In the dynamic world of cloud computing, ensuring the resilience and availability of critical applications is paramount. Disaster recovery (DR) is the process by which an organization anticipates and addresses technology-related disasters. For organizations implementing critical workload orchestration using Amazon Managed Workflows for Apache Airflow (Amazon MWAA), it is crucial to have a DR plan in place to ensure business continuity.
In this series, we explore the need for Amazon MWAA disaster recovery and prescribe solutions that will sustain Amazon MWAA environments against unintended disruptions. This lets you to define, avoid, and handle disruption risks as part of your business continuity plan. This post focuses on designing the overall DR architecture. A future post in this series will focus on implementing the individual components using AWS services.
The need for Amazon MWAA disaster recovery
Amazon MWAA, a fully managed service for Apache Airflow, brings immense value to organizations by automating workflow orchestration for extract, transform, and load (ETL), DevOps, and machine learning (ML) workloads. Amazon MWAA has a distributed architecture with multiple components such as scheduler, worker, web server, queue, and database. This makes it difficult to implement a comprehensive DR strategy.
An active Amazon MWAA environment continuously parses Airflow Directed Acyclic Graphs (DAGs), reading them from a configured Amazon Simple Storage Service (Amazon S3) bucket. DAG source unavailability due to network unreachability, unintended corruption, or deletes leads to extended downtime and service disruption.
Within Airflow, the metadata database is a core component storing configuration variables, roles, permissions, and DAG run histories. A healthy metadata database is therefore critical for your Airflow environment. As with any core Airflow component, having a backup and disaster recovery plan in place for the metadata database is essential.
Amazon MWAA deploys Airflow components to multiple Availability Zones within your VPC in your preferred AWS Region. This provides fault tolerance and automatic recovery against a single Availability Zone failure. For mission-critical workloads, being resilient to the impairments of a unitary Region through multi-Region deployments is additionally important to ensure high availability and business continuity.
Balancing between costs to maintain redundant infrastructures, complexity, and recovery time is essential for Amazon MWAA environments. Organizations aim for cost-effective solutions that minimize their Recovery Time Objective (RTO) and Recovery Point Objective (RPO) to meet their service level agreements, be economically viable, and meet their customers’ demands.
Detect disasters in the primary environment: Proactive monitoring through metrics and alarms
Prompt detection of disasters in the primary environment is crucial for timely disaster recovery. Monitoring the Amazon CloudWatch SchedulerHeartbeat metric provides insights into Airflow health of an active Amazon MWAA environment. You can add other health check metrics to the evaluation criteria, such as checking the availability of upstream or downstream systems and network reachability. Combined with CloudWatch alarms, you can send notifications when these thresholds over a number of time periods are not met. You can add alarms to dashboards to monitor and receive alerts about your AWS resources and applications across multiple Regions.
AWS publishes our most up-to-the-minute information on service availability on the Service Health Dashboard. You can check at any time to get current status information, or subscribe to an RSS feed to be notified of interruptions to each individual service in your operating Region. The AWS Health Dashboard provides information about AWS Health events that can affect your account.
By combining metric monitoring, available dashboards, and automatic alarming, you can promptly detect unavailability of your primary environment, enabling proactive measures to transition to your DR plan. It is critical to factor in incident detection, notification, escalation, discovery, and declaration into your DR planning and implementation to provide realistic and achievable objectives that provide business value.
In the following sections, we discuss two Amazon MWAA DR strategy solutions and their architecture.
DR strategy solution 1: Backup and restore
The backup and restore strategy involves generating Airflow component backups in the same or different Region as your primary Amazon MWAA environment. To ensure continuity, you can asynchronously replicate these to your DR Region, with minimal performance impact on your primary Amazon MWAA environment. In the event of a rare primary Regional impairment or service disruption, this strategy will create a new Amazon MWAA environment and recover historical data to it from existing backups. However, it’s important to note that during the recovery process, there will be a period where no Airflow environments are operational to process workflows until the new environment is fully provisioned and marked as available.
This strategy provides a low-cost and low-complexity solution that is also suitable for mitigating against data loss or corruption within your primary Region. The amount of data being backed up and the time to create a new Amazon MWAA environment (typically 20–30 minutes) affects how quickly restoration can happen. To enable infrastructure to be redeployed quickly without errors, deploy using infrastructure as code (IaC). Without IaC, it may be complex to restore an analogous DR environment, which will lead to increased recovery times and possibly exceed your RTO.
Let’s explore the setup required when your primary Amazon MWAA environment is actively running, as shown in the following figure.
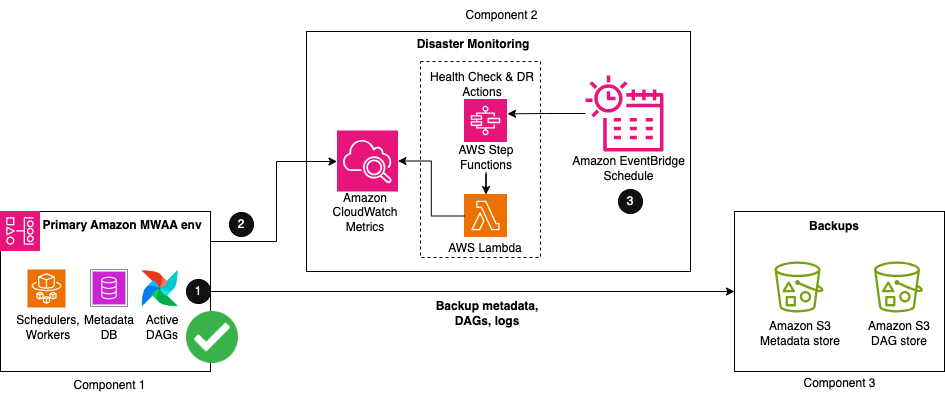
The solution comprises three key components. The first component is the primary environment, where the Airflow workflows are initially deployed and actively running. The second component is the disaster monitoring component, comprised of CloudWatch and a combination of an AWS Step Functions state machine and a AWS Lambda function. The third component is for creating and storing backups of all configurations and metadata that is required to restore. This can be in the same Region as your primary or replicated to your DR Region using S3 Cross-Region Replication (CRR). For CRR, you also pay for inter-Region data transfer out from Amazon S3 to each destination Region.
The first three steps in the workflow are as follows:
- As part of your backup creation process, Airflow metadata is replicated to an S3 bucket using an export DAG utility, run periodically based on your RPO interval.
- Your existing primary Amazon MWAA environment automatically emits the status of its scheduler’s health to the CloudWatch SchedulerHeartbeat metric.
- A multi-step Step Functions state machine is triggered from a periodic Amazon EventBridge schedule to monitor the scheduler’s health status. As the primary step of the state machine, a Lambda function evaluates the status of the SchedulerHeartbeat metric. If the metric is deemed healthy, no action is taken.
The following figure illustrates the additional steps in the solution workflow.
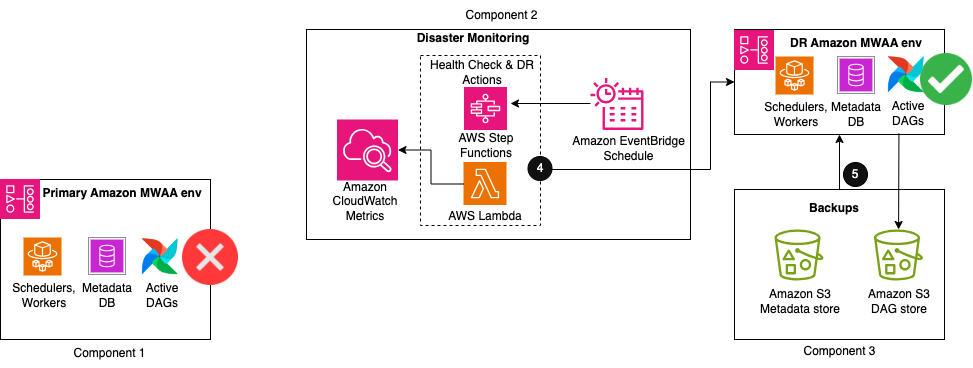
- When the heartbeat count deviates from the normal count for a period of time, a series of actions are initiated to recover to a new Amazon MWAA environment in the DR Region. These actions include starting creation of a new Amazon MWAA environment, replicating the primary environment configurations, and then waiting for the new environment to become available.
- When the environment is available, an import DAG utility is run to restore the metadata contents from the backups. Any DAG runs that were interrupted during the impairment of the primary environment need to be manually rerun to maintain service level agreements. Future DAG runs are queued to run as per their next configured schedule.
DR strategy solution 2: Active-passive environments with periodic data synchronization
The active-passive environments with periodic data synchronization strategy focuses on maintaining recurrent data synchronization between an active primary and a passive Amazon MWAA DR environment. By periodically updating and synchronizing DAG stores and metadata databases, this strategy ensures that the DR environment remains current or nearly current with the primary. The DR Region can be the same or a different Region than your primary Amazon MWAA environment. In the event of a disaster, backups are available to revert to a previous known good state to minimize data loss or corruption.
This strategy provides low RTO and RPO with frequent synchronization, allowing quick recovery with minimal data loss. The infrastructure costs and code deployments are compounded to maintain both the primary and DR Amazon MWAA environments. Your DR environment is available immediately to run DAGs on.
The following figure illustrates the setup required when your primary Amazon MWAA environment is actively running.
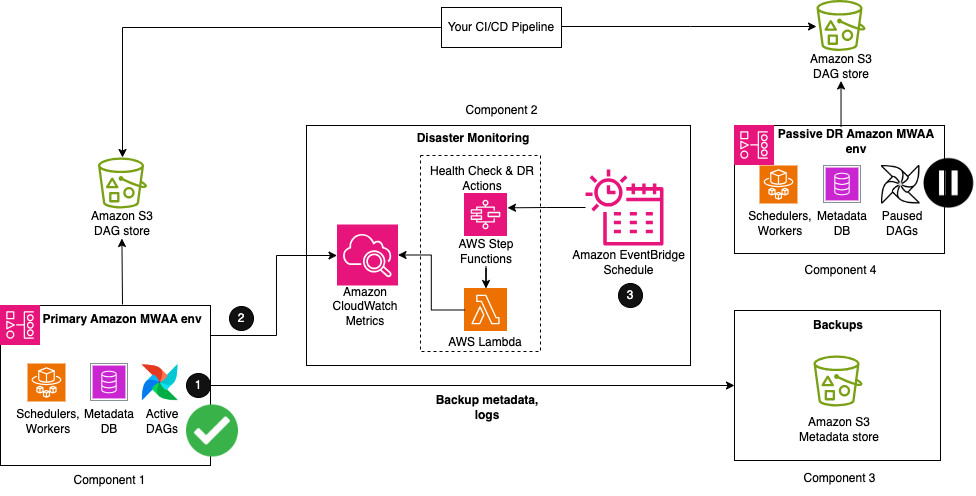
The solution comprises four key components. Similar to the backup and restore solution, the first component is the primary environment, where the workflow is initially deployed and is actively running. The second component is the disaster monitoring component, consisting of CloudWatch and a combination of a Step Functions state machine and Lambda function. The third component creates and stores backups for all configurations and metadata required for the database synchronization. This can be in the same Region as your primary or replicated to your DR Region using Amazon S3 Cross-Region Replication. As mentioned earlier, for CRR, you also pay for inter-Region data transfer out from Amazon S3 to each destination Region. The last component is a passive Amazon MWAA environment that has the same Airflow code and environment configurations as the primary. The DAGs are deployed in the DR environment using the same continuous integration and continuous delivery (CI/CD) pipeline as the primary. Unlike the primary, DAGs are kept in a paused state to not cause duplicate runs.
The first steps of the workflow are similar to the backup and restore strategy:
- As part of your backup creation process, Airflow metadata is replicated to an S3 bucket using an export DAG utility, run periodically based on your RPO interval.
- Your existing primary Amazon MWAA environment automatically emits the status of its scheduler’s health to CloudWatch SchedulerHeartbeat metric.
- A multi-step Step Functions state machine is triggered from a periodic Amazon EventBridge schedule to monitor scheduler health status. As the primary step of the state machine, a Lambda function evaluates the status of the SchedulerHeartbeat metric. If the metric is deemed healthy, no action is taken.
The following figure illustrates the final steps of the workflow.
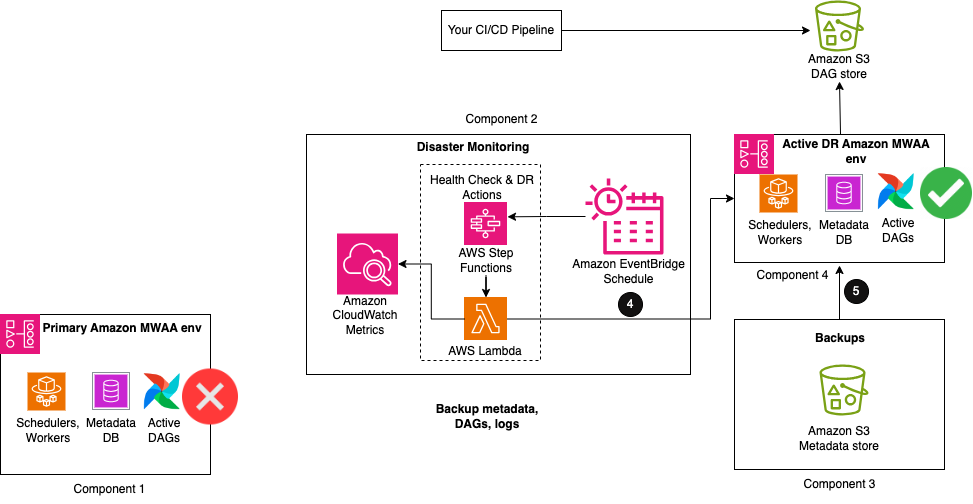
- When the heartbeat count deviates from the normal count for a period of time, DR actions are initiated.
- As a first step, a Lambda function triggers an import DAG utility to restore the metadata contents from the backups to the passive Amazon MWAA DR environment. When the imports are complete, the same DAG can un-pause the other Airflow DAGs, making them active for future runs. Any DAG runs that were interrupted during the impairment of the primary environment need to be manually rerun to maintain service level agreements. Future DAG runs are queued to run as per their next configured schedule.
Best practices to improve resiliency of Amazon MWAA
To enhance the resiliency of your Amazon MWAA environment and ensure smooth disaster recovery, consider implementing the following best practices:
- Robust backup and restore mechanisms – Implementing comprehensive backup and restore mechanisms for Amazon MWAA data is essential. Regularly deleting existing metadata based on your organization’s retention policies reduces backup times and makes your Amazon MWAA environment more performant.
- Automation using IaC – Using automation and orchestration tools such as AWS CloudFormation, the AWS Cloud Development Kit (AWS CDK), or Terraform can streamline the deployment and configuration management of Amazon MWAA environments. This ensures consistency, reproducibility, and faster recovery during DR scenarios.
- Idempotent DAGs and tasks – In Airflow, a DAG is considered idempotent if rerunning the same DAG with the same inputs multiple times has the same effect as running it only once. Designing idempotent DAGs and keeping tasks atomic decreases recovery time from failures when you have to manually rerun an interrupted DAG in your recovered environment.
- Regular testing and validation – A robust Amazon MWAA DR strategy should include regular testing and validation exercises. By simulating disaster scenarios, you can identify any gaps in your DR plans, fine-tune processes, and ensure your Amazon MWAA environments are fully recoverable.
Conclusion
In this post, we explored the challenges for Amazon MWAA disaster recovery and discussed best practices to improve resiliency. We examined two DR strategy solutions: backup and restore and active-passive environments with periodic data synchronization. By implementing these solutions and following best practices, you can protect your Amazon MWAA environments, minimize downtime, and mitigate the impact of disasters. Regular testing, validation, and adaptation to evolving requirements are crucial for an effective Amazon MWAA DR strategy. By continuously evaluating and refining your disaster recovery plans, you can ensure the resilience and uninterrupted operation of your Amazon MWAA environments, even in the face of unforeseen events.
For additional details and code examples on Amazon MWAA, refer to the Amazon MWAA User Guide and the Amazon MWAA examples GitHub repo.
About the Authors
 Parnab Basak is a Senior Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
Parnab Basak is a Senior Solutions Architect and a Serverless Specialist at AWS. He specializes in creating new solutions that are cloud native using modern software development practices like serverless, DevOps, and analytics. Parnab works closely in the analytics and integration services space helping customers adopt AWS services for their workflow orchestration needs.
 Chandan Rupakheti is a Solutions Architect and a Serverless Specialist at AWS. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud and bringing stakeholders together in their cloud journey. Outside his professional life, he loves spending time with his family and friends besides listening and playing music.
Chandan Rupakheti is a Solutions Architect and a Serverless Specialist at AWS. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud and bringing stakeholders together in their cloud journey. Outside his professional life, he loves spending time with his family and friends besides listening and playing music.
 Vinod Jayendra is a Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers in solving their architectural, operational, and cost optimization challenges. With a particular focus on Serverless technologies, he draws from his extensive background in application development to deliver top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports team.
Vinod Jayendra is a Enterprise Support Lead in ISV accounts at Amazon Web Services, where he helps customers in solving their architectural, operational, and cost optimization challenges. With a particular focus on Serverless technologies, he draws from his extensive background in application development to deliver top-tier solutions. Beyond work, he finds joy in quality family time, embarking on biking adventures, and coaching youth sports team.
 Rupesh Tiwari is a Senior Solutions Architect at AWS in New York City, with a focus on Financial Services. He has over 18 years of IT experience in the finance, insurance, and education domains, and specializes in architecting large-scale applications and cloud-native big data workloads. In his spare time, Rupesh enjoys singing karaoke, watching comedy TV series, and creating joyful moments with his family.
Rupesh Tiwari is a Senior Solutions Architect at AWS in New York City, with a focus on Financial Services. He has over 18 years of IT experience in the finance, insurance, and education domains, and specializes in architecting large-scale applications and cloud-native big data workloads. In his spare time, Rupesh enjoys singing karaoke, watching comedy TV series, and creating joyful moments with his family.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/disaster-recovery-strategies-for-amazon-mwaa-part-1/

