오늘날 NFL은 NFL에서 제공하는 통계의 수를 늘리기 위한 여정을 계속하고 있습니다. 차세대 통계 플랫폼 32개 팀과 팬 모두에게. 기계 학습(ML)에서 파생된 고급 분석을 통해 NFL은 축구를 정량화하고 팬에게 축구에 대한 지식을 높이는 데 필요한 도구를 제공하는 새로운 방법을 만들고 있습니다. 게임 내 게임 축구의. NFL은 2022년 시즌에 플레이어 추적 데이터와 새로운 고급 분석 기술을 활용하는 것을 목표로 했습니다. 특별한 팀을 더 잘 이해하기 위해.
이 프로젝트의 목표는 복귀자가 펀트 또는 킥오프 플레이에서 얼마나 많은 야드를 얻을지 예측하는 것이었습니다. 펀트 및 킥오프 수익에 대한 예측 모델을 구축할 때 어려운 점 중 하나는 터치다운과 같이 게임의 역학에서 매우 중요한 매우 드문 이벤트를 사용할 수 있다는 것입니다. 두꺼운 꼬리가 있는 데이터 분포는 드문 이벤트가 모델의 전체 성능에 상당한 영향을 미치는 실제 응용 프로그램에서 일반적입니다. 강력한 방법을 사용하여 극한 상황에 대한 분포를 정확하게 모델링하는 것이 전반적인 성능 향상에 매우 중요합니다.
이 게시물에서는 GluonTS에서 구현된 Spliced Binned-Pareto 분포를 사용하여 이러한 두꺼운 꼬리 분포를 견고하게 모델링하는 방법을 보여줍니다.
먼저 사용된 데이터 세트를 설명합니다. 다음으로 데이터 세트에 적용된 데이터 전처리 및 기타 변환 방법을 제시합니다. 그런 다음 ML 방법론 및 모델 교육 절차에 대해 자세히 설명합니다. 마지막으로 모델 성능 결과를 제시합니다.
데이터 세트
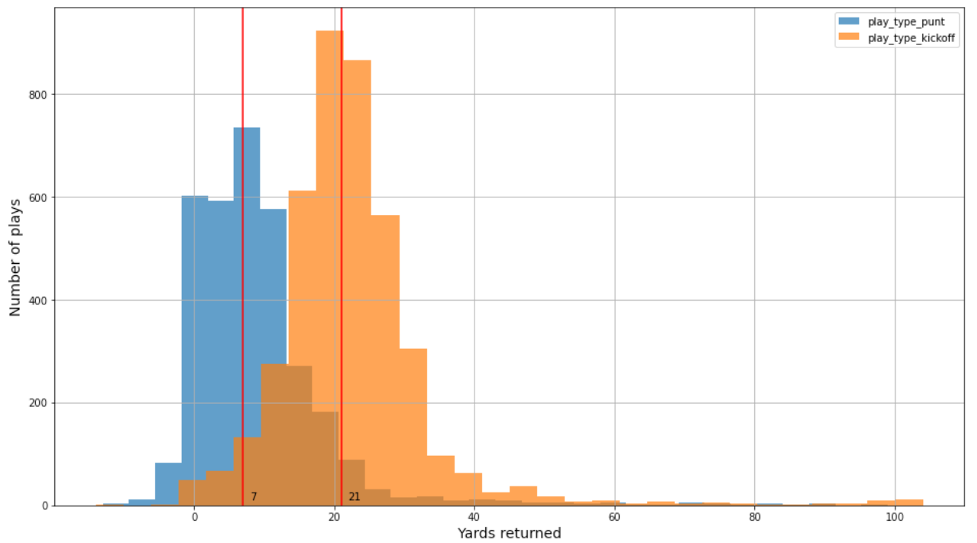
이 게시물에서는 두 개의 데이터 세트를 사용하여 펀트 및 킥오프 수익에 대한 별도의 모델을 구축했습니다. 플레이어 추적 데이터에는 플레이어의 위치, 방향, 가속도 등(x,y 좌표)이 포함됩니다. 펀트 및 킥오프 플레이를 위해 각각 3,000개의 NFL 시즌(4,000-2018)에서 약 2021회 및 0.23회의 플레이가 있습니다. 또한 데이터 세트에는 펀트 및 킥오프 관련 터치다운이 매우 적습니다(각각 0.8% 및 XNUMX%). 펀트와 킥오프의 데이터 분포는 다릅니다. 예를 들어, 킥오프와 펀트에 대한 실제 야드 분포는 유사하지만 다음 그림과 같이 이동됩니다.
데이터 전처리 및 기능 엔지니어링
먼저, 펀트 및 킥오프 리턴과 관련된 데이터에 대해서만 추적 데이터를 필터링했습니다. 플레이어 데이터는 모델 개발을 위한 기능을 파생하는 데 사용되었습니다.
- X – 필드의 긴 축을 따라 플레이어 위치
- Y – 필드의 짧은 축을 따라 플레이어 위치
- S – 야드/초 단위의 속도; 더 정확하기 위해 Dis*10으로 대체됨(Dis는 지난 0.1초 동안의 거리임)
- 디렉토리 – 선수의 움직임 각도(도)
이전 데이터에서 각 플레이는 10명의 공격수(볼 캐리어 제외), 11명의 수비수 및 14개의 파생 기능이 포함된 10X11X14의 데이터로 변환되었습니다.
- sX – 플레이어의 x 속도
- sY – 플레이어의 y 속도
- s – 플레이어의 속도
- aX – 플레이어의 x 가속도
- aY – 플레이어의 y 가속도
- relX – 볼 캐리어에 대한 플레이어의 x 거리
- 의존하다 – 볼 캐리어에 대한 플레이어의 y 거리
- relSx – 볼 캐리어에 대한 플레이어의 x 속도
- relSy – 볼 캐리어에 대한 플레이어의 y 속도
- 상대 거리 – 볼 캐리어에 대한 플레이어의 유클리드 거리
- oppX – 수비 선수에 대한 공격 선수의 x 거리
- oppY – 수비 선수에 대한 공격 선수의 y 거리
- oppSx –x 수비 선수에 비해 공격 선수의 속도
- 반대 – 수비 선수에 대한 공격 선수의 y 속도
데이터를 늘리고 오른쪽 및 왼쪽 위치를 설명하기 위해 X 및 Y 위치 값도 오른쪽 및 왼쪽 필드 위치를 설명하도록 미러링되었습니다. 데이터 전처리 및 기능 엔지니어링은 우승자로부터 채택되었습니다. NFL 빅 데이터 보울 Kaggle에서의 경쟁.
ML 방법론 및 모델 교육
우리는 터치다운 확률을 포함하여 플레이에서 가능한 모든 결과에 관심이 있기 때문에 회귀 문제로 얻은 평균 야드를 단순히 예측할 수 없습니다. 가능한 모든 야드 이득의 전체 확률 분포를 예측해야 하므로 문제를 확률적 예측으로 구성했습니다.
확률적 예측을 구현하는 한 가지 방법은 얻은 야드를 여러 빈(예: 0 미만, 0–1, 1–2, ..., 14–15, 15 이상)에 할당하고 빈을 분류로 예측하는 것입니다. 문제. 이 접근 방식의 단점은 작은 빈이 분포의 고화질 그림을 갖기를 원하지만 작은 빈은 빈당 데이터 포인트 수가 적고 분포, 특히 꼬리가 잘못 추정되고 불규칙할 수 있음을 의미합니다.
확률적 예측을 구현하는 또 다른 방법은 출력을 제한된 수의 매개변수(예: 가우시안 또는 감마 분포)가 있는 연속 확률 분포로 모델링하고 매개변수를 예측하는 것입니다. 이 접근 방식은 분포에 대한 매우 높은 정의와 규칙적인 그림을 제공하지만 획득한 야드의 실제 분포에 맞추기에는 너무 엄격하여 다중 모드 및 두꺼운 꼬리가 있습니다.
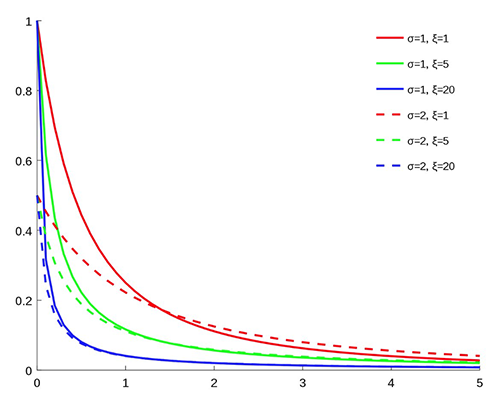
두 가지 방법을 최대한 활용하기 위해 다음을 사용합니다. Spliced Binned-Pareto 분포 (SBP), 많은 데이터를 사용할 수 있는 분포의 중심에 빈이 있고 일반화 파레토 분포 (GPD) 터치다운과 같이 드물지만 중요한 이벤트가 발생할 수 있는 양쪽 끝에 있습니다. GPD에는 두 가지 매개변수가 있습니다. 하나는 스케일용이고 다른 하나는 꼬리의 무게용입니다(출처: Wikipedia).
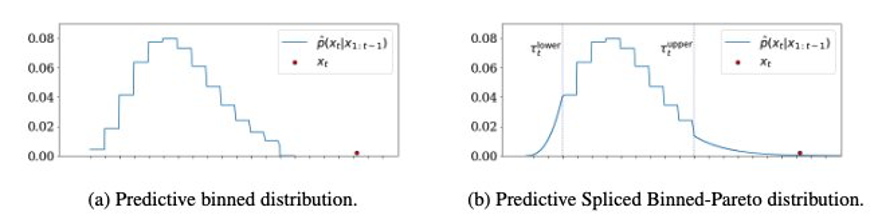
양쪽에서 비닝된 분포(다음 왼쪽 그래프 참조)로 GPD를 연결하여 오른쪽에서 다음과 같은 SBP를 얻습니다. 스플라이싱이 수행되는 하한 및 상한 임계값은 하이퍼파라미터입니다.
기준선으로 우리는 우승한 모델을 사용했습니다. NFL 빅 데이터 보울 Kaggle에서의 경쟁. 이 모델은 CNN 레이어를 사용하여 준비된 데이터에서 기능을 추출하고 결과를 "빈당 1야드" 분류 문제로 예측합니다. 모델의 경우 다음 그림과 같이 기준선에서 기능 추출 레이어를 유지하고 각 빈에 대한 확률 대신 SBP 매개 변수를 출력하도록 마지막 레이어만 수정했습니다(게시물에서 편집한 이미지). 1위 솔루션 The Zoo).

에서 제공하는 SBP 분포를 사용했습니다. 글루온티에스. GluonTS는 확률적 시계열 모델링을 위한 Python 패키지이지만 SBP 분포는 시계열에만 국한되지 않으며 회귀를 위해 용도를 변경할 수 있었습니다. GluonTS SBP 사용 방법에 대한 자세한 내용은 다음 데모를 참조하십시오. 수첩.
모델은 2018, 2019 및 2020 시즌에 대해 훈련 및 교차 검증되었으며 2021 시즌에 테스트되었습니다. 교차 검증 중 유출을 방지하기 위해 동일한 게임의 모든 플레이를 동일한 폴드로 그룹화했습니다.
평가를 위해 Kaggle 경쟁에서 사용된 메트릭을 유지했습니다. CRPS(연속 순위 확률 점수), 이는 이상값에 더 강력한 로그 우도의 대안으로 볼 수 있습니다. 우리는 또한 피어슨 상관 계수 그리고 RMSE 일반적이고 해석 가능한 정확도 지표로 사용됩니다. 또한 캘리브레이션을 평가하기 위해 터치다운 확률과 확률도를 살펴보았습니다.
모델은 다음을 사용하여 CRPS 손실에 대해 훈련되었습니다. 확률 적 가중치 평균 그리고 조기 중지.
출력 분포의 비닝된 부분의 불규칙성을 처리하기 위해 두 가지 기술을 사용했습니다.
- 두 연속 빈 사이의 제곱 차이에 비례하는 평활도 페널티
- 교차 검증 중에 훈련된 앙상블 모델
모델 성능 결과
각 데이터 세트에 대해 다음 옵션에 대해 그리드 검색을 수행했습니다.
- 확률 모델
- 기준선은 야드당 하나의 확률이었습니다.
- SBP는 중앙에서 야드당 하나의 확률, 꼬리에서 일반화된 SBP였습니다.
- 분포 평활화
- 스무딩 없음(스무딩 페널티 = 0)
- 부드러움 페널티 = 5
- 부드러움 페널티 = 10
- 교육 및 추론 절차
- 10겹 교차 검증 및 앙상블 추론(k10)
- 10 에포크 또는 20 에포크에 대한 훈련 및 검증 데이터에 대한 교육
그런 다음 CRPS로 정렬된 상위 XNUMX개 모델에 대한 지표를 살펴보았습니다(낮을수록 좋음).
킥오프 데이터의 경우 SBP 모델은 CRPS 측면에서 약간 초과 성능을 보이지만 더 중요한 것은 터치다운 확률을 더 잘 추정합니다(실제 확률은 테스트 세트에서 0.80%임). 최고의 모델은 다음 표와 같이 10겹 앙상블(k10)을 사용하고 평활도 패널티가 없음을 알 수 있습니다.
| 트레이닝 | 모델 | 매끄러움 | CRPS | RMSE | CORR% | P(터치다운)% |
| k10 | SBP | 0 | 4.071 | 9.641 | 47.15 | 0.78 |
| k10 | 기준 | 0 | 4.074 | 9.62 | 47.585 | 0.306 |
| k10 | 기준 | 5 | 4.075 | 9.626 | 47.43 | 0.274 |
| k10 | SBP | 5 | 4.079 | 9.656 | 46.977 | 0.682 |
| k10 | 기준 | 10 | 4.08 | 9.621 | 47.519 | 0.265 |
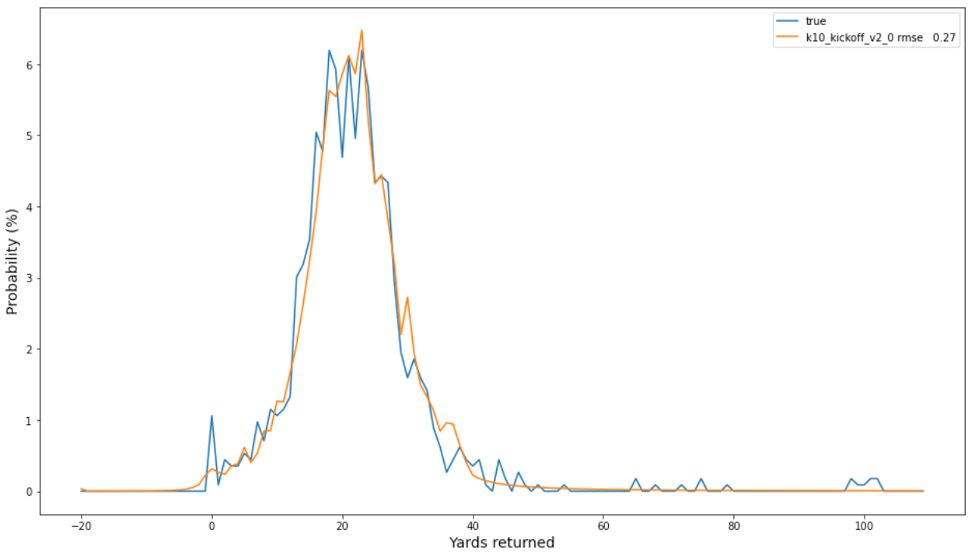
관찰된 빈도와 예측 확률에 대한 다음 플롯은 두 분포 사이의 RMSE가 0.27인 최상의 모델이 잘 보정되었음을 나타냅니다. 실제(파란색) 경험적 분포의 꼬리에서 발생하는 높은 야드(예: 100)의 발생에 유의하십시오. 확률은 기준선 방법보다 SBP에서 더 잘 포착할 수 있습니다.
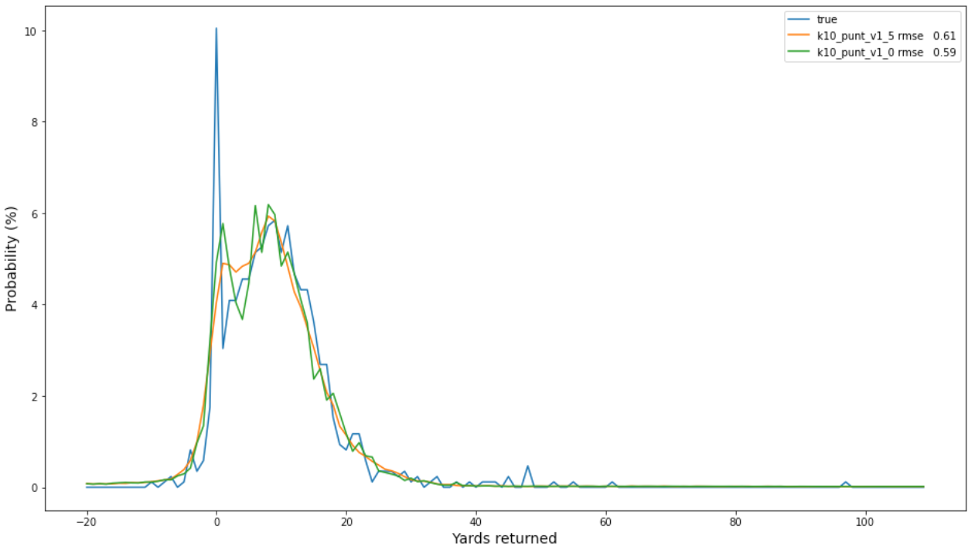
펀트 데이터의 경우 기준선이 SBP를 능가합니다. 아마도 극단적인 야드 수의 꼬리가 실현되는 횟수가 더 적기 때문일 것입니다. 따라서 0~10야드 피크 사이의 양식을 캡처하는 것이 더 나은 절충안입니다. 킥오프 데이터와 달리 최상의 모델은 평활도 패널티를 사용합니다. 다음 표는 조사 결과를 요약한 것입니다.
| 트레이닝 | 모델 | 매끄러움 | CRPS | RMSE | CORR% | P(터치다운)% |
| k10 | 기준 | 5 | 3.961 | 8.313 | 35.227 | 0.547 |
| k10 | 기준 | 0 | 3.972 | 8.346 | 34.227 | 0.579 |
| k10 | 기준 | 10 | 3.978 | 8.351 | 34.079 | 0.555 |
| k10 | SBP | 5 | 3.981 | 8.342 | 34.971 | 0.723 |
| k10 | SBP | 0 | 3.991 | 8.378 | 33.437 | 0.677 |
두 가지 최고의 펀트 모델에 대한 관찰 빈도(파란색) 및 예측 확률의 다음 도표는 평활화되지 않은 모델(주황색)이 평활화 모델(녹색)보다 약간 더 잘 보정되었으며 전반적으로 더 나은 선택일 수 있음을 나타냅니다.
결론
이 게시물에서는 Fat-tailed 데이터 분포를 사용하여 예측 모델을 구축하는 방법을 보여주었습니다. 우리는 GluonTS에서 구현된 Spliced Binned-Pareto 분포를 사용했는데, 이는 이러한 두꺼운 꼬리 분포를 견고하게 모델링할 수 있습니다. 우리는 이 기술을 사용하여 펀트 및 킥오프 수익 모델을 구축했습니다. 데이터에 이벤트가 거의 없지만 이러한 이벤트가 모델의 전체 성능에 상당한 영향을 미치는 유사한 사용 사례에 이 솔루션을 적용할 수 있습니다.
제품 및 서비스에서 ML 사용을 가속화하는 데 도움이 필요한 경우 Amazon ML 솔루션 랩 프로그램)
저자에 관하여
 테스파가비르 메하리즈기 데이터 과학자입니다. Amazon ML 솔루션 랩 여기서 그는 의료 및 생명 과학, 제조, 자동차, 스포츠 및 미디어와 같은 다양한 산업의 AWS 고객이 기계 학습 및 AWS 클라우드 서비스 사용을 가속화하여 비즈니스 문제를 해결하도록 돕습니다.
테스파가비르 메하리즈기 데이터 과학자입니다. Amazon ML 솔루션 랩 여기서 그는 의료 및 생명 과학, 제조, 자동차, 스포츠 및 미디어와 같은 다양한 산업의 AWS 고객이 기계 학습 및 AWS 클라우드 서비스 사용을 가속화하여 비즈니스 문제를 해결하도록 돕습니다.
 마크 반 오드헤우스덴 Amazon Web Services의 Amazon ML 솔루션 랩 팀의 선임 데이터 과학자입니다. 그는 AWS 고객과 협력하여 인공 지능 및 기계 학습으로 비즈니스 문제를 해결합니다. 직장 밖에서는 해변에서, 아이들과 놀고, 서핑을 하거나 카이트서핑을 하는 그를 볼 수 있습니다.
마크 반 오드헤우스덴 Amazon Web Services의 Amazon ML 솔루션 랩 팀의 선임 데이터 과학자입니다. 그는 AWS 고객과 협력하여 인공 지능 및 기계 학습으로 비즈니스 문제를 해결합니다. 직장 밖에서는 해변에서, 아이들과 놀고, 서핑을 하거나 카이트서핑을 하는 그를 볼 수 있습니다.
 판판 쉬 AWS Amazon ML 솔루션 연구소의 수석 응용 과학자이자 관리자입니다. 그녀는 AI 및 클라우드 채택을 가속화하기 위해 다양한 산업 분야에서 영향력이 큰 고객 애플리케이션을 위한 기계 학습 알고리즘의 연구 및 개발에 참여하고 있습니다. 그녀의 연구 관심 분야에는 모델 해석 가능성, 인과 관계 분석, Human-in-the-loop AI 및 대화형 데이터 시각화가 포함됩니다.
판판 쉬 AWS Amazon ML 솔루션 연구소의 수석 응용 과학자이자 관리자입니다. 그녀는 AI 및 클라우드 채택을 가속화하기 위해 다양한 산업 분야에서 영향력이 큰 고객 애플리케이션을 위한 기계 학습 알고리즘의 연구 및 개발에 참여하고 있습니다. 그녀의 연구 관심 분야에는 모델 해석 가능성, 인과 관계 분석, Human-in-the-loop AI 및 대화형 데이터 시각화가 포함됩니다.
 정경훈(Jonathan) National Football League의 수석 소프트웨어 엔지니어입니다. 그는 지난 XNUMX년 동안 Next Gen Stats 팀에서 원시 데이터 스트리밍, 데이터 처리를 위한 마이크로서비스 구축, 처리된 데이터를 노출하는 API 구축에 이르는 플랫폼 구축을 도왔습니다. 그는 Amazon Machine Learning Solutions Lab과 협력하여 작업할 깨끗한 데이터를 제공하고 데이터 자체에 대한 도메인 지식을 제공했습니다. 업무 외 시간에는 로스앤젤레스에서 자전거 타기와 시에라에서 하이킹을 즐깁니다.
정경훈(Jonathan) National Football League의 수석 소프트웨어 엔지니어입니다. 그는 지난 XNUMX년 동안 Next Gen Stats 팀에서 원시 데이터 스트리밍, 데이터 처리를 위한 마이크로서비스 구축, 처리된 데이터를 노출하는 API 구축에 이르는 플랫폼 구축을 도왔습니다. 그는 Amazon Machine Learning Solutions Lab과 협력하여 작업할 깨끗한 데이터를 제공하고 데이터 자체에 대한 도메인 지식을 제공했습니다. 업무 외 시간에는 로스앤젤레스에서 자전거 타기와 시에라에서 하이킹을 즐깁니다.
 마이클 치 National Football League에서 차세대 통계 및 데이터 엔지니어링을 감독하는 기술 선임 이사입니다. 그는 University of Illinois at Urbana Champaign에서 수학 및 컴퓨터 과학 학위를 받았습니다. Michael은 2007년에 NFL에 처음 합류했으며 주로 축구 통계를 위한 기술 및 플랫폼에 중점을 두었습니다. 여가 시간에는 야외에서 가족과 함께 시간을 보내는 것을 즐깁니다.
마이클 치 National Football League에서 차세대 통계 및 데이터 엔지니어링을 감독하는 기술 선임 이사입니다. 그는 University of Illinois at Urbana Champaign에서 수학 및 컴퓨터 과학 학위를 받았습니다. Michael은 2007년에 NFL에 처음 합류했으며 주로 축구 통계를 위한 기술 및 플랫폼에 중점을 두었습니다. 여가 시간에는 야외에서 가족과 함께 시간을 보내는 것을 즐깁니다.
 마이크 밴드 National Football League의 Next Gen Stats 연구 및 분석 선임 관리자입니다. 2018년 팀에 합류한 이후 그는 팬, NFL 방송 파트너 및 32개 클럽 모두를 위한 선수 추적 데이터에서 파생된 주요 통계 및 통찰력의 아이디어 구상, 개발 및 커뮤니케이션을 담당했습니다. Mike는 시카고 대학교에서 분석학 석사 학위, 플로리다 대학교에서 스포츠 관리 학사 학위, 미네소타 바이킹스의 스카우트 부서 및 채용 부서에서 경험을 통해 팀에 풍부한 지식과 경험을 제공합니다. 플로리다 게이터 풋볼의
마이크 밴드 National Football League의 Next Gen Stats 연구 및 분석 선임 관리자입니다. 2018년 팀에 합류한 이후 그는 팬, NFL 방송 파트너 및 32개 클럽 모두를 위한 선수 추적 데이터에서 파생된 주요 통계 및 통찰력의 아이디어 구상, 개발 및 커뮤니케이션을 담당했습니다. Mike는 시카고 대학교에서 분석학 석사 학위, 플로리다 대학교에서 스포츠 관리 학사 학위, 미네소타 바이킹스의 스카우트 부서 및 채용 부서에서 경험을 통해 팀에 풍부한 지식과 경험을 제공합니다. 플로리다 게이터 풋볼의
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/predict-football-punt-and-kickoff-return-yards-with-fat-tailed-distribution-using-gluonts/

