データ エンジニアリングは、分析、レポート、機械学習に不可欠なデータを収集、変換、配信することで、膨大なデータ エコシステムにおいて極めて重要な役割を果たします。 意欲的なデータ エンジニアは、実践的な経験を積み、専門知識を披露するために現実世界のプロジェクトを求めることがよくあります。 この記事では、データ エンジニアリング プロジェクトのアイデアのトップ 20 をソース コードとともに紹介します。 初心者、中級レベルのエンジニア、または上級実務者であっても、これらのプロジェクトはデータ エンジニアリング スキルを磨く素晴らしい機会を提供します。
目次
初心者向けのデータ エンジニアリング プロジェクト
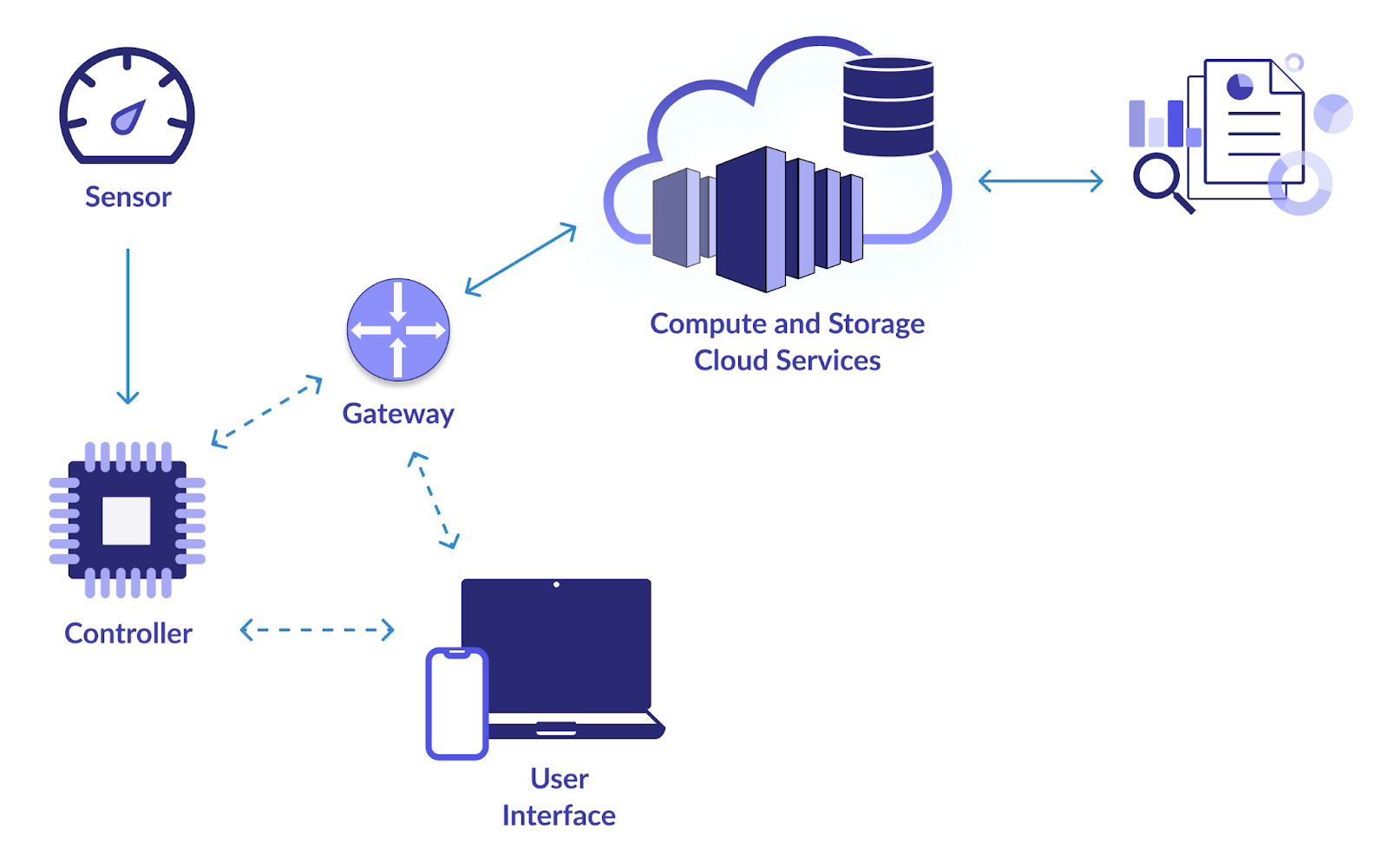
1. スマートIoTインフラ
DevOps Tools Engineer試験のObjective
このプロジェクトの主な目標は、IoT (モノのインターネット) デバイスからデータを収集および分析するための信頼できるデータ パイプラインを確立することです。 Web カメラ、温度センサー、モーション検知器、その他の IoT デバイスはすべて、大量のデータを生成します。 このデータを効果的に消費、保存、処理、分析するシステムを設計したいと考えています。 これにより、IoT データからの学習に基づいたリアルタイムの監視と意思決定が可能になります。
の解き方?
- Apache Kafka や MQTT などのテクノロジーを利用して、IoT デバイスから効率的にデータを取り込みます。 これらのテクノロジーは、高スループットのデータ ストリームをサポートします。
- Apache Cassandra や MongoDB などのスケーラブルなデータベースを採用して、受信した IoT データを保存します。 これらの NoSQL データベースは、量と種類の IoT データを処理できます。
- Apache Spark Streaming または Apache Flink を使用してリアルタイム データ処理を実装します。 これらのフレームワークを使用すると、データを到着時に分析して変換できるため、リアルタイムの監視に適しています。
- Grafana や Kibana などの視覚化ツールを使用して、IoT データに関する洞察を提供するダッシュボードを作成します。 リアルタイムの視覚化は、関係者が情報に基づいた意思決定を行うのに役立ちます。
2. 航空データ分析

DevOps Tools Engineer試験のObjective
連邦航空局 (FAA)、航空会社、空港などの多数のソースから航空データを収集、処理、分析するために、このプロジェクトではデータ パイプラインの開発を試みています。 航空データには、フライト、空港、天気、乗客の人口統計が含まれます。 あなたの目標は、このデータから有意義な洞察を抽出して、フライト スケジュールを改善し、安全対策を強化し、航空業界のさまざまな側面を最適化することです。
の解き方?
- Apache Nifi または AWS Kinesis は、さまざまなソースからのデータの取り込みに使用できます。
- 処理されたデータを Amazon Redshift や Google BigQuery などのデータ ウェアハウスに保存して、効率的なクエリと分析を実現します。
- Pandas や Matplotlib などのライブラリで Python を使用して、詳細な航空データを分析します。 これには、フライト遅延のパターンの特定、ルートの最適化、乗客の傾向の評価などが含まれます。
- Tableau や Power BI などのツールを使用すると、航空分野で関係者がデータに基づいた意思決定を行うのに役立つ有益な視覚化を作成できます。
3. 出荷・流通需要予測
DevOps Tools Engineer試験のObjective
このプロジェクトの目的は、出荷および流通データを処理する堅牢な ETL (抽出、変換、読み込み) パイプラインを作成することです。 履歴データを使用して、出荷と流通の観点から将来の製品需要を予測する需要予測システムを構築します。 これは、在庫管理を最適化し、運用コストを削減し、タイムリーな配送を確保するために非常に重要です。
の解き方?
- Apache NiFi または Talend を使用して ETL パイプラインを構築すると、さまざまなソースからデータを抽出し、変換して、適切なデータ ストレージ ソリューションにロードできます。
- データ変換タスクには Python や Apache Spark などのツールを利用します。 予測モデルに適したデータにするために、データのクリーニング、集計、および前処理が必要になる場合があります。
- ARIMA (AutoRegressive Integrated Moving Average) や Prophet などの予測モデルを実装して、需要を正確に予測します。
- クリーンアップおよび変換されたデータを PostgreSQL や MySQL などのデータベースに保存します。
このデータ エンジニアリング プロジェクトのソース コードを表示するには、ここをクリックしてください。
4. イベントデータの分析

DevOps Tools Engineer試験のObjective
会議、スポーツ イベント、コンサート、懇親会などのさまざまなイベントから情報を収集するデータ パイプラインを作成します。 リアルタイムのデータ処理、これらのイベントに関するソーシャル メディア投稿のセンチメント分析、トレンドと洞察をリアルタイムで示すビジュアライゼーションの作成はすべてプロジェクトの一部です。
の解き方?
- イベント データ ソースに応じて、ツイートの収集、イベント関連 Web サイトの Web スクレイピング、またはその他のデータ取り込み方法に Twitter API を使用する場合があります。
- Python で自然言語処理 (NLP) テクニックを使用して、ソーシャル メディアの投稿に対する感情分析を実行します。 NLTK や spaCy などのツールは価値があります。
- Apache Kafka や Apache Flink などのストリーミング テクノロジーを使用して、リアルタイムのデータ処理と分析を行います。
- Dash や Plotly などのフレームワークを使用してインタラクティブなダッシュボードやビジュアライゼーションを作成し、イベント関連の洞察を使いやすい形式で表示します。
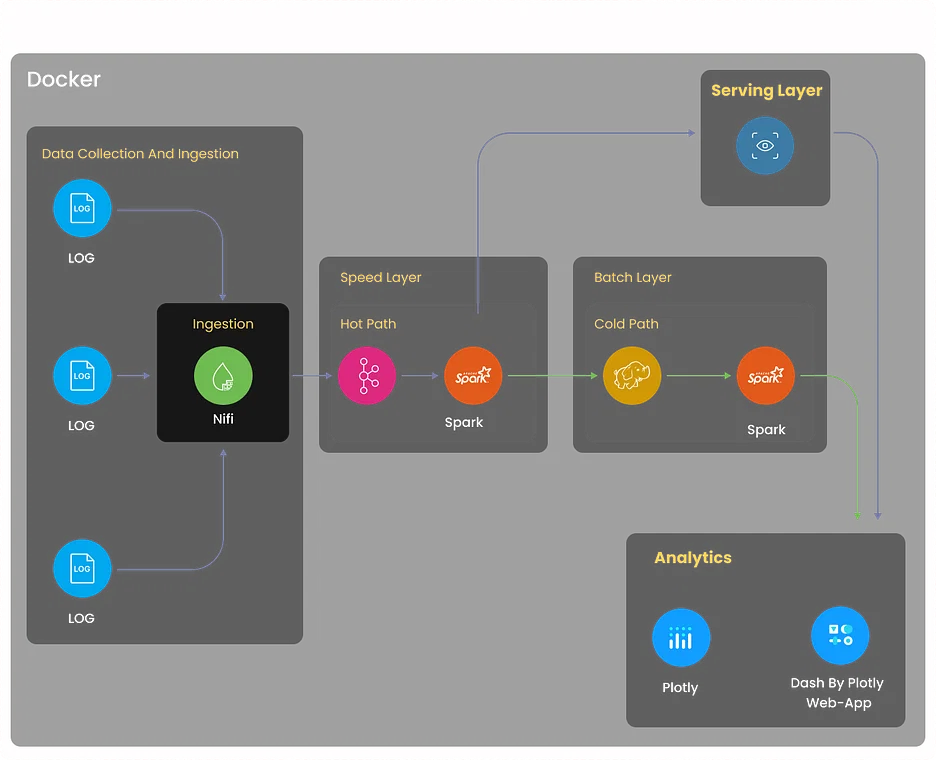
5. ログ分析プロジェクト
DevOps Tools Engineer試験のObjective
サーバー、アプリケーション、ネットワーク デバイスなどのさまざまなソースからログを収集する包括的なログ分析システムを構築します。 システムは、ログ データを一元管理し、異常を検出し、トラブルシューティングを容易にし、ログベースの洞察を通じてシステム パフォーマンスを最適化する必要があります。
の解き方?
- Logstash や Fluentd などのツールを使用してログ収集を実装します。 これらのツールは、さまざまなソースからのログを集約し、さらなる処理のために正規化することができます。
- 強力な分散検索および分析エンジンである Elasticsearch を利用して、ログ データを効率的に保存し、インデックスを付けます。
- Kibana を使用して、ユーザーがログ データをリアルタイムで監視できるダッシュボードと視覚化を作成します。
- Elasticsearch Watcher または Grafana Alerts を使用してアラート メカニズムを設定し、特定のログ パターンや異常が検出されたときに関連する関係者に通知します。
このデータ エンジニアリング プロジェクトを探索するにはここをクリックしてください
6. 推奨事項のための Movielens データ分析

DevOps Tools Engineer試験のObjective
- Movielens データセットを使用してレコメンデーション エンジンを設計および開発します。
- データを前処理してクリーンアップするための堅牢な ETL パイプラインを作成します。
- 協調フィルタリング アルゴリズムを実装して、パーソナライズされた映画の推奨をユーザーに提供します。
の解き方?
- Apache Spark または AWS Glue を活用して、ムービーとユーザー データを抽出し、適切な形式に変換して、データ ストレージ ソリューションにロードする ETL パイプラインを構築します。
- Scikit-learn や TensorFlow などのライブラリを使用して、ユーザーベースまたはアイテムベースの協調フィルタリングなどの協調フィルタリング手法を実装します。
- クリーンアップおよび変換されたデータを、Amazon S3 や Hadoop HDFS などのデータ ストレージ ソリューションに保存します。
- ユーザーが好みを入力できる Web ベースのアプリケーションを開発し (Flask や Django などを使用)、推奨エンジンがパーソナライズされた映画の推奨を提供します。
このデータ エンジニアリング プロジェクトを探索するには、ここをクリックしてください。
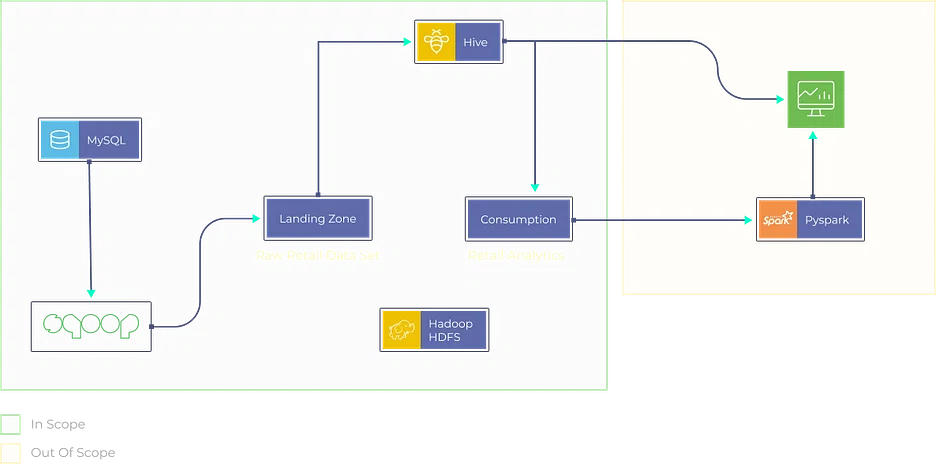
7. 小売分析プロジェクト
DevOps Tools Engineer試験のObjective
POS システム、在庫データベース、顧客とのやり取りなど、さまざまなソースからデータを取り込む小売分析プラットフォームを作成します。 販売傾向を分析し、在庫管理を最適化し、顧客向けにパーソナライズされた製品の推奨事項を生成します。
の解き方?
- Apache Beam や AWS Data Pipeline などのツールを使用して ETL プロセスを実装し、小売ソースからデータを抽出、変換、ロードします。
- XGBoost や Random Forest などの機械学習アルゴリズムを利用して、販売予測と在庫の最適化を行います。
- Snowflake や Azure Synapse Analytics などのデータ ウェアハウジング ソリューションにデータを保存して管理し、効率的なクエリを実行します。
- Tableau や Looker などのツールを使用してインタラクティブなダッシュボードを作成し、視覚的に魅力的でわかりやすい形式で小売分析の分析情報を表示します。
GitHub 上のデータ エンジニアリング プロジェクト
8. リアルタイムデータ分析
DevOps Tools Engineer試験のObjective
リアルタイム データ分析に焦点を当てたオープンソース プロジェクトに貢献します。 このプロジェクトは、プロジェクトのデータ処理速度、スケーラビリティ、リアルタイム視覚化機能を向上させる機会を提供します。 データ ストリーミング コンポーネントのパフォーマンスの強化、リソース使用量の最適化、またはリアルタイム分析のユースケースをサポートするための新機能の追加を任される場合があります。
の解き方?
解決方法は貢献するプロジェクトによって異なりますが、多くの場合、Apache Flink、Spark Streaming、Apache Storm などのテクノロジーが関係します。
このデータ エンジニアリング プロジェクトのソース コードを調べるには、ここをクリックしてください。
9. Azure Stream Services を使用したリアルタイム データ分析

DevOps Tools Engineer試験のObjective
Azure 上でリアルタイム データ処理プロジェクトに貢献または作成して、Azure Stream Analytics を探索します。 これには、洞察を得てリアルタイム データを視覚化するために、Azure Functions や Power BI などの Azure サービスを統合することが含まれる場合があります。 リアルタイム分析機能を強化し、プロジェクトをより使いやすくすることに集中できます。
の解き方?
- データソースや必要な洞察など、プロジェクトの目的と要件を明確に概説します。
- Azure Stream Analytics 環境を作成し、入力/出力を構成し、Azure Functions と Power BI を統合します。
- リアルタイム データを取り込み、SQL のようなクエリを使用して必要な変換を適用します。
- Azure Functions を使用して、リアルタイム データ処理のためのカスタム ロジックを実装します。
- リアルタイムのデータ視覚化のために Power BI を設定し、ユーザー フレンドリーなエクスペリエンスを確保します。
このデータ エンジニアリング プロジェクトのソース コードを調べるには、ここをクリックしてください。
10. Finnhub API と Kafka を使用したリアルタイム金融市場データ パイプライン
DevOps Tools Engineer試験のObjective
Finnhub API と Apache Kafka を使用して、リアルタイムの金融市場データを収集して処理するデータ パイプラインを構築します。 このプロジェクトには、株価の分析、ニュース データのセンチメント分析の実行、およびリアルタイムの市場動向の視覚化が含まれます。 貢献には、データ取り込みの最適化、データ分析の強化、視覚化コンポーネントの改善などが含まれます。
の解き方?
- リアルタイムの金融市場データの収集と処理、株価分析とセンチメント分析の実行など、プロジェクトの目標を明確に説明します。
- Apache Kafka と Finnhub API を使用してデータ パイプラインを作成し、リアルタイムの市場データを収集および処理します。
- パイプライン内のニュース データに対して株価を分析し、センチメント分析を実行します。
- リアルタイムの市場トレンドを視覚化し、データの取り込みと分析の最適化を検討します。
- プロジェクト全体を通じて、データ処理を最適化し、分析を改善し、視覚化コンポーネントを強化する機会を検討します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
11. リアルタイム音楽アプリケーションのデータ処理パイプライン
DevOps Tools Engineer試験のObjective
ユーザー行動データのリアルタイムでの処理と分析に重点を置いた、リアルタイム音楽ストリーミング データ プロジェクトで協力します。 ユーザーの好みを調査し、人気を追跡し、音楽推奨システムを強化します。 貢献には、データ処理効率の向上、高度な推奨アルゴリズムの実装、またはリアルタイム ダッシュボードの開発が含まれる場合があります。
の解き方?
- リアルタイムのユーザー行動分析と音楽レコメンデーションの強化に重点を置いて、プロジェクトの目標を明確に定義します。
- リアルタイムのデータ処理で協力して、ユーザーの好みを調査し、人気を追跡し、推奨システムを改良します。
- データ処理パイプライン内の効率向上を特定して実装します。
- 高度な推奨アルゴリズムを開発および統合して、システムを強化します。
- ユーザー行動データを監視および視覚化するためのリアルタイム ダッシュボードを作成し、継続的な機能強化を検討します。
高度なデータ エンジニアリング プロジェクトの再開
12 ウェブサイトモニタリング

DevOps Tools Engineer試験のObjective
パフォーマンス、稼働時間、ユーザー エクスペリエンスを追跡する包括的な Web サイト監視システムを開発します。 このプロジェクトには、Web スクレイピングに Selenium などのツールを利用して Web サイトからデータを収集し、パフォーマンスの問題が検出されたときにリアルタイムで通知するアラート メカニズムを作成することが含まれます。
の解き方?
- プロジェクトの目標を定義します。これには、パフォーマンスと稼働時間を追跡するための Web サイト監視システムの構築や、ユーザー エクスペリエンスの向上が含まれます。
- Web スクレイピングに Selenium を利用して、ターゲット Web サイトからデータを収集します。
- リアルタイムのアラート メカニズムを実装して、パフォーマンスの問題やダウンタイムが検出されたときに通知します。
- Web サイトのパフォーマンス、稼働時間、ユーザー エクスペリエンスを追跡するための包括的なシステムを作成します。
- 監視システムの継続的なメンテナンスと最適化を計画して、長期にわたる有効性を確保します。
このデータ エンジニアリング プロジェクトのソース コードを調べるには、ここをクリックしてください。
13. ビットコインマイニング

DevOps Tools Engineer試験のObjective
ビットコイン マイニング データ パイプラインを作成して、暗号通貨の世界に飛び込みます。 トランザクション パターンを分析し、ブロックチェーン ネットワークを調査し、ビットコイン エコシステムについての洞察を得ることができます。 このプロジェクトでは、ブロックチェーン API からのデータ収集、分析、視覚化が必要になります。
の解き方?
- トランザクション分析とブロックチェーン探索のためのビットコイン マイニング データ パイプラインの作成に重点を置き、プロジェクトの目標を定義します。
- マイニング関連データのブロックチェーン API からのデータ収集メカニズムを実装します。
- ブロックチェーン分析を詳しく調べてトランザクション パターンを調査し、ビットコイン エコシステムについての洞察を得ることができます。
- ビットコイン ネットワークの洞察を効果的に表現するデータ視覚化コンポーネントを開発します。
- ビットコイン マイニング活動の全体像を把握するためのデータ収集、分析、視覚化を含む包括的なデータ パイプラインを作成します。
このデータ エンジニアリング プロジェクトのソース コードを調べるには、ここをクリックしてください。
14. クラウド機能を探索する GCP プロジェクト

DevOps Tools Engineer試験のObjective
Cloud Functions、BigQuery、Dataflow などの GCP サービスを活用するデータ エンジニアリング プロジェクトを設計して実装することで、Google Cloud Platform (GCP) を探索します。 このプロジェクトには、リソース使用量の最適化とデータ エンジニアリング ワークフローの改善に重点を置いた、データ処理、変換、視覚化タスクが含まれる場合があります。
の解き方?
- Cloud Functions、BigQuery、Dataflow などのデータ エンジニアリングに GCP サービスを使用することを強調し、プロジェクトの範囲を明確に定義します。
- GCP サービスの統合を設計して実装し、Cloud Functions、BigQuery、Dataflow を効率的に利用できるようにします。
- 包括的な目標に合わせて、プロジェクトの一部としてデータ処理および変換タスクを実行します。
- 効率を高めるために、GCP 環境内でのリソース使用の最適化に重点を置きます。
- プロジェクトのライフサイクル全体を通じてデータ エンジニアリング ワークフローを改善する機会を模索し、合理化された効果的なプロセスを目指します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
15. Reddit データの視覚化
DevOps Tools Engineer試験のObjective
最も人気のあるソーシャル メディア プラットフォームの XNUMX つである Reddit からデータを収集して分析します。 インタラクティブなビジュアライゼーションを作成し、プラットフォーム上のユーザーの行動、トレンドのトピック、センチメント分析についての洞察を得ることができます。 このプロジェクトには、Web スクレイピング、データ分析、および創造的なデータ視覚化技術が必要です。
の解き方?
- ユーザーの行動、トレンドのトピック、センチメント分析についての洞察を得るために、Reddit からのデータ収集と分析に重点を置き、プロジェクトの目標を定義します。
- Web スクレイピング技術を実装して Reddit のプラットフォームからデータを収集します。
- データ分析を詳しく調べて、ユーザーの行動を調査し、トレンドのトピックを特定し、感情分析を実行します。
- インタラクティブなビジュアライゼーションを作成して、Reddit データから得られた洞察を効果的に伝えます。
- 革新的なデータ視覚化技術を採用して、プロジェクト全体を通じて結果のプレゼンテーションを強化します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
Azure データ エンジニアリング プロジェクト
16. Yelp データ分析

DevOps Tools Engineer試験のObjective
このプロジェクトの目標は、Yelp データを包括的に分析することです。 Yelp データを抽出、変換し、適切なストレージ ソリューションにロードするためのデータ パイプラインを構築します。 分析には以下が含まれます。
- 人気のあるビジネスを特定する。
- ユーザーのレビュー感情を分析します。
- サービスを改善するための洞察を地元企業に提供します。
の解き方?
- Web スクレイピング技術または Yelp API を使用してデータを抽出します。
- Python または Azure Data Factory を使用してデータをクリーンアップし、前処理します。
- Azure Blob Storage または Azure SQL Data Warehouse にデータを保存します。
- Pandas や Matplotlib などの Python ライブラリを使用してデータ分析を実行します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
17.データガバナンス
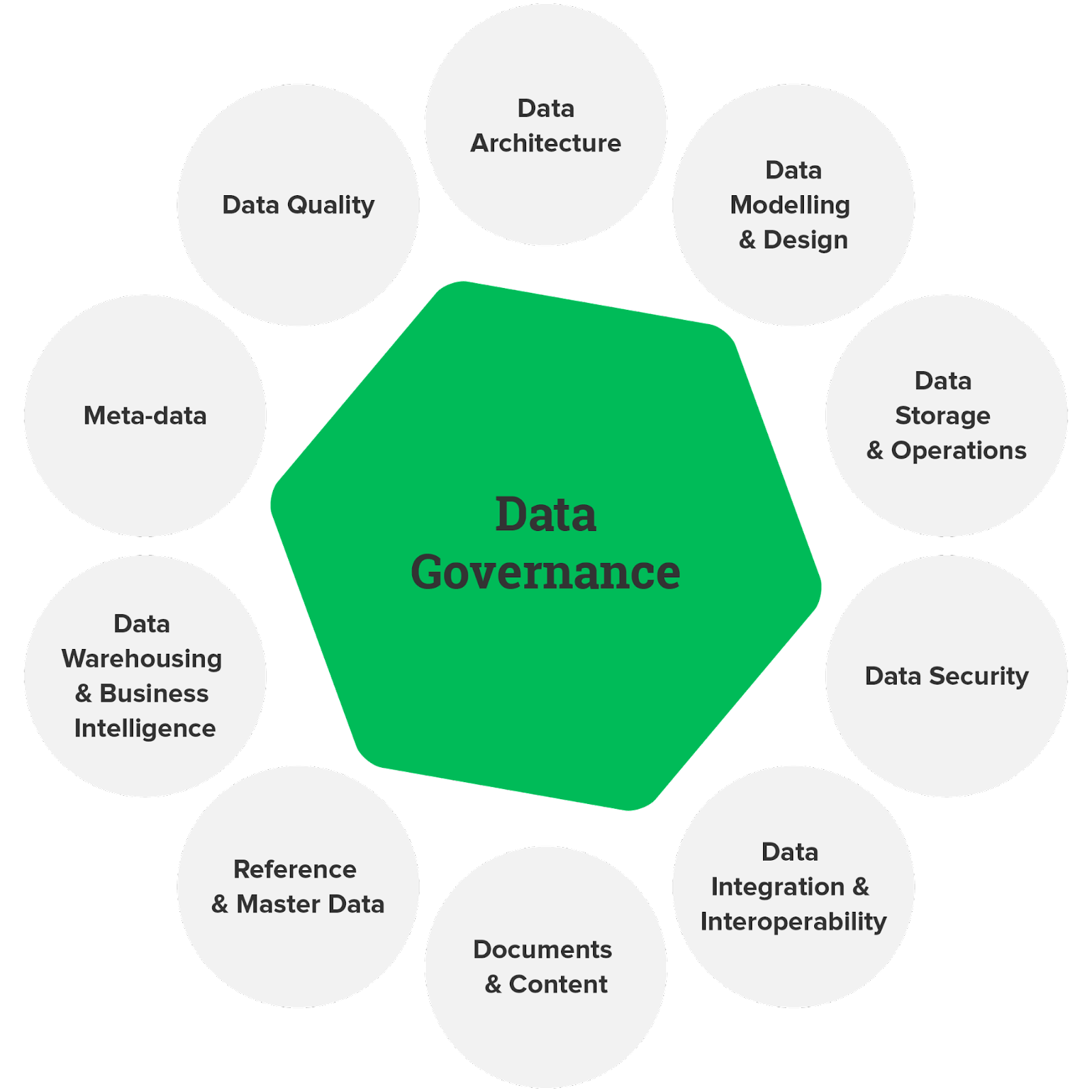
DevOps Tools Engineer試験のObjective
データガバナンスは、データの品質、コンプライアンス、セキュリティを確保するために重要です。 このプロジェクトでは、Azure サービスを使用してデータ ガバナンス フレームワークを設計および実装します。 これには、データが規制に従って責任を持って使用されることを保証するための、データ ポリシーの定義、データ カタログの作成、およびデータ アクセス制御の設定が含まれる場合があります。
の解き方?
- Azure Purview を利用して、データ資産を文書化して分類するカタログを作成します。
- Azure Policy と Azure Blueprints を使用してデータ ポリシーを実装します。
- ロールベースのアクセス制御 (RBAC) と Azure Active Directory の統合を設定して、データ アクセスを管理します。
このデータ エンジニアリング プロジェクトのソース コードを調べるには、ここをクリックしてください。
18. リアルタイムのデータ取り込み

DevOps Tools Engineer試験のObjective
Azure Data Factory、Azure Stream Analytics、Azure Event Hubs などのサービスを使用して、Azure 上でリアルタイム データ インジェスト パイプラインを設計します。 目標は、さまざまなソースからデータを取り込んでリアルタイムで処理し、意思決定のための洞察を即座に提供することです。
の解き方?
- データの取り込みには Azure Event Hubs を使用します。
- Azure Stream Analytics を使用してリアルタイム データ処理を実装します。
- 処理されたデータを Azure Data Lake Storage または Azure SQL Database に保存します。
- Power BI または Azure ダッシュボードを使用して、リアルタイムの分析情報を視覚化します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
AWS データエンジニアリングプロジェクトのアイデア
19.ETLパイプライン

DevOps Tools Engineer試験のObjective
AWS 上にエンドツーエンドの ETL (抽出、変換、ロード) パイプラインを構築します。 パイプラインは、さまざまなソースからデータを抽出し、変換を実行し、処理されたデータをデータ ウェアハウスまたはレイクにロードする必要があります。 このプロジェクトは、データ エンジニアリングの中心原則を理解するのに最適です。
の解き方?
- データ抽出には AWS Glue または AWS Data Pipeline を使用します。
- Amazon EMR または AWS Glue で Apache Spark を使用して変換を実装します。
- 処理されたデータを Amazon S3 または Amazon Redshift に保存します。
- オーケストレーション用に AWS Step Functions または AWS Lambda を使用して自動化を設定します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
20. ETL および ELT の操作

DevOps Tools Engineer試験のObjective
AWS での ETL (抽出、変換、ロード) および ELT (抽出、ロード、変換) データ統合アプローチを検討します。 さまざまなシナリオにおける強みと弱みを比較します。 このプロジェクトでは、特定のデータ エンジニアリング要件に基づいて、各アプローチをいつ使用するかについての洞察を提供します。
の解き方?
- データの変換と読み込みに AWS Glue を使用して ETL プロセスを実装します。 ELT 操作には AWS Data Pipeline または AWS DMS (Database Migration Service) を採用します。
- アプローチに応じて、Amazon S3、Amazon Redshift、または Amazon Aurora にデータを保存します。
- AWS Step Functions または AWS Lambda 関数を使用してデータ ワークフローを自動化します。
このプロジェクトのソース コードを調べるには、ここをクリックしてください。
まとめ
データ エンジニアリング プロジェクトは、データの世界に飛び込み、その力を活用し、有意義な洞察を引き出す素晴らしい機会を提供します。 リアルタイム ストリーミング データ用のパイプラインを構築している場合でも、膨大なデータセットを処理するためのソリューションを作成している場合でも、これらのプロジェクトはスキルを磨き、刺激的なキャリアの可能性への扉を開きます。
しかし、ここで立ち止まらないでください。 データ エンジニアリングの取り組みを次のレベルに引き上げたいと考えている場合は、 BlackBelt Plus プログラム。 BB+ を使用すると、専門家のガイダンス、実践的な経験、サポート的なコミュニティにアクセスでき、データ エンジニアリング スキルを新たな高みに押し上げることができます。 今すぐ登録!
よくある質問
A. データ エンジニアリングには、データ パイプラインの設計、構築、保守が含まれます。 例: 分析のために顧客データを収集、クリーニング、保存するためのパイプラインを作成します。
A. データ エンジニアリングのベスト プラクティスには、堅牢なデータ品質チェック、効率的な ETL プロセス、文書化、将来のデータ増加に備えたスケーラビリティが含まれます。
A. データ エンジニアは、データ パイプラインの開発、データの正確性の確保、データ サイエンティストとの連携、データ関連の問題のトラブルシューティングなどのタスクに取り組みます。
A. 履歴書でデータ エンジニアリング プロジェクトを紹介するには、主要なプロジェクトを強調し、使用されているテクノロジに言及し、データ処理または分析の結果への影響を定量化します。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/09/data-engineering-project/

