AmazonSageMakerデータラングラー Amazon SageMaker Studio で、機械学習 (ML) 用のデータの集約と準備にかかる時間を数週間から数分に短縮します。 Data Wrangler を使用すると、さまざまな一般的なソースからデータにアクセスできます (アマゾンS3, アマゾンアテナ, Amazonレッドシフト, アマゾンEMR および Snowflake) および 40 を超えるその他のサードパーティ ソース。 今日から接続できるようになりました アマゾンEMR ビッグデータ クエリ エンジンとして Hive を使用して、ML 用の大規模なデータセットを取り込みます。
大量のデータを集約して準備することは、ML ワークフローの重要な部分です。 データ サイエンティストとデータ エンジニアは、Amazon EMR で実行されている Apache Spark、Apache Hive、および Presto を使用して、大規模なデータ処理を行っています。 このブログ投稿では、データの専門家が SageMaker Data Wrangler のビジュアル インターフェイスを使用して、Hive エンドポイントを持つ既存の Amazon EMR クラスターを見つけて接続する方法について説明します。 モデリングやレポート作成の準備として、データベース、テーブル、スキーマを視覚的に分析し、Hive クエリを作成して ML データセットを作成できます。 次に、Data Wrangler ビジュアル インターフェイスを使用してデータをすばやくプロファイリングして、データ品質を評価し、異常やデータの欠落または誤りを特定し、これらの問題に対処する方法についてアドバイスを得ることができます。 より一般的な ML を利用した組み込み分析と、Spark でサポートされている 300 以上の組み込み変換を利用して、コードを XNUMX 行も書かずに機能を分析、クリーンアップ、およびエンジニアリングできます。 最後に、モデルをトレーニングしてデプロイすることもできます SageMakerオートパイロットData Wrangler のビジュアル インターフェイスから、SageMaker パイプラインでジョブをスケジュールしたり、データ準備を操作したりできます。
ソリューションの概要
SageMaker Studio セットアップを使用すると、データ プロフェッショナルは既存の EMR クラスターをすばやく特定して接続できます。 さらに、データの専門家は EMR クラスターを以下から検出できます。 事前定義されたテンプレートを使用する SageMaker Studio 数回クリックするだけでオンデマンド。 お客様は SageMaker Studio ユニバーサル ノートブックを使用してコードを記述できます Apache Spark, ハイブ, プレストで or パイスパーク 大規模なデータ準備を実行します。 ただし、学習曲線が急峻であるため、すべてのデータ プロフェッショナルがデータを準備するための Spark コードの記述に精通しているわけではありません。 Amazon SageMaker Data Wrangler のデータソースである Amazon EMR のおかげで、コードを XNUMX 行も書かずに、迅速かつ簡単に Amazon EMR に接続できるようになりました。
次の図は、このソリューションで使用されるさまざまなコンポーネントを表しています。

EMR クラスターへの接続を確立するために使用できる XNUMX つの認証オプションを示します。 オプションごとに、独自のスタックを展開します AWS CloudFormation テンプレート。
各オプションが選択されると、CloudFormation テンプレートは次のアクションを実行します。
- という名前のユーザー プロファイルとともに、VPC のみのモードでスタジオ ドメインを作成します。
studio-user. - サンプルを正常に実行するために、VPC、エンドポイント、サブネット、セキュリティ グループ、EMR クラスター、およびその他の必要なリソースを含むビルディング ブロックを作成します。
- EMR クラスターの場合、AWS Glue Data Catalog を EMR Hive および Presto のメタストアとして接続し、EMR に Hive テーブルを作成し、そこに 米国の空港データセット.
- LDAP CloudFormation テンプレートの場合、 アマゾン エラスティック コンピューティング クラウド Hive および Presto LDAP ユーザーを認証する LDAP サーバーをホストする (Amazon EC2) インスタンス。
オプション 1: ライトウェイト アクセス ディレクトリ プロトコル
LDAP 認証 CloudFormation テンプレートの場合、Amazon EC2 インスタンスに LDAP サーバーをプロビジョニングし、このサーバーを認証に使用するように EMR クラスターを構成します。 これは TLS 対応です。
オプション 2: 認証なし
No-Auth 認証 CloudFormation テンプレートでは、認証が有効になっていない標準の EMR クラスターを使用します。
AWS CloudFormation を使用してリソースをデプロイする
次の手順を実行して、環境をデプロイします。
- にサインインする AWSマネジメントコンソール として AWS IDおよびアクセス管理 (IAM)ユーザー、できれば管理者ユーザー。
- 選択する 発射スタック 適切な認証シナリオの CloudFormation テンプレートを起動します。 CloudFormation スタックのデプロイに使用されるリージョンに既存の Studio ドメインがないことを確認してください。 リージョンに Studio ドメインが既にある場合は、別のリージョンを選択できます。
LDAP 
認証なし - 選択する Next.
- スタック名、スタックの名前を入力します(たとえば、
dw-emr-hive-blog). - 他の値はデフォルトのままにします。
- 続行するには、 Next スタックの詳細ページとスタック オプションから。
LDAP スタックは、次の資格情報を使用します。- ユーザ名:
david - パスワード:
welcome123
- ユーザ名:
- レビューページで、チェックボックスを選択して、AWSCloudFormationがリソースを作成する可能性があることを確認します。
- 選択する スタックを作成. スタックのステータスが
CREATE_IN_PROGRESS〜へCREATE_COMPLETE。 このプロセスには通常10〜15分かかります。
Data Wrangler で Amazon EMR をデータ ソースとして設定する
このセクションでは、Data Wrangler のデータ ソースとして CloudFormation テンプレートを介して作成された既存の Amazon EMR クラスターへの接続について説明します。
新しいデータ フローを作成する
データ フローを作成するには、次の手順を実行します。
- SageMaker コンソールで、 ドメイン、次にクリックしてください スタジオドメイン 上記の CloudFormation テンプレートを実行して作成されます。
- 選択 スタジオユーザー ユーザー プロファイルを作成し、Studio を起動します。
- 選択する オープンスタジオ.
- Studio Home コンソールで、 データを視覚的にインポートして準備する. または、 File ドロップダウン、選択 新作、を選択します データラングラーの流れ.
- 新しいフローの作成には数分かかる場合があります。 フローが作成されると、 インポート日 ページで見やすくするために変数を解析したりすることができます。

- Data Wrangler でデータ ソースとして Amazon EMR を追加します。 上で データソースを追加する メニュー、選択 アマゾンEMR.
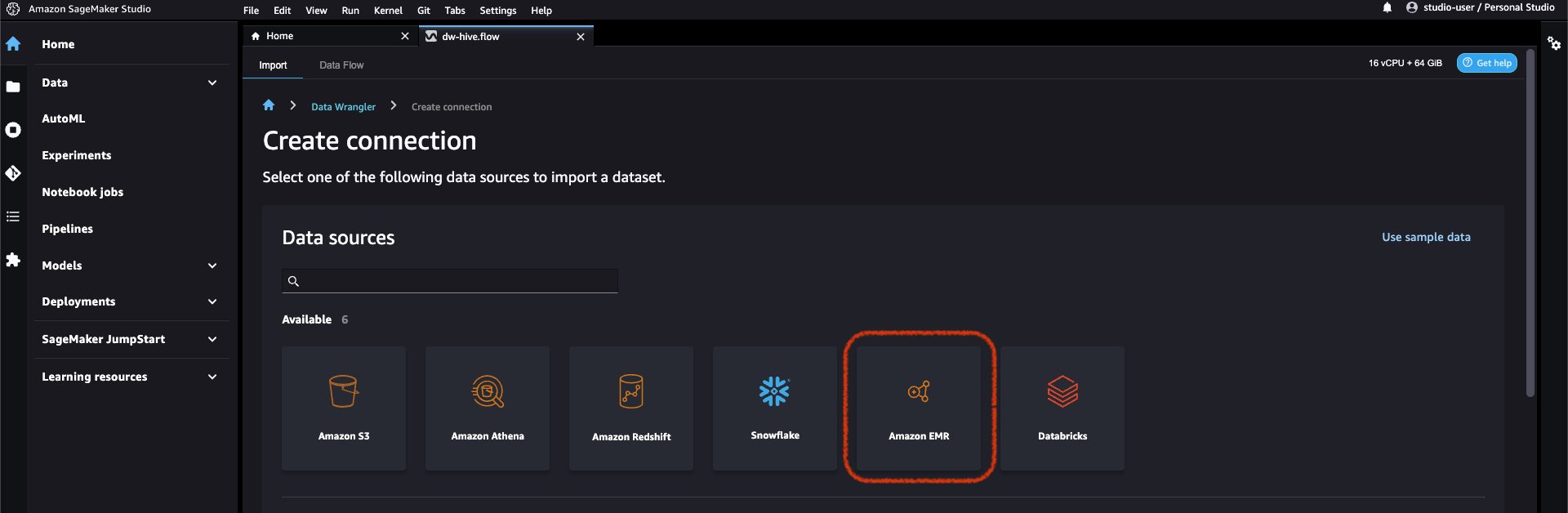
Studio 実行ロールに表示権限があるすべての EMR クラスターを参照できます。 クラスターに接続するには XNUMX つのオプションがあります。 XNUMX つはインタラクティブな UI を使用する方法で、もう XNUMX つは最初に使用する方法です。 AWS Secrets Manager を使用してシークレットを作成する EMR クラスター情報を含む JDBC URL を使用して、保存されている AWS シークレット ARN を UI に提供して、Hive に接続します。 このブログでは、最初のオプションに従います。
- 使用する次のクラスターのいずれかを選択します。 ソフトウェアの制限をクリック Nextをクリックし、エンドポイントを選択します。

- 選択 ハイブ、 Amazon EMR に接続し、接続を識別する名前を作成して、 Next.
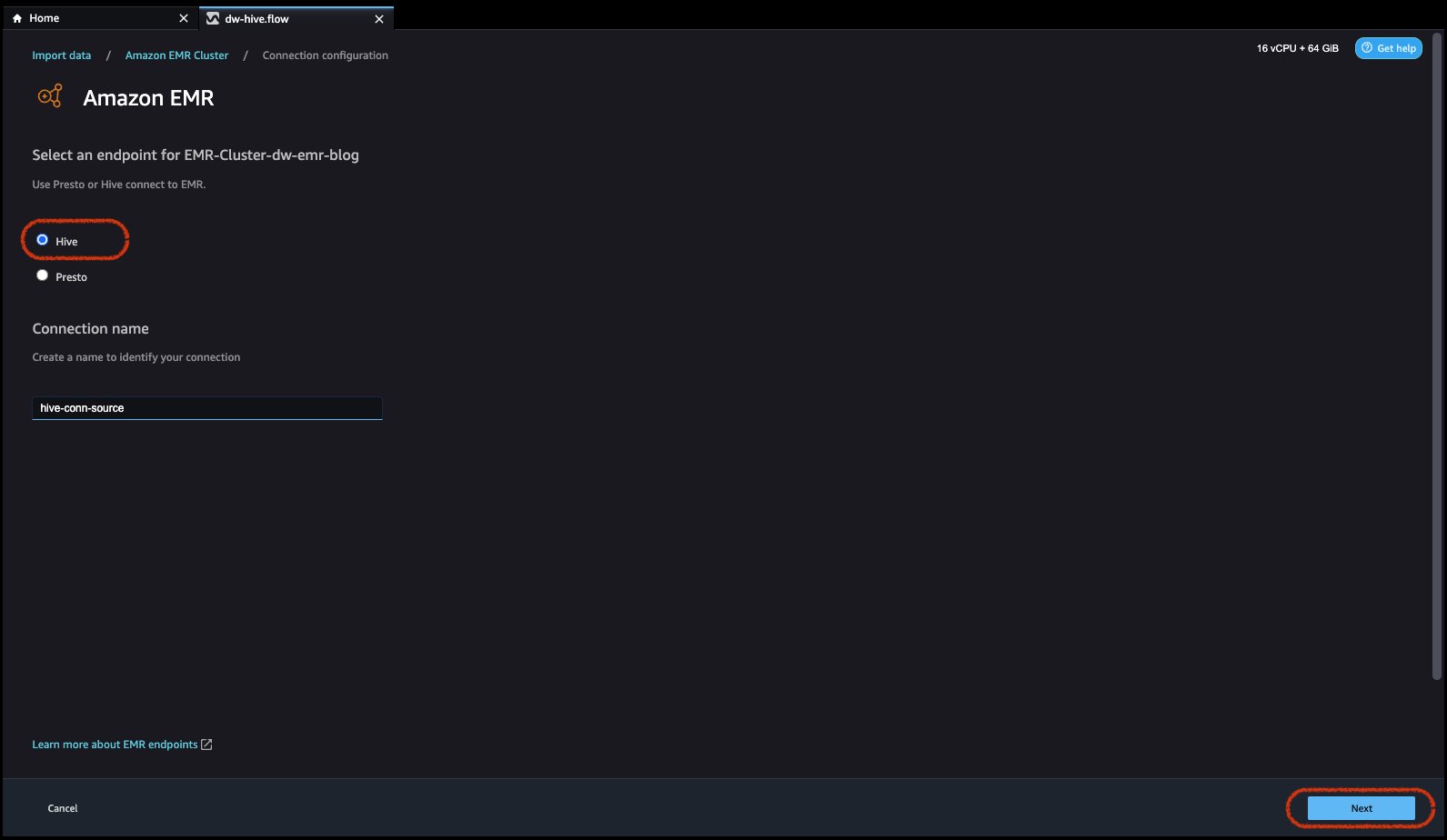
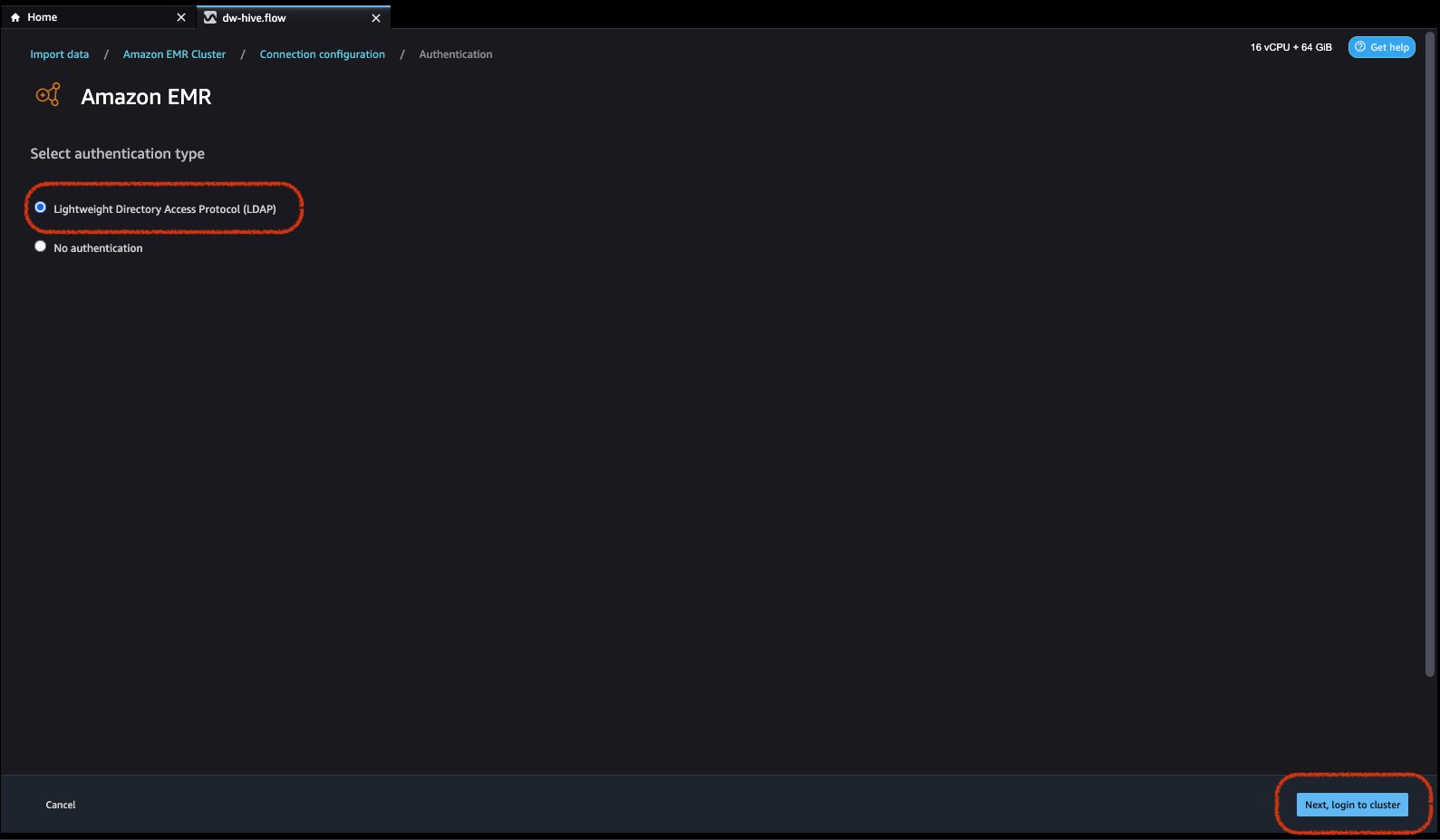
- 認証タイプを選択します。 ライトウェイトディレクトリアクセスプロトコル(LDAP) or 認証なし.
Lightweight Directory Access Protocol (LDAP) の場合は、オプションを選択して をクリックします。 次に、clusteにログインします次に、認証するユーザー名とパスワードを入力し、[接続] をクリックします。
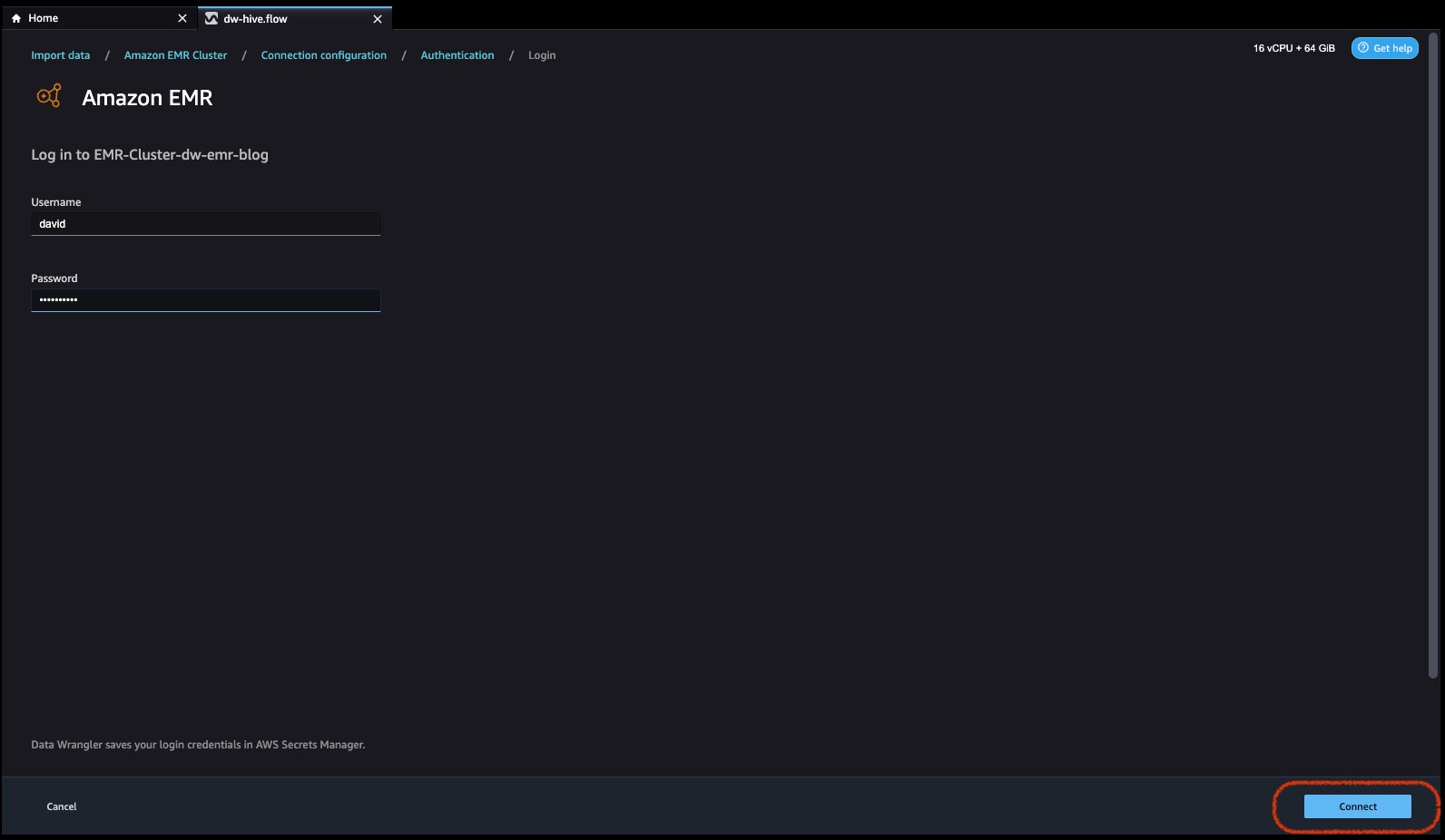
認証なしの場合、VPC 内でユーザー認証情報を提供せずに EMR Hive に接続されます。 EMR の Data Wrangler の SQL エクスプローラー ページに入ります。

- 接続すると、データベース ツリーとテーブルのプレビューまたはスキーマを対話的に表示できます。 また、EMR からデータをクエリ、探索、視覚化することもできます。 プレビューでは、デフォルトで 100 レコードの制限が表示されます。 クエリ エディター ボックスに SQL ステートメントを入力し、 ラン ボタンをクリックすると、EMR の Hive エンジンでクエリが実行され、データがプレビューされます。
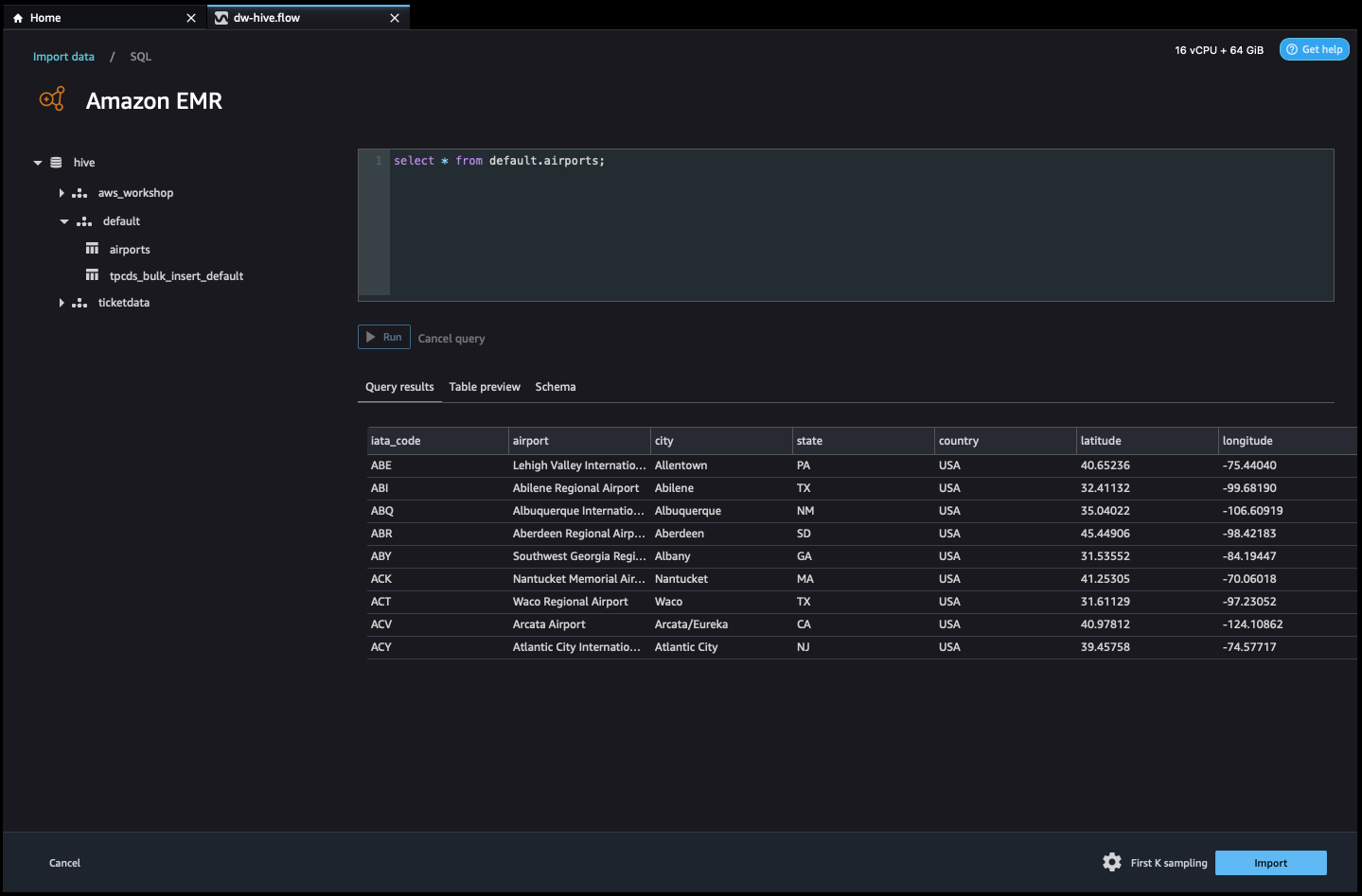
クエリをキャンセル ボタンを使用すると、進行中のクエリに異常に長い時間がかかる場合にキャンセルできます。
- 最後のステップはインポートです。 照会されたデータの準備ができたら、Data Wrangler にデータをインポートするためのサンプリング タイプ (FirstK、Random、または Stratified) とサンプリング サイズに従って、データ選択のサンプリング設定を更新するオプションがあります。
クリック インポート. 準備ページが読み込まれ、さまざまな変換と重要な分析をデータセットに追加できるようになります。
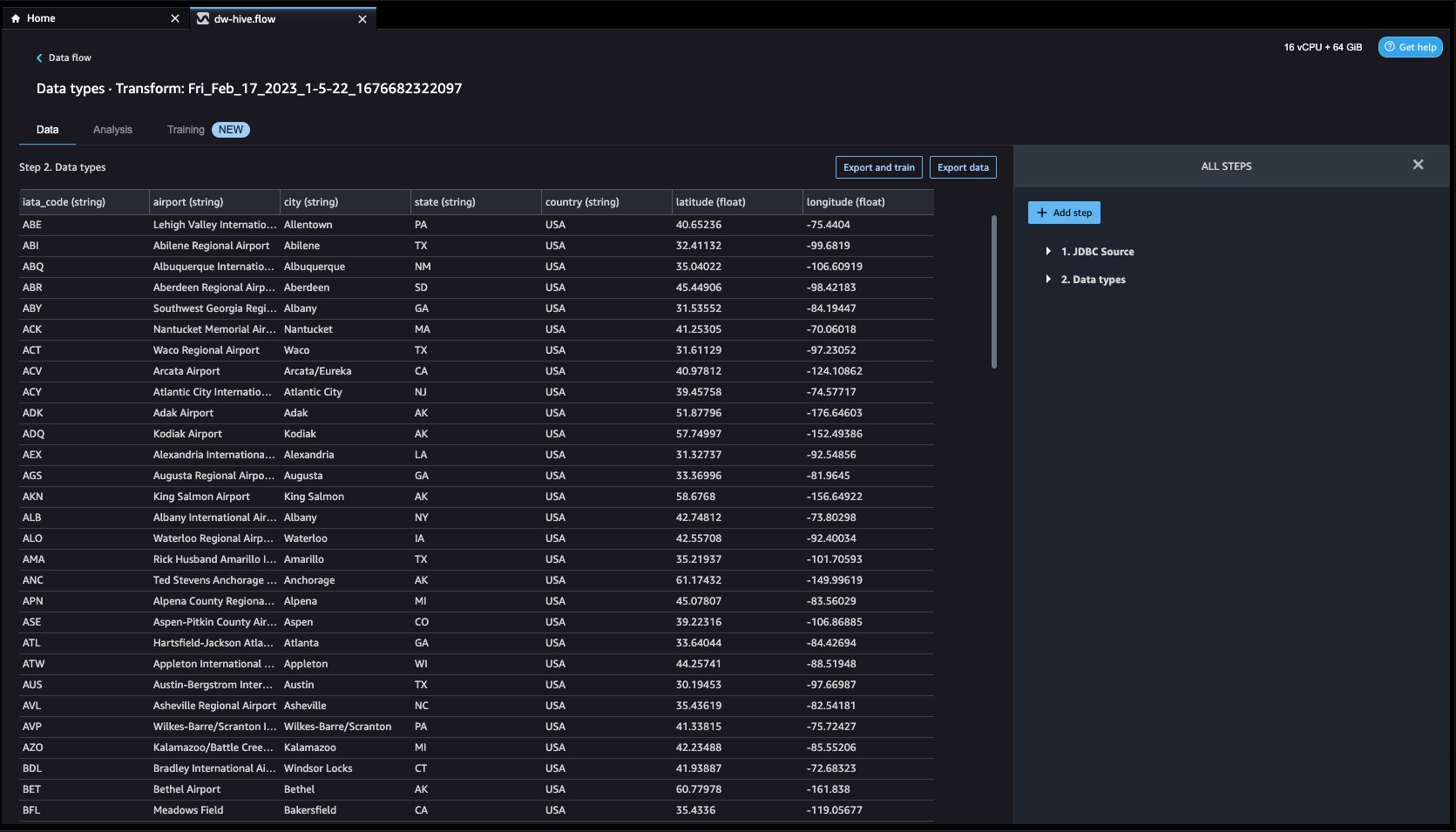
- MFAデバイスに移動する データフロー トップ画面から、変換と分析のために必要に応じてフローにステップを追加します。 実行できます データ インサイト レポート データ品質の問題を特定し、それらの問題を修正するための推奨事項を取得します。 変換の例をいくつか見てみましょう。
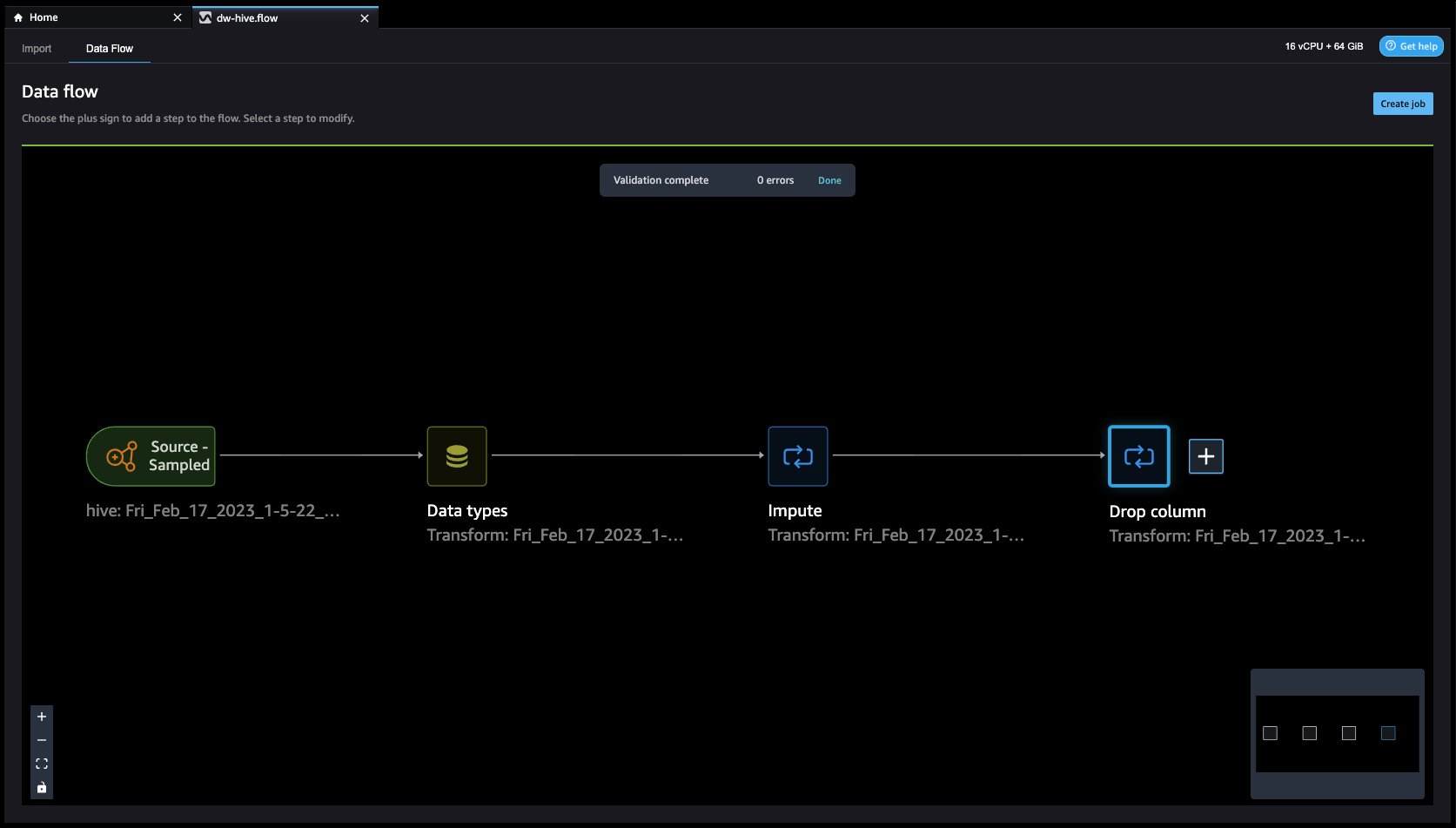
- データフロー Hive コネクタを使用して EMR をデータ ソースとして使用していることがわかります。
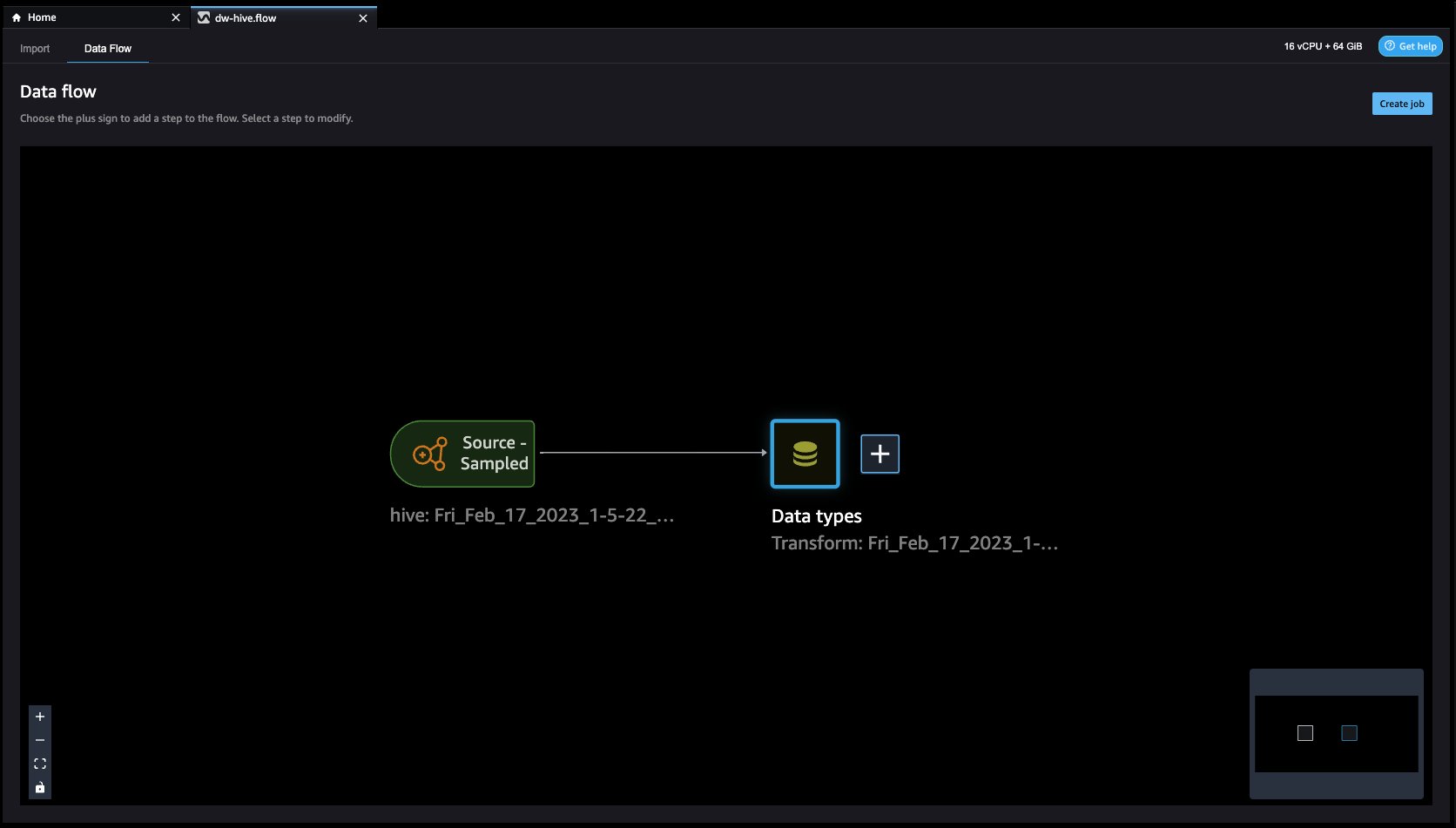
- クリックしてみましょう + 右のボタン データ型 をクリックして 変換を追加. これを行うと、元に戻ります。 且つ ビュー。
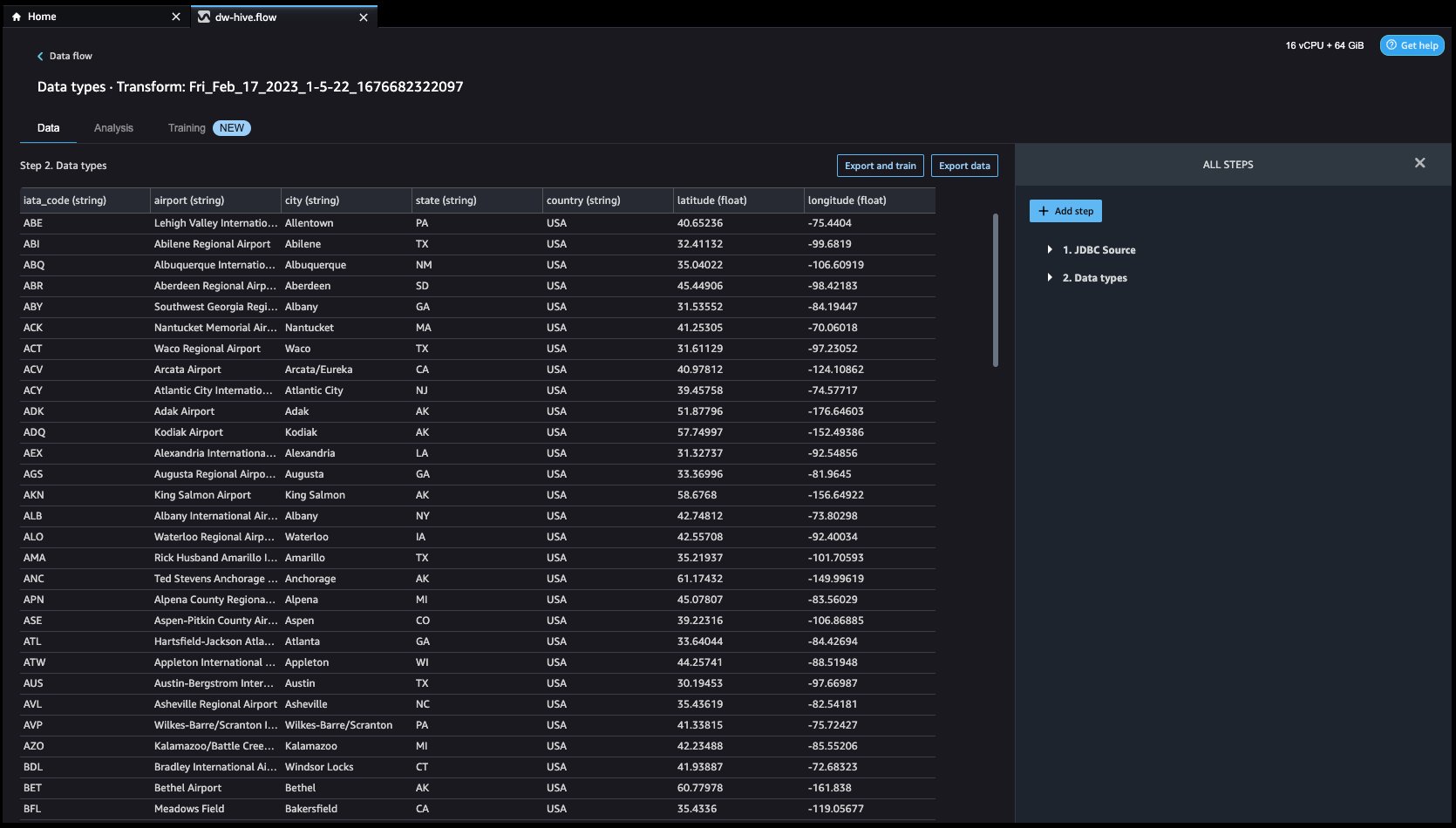
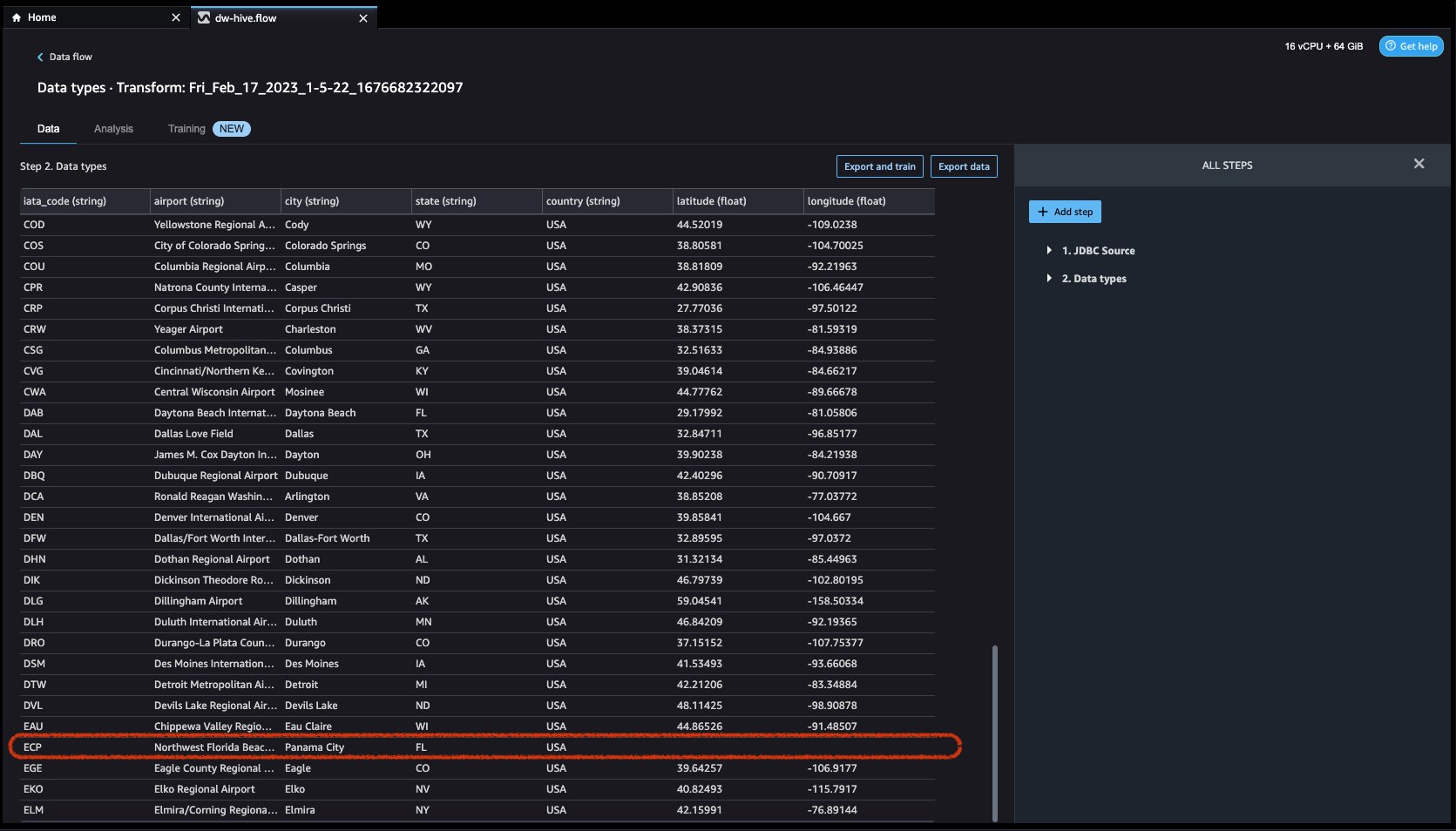
データを調べてみましょう。 次のような複数の機能があることがわかります iata_code, 空港, シティ, 状態, 国, 緯度, 経度. データセット全体が XNUMX つの国 (米国) に基づいていることがわかります。 緯度 および 経度. データが欠落していると、パラメーターの推定に偏りが生じる可能性があり、サンプルの代表性が低下する可能性があるため、いくつかのことを実行する必要があります。 帰属 データセットの欠損値を処理します。
- クリックしてみましょう ステップを追加 右側のナビゲーション バーのボタン。 選択する ハンドルがありません. 構成は、次のスクリーンショットで確認できます。
変換、 select 代入。 選択する 列タイプ as 数値の および 入力列 名 緯度 および 経度。 おおよその中央値を使用して欠損値を代入します。
最初にクリックします プレビュー 欠落している値を表示し、[更新] をクリックして変換を追加します。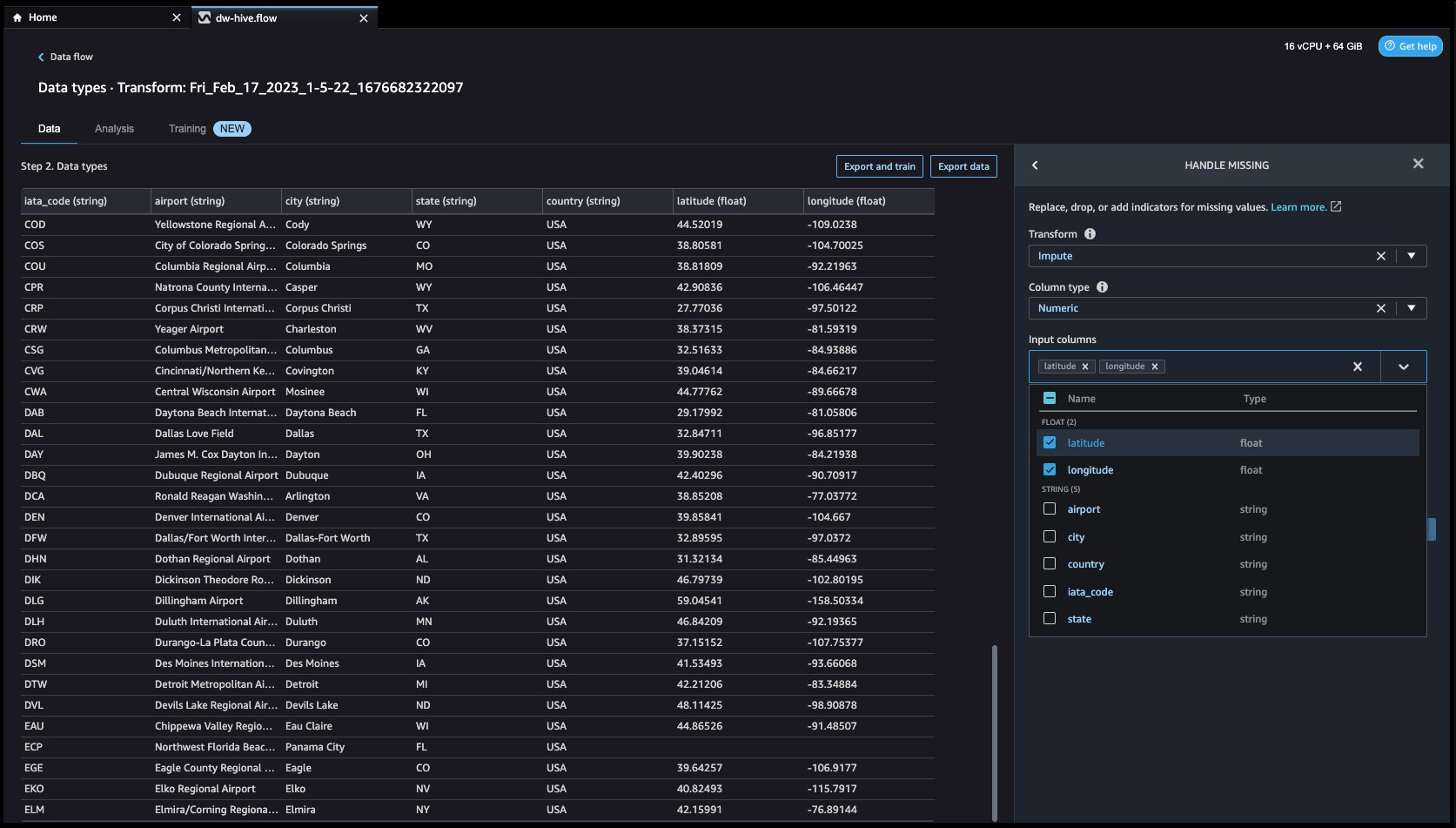

- 別の変換例を見てみましょう。 ML モデルを構築するとき、列が冗長であるかモデルに役立たない場合、列は削除されます。 列を削除する最も一般的な方法は、ドロップすることです。 私たちのデータセットでは、機能 国 データセットは米国の空港データ専用であるため、削除できます。 列を管理するには、 ステップを追加 右側のナビゲーション バーのボタンをクリックして選択します。 列を管理する. 構成は、次のスクリーンショットで確認できます。 下 最適化の適用選択 ドロップカラム、および ドロップする列選択 国.
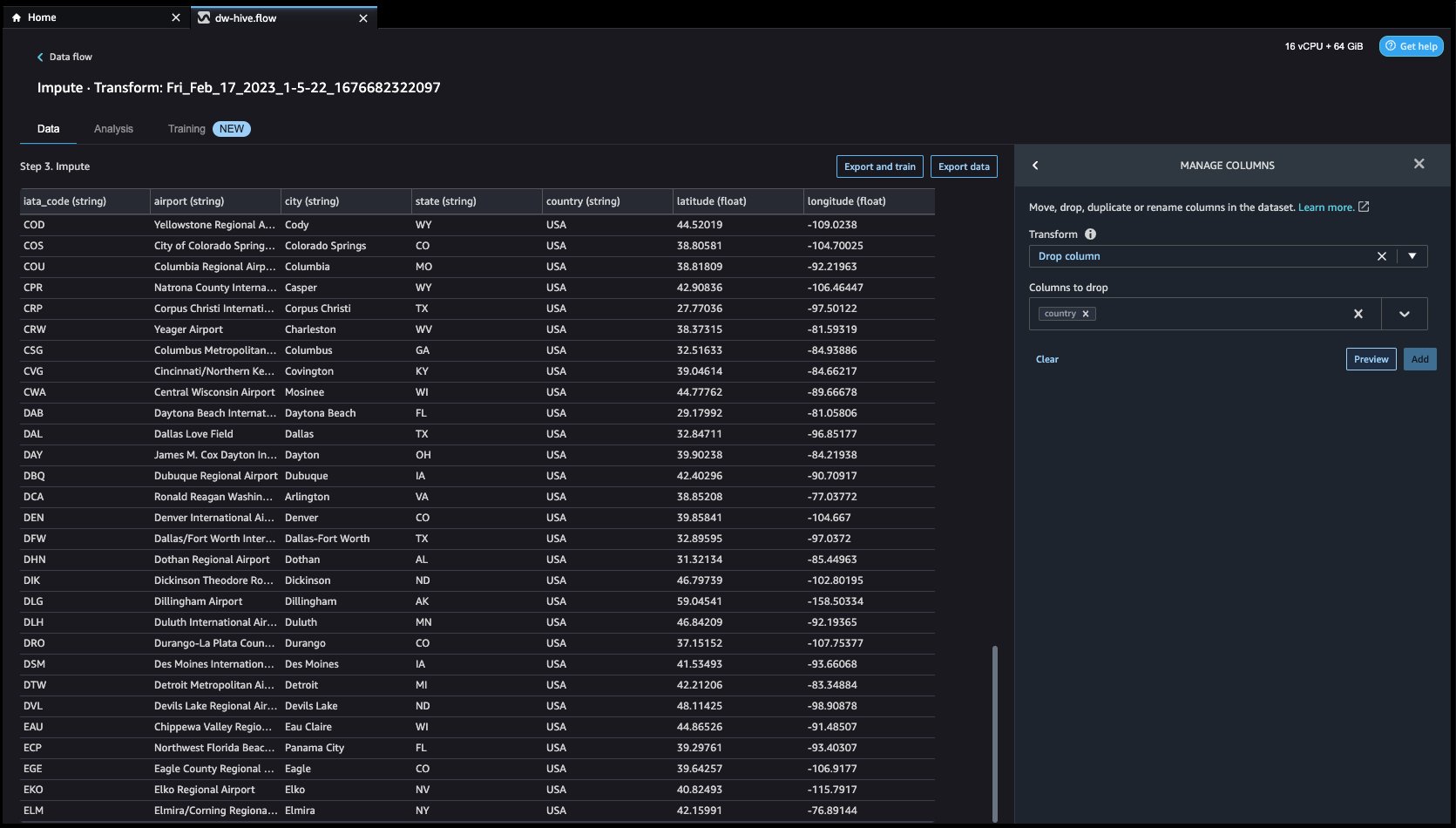
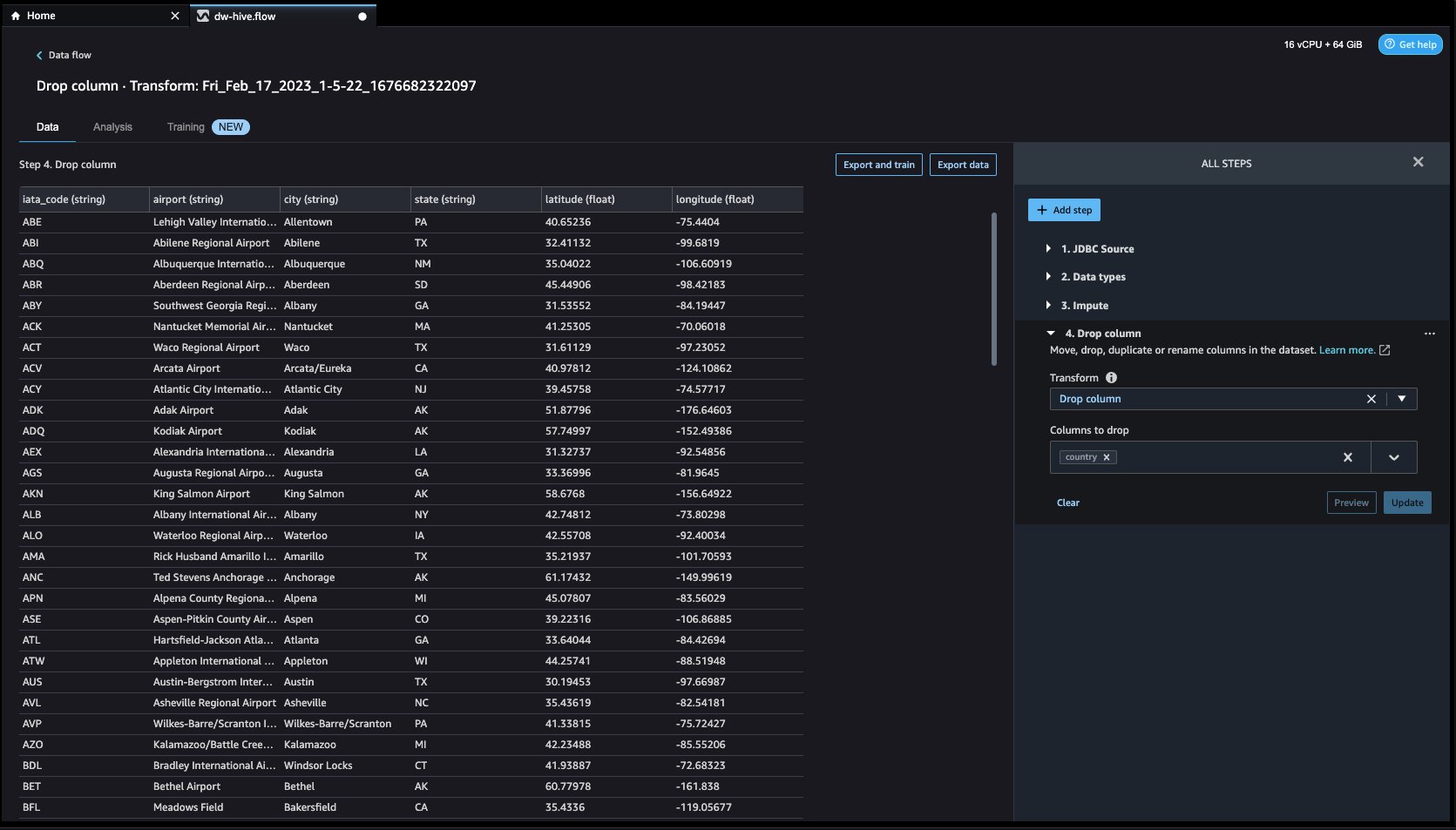
- ソフトウェアの制限をクリック プレビュー その後 アップデイト 列をドロップします。
- Feature Store は、ML モデルの機能を保存、共有、管理するためのリポジトリです。 をクリックしてみましょう + 右のボタン ドロップカラム。 選択する 輸出 選択して SageMakerフィーチャーストア (Jupyter ノートブック経由).
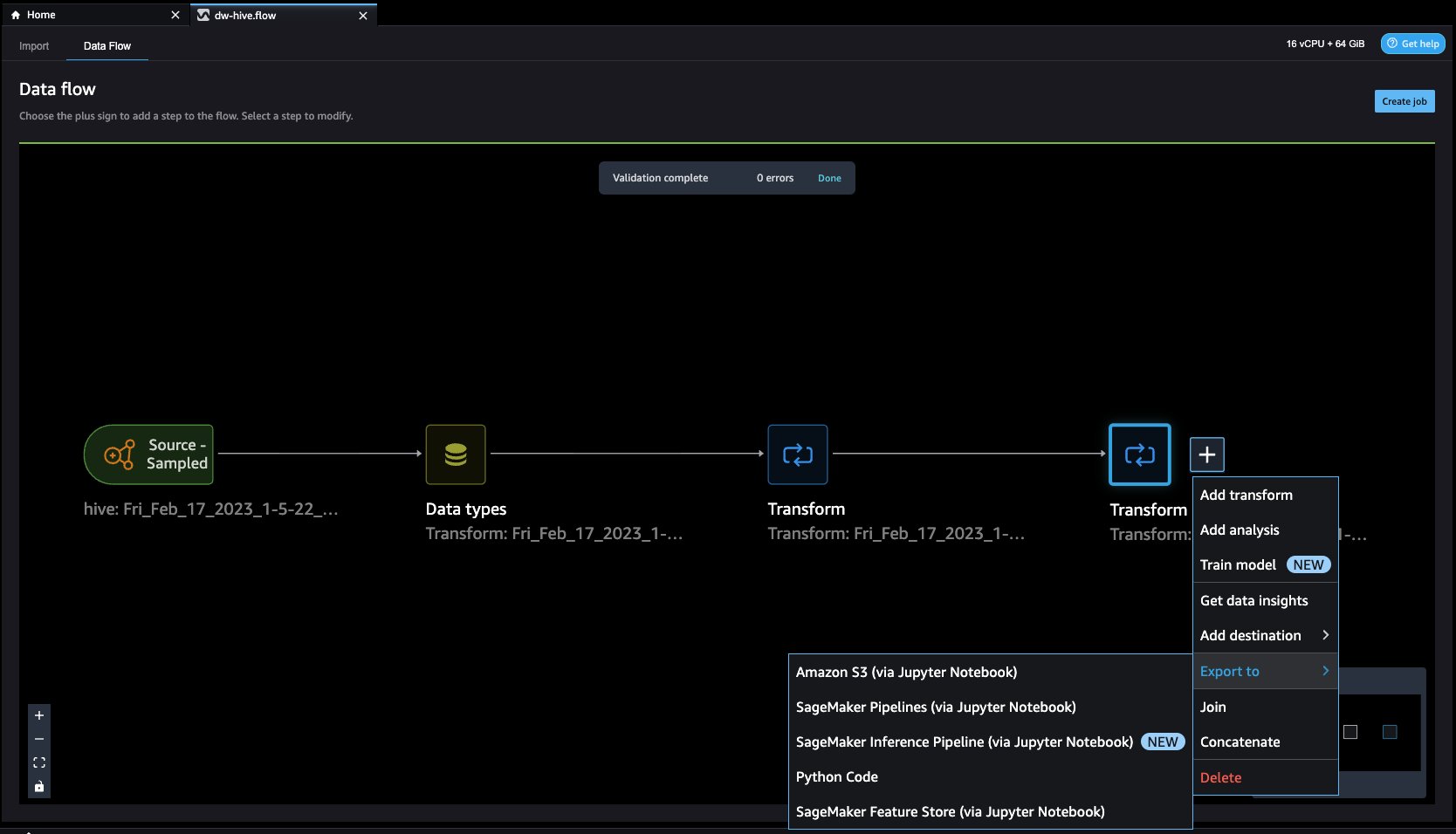
- 選択することによって、 SageMakerフィーチャーストア 宛先として、機能を既存の機能グループに保存するか、新しい機能グループを作成できます。
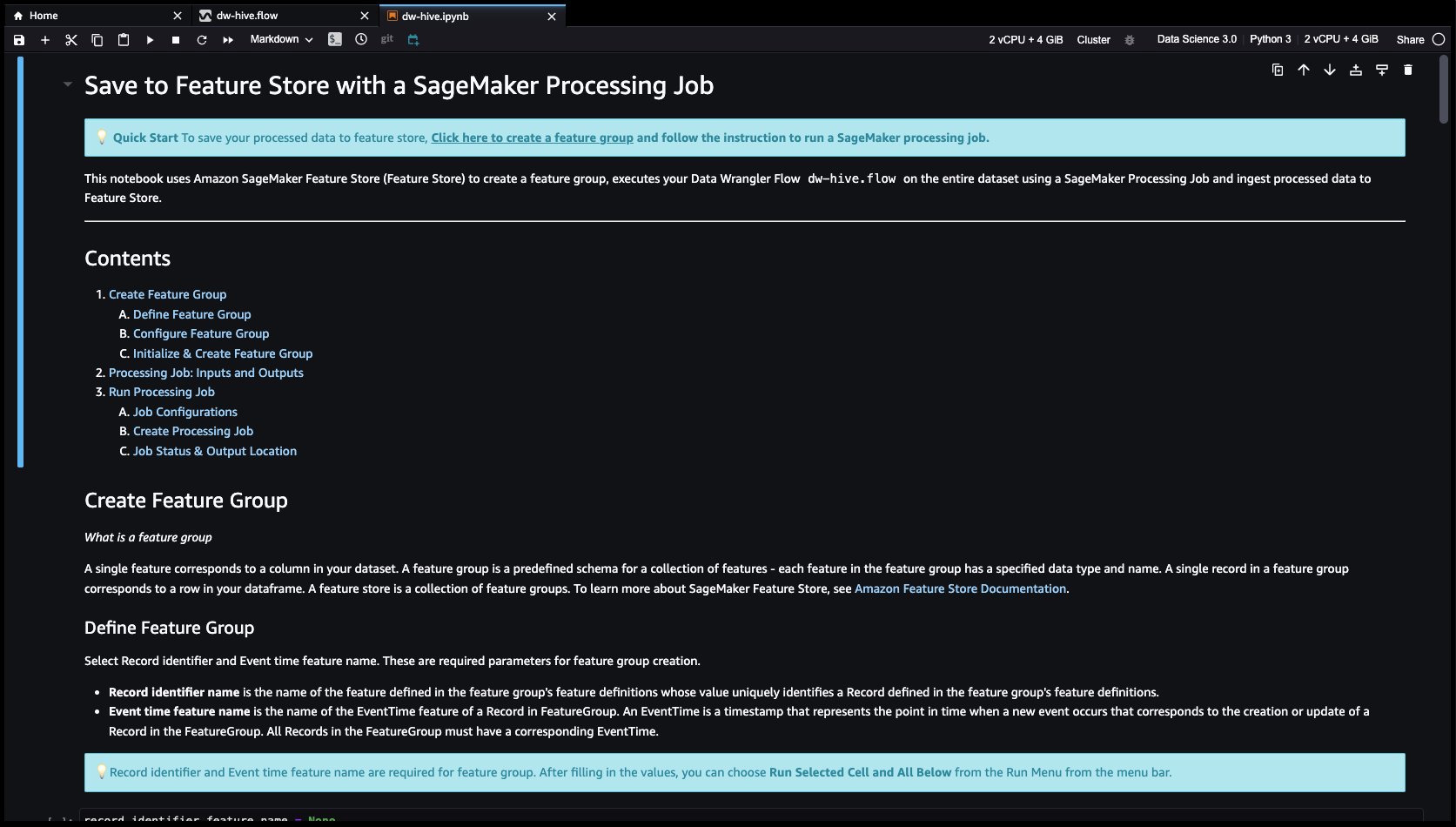
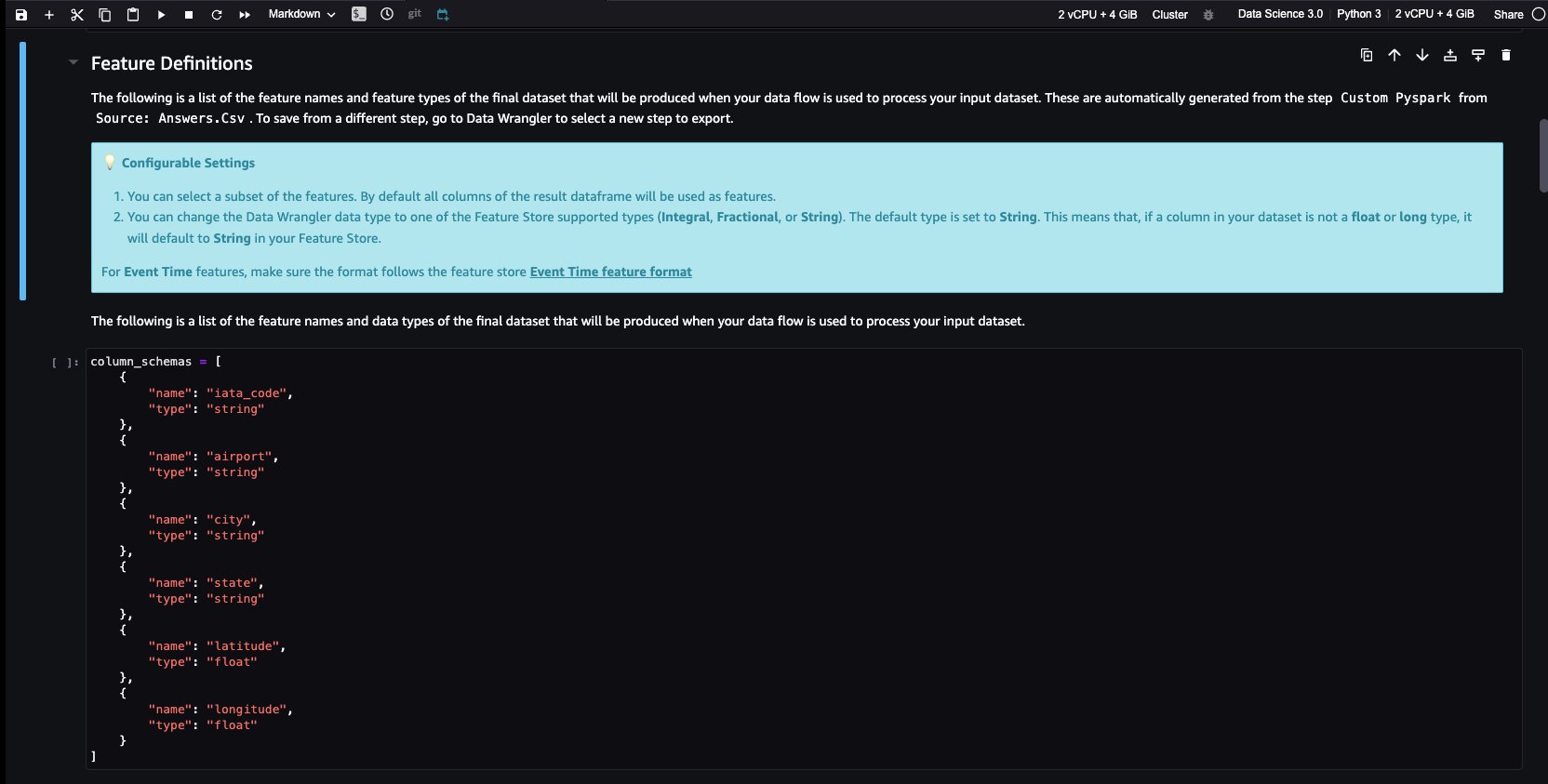
Data Wrangler で機能を作成し、それらの機能を Feature Store に簡単に保存しました。 Data Wrangler UI での機能エンジニアリングのワークフローの例を示しました。 次に、新しい機能グループを作成して、これらの機能を Data Wrangler から直接 Feature Store に保存しました。 最後に、これらの機能を Feature Store に取り込む処理ジョブを実行しました。 Data Wrangler と Feature Store を組み合わせることで、自動化された繰り返し可能なプロセスを構築し、最小限のコーディングでデータ準備タスクを合理化することができました。 Data Wrangler は、同じデータ準備フローを自動化する柔軟性も提供します。 スケジュールされたジョブ. また、自動的に SageMaker Autopilot を使用してモデルをトレーニングおよびデプロイする Data Wrangler のビジュアル インターフェイスから、または SageMaker Pipelines (Jupyter Notebook 経由) でトレーニングまたは機能エンジニアリング パイプラインを作成し、SageMaker 推論パイプライン (Jupyter Notebook 経由) で推論エンドポイントにデプロイします。

クリーンアップ
Data Wrangler での作業が完了したら、次の手順に従って作成したリソースを削除し、追加料金が発生しないようにします。
- SageMaker Studio をシャットダウンします。
SageMaker Studio 内から、すべてのタブを閉じてから、 File その後 シャットダウン. プロンプトが表示されたら、選択します すべてシャットダウン.
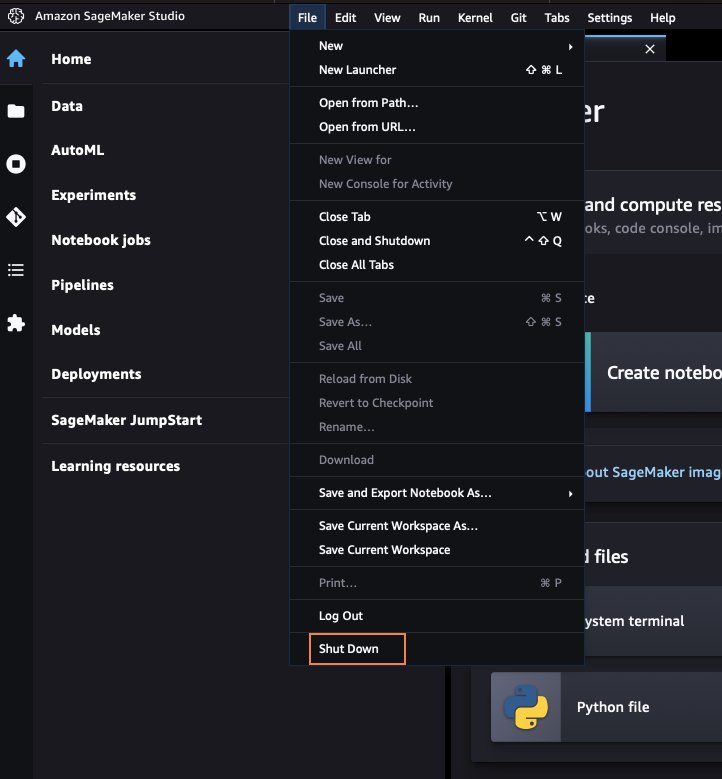

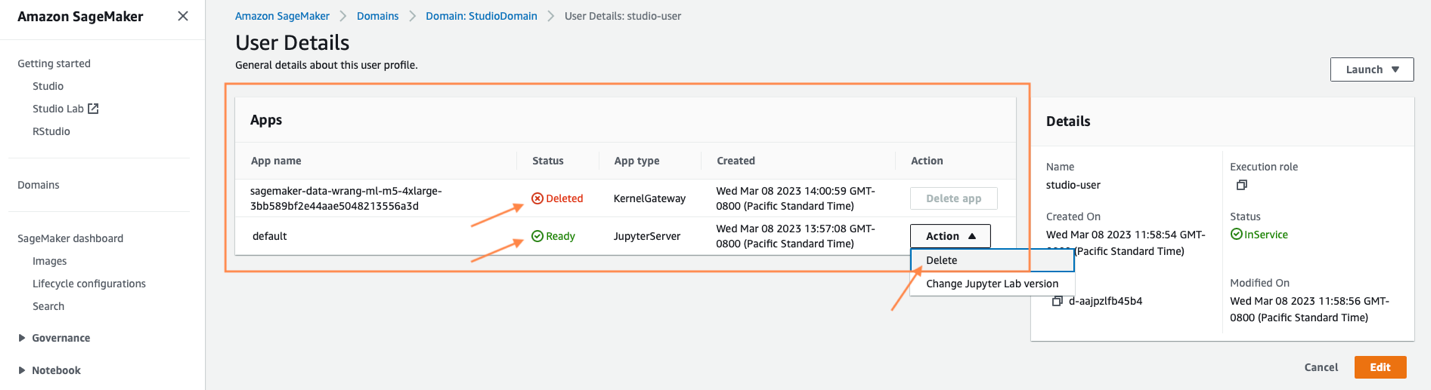
インスタンスの種類によっては、シャットダウンに数分かかる場合があります。 ユーザー プロファイルに関連付けられているすべてのアプリが削除されていることを確認します。 削除されていない場合は、ユーザー プロファイルに関連付けられているアプリを手動で削除します。
- CloudFormation の起動から作成された S3 バケットを空にします。
AWS コンソール検索で S3 を検索して、Amazon S3 ページを開きます。 クラスターのプロビジョニング時に作成された S3 バケットを空にします。 バケットの形式は dw-emr-hive-blog-.
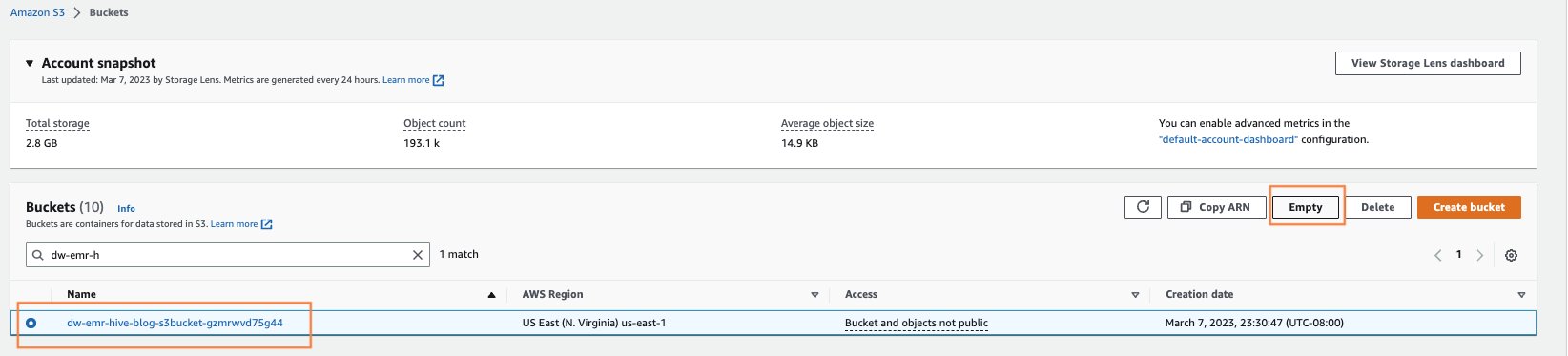
- SageMaker Studio EFS を削除します。
AWS コンソール検索で EFS を検索して、EFS ページを開きます。

SageMaker によって作成されたファイルシステムを見つけます。 これを確認するには、 ファイル システム ID タグの確認 ManagedByAmazonSageMakerResource タグ タブには何も表示されないことに注意してください。
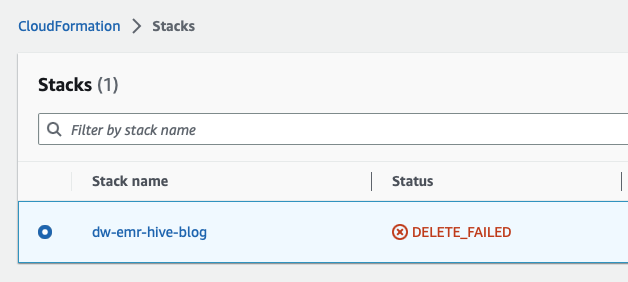
- CloudFormation スタックを削除します。 AWS コンソールから CloudFormation サービスを検索して開き、CloudFormation を開きます。
で始まるテンプレートを選択します わー 次の画面に示すように、をクリックしてスタックを削除します。 削除

これは予期されたものであり、これに戻って以降の手順でクリーンアップします。
- CloudFormation スタックが完了に失敗した後、VPC を削除します。 最初に AWS コンソールから VPC を開きます。
- 次に、SageMaker Studio CloudFormation によって作成された VPC を特定します。
dw-emr-をクリックし、プロンプトに従って VPC を削除します。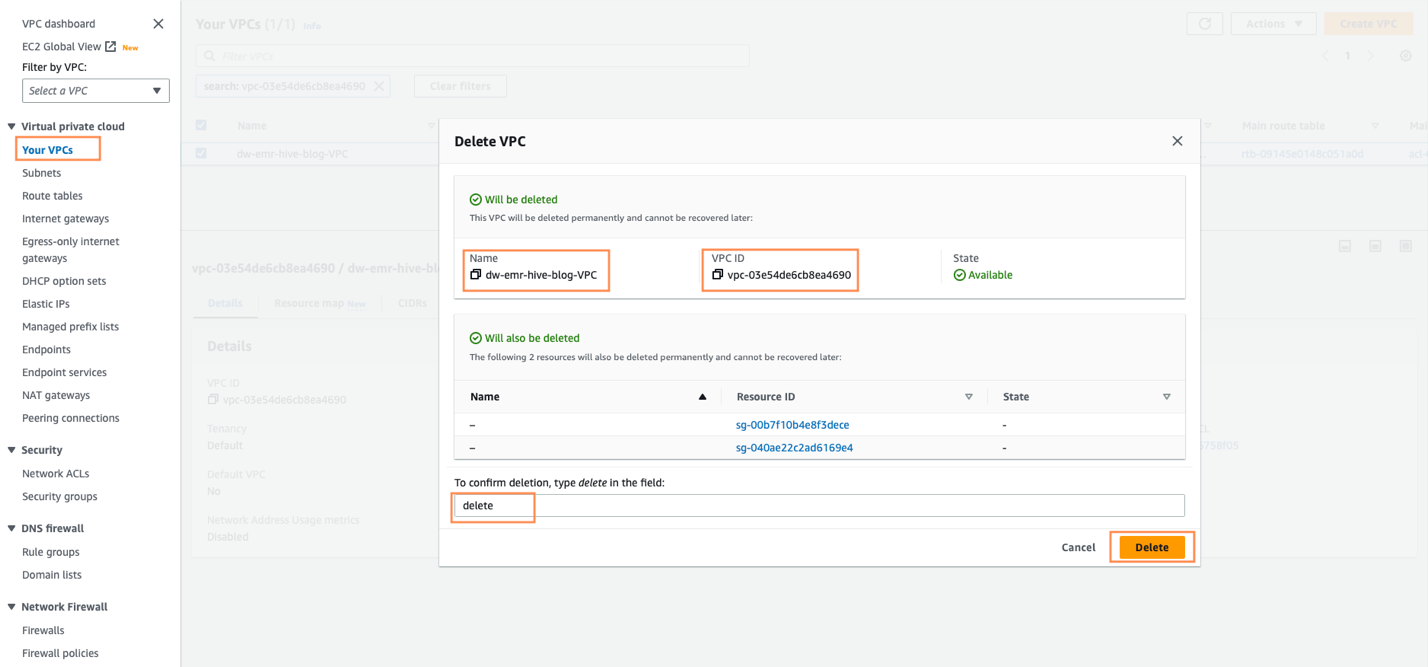
- CloudFormation スタックを削除します。
CloudFormation に戻り、スタックの削除を再試行します dw-emr-hive-blog.

完了! このブログ投稿で説明されている CloudFormation テンプレートによってプロビジョニングされたすべてのリソースは、アカウントから削除されます。
まとめ
この投稿では、Data Wrangler で Amazon EMR をデータ ソースとして設定する方法、データセットを変換および分析する方法、結果をデータ フローにエクスポートして Jupyter ノートブックで使用する方法について説明しました。 Data Wrangler の組み込み分析機能を使用してデータセットを視覚化した後、データ フローをさらに強化しました。 コードを XNUMX 行も書かずにデータ準備パイプラインを作成したという事実は重要です。
Data Wrangler の使用を開始するには、次を参照してください。 Amazon SageMaker Data Wrangler で ML データを準備する で最新情報をご覧ください。 Data Wrangler 製品ページ および AWS 技術文書.
著者について
 アジャイ・ゴビンダラム AWS のシニア ソリューション アーキテクトです。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。 彼の経験は、中規模から大規模の AI / ML アプリケーションの展開に対して、技術的な方向性と設計支援を提供することにあります。 彼の知識は、アプリケーション アーキテクチャからビッグ データ、分析、機械学習にまで及びます。 休息中に音楽を聴いたり、アウトドアを体験したり、愛する人と過ごす時間を楽しんでいます。
アジャイ・ゴビンダラム AWS のシニア ソリューション アーキテクトです。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。 彼の経験は、中規模から大規模の AI / ML アプリケーションの展開に対して、技術的な方向性と設計支援を提供することにあります。 彼の知識は、アプリケーション アーキテクチャからビッグ データ、分析、機械学習にまで及びます。 休息中に音楽を聴いたり、アウトドアを体験したり、愛する人と過ごす時間を楽しんでいます。
 イシャドゥア サンフランシスコ ベイエリアを拠点とするシニア ソリューション アーキテクトです。 彼女は、AWS エンタープライズのお客様の目標と課題を理解することで成長を支援し、回復力とスケーラビリティを確保しながら、クラウドネイティブな方法でアプリケーションを設計する方法を案内しています。 彼女は、機械学習技術と環境の持続可能性に情熱を注いでいます。
イシャドゥア サンフランシスコ ベイエリアを拠点とするシニア ソリューション アーキテクトです。 彼女は、AWS エンタープライズのお客様の目標と課題を理解することで成長を支援し、回復力とスケーラビリティを確保しながら、クラウドネイティブな方法でアプリケーションを設計する方法を案内しています。 彼女は、機械学習技術と環境の持続可能性に情熱を注いでいます。
 ヴァルンメタ AWS のソリューション アーキテクトです。 彼は、顧客が AWS クラウドでエンタープライズ規模の適切に設計されたソリューションを構築するのを支援することに情熱を注いでいます。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。
ヴァルンメタ AWS のソリューション アーキテクトです。 彼は、顧客が AWS クラウドでエンタープライズ規模の適切に設計されたソリューションを構築するのを支援することに情熱を注いでいます。 彼は、AI/ML を使用して複雑なビジネス上の問題を解決している戦略的な顧客と協力しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/accelerate-time-to-insight-with-amazon-sagemaker-data-wrangler-and-the-power-of-apache-hive/

