この投稿は、BigBasket の Santosh Waddi と Nanda Kishore Thatikonda の共同執筆です。
ビッグバスケット はインド最大のオンライン食品および食料品店です。クイック コマース、スロット配信、毎日のサブスクリプションなど、複数の e コマース チャネルで運営されています。実店舗や自動販売機でもお買い求めいただけます。 50,000 のブランド、1,000 を超える製品という幅広い品揃えを提供し、500 以上の都市や町で事業を展開しています。 BigBasket は 10 万人以上の顧客にサービスを提供しています。
この投稿では、BigBasket がどのように使用されたかについて説明します。 アマゾンセージメーカー 日用消費財 (FMCG) 製品識別用のコンピューター ビジョン モデルをトレーニングすることで、トレーニング時間を約 50% 削減し、コストを 20% 節約することができました。
お客様の課題
現在、インドのほとんどのスーパーマーケットや実店舗では、レジカウンターでの手動チェックアウトが提供されています。これには 2 つの問題があります。
- 規模が拡大するにつれて、追加の人員、重量シール、店舗運営チームの繰り返しのトレーニングが必要になります。
- ほとんどの店舗では、チェックアウト カウンターと計量カウンターが異なるため、顧客の購入までの過程で摩擦が生じます。顧客は多くの場合、重量ステッカーを紛失してしまい、精算プロセスに進む前に計量カウンターに戻ってステッカーを再度受け取ります。
セルフレジの流れ
BigBasket は、カメラを使用して商品を独自に区別する AI を活用したチェックアウト システムを実店舗に導入しました。次の図は、チェックアウト プロセスの概要を示しています。
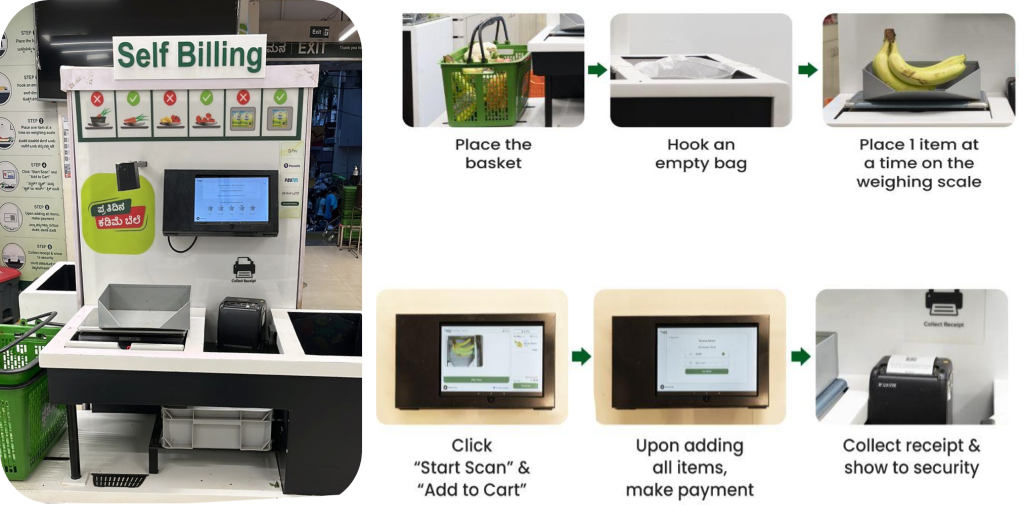
BigBasket チームは、コンピューター ビジョンのオブジェクト認識用のオープンソースの社内 ML アルゴリズムを実行して、AI 対応のチェックアウトを強化していました。 フレショ (物理的な)店舗。既存のセットアップを運用するには次の課題に直面していました。
- 新製品が継続的に導入されるため、コンピューター ビジョン モデルには新製品情報を継続的に組み込む必要がありました。このシステムは、12,000 以上の在庫管理単位 (SKU) からなる大規模なカタログを処理する必要があり、新しい SKU は毎月 600 以上のペースで継続的に追加されていました。
- 新製品に対応するために、最新のトレーニング データを使用して新しいモデルが毎月作成されました。新製品に適応するためにモデルを頻繁にトレーニングするにはコストと時間がかかりました。
- BigBasket は、市場投入までの時間を短縮するためにトレーニング サイクル時間を短縮したいと考えていました。 SKU の増加により、モデルにかかる時間は直線的に増加しており、トレーニングの頻度が非常に高く、長い時間がかかるため、市場投入までの時間に影響を及ぼしました。
- モデルのトレーニングのためのデータ拡張と、完全なエンドツーエンドのトレーニング サイクルを手動で管理することにより、大幅なオーバーヘッドが追加されていました。 BigBasket はこれをサードパーティのプラットフォームで実行していましたが、これには多大なコストがかかりました。
ソリューションの概要
これらの課題に対処するために、BigBasket に対し、SageMaker を使用して既存の日用消費財製品の検出および分類ソリューションを再構築することを推奨しました。 BigBasket は、本格的な運用に移行する前に、パフォーマンス、コスト、利便性の指標を評価するために SageMaker でパイロットを試みました。
彼らの目的は、SKU 検出のために既存のコンピューター ビジョン機械学習 (ML) モデルを微調整することでした。畳み込みニューラル ネットワーク (CNN) アーキテクチャを使用しました。 レスネット152 画像分類用。 SKU あたり約 300 枚の画像からなる大規模なデータセットがモデル トレーニング用に推定され、合計 4 万枚を超えるトレーニング画像が生成されました。特定の SKU については、より広範囲の環境条件を網羅するためにデータを増強しました。
次の図は、ソリューションのアーキテクチャを示しています。

完全なプロセスは、次の高レベルの手順に要約できます。
- データのクレンジング、注釈、および拡張を実行します。
- データを Amazon シンプル ストレージ サービス (Amazon S3)バケット。
- SageMaker を使用して、 光沢のためのAmazonFSx 効率的なデータ増強のために。
- データをトレーニング セット、検証セット、テスト セットに分割します。 Lustre には FSx を使用し、 Amazon リレーショナル データベース サービス (Amazon RDS) による高速並列データ アクセス。
- カスタムを使用する パイトーチ 他のオープンソース ライブラリを含む Docker コンテナ。
- SageMaker 分散データ並列処理 (SMDDP) 分散トレーニングを加速します。
- モデルのトレーニング メトリクスをログに記録します。
- 最終モデルを S3 バケットにコピーします。
ビッグバスケット使用 SageMaker ノートブック ML モデルをトレーニングし、既存のオープンソース PyTorch やその他のオープンソースの依存関係を SageMaker PyTorch コンテナに簡単に移植して、パイプラインをシームレスに実行することができました。これは、BigBasket チームが認識した最初の利点でした。SageMaker 環境での実行に互換性を持たせるためにコードに必要な変更がほとんどなかったためです。
モデル ネットワークは、ResNet 152 アーキテクチャとそれに続く完全に接続された層で構成されます。低レベルのフィーチャ レイヤーをフリーズし、ImageNet モデルからの転移学習を通じて取得した重みを保持しました。モデル パラメーターの合計は 66 万で、トレーニング可能なパラメーターは 23 万で構成されています。この転移学習ベースのアプローチにより、トレーニング時に使用する画像が減り、より高速な収束が可能になり、総トレーニング時間も短縮されました。
モデルの構築とトレーニング Amazon SageMakerスタジオ モデルの準備、構築、トレーニング、調整に必要なものすべてを備えた統合開発環境 (IDE) を提供しました。画像のトリミング、回転、反転などの手法を使用してトレーニング データを拡張すると、モデルのトレーニング データとモデルの精度が向上します。
AWS インフラストラクチャ向けに特別に設計された最適化された通信アルゴリズムを含む SMDDP ライブラリの使用により、モデルのトレーニングが 50% 高速化されました。モデルのトレーニングおよびデータ拡張中のデータの読み取り/書き込みパフォーマンスを向上させるために、高パフォーマンスのスループットを実現する FSx for Lustre を使用しました。
開始時のトレーニング データ サイズは 1.5 TB を超えていました。うちは2つ使いました アマゾン エラスティック コンピューティング クラウド (Amazon EC2) p4d.24 ラージ インスタンス 8 GPU と 40 GB GPU メモリを搭載。 SageMaker 分散トレーニングの場合、インスタンスは同じ AWS リージョンとアベイラビリティーゾーンにある必要があります。また、S3 バケットに保存されているトレーニング データは、同じアベイラビリティーゾーンに存在する必要があります。このアーキテクチャでは、BigBasket が他のインスタンス タイプに変更したり、現在のアーキテクチャにインスタンスを追加したりして、大幅なデータ増加に対応したり、トレーニング時間のさらなる短縮を実現したりすることもできます。
SMDDP ライブラリがトレーニング時間、コスト、複雑さを軽減するのにどのように役立ったか
従来の分散データ トレーニングでは、トレーニング フレームワークが GPU (ワーカー) にランクを割り当て、各 GPU 上にモデルのレプリカを作成します。各トレーニング反復中に、グローバル データ バッチが部分 (バッチ シャード) に分割され、その部分が各ワーカーに配布されます。次に、各ワーカーは、各 GPU 上のトレーニング スクリプトで定義された前方パスと後方パスを続行します。最後に、さまざまなモデル レプリカからのモデルの重みと勾配は、AllReduce と呼ばれる集合通信操作を通じて反復の最後に同期されます。各ワーカーと GPU がモデルの同期されたレプリカを取得した後、次の反復が開始されます。
SMDDP ライブラリは、この分散データ並列トレーニング プロセスのパフォーマンスを向上させる集合通信ライブラリです。 SMDDP ライブラリは、AllReduce などの主要な集合通信操作の通信オーバーヘッドを削減します。 AllReduce の実装は AWS インフラストラクチャ向けに設計されており、AllReduce 操作をバックワード パスとオーバーラップさせることでトレーニングを高速化できます。このアプローチは、CPU と GPU 間のカーネル操作を最適化することで、ほぼ線形のスケーリング効率とより高速なトレーニング速度を実現します。
次の計算に注意してください。
- グローバル バッチのサイズは、(クラスター内のノード数) * (ノードあたりの GPU の数) * (バッチ シャードあたり) です。
- バッチ シャード (小さなバッチ) は、反復ごとに各 GPU (ワーカー) に割り当てられるデータセットのサブセットです。
BigBasket は、SMDDP ライブラリを使用して全体のトレーニング時間を短縮しました。 FSx for Lustre を使用すると、モデルのトレーニングとデータ拡張中のデータの読み取り/書き込みスループットが削減されました。データ並列処理により、BigBasket は他の代替手段と比較してほぼ 50% 高速かつ 20% 安価なトレーニングを達成することができ、AWS で最高のパフォーマンスを実現しました。 SageMaker は、完了後にトレーニング パイプラインを自動的にシャットダウンします。 AWS ではトレーニング時間が 50% 短縮され、プロジェクトは正常に完了しました (AWS では 4.5 日、従来のプラットフォームでは 9 日)。
この記事の執筆時点で、BigBasket は完全なソリューションを実稼働環境で 6 か月以上実行し、新しい都市に対応してシステムを拡張しており、毎月新しい店舗を追加しています。
「SMDDP サービスを使用した分散トレーニングへの移行に関する AWS とのパートナーシップは大きな成功を収めました。トレーニング時間が 50% 削減されただけでなく、20% 安くなりました。私たちのパートナーシップ全体において、AWS は顧客のこだわりと結果の提供に基準を設け、約束されたメリットを実現するために私たちと協力してきました。」
– BigBasket エンジニアリング責任者 Keshav Kumar 氏。
まとめ
この投稿では、BigBasket が SageMaker を使用して日用消費財製品識別用のコンピューター ビジョン モデルをトレーニングした方法について説明しました。 AI を活用した自動セルフ チェックアウト システムの導入により、イノベーションを通じて小売顧客のエクスペリエンスが向上し、同時にチェックアウト プロセスにおける人的ミスが排除されます。 SageMaker 分散トレーニングを使用して新製品のオンボーディングを加速すると、SKU のオンボーディングの時間とコストが削減されます。 FSx for Lustre を統合すると、高速な並列データ アクセスが可能になり、毎月数百もの新しい SKU を使用して効率的にモデルを再トレーニングできます。全体として、この AI ベースのセルフ チェックアウト ソリューションは、フロントエンド チェックアウト エラーのない強化されたショッピング エクスペリエンスを提供します。自動化とイノベーションにより、小売店のチェックアウトとオンボーディング業務が変革されました。
SageMaker は、コードの作成、データ取得、データタグ付け、モデルトレーニング、モデルチューニング、デプロイメント、モニタリングなどのための SageMaker Studio ノートブック環境など、エンドツーエンドの ML 開発、デプロイメント、モニタリング機能を提供します。あなたのビジネスがこの投稿で説明したいずれかの課題に直面しており、市場投入までの時間を節約してコストを改善したい場合は、お住まいの地域の AWS アカウント チームに連絡して、SageMaker の使用を開始してください。
著者について
 サントシュ・ワディ BigBasket の主任エンジニアであり、AI の課題解決に 10 年以上の専門知識をもたらしています。コンピューター ビジョン、データ サイエンス、ディープ ラーニングの強力な背景を持ち、IIT ボンベイで大学院の学位を取得しています。 Santosh は、著名な IEEE 出版物を執筆しており、ベテランの技術ブログ著者として、Samsung 在職中にコンピュータ ビジョン ソリューションの開発にも多大な貢献をしてきました。
サントシュ・ワディ BigBasket の主任エンジニアであり、AI の課題解決に 10 年以上の専門知識をもたらしています。コンピューター ビジョン、データ サイエンス、ディープ ラーニングの強力な背景を持ち、IIT ボンベイで大学院の学位を取得しています。 Santosh は、著名な IEEE 出版物を執筆しており、ベテランの技術ブログ著者として、Samsung 在職中にコンピュータ ビジョン ソリューションの開発にも多大な貢献をしてきました。
 ナンダ・キショア・タティコンダ BigBasket でデータ エンジニアリングと分析を率いるエンジニアリング マネージャーです。 Nanda は異常検出用の複数のアプリケーションを構築しており、同様の分野で特許を申請しています。彼は、エンタープライズ グレードのアプリケーションの構築、複数の組織でのデータ プラットフォームの構築、およびデータに裏付けられた意思決定を合理化するためのレポート プラットフォームに取り組んできました。 Nanda は、Java/J18EE、Spring テクノロジ、および Hadoop と Apache Spark を使用したビッグ データ フレームワークで 2 年以上の経験があります。
ナンダ・キショア・タティコンダ BigBasket でデータ エンジニアリングと分析を率いるエンジニアリング マネージャーです。 Nanda は異常検出用の複数のアプリケーションを構築しており、同様の分野で特許を申請しています。彼は、エンタープライズ グレードのアプリケーションの構築、複数の組織でのデータ プラットフォームの構築、およびデータに裏付けられた意思決定を合理化するためのレポート プラットフォームに取り組んできました。 Nanda は、Java/J18EE、Spring テクノロジ、および Hadoop と Apache Spark を使用したビッグ データ フレームワークで 2 年以上の経験があります。
 スダンシュ・ヘイト は AWS のプリンシパル AI & ML スペシャリストであり、クライアントと連携して MLOps と生成 AI の取り組みについてアドバイスを行っています。前職では、オープン ソース ベースの AI およびゲーミフィケーション プラットフォームを基礎から構築するためにチームを概念化し、作成し、主導し、100 を超えるクライアントで商用化に成功しました。 Sudhanshu はいくつかの特許を取得しています。 2 冊の本、いくつかの論文、ブログを執筆しています。そしてさまざまなフォーラムで彼の見解を発表しました。彼は思想的リーダーであり講演者でもあり、この業界に 25 年近く携わっています。彼は世界中のフォーチュン 1000 のクライアントと仕事をしてきましたが、最近ではインドのデジタル ネイティブのクライアントと仕事をしています。
スダンシュ・ヘイト は AWS のプリンシパル AI & ML スペシャリストであり、クライアントと連携して MLOps と生成 AI の取り組みについてアドバイスを行っています。前職では、オープン ソース ベースの AI およびゲーミフィケーション プラットフォームを基礎から構築するためにチームを概念化し、作成し、主導し、100 を超えるクライアントで商用化に成功しました。 Sudhanshu はいくつかの特許を取得しています。 2 冊の本、いくつかの論文、ブログを執筆しています。そしてさまざまなフォーラムで彼の見解を発表しました。彼は思想的リーダーであり講演者でもあり、この業界に 25 年近く携わっています。彼は世界中のフォーチュン 1000 のクライアントと仕事をしてきましたが、最近ではインドのデジタル ネイティブのクライアントと仕事をしています。
 アユシュ・クマール AWS のソリューションアーキテクトです。彼はさまざまな AWS 顧客と協力し、顧客が最新の最新アプリケーションを導入し、クラウドネイティブ テクノロジーでより迅速に革新できるよう支援しています。彼が暇なときにキッチンで実験しているのがわかります。
アユシュ・クマール AWS のソリューションアーキテクトです。彼はさまざまな AWS 顧客と協力し、顧客が最新の最新アプリケーションを導入し、クラウドネイティブ テクノロジーでより迅速に革新できるよう支援しています。彼が暇なときにキッチンで実験しているのがわかります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

