アマゾンセージメーカー、エンドツーエンドの機械学習 (ML) ライフサイクル全体を管理できます。 実験の追跡や、モデル レジストリを介したモデル ガバナンスなど、ML ワークフローの側面を管理するのに役立つ多くのネイティブ機能を提供します。 この投稿では、ML ワークフローを管理するためのオープンソース プラットフォームである MLflow を既に使用しているお客様に合わせたソリューションを提供します。
で 以前の投稿では、MLflow と、それを AWS で実行して SageMaker と統合する方法について説明しました。特に、トレーニング ジョブを実験として追跡し、MLflow に登録されたモデルを SageMaker マネージド インフラストラクチャにデプロイする場合について説明しました。 しかし オープンソース版 of MLflow は、追跡サーバー上の複数のテナントに対してネイティブのユーザー アクセス制御メカニズムを提供しません。 これは、サーバーにアクセスできるすべてのユーザーが管理者権限を持ち、実験、モデル バージョン、およびステージを変更できることを意味します。 これは、監査目的で強力なモデル ガバナンスを維持する必要がある、規制された業界の企業にとって課題となる可能性があります。
この投稿では、MLflow サーバーの外部にアクセス制御を実装し、認証および承認タスクをオフロードすることで、これらの制限に対処します。 アマゾンAPIゲートウェイを使用して、リソース レベルできめ細かいアクセス制御メカニズムを実装します。 アイデンティティおよびアクセス管理 (私は)。 そうすることで、SageMaker が管理するインフラストラクチャと Amazon SageMakerスタジオ、資格情報や資格情報管理の背後にあるすべての複雑さについて心配する必要はありません。 このアーキテクチャで提案されているモジュラー設計により、MLflow サーバー自体に影響を与えることなく、アクセス制御ロジックを簡単に変更できます。 最後に、SageMaker Studio の拡張性のおかげで、次のスクリーンショットに示すように、Studio 内で MLflow にアクセスできるようにすることで、データ サイエンティストのエクスペリエンスをさらに改善します。
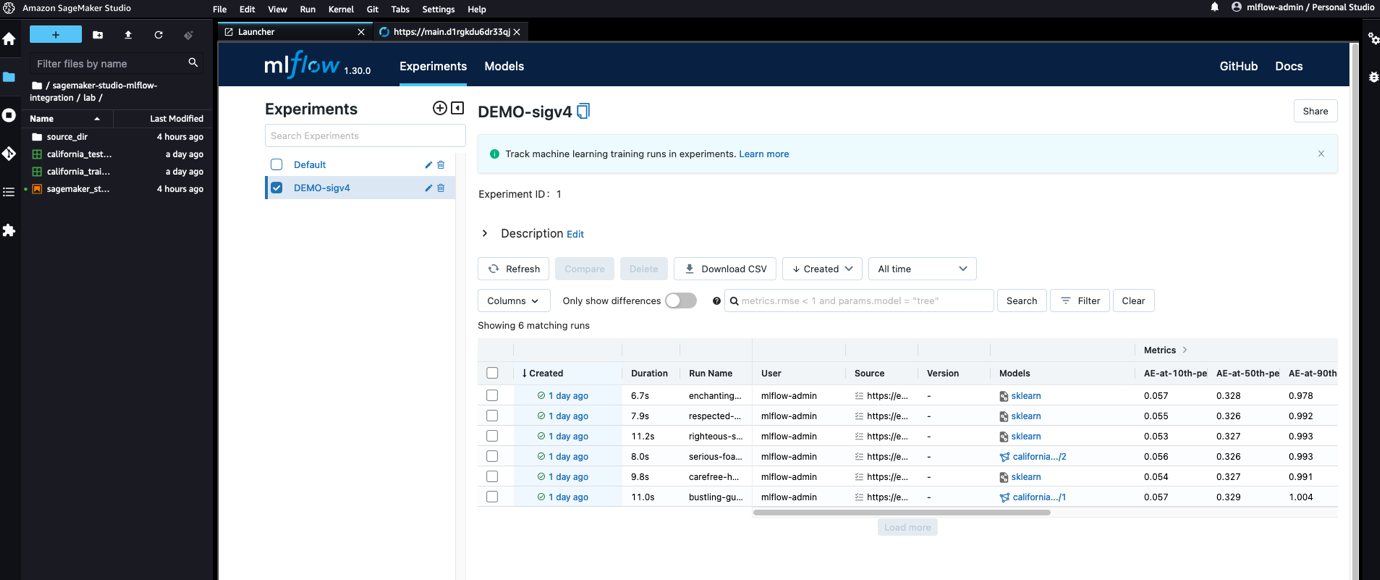
MLflow には、次を可能にする機能が統合されています。 AWS 認証情報を使用して署名をリクエストする Python SDK のアップストリーム リポジトリに追加し、SageMaker との統合を改善します。 MLflow Python SDK への変更は、MLflow バージョン 1.30.0 以降、すべてのユーザーが利用できます。
大まかに言うと、この記事は次のことを示しています。
- 外部から直接アクセスできないプライベート サブネットで実行されているサーバーレス アーキテクチャに MLflow サーバーをデプロイする方法。 このタスクでは、次の GitHub リポジトリの上に構築します。 MLflow と Amazon SageMaker で機械学習のライフサイクルを管理する.
- API ゲートウェイへのプライベート統合を介して MLflow サーバーを公開し、SDK を介したプログラムによるアクセスと MLflow UI を介したブラウザー アクセスのための安全なアクセス制御を実装する方法。
- 関連する SageMaker 実行ロールを使用して実験と実行をログに記録し、モデルを SageMaker から MLflow サーバーに登録してリクエストを認証および承認する方法と、 アマゾンコグニート MLflow UI に。 実験の追跡を示す例と、SageMaker トレーニング ジョブと Studio からの MLflow でモデル レジストリを使用する例を、提供されている ノート.
- マルチアカウント設定で MLflow を一元化されたリポジトリとして使用する方法。
- Studio 内で MLflow をレンダリングすることにより、Studio を拡張してユーザー エクスペリエンスを向上させる方法。 このタスクでは、JupyterLab 拡張機能をインストールして Studio の拡張性を活用する方法を示します。
それでは、詳細を詳しく見ていきましょう。
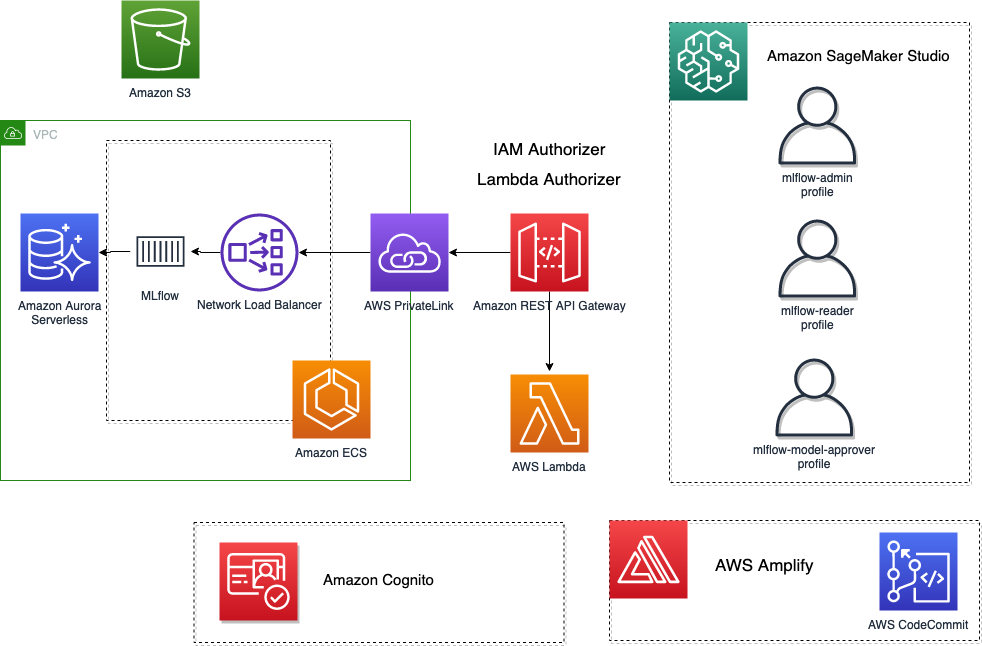
ソリューションの概要
MLflow は、並行して動作する XNUMX つの異なるコア コンポーネントと考えることができます。
- バックエンド MLflow 追跡サーバー用の REST API
- モデル トレーニング コードから MLflow 追跡サーバー API をプログラムで操作するための SDK
- 実験、実行、アーティファクトを視覚化するための MLflow UI の React フロント エンド
次の図に、私たちが想定して実装したアーキテクチャの概要を示します。
前提条件
ソリューションをデプロイする前に、管理者権限を持つ AWS アカウントにアクセスできることを確認してください。
ソリューション インフラストラクチャをデプロイする
この投稿で説明されているソリューションをデプロイするには、 GitHubリポジトリ README. インフラストラクチャの展開を自動化するために、 AWSクラウド開発キット (AWS CDK)。 AWS CDK は、作成するオープンソースのソフトウェア開発フレームワークです。 AWS CloudFormation スタック 自動で CloudFormationテンプレート 世代。 スタックは、プログラムで更新、移動、または削除できる AWS リソースのコレクションです。 AWS CDK 構成 は AWS CDK アプリケーションの構成要素であり、クラウド アーキテクチャを定義するための青写真を表しています。
XNUMX つのスタックを組み合わせます。
- MLFlowVPC スタック スタックは次のアクションを実行します。
- RestApiゲートウェイスタック スタックは次のアクションを実行します。
- AWS PrivateLink を介して MLflow サーバーを REST API ゲートウェイに公開します。
- UI にアクセスするユーザーを管理するために Amazon Cognito ユーザープールをデプロイします (デプロイ後も空のままです)。
- 展開します AWSラムダ オーソライザーは、Amazon Cognito ユーザープール ID キーを使用して JWT トークンを検証し、リクエストを許可または拒否する IAM ポリシーを返します。 この認可戦略が適用されるのは
<MLFlow-Tracking-Server-URI>/*. - IAM オーソライザーを追加します。 これは に適用されます
<MLFlow-Tracking-Server-URI>/api/*、前のものより優先されます。
- AmplifyMLFlowStack スタックは次のアクションを実行します。
- パッチが適用された MLflow リポジトリにリンクされたアプリを作成します AWS コードコミット MLflow UI をビルドしてデプロイします。
- SageMakerStudioユーザースタック スタックは次のアクションを実行します。
- Studio ドメインをデプロイします (まだ存在しない場合)。
- XNUMX 人のユーザーを追加します。それぞれのユーザーは、異なるアクセス レベルを実装する異なる SageMaker 実行ロールを持ちます。
- mlflow 管理者 – 任意の MLflow リソースに対する管理者のようなアクセス許可があります。
- mlflow リーダー – MLflow リソースに対する読み取り専用の管理者権限があります。
- mlflow-モデル-承認者 – mlflow-reader と同じアクセス許可を持ち、さらに MLflow の既存の実行から新しいモデルを登録し、既存の登録済みモデルを新しいステージに昇格させることができます。
サーバーレス アーキテクチャに MLflow 追跡サーバーをデプロイする
私たちの目標は、信頼性が高く、可用性が高く、費用対効果が高く、安全な MLflow 追跡サーバーの展開を実現することです。 サーバーレス テクノロジは、最小限の運用オーバーヘッドでこれらすべての要件を満たすための最適な候補です。 これを実現するために、MLflow 実験追跡サーバー用の Docker コンテナ イメージを構築し、プライベート サブネットで実行される専用 VPC の Amazon ECS の AWS Fargate で実行します。 MLflow は、バックエンド ストアとアーティファクト ストアの 3 つのストレージ コンポーネントに依存しています。 バックエンド ストアには Aurora Serverless を使用し、アーティファクト ストアには Amazon SXNUMX を使用します。 高レベルのアーキテクチャについては、次を参照してください。 シナリオ 4: リモート トラッキング サーバー、バックエンド、アーティファクト ストアを使用した MLflow. このタスクを実行する方法の詳細については、次の GitHub リポジトリを参照してください。 MLflow と Amazon SageMaker で機械学習のライフサイクルを管理する.
API Gateway を介した安全な MLflow
この時点では、まだアクセス制御メカニズムが整っていません。 最初のステップとして、AWS PrivateLink を使用して MLflow を外部に公開します。これにより、VPC と他の AWS サービス (この場合は API ゲートウェイ) の間にプライベート接続が確立されます。 その後、MLflow への受信要求は、 REST API ゲートウェイ、着信リクエストを承認するためのいくつかのメカニズムを実装する可能性を与えてくれます。 ここでは、次の XNUMX つだけに焦点を当てます。
- IAM オーソライザーの使用 –と IAM オーソライザー、リクエスターには、API Gateway リソースにアクセスするための適切な IAM ポリシーが割り当てられている必要があります。 すべてのリクエストは、HTTP 経由で送信されるリクエストに認証情報を追加する必要があります。 AWS 署名バージョン 4.
- Lambda オーソライザーの使用 – これにより、要求を承認する方法を完全に制御できるため、最大の柔軟性が提供されます。 最終的に、 ラムダ承認者 IAM ポリシーを返す必要があります。これは、リクエストを許可するか拒否するかについて API Gateway によって評価されます。
API Gateway でサポートされている認証および承認メカニズムの完全なリストについては、次を参照してください。 APIGatewayでのRESTAPIへのアクセスの制御と管理.
MLflow Python SDK 認証 (IAM オーソライザー)
MLflow 実験追跡サーバーは、 REST API リソースとアーティファクトをプログラムで操作します。 MLflow Python SDK は、メトリクス、実行、アーティファクトをログに記録する便利な方法を提供し、名前空間でホストされている API リソースとインターフェイスします <MLflow-Tracking-Server-URI>/api/. この名前空間でのリソース アクセス制御に IAM オーソライザーを使用するように API Gateway を構成するため、すべてのリクエストが AWS 署名バージョン 4 で署名される必要があります。
リクエストの署名プロセスを容易にするために、MLflow 1.30.0 以降では、この機能をシームレスに有効にすることができます。 であることを確認してください。 requests_auth_aws_sigv4 ライブラリがシステムにインストールされ、 MLFLOW_TRACKING_AWS_SIGV4 環境変数 True. 詳細については、 公式の MLflow ドキュメント.
この時点で、MLflow SDK には AWS 資格情報のみが必要です。 なぜなら request_auth_aws_sigv4 使用されます ボト3 資格情報を取得するために、それができることを知っています インスタンス メタデータから資格情報を読み込む IAM ロールが アマゾン エラスティック コンピューティング クラウド (Amazon EC2) インスタンス (Boto3 に資格情報を提供するその他の方法については、 Credentials
)。 これは、この投稿の後半で説明するように、関連付けられた実行ロールから SageMaker マネージド インスタンスから実行するときに、AWS 資格情報をロードすることもできることを意味します。
API Gateway 経由で MLflow API にアクセスするように IAM ポリシーを構成する
IAM ロールとポリシーを使用して、API Gateway でリソースを呼び出すことができるユーザーを制御できます。 詳細および IAM ポリシーのリファレンス ステートメントについては、次を参照してください。 APIを呼び出すためのアクセスを制御する.
次のコードは、MLflow をシールドする API Gateway 上のすべてのリソースのすべてのメソッドに対する呼び出し元のアクセス許可を付与し、実質的に MLflow サーバーへの管理者アクセスを許可する IAM ポリシーの例を示しています。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/*/*",
"Effect": "Allow"
}
]
}ユーザーにすべてのリソースへの読み取り専用アクセスを許可するポリシーが必要な場合、IAM ポリシーは次のコードのようになります。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "execute-api:Invoke",
"Resource": [
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/",
"arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search",
],
"Effect": "Allow"
}
]
}別の例として、特定のユーザーにモデルをモデル レジストリに登録し、後で特定の段階 (ステージング、運用など) に昇格させるアクセス許可を付与するポリシーが考えられます。
{ "Version": "2012-10-17", "Statement": [ { "Action": "execute-api:Invoke", "Resource": [ "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/GET/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/runs/search/", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/experiments/search", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/model-versions/*", "arn:aws:execute-api:<REGION>:<ACCOUNT_ID>:<MLFLOW_API_ID>/<STAGE>/POST/api/2.0/mlflow/registered-models/*" ], "Effect": "Allow" } ]
}MLflow UI 認証 (Lambda オーソライザー)
MLflow サーバーへのブラウザー アクセスは、React で実装された MLflow UI によって処理されます。 MLflow UI は、認証されたユーザーをサポートするように設計されていません。 堅牢なログイン フローを実装するのは困難な作業に思えるかもしれませんが、幸いなことに、 UI React コンポーネントを増幅する これにより、ID ストアに Amazon Cognito を使用して、React アプリケーションでログインフローを作成する労力が大幅に削減されます。
Amazon Cognito を使用すると、独自のユーザーベースを管理できるだけでなく、 サードパーティ ID フェデレーションをサポート、ADFS フェデレーションなどの構築を可能にします ( Amazon Cognito ユーザープールを使用してウェブアプリの ADFS フェデレーションを構築する 詳細については)。 Amazon Cognito によって発行されたトークンは、API Gateway で検証する必要があります。 トークンを検証するだけでは、きめ細かなアクセス制御には十分ではないため、Lambda オーソライザーを使用すると、必要なロジックを柔軟に実装できます。 次に、独自の Lambda オーソライザーを構築して JWT トークンを検証し、IAM ポリシーを生成して API Gateway がリクエストを拒否または許可できるようにします。 次の図は、MLflow ログイン フローを示しています。
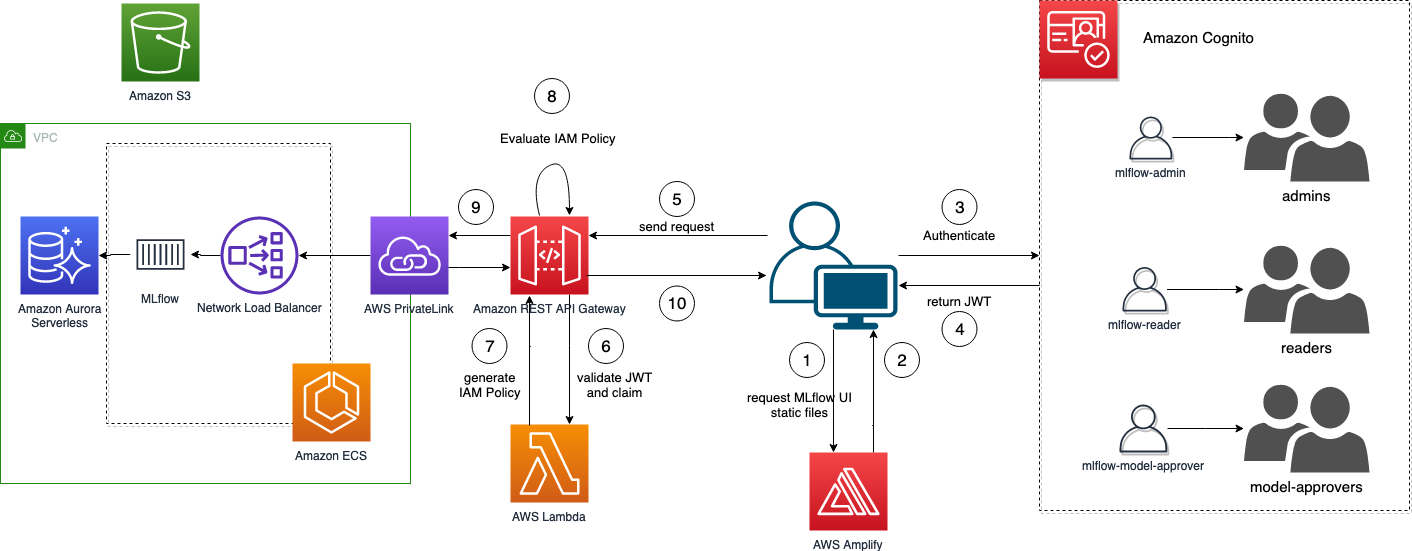
実際のコード変更の詳細については、パッチ ファイルを参照してください。 cognito.patch、MLflow バージョン 2.3.1 に適用されます。
このパッチでは、次の XNUMX つの機能が導入されています。
- Amplify UI コンポーネントを追加し、ログインフローを実装する環境変数を介して Amazon Cognito の詳細を設定します
- セッションから JWT を抽出し、JWT の送信先のベアラー トークンを含む Authorization ヘッダーを作成します。
アップストリームから分岐したコードを維持すると、常にアップストリームに依存するよりも複雑になりますが、Amplify React UI コンポーネントに依存しているため、変更が最小限であることに注意してください。
新しいログイン フローが整ったら、更新された MLflow UI の運用ビルドを作成しましょう。 AWSAmplifyホスティング は、CI/CD および Web アプリのホスティングに git ベースのワークフローを提供する AWS のサービスです。 パイプラインのビルド ステップは、 buildspec.yamlここでは、認証フローを設定するために Amplify UI React コンポーネントが必要とする Amazon Cognito ユーザー プール ID、Amazon Cognito ID プール ID、およびユーザー プール クライアント ID に関する詳細を環境変数として挿入できます。 次のコードは、 buildspec.yaml ファイル:
version: "1.0"
applications: - frontend: phases: preBuild: commands: - fallocate -l 4G /swapfile - chmod 600 /swapfile - mkswap /swapfile - swapon /swapfile - swapon -s - yarn install build: commands: - echo "REACT_APP_REGION=$REACT_APP_REGION" >> .env - echo "REACT_APP_COGNITO_USER_POOL_ID=$REACT_APP_COGNITO_USER_POOL_ID" >> .env - echo "REACT_APP_COGNITO_IDENTITY_POOL_ID=$REACT_APP_COGNITO_IDENTITY_POOL_ID" >> .env - echo "REACT_APP_COGNITO_USER_POOL_CLIENT_ID=$REACT_APP_COGNITO_USER_POOL_CLIENT_ID" >> .env - yarn run build artifacts: baseDirectory: build files: - "**/*"SageMaker 実行ロールを使用して、実験と実行を安全に記録します
ここで説明するソリューションの重要な側面の XNUMX つは、SageMaker との安全な統合です。 SageMaker はマネージド サービスであるため、ユーザーに代わって操作を実行します。 SageMaker ができることは、SageMaker トレーニングジョブに関連付けるか、Studio から作業するユーザープロファイルに関連付ける実行ロールに添付された IAM ポリシーによって定義されます。 SageMaker 実行ロールの詳細については、次を参照してください。 SageMakerの役割.
で IAM 認証を使用するように API Gateway を設定することにより、 <MLFlow-Tracking-Server-URI>/api/* リソース、SageMaker 実行ロールに一連の IAM ポリシーを定義して、指定されたアクセスレベルに従って SageMaker が MLflow とやり取りできるようにすることができます。
を設定するとき MLFLOW_TRACKING_AWS_SIGV4 環境変数 True Studio または SageMaker トレーニング ジョブで作業している間、MLflow Python SDK はすべてのリクエストに自動的に署名し、API ゲートウェイによって検証されます。
os.environ['MLFLOW_TRACKING_AWS_SIGV4'] = "True"
mlflow.set_tracking_uri(tracking_uri)
mlflow.set_experiment(experiment_name)MLflow SDK を使用して SageMaker 実行ロールをテストする
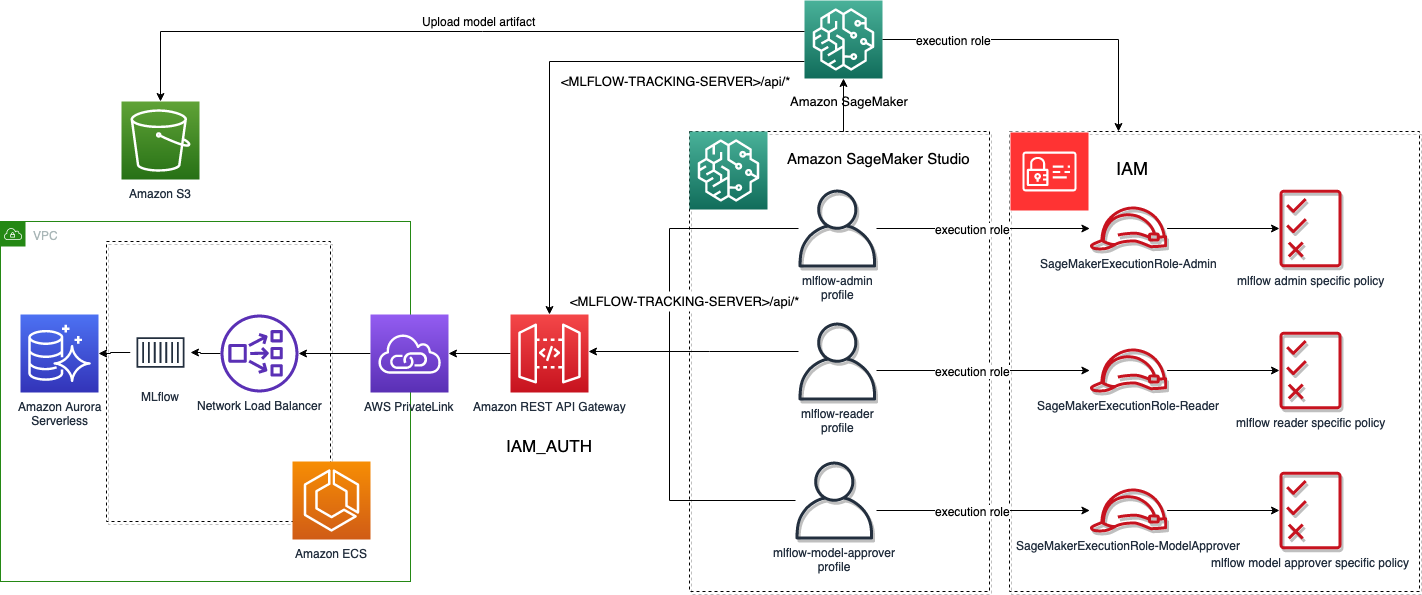
生成された Studio ドメインにアクセスすると、次の XNUMX 人のユーザーが見つかります。
- mlflow 管理者 – Amazon Cognito グループ管理者のユーザーと同様のアクセス許可を持つ実行ロールに関連付けられている
- mlflow リーダー – Amazon Cognito グループリーダーのユーザーと同様のアクセス許可を持つ実行ロールに関連付けられている
- mlflow-モデル-承認者 – Amazon Cognito グループ model-approvers のユーザーと同様のアクセス許可を持つ実行ロールに関連付けられている
XNUMX つの異なるロールをテストするには、次を参照してください。 ラボ 各ユーザー プロファイルのこのサンプルの一部として提供されます。
次の図は、MLflow を使用した Studio ユーザープロファイルと SageMaker ジョブ認証のワークフローを示しています。
同様に、SageMaker マネージドインフラストラクチャで SageMaker ジョブを実行する場合、環境変数を設定すると MLFLOW_TRACKING_AWS_SIGV4 〜へ Trueであり、ジョブに渡された SageMaker 実行ロールには、API Gateway にアクセスするための正しい IAM ポリシーが含まれているため、資格情報を自分で管理する必要なく、MLflow 追跡サーバーと安全にやり取りできます。 次のコードに示すように、SageMaker トレーニング ジョブを実行し、エスティメータ クラスを初期化するときに、SageMaker が注入してトレーニング スクリプトで使用できるようにする環境変数を渡すことができます。
environment={ "AWS_DEFAULT_REGION": region, "MLFLOW_EXPERIMENT_NAME": experiment_name, "MLFLOW_TRACKING_URI": tracking_uri, "MLFLOW_AMPLIFY_UI_URI": mlflow_amplify_ui, "MLFLOW_TRACKING_AWS_SIGV4": "true", "MLFLOW_USER": user
} estimator = SKLearn( entry_point='train.py', source_dir='source_dir', role=role, metric_definitions=metric_definitions, hyperparameters=hyperparameters, instance_count=1, instance_type='ml.m5.large', framework_version='1.0-1', base_job_name='mlflow', environment=environment
)MLflow UI から実行と実験を視覚化する
最初のデプロイが完了したら、実装したアクセス許可をテストするために、それぞれが異なるグループに属する XNUMX 人のユーザーを Amazon Cognito ユーザー プールに入力してみましょう。 このスクリプトを使用できます add_users_and_groups.py ユーザープールをシードします。 スクリプトを実行した後、Amazon Cognito コンソールで Amazon Cognito ユーザー プールを確認すると、作成された XNUMX 人のユーザーが表示されます。
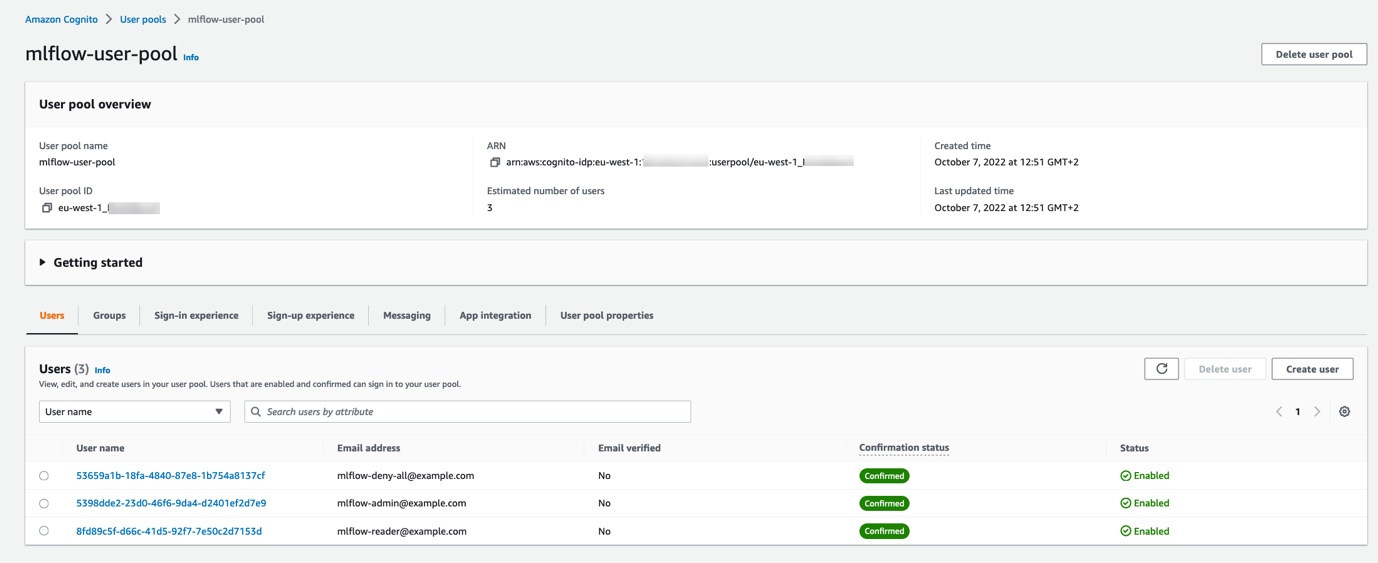
REST API Gateway 側では、Lambda オーソライザーは最初に Amazon Cognito ユーザープールキーを使用してトークンの署名を検証し、クレームを検証します。 その後、ユーザーが属する Amazon Cognito グループを JWT トークンのクレームから抽出します (cognito:groups)、プログラムしたグループに基づいて異なる権限を適用します。
この特定のケースでは、次の XNUMX つのグループがあります。
- 管理者 – すべてを表示および編集できます
- 読者 – すべてしか見えない
- モデル承認者 – リーダーと同様に、モデルの登録、バージョンの作成、モデル バージョンの次のステージへの昇格が可能
グループに応じて、Lambda オーソライザーは異なる IAM ポリシーを生成します。 これは、承認を得る方法のほんの一例です。 Lambda オーソライザーを使用すると、必要なロジックを実装できます。 Lambda 関数自体で実行時に IAM ポリシーを構築することを選択しました。 ただし、適切な IAM ポリシーを事前に生成して、 Amazon DynamoDB、独自のビジネス ロジックに従って実行時にそれらを取得します。 ただし、アクションのサブセットのみを制限する場合は、 MLflow REST API 定義.
Lambda オーソライザーのコードは、 GitHubレポ.
マルチアカウントに関する考慮事項
データ サイエンス ワークフローは、実験から本番環境に進む際に、複数の段階を通過する必要があります。 一般的なアプローチには、AI/ML ワークフローのさまざまなフェーズ (実験、開発、本番) 専用の個別のアカウントが含まれます。 ただし、モデルの中央リポジトリとして機能する専用のアカウントを持つことが望ましい場合もあります。 私たちのアーキテクチャとサンプルは単一のアカウントを参照していますが、この最後のシナリオを実装するために簡単に拡張できます。 ロールを切り替える IAM 機能 アカウント間でも。
次の図は、MLflow を分離された AWS アカウントの中央リポジトリとして使用するアーキテクチャを示しています。
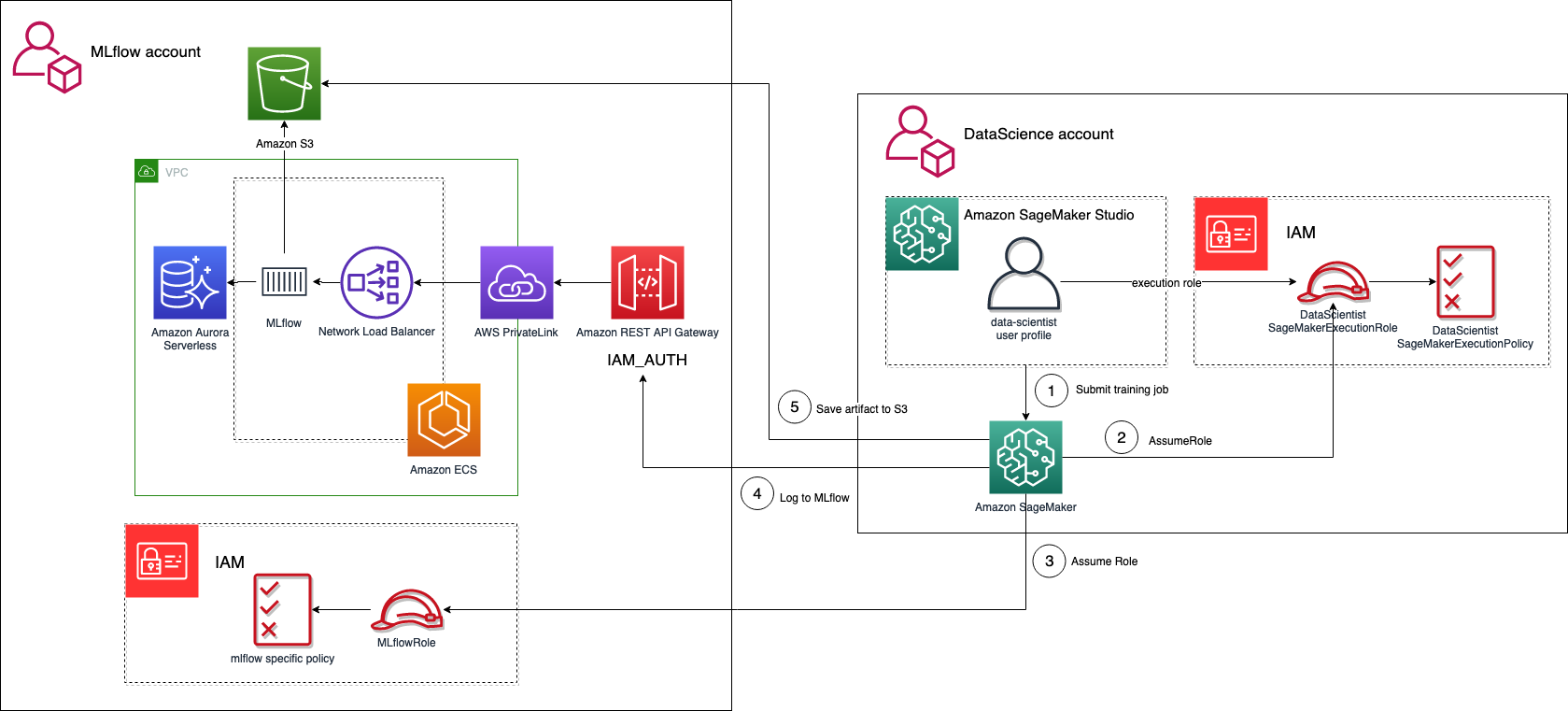
このユース ケースでは、XNUMX つのアカウントがあります。XNUMX つは MLflow サーバー用で、もう XNUMX つはデータ サイエンス チームがアクセスできる実験用です。 データ サイエンス アカウントで実行されている SageMaker トレーニング ジョブからのクロスアカウント アクセスを有効にするには、次の要素が必要です。
- MLflow アカウントで別のロールを引き受けることを許可する IAM ポリシーがアタッチされた、データ サイエンス AWS アカウントでの SageMaker 実行ロール:
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "<ARN-ROLE-IN-MLFLOW-ACCOUNT>" }
}- MLflow 追跡サーバーへのアクセスを許可し、データ サイエンス アカウントの SageMaker 実行ロールがそれを引き受けることを許可する、適切な IAM ポリシーがアタッチされた MLflow アカウントの IAM ロール:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "<ARN-SAGEMAKER-EXECUTION-ROLE-IN-DATASCIENCE-ACCOUNT>" }, "Action": "sts:AssumeRole" } ]
}データ サイエンス アカウントで実行されているトレーニング スクリプト内で、MLflow クライアントを初期化する前に、この例を使用できます。 この新しい資格情報のセットは、MLflow クライアント内で初期化された新しい Boto3 セッションによって取得されるため、MLflow アカウントで役割を引き受け、一時的な資格情報を環境変数として保存する必要があります。
import boto3 # Session using the SageMaker Execution Role in the Data Science Account
session = boto3.Session()
sts = session.client("sts") response = sts.assume_role( RoleArn="<ARN-ROLE-IN-MLFLOW-ACCOUNT>", RoleSessionName="AssumedMLflowAdmin"
) credentials = response['Credentials']
os.environ['AWS_ACCESS_KEY_ID'] = credentials['AccessKeyId']
os.environ['AWS_SECRET_ACCESS_KEY'] = credentials['SecretAccessKey']
os.environ['AWS_SESSION_TOKEN'] = credentials['SessionToken'] # set remote mlflow server and initialize a new boto3 session in the context
# of the assumed role
mlflow.set_tracking_uri(tracking_uri)
experiment = mlflow.set_experiment(experiment_name)この例では、 RoleArn は、引き受けるロールの ARN であり、 RoleSessionName 想定セッション用に選択する名前です。 の sts.assume_role メソッドは、MLflow クライアントが想定されたロールの新しいクライアントを作成するために使用する一時的なセキュリティ資格情報を返します。 次に、MLflow クライアントは、引き受けたロールのコンテキストで、署名された要求を API Gateway に送信します。
SageMaker Studio 内で MLflow をレンダリングする
SageMaker Studio は JupyterLab に基づいており、JupyterLab と同様に、拡張機能をインストールして生産性を高めることができます。 この柔軟性のおかげで、MLflow と SageMaker を使用するデータ サイエンティストは、Studio 環境から MLflow UI にアクセスし、ログに記録された実験と実行をすぐに視覚化することで、統合をさらに改善できます。 次のスクリーンショットは、Studio でレンダリングされた MLflow の例を示しています。
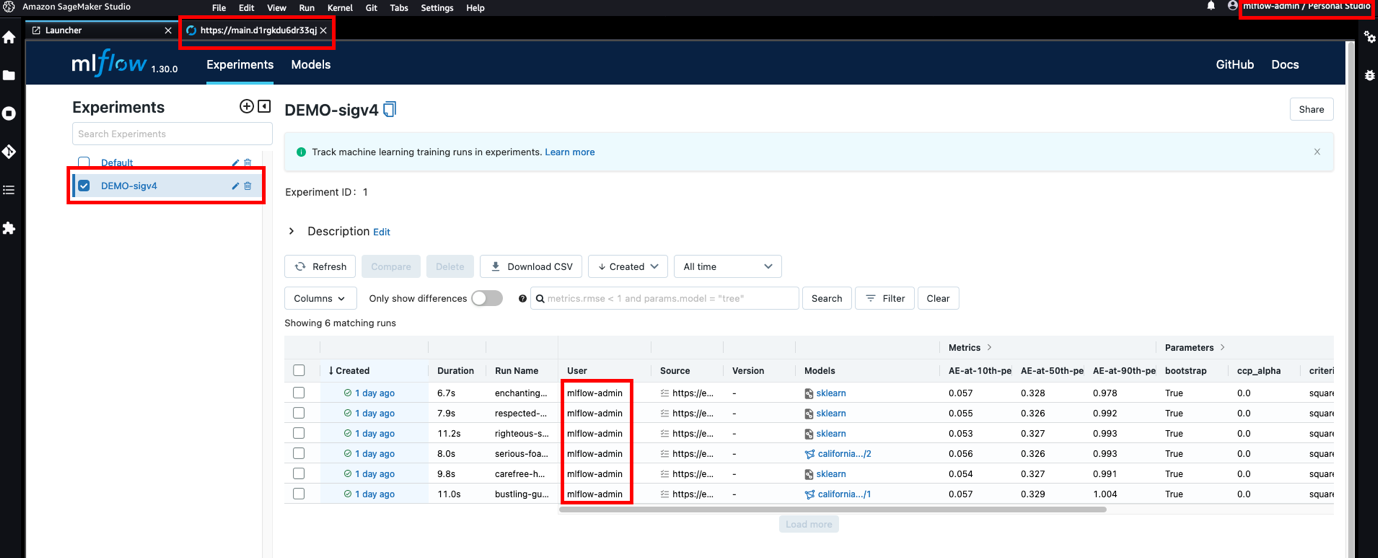
Studio に JupyterLab 拡張機能をインストールする方法については、次を参照してください。 Amazon SageMakerStudioおよびSageMakerNotebookインスタンスには、開発者の生産性を高めるためにJupyterLab3ノートブックが付属しています。. ライフサイクル構成による自動化の追加の詳細については、次を参照してください。 ライフサイクル設定を使用してAmazonSageMakerStudioをカスタマイズする.
この投稿をサポートするサンプル リポジトリでは、 説明書 のインストール方法について jupyterlab-iframe 拡大。 拡張機能をインストールすると、Amazon Cognito ユーザープールに保存したのと同じ認証情報セットを使用して、Studio を離れずに MLflow UI にアクセスできます。
次のステップ
この作業を拡張するには、いくつかのオプションがあります。 XNUMX つのアイデアは、SageMaker Studio と MLflow UI の両方の ID ストアを統合することです。 もう XNUMX つのオプションは、Amazon Cognito でサードパーティの ID フェデレーション サービスを利用してから、 AWS IAM アイデンティティ センター (AWS Single Sign-On の後継) 同じサードパーティ ID を使用して Studio へのアクセスを許可します。 もうXNUMXつは、完全自動化を導入することです AmazonSageMakerパイプライン モデル構築の CI/CD 部分には、MLflow を集中型の実験追跡サーバーとして使用し、強力なガバナンス機能を備えたモデル レジストリを使用し、承認されたモデルを SageMaker ホスティング エンドポイントに自動的にデプロイする自動化を行います。
まとめ
この投稿の目的は、MLflow にエンタープライズ レベルのアクセス制御を提供することでした。 これを実現するために、認証と承認のプロセスを MLflow サーバーから分離し、API Gateway に転送しました。 MLflow Python SDK と MLflow UI の両方の要件を満たすために、API Gateway が提供する XNUMX つの認証方法、IAM オーソライザーと Lambda オーソライザーを利用しました。 ユーザーは MLflow の外部にいることを理解することが重要であるため、一貫したガバナンスには、特に非常に細かいアクセス許可の場合に、IAM ポリシーを維持する必要があります。 最後に、単純な拡張機能を使用して MLflow を Studio に統合することで、データ サイエンティストのエクスペリエンスを向上させる方法を示しました。
にアクセスして、自分でソリューションを試してみてください。 GitHubレポ コメント欄にご不明な点がございましたらお知らせください。
その他のリソース
SageMaker と MLflow の詳細については、以下を参照してください。
著者について
 パオロディフランチェスコ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトです。 彼は電気通信工学の博士号を取得しており、ソフトウェア エンジニアリングの経験があります。 彼は機械学習に情熱を傾けており、現在、特に MLOps に関する議論において、AWS で顧客が目標を達成できるように彼の経験を活用することに力を注いでいます。 仕事以外では、サッカーと読書を楽しんでいます。
パオロディフランチェスコ アマゾン ウェブ サービス (AWS) のシニア ソリューション アーキテクトです。 彼は電気通信工学の博士号を取得しており、ソフトウェア エンジニアリングの経験があります。 彼は機械学習に情熱を傾けており、現在、特に MLOps に関する議論において、AWS で顧客が目標を達成できるように彼の経験を活用することに力を注いでいます。 仕事以外では、サッカーと読書を楽しんでいます。
 クリス・フレグリー カリフォルニア州サンフランシスコに拠点を置くアマゾン ウェブ サービス (AWS) で AI と機械学習のプリンシパル スペシャリスト ソリューション アーキテクトを務めています。 彼は、O'Reilly の本「Data Science on AWS」の共著者です。 Chris は、Apache Spark、TensorFlow、Ray、KubeFlow に焦点を当てた多くのグローバル ミートアップの創設者でもあります。 彼は、O'Reilly AI、Open Data Science Conference、Big Data Spain など、世界中の AI および機械学習カンファレンスで定期的に講演しています。
クリス・フレグリー カリフォルニア州サンフランシスコに拠点を置くアマゾン ウェブ サービス (AWS) で AI と機械学習のプリンシパル スペシャリスト ソリューション アーキテクトを務めています。 彼は、O'Reilly の本「Data Science on AWS」の共著者です。 Chris は、Apache Spark、TensorFlow、Ray、KubeFlow に焦点を当てた多くのグローバル ミートアップの創設者でもあります。 彼は、O'Reilly AI、Open Data Science Conference、Big Data Spain など、世界中の AI および機械学習カンファレンスで定期的に講演しています。
 イルシャド・ブーフ アマゾン ウェブ サービス (AWS) のプリンシパル ソリューション アーキテクトです。 Irshad は、大規模な AWS グローバル ISV および SI パートナーと協力して、クラウド戦略の構築と Amazon のクラウド コンピューティング プラットフォームの幅広い採用を支援しています。 Irshad は、CIO、CTO、およびそのアーキテクトとやり取りし、彼らとそのエンド カスタマーがクラウド ビジョンを実装するのを支援します。 Irshad は、特定の実装プロジェクトに関する戦略的および技術的な関与と最終的な成功を所有しており、アマゾン ウェブ サービス テクノロジーに関する深い専門知識と、アマゾン ウェブ サービス プラットフォームを使用してアプリケーションとサービスを構築する方法に関する幅広いノウハウを開発しています。
イルシャド・ブーフ アマゾン ウェブ サービス (AWS) のプリンシパル ソリューション アーキテクトです。 Irshad は、大規模な AWS グローバル ISV および SI パートナーと協力して、クラウド戦略の構築と Amazon のクラウド コンピューティング プラットフォームの幅広い採用を支援しています。 Irshad は、CIO、CTO、およびそのアーキテクトとやり取りし、彼らとそのエンド カスタマーがクラウド ビジョンを実装するのを支援します。 Irshad は、特定の実装プロジェクトに関する戦略的および技術的な関与と最終的な成功を所有しており、アマゾン ウェブ サービス テクノロジーに関する深い専門知識と、アマゾン ウェブ サービス プラットフォームを使用してアプリケーションとサービスを構築する方法に関する幅広いノウハウを開発しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/securing-mlflow-in-aws-fine-grained-access-control-with-aws-native-services/

