In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. To address this challenge, organizations can deploy a data mesh using AWS Lake Formation that connects the multiple EMR clusters. With the AWS Glue Data Catalog federation to external Hive metastore feature, you can now now apply data governance to the metadata residing across those EMR clusters and analyze them using AWS analytics services such as Amazon Athena, Amazon Redshift Spectrum, AWS Glue ETL (extract, transform, and load) jobs, EMR notebooks, EMR Serverless using Lake Formation for fine-grained access control, and Amazon SageMaker Studio. For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions.
In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters. This approach enables organizations to take advantage of the scalability and flexibility of EMR clusters while maintaining control and integrity of their data assets across the data mesh.
Use cases for Hive metastore federation for Amazon EMR
Hive metastore federation for Amazon EMR is applicable to the following use cases:
- Governance of Amazon EMR-based data lakes – Producers generate data within their AWS accounts using an Amazon EMR-based data lake supported by EMRFS on Amazon Simple Storage Service (Amazon S3)and HBase. These data lakes require governance for access without the necessity of moving data to consumer accounts. The data resides on Amazon S3, which reduces the storage costs significantly.
- Centralized catalog for published data – Multiple producers release data currently governed by their respective entities. For consumer access, a centralized catalog is necessary where producers can publish their data assets.
- Consumer personas – Consumers include data analysts who run queries on the data lake, data scientists who prepare data for machine learning (ML) models and conduct exploratory analysis, as well as downstream systems that run batch jobs on the data within the data lake.
- Cross-producer data access – Consumers may need to access data from multiple producers within the same catalog environment.
- Data access entitlements – Data access entitlements involve implementing restrictions at the database, table, and column levels to provide appropriate data access control.
Solution overview
The following diagram shows how data from producers with their own Hive metastores (left) can be made available to consumers (right) using Lake Formation permissions enforced in a central governance account.
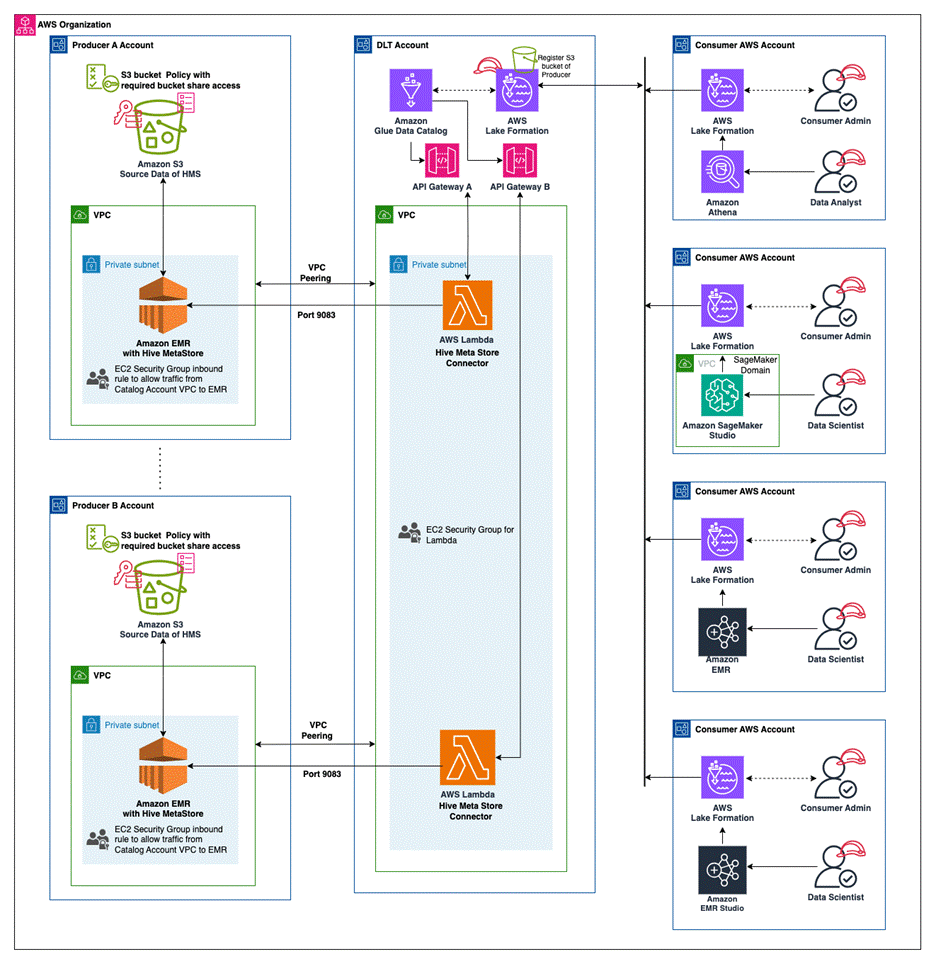
Producer and consumer are logical concepts used to indicate the production and consumption of data through a catalog. An entity can act both as a producer of data assets and as a consumer of data assets. The onboarding of producers is facilitated by sharing metadata, whereas the onboarding of consumers is based on granting permission to access this metadata.
The solution consists of multiple steps in the producer, catalog, and consumer accounts:
- Deploy the AWS CloudFormation templates and set up the producer, central governance and catalog, and consumer accounts.
- Test access to the producer cataloged Amazon S3 data using EMR Serverless in the consumer account.
- Test access using Athena queries in the consumer account.
- Test access using SageMaker Studio in the consumer account.
Producer
Producers create data within their AWS accounts using an Amazon EMR-based data lake and Amazon S3. Multiple producers then publish this data into a central catalog (data lake technology) account. Each producer account, along with the central catalog account, has either VPC peering or AWS Transit Gateway enabled to facilitate AWS Glue Data Catalog federation with the Hive metastore.
For each producer, an AWS Glue Hive metastore connector AWS Lambda function is deployed in the catalog account. This enables the Data Catalog to access Hive metastore information at runtime from the producer. The data lake locations (the S3 bucket location of the producers) are registered in the catalog account.
Central catalog
A catalog offers governed and secure data access to consumers. Federated databases are established within the catalog account’s Data Catalog using the Hive connection, managed by the catalog Lake Formation admin (LF-Admin). These federated databases in the catalog account are then shared by the data lake LF-Admin with the consumer LF-Admin of the external consumer account.
Data access entitlements are managed by applying access controls as needed at various levels, such as the database or table.
Consumer
The consumer LF-Admin grants the necessary permissions or restricted permissions to roles such as data analysts, data scientists, and downstream batch processing engine AWS Identity and Access Management (IAM) roles within its account.
Data access entitlements are managed by applying access control based on requirements at various levels, such as databases and tables.
Prerequisites
You need three AWS accounts with admin access to implement this solution. It is recommended to use test accounts. The producer account will host the EMR cluster and S3 buckets. The catalog account will host Lake Formation and AWS Glue. The consumer account will host EMR Serverless, Athena, and SageMaker notebooks.
Set up the producer account
Before you launch the CloudFormation stack, gather the following information from the catalog account:
- Catalog AWS account ID (12-digit account ID)
- Catalog VPC ID (for example,
vpc-xxxxxxxx) - VPC CIDR (catalog account VPC CIDR; it should not overlap 10.0.0.0/16)
The VPC CIDR of the producer and catalog can’t overlap due to VPC peering and Transit Gateway requirements. The VPC CIDR should be a VPC from the catalog account where the AWS Glue metastore connector Lambda function will be eventually deployed.
The CloudFormation stack for the producer creates the following resources:
- S3 bucket to host data for the Hive metastore of the EMR cluster.
- VPC with the CIDR 10.0.0.0/16. Make sure there is no existing VPC with this CIDR in use.
- VPC peering connection between the producer and catalog account.
- Amazon Elastic Compute Cloud (Amazon EC2) security groups for the EMR cluster.
- IAM roles required for the solution.
- EMR 6.10 cluster launched with Hive.
- Sample data downloaded to the S3 bucket.
- A database and external tables, pointing to the downloaded sample data, in its Hive metastore.
Complete the following steps:
- Launch the template PRODUCER.yml. It’s recommended to use an IAM role that has administrator privileges.
- Gather the values for the following on the CloudFormation stack’s Outputs tab:
VpcPeeringConnectionId(for example,pcx-xxxxxxxxx)DestinationCidrBlock(10.0.0.0/16)S3ProducerDataLakeBucketName
Set up the catalog account
The CloudFormation stack for the catalog account creates the Lambda function for federation. Before you launch the template, on the Lake Formation console, add the IAM role and user deploying the stack as the data lake admin.
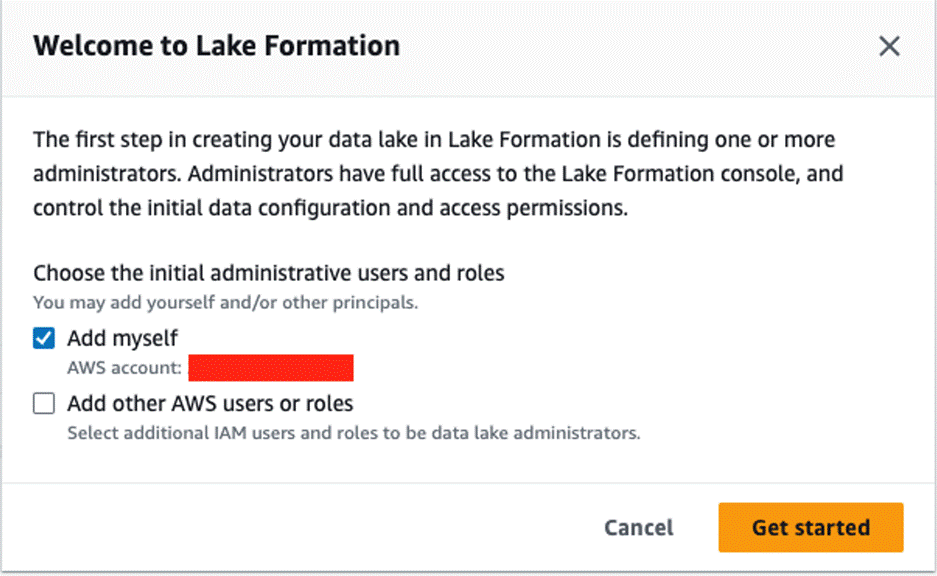
Then complete the following steps:
- Launch the template CATALOG.yml.
- For the
RouteTableIdparameter, use the catalog account VPCRouteTableId. This is the VPC where the AWS Glue Hive metastore connector Lambda function will be deployed. - On the stack’s Outputs tab, copy the value for
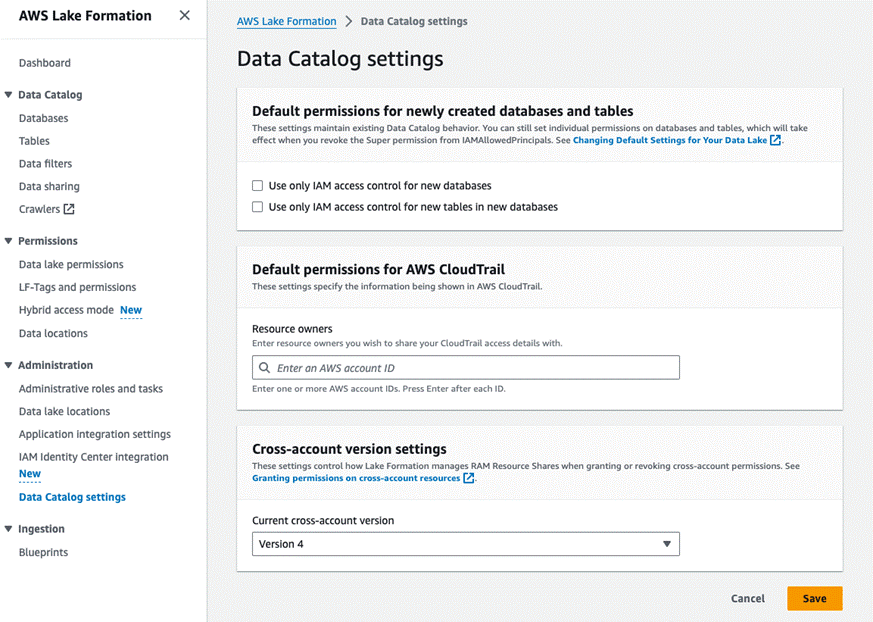
LFRegisterLocationServiceRole(arn:aws:iam::account-id: role/role-name). - Confirm if the Data Catalog setting has the IAM access control options un-checked and the current cross-account version is set to 4.
- Log in to the producer account and add the following bucket policy to the producer S3 bucket that was created during the producer account setup. Add the ARN of
LFRegisterLocationServiceRoleto the Principal section and provide the S3 bucket name under the Resource section.
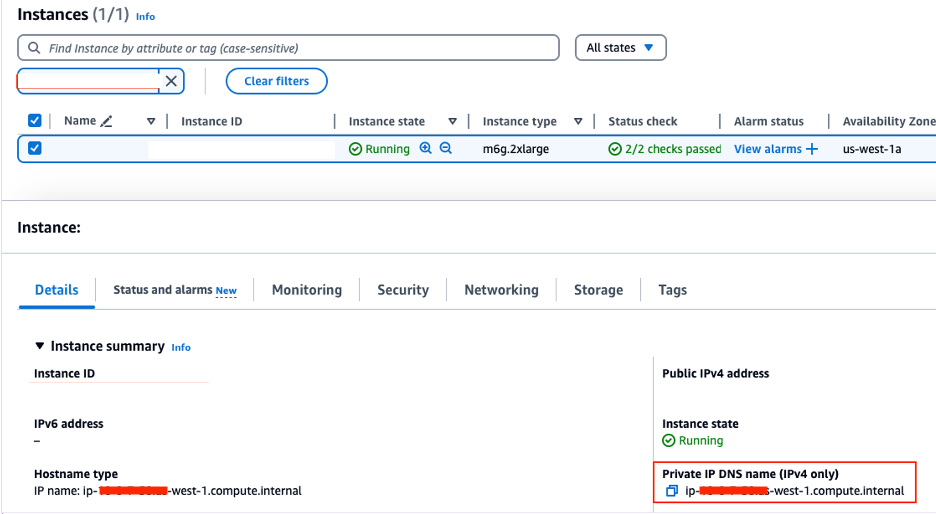
- In the producer account, on the Amazon EMR console, navigate to the primary node EC2 instance to get the value for Private IP DNS name (IPv4 only) (for example,
ip-xx-x-x-xx.us-west-1.compute.internal).
- Switch to the catalog account and deploy the AWS Glue Data Catalog federation Lambda function (GlueDataCatalogFederation-HiveMetastore).
The default Region is set to us-east-1. Change it to your desired Region before deploying the function.
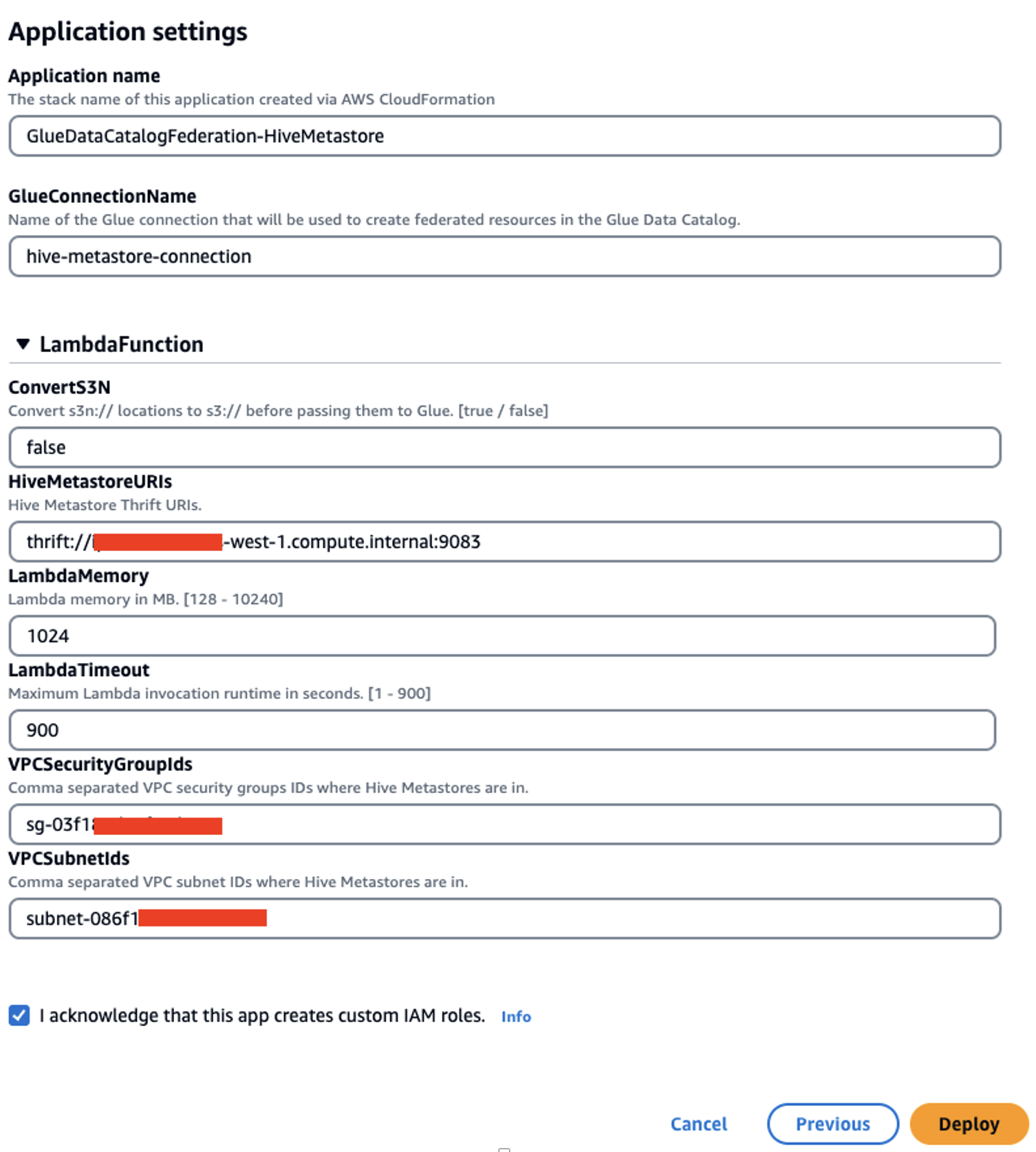
Use the VPC that was used as the CloudFormation input for the VPC CIDR. You can use the VPC’s default security group ID. If using another security group, make sure the outbound allows traffic to 0.0.0.0/0.
Next, you create a federated database in Lake Formation.
- On the Lake Formation console, choose Data sharing in the navigation pane.
- Choose Create database.
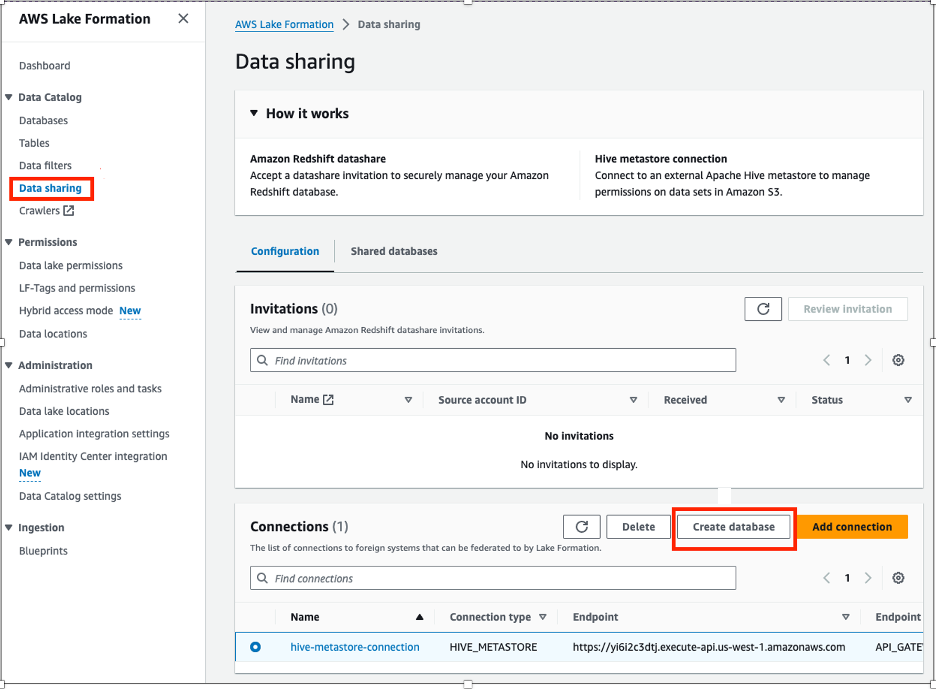
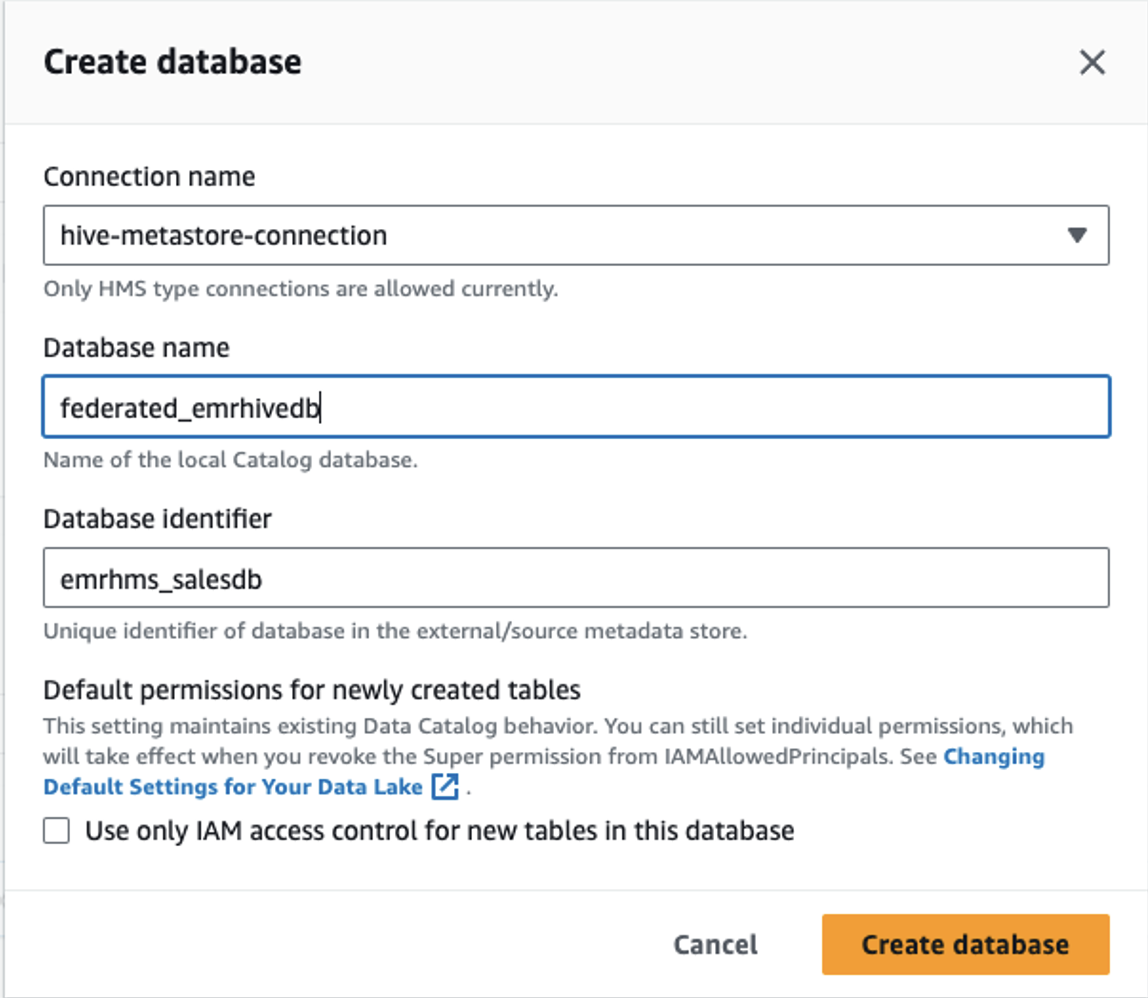
- Provide the following information:
- For Connection name, choose your connection.
- For Database name, enter a name for your database.
- For Database identifier, enter
emrhms_salesdb(this is the database created on the EMR Hive metastore).
- Choose Create database.
- On the Databases page, select the database and on the Actions menu, choose Grant to grant describe permissions to the consumer account.
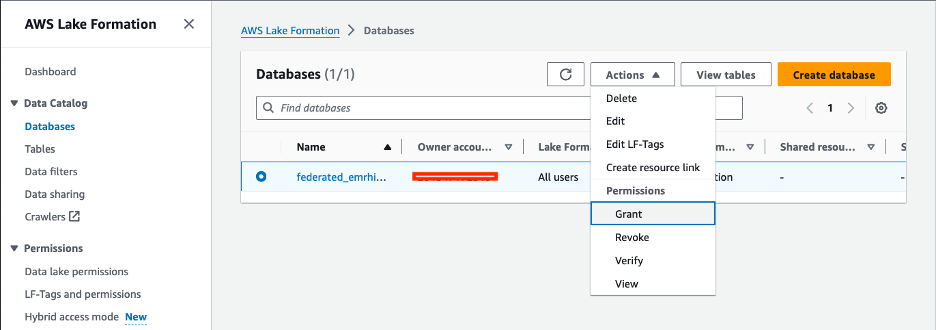
- Under Principals, select External accounts and choose your account ARN.
- Under LF-Tags or catalog resources, select Named Data Catalog resources and choose your database and table.
- Under Table permissions, provide the following information:
- For Table permissions¸ select Select and Describe.
- For Grantable permissions¸ select Select and Describe.
- Under Data permissions, select All data access.
- Choose Grant.
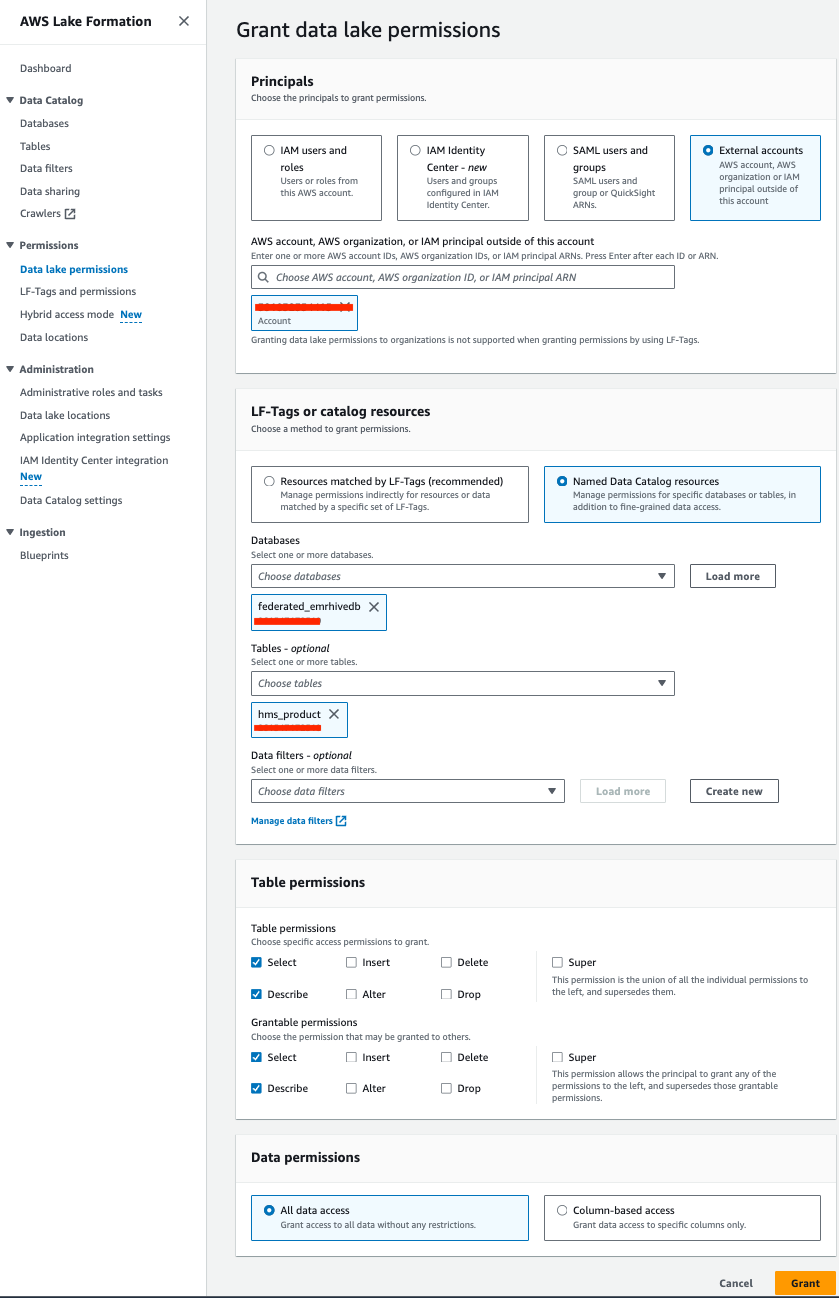
- On the Tables page, select your table and on the Actions menu, choose Grant to grant select and describe permissions.
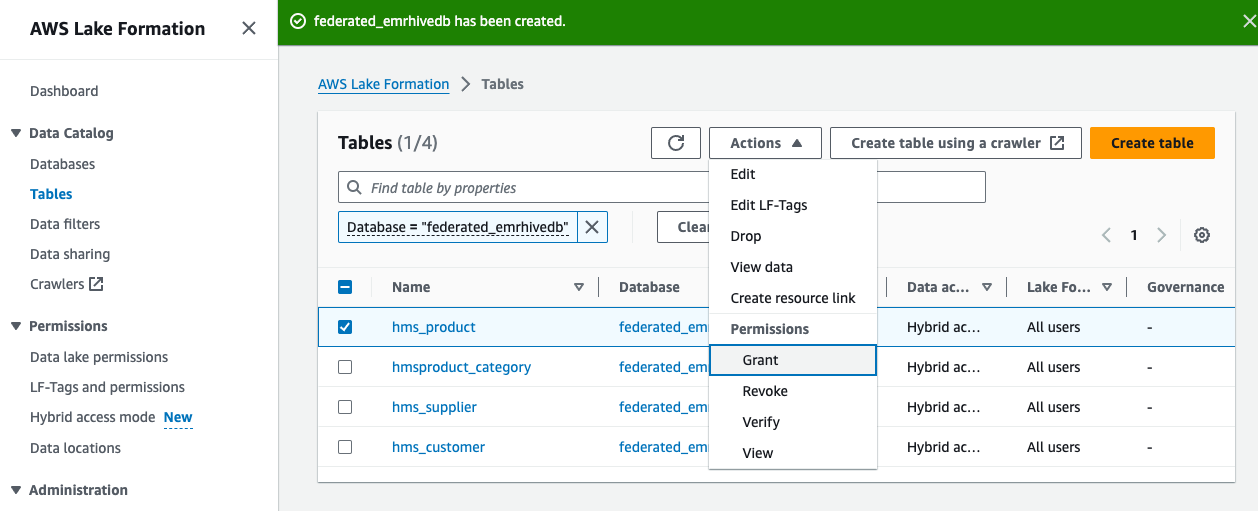
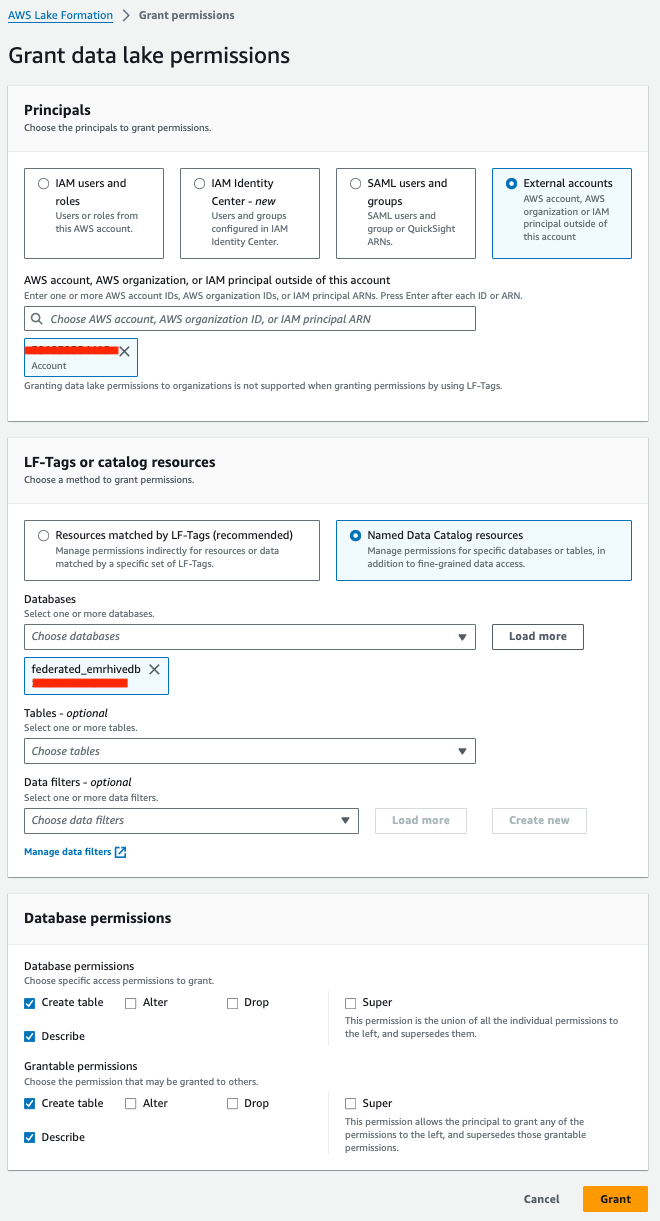
- Under Principals, select External accounts and choose your account ARN.
- Under LF-Tags or catalog resources, select Named Data Catalog resources and choose your database.
- Under Database permissions¸ provide the following information:
- For Database permissions¸ select Create table and Describe.
- For Grantable permissions¸ select Create table and Describe.
- Choose Grant.
Set up the consumer account
Consumers include data analysts who run queries on the data lake, data scientists who prepare data for ML models and conduct exploratory analysis, as well as downstream systems that run batch jobs on the data within the data lake.
The consumer account setup in this section shows how you can query the shared Hive metastore data using Athena for the data analyst persona, EMR Serverless to run batch scripts, and SageMaker Studio for the data scientist to further use data in the downstream model building process.
For EMR Serverless and SageMaker Studio, if you’re using the default IAM service role, add the required Data Catalog and Lake Formation IAM permissions to the role and use Lake Formation to grant table permission access to the role’s ARN.
Data analyst use case
In this section, we demonstrate how a data analyst can query the Hive metastore data using Athena. Before you get started, on the Lake Formation console, add the IAM role or user deploying the CloudFormation stack as the data lake admin.
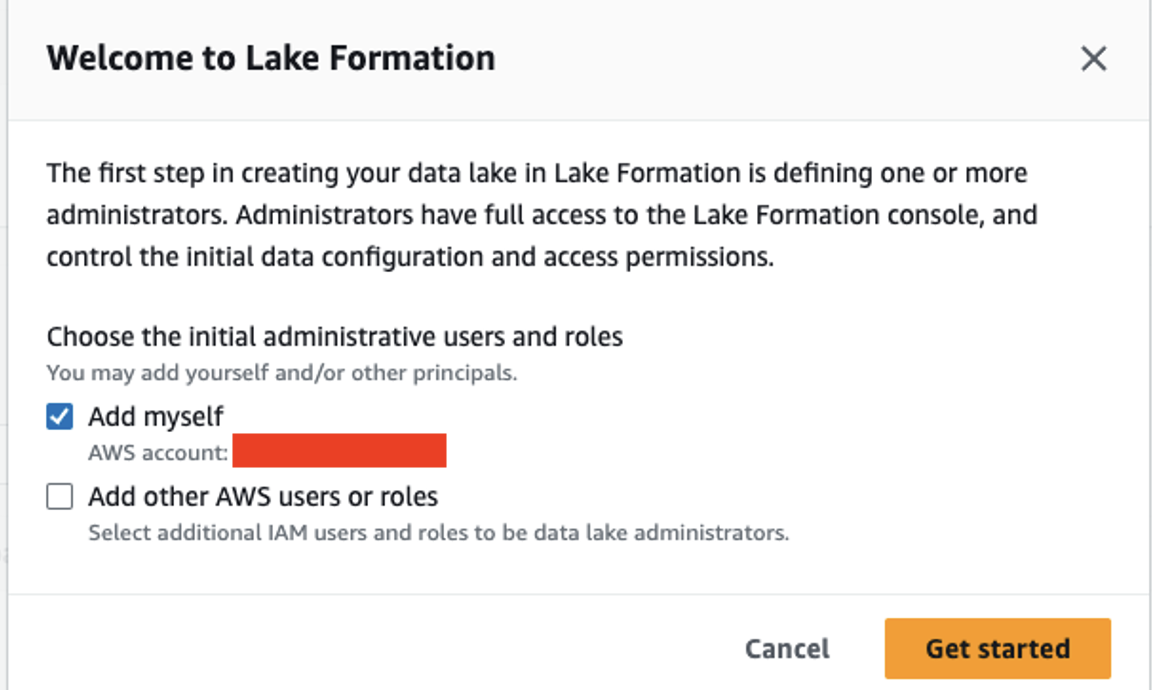
Then complete the following steps:
- Run the CloudFormation template CONSUMER.yml.
- If the catalog and consumer accounts are not part of the organization in AWS Organizations, navigate to the AWS Resource Access Manager (AWS RAM) console and manually accept the resources shared from the catalog account.
- On the Lake Formation console, on the Databases page, select your database and on the Actions menu, choose Create resource link.
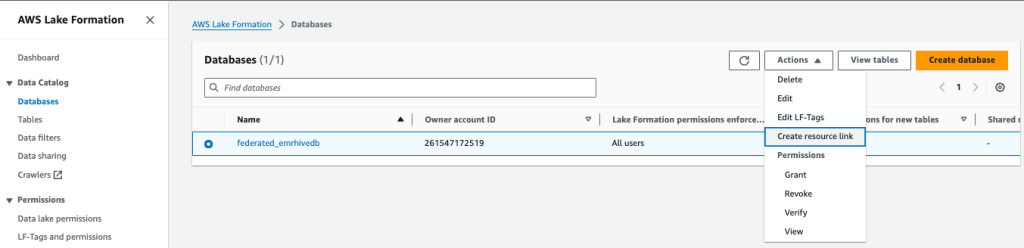
- Under Database resource link details, provide the following information:
- For Resource link name, enter a name.
- For Shared database’s region, choose a Region.
- For Shared database, choose your database.
- For Shared database’s owner ID, enter the account ID.
- Choose Create.
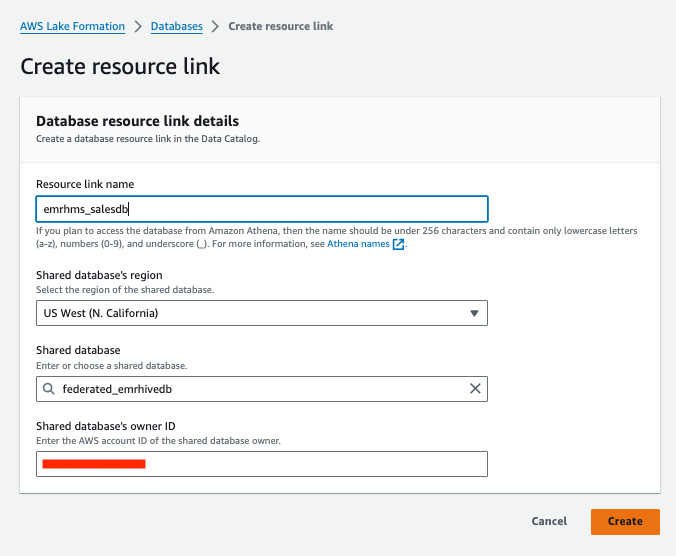
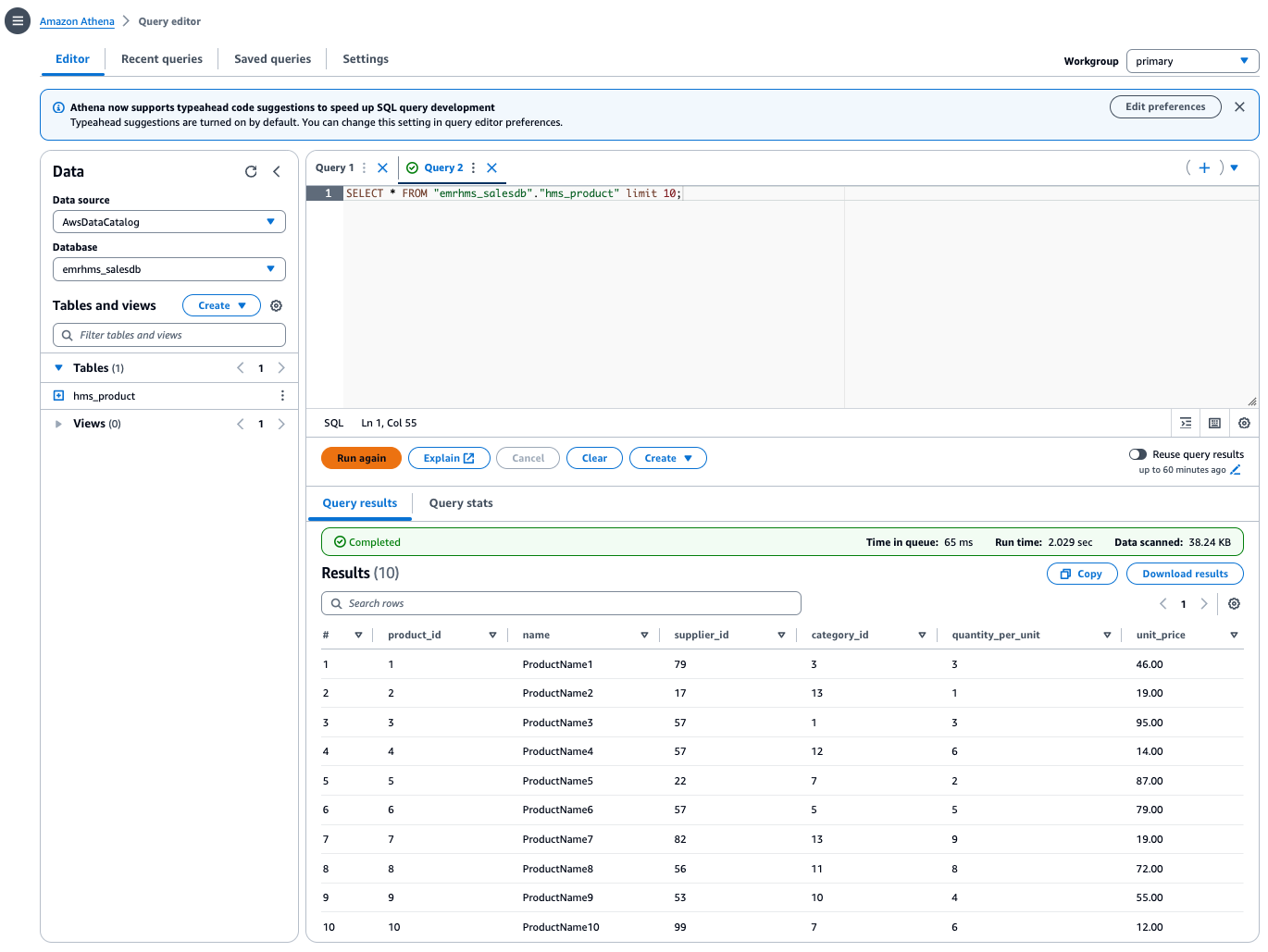
Now you can use Athena to query the table on the consumer side, as shown in the following screenshot.
Batch job use case
Complete the following steps to set up EMR Serverless to run a sample Spark job to query the existing table:
- On the Amazon EMR console, choose EMR Serverless in the navigation pane.
- Choose Get started.

- Choose Create and launch EMR Studio.
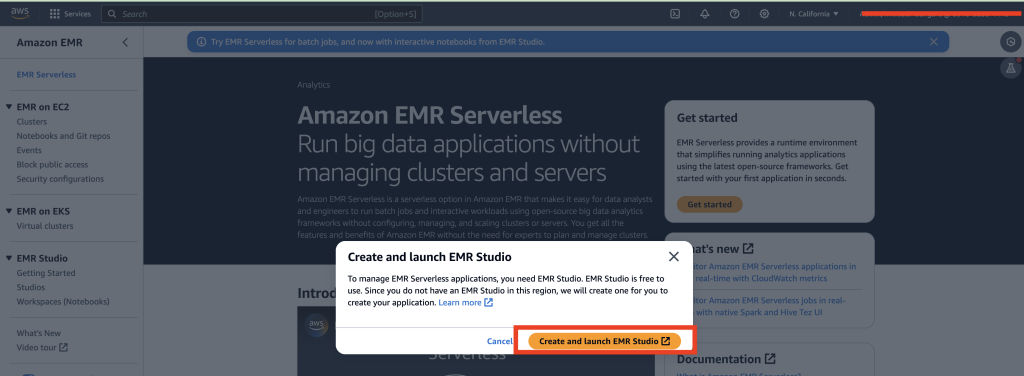
- Under Application settings, provide the following information:
- For Name, enter a name.
- For Type, choose Spark.
- For Release version, choose the current version.
- For Architecture, select x86_64.
- Under Application setup options, select Use custom settings.
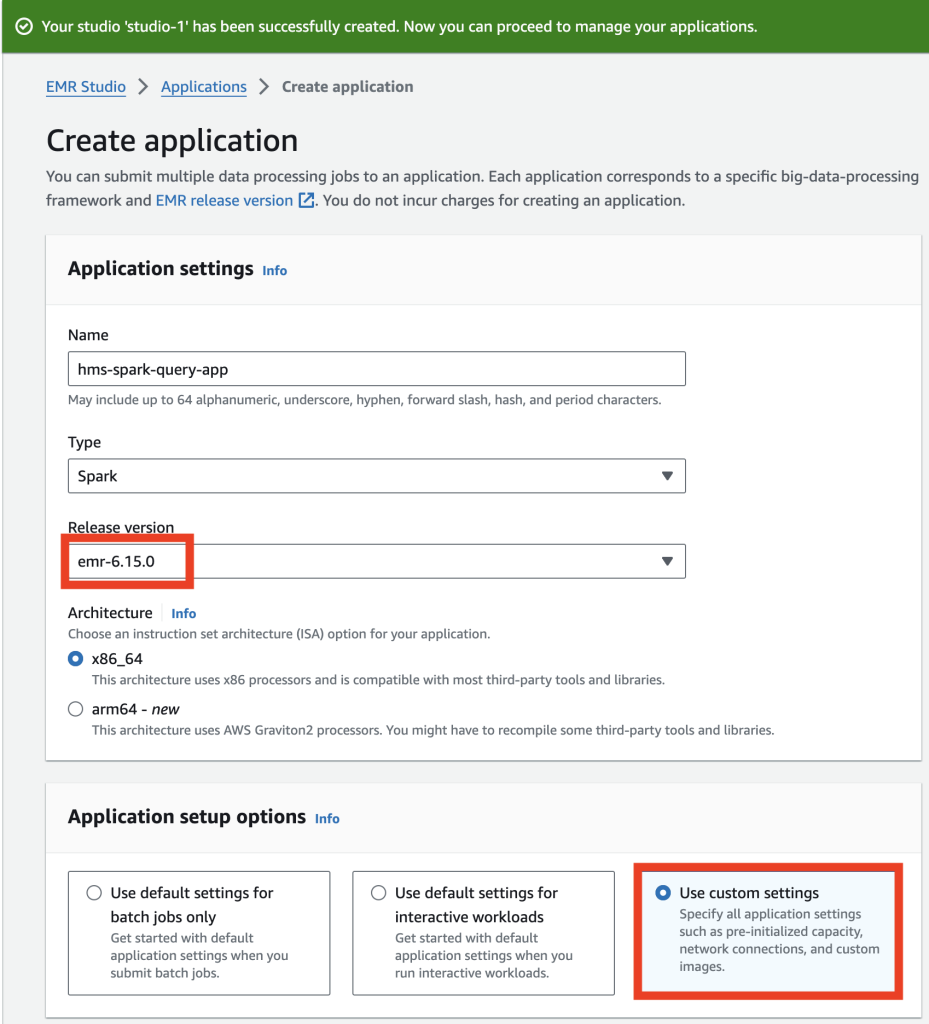
- Under Additional configurations, for Metastore configuration, select Use AWS Glue Data Catalog as metastore, then select Use Lake Formation for fine-grained access control.
- Choose Create and start application.
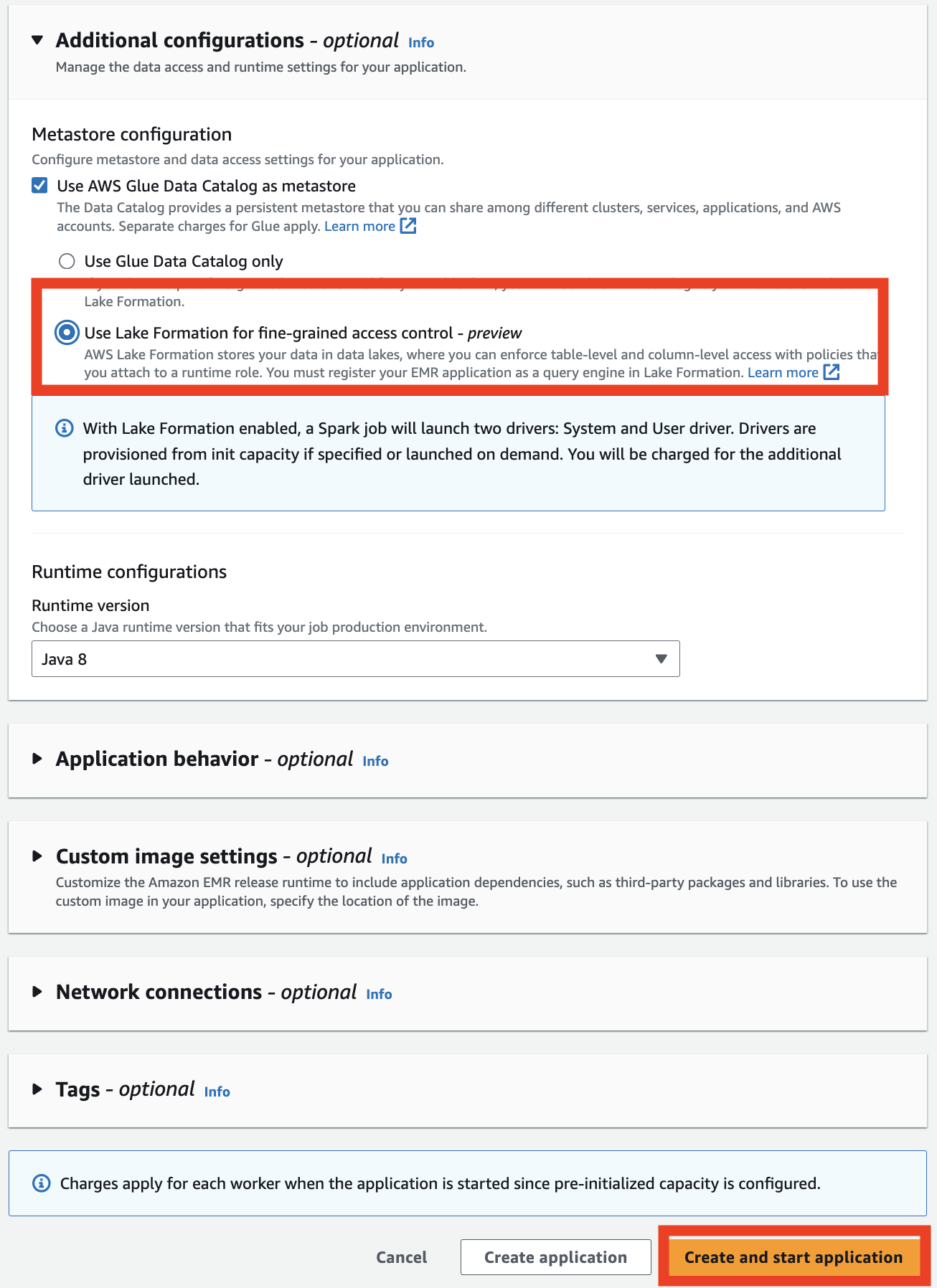
- On the application details page, on the Job runs tab, choose Submit job run.
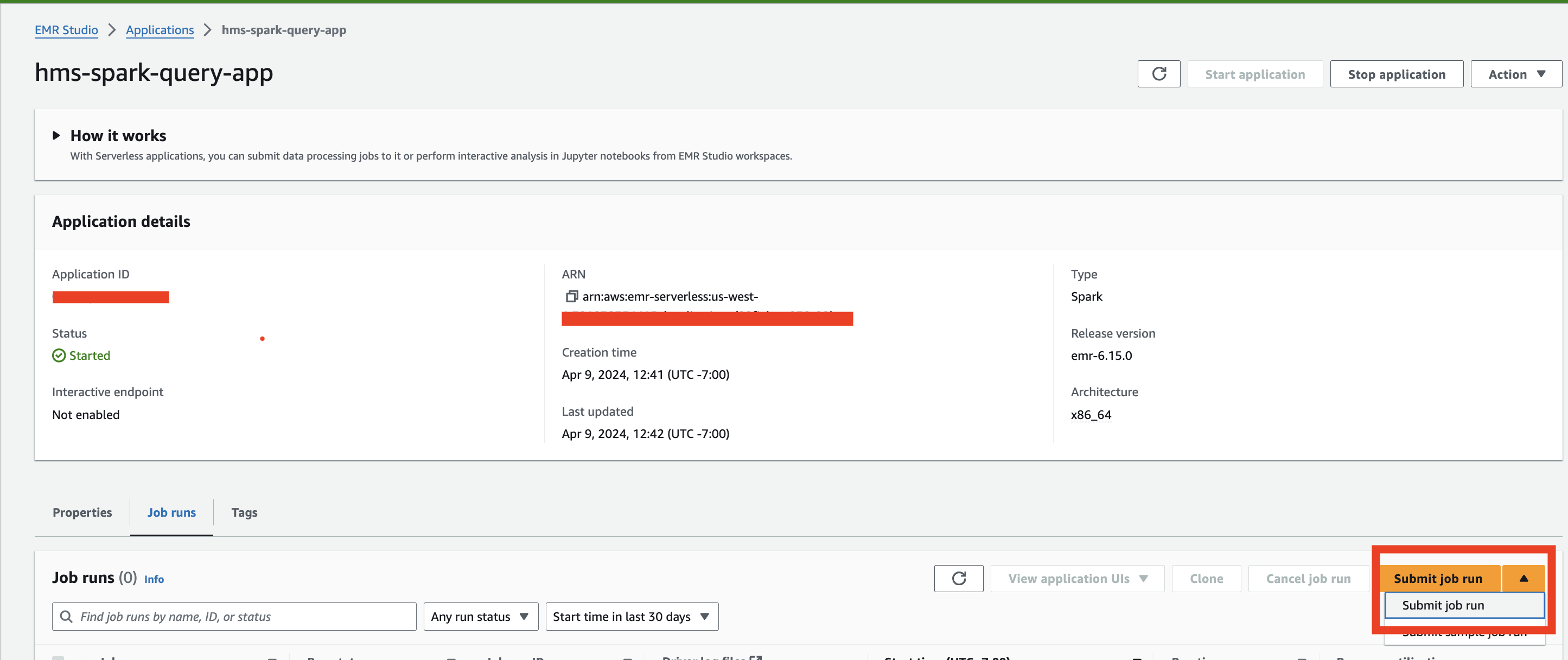
- Under Job details, provide the following information:
- For Name, enter a name.
- For Runtime role¸ choose Create new role.
- Note the IAM role that gets created.
- For Script location, enter the S3 bucket location created by the CloudFormation template (the script is
emr-serverless-query-script.py).
- Choose Submit job run.
- Add the following AWS Glue access policy to the IAM role created in the previous step (provide your Region and the account ID of your catalog account):
- Add the following Lake Formation access policy:
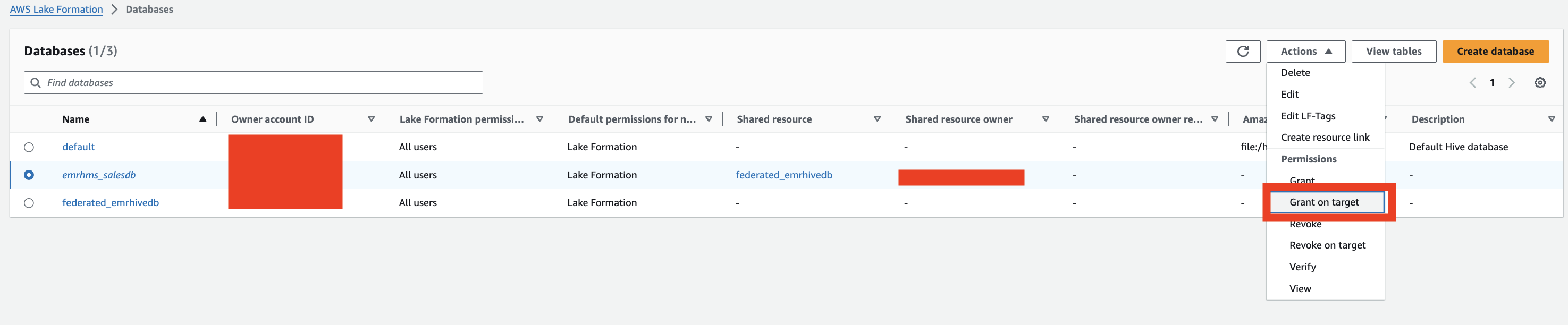
- On the Databases page, select the database and on the Actions menu, choose Grant to grant Lake Formation access to the EMR Serverless runtime role.
- Under Principals, select IAM users and roles and choose your role.
- Under LF-Tags or catalog resources, select Named Data Catalog resources and choose your database.
- Under Resource link permissions, for Resource link permissions, select Describe.
- Choose Grant.
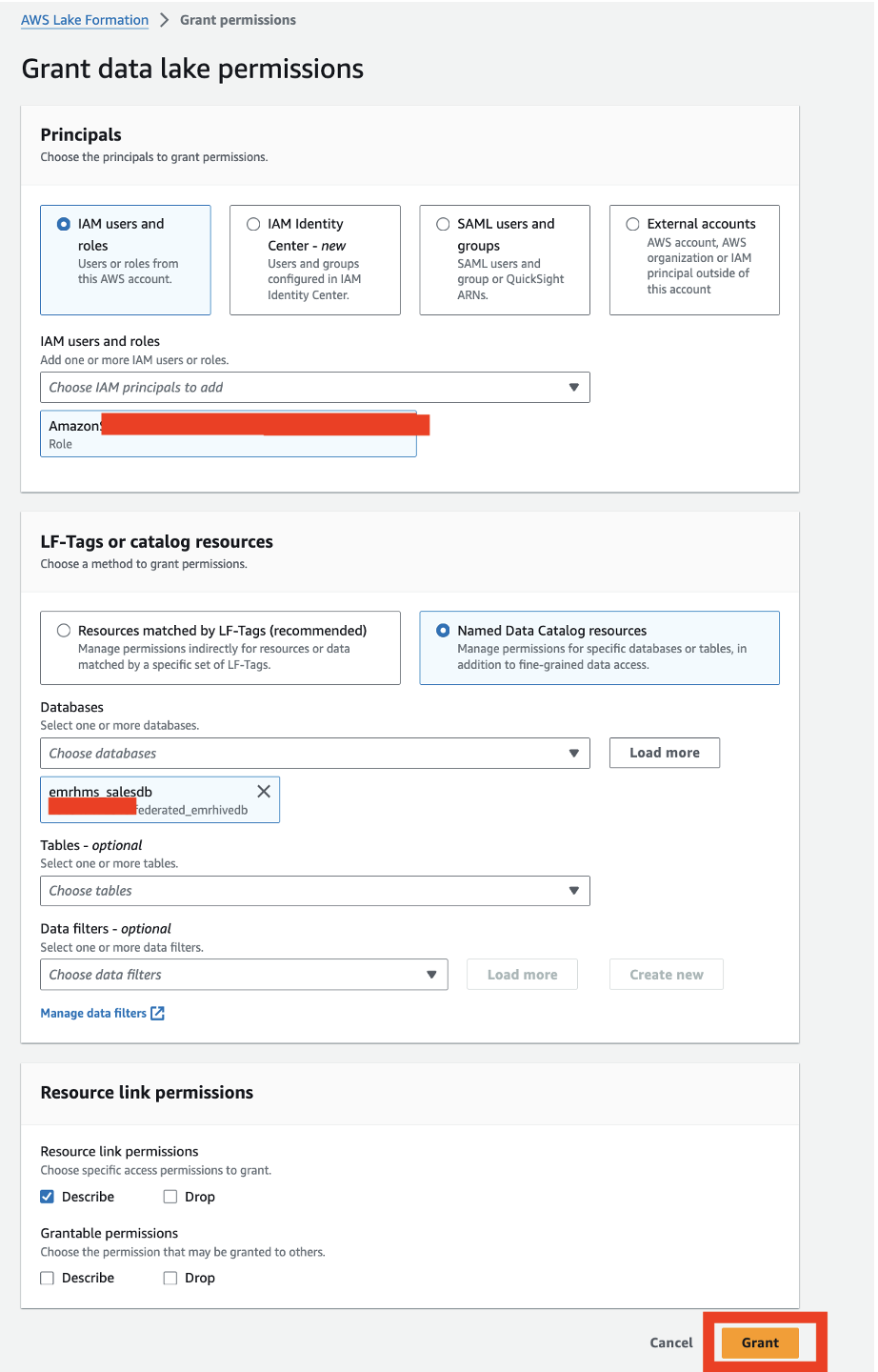
- On the Databases page, select the database and on the Actions menu, choose Grant on target.
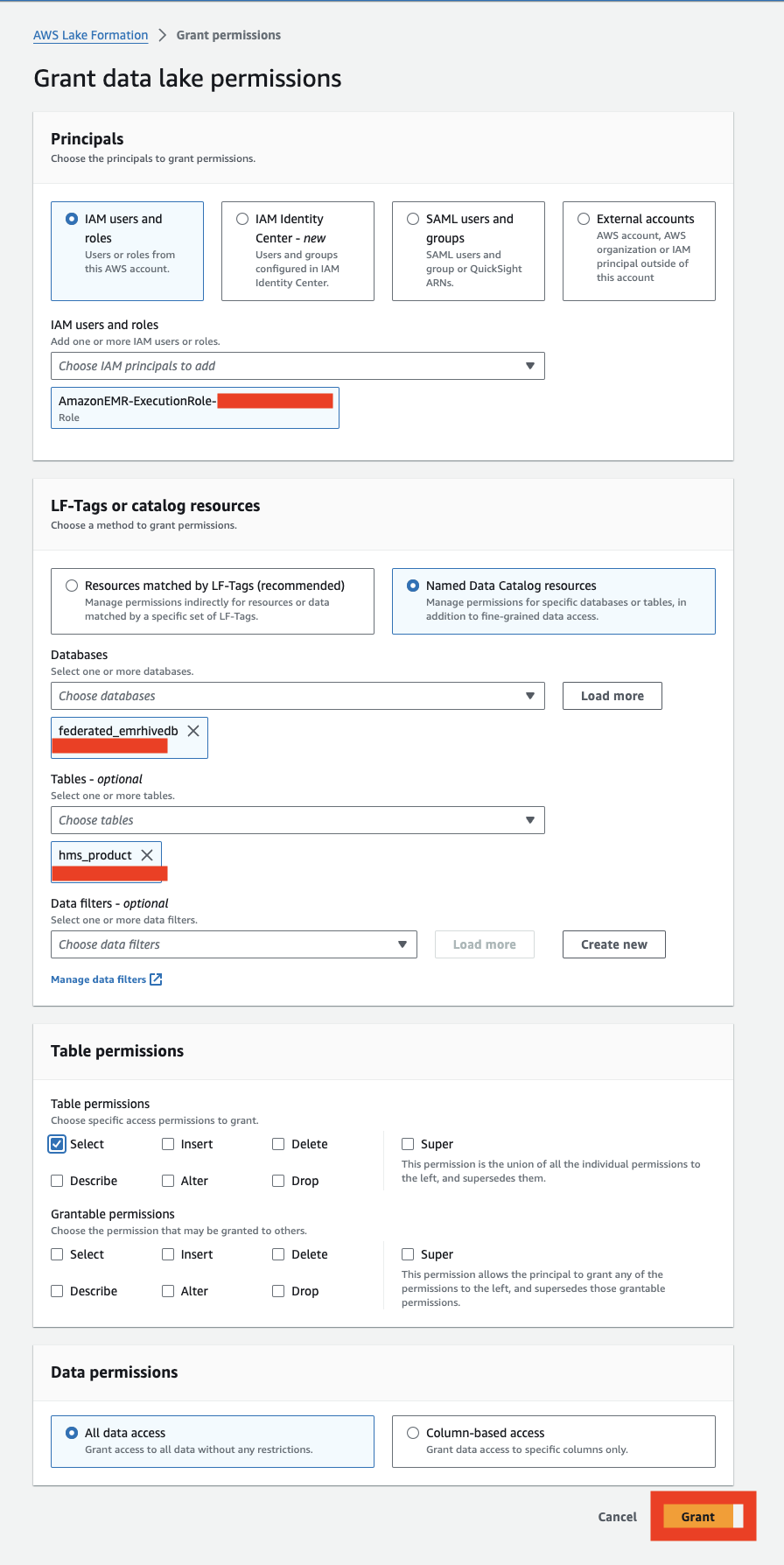
- Provide the following information:
- Under Principals, select IAM users and roles and choose your role.
- Under LF-Tags or catalog resources, select Named Data Catalog resources and choose your database and table
- Under Table permissions, for Table permissions, select Select.
- Under Data permissions, select All data access.
- Choose Grant.
- Submit the job again by cloning it.
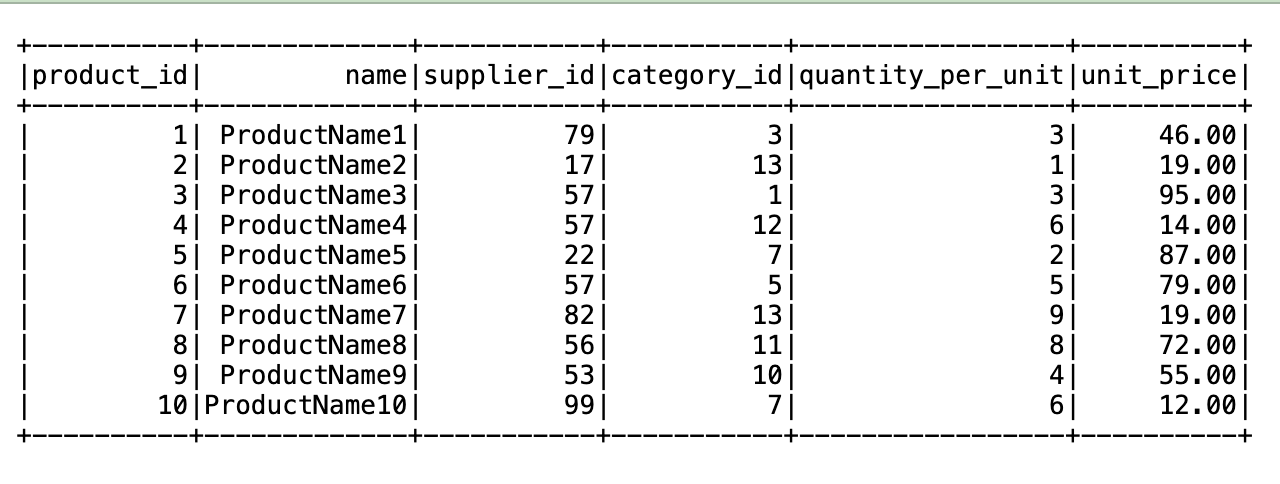
- When the job is complete, choose View logs.
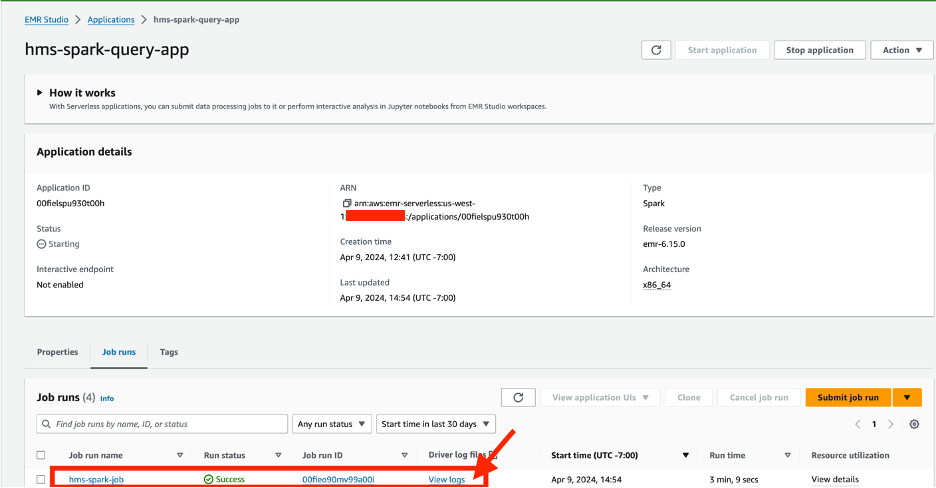
The output should look like the following screenshot.
Data scientist use case
For this use case, a data scientist queries the data through SageMaker Studio. Complete the following steps:
- Set up SageMaker Studio.
- Confirm that the domain user role has been granted permission by Lake Formation to SELECT data from the table.
- Follow steps similar to the batch run use case to grant access.
The following screenshot shows an example notebook.
Clean up
We recommend deleting the CloudFormation stack after use, because the deployed resources will incur costs. There are no prerequisites to delete the producer, catalog, and consumer CloudFormation stacks. To delete the Hive metastore connector stack on the catalog account (serverlessrepo-GlueDataCatalogFederation-HiveMetastore), first delete the federated database you created.
Conclusion
In this post, we explained how to create a federated Hive metastore for deploying a data mesh architecture with multiple Hive data warehouses across EMR clusters.
By using Data Catalog metadata federation, organizations can construct a sophisticated data architecture. This approach not only seamlessly extends your Hive data warehouse but also consolidates access control and fosters integration with various AWS analytics services. Through effective data governance and meticulous orchestration of the data mesh architecture, organizations can provide data integrity, regulatory compliance, and enhanced data sharing across EMR clusters.
We encourage you to check out the features of the AWS Glue Hive metastore federation connector and explore how to implement a data mesh architecture across multiple EMR clusters. To learn more and get started, refer to the following resources:
About the Authors
 Sudipta Mitra is a Senior Data Architect for AWS, and passionate about helping customers to build modern data analytics applications by making innovative use of latest AWS services and their constantly evolving features. A pragmatic architect who works backwards from customer needs, making them comfortable with the proposed solution, helping achieve tangible business outcomes. His main areas of work are Data Mesh, Data Lake, Knowledge Graph, Data Security and Data Governance.
Sudipta Mitra is a Senior Data Architect for AWS, and passionate about helping customers to build modern data analytics applications by making innovative use of latest AWS services and their constantly evolving features. A pragmatic architect who works backwards from customer needs, making them comfortable with the proposed solution, helping achieve tangible business outcomes. His main areas of work are Data Mesh, Data Lake, Knowledge Graph, Data Security and Data Governance.
 Deepak Sharma is a Senior Data Architect with the AWS Professional Services team, specializing in big data and analytics solutions. With extensive experience in designing and implementing scalable data architectures, he collaborates closely with enterprise customers to build robust data lakes and advanced analytical applications on the AWS platform.
Deepak Sharma is a Senior Data Architect with the AWS Professional Services team, specializing in big data and analytics solutions. With extensive experience in designing and implementing scalable data architectures, he collaborates closely with enterprise customers to build robust data lakes and advanced analytical applications on the AWS platform.
 Nanda Chinnappa is a Cloud Infrastructure Architect with AWS Professional Services at Amazon Web Services. Nanda specializes in Infrastructure Automation, Cloud Migration, Disaster Recovery and Databases which includes Amazon RDS and Amazon Aurora. He helps AWS Customer’s adopt AWS Cloud and realize their business outcome by executing cloud computing initiatives.
Nanda Chinnappa is a Cloud Infrastructure Architect with AWS Professional Services at Amazon Web Services. Nanda specializes in Infrastructure Automation, Cloud Migration, Disaster Recovery and Databases which includes Amazon RDS and Amazon Aurora. He helps AWS Customer’s adopt AWS Cloud and realize their business outcome by executing cloud computing initiatives.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/design-a-data-mesh-pattern-for-amazon-emr-based-data-lakes-using-aws-lake-formation-with-hive-metastore-federation/

