第1部 この 2 部構成のシリーズでは、プレーン テキスト データ属性を仮名に、またはその逆に変換する仮名化サービスを構築する方法について説明しました。一元化された仮名化サービスは、仮名を生成するためのユニークで広く認知されたアーキテクチャを提供します。その結果、組織は、すべてのプラットフォームにわたって機密データを処理するための標準プロセスを実現できます。さらに、これにより、開発チームや分析ユーザーからさまざまなコンプライアンス要件を理解して実装するために必要な複雑さと専門知識がなくなり、ビジネスの成果に集中できるようになります。
分離されたサービスベースのアプローチに従うということは、組織として、ビジネス上の問題を解決するために特定のテクノロジーを使用することに偏りがないことを意味します。個々のチームがどのテクノロジーを好むかに関係なく、仮名化サービスを呼び出して機密データを仮名化できます。
この投稿では、仮名化サービスを使用できる一般的な抽出、変換、ロード (ETL) の使用パターンに焦点を当てます。 ETL ジョブで仮名化サービスを使用する方法については、 アマゾンEMR (使用 EC2 上の Amazon EMR) ストリーミングおよびバッチの使用例の場合。さらに、 アマゾンアテナ & AWSグルー に基づいた消費パターン GitHubレポ ソリューションの。
ソリューションの概要
次の図は、ソリューション アーキテクチャを示しています。

右側のアカウントは仮名化サービスをホストしており、このシリーズのパート 1 で説明した手順に従って展開できます。
左側のアカウントは、この投稿の一部として設定したアカウントで、仮名化サービスを使用した Amazon EMR に基づく ETL プラットフォームを表しています。
仮名化サービスと ETL プラットフォームを同じアカウントにデプロイできます。
Amazon EMR を使用すると、Apache Spark などのビッグデータ フレームワークを迅速かつコスト効率よく作成、運用、拡張できます。
このソリューションでは、仮名化サービスを利用する方法を示します。 アマゾンEMR Apache Spark バッチおよびストリーミングのユースケース向け。バッチ アプリケーションは、 Amazon シンプル ストレージ サービス (Amazon S3) バケットからのレコードをストリーミング アプリケーションが消費します。 Amazon Kinesisデータストリーム.
バッチおよびストリーミング ジョブで使用される PySpark コード
どちらのアプリケーションも、仮名化にリンクされている API ゲートウェイに対して HTTP POST 呼び出しを行う共通のユーティリティ関数を使用します。 AWSラムダ 関数。 REST API 呼び出しは、Spark RDD を使用して Spark パーティションごとに行われます。 マップパーティション 関数。 POST リクエストの本文には、特定の入力列の一意の値のリストが含まれています。 POST リクエストの応答には、対応する仮名化された値が含まれています。このコードは、指定されたデータセットの機密値を仮名化された値と交換します。結果は Amazon S3 に保存され、 AWSグルー データカタログ、Apacheを使用 氷山 テーブル形式。
Iceberg は、ACID トランザクション、スキーマ進化、タイム トラベル クエリをサポートするオープン テーブル形式です。これらの機能を使用して、 忘れられる権利 SQL ステートメントまたはプログラミング インターフェイスを使用した (またはデータ消去) ソリューション。 Iceberg は、バージョン 6.5.0 以降の Amazon EMR、AWS Glue、および Athena でサポートされています。バッチおよびストリーミング パターンでは、ターゲット形式として Iceberg が使用されます。 Iceberg を使用して ACID 準拠のデータ レイクを構築する方法の概要については、以下を参照してください。 AmazonEMRでApacheIcebergを使用して、高性能でACIDに準拠した進化するデータレイクを構築します.
前提条件
次の前提条件が必要です。
- An AWSアカウント.
- An AWS IDおよびアクセス管理 をデプロイする権限を持つ (IAM) プリンシパル AWS CloudFormation スタックと関連リソース。
- AWSコマンドラインインターフェイス (AWS CLI) は、提供されたスクリプトを実行するために使用する開発マシンまたはデプロイメントマシンにインストールされます。
- ソリューションがデプロイされる同じアカウントおよび AWS リージョン内の S3 バケット。
- Python3 コマンドが実行されるローカル マシンにインストールされます。
- PyYAML を使用してインストールされました ピップ.
- CloudFormation スタックをデプロイする bash スクリプトを実行するための bash ターミナル。
- Parquet ファイル内の入力データセットを含む追加の S3 バケット (バッチ アプリケーションの場合のみ)。をコピーします サンプルデータセット S3 バケットに。
- のコピー 最新のコードリポジトリ ローカルマシンで使用して
git cloneまたはダウンロードオプション。
新しい bash ターミナルを開き、複製されたリポジトリのルート フォルダーに移動します。
提案されたパターンのソース コードは、複製されたリポジトリにあります。次のパラメータを使用します。
- ARTEFACT_S3_BUCKET – インフラストラクチャ コードが保存される S3 バケット。バケットは、ソリューションが存在するのと同じアカウントおよびリージョンに作成する必要があります。
- AWS_REGION – ソリューションがデプロイされるリージョン。
- AWS_PROFILE – に適用される名前付きプロファイル。 AWS CLIコマンド。これには、関連リソースの CloudFormation スタックをデプロイする権限を持つ IAM プリンシパルの認証情報が含まれている必要があります。
- サブネットID – EMR クラスターがスピンアップされるサブネット ID。サブネットは既存であり、デモンストレーションの目的で、デフォルト VPC のデフォルトのサブネット ID を使用します。
- EP_URL – 仮名化サービスのエンドポイント URL。これを次のようにデプロイされたソリューションから取得します。 第1部 このシリーズの。
- API_SECRET - あん アマゾンAPIゲートウェイ キー に保存されます AWSシークレットマネージャー。 API キーは、図に示すデプロイメントから生成されます。 第1部 このシリーズの。
- S3_INPUT_PATH – 入力データセットを Parquet ファイルとして含むフォルダーを指す S3 URI。
- KINESIS_DATA_STREAM_NAME – CloudFormation スタックでデプロイされた Kinesis データストリーム名。
- バッチサイズ – バッチごとにデータ ストリームにプッシュされるレコードの数。
- THREADS_NUM – データをデータ ストリームにアップロードするためにローカル マシンで使用される並列スレッドの数。スレッドが多いほど、メッセージ量も多くなります。
- EMR_CLUSTER_ID – コードが実行される EMR クラスター ID (EMR クラスターは CloudFormation スタックによって作成されました)。
- STACK_NAME – デプロイメント スクリプトで割り当てられる CloudFormation スタックの名前。
バッチ展開の手順
前提条件で説明したように、ソリューションを展開する前に、 テストデータセット Amazon S3に。次に、ファイルを含むフォルダーの S3 パスをパラメーターとして指定します。 <S3_INPUT_PATH>.
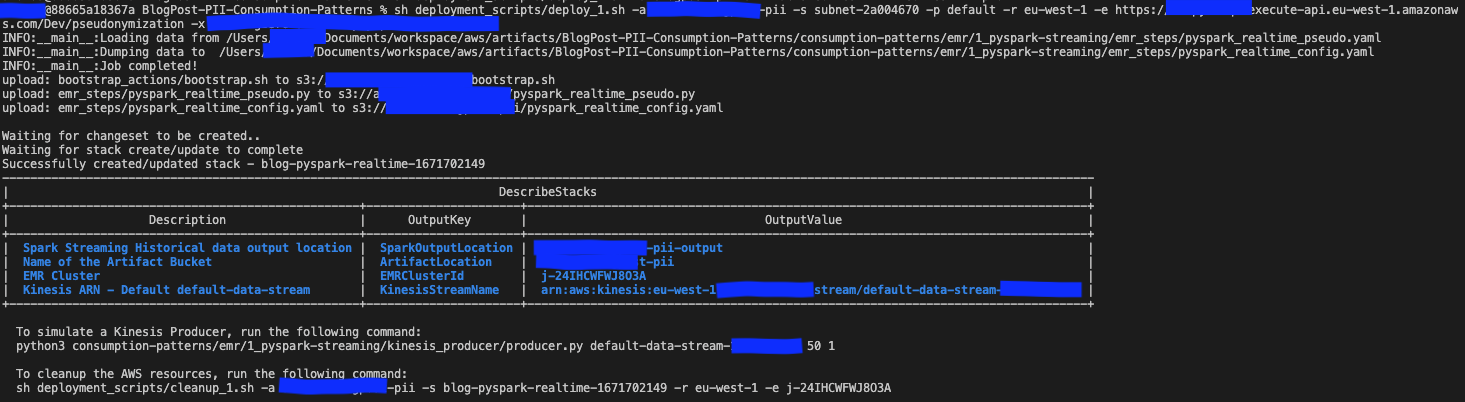
AWS CloudFormation を介してソリューション リソースを作成します。ソリューションをデプロイするには、 デプロイ_1.sh スクリプト内にあります deployment_scripts フォルダにコピーします。
デプロイメントの前提条件が満たされたら、次のコマンドを入力してソリューションをデプロイします。
sh ./deployment_scripts/deploy_1.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>
-i <S3_INPUT_PATH>出力は次のスクリーンショットのようになります。

クリーンアップ コマンドに必要なパラメータは、実行の最後に出力されます。 deploy_1.sh 脚本。これらの値を必ず書き留めてください。
バッチ ソリューションをテストする
を使用してデプロイされた CloudFormation テンプレート内で、 deploy_1.sh スクリプト、以下を含む EMR ステップ Spark バッチ アプリケーション は、EMR クラスターのセットアップの最後に追加されます。
結果を確認するには、変数を使用して CloudFormation スタック出力で特定された S3 バケットを確認します。 SparkOutputLocation.

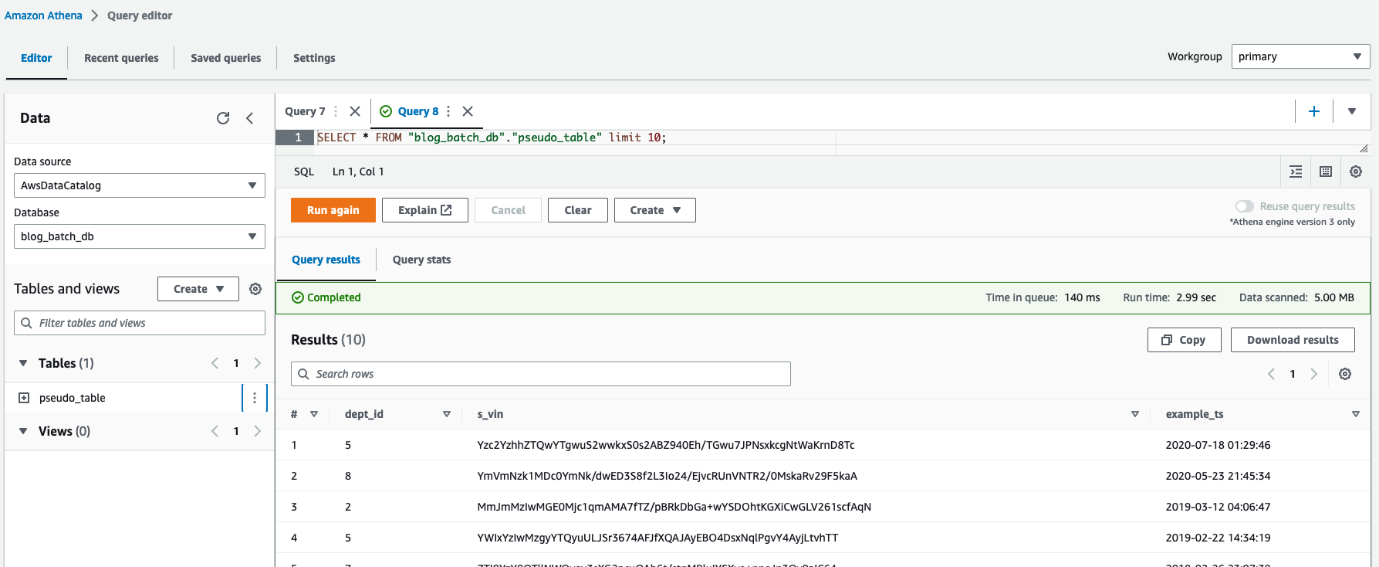
Athena を使用して次のこともできます。 テーブルをクエリする pseudo_table データベース内 blog_batch_db.
バッチリソースをクリーンアップする
この演習の一環として作成されたリソースを破棄するには、
bash ターミナルで、複製されたリポジトリのルート フォルダーに移動します。以前に実行した出力として表示されているクリーンアップ コマンドを入力します。 デプロイ_1.sh スクリプト:
sh ./deployment_scripts/cleanup_1.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>出力は次のスクリーンショットのようになります。

ストリーミング展開の手順
AWS CloudFormation を介してソリューション リソースを作成します。ソリューションをデプロイするには、 デプロイ_2.sh スクリプト内にあります deployment_scripts フォルダ。このパターンの CloudFormation スタック テンプレートは、 GitHubレポ.
デプロイメントの前提条件が満たされたら、次のコマンドを入力してソリューションをデプロイします。
sh deployment_scripts/deploy_2.sh
-a <ARTEFACT_S3_BUCKET>
-r <AWS_REGION>
-p <AWS_PROFILE>
-s <SUBNET_ID>
-e <EP_URL>
-x <API_SECRET>出力は次のスクリーンショットのようになります。
クリーンアップ コマンドに必要なパラメータは、コマンドの出力の最後に出力されます。 デプロイ_2.sh 脚本。後で使用できるように、これらの値を必ず保存してください。
ストリーミング ソリューションをテストする
を使用してデプロイされた CloudFormation テンプレート内で、 deploy_2.sh スクリプト、以下を含む EMR ステップ Sparkストリーミングアプリケーション は、EMR クラスターのセットアップの最後に追加されます。エンドツーエンドのパイプラインをテストするには、デプロイされた Kinesis データストリームにレコードをプッシュする必要があります。 bash ターミナルで次のコマンドを使用すると、プロセスが手動で停止されるまで継続的にストリームにレコードを配置する Kinesis プロデューサーをアクティブ化できます。プロデューサーのメッセージ量を制御するには、 BATCH_SIZE と THREADS_NUM 変数。


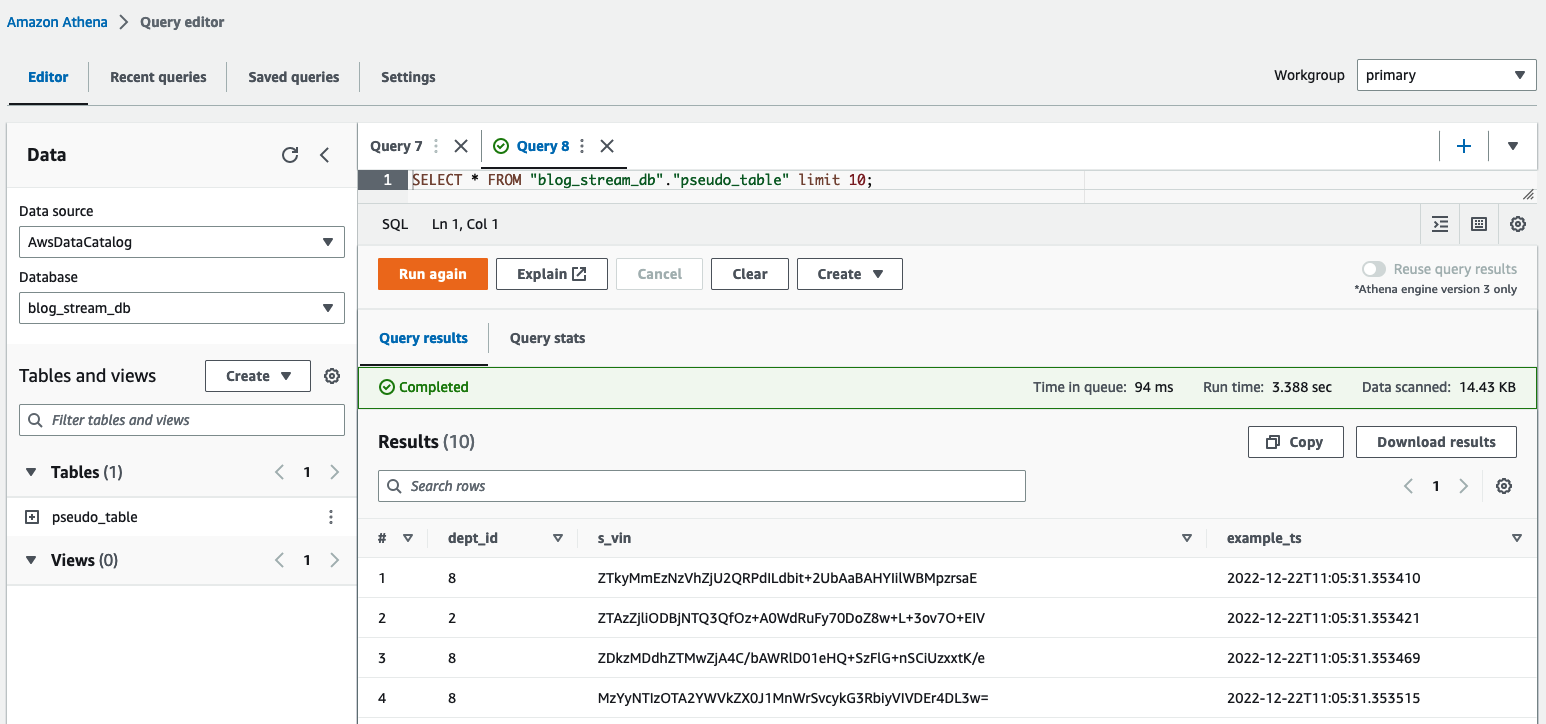
Athena クエリエディターで、クエリを実行して結果を確認します。 table pseudo_table データベース内 blog_stream_db.
ストリーミング リソースをクリーンアップする
この演習の一部として作成されたリソースを破棄するには、次の手順を実行します。
- 前のセクションで bash ターミナルで起動した Python Kinesis プロデューサを停止します。
- 次のコマンドを入力します。
sh ./deployment_scripts/cleanup_2.sh
-a <ARTEFACT_S3_BUCKET>
-s <STACK_NAME>
-r <AWS_REGION>
-e <EMR_CLUSTER_ID>出力は次のスクリーンショットのようになります。

公演詳細
ユースケースによって、データ サイズ、計算能力、コストに関する要件が異なる場合があります。パフォーマンスに影響を与える可能性のあるいくつかのベンチマークと要因を提供しました。ただし、ソリューションが特定の要件を満たしているかどうかを確認するために、下位環境でソリューションを検証することを強くお勧めします。
提案されたソリューション (Amazon EMR を使用してデータセットを仮名化することを目的とした) のパフォーマンスは、仮名化サービスへの並列呼び出しの最大数と各呼び出しのペイロード サイズによって影響を受ける可能性があります。並列呼び出しに関して考慮すべき要素は次のとおりです。 Secrets Manager からの GetSecretValue 呼び出し制限 (10.000 秒あたり 1,000、ハードリミット) および Lambda のデフォルトの同時実行並列処理 (デフォルトで XNUMX、クォータ リクエストによって増加可能)。エグゼキューターの数、データセットを構成するパーティションの数、クラスター構成 (ノードの数と種類) を調整して、最大並列処理を制御できます。各呼び出しのペイロード サイズに関して考慮すべき要素は次のとおりです。 APIゲートウェイの最大ペイロードサイズ(6MB) Lambda 関数の最大実行時間 (15 分)。バッチ サイズの値を調整することで、ペイロード サイズと Lambda 関数の実行時間を制御できます。バッチ サイズの値は、各 API 呼び出しごとに仮名化されるアイテムの数を決定する PySpark スクリプトのパラメータです。これらすべての要因の影響を把握し、Amazon EMR を使用して消費パターンのパフォーマンスを評価するために、次のシナリオを設計および監視しました。
バッチ消費パターンのパフォーマンス
バッチ消費パターンのパフォーマンスを評価するために、それぞれ 1 MB の 10、100、および 97.7 個の Parquet ファイルで構成される XNUMX つの入力データセットを使用して仮名化アプリケーションを実行しました。を使用して入力ファイルを生成しました。 dataset_generator.py スクリプト。
クラスター容量ノードは、1 つのプライマリ (m5.4xlarge) と 15 のコア (m5d.8xlarge) でした。このクラスター構成は 100 つのシナリオすべてで同じであり、Spark アプリケーションは最大 XNUMX 個のエグゼキューターを使用できました。の batch_sizeこれも 900 つのシナリオで同じで、API 呼び出しごとに 5 VIN に設定され、最大 VIN サイズは XNUMX バイトでした。
次の表は、3 つのシナリオの情報をまとめたものです。
| 実行ID | 再分割 | データセットサイズ | エグゼキュータの数 | エグゼキュータあたりのコア数 | エグゼキュータメモリ | ランタイム |
| A | 800 | 9.53 GB | 100 | 4 | 4 GiB | 11分、10秒 |
| B | 80 | 0.95 GB | 10 | 4 | 4 GiB | 8分、36秒 |
| C | 8 | 0.09 GB | 1 | 4 | 4 GiB | 7分、56秒 |
ご覧のとおり、仮名化サービスへの呼び出しを適切に並列化することで、全体の実行時間を制御できるようになります。
次の例では、仮名化サービスの 3 つの重要な Lambda メトリクスを分析します。 Invocations, ConcurrentExecutions, Duration.
次のグラフは、 Invocations 統計を使用したメトリック SUM オレンジ色と RUNNING SUM 青色の。

累積呼び出しの開始点と終了点の差を計算することで、各実行中に行われた呼び出しの数を抽出できます。
| 実行ID | データセットサイズ | 合計呼び出し数 |
| A | 9.53 GB | 1.467.000-0 = 1.467.000 |
| B | 0.95 GB | 1.467.000-1.616.500 = 149.500 |
| C | 0.09 GB | 1.616.500-1.631.000 = 14.500 |
予想どおり、呼び出しの数はデータセットのサイズに比例して 10 ずつ増加します。
次のグラフは合計を示しています ConcurrentExecutions 統計を使用したメトリック MAX 青色の。
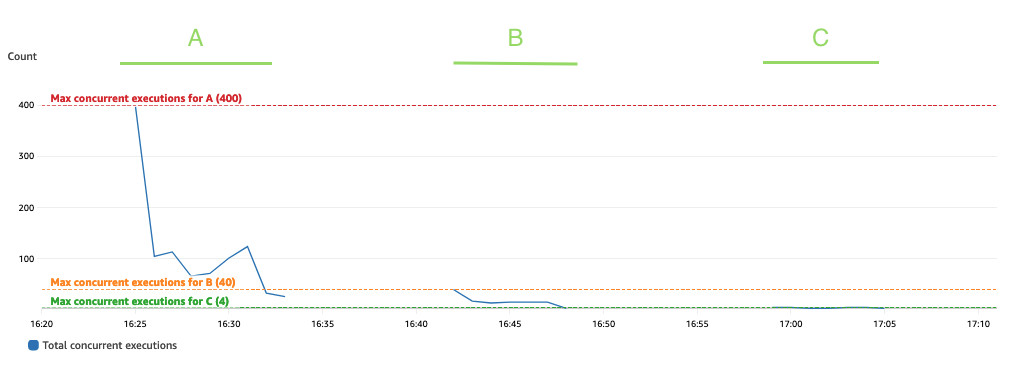
このアプリケーションは、Lambda 関数の同時実行の最大数が、並列処理できる Spark タスク (Spark データセット パーティション) の量によって決まるように設計されています。この数値は次のように計算できます。 MIN (執行者 x executor_cores、Spark データセット パーティション)。
テストでは、それぞれ 800 つのコアを持つ 100 個のエグゼキューターを使用して、400 個のパーティションを処理しました。これにより、400 個のタスクが並列処理されるため、Lambda 関数の同時実行は 400 を超えることはできません。同じロジックが実行 B と C に適用されました。これが前のグラフに反映されていることがわかります。同時実行の量は決して超えません。 40、4、および XNUMX の値。
スロットルを回避するには、並列処理できる Spark タスクの量が Lambda 関数の同時実行制限を超えていないことを確認してください。その場合は、Lambda 関数の同時実行制限を増やすか (パフォーマンスを維持したい場合)、パーティションの量または使用可能なエグゼキュータの数を減らす必要があります (アプリケーションのパフォーマンスに影響します)。
次のグラフはラムダを示しています。 Duration 統計を使用したメトリック AVG オレンジ色と MAX 緑で。
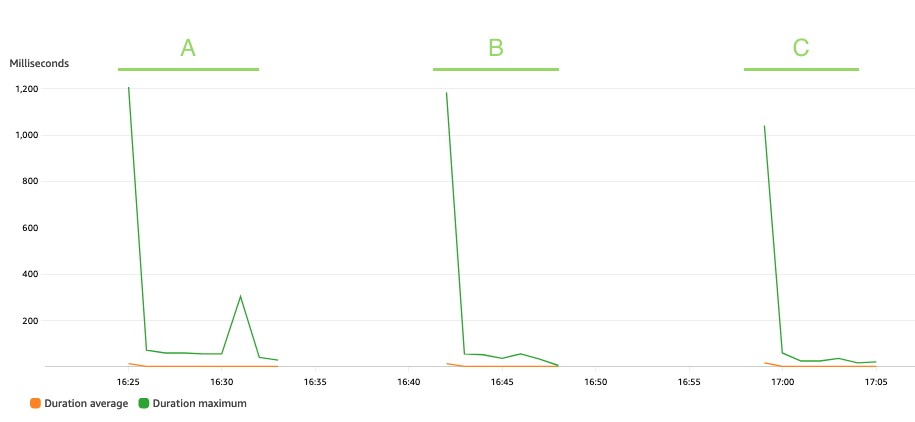
予想通り、データセットのサイズは仮名化関数の実行時間には影響せず、コールド スタートに直面する一部の最初の呼び出しを除いて、3 つのシナリオを通じて平均 XNUMX ミリ秒で一定のままです。これは、各仮名化呼び出しに含まれるレコードの最大数が一定であるためです (batch_size 値)。
Lambda は、呼び出しの数とコードの実行にかかる時間 (期間) に基づいて課金されます。平均期間と呼び出しメトリクスを使用して、仮名化サービスのコストを見積もることができます。
ストリーミング消費パターンのパフォーマンス
ストリーミング消費パターンのパフォーマンスを評価するために、 プロデューサー.py このスクリプトは、レコードをバッチで Kinesis データストリームにプッシュする Kinesis データプロデューサーを定義します。
ストリーミング アプリケーションは 15 分間実行されたままになり、次のように構成されました。 batch_interval ストリーミング データがバッチに分割される時間間隔は 1 分です。次の表は、関連する要因をまとめたものです。
| 再分割 | クラスター容量ノード | エグゼキュータの数 | 処刑者の記憶 | バッチウィンドウ | バッチサイズ | VIN サイズ |
| 17 |
1 プライマリ (m5.xlarge)、 3コア(m5.2xlarge) |
6 | 9 GiB | 60 seconds | 900 VIN/API コール。 | 5バイト/VIN |
次のグラフは、Kinesis Data Streams メトリクスを示しています。 PutRecords (青色)と GetRecords (オレンジ色) 1 分間の期間で集計され、統計を使用します。 SUM。最初のグラフはメトリクスをバイト単位で示しており、最大で 6.8 分あたり 85,000 MB になります。 XNUMX 番目のグラフは、XNUMX 分あたり XNUMX レコードに達するレコード数のメトリクスを示しています。
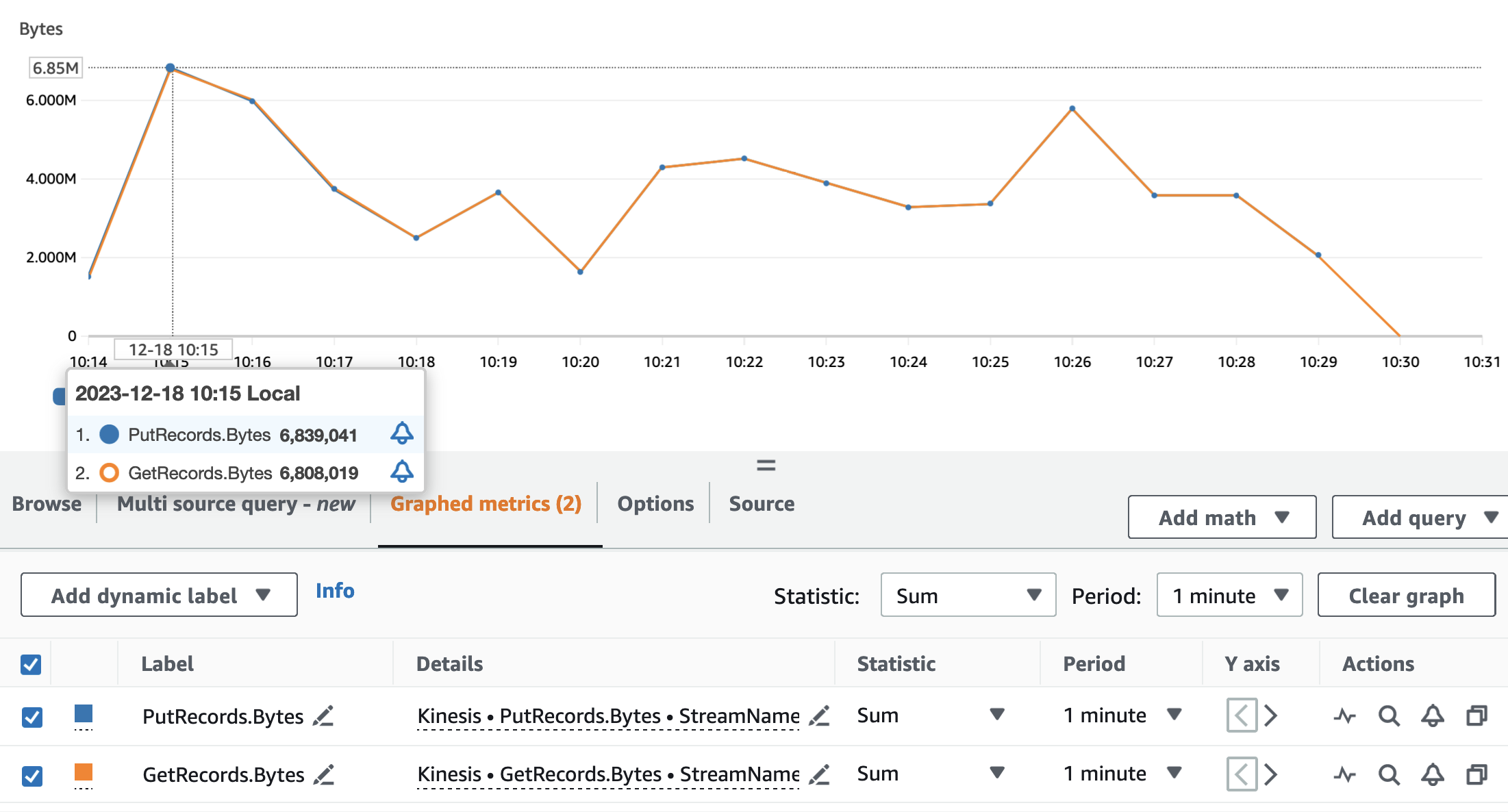

メトリクスが GetRecords & PutRecords アプリケーションの実行のほぼ全体で重複する値があります。これは、ストリーミング アプリケーションがストリームの負荷に対応できたことを意味します。
次に、仮名化サービスに関連する Lambda メトリクスを分析します。 Invocations, ConcurrentExecutions, Duration.
次のグラフは、 Invocations 統計を使用したメトリック SUM (オレンジ色)と RUNNING SUM 青色の。
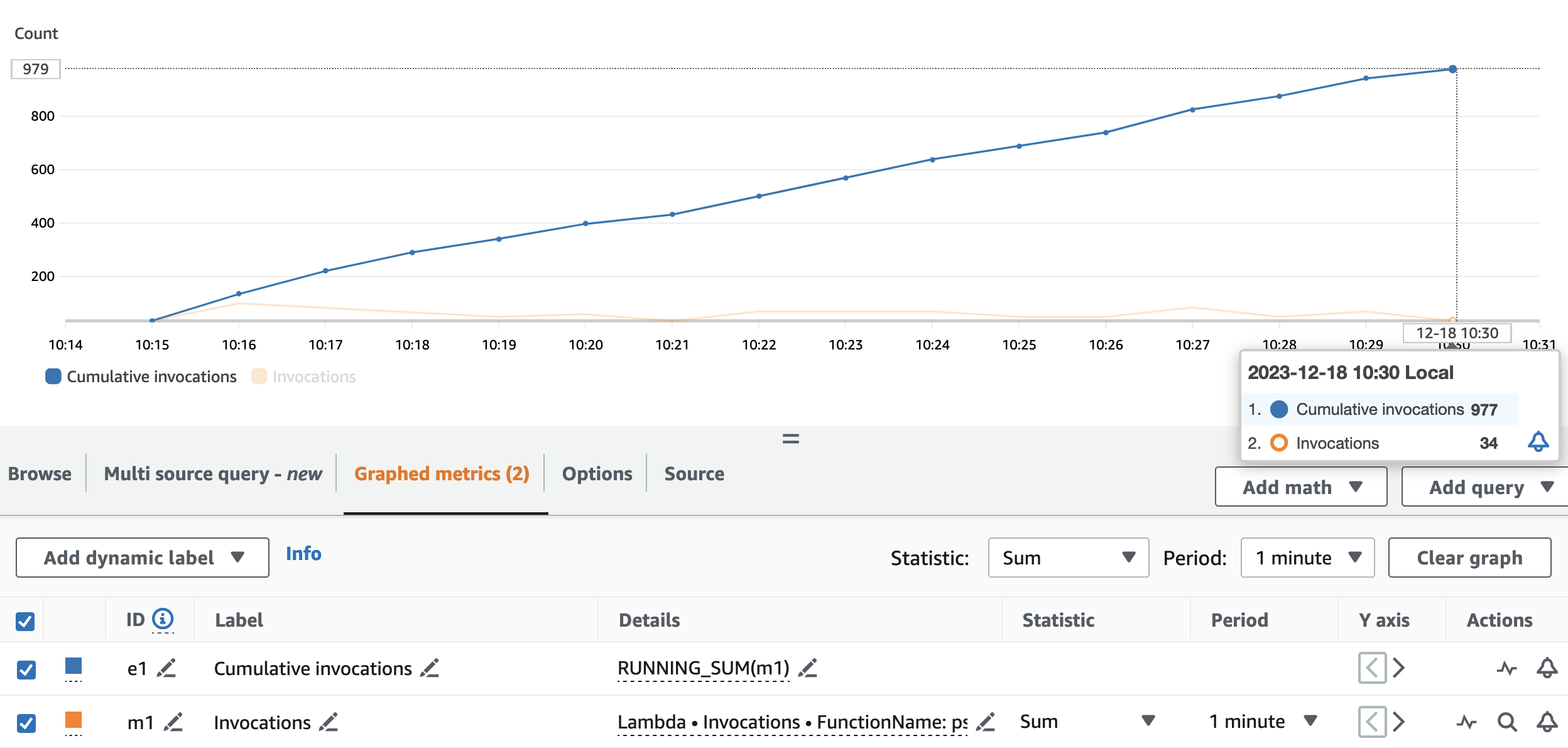
累積呼び出しの開始点と終了点の差を計算することで、実行中に行われた呼び出しの数を抽出できます。具体的には、ストリーミング アプリケーションは 15 分間で仮名化 API を 977 回呼び出しました。これは 65 分あたり約 XNUMX 回の呼び出しに相当します。
次のグラフは合計を示しています ConcurrentExecutions 統計を使用したメトリック MAX 青色の。
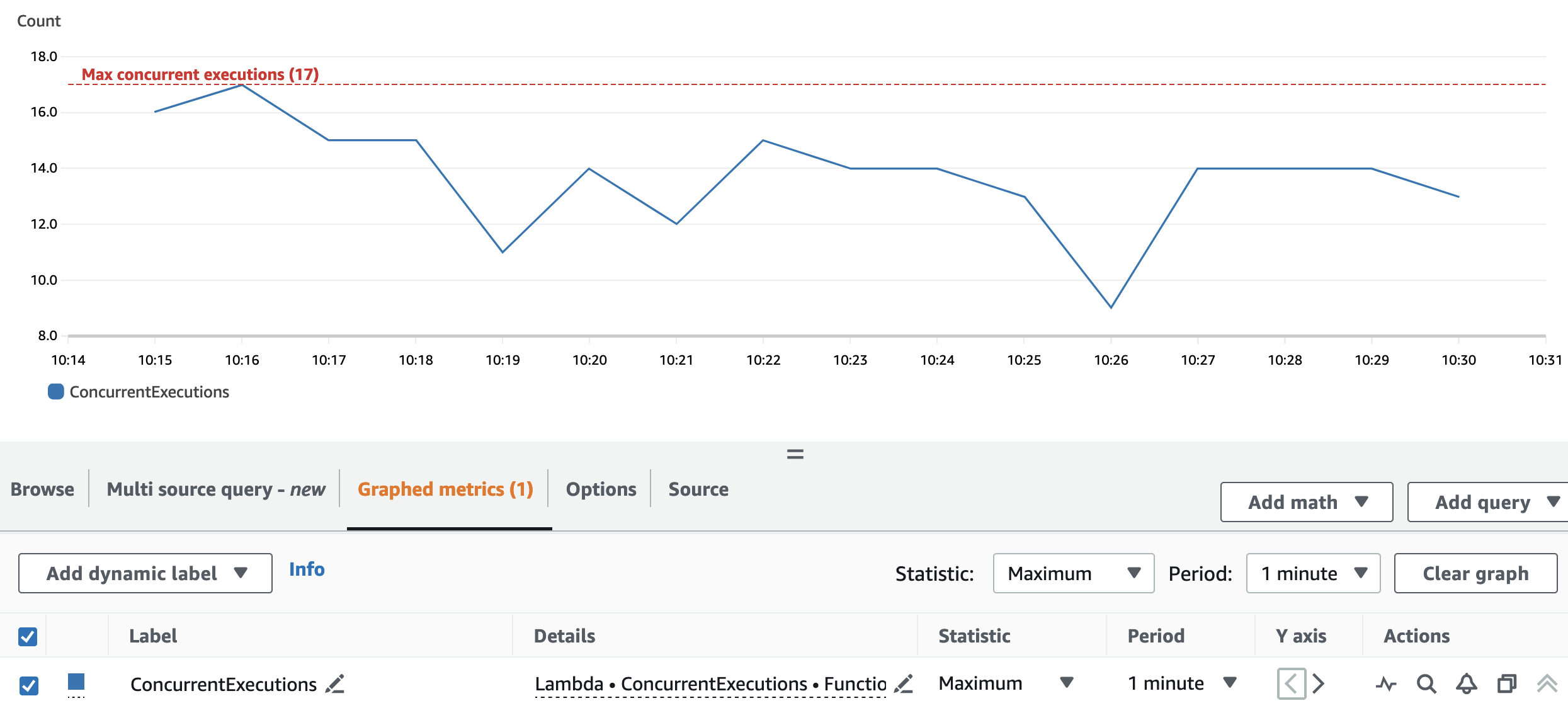
再パーティションとクラスター構成により、アプリケーションはすべての Spark RDD パーティションを並行して処理できるようになります。結果として、Lambda 関数の同時実行数は常に再パーティション数 (17) 以下になります。
スロットルを回避するには、並列処理できる Spark タスクの量が Lambda 関数の同時実行制限を超えていないことを確認してください。この側面については、バッチの使用例と同じ提案が有効です。
次のグラフはラムダを示しています。 Duration 統計を使用したメトリック AVG 青と MAX オレンジ色。
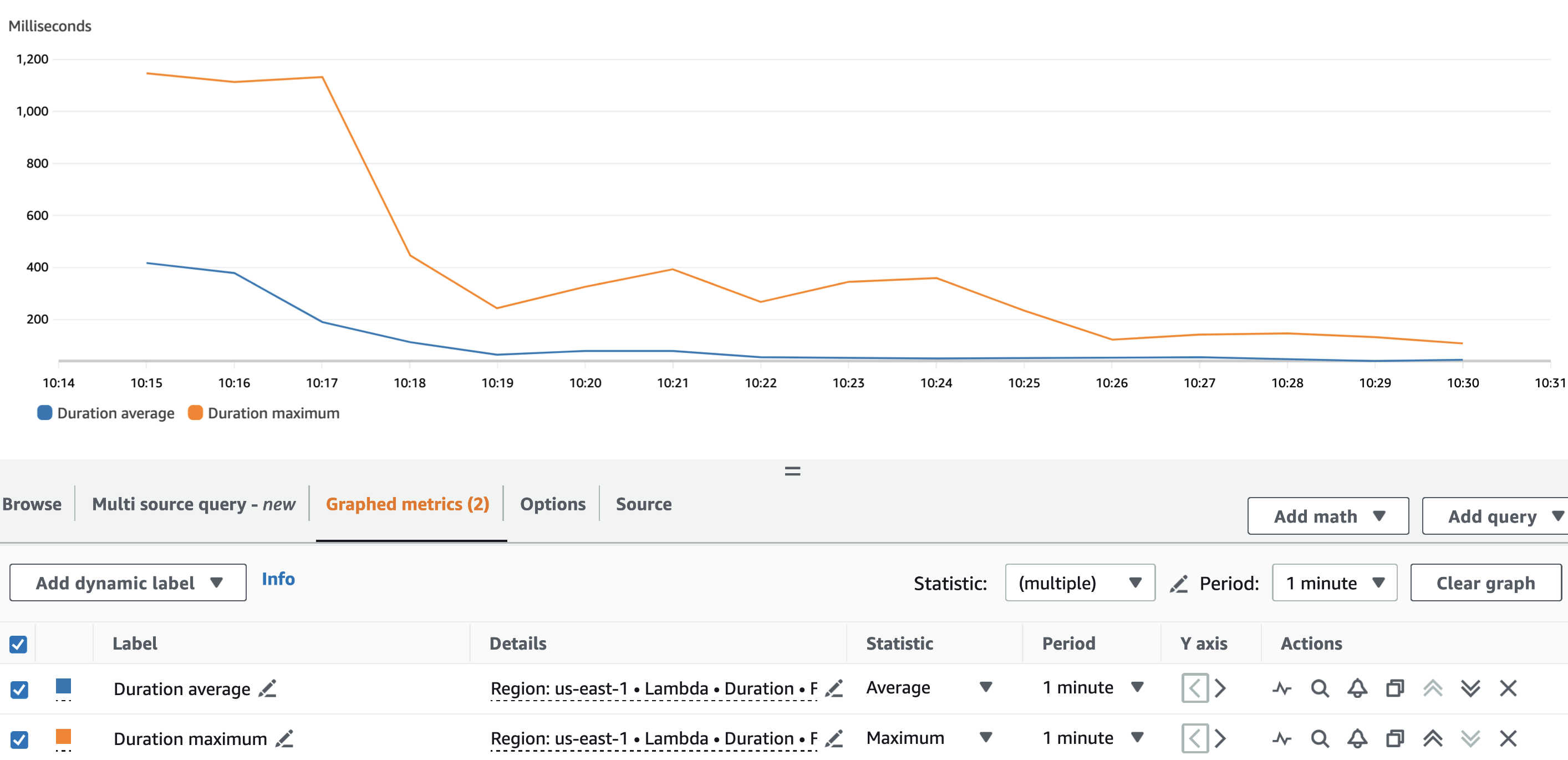
予想通り、Lambda 関数のコールド スタートを除けば、仮名化関数の平均継続時間は実行全体を通じてほぼ一定でした。これは、 batch_size コールごとに仮名化する VIN の数を定義する値は、900 に設定され、XNUMX で一定のままでした。
Kinesis データストリームの取り込み速度とストリーミングアプリケーションの消費速度は、仮名化サービスに対して行われる API 呼び出しの数、つまり関連コストに影響を与える要因です。
次のグラフはラムダを示しています。 Invocations 統計を使用したメトリック SUM オレンジ色、および Kinesis Data Streams GetRecords.Records 統計を使用したメトリック SUM 青色の。ストリームから取得される 1 分あたりのレコードの量と Lambda 関数の呼び出しの量の間には相関関係があり、それによってストリーミング実行のコストに影響を与えることがわかります。

に加え batch_intervalを使用して、ストリーミング アプリケーションの消費率を制御できます。 Spark ストリーミングのプロパティ ような spark.streaming.receiver.maxRate & spark.streaming.blockInterval。 詳細については、を参照してください。 Spark ストリーミング + Kinesis の統合 & Spark ストリーミング プログラミング ガイド.
まとめ
データプライバシー法の規則や規制を順守するのは難しい場合があります。 PII 属性の仮名化は、機密データを扱う際に考慮すべき多くの点の 1 つです。
この 2 部構成のシリーズでは、堅牢なデータ プラットフォームの構築を支援する機能を備えたさまざまな AWS サービスを使用して、仮名化サービスを構築および利用する方法を検討しました。で 第1部では、仮名化サービスの構築方法を示して基盤を構築しました。この投稿では、コスト効率とパフォーマンスの高い方法で仮名化サービスを利用するためのさまざまなパターンを紹介しました。をチェックしてください GitHubの 追加の消費パターンのリポジトリ。
著者について
 エドヴィン・ハルバシュー AWS プロフェッショナル サービスのシニア グローバル セキュリティ アーキテクトであり、サイバーセキュリティと自動化に情熱を注いでいます。 彼は、顧客がクラウドで安全で準拠したソリューションを構築するのを支援しています。 仕事以外では、旅行とスポーツが好きです。
エドヴィン・ハルバシュー AWS プロフェッショナル サービスのシニア グローバル セキュリティ アーキテクトであり、サイバーセキュリティと自動化に情熱を注いでいます。 彼は、顧客がクラウドで安全で準拠したソリューションを構築するのを支援しています。 仕事以外では、旅行とスポーツが好きです。
 ラフル・シャウリヤ AWS プロフェッショナル サービスのプリンシパル ビッグデータ アーキテクトです。彼は、AWS 上でデータ プラットフォームと分析アプリケーションを構築する顧客を支援し、緊密に連携しています。仕事以外では、ラーフルは愛犬バーニーと長い散歩をするのが大好きです。
ラフル・シャウリヤ AWS プロフェッショナル サービスのプリンシパル ビッグデータ アーキテクトです。彼は、AWS 上でデータ プラットフォームと分析アプリケーションを構築する顧客を支援し、緊密に連携しています。仕事以外では、ラーフルは愛犬バーニーと長い散歩をするのが大好きです。
 アンドレア・モンタナリ AWS プロフェッショナル サービスのシニア ビッグデータ アーキテクトです。彼は、AWS 上で大規模な分析ソリューションを構築する顧客とパートナーを積極的にサポートしています。
アンドレア・モンタナリ AWS プロフェッショナル サービスのシニア ビッグデータ アーキテクトです。彼は、AWS 上で大規模な分析ソリューションを構築する顧客とパートナーを積極的にサポートしています。
 マリア・グエラ AWS プロフェッショナル サービスのビッグデータ アーキテクトです。 Maria は、データ分析と機械工学のバックグラウンドを持っています。 彼女は、顧客がクラウドでデータ関連のワークロードを設計および開発するのを支援しています。
マリア・グエラ AWS プロフェッショナル サービスのビッグデータ アーキテクトです。 Maria は、データ分析と機械工学のバックグラウンドを持っています。 彼女は、顧客がクラウドでデータ関連のワークロードを設計および開発するのを支援しています。
 プシュプラジ・シン AWS プロフェッショナル サービスのシニア データ アーキテクトです。彼はデータと DevOps エンジニアリングに情熱を持っています。彼は、顧客が大規模なデータ駆動型アプリケーションを構築できるよう支援しています。
プシュプラジ・シン AWS プロフェッショナル サービスのシニア データ アーキテクトです。彼はデータと DevOps エンジニアリングに情熱を持っています。彼は、顧客が大規模なデータ駆動型アプリケーションを構築できるよう支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-a-pseudonymization-service-on-aws-to-protect-sensitive-data-part-2/

