모델 가중치, 기울기 및 최적화 상태를 포함하여 모델의 전체 복사본을 보유합니다. 각 작업자는 데이터 배치를 처리하고 역방향 전달이 끝나면 다음을 사용합니다. 올리듀스 다양한 작업자 간에 그라디언트를 동기화하는 작업입니다.
각 GPU에 모델 복제본이 있으면 DDP 워크플로에 수용할 수 있는 모델의 크기가 제한됩니다. FSDP는 데이터 병렬 처리의 단순성을 유지하면서 데이터 병렬 작업자 간에 모델 매개변수, 최적화 프로그램 상태 및 기울기를 분할하여 이러한 제한을 극복하는 데 도움이 됩니다.
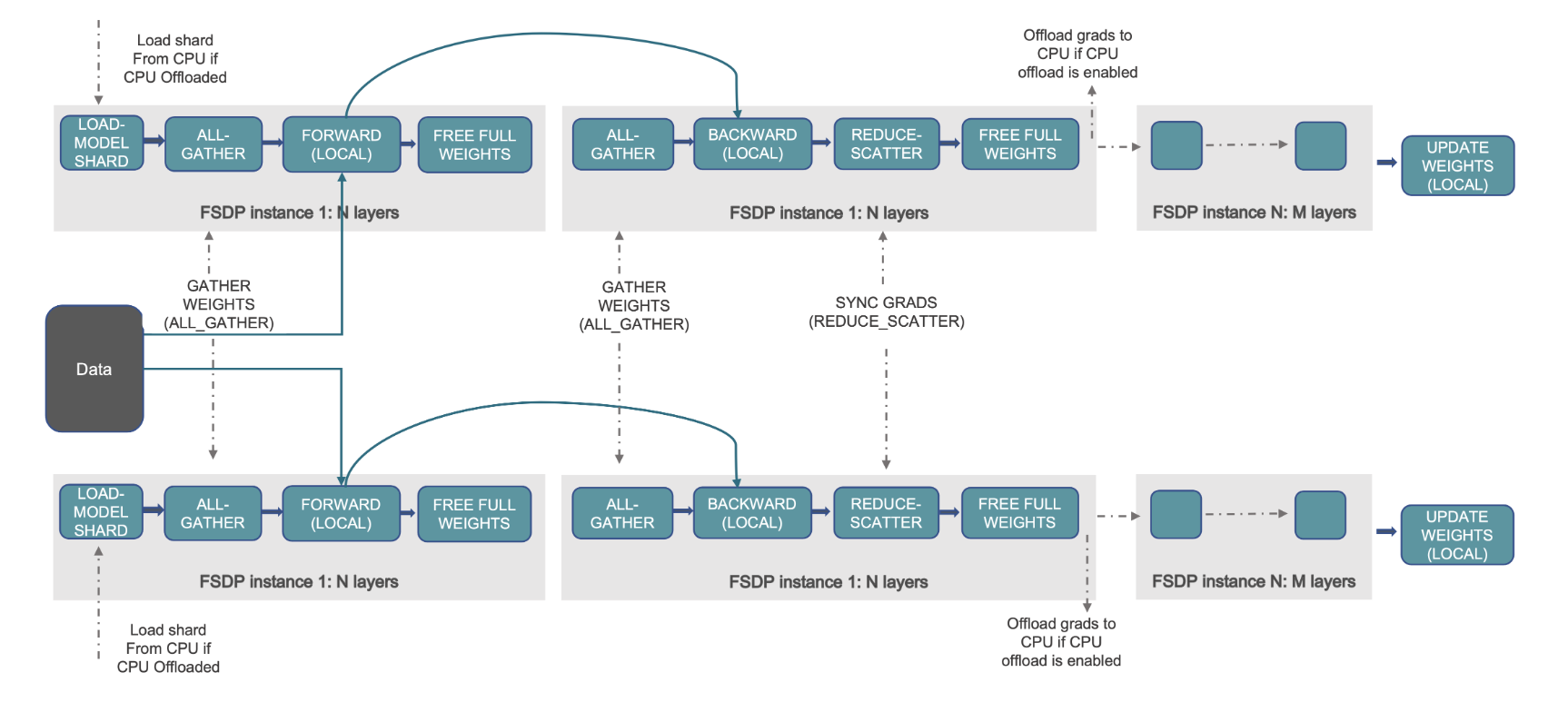
이는 다음 다이어그램에서 설명됩니다. DDP의 경우 각 GPU는 최적화 상태(OS), 그라데이션(G) 및 매개변수(P)를 포함하여 모델 상태의 전체 복사본을 보유합니다. M(OS + G + 피). FSDP에서 각 GPU는 최적화 상태(OS), 기울기(G) 및 매개변수(P)를 포함하여 모델 상태의 일부만 보유합니다. M (OS + G + P). FSDP를 사용하면 모든 작업자에서 DDP에 비해 GPU 메모리 공간이 훨씬 작아져 매우 큰 모델을 훈련하거나 훈련 작업에 더 큰 배치 크기를 사용할 수 있습니다.

그러나 이는 통신 오버헤드가 증가하는 대가로 발생하며, 이는 다음과 같은 기능을 갖춘 통신 및 계산 프로세스 중복과 같은 FSDP 최적화를 통해 완화됩니다. 미리 가져오기. 자세한 내용은 다음을 참조하세요. 완전 샤딩 데이터 병렬(FSDP) 시작하기.
FSDP는 훈련 작업의 성능과 효율성을 조정할 수 있는 다양한 매개변수를 제공합니다. FSDP의 주요 기능 중 일부는 다음과 같습니다.
- 변압기 포장 정책
- 유연한 혼합 정밀도
- 활성화 체크포인트
- 다양한 네트워크 속도와 클러스터 토폴로지에 적합한 다양한 샤딩 전략:
- 전체_SHARD – 샤드 모델 매개변수, 기울기 및 최적화 상태
- HYBRID_SHARD – 노드 전체의 노드 DDP 내의 전체 샤드; 모델의 전체 복제본을 위한 유연한 샤딩 그룹 지원(HSDP)
- SHARD_GRAD_OP – 샤드 전용 그래디언트 및 최적화 상태
- NO_SHARD – DDP와 유사
FSDP에 대한 자세한 내용은 다음을 참조하세요. Pytorch FSDP 및 AWS를 사용한 효율적인 대규모 교육.
다음 그림은 FSDP가 두 개의 데이터 병렬 프로세스에 대해 작동하는 방식을 보여줍니다.
솔루션 개요
이 게시물에서는 AWS 클라우드 및 온프레미스 데이터 센터에서 Kubernetes를 실행하는 관리형 서비스인 Amazon EKS를 사용하여 컴퓨팅 클러스터를 설정했습니다. 많은 고객이 Amazon EKS를 채택하여 Kubernetes 기반 AI/ML 워크로드를 실행하고 성능, 확장성, 안정성 및 가용성은 물론 AWS 네트워킹, 보안 및 기타 서비스와의 통합을 활용하고 있습니다.
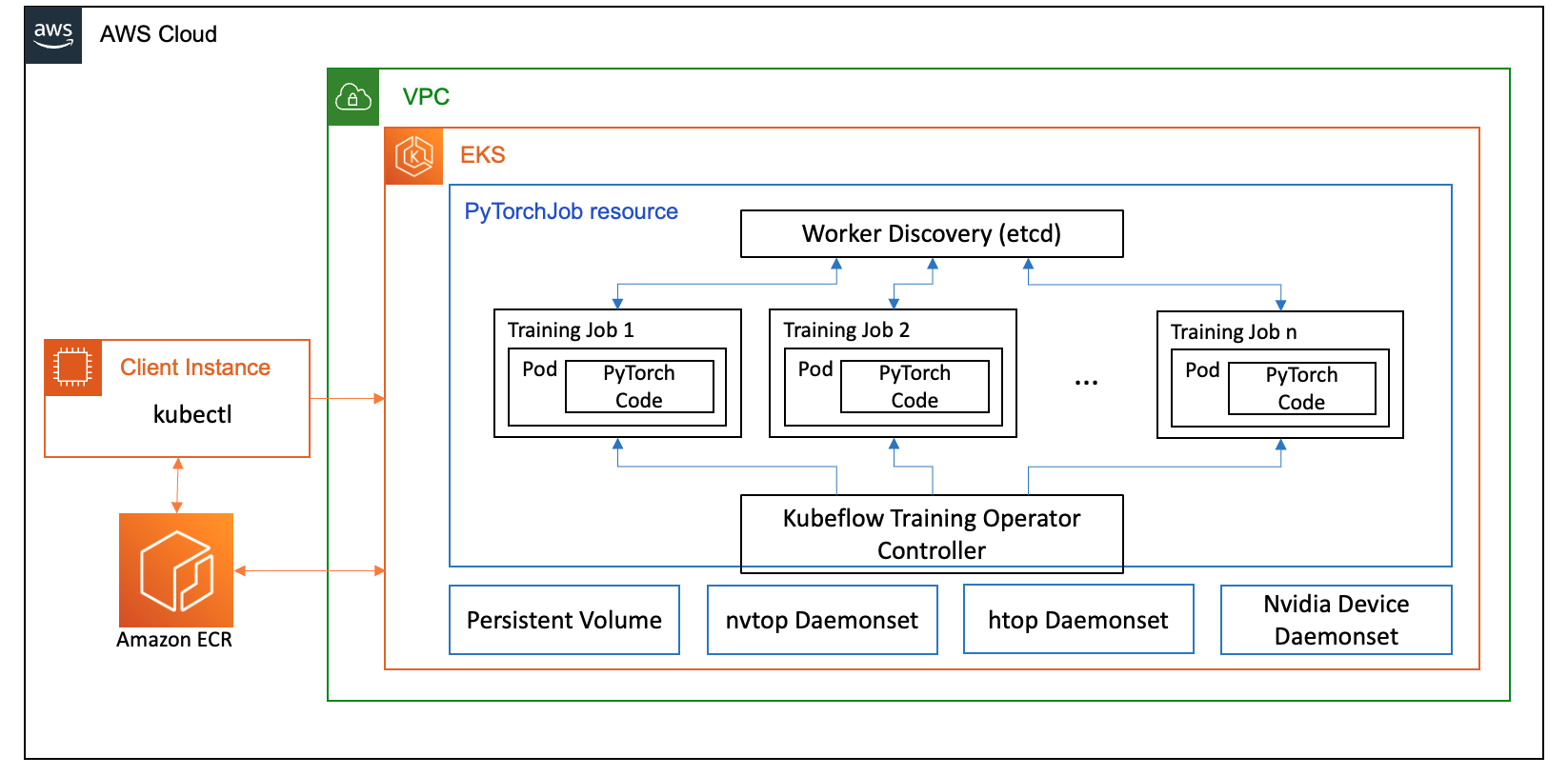
FSDP 사용 사례의 경우 Kubeflow 교육 운영자 ML 모델에 대한 미세 조정 및 확장 가능한 분산 교육을 용이하게 하는 Kubernetes 기반 프로젝트인 Amazon EKS를 기반으로 합니다. PyTorch 훈련 작업을 대규모로 배포하고 관리하는 데 사용할 수 있는 PyTorch를 포함한 다양한 ML 프레임워크를 지원합니다.
Kubeflow Training Operator의 PyTorchJob 사용자 정의 리소스를 활용하여 리소스 활용도를 최적화할 수 있는 구성 가능한 작업자 복제본 수를 사용하여 Kubernetes에서 교육 작업을 실행합니다.
다음은 Llama2 미세 조정 사용 사례에서 역할을 하는 교육 연산자의 몇 가지 구성 요소입니다.
- PyTorch에 대한 분산 교육 작업을 조율하는 중앙 집중식 Kubernetes 컨트롤러입니다.
- PyTorchJob은 Kubernetes에서 Llama2 훈련 작업을 정의하고 배포하기 위해 Kubeflow Training Operator에서 제공하는 PyTorch용 Kubernetes 사용자 지정 리소스입니다.
- etcd는 PyTorch 모델의 분산 훈련을 조정하기 위한 랑데부 메커니즘 구현과 관련이 있습니다. 이것
etcd서버는 랑데부 프로세스의 일부로 분산 훈련 중에 참여하는 작업자의 조정 및 동기화를 용이하게 합니다.
다음 다이어그램은 솔루션 아키텍처를 보여줍니다.
대부분의 세부 사항은 Llama2 예제를 실행하는 데 사용하는 자동화 스크립트에 의해 추상화됩니다.
이 사용 사례에서는 다음 코드 참조를 사용합니다.
라마2란 무엇인가요?
Llama2는 2조 개의 텍스트 및 코드 토큰에 대해 사전 훈련된 LLM입니다. Llama2는 현재 사용 가능한 가장 크고 가장 강력한 LLM 중 하나입니다. 자연어 처리(NLP), 텍스트 생성 및 번역을 포함한 다양한 작업에 LlamaXNUMX를 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요. 라마 시작하기.
Llama2는 세 가지 모델 크기로 제공됩니다.
- 라마2-70b – 2억 개의 매개변수를 갖춘 가장 큰 Llama70 모델입니다. 가장 강력한 Llama2 모델이며 가장 까다로운 작업에 사용할 수 있습니다.
- 라마2-13b – 2억 개의 매개변수를 갖춘 중형 Llama13 모델입니다. 성능과 효율성 사이의 균형이 잘 잡혀 있어 다양한 작업에 사용할 수 있습니다.
- 라마2-7b – 2억 개의 매개변수를 갖춘 가장 작은 Llama7 모델입니다. 가장 효율적인 Llama2 모델이며 최고 수준의 성능이 필요하지 않은 작업에 사용할 수 있습니다.
이 게시물을 통해 Amazon EKS에서 이러한 모든 모델을 세부적으로 조정할 수 있습니다. EKS 클러스터를 생성하고 여기서 FSDP 작업을 실행하는 간단하고 재현 가능한 환경을 제공하기 위해 다음을 사용합니다. AWS-DO-EKS 프로젝트. 이 예는 기존 EKS 클러스터에서도 작동합니다.
스크립트로 작성된 연습은 다음에서 사용할 수 있습니다. GitHub의 즉시 사용 가능한 경험을 위해. 다음 섹션에서는 엔드투엔드 프로세스를 더 자세히 설명합니다.
솔루션 인프라 프로비저닝
이 게시물에 설명된 실험에서는 p4de(A100 GPU) 및 p5(H100 GPU) 노드가 있는 클러스터를 사용합니다.
p4de.24xlarge 노드가 있는 클러스터
p4de 노드가 있는 클러스터의 경우 다음을 사용합니다. eks-gpu-p4de-odcr.yaml 스크립트:
사용 엑스크틀 앞의 클러스터 매니페스트에서는 p4de 노드가 있는 클러스터를 생성합니다.
p5.48xlarge 노드가 있는 클러스터
P5 노드가 있는 EKS 클러스터에 대한 Terraform 템플릿은 다음 위치에 있습니다. GitHub 레포.
다음을 통해 클러스터를 사용자 정의할 수 있습니다. 변수.tf 파일을 만든 다음 Terraform CLI를 통해 생성합니다.
간단한 kubectl 명령을 실행하여 클러스터 가용성을 확인할 수 있습니다.
이 명령의 출력에 예상 노드 수가 준비 상태로 표시되면 클러스터는 정상입니다.
필수 구성 요소 배포
Amazon EKS에서 FSDP를 실행하려면 다음을 사용합니다. PyTorchJob 사용자 정의 리소스. 그것은 필요하다 등 과 Kubeflow 교육 운영자 전제 조건으로.
다음 코드를 사용하여 etcd를 배포합니다.
다음 코드를 사용하여 Kubeflow Training Operator를 배포합니다.
FSDP 컨테이너 이미지를 구축하고 Amazon ECR에 푸시
다음 코드를 사용하여 FSDP 컨테이너 이미지를 빌드하고 Amazon Elastic Container Registry (아마존 ECR):
FSDP PyTorchJob 매니페스트 만들기
너를 넣으 라. 포옹하는 얼굴 토큰 실행하기 전에 다음 스니펫에서:
다음을 사용하여 PyTorchJob을 구성하세요. .env 파일을 작성하거나 아래와 같이 환경 변수에 직접 입력하세요.
다음을 사용하여 PyTorchJob 매니페스트를 생성합니다. fsdp 템플릿 과 generate.sh 스크립트를 사용하거나 아래 스크립트를 사용하여 직접 생성하세요.
PyTorchJob 실행
다음 코드를 사용하여 PyTorchJob을 실행합니다.
생성된 지정된 수의 FDSP 작업자 포드가 표시되며, 이미지를 가져온 후 실행 중 상태로 전환됩니다.
PyTorchJob의 상태를 보려면 다음 코드를 사용하세요.
PyTorchJob을 중지하려면 다음 코드를 사용하세요.
작업이 완료된 후에는 새 실행을 시작하기 전에 삭제해야 합니다. 우리는 또한etcd포드를 실행하고 새 작업을 시작하기 전에 다시 시작하면 RendezvousClosedError.
클러스터 규모 조정
클러스터에 있는 작업자 노드의 수와 인스턴스 유형을 변경하면서 작업을 생성하고 실행하는 이전 단계를 반복할 수 있습니다. 이를 통해 앞서 표시된 것과 같은 스케일링 차트를 생성할 수 있습니다. 일반적으로 클러스터에 더 많은 노드가 추가되면 GPU 메모리 공간이 감소하고 에포크 시간이 감소하며 처리량이 증가하는 것을 볼 수 있습니다. 이전 차트는 5~1개 노드 크기의 다양한 p16 노드 그룹을 사용하여 여러 실험을 수행하여 생성되었습니다.
FSDP 교육 워크로드 관찰
생성 인공 지능 워크로드의 관찰 가능성은 실행 중인 작업에 대한 가시성을 확보하고 컴퓨팅 리소스 활용도를 극대화하는 데 중요합니다. 이 게시물에서는 이러한 목적으로 몇 가지 Kubernetes 기반 및 오픈 소스 관찰 도구를 사용합니다. 이러한 도구를 사용하면 오류, 통계 및 모델 동작을 추적할 수 있으므로 AI 관찰 가능성이 모든 비즈니스 사용 사례의 중요한 부분이 됩니다. 이 섹션에서는 FSDP 교육 작업을 관찰하기 위한 다양한 접근 방식을 보여줍니다.
작업자 포드 로그
가장 기본적인 수준에서는 훈련 포드의 로그를 볼 수 있어야 합니다. 이는 Kubernetes 기본 명령을 사용하여 쉽게 수행할 수 있습니다.
먼저 Pod 목록을 검색하고 로그를 보려는 Pod의 이름을 찾습니다.
그런 다음 선택한 Pod에 대한 로그를 확인합니다.

하나의 작업자(선출된 리더) 포드 로그에만 전체 작업 통계가 나열됩니다. 선출된 리더 포드의 이름은 각 작업자 포드 로그의 시작 부분에서 확인할 수 있으며 키로 식별됩니다. master_addr=.
CPU 사용률
분산 학습 워크로드에는 CPU와 GPU 리소스가 모두 필요합니다. 이러한 워크로드를 최적화하려면 이러한 리소스가 어떻게 활용되는지 이해하는 것이 중요합니다. 다행히 CPU 및 GPU 활용도를 시각화하는 데 도움이 되는 몇 가지 훌륭한 오픈 소스 유틸리티를 사용할 수 있습니다. CPU 사용률을 보려면 다음을 사용할 수 있습니다.htop. 작업자 Pod에 이 유틸리티가 포함된 경우 아래 명령을 사용하여 Pod에서 셸을 열고 다음을 실행할 수 있습니다.htop.
또는 htop을 배포할 수 있습니다.daemonset다음에 제공된 것과 같은 GitHub 레포.
XNUMXD덴탈의daemonset각 노드에서 경량 htop 포드를 실행합니다. 이러한 포드 중 하나에 실행하고 다음을 실행할 수 있습니다.htop명령:
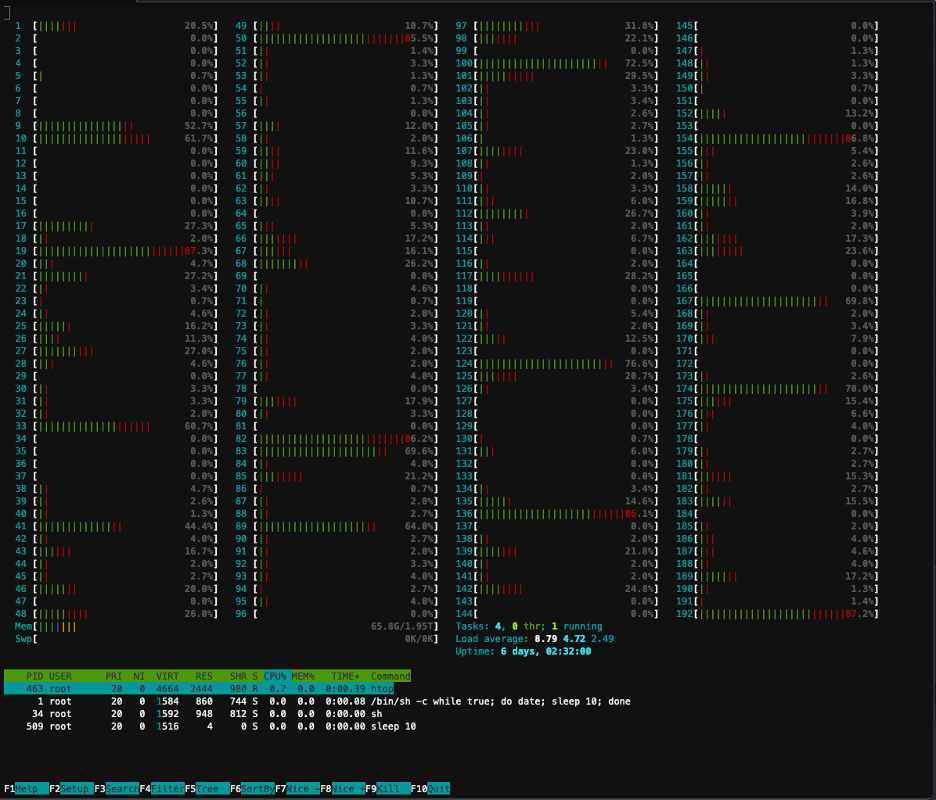
다음 스크린샷은 클러스터 노드 중 하나의 CPU 사용률을 보여줍니다. 이 경우 vCPU가 5.48개인 P192xlarge 인스턴스를 살펴보겠습니다. 모델 가중치가 다운로드되는 동안 프로세서 코어는 유휴 상태이며, 모델 가중치가 GPU 메모리에 로드되는 동안 활용도가 증가하는 것을 볼 수 있습니다.
GPU 활용
경우nvtop유틸리티는 포드에서 사용할 수 있습니다. 아래를 사용하여 유틸리티를 실행한 다음 실행할 수 있습니다.nvtop.
또는 nvtop을 배포할 수 있습니다.daemonset다음에 제공된 것과 같은 GitHub 레포.
이것은nvtop각 노드의 Pod. 해당 포드 중 하나에 실행하고 실행할 수 있습니다.nvtop:
다음 스크린샷은 훈련 클러스터에 있는 노드 중 하나의 GPU 사용률을 보여줍니다. 이 경우에는 5.48개의 NVIDIA H8 GPU가 있는 P100xlarge 인스턴스를 살펴보겠습니다. 모델 가중치가 다운로드되는 동안 GPU는 유휴 상태입니다. 그런 다음 모델 가중치가 GPU에 로드됨에 따라 GPU 메모리 사용률이 증가하고 훈련 반복이 진행되는 동안 GPU 사용률이 100%로 급증합니다.

Grafana 대시보드
이제 시스템이 포드 및 노드 수준에서 어떻게 작동하는지 이해했으므로 클러스터 수준에서 측정항목을 살펴보는 것도 중요합니다. 집계된 활용도 지표는 NVIDIA DCGM 내보내기 및 Prometheus를 통해 수집하고 Grafana에서 시각화할 수 있습니다.
Prometheus-Grafana 배포 예시는 다음에서 확인할 수 있습니다. GitHub 레포.
DCGM 내보내기 배포 예시는 다음에서 확인할 수 있습니다. GitHub 레포.
다음 스크린샷에는 간단한 Grafana 대시보드가 표시되어 있습니다. 이는 다음 DCGM 지표를 선택하여 구축되었습니다. DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMP및 DCGM_FI_DEV_POWER_USAGE. 대시보드는 다음에서 Prometheus로 가져올 수 있습니다. GitHub의.
다음 대시보드는 Llama2 7b 단일 에포크 훈련 작업의 한 실행을 보여줍니다. 그래프는 스트리밍 멀티프로세서(SM) 클록이 증가함에 따라 GPU 및 메모리 활용도와 함께 GPU의 전력 소비 및 온도도 증가한다는 것을 보여줍니다. 또한 이 실행 중에 XID 오류가 없었고 GPU가 정상임을 확인할 수 있습니다.
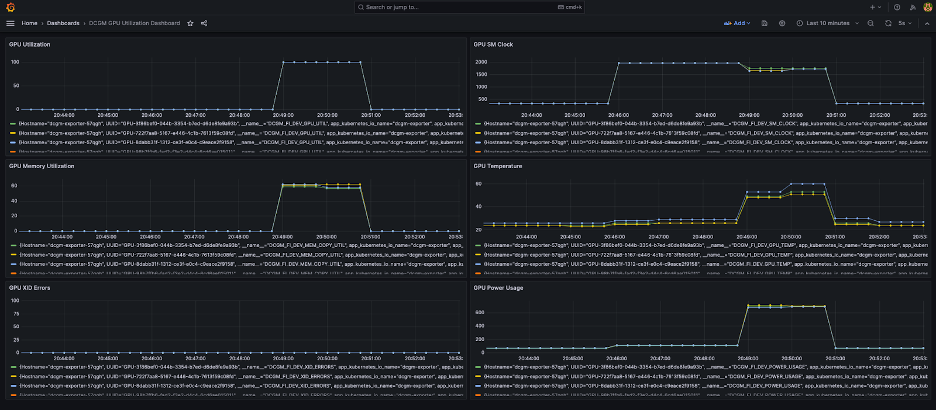
2024년 XNUMX월부터 EKS에 대한 GPU 관측 기능은 기본적으로 다음에서 지원됩니다. CloudWatch 컨테이너 통찰력. 이 기능을 활성화하려면 EKS 클러스터에 CloudWatch 관찰 가능성 추가 기능을 배포하기만 하면 됩니다. 그런 다음 Container Insights에서 사전 구성되고 사용자 정의 가능한 대시보드를 통해 포드, 노드 및 클러스터 수준 지표를 찾아볼 수 있습니다.
정리
이 블로그에 제공된 예제를 사용하여 클러스터를 생성한 경우 다음 코드를 실행하여 클러스터 및 VPC를 포함하여 클러스터와 연결된 모든 리소스를 삭제할 수 있습니다.
eksctl의 경우:
테라폼의 경우:
예정된 기능
FSDP에는 GPU당 메모리 공간을 더욱 향상시키는 것을 목표로 매개변수별 샤딩 기능이 포함될 것으로 예상됩니다. 또한 FP8 지원의 지속적인 개발은 H100 GPU의 FSDP 성능을 향상시키는 것을 목표로 합니다. 마지막으로 FSDP가 통합되면torch.compile, 추가적인 성능 개선과 선택적 활성화 체크포인트와 같은 기능 활성화를 기대합니다.
결론
이 게시물에서는 FSDP가 각 GPU의 메모리 공간을 줄여 더 큰 모델을 보다 효율적으로 훈련하고 처리량을 선형에 가까운 확장을 달성하는 방법에 대해 논의했습니다. 우리는 P2de 및 P4 인스턴스에서 Amazon EKS를 사용하여 Llama5 모델을 훈련하는 단계별 구현을 통해 이를 입증했으며 kubectl, htop, nvtop 및 dcgm과 같은 관찰 도구를 사용하여 로그와 CPU 및 GPU 사용률을 모니터링했습니다.
자신의 LLM 교육 작업에 PyTorch FSDP를 활용하는 것이 좋습니다. 시작하기 aws-do-fsdp.
저자에 관하여
 칸월짓 쿠르미 Amazon Web Services의 수석 AI/ML 솔루션 설계자입니다. 그는 AWS 고객과 협력하여 지침과 기술 지원을 제공하고 AWS에서 기계 학습 솔루션의 가치를 향상시킬 수 있도록 돕습니다. Kanwaljit는 컨테이너화된 분산 컴퓨팅 및 딥 러닝 애플리케이션을 통해 고객을 돕는 전문 분야입니다.
칸월짓 쿠르미 Amazon Web Services의 수석 AI/ML 솔루션 설계자입니다. 그는 AWS 고객과 협력하여 지침과 기술 지원을 제공하고 AWS에서 기계 학습 솔루션의 가치를 향상시킬 수 있도록 돕습니다. Kanwaljit는 컨테이너화된 분산 컴퓨팅 및 딥 러닝 애플리케이션을 통해 고객을 돕는 전문 분야입니다.
 알렉스 이안쿨스키 AWS의 자체 관리형 기계 학습 부문 수석 솔루션 설계자입니다. 그는 심층적인 실무 작업을 좋아하는 풀스택 소프트웨어 및 인프라 엔지니어입니다. 그는 컨테이너 기반 AWS 서비스에서 ML 및 AI 워크로드를 컨테이너화하고 조정하여 고객을 돕는 데 중점을 두고 있습니다. 그는 또한 오픈 소스의 저자이기도 합니다. 프레임워크를 수행하다 컨테이너 기술을 적용하여 혁신 속도를 가속화하는 동시에 세계 최대의 과제를 해결하는 것을 좋아하는 Docker 선장입니다.
알렉스 이안쿨스키 AWS의 자체 관리형 기계 학습 부문 수석 솔루션 설계자입니다. 그는 심층적인 실무 작업을 좋아하는 풀스택 소프트웨어 및 인프라 엔지니어입니다. 그는 컨테이너 기반 AWS 서비스에서 ML 및 AI 워크로드를 컨테이너화하고 조정하여 고객을 돕는 데 중점을 두고 있습니다. 그는 또한 오픈 소스의 저자이기도 합니다. 프레임워크를 수행하다 컨테이너 기술을 적용하여 혁신 속도를 가속화하는 동시에 세계 최대의 과제를 해결하는 것을 좋아하는 Docker 선장입니다.
 아나 시모에스 그는 AWS의 ML 프레임워크 부문 수석 기계 학습 전문가입니다. 그녀는 클라우드의 HPC 인프라에 대규모로 AI, ML 및 생성 AI를 배포하는 고객을 지원합니다. Ana는 고객이 새로운 워크로드와 생성 AI 및 기계 학습 사용 사례에 대해 가격 대비 성능을 달성할 수 있도록 지원하는 데 중점을 두고 있습니다.
아나 시모에스 그는 AWS의 ML 프레임워크 부문 수석 기계 학습 전문가입니다. 그녀는 클라우드의 HPC 인프라에 대규모로 AI, ML 및 생성 AI를 배포하는 고객을 지원합니다. Ana는 고객이 새로운 워크로드와 생성 AI 및 기계 학습 사용 사례에 대해 가격 대비 성능을 달성할 수 있도록 지원하는 데 중점을 두고 있습니다.
 하미드 쇼자나제리 오픈 소스, 고성능 모델 최적화, 분산 교육을 담당하는 PyTorch의 파트너 엔지니어입니다(FSDP) 및 추론. 그는 공동 창작자이다. 라마 레시피 그리고 기여자 횃불. 그의 주요 관심은 비용 효율성을 개선하여 더 넓은 커뮤니티가 AI에 더 쉽게 접근할 수 있도록 하는 것입니다.
하미드 쇼자나제리 오픈 소스, 고성능 모델 최적화, 분산 교육을 담당하는 PyTorch의 파트너 엔지니어입니다(FSDP) 및 추론. 그는 공동 창작자이다. 라마 레시피 그리고 기여자 횃불. 그의 주요 관심은 비용 효율성을 개선하여 더 넓은 커뮤니티가 AI에 더 쉽게 접근할 수 있도록 하는 것입니다.
 덜 라이트 PyTorch의 AI/파트너 엔지니어입니다. 그는 Triton/CUDA 커널을 연구하고 있습니다(SplitK 작업 분해로 DeQuant 가속화); 페이징, 스트리밍 및 양자화 최적화 프로그램; 및 PyTorch 분산(파이토치 FSDP).
덜 라이트 PyTorch의 AI/파트너 엔지니어입니다. 그는 Triton/CUDA 커널을 연구하고 있습니다(SplitK 작업 분해로 DeQuant 가속화); 페이징, 스트리밍 및 양자화 최적화 프로그램; 및 PyTorch 분산(파이토치 FSDP).
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

