기업이 확장됨에 따라 기업 네트워크 내 IP 주소에 대한 수요가 공급을 초과하는 경우가 많습니다. 조직의 네트워크는 미래의 요구 사항을 어느 정도 예상하여 설계하는 경우가 많지만, 기업이 발전함에 따라 정보 기술(IT) 요구 사항이 이전에 설계된 네트워크를 능가하게 됩니다. 기업은 제한된 IP 주소 풀을 관리하는 데 어려움을 겪을 수 있습니다.
데이터 엔지니어링 워크로드의 경우 AWS 접착제 이렇게 제한된 네트워크 구성에서 사용되기 때문에 팀은 때때로 많은 작업을 동시에 실행하는 데 어려움을 겪을 수 있습니다. 이는 데이터베이스에 대한 필수 연결을 지원하는 데 필요한 IP 주소가 충분하지 않기 때문에 발생합니다. 이러한 부족을 극복하기 위해 팀은 회사 네트워크 풀에서 더 많은 IP 주소를 얻을 수 있습니다. IP 주소가 회사 네트워크에서 재사용되는 경우 획득한 IP 주소는 고유하거나(중복되지 않음) 겹칠 수 있습니다.
겹치는 IP 주소를 사용하는 경우 연결을 설정하려면 추가 네트워크 관리가 필요합니다. 네트워킹 솔루션에는 다음과 같은 옵션이 포함될 수 있습니다. 개인 네트워크 주소 변환(NAT) 게이트웨이, AWS 프라이빗링크, 또는 자체 관리형 NAT 장비를 사용하여 IP 주소를 변환합니다.
이 게시물에서는 AWS Glue 작업을 확장하는 두 가지 전략에 대해 설명합니다.
- 데이터 처리 장치(DPU) 크기를 적절하게 조정하고, AWS Glue의 Auto Scaling 기능을 사용하고, 작업을 미세 조정하여 IP 주소 소비를 최적화합니다.
- 개인 NAT 게이트웨이를 통해 라우팅할 수 없는 추가적인 CIDR(Classless Inter-Domain Routing) 범위를 사용하여 네트워크 용량을 확장합니다.
이러한 솔루션에 대해 자세히 알아보기 전에 AWS Glue가 어떻게 사용하는지 이해해 보겠습니다. 탄력적 네트워크 인터페이스 (ENI) 연결을 설정합니다. VPC 내부의 데이터 스토어에 대한 액세스를 활성화하려면 VPC에 연결된 AWS Glue 연결을 생성해야 합니다. AWS Glue 작업이 VPC에서 실행되면 작업은 각 데이터 연결에 대해 구성된 VPC 내부에 ENI를 생성하고 해당 ENI는 지정된 VPC의 IP 주소를 사용합니다. 이러한 ENI는 작업이 완료될 때까지 수명이 짧고 활성 상태입니다.
이제 AWS Glue IP 주소 소비 최적화를 설명하는 첫 번째 솔루션을 살펴보겠습니다.
효율적인 IP 주소 사용을 위한 전략
AWS Glue에서는 작업에 사용되는 작업자 수에 따라 VPC 서브넷에서 사용되는 IP 주소 수가 결정됩니다. 이는 각 작업자마다 하나의 ENI에 매핑되는 하나의 IP 주소가 필요하기 때문입니다. AWS Glue 서브넷에 할당된 CIDR 범위가 충분하지 않으면 IP 주소 소진 오류가 발생할 수 있습니다. 다음은 AWS Glue IP 주소 사용을 최적화하기 위한 몇 가지 모범 사례입니다.
- 작업의 DPU 크기를 적절하게 조정 – AWS Glue는 분산 처리 엔진입니다. 작업을 병렬로 실행할 수 있으면 효율적으로 작동합니다. 작업에 필요한 DPU보다 많은 경우 작업이 항상 더 빠르게 실행되는 것은 아닙니다. 따라서 적절한 수의 DPU를 찾으면 IP 주소를 최적으로 사용할 수 있습니다. 시스템에 관측성을 구축하고 작업 성과를 분석함으로써 ENI 소비 추세에 대한 통찰력을 얻은 다음 작업에 적절한 용량을 적절한 크기로 구성할 수 있습니다. 자세한 내용은 다음을 참조하세요. DPU 용량 계획 모니터링. Spark UI는 AWS Glue 작업의 작업자 사용량을 모니터링하는 데 유용한 도구입니다. 자세한 내용은 다음을 참조하세요. Apache Spark 웹 UI를 사용하여 작업 모니터링.
- AWS Glue Auto Scaling – 작업의 용량 요구 사항을 미리 예측하기 어려운 경우가 많습니다. AWS Glue의 Auto Scaling 기능을 활성화하면 이러한 책임 중 일부가 AWS로 이전됩니다. 워크로드 요구 사항에 따라 런타임 시 작업은 작업자 노드를 정의된 최대 구성까지 자동으로 확장합니다. 추가 요구 사항이 없으면 AWS Glue는 작업자를 초과 프로비저닝하지 않으므로 리소스를 절약하고 비용을 절감할 수 있습니다. Auto Scaling 기능은 AWS Glue 3.0 이상에서 사용할 수 있습니다. 자세한 내용은 다음을 참조하세요. AWS Glue Auto Scaling 소개: 최적화된 Apache Spark로 더 저렴한 비용으로 서버리스 컴퓨팅 리소스의 크기를 자동으로 조정.
- 직무 수준 최적화 – 다음을 사용하여 직무 수준 최적화를 식별합니다. AWS Glue 작업 지표 , 다음의 모범 사례를 적용합니다. Apache Spark 작업용 AWS Glue 성능 튜닝 모범 사례.
다음으로 네트워크 용량 확장을 자세히 설명하는 두 번째 솔루션을 살펴보겠습니다.
네트워크 규모(IP 주소) 확장을 위한 솔루션
이 섹션에서는 네트워크 크기를 확장할 수 있는 두 가지 솔루션에 대해 자세히 설명합니다.
라우팅 가능한 주소로 VPC CIDR 범위 확장
한 가지 해결책은 다음에서 더 많은 개인 IPv4 CIDR 범위를 추가하는 것입니다. RFC 1918 귀하의 VPC에. 이론적으로 각 AWS 계정은 이러한 IP 주소 CIDR의 일부 또는 전부에 할당될 수 있습니다. IPAM(IP 주소 관리) 팀은 여러 AWS 계정 또는 사업부에서 IP 주소가 겹치는 것을 방지하기 위해 RFC1918에서 각 사업부가 사용할 수 있는 IP 주소 할당을 관리하는 경우가 많습니다. IPAM 팀에서 할당한 현재 라우팅 가능한 IP 주소 할당량이 충분하지 않은 경우 더 많은 것을 요청할 수 있습니다.
IPAM 팀이 겹치지 않는 추가 CIDR 범위를 발급하는 경우 이를 기존 VPC에 보조 CIDR로 추가하거나 이를 사용하여 새 VPC를 생성할 수 있습니다. 새 VPC를 생성하려는 경우 다음을 통해 VPC를 상호 연결할 수 있습니다. VPC 피어링 or AWS 전송 게이트웨이.
이 추가 용량이 정의된 기간 내에 모든 작업을 실행하기에 충분하다면 간단하고 비용 효과적인 솔루션입니다. 그렇지 않으면 다음 섹션에 설명된 대로 개인 NAT 게이트웨이와 겹치는 IP 주소를 채택하는 것을 고려할 수 있습니다. 다음 솔루션에서는 Transit Gateway를 사용하여 VPC를 연결해야 합니다. 두 VPC에 CIDR 범위가 겹치면 VPC 피어링이 불가능하기 때문입니다.
프라이빗 NAT 게이트웨이로 라우팅할 수 없는 CIDR 구성
AWS 백서에 설명된 대로 확장 가능하고 안전한 다중 VPC AWS 네트워크 인프라 구축, 라우팅할 수 없는 IP 주소 서브넷을 생성하고 라우팅할 수 있는 IP 주소 공간(비중첩)에 있는 개인 NAT 게이트웨이를 사용하여 트래픽을 라우팅함으로써 네트워크 용량을 확장할 수 있습니다. 개인 NAT 게이트웨이는 라우팅할 수 없는 IP 주소와 라우팅할 수 있는 IP 주소 간의 트래픽을 변환하고 라우팅합니다. 다음 다이어그램은 AWS Glue를 참조하여 솔루션을 보여줍니다.
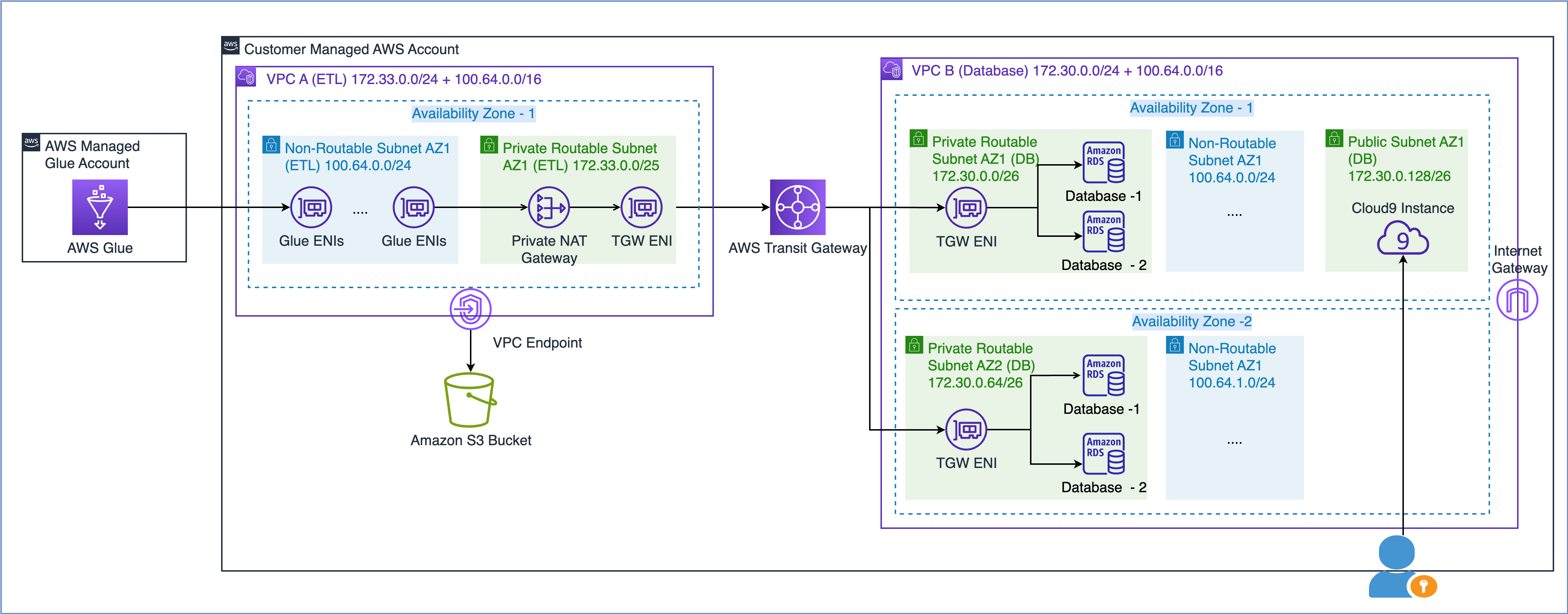
위 다이어그램에서 볼 수 있듯이 VPC A(ETL)에는 두 개의 CIDR 범위가 연결되어 있습니다. 더 작은 CIDR 범위 172.33.0.0/24는 어디에서도 재사용되지 않으므로 라우팅 가능하지만, 더 큰 CIDR 범위 100.64.0.0/16은 데이터베이스 VPC에서 재사용되기 때문에 라우팅이 불가능합니다.
VPC B(데이터베이스)에서는 라우팅 가능한 서브넷 172.30.0.0/26 및 172.30.0.64/26에 두 개의 데이터베이스를 호스팅했습니다. 이 두 서브넷은 고가용성을 위해 두 개의 별도 가용 영역에 있습니다. 또한 라우팅할 수 없는 설정을 시뮬레이션하기 위해 사용되지 않은 추가 서브넷 100.64.0.0/24 및 100.64.1.0/24가 XNUMX개 있습니다.
용량 요구 사항에 따라 라우팅할 수 없는 CIDR 범위의 크기를 선택할 수 있습니다. IP 주소를 재사용할 수 있으므로 필요에 따라 매우 큰 서브넷을 만들 수 있습니다. 예를 들어 CIDR 마스크 /16은 약 65,000개의 IPv4 주소를 제공합니다. 네트워크 엔지니어링 팀과 협력하여 서브넷 크기를 조정할 수 있습니다.
즉, VPC에서 라우팅 가능한 서브넷과 라우팅 불가능한 서브넷을 모두 사용하도록 AWS Glue 작업을 구성하여 사용 가능한 IP 주소 풀을 최대화할 수 있습니다.
이제 라우팅할 수 없는 서브넷에 있는 Glue ENI가 다른 VPC의 데이터 소스와 통신하는 방법을 살펴보겠습니다.
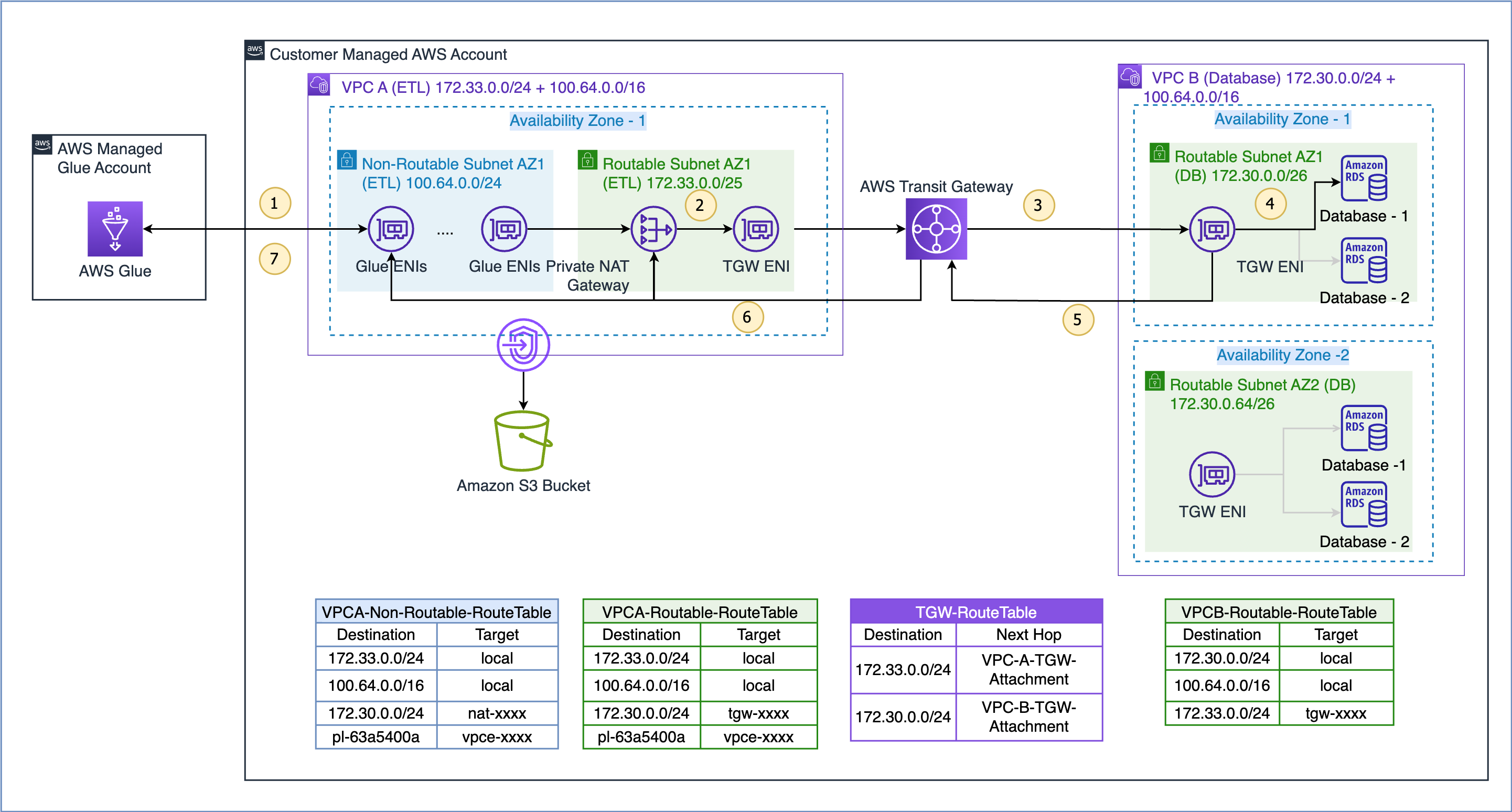
여기에 설명된 사용 사례의 데이터 흐름은 다음과 같습니다(위 그림의 번호가 매겨진 단계 참조).
- AWS Glue 작업이 데이터 소스에 액세스해야 하는 경우 먼저 작업에서 AWS Glue 연결을 사용하고 VPC A의 라우팅할 수 없는 서브넷 100.64.0.0/24에 ENI를 생성합니다. 나중에 AWS Glue는 데이터베이스 연결 구성을 사용하고 VPC B 172.30.0.0/24의 데이터베이스에 연결을 시도합니다.
- 라우팅 테이블에 따르면
VPCA-Non-Routable-RouteTable대상 172.30.0.0/24는 개인 NAT 게이트웨이에 대해 구성됩니다. 요청은 NAT 게이트웨이로 전송되며, NAT 게이트웨이는 소스 IP 주소를 라우팅할 수 없는 IP 주소에서 라우팅할 수 있는 IP 주소로 변환합니다. 그런 다음 트래픽은 VPC A의 Transit Gateway 연결로 전송됩니다.VPCA-Routable-RouteTableVPC A의 라우팅 테이블 - Transit Gateway는 172.30.0.0/24 경로를 사용하고 트래픽을 VPC B Transit Gateway 연결로 보냅니다.
- VPC B의 전송 게이트웨이 ENI는 VPC B의 로컬 경로를 사용하여 데이터베이스 엔드포인트에 연결하고 데이터를 쿼리합니다.
- 쿼리가 완료되면 응답이 다시 VPC A로 전송됩니다. 응답 트래픽은 VPC B의 Transit Gateway 연결로 라우팅된 다음 Transit Gateway는 172.33.0.0/24 경로를 사용하고 트래픽을 VPC A Transit Gateway 연결로 보냅니다. .
- VPC A의 전송 게이트웨이 ENI는 로컬 경로를 사용하여 프라이빗 NAT 게이트웨이로 트래픽을 전달합니다. 그러면 프라이빗 NAT 게이트웨이가 대상 IP 주소를 라우팅할 수 없는 서브넷의 ENI 주소로 변환합니다.
- 마지막으로 AWS Glue 작업은 데이터를 수신하고 계속 처리합니다.
개인 NAT 게이트웨이 솔루션은 조직의 라우팅 가능한 네트워크에서 추가 IP 주소를 얻을 수 없을 때 추가 IP 주소가 필요한 경우에 사용할 수 있는 옵션입니다. 때로는 각각의 추가 서비스에 추가 비용이 발생하며 이러한 절충은 목표를 달성하는 데 필요합니다. NAT 게이트웨이 가격 섹션을 참조하세요. Amazon VPC 요금 페이지
사전 조건
프라이빗 NAT 게이트웨이 솔루션 연습을 완료하려면 다음이 필요합니다.
솔루션 배포
솔루션을 구현하려면 다음 단계를 완료하십시오.
- AWS 관리 콘솔에 로그인합니다.
- 클릭하여 솔루션 배포
 . 이 스택의 기본값은
. 이 스택의 기본값은 us-east-1에서 원하는 지역을 선택할 수 있습니다. - 다음 것 그런 다음 스택 세부 정보를 지정합니다. 입력 매개변수를 미리 채워진 기본값으로 유지하거나 필요에 따라 변경할 수 있습니다.
- 럭셔리
DatabaseUserPassword, 원하는 영숫자 비밀번호를 입력하고 나중에 사용할 수 있도록 기록해 두십시오. - 럭셔리
S3BucketName, 고유한 이름을 입력하세요. 아마존 단순 스토리지 서비스 (Amazon S3) 버킷 이름. 이 버킷은 AWS 공개 코드 리포지토리에서 복사될 AWS Glue 작업 스크립트를 저장합니다.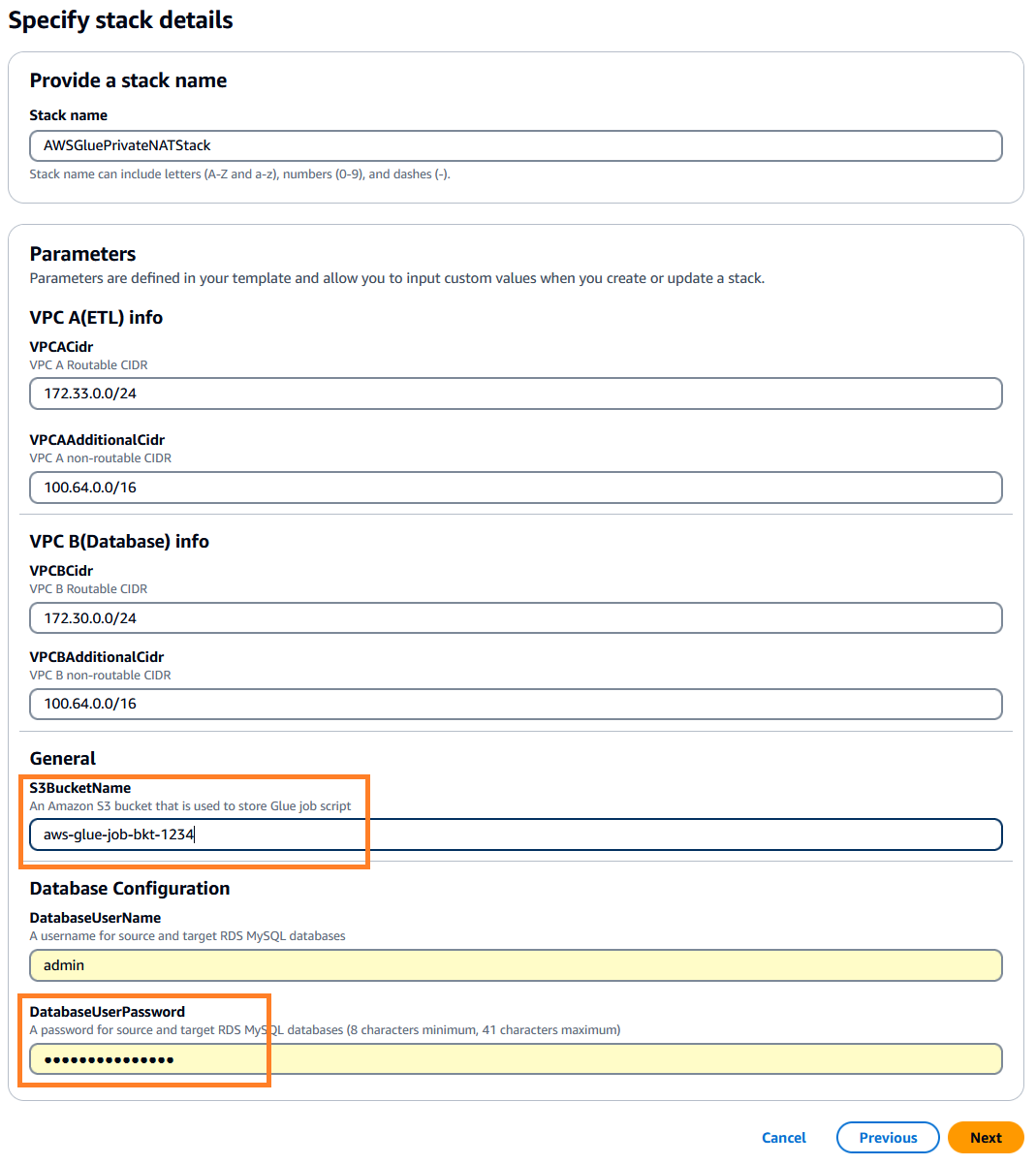
- 다음 것.
- 기본값을 그대로 두고 다음을 클릭합니다. 다음 것 또.
- 세부정보를 검토하고 IAM 리소스 생성을 확인한 후 다음을 클릭합니다. 제출 배포를 시작합니다.
이벤트를 모니터링하여 AWS CloudFormation 콘솔에서 생성되는 리소스를 확인할 수 있습니다. 스택 리소스가 생성되는 데 약 20분 정도 걸릴 수 있습니다.
스택 생성이 완료되면 AWS CloudFormation 콘솔의 출력 탭으로 이동하여 나중에 사용할 수 있도록 다음 값을 기록해 두십시오.
DBSourceDBTargetSourceCrawlerTargetCrawler
AWS Cloud9 인스턴스에 연결
다음으로, 다음을 사용하여 MySQL용 소스 및 대상 Amazon RDS 테이블을 준비해야 합니다. AWS 클라우드9 사례. 다음 단계를 완료하세요.
- AWS Cloud9 콘솔 페이지에서
aws-glue-cloud9환경을 제공합니다. - Cloud9 IDE 열에서 다음을 클릭합니다. 엽니다 새 웹 브라우저에서 AWS Cloud9 인스턴스를 시작합니다.
소스 MySQL 테이블 준비
소스 테이블을 준비하려면 다음 단계를 완료하세요.
- AWS Cloud9 터미널에서 다음 명령을 사용하여 MySQL 클라이언트를 설치합니다.
sudo yum update -y && sudo yum install -y mysql - 다음 명령을 사용하여 소스 데이터베이스에 연결합니다. 소스 호스트 이름을 이전에 캡처한 DBSource 값으로 바꿉니다. 메시지가 표시되면 스택 생성 중에 지정한 데이터베이스 암호를 입력합니다.
mysql -h <Source Hostname> -P 3306 -u admin -p - 다음 스크립트를 실행하여 소스를 생성하세요.
emp테이블을 만들고 테스트 데이터를 로드합니다.-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - 소스 확인
emp아래 SQL 쿼리를 사용하여 테이블 개수를 계산합니다(나중 단계에서 확인을 위해 필요함).select count(*) from emp; - 다음 명령을 실행하여 MySQL 클라이언트 유틸리티를 종료하고 AWS Cloud9 인스턴스 터미널로 돌아갑니다.
quit;
대상 MySQL 테이블 준비
대상 테이블을 준비하려면 다음 단계를 완료하십시오.
- 다음 명령을 사용하여 대상 데이터베이스에 연결합니다. 대상 호스트 이름을 이전에 캡처한 DBTarget 값으로 바꿉니다. 메시지가 표시되면 스택 생성 중에 지정한 데이터베이스 비밀번호를 입력하십시오.
mysql -h <Target Hostname> -P 3306 -u admin -p - 다음 스크립트를 실행하여 대상을 만듭니다.
emp테이블. 이 테이블은 후속 단계에서 AWS Glue 작업에 의해 로드됩니다.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
네트워킹 설정 확인(선택 사항)
다음 단계는 프라이빗 NAT 게이트웨이 솔루션의 NAT 게이트웨이, 라우팅 테이블 및 전송 게이트웨이 구성을 이해하는 데 유용합니다. 이러한 구성 요소는 CloudFormation 스택 생성 중에 생성되었습니다.
- Amazon VPC 콘솔 페이지에서 Virtual Private Cloud 섹션으로 이동하여 NAT 게이트웨이를 찾습니다.
- 이름으로 NAT 게이트웨이 검색
Glue-OverlappingCIDR-NATGW더 자세히 살펴보세요. 다음 스크린샷에서 볼 수 있듯이 NAT 게이트웨이는 라우팅 가능한 서브넷의 VPC A(ETL)에 생성되었습니다.
- 왼쪽 탐색 창에서 Virtual Private Cloud 섹션 아래의 라우팅 테이블로 이동합니다.
- 에 대한 검색
VPCA-Non-Routable-RouteTable더 자세히 살펴보세요. NAT 게이트웨이를 사용하여 겹치는 CIDR의 트래픽을 변환하도록 라우팅 테이블이 구성되어 있음을 확인할 수 있습니다.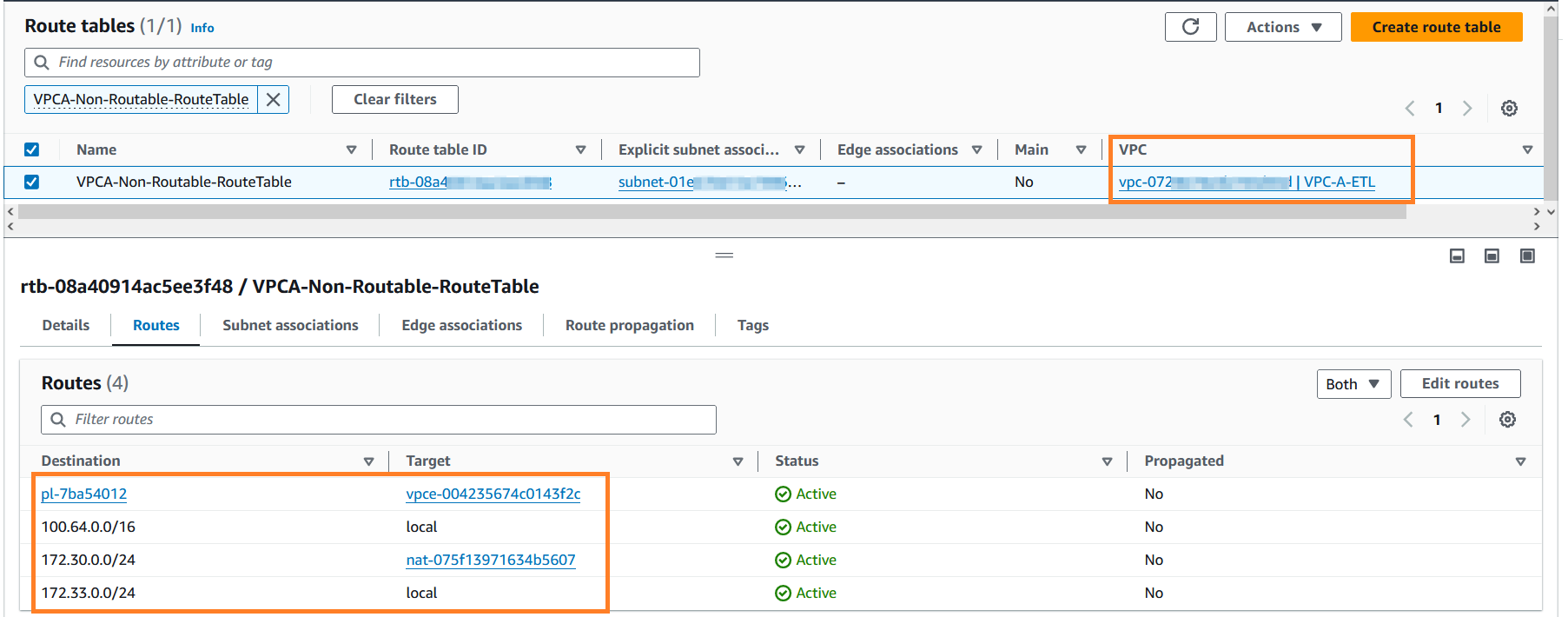
- 왼쪽 탐색 창에서 Transit Gateway 섹션으로 이동하여 Transit Gateway 첨부 파일을 클릭합니다. 입력하다
VPC-검색 상자에서 새로 생성된 Transit Gateway 연결 2개를 찾습니다. - 이러한 첨부 파일을 더 자세히 탐색하여 해당 구성을 알아볼 수 있습니다.
AWS Glue 크롤러 실행
소스와 대상을 카탈로그화하는 데 필요한 AWS Glue 크롤러를 실행하려면 다음 단계를 완료하십시오. emp 테이블. 이는 AWS Glue 작업을 실행하기 위한 필수 단계입니다.
- AWS Glue 콘솔 페이지의 탐색 창에 있는 데이터 카탈로그 섹션에서 다음을 클릭합니다. 겉옷.
- 앞서 기록한 소스 및 대상 크롤러를 찾으십시오.
- 해당 크롤러를 선택하고 다음을 클릭하세요. 달리기 해당 AWS Glue 데이터 카탈로그 테이블을 생성합니다.
- 성공적인 완료를 위해 AWS Glue 크롤러를 모니터링할 수 있습니다. 두 크롤러가 모두 완료되는 데 약 3~4분 정도 걸릴 수 있습니다. 완료되면 작업의 마지막 실행 상태가 성공으로 변경되고, 이 실행에서 생성된 두 개의 AWS Glue 카탈로그 테이블도 볼 수 있습니다.

AWS Glue ETL 작업 실행
테이블을 설정하고 사전 조건 단계를 완료한 후에는 이제 CloudFormation 템플릿을 사용하여 생성한 AWS Glue 작업을 실행할 준비가 되었습니다. 이 작업은 소스 MySQL용 RDS 데이터베이스에 연결하고, 데이터를 추출하고, 대상 MySQL용 RDS 데이터베이스에 데이터를 로드합니다. 이 작업은 원본 MySQL 테이블에서 데이터를 읽고 프라이빗 NAT 게이트웨이 솔루션을 사용하여 대상 MySQL 테이블에 로드합니다. AWS Glue 작업을 실행하려면 다음 단계를 완료하세요.
- AWS Glue 콘솔에서 다음을 클릭합니다. ETL 작업 탐색 창에서
- 직업을 클릭하세요
glue-private-nat-job. - 달리기 그것을 시작하십시오.
다음은 이 ETL 작업에 대한 PySpark 스크립트입니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
작업의 DPU 구성에 따라 AWS Glue는 AWS Glue 연결에 구성된 라우팅할 수 없는 서브넷에 ENI 세트를 생성합니다. 네트워크 인터페이스 페이지에서 이러한 ENI를 모니터링할 수 있습니다. 아마존 엘라스틱 컴퓨트 클라우드 (아마존 EC2) 콘솔.
아래 스크린샷은 작업 매개변수에 구성된 요청된 작업자 수와 일치하도록 작업 실행을 위해 생성된 10개의 ENI를 보여줍니다. 예상한 대로 ENI는 라우팅할 수 없는 VPC A의 서브넷에 생성되어 IP 주소의 확장성을 가능하게 했습니다. 작업이 완료되면 이러한 ENI는 AWS Glue에 의해 자동으로 릴리스됩니다.
AWS Glue 작업이 실행 중일 때 상태를 모니터링할 수 있습니다. 성공적으로 완료되면 작업 상태가 다음으로 변경됩니다. 성공.
결과 확인
AWS Glue 작업이 완료된 후 대상 MySQL 데이터베이스에 연결합니다. 대상 레코드 수가 소스와 일치하는지 확인하십시오. AWS Cloud9 터미널에서 아래 SQL 쿼리를 사용할 수 있습니다.
USE targetdb;
SELECT count(*) from emp;마지막으로 다음 명령을 사용하여 MySQL 클라이언트 유틸리티를 종료하고 AWS Cloud9 터미널로 돌아갑니다. quit;
이제 AWS Glue가 라우팅할 수 없는 서브넷의 IP 주소를 사용하여 대상 데이터베이스에 데이터를 로드하는 작업을 성공적으로 완료했는지 확인할 수 있습니다. 이것으로 개인 NAT 게이트웨이 솔루션에 대한 엔드투엔드 테스트를 마칩니다.
정리
향후 비용이 발생하지 않도록 하려면 다음 단계를 완료하여 CloudFormation 스택을 통해 생성된 리소스를 삭제하십시오.
- AWS CloudFormation 콘솔의 탐색 창에서 스택을 클릭합니다.
- 스택 선택
AWSGluePrivateNATStack. - 스택을 삭제하려면 삭제를 클릭하세요. 메시지가 표시되면 스택 삭제를 확인합니다.
결론
이 게시물에서는 프라이빗 NAT 게이트웨이 솔루션을 사용하여 IP 주소 소비를 최적화하고 네트워크 용량을 확장하여 AWS Glue 작업을 확장하는 방법을 시연했습니다. 이 2중 접근 방식은 IP 주소 용량 제약이 있는 환경에서 차단을 해제하는 데 도움이 됩니다. AWS Glue IP 주소 최적화 섹션에서 설명한 옵션은 IP 주소 확장 솔루션을 보완하며, 반복적으로 구축하여 데이터 플랫폼을 완성할 수 있습니다.
다음에서 AWS Glue 작업 최적화 기술에 대해 자세히 알아보세요. Apache Spark용 AWS Glue에서 비용 모니터링 및 최적화 과 AWS Glue를 사용하여 Apache Spark 작업을 확장하고 데이터를 분할하는 모범 사례.
저자 소개
 수샨스 코타팔리 자동차 및 제조 고객을 지원하는 Amazon Web Services의 솔루션 설계자입니다. 그는 비즈니스 목표를 달성하기 위한 기술 솔루션 설계에 열정을 갖고 있으며 서버리스 및 이벤트 중심 아키텍처에 깊은 관심을 가지고 있습니다.
수샨스 코타팔리 자동차 및 제조 고객을 지원하는 Amazon Web Services의 솔루션 설계자입니다. 그는 비즈니스 목표를 달성하기 위한 기술 솔루션 설계에 열정을 갖고 있으며 서버리스 및 이벤트 중심 아키텍처에 깊은 관심을 가지고 있습니다.
 센틸 카말라 라티남 데이터 및 분석을 전문으로 하는 Amazon Web Services의 솔루션 설계자입니다. 그는 고객이 최신 데이터 플랫폼을 설계하고 구축할 수 있도록 돕는 데 열정을 쏟고 있습니다. 여가 시간에는 Senthil은 가족과 함께 시간을 보내고 배드민턴을 치는 것을 좋아합니다.
센틸 카말라 라티남 데이터 및 분석을 전문으로 하는 Amazon Web Services의 솔루션 설계자입니다. 그는 고객이 최신 데이터 플랫폼을 설계하고 구축할 수 있도록 돕는 데 열정을 쏟고 있습니다. 여가 시간에는 Senthil은 가족과 함께 시간을 보내고 배드민턴을 치는 것을 좋아합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

