In today’s data-driven world, organizations are continually confronted with the task of managing extensive volumes of data securely and efficiently. Whether it’s customer information, sales records, or sensor data from Internet of Things (IoT) devices, the importance of handling and storing data at scale with ease of use is paramount.
A common use case that we see amongst customers is to search and visualize data. In this post, we show how to ingest CSV files from Amazon Simple Storage Service (Amazon S3) into Amazon OpenSearch Service using the Amazon OpenSearch Ingestion feature and visualize the ingested data using OpenSearch Dashboards.
OpenSearch Service is a fully managed, open source search and analytics engine that helps you with ingesting, searching, and analyzing large datasets quickly and efficiently. OpenSearch Service enables you to quickly deploy, operate, and scale OpenSearch clusters. It continues to be a tool of choice for a wide variety of use cases such as log analytics, real-time application monitoring, clickstream analysis, website search, and more.
OpenSearch Dashboards is a visualization and exploration tool that allows you to create, manage, and interact with visuals, dashboards, and reports based on the data indexed in your OpenSearch cluster.
Visualize data in OpenSearch Dashboards
Visualizing the data in OpenSearch Dashboards involves the following steps:
- Ingest data – Before you can visualize data, you need to ingest the data into an OpenSearch Service index in an OpenSearch Service domain or Amazon OpenSearch Serverless collection and define the mapping for the index. You can specify the data types of fields and how they should be analyzed; if nothing is specified, OpenSearch Service automatically detects the data type of each field and creates a dynamic mapping for your index by default.
- Create an index pattern – After you index the data into your OpenSearch Service domain, you need to create an index pattern that enables OpenSearch Dashboards to read the data stored in the domain. This pattern can be based on index names, aliases, or wildcard expressions. You can configure the index pattern by specifying the timestamp field (if applicable) and other settings that are relevant to your data.
- Create visualizations – You can create visuals that represent your data in meaningful ways. Common types of visuals include line charts, bar charts, pie charts, maps, and tables. You can also create more complex visualizations like heatmaps and geospatial representations.
Ingest data with OpenSearch Ingestion
Ingesting data into OpenSearch Service can be challenging because it involves a number of steps, including collecting, converting, mapping, and loading data from different data sources into your OpenSearch Service index. Traditionally, this data was ingested using integrations with Amazon Data Firehose, Logstash, Data Prepper, Amazon CloudWatch, or AWS IoT.
The OpenSearch Ingestion feature of OpenSearch Service introduced in April 2023 makes ingesting and processing petabyte-scale data into OpenSearch Service straightforward. OpenSearch Ingestion is a fully managed, serverless data collector that allows you to ingest, filter, enrich, and route data to an OpenSearch Service domain or OpenSearch Serverless collection. You configure your data producers to send data to OpenSearch Ingestion, which automatically delivers the data to the domain or collection that you specify. You can configure OpenSearch Ingestion to transform your data before delivering it.
OpenSearch Ingestion scales automatically to meet the requirements of your most demanding workloads, helping you focus on your business logic while abstracting away the complexity of managing complex data pipelines. It’s powered by Data Prepper, an open source streaming Extract, Transform, Load (ETL) tool that can filter, enrich, transform, normalize, and aggregate data for downstream analysis and visualization.
OpenSearch Ingestion uses pipelines as a mechanism that consists of three major components:
- Source – The input component of a pipeline. It defines the mechanism through which a pipeline consumes records.
- Processors – The intermediate processing units that can filter, transform, and enrich records into a desired format before publishing them to the sink. The processor is an optional component of a pipeline.
- Sink – The output component of a pipeline. It defines one or more destinations to which a pipeline publishes records. A sink can also be another pipeline, which allows you to chain multiple pipelines together.
You can process data files written in S3 buckets in two ways: by processing the files written to Amazon S3 in near real time using Amazon Simple Queue Service (Amazon SQS), or with the scheduled scans approach, in which you process the data files in batches using one-time or recurring scheduled scan configurations.
In the following section, we provide an overview of the solution and guide you through the steps to ingest CSV files from Amazon S3 into OpenSearch Service using the S3-SQS approach in OpenSearch Ingestion. Additionally, we demonstrate how to visualize the ingested data using OpenSearch Dashboards.
Solution overview
The following diagram outlines the workflow of ingesting CSV files from Amazon S3 into OpenSearch Service.
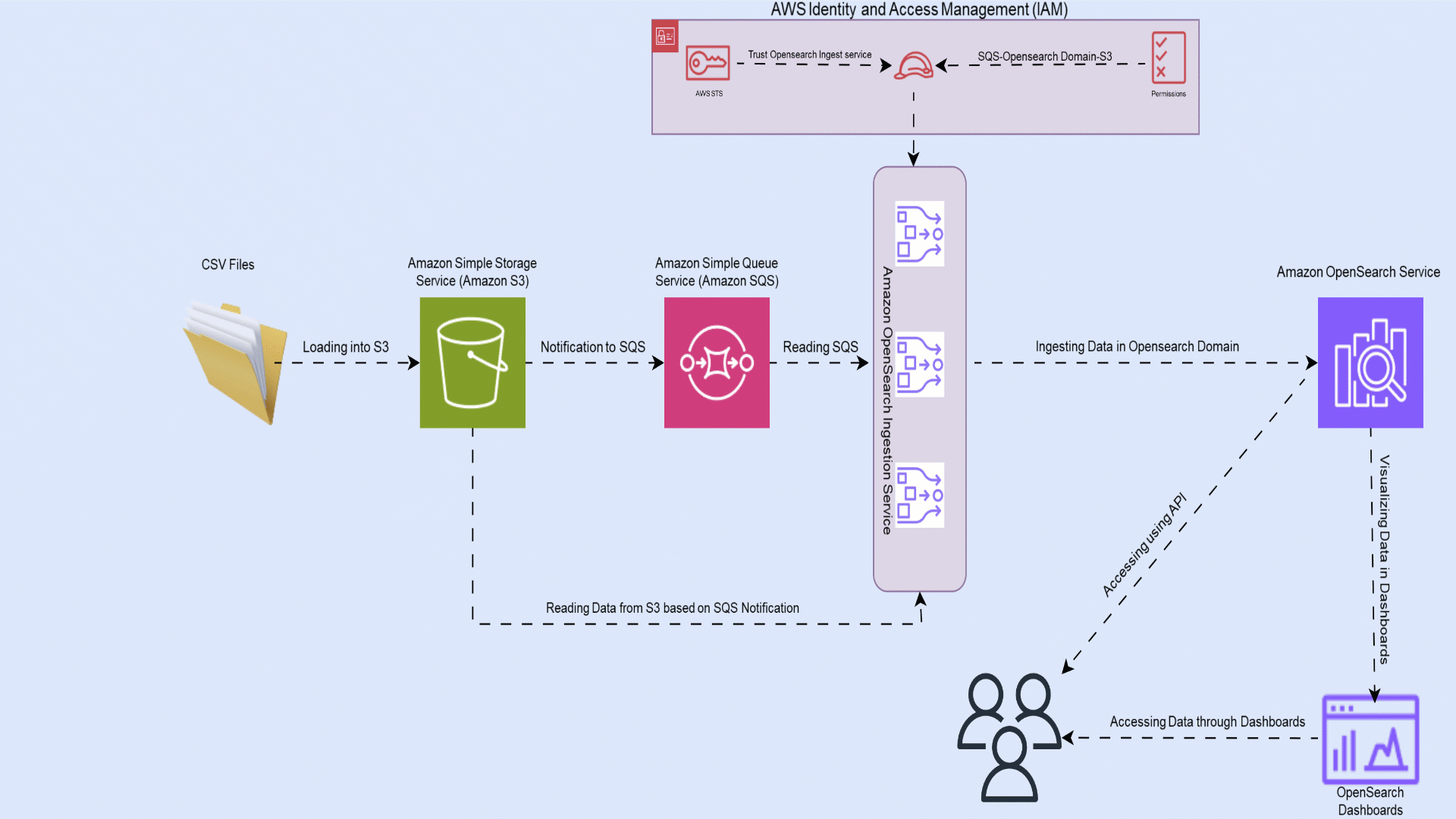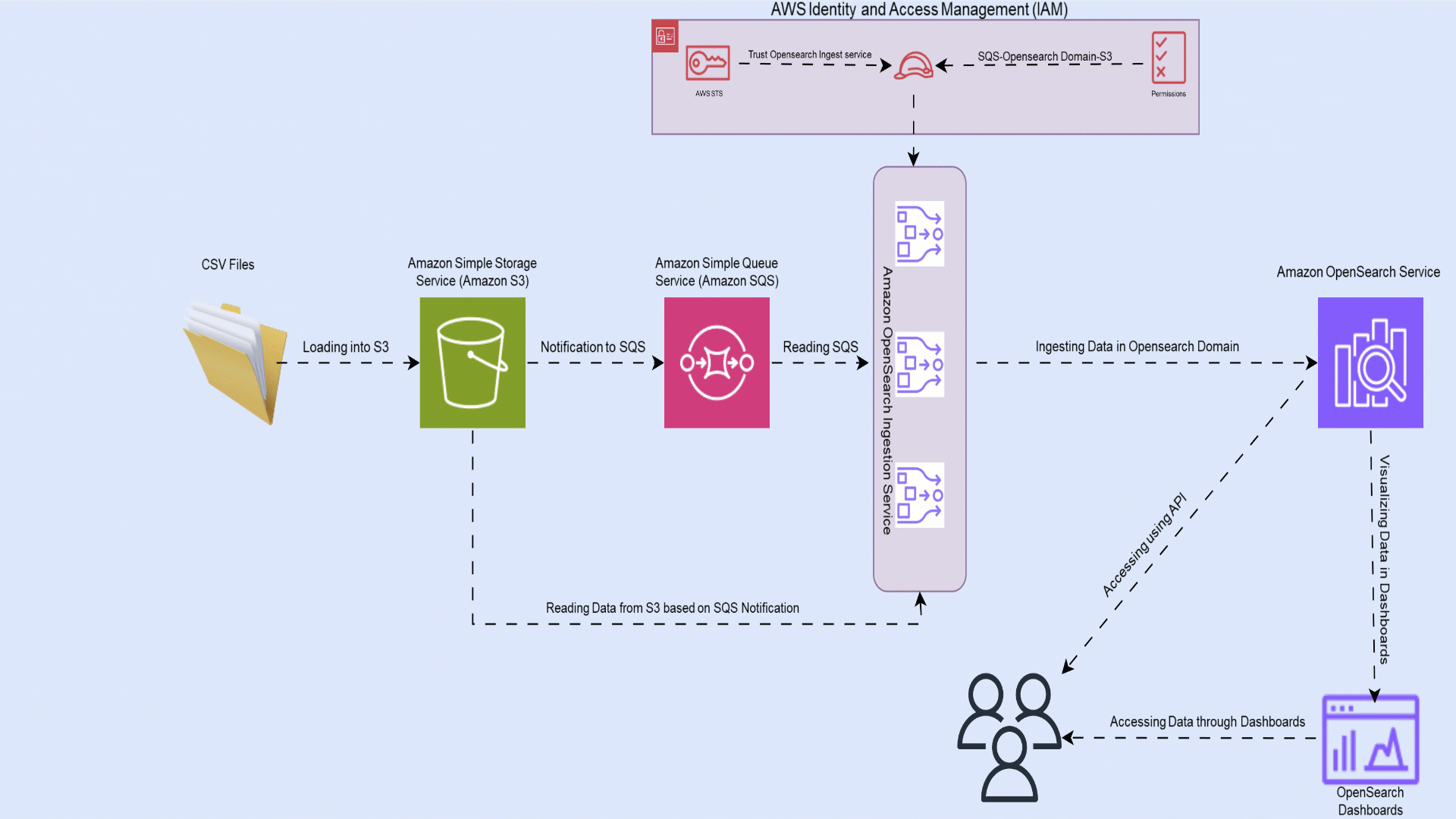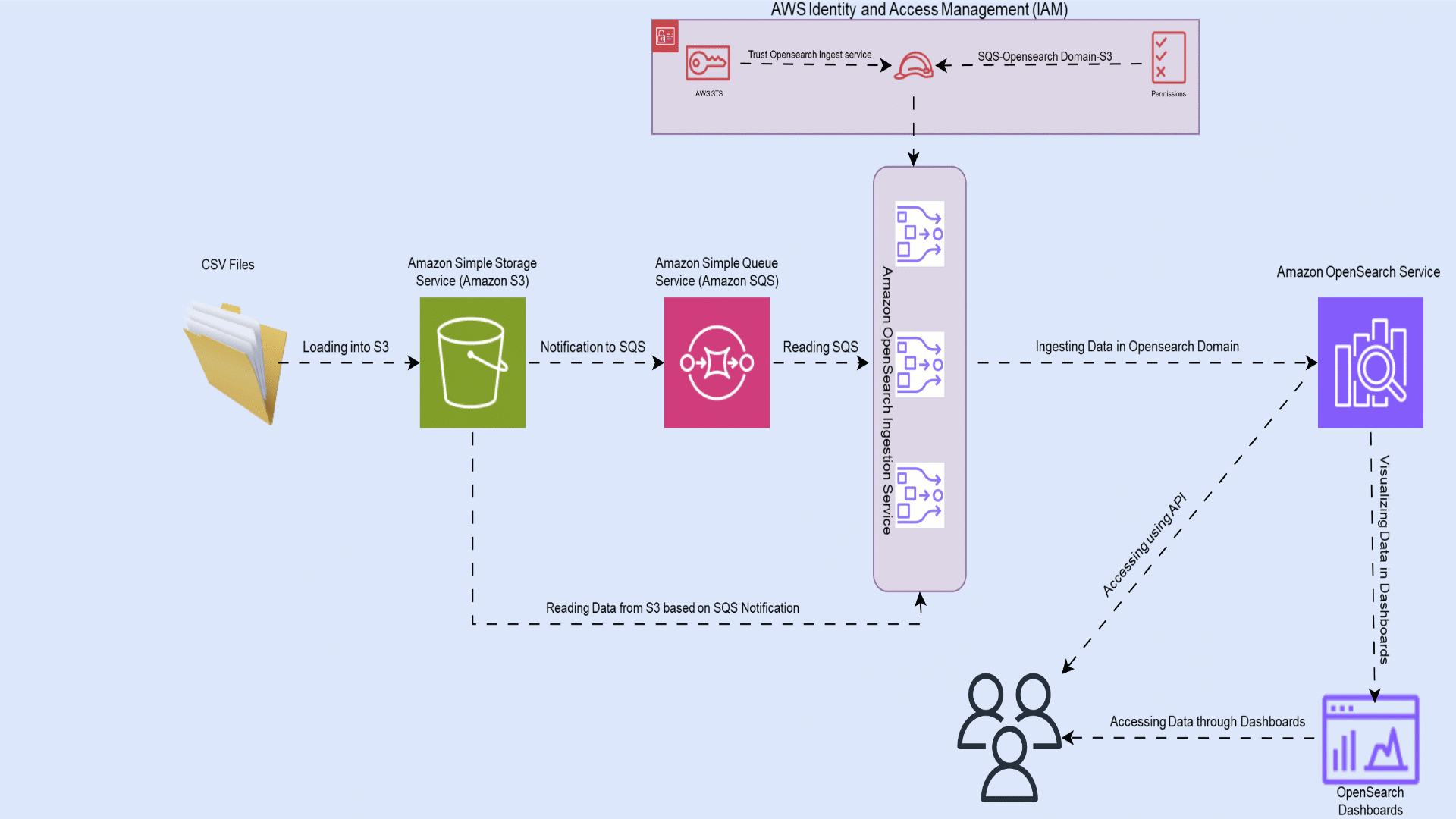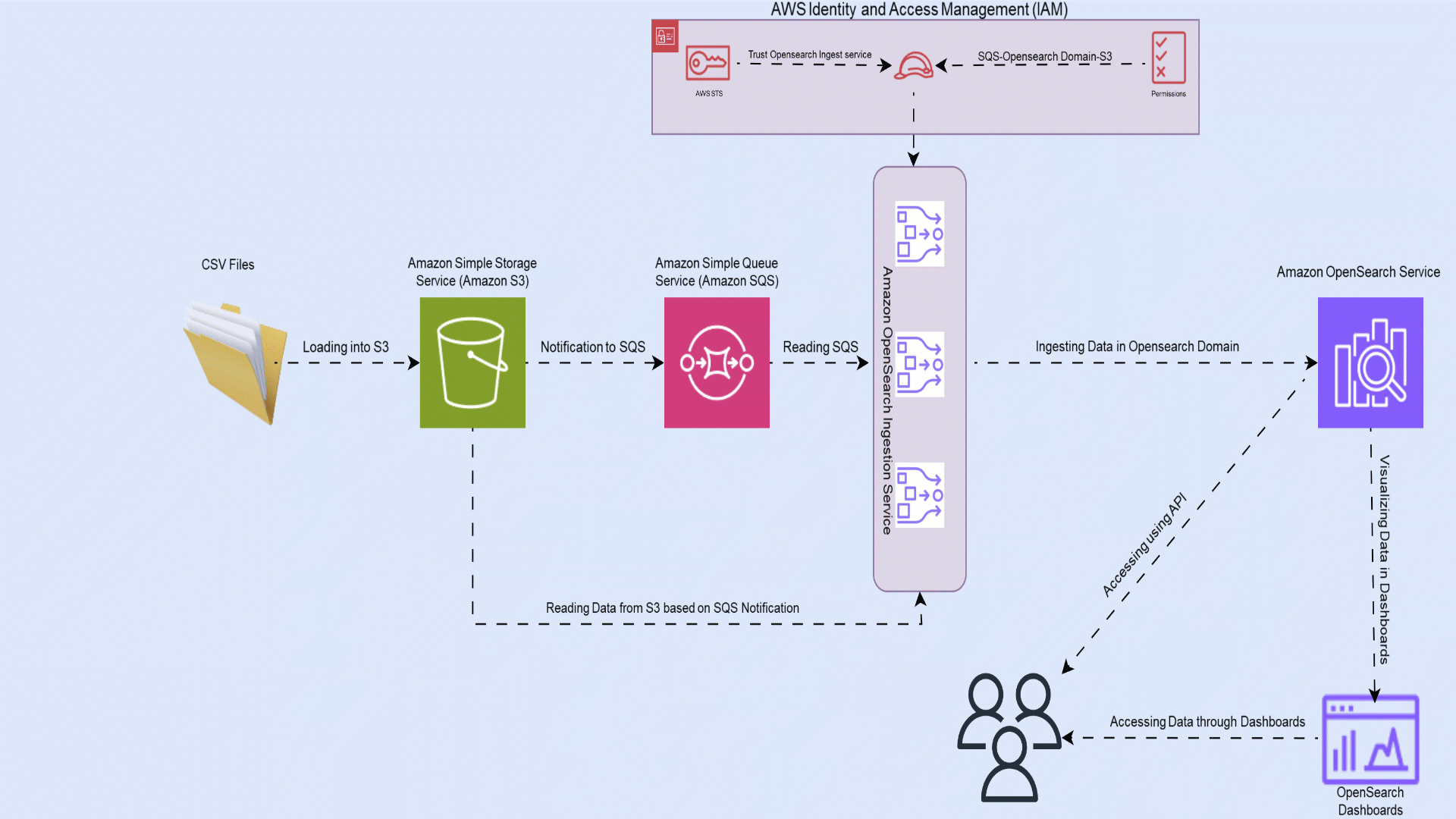
The workflow comprises the following steps:
- The user uploads CSV files into Amazon S3 using techniques such as direct upload on the AWS Management Console or AWS Command Line Interface (AWS CLI), or through the Amazon S3 SDK.
- Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp.
- The OpenSearch Ingestion pipeline receives the message from Amazon SQS, loads the files from Amazon S3, and parses the CSV data from the message into columns. It then creates an index in the OpenSearch Service domain and adds the data to the index.
- Lastly, you create an index pattern and visualize the ingested data using OpenSearch Dashboards.
OpenSearch Ingestion provides a serverless ingestion framework to effortlessly ingest data into OpenSearch Service with just a few clicks.
Prerequisites
Make sure you meet the following prerequisites:
Create an SQS queue
Amazon SQS offers a secure, durable, and available hosted queue that lets you integrate and decouple distributed software systems and components. Create a standard SQS queue and provide a descriptive name for the queue, then update the access policy by navigating to the Amazon SQS console, opening the details of your queue, and editing the policy on the Advanced tab.
The following is a sample access policy you could use for reference to update the access policy:
SQS FIFO (First-In-First-Out) queues aren’t supported as an Amazon S3 event notification destination. To send a notification for an Amazon S3 event to an SQS FIFO queue, you can use Amazon EventBridge.
Create an S3 bucket and enable Amazon S3 event notification
Create an S3 bucket that will be the source for CSV files and enable Amazon S3 notifications. The Amazon S3 notification invokes an action in response to a specific event in the bucket. In this workflow, whenever there in an event of type S3:ObjectCreated:*, the event sends an Amazon S3 notification to the SQS queue created in the previous step. Refer to Walkthrough: Configuring a bucket for notifications (SNS topic or SQS queue) to configure the Amazon S3 notification in your S3 bucket.
Create an IAM policy for the OpenSearch Ingest pipeline
Create an AWS Identity and Access Management (IAM) policy for the OpenSearch pipeline with the following permissions:
- Read and delete rights on Amazon SQS
GetObjectrights on Amazon S3- Describe domain and
ESHttprights on your OpenSearch Service domain
The following is an example policy:
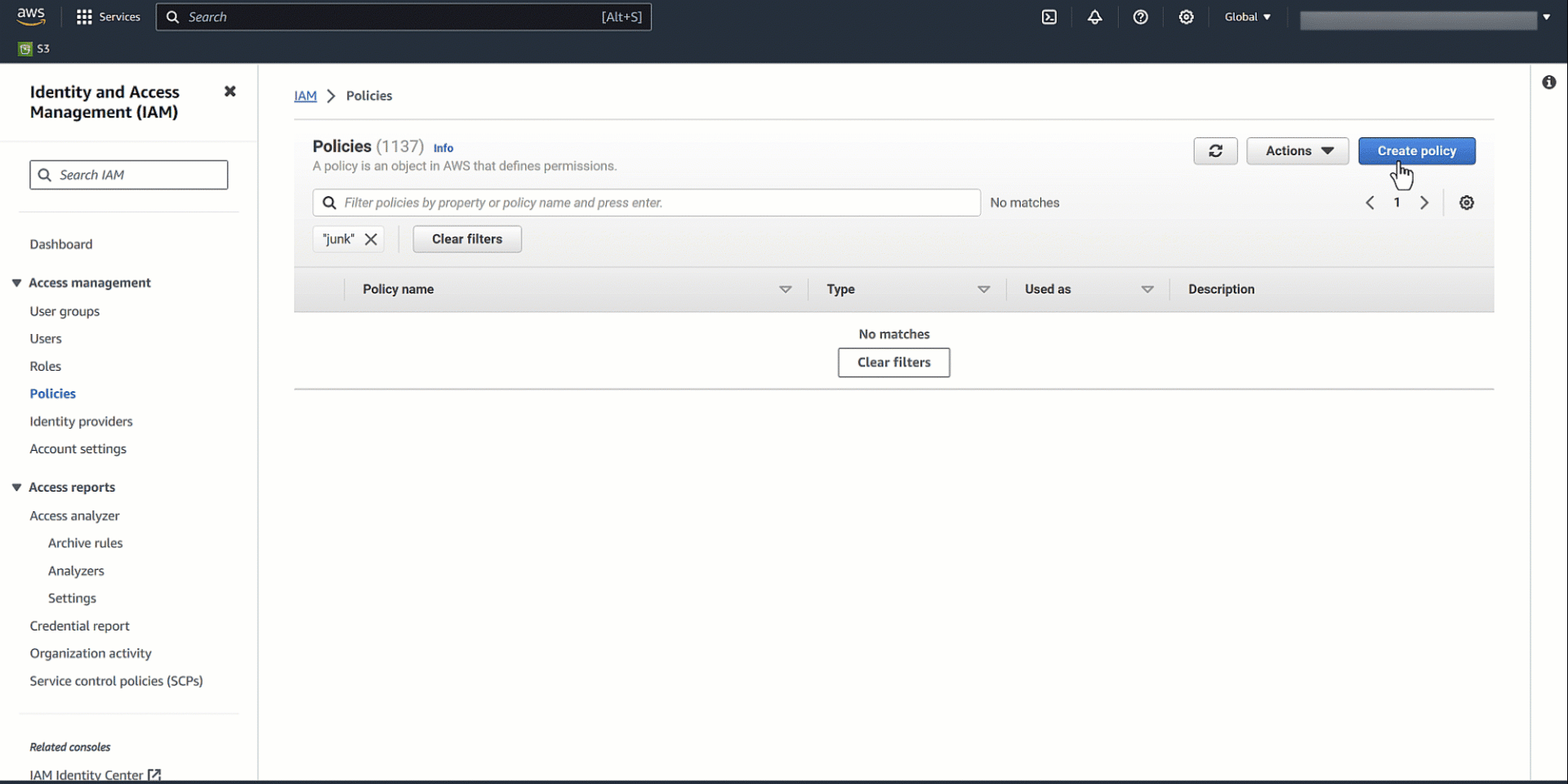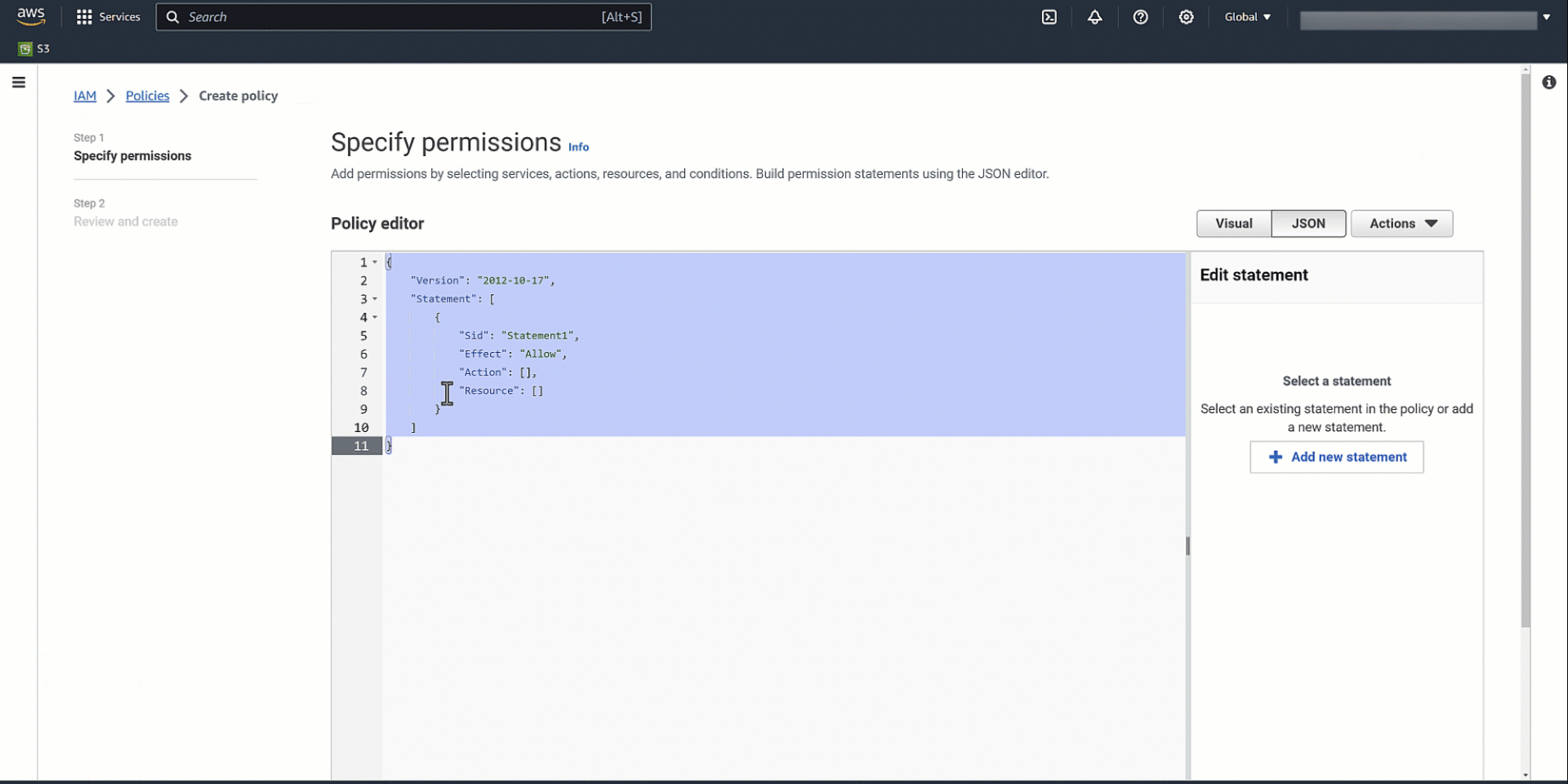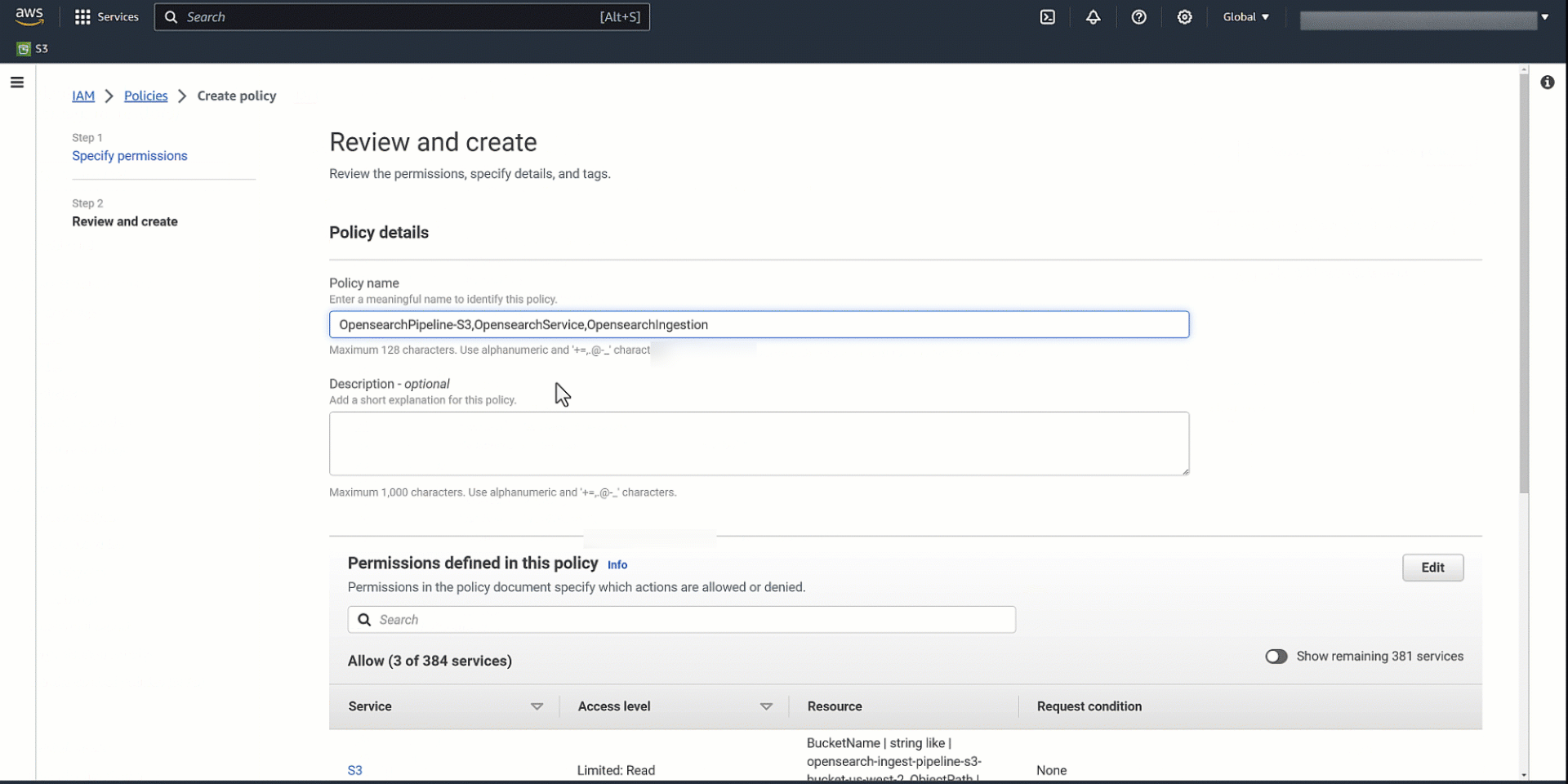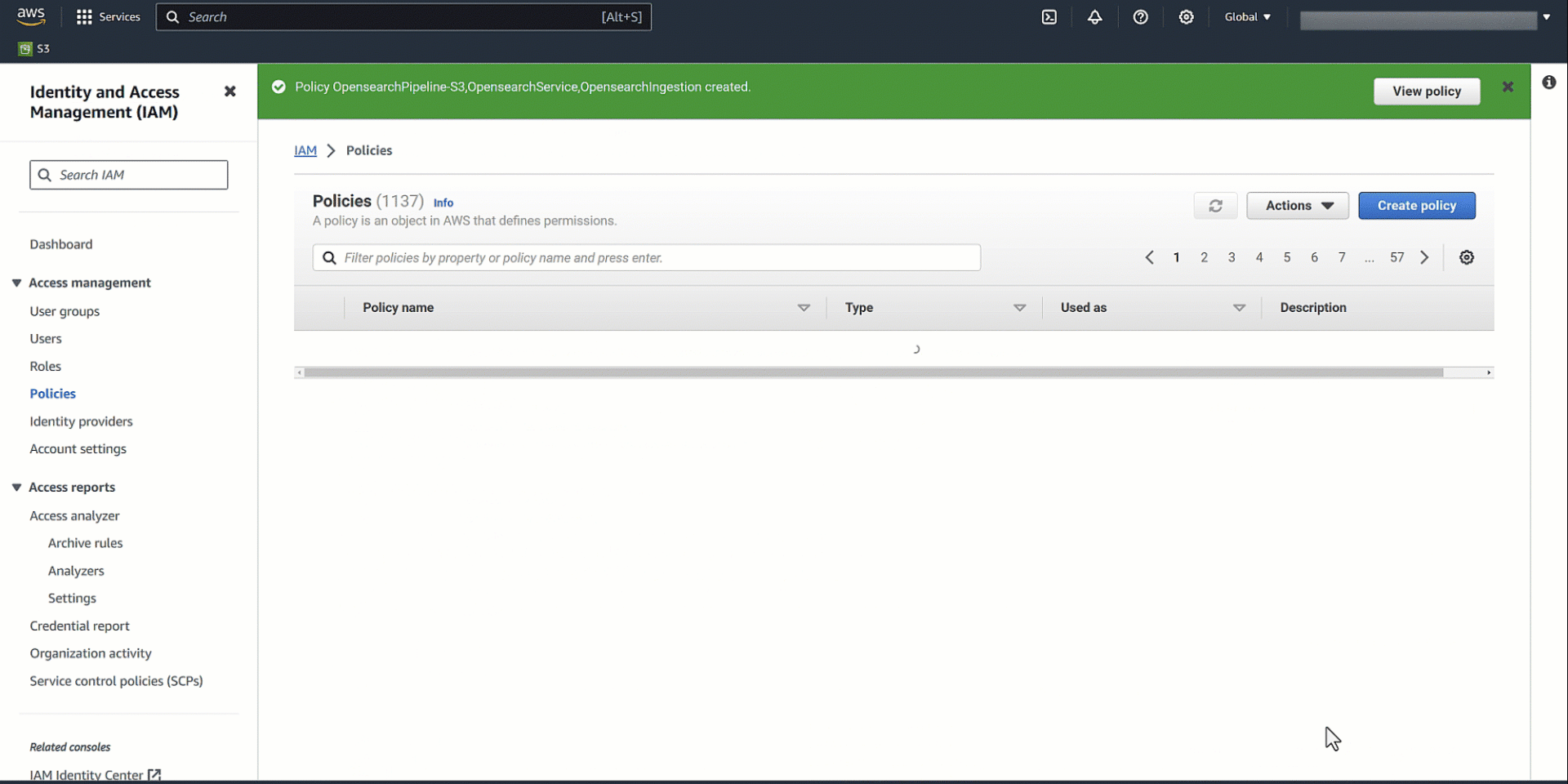
Create an IAM role and attach the IAM policy
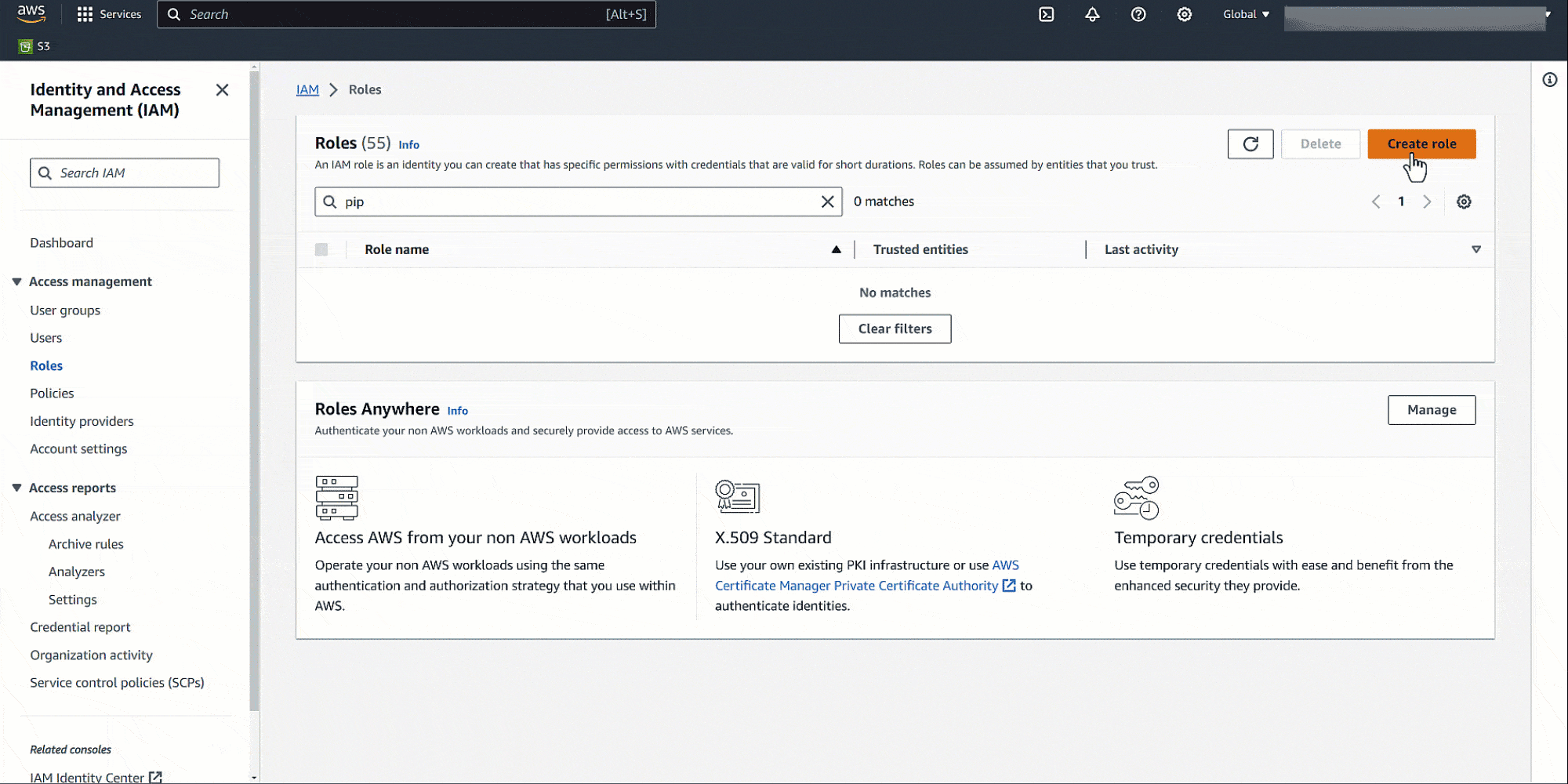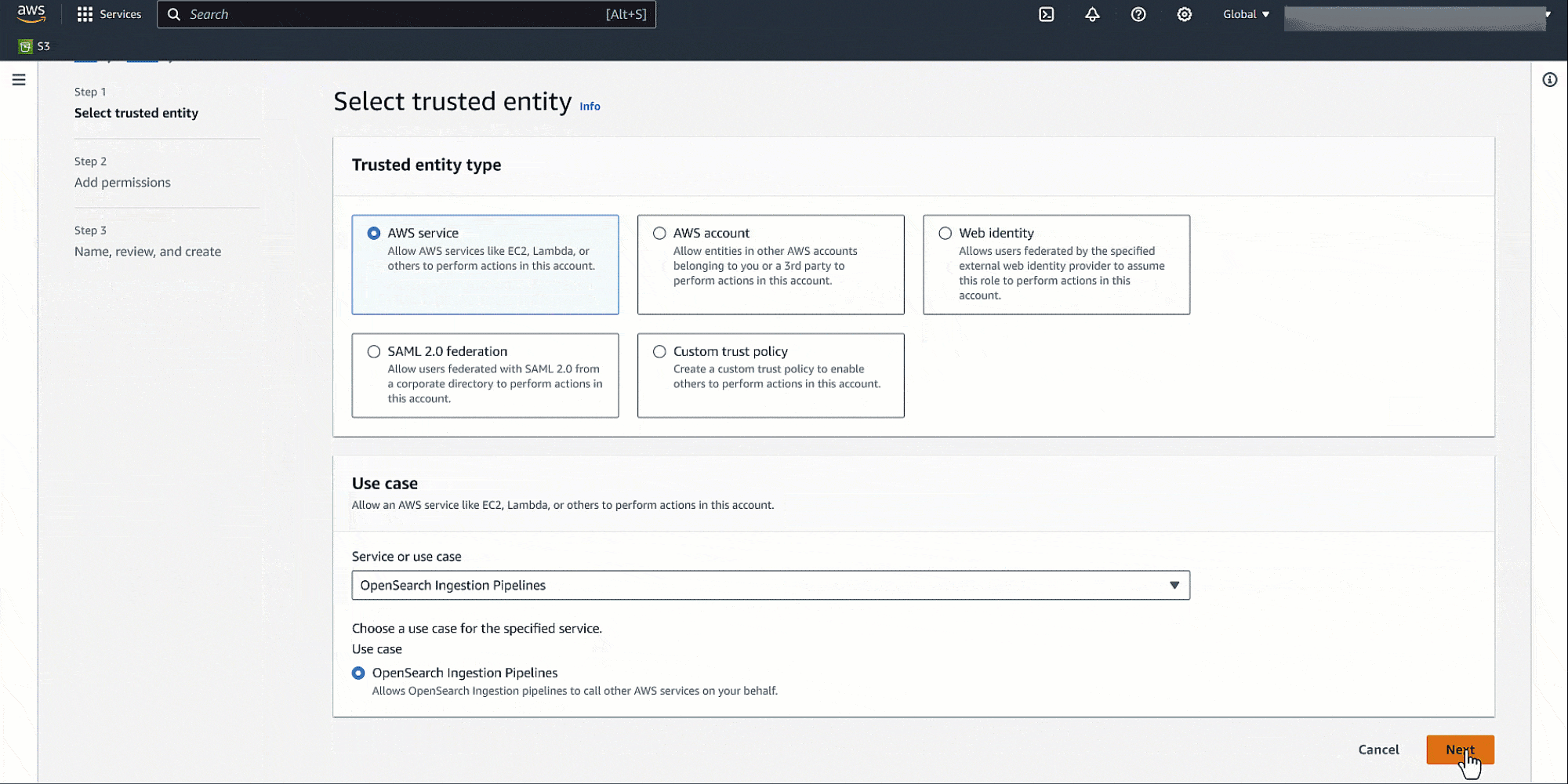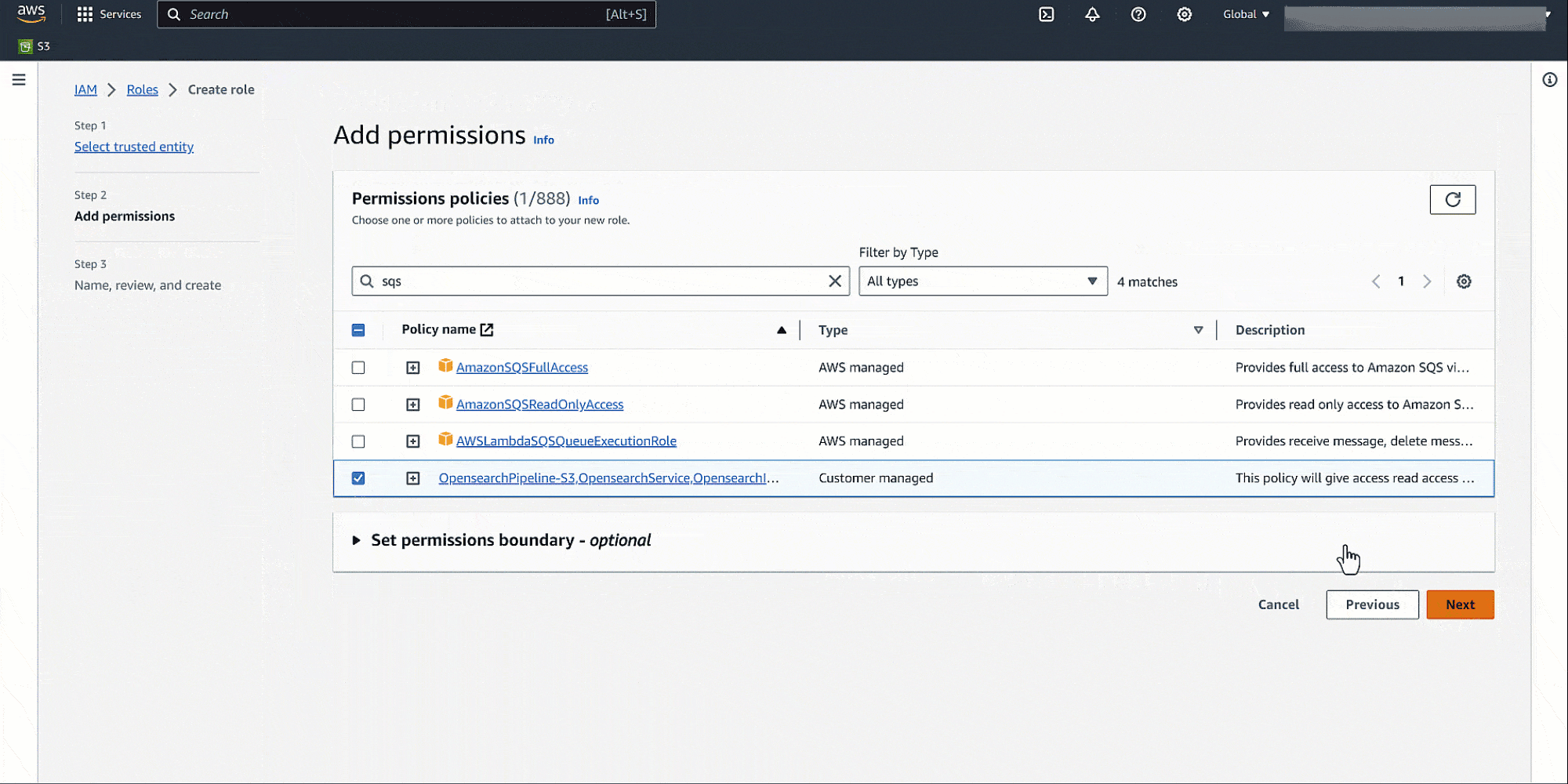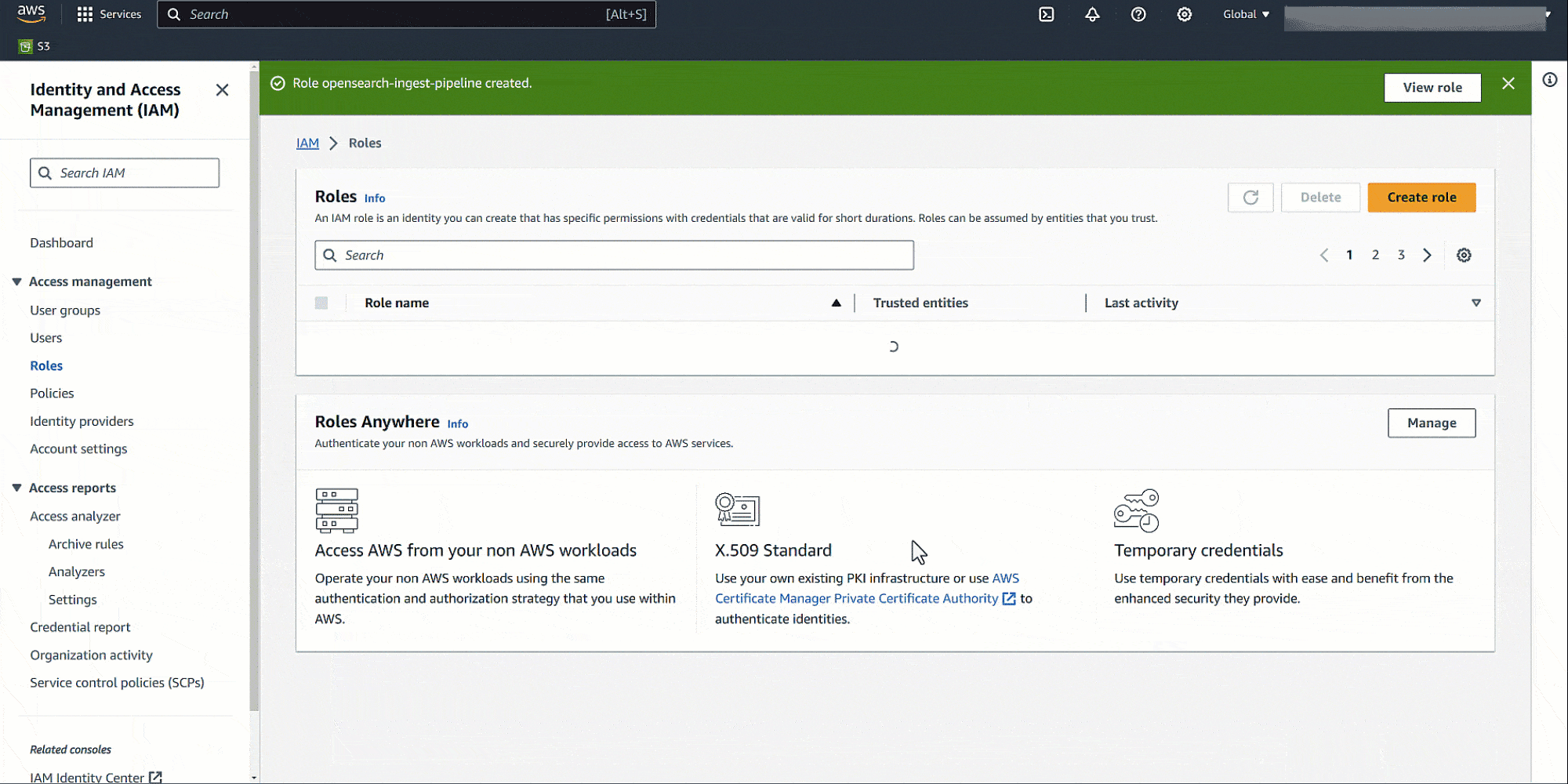
A trust relationship defines which entities (such as AWS accounts, IAM users, roles, or services) are allowed to assume a particular IAM role. Create an IAM role for the OpenSearch Ingestion pipeline (osis-pipelines.amazonaws.com), attach the IAM policy created in the previous step, and add the trust relationship to allow OpenSearch Ingestion pipelines to write to domains.
Configure an OpenSearch Ingestion pipeline
A pipeline is the mechanism that OpenSearch Ingestion uses to move data from its source (where the data comes from) to its sink (where the data goes). OpenSearch Ingestion provides out-of-the-box configuration blueprints to help you quickly set up pipelines without having to author a configuration from scratch. Set up the S3 bucket as the source and OpenSearch Service domain as the sink in the OpenSearch Ingestion pipeline with the following blueprint:
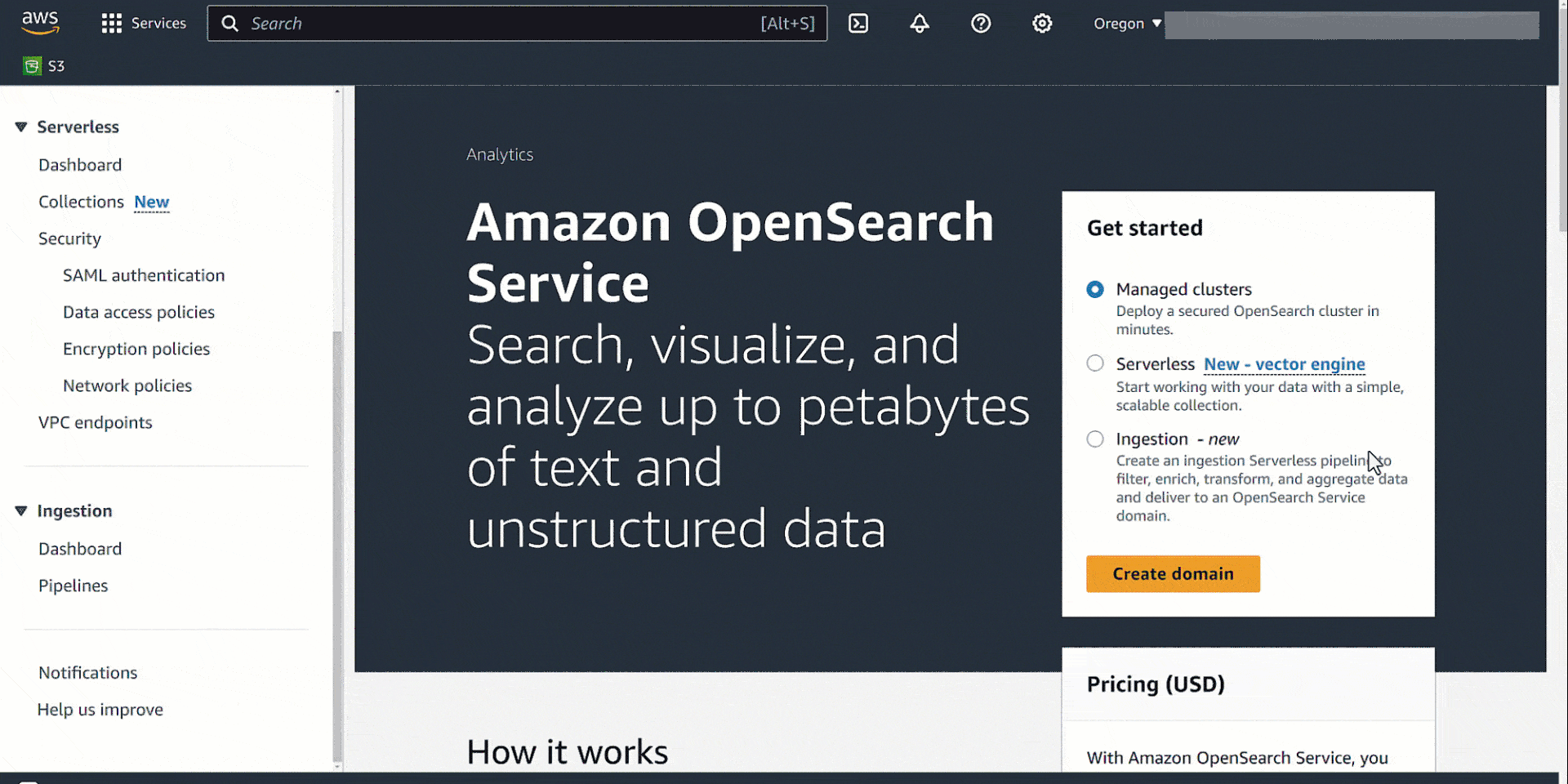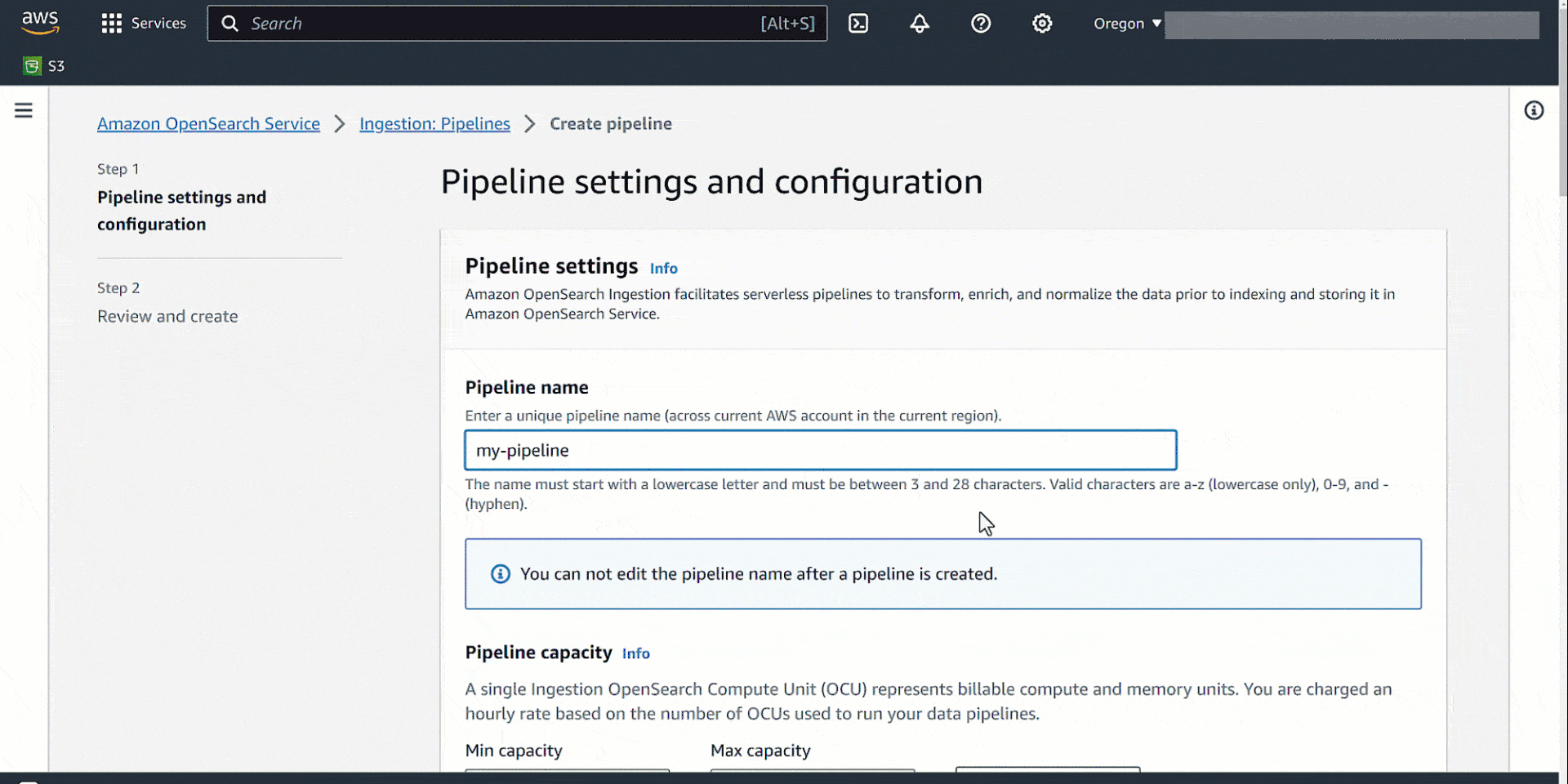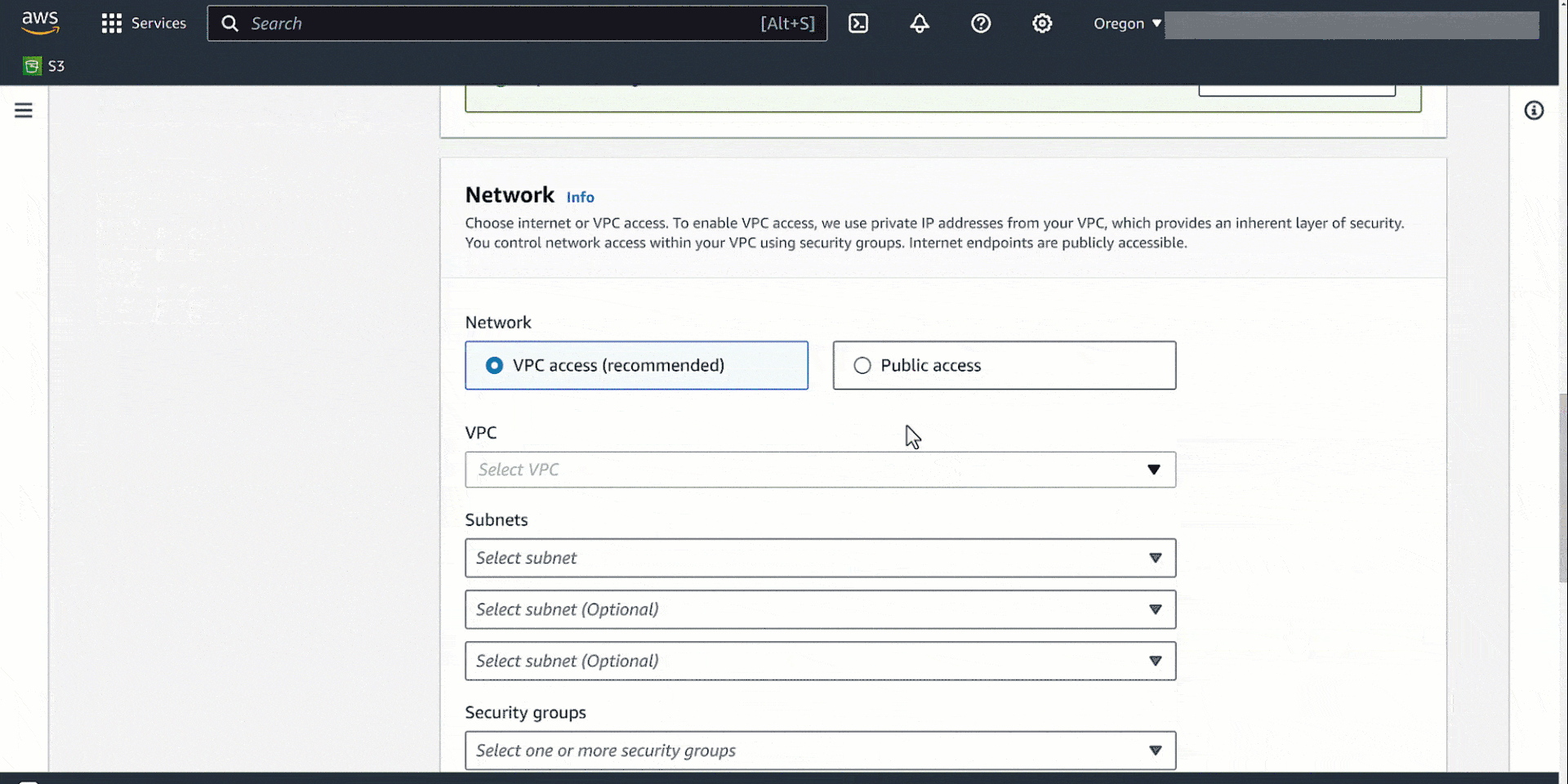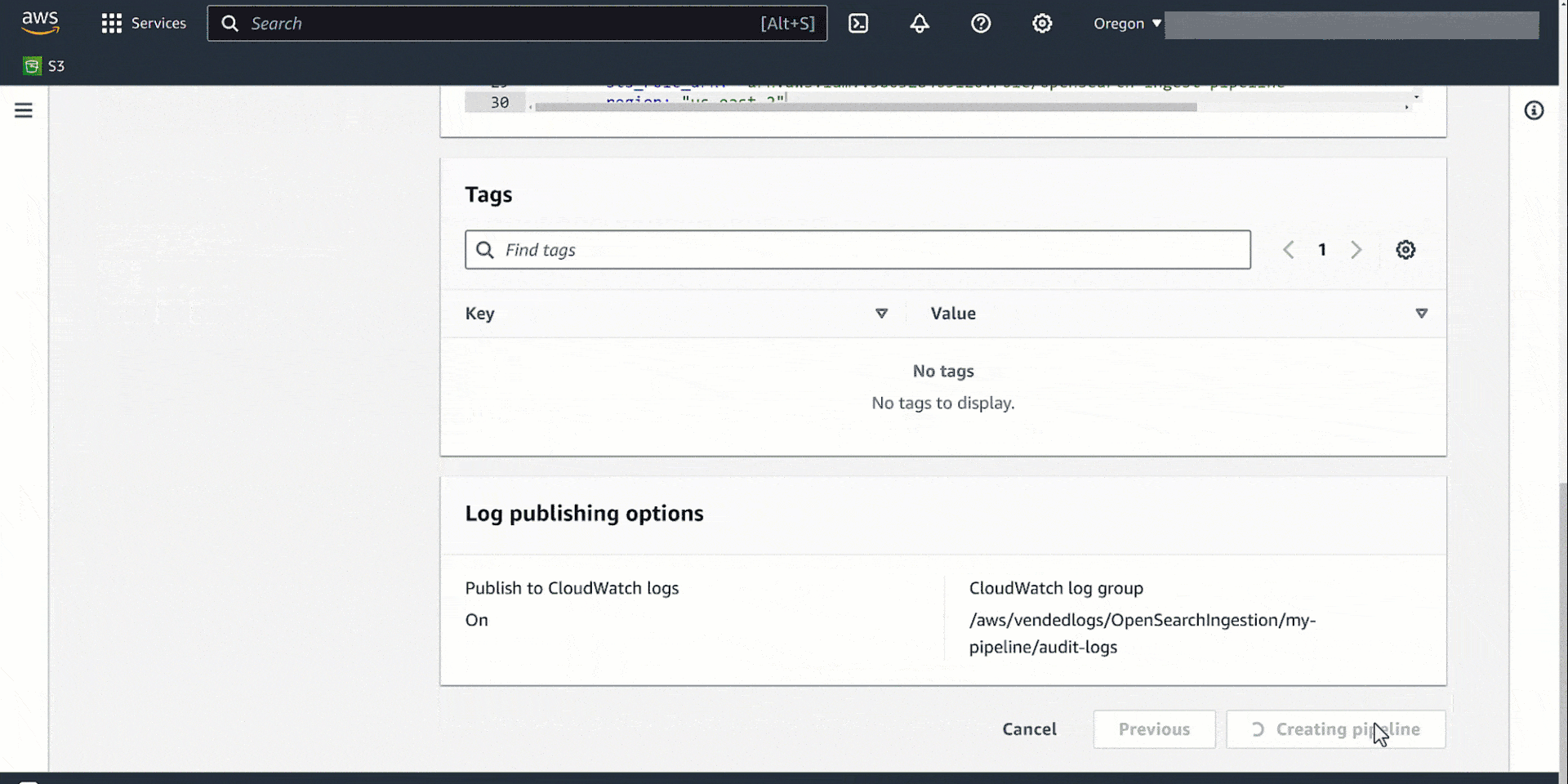
On the OpenSearch Service console, create a pipeline with the name my-pipeline. Keep the default capacity settings and enter the preceding pipeline configuration in the Pipeline configuration section.
Update the configuration setting with the previously created IAM roles to read from Amazon S3 and write into OpenSearch Service, the SQS queue URL, and the OpenSearch Service domain endpoint.
Validate the solution
To validate this solution, you can use the dataset SaaS-Sales.csv. This dataset contains transaction data from a software as a service (SaaS) company selling sales and marketing software to other companies (B2B). You can initiate this workflow by uploading the SaaS-Sales.csv file to the S3 bucket. This invokes the pipeline and creates an index in the OpenSearch Service domain you created earlier.
Follow these steps to validate the data using OpenSearch Dashboards.
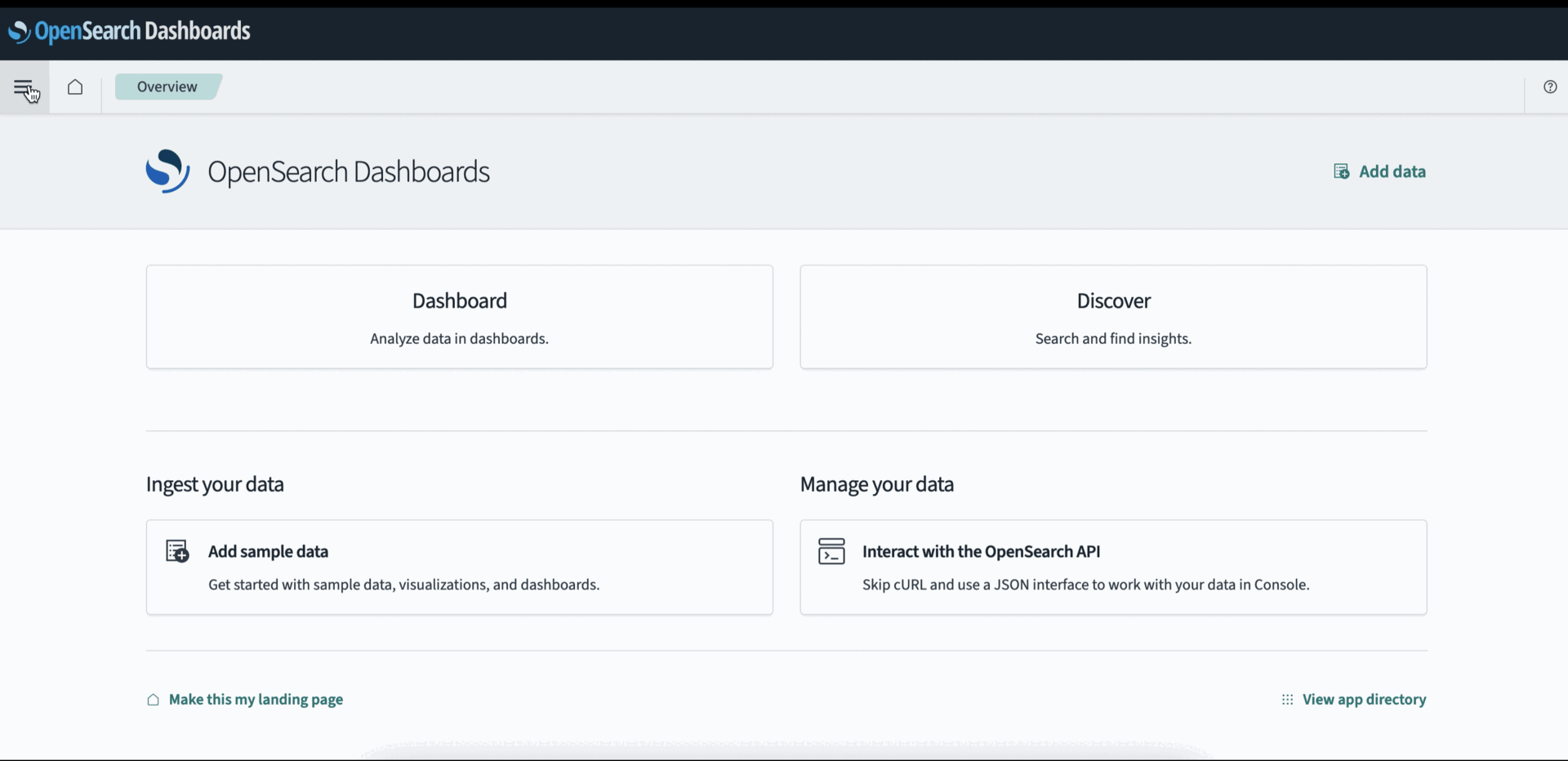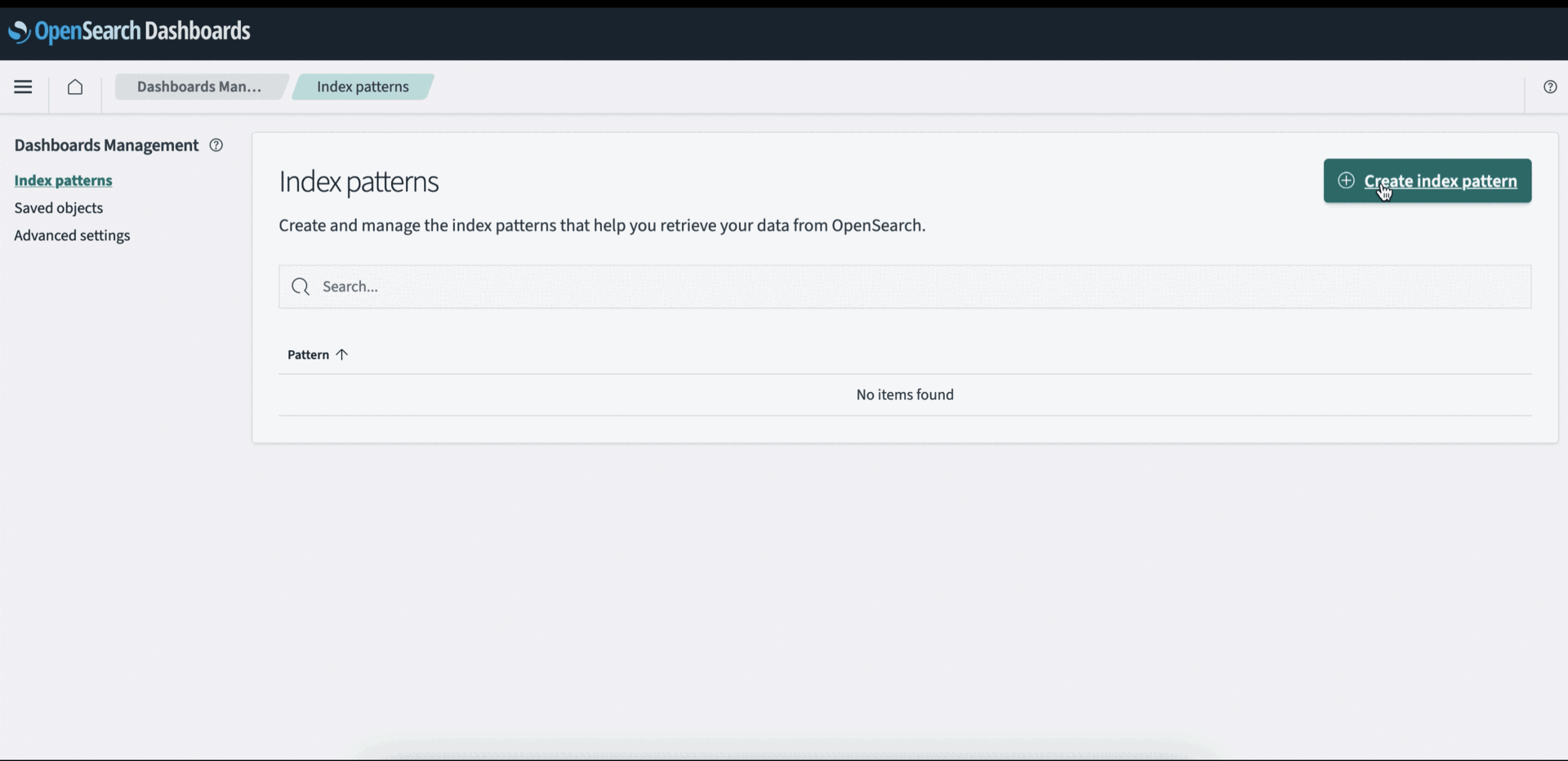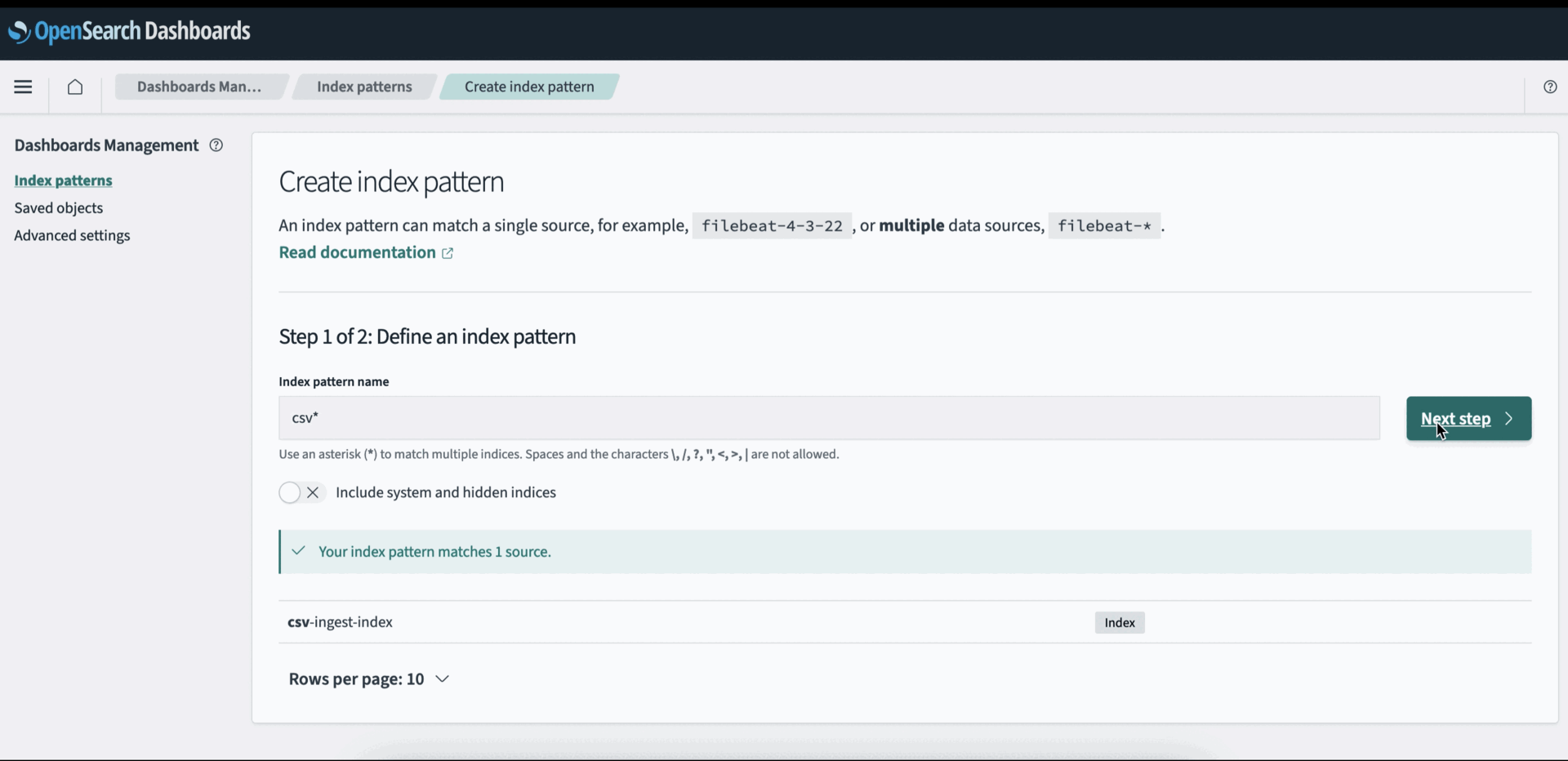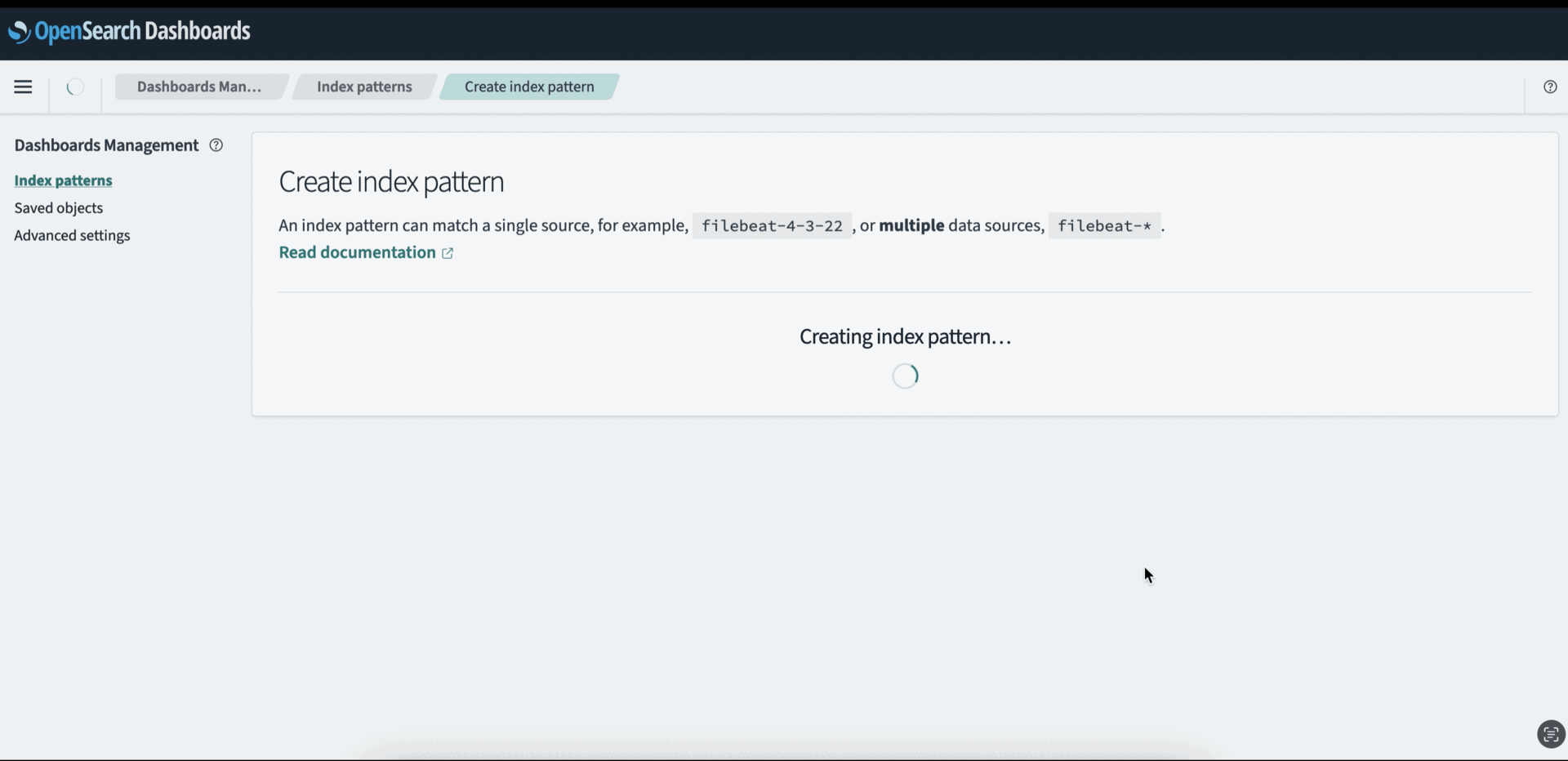
First, you create an index pattern. An index pattern is a way to define a logical grouping of indexes that share a common naming convention. This allows you to search and analyze data across all matching indexes using a single query or visualization. For example, if you named your indexes csv-ingest-index-2024-01-01 and csv-ingest-index-2024-01-02 while ingesting the monthly sales data, you can define an index pattern as csv-* to encompass all these indexes.
Next, you create a visualization. Visualizations are powerful tools to explore and analyze data stored in OpenSearch indexes. You can gather these visualizations into a real time OpenSearch dashboard. An OpenSearch dashboard provides a user-friendly interface for creating various types of visualizations such as charts, graphs, maps, and dashboards to gain insights from data.
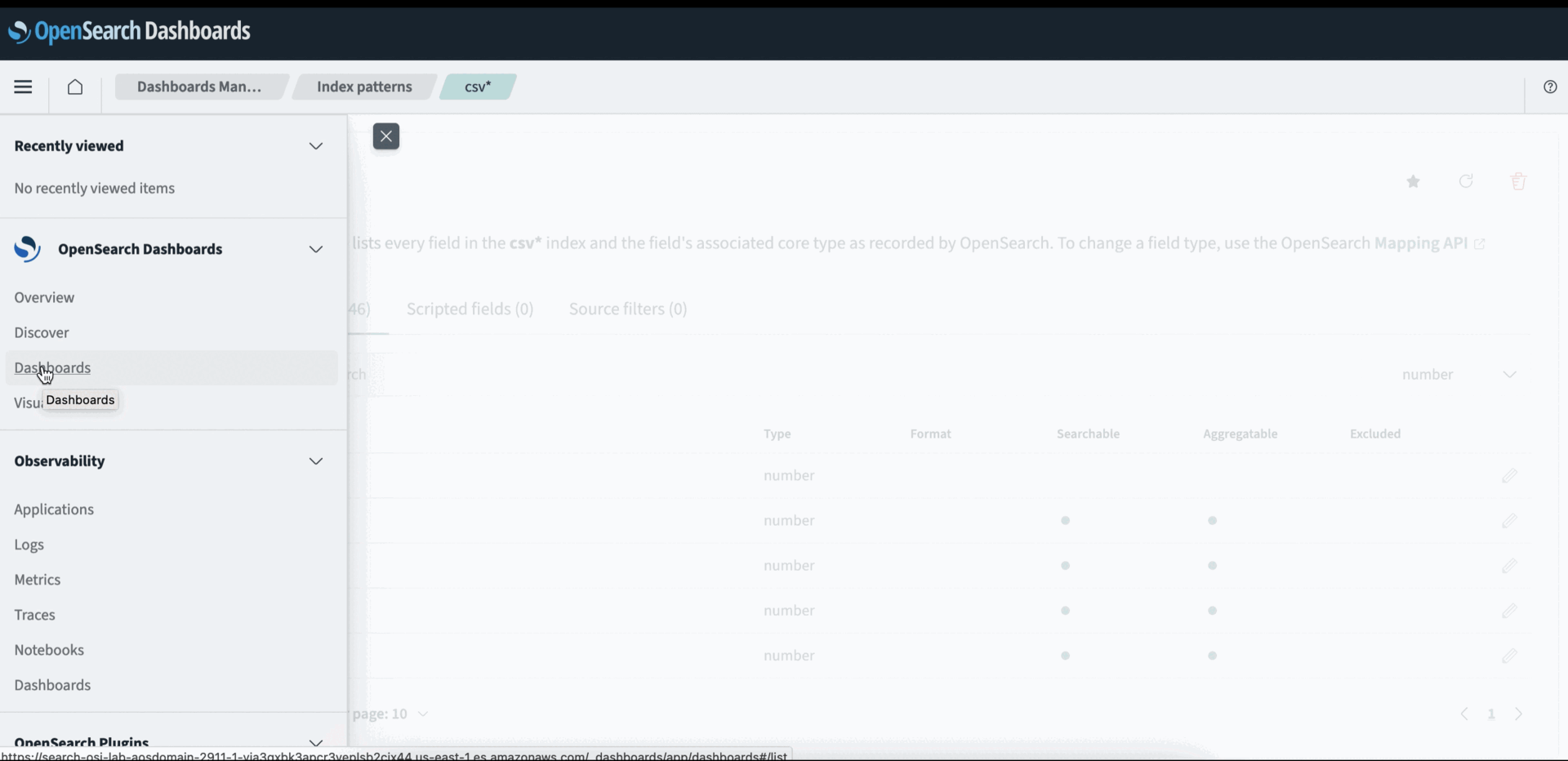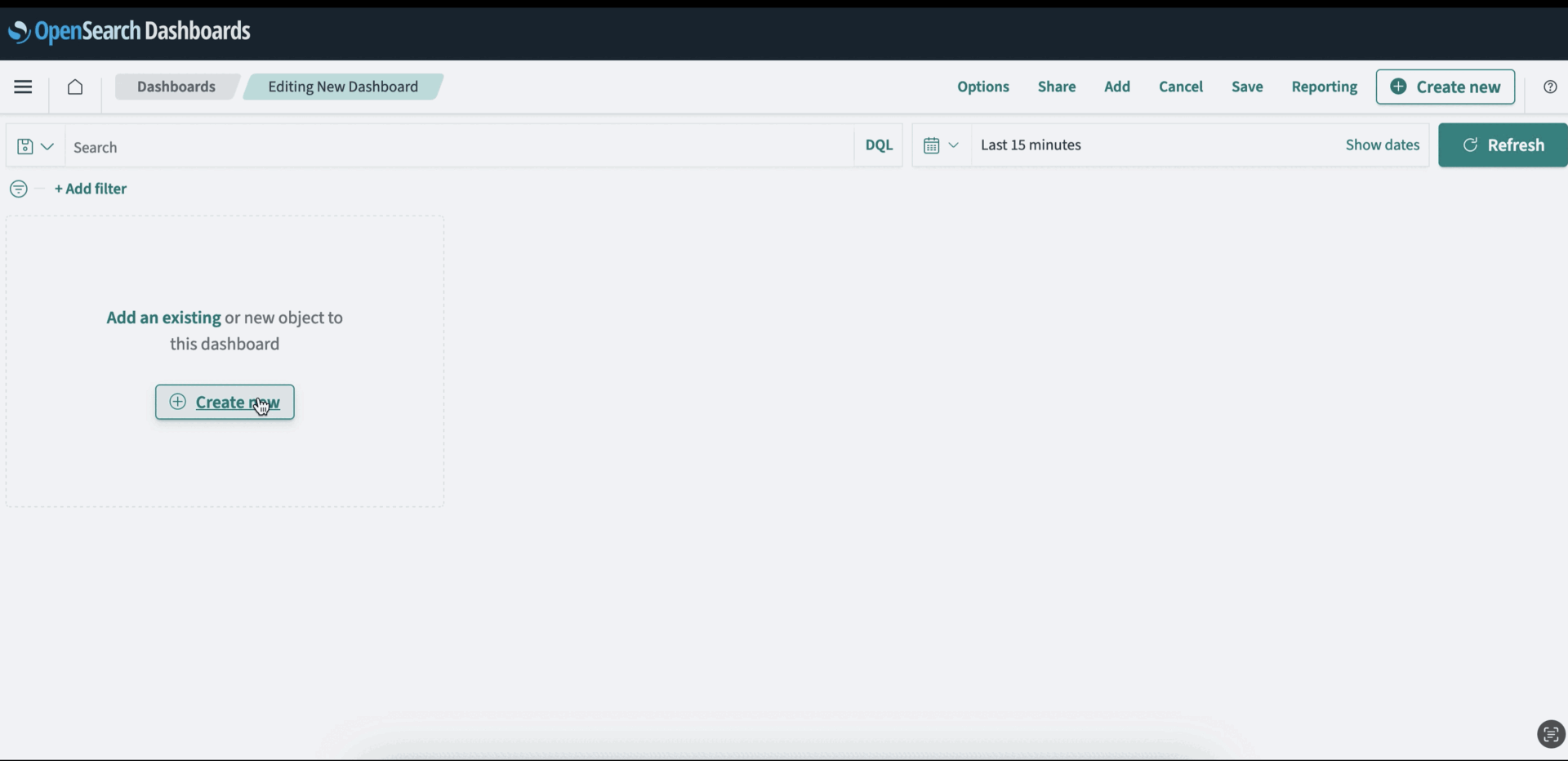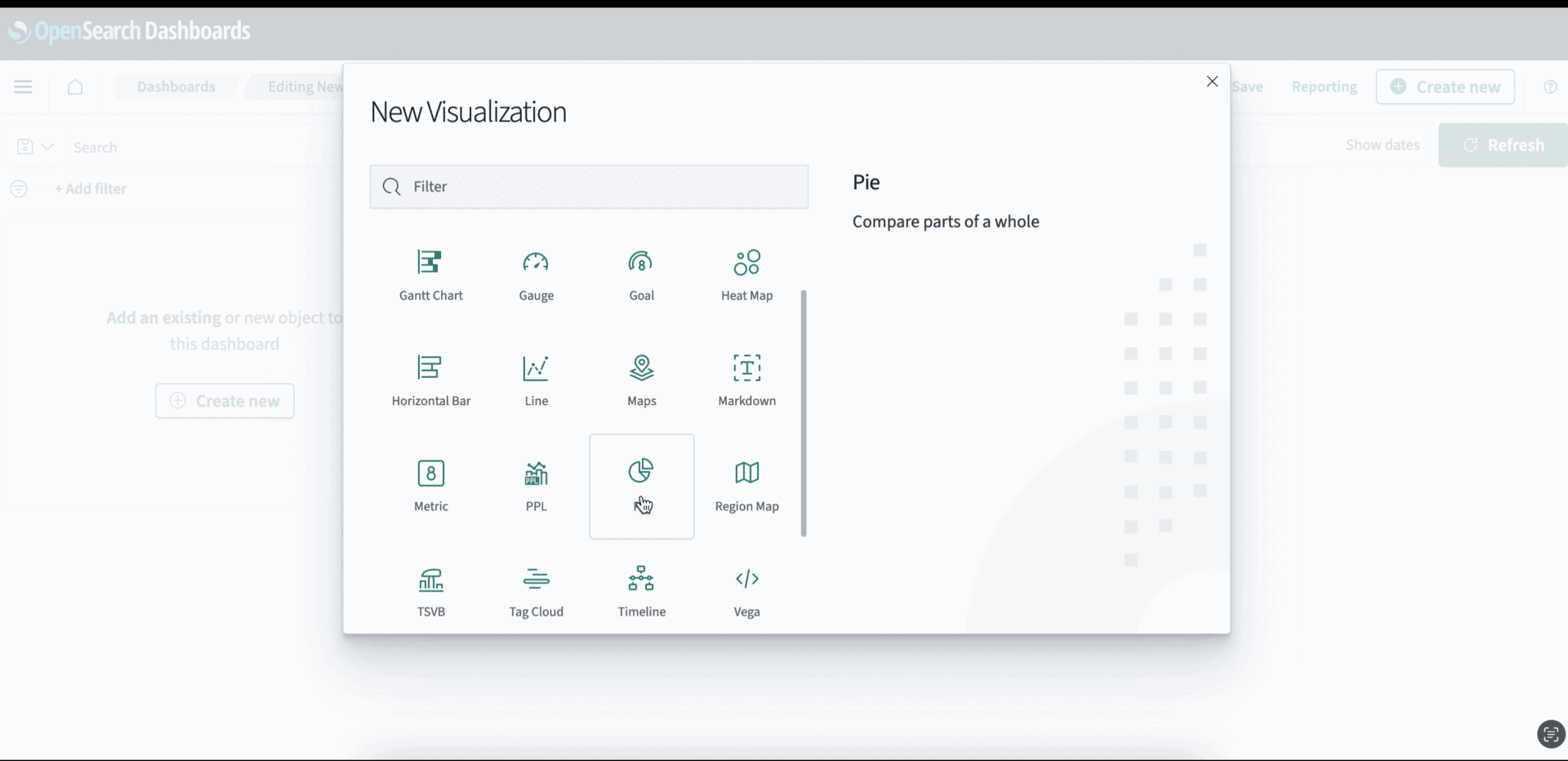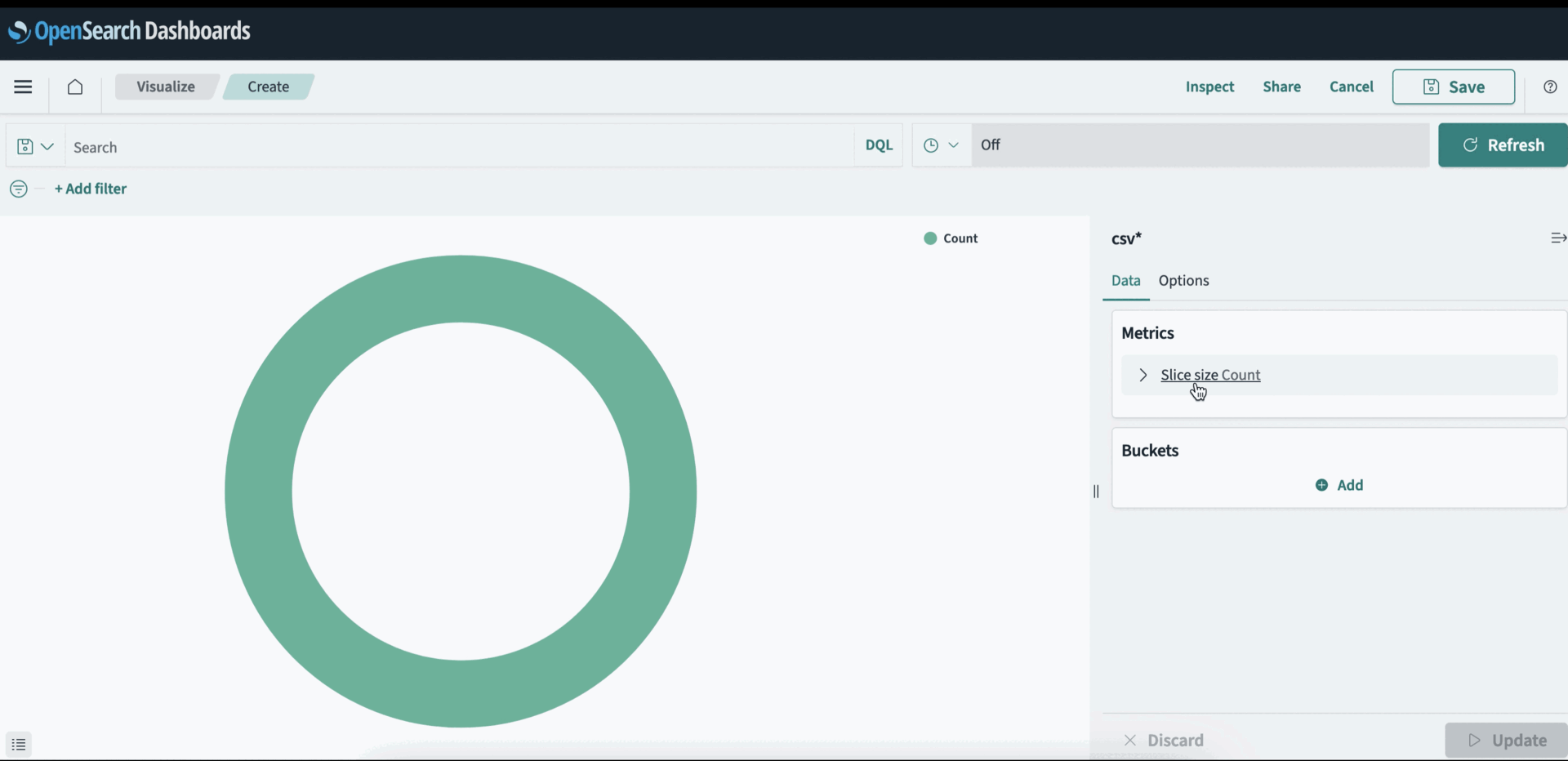
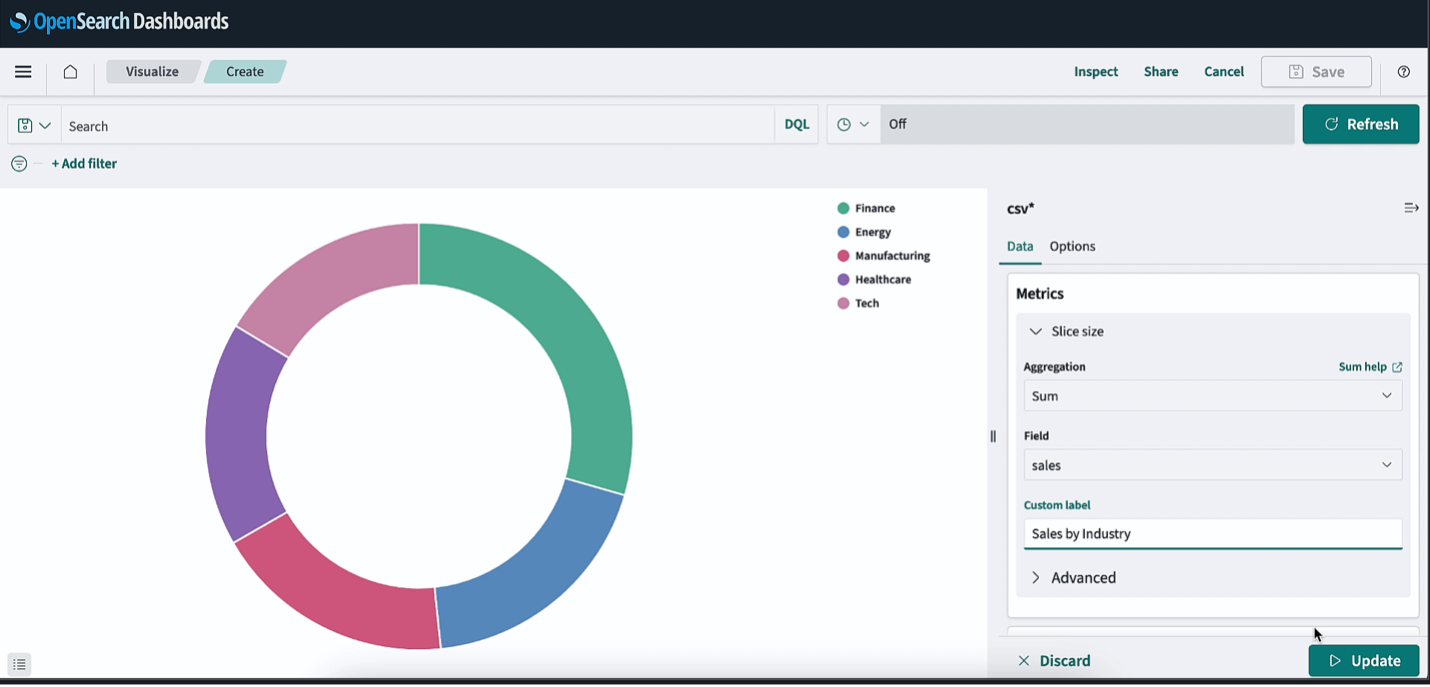
You can visualize the sales data by industry with a pie chart with the index pattern created in the previous step. To create a pie chart, update the metrics details as follows on the Data tab:
- Set Metrics to Slice
- Set Aggregation to Sum
- Set Field to sales
To view the industry-wise sales details in the pie chart, add a new bucket on the Data tab as follows:
- Set Buckets to Split Slices
- Set Aggregation to Terms
- Set Field to
industry.keyword
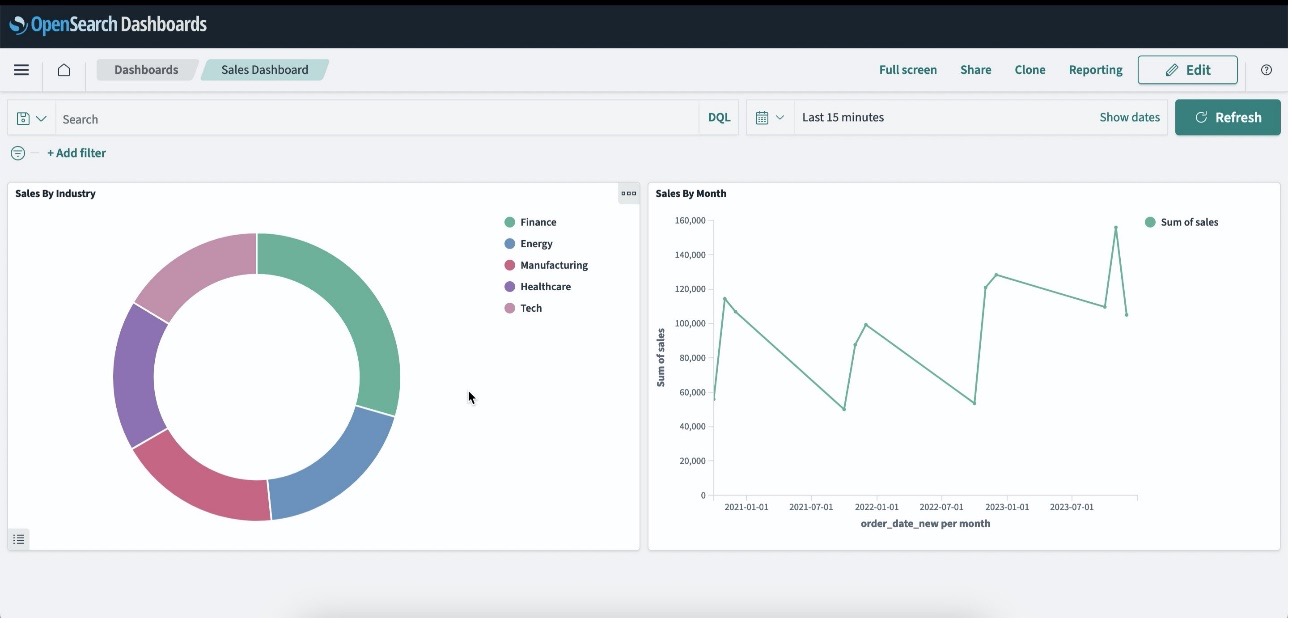
You can visualize the data by creating more visuals in the OpenSearch dashboard.
Clean up
When you’re done exploring OpenSearch Ingestion and OpenSearch Dashboards, you can delete the resources you created to avoid incurring further costs.
Conclusion
In this post, you learned how to ingest CSV files efficiently from S3 buckets into OpenSearch Service with the OpenSearch Ingestion feature in a serverless way without requiring a third-party agent. You also learned how to analyze the ingested data using OpenSearch dashboard visualizations. You can now explore extending this solution to build OpenSearch Ingestion pipelines to load your data and derive insights with OpenSearch Dashboards.
About the Authors
 Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.
Sharmila Shanmugam is a Solutions Architect at Amazon Web Services. She is passionate about solving the customers’ business challenges with technology and automation and reduce the operational overhead. In her current role, she helps customers across industries in their digital transformation journey and build secure, scalable, performant and optimized workloads on AWS.
 Harsh Bansal is an Analytics Solutions Architect with Amazon Web Services. In his role, he collaborates closely with clients, assisting in their migration to cloud platforms and optimizing cluster setups to enhance performance and reduce costs. Before joining AWS, he supported clients in leveraging OpenSearch and Elasticsearch for diverse search and log analytics requirements.
Harsh Bansal is an Analytics Solutions Architect with Amazon Web Services. In his role, he collaborates closely with clients, assisting in their migration to cloud platforms and optimizing cluster setups to enhance performance and reduce costs. Before joining AWS, he supported clients in leveraging OpenSearch and Elasticsearch for diverse search and log analytics requirements.
 Rohit Kumar works as a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He focuses on Amazon OpenSearch Service, offering guidance and technical help to customers, helping them create scalable, highly available, and secure solutions on AWS Cloud. Outside of work, Rohit enjoys watching or playing cricket. He also loves traveling and discovering new places. Essentially, his routine revolves around eating, traveling, cricket, and repeating the cycle.
Rohit Kumar works as a Cloud Support Engineer in the Support Engineering team at Amazon Web Services. He focuses on Amazon OpenSearch Service, offering guidance and technical help to customers, helping them create scalable, highly available, and secure solutions on AWS Cloud. Outside of work, Rohit enjoys watching or playing cricket. He also loves traveling and discovering new places. Essentially, his routine revolves around eating, traveling, cricket, and repeating the cycle.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/ingest-and-analyze-your-data-using-amazon-opensearch-service-with-amazon-opensearch-ingestion/

