Die Einführung von ChatGPT und die zunehmende Beliebtheit der generativen KI haben die Fantasie von Kunden beflügelt, die neugierig sind, wie sie diese Technologie nutzen können, um neue Produkte und Dienste auf AWS zu erstellen, beispielsweise Unternehmens-Chatbots, die eher auf Konversation ausgerichtet sind. In diesem Beitrag erfahren Sie, wie Sie eine Web-Benutzeroberfläche erstellen können, die wir Chat Studio nennen, um eine Konversation zu starten und mit den in verfügbaren Foundation-Modellen zu interagieren Amazon SageMaker-JumpStart wie Llama 2, Stable Diffusion und andere Modelle, die auf verfügbar sind Amazon Sage Maker. Nachdem Sie diese Lösung bereitgestellt haben, können Benutzer schnell loslegen und über eine Weboberfläche die Funktionen mehrerer Basismodelle in der Konversations-KI erleben.
Chat Studio kann optional auch den Endpunkt des Stable Diffusion-Modells aufrufen, um eine Collage relevanter Bilder und Videos zurückzugeben, wenn der Benutzer die Anzeige von Medien anfordert. Diese Funktion kann dazu beitragen, das Benutzererlebnis durch die Verwendung von Medien als begleitende Assets zur Antwort zu verbessern. Dies ist nur ein Beispiel dafür, wie Sie Chat Studio mit zusätzlichen Integrationen bereichern können, um Ihre Ziele zu erreichen.
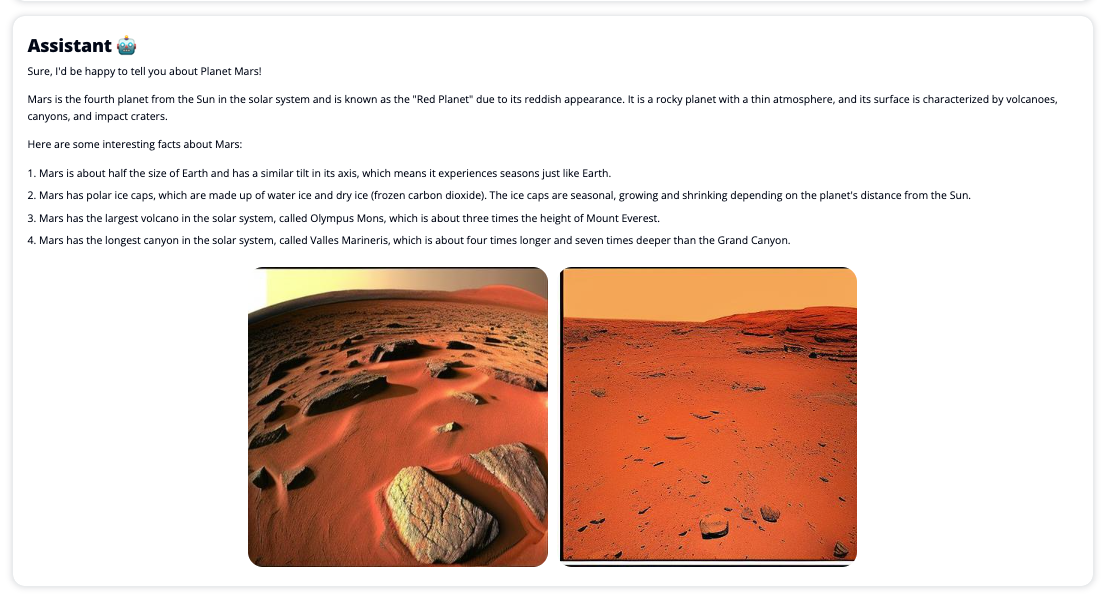
Die folgenden Screenshots zeigen Beispiele dafür, wie eine Benutzeranfrage und -antwort aussieht.

Große Sprachmodelle
Generative KI-Chatbots wie ChatGPT basieren auf großen Sprachmodellen (LLMs), die auf einem neuronalen Deep-Learning-Netzwerk basieren, das auf großen Mengen unbeschrifteten Textes trainiert werden kann. Der Einsatz von LLMs ermöglicht ein besseres Gesprächserlebnis, das den Interaktionen mit echten Menschen sehr ähnlich ist, wodurch ein Gefühl der Verbundenheit und eine höhere Benutzerzufriedenheit gefördert wird.
SageMaker-Grundlagenmodelle
Im Jahr 2021 bezeichnete das Stanford Institute for Human-Centered Artificial Intelligence einige LLMs als Gründungsmodelle. Grundlagenmodelle werden anhand eines großen und breiten Satzes allgemeiner Daten vorab trainiert und sollen als Grundlage für weitere Optimierungen in einer Vielzahl von Anwendungsfällen dienen, von der Generierung digitaler Kunst bis hin zur Klassifizierung mehrsprachiger Texte. Diese Basismodelle sind bei Kunden beliebt, da das Training eines neuen Modells von Grund auf zeitaufwändig und teuer sein kann. SageMaker JumpStart bietet Zugriff auf Hunderte von Basismodellen, die von Open-Source- und proprietären Drittanbietern verwaltet werden.
Lösungsüberblick
Dieser Beitrag führt Sie durch einen Low-Code-Workflow für die Bereitstellung vorab trainierter und benutzerdefinierter LLMs über SageMaker und die Erstellung einer Web-Benutzeroberfläche als Schnittstelle zu den bereitgestellten Modellen. Wir decken die folgenden Schritte ab:
- Stellen Sie SageMaker-Grundlagenmodelle bereit.
- Deploy AWS Lambda und AWS Identity and Access Management and (IAM)-Berechtigungen verwenden AWS CloudFormation.
- Richten Sie die Benutzeroberfläche ein und führen Sie sie aus.
- Fügen Sie optional weitere SageMaker-Grundlagenmodelle hinzu. Dieser Schritt erweitert die Fähigkeit von Chat Studio, mit zusätzlichen Basismodellen zu interagieren.
- Stellen Sie die Anwendung optional mit bereit AWS verstärken. Mit diesem Schritt wird Chat Studio im Web bereitgestellt.
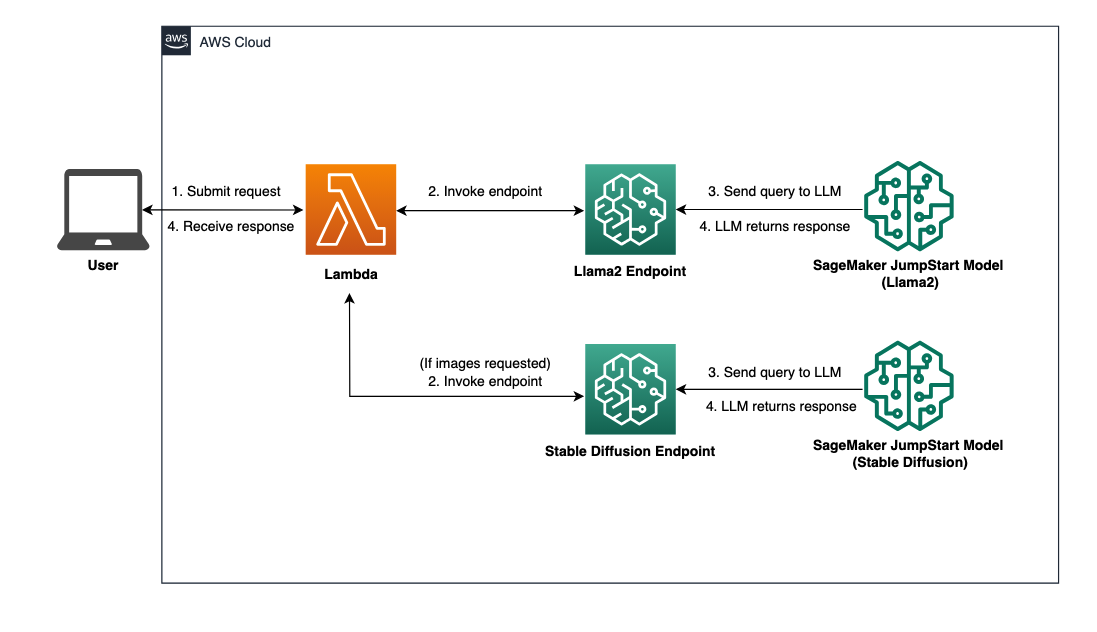
Einen Überblick über die Lösungsarchitektur finden Sie im folgenden Diagramm.
Voraussetzungen:
Um durch die Lösung zu gehen, müssen Sie die folgenden Voraussetzungen erfüllen:
- An AWS-Konto mit ausreichenden IAM-Benutzerrechten.
npmin Ihrer lokalen Umgebung installiert. Anweisungen zur Installation finden Sie hiernpm, beziehen auf Node.js und npm herunterladen und installieren.- Ein Dienstkontingent von 1 für die entsprechenden SageMaker-Endpunkte. Für Llama 2 13b Chat verwenden wir eine ml.g5.48xlarge-Instanz und für Stable Diffusion 2.1 eine ml.p3.2xlarge-Instanz.
Um eine Erhöhung des Servicekontingents anzufordern, klicken Sie auf: AWS Service Quotas-Konsole, navigiere zu AWS-Services, SageMakerund Anforderung einer Dienstkontingenterhöhung auf einen Wert von 1 für ml.g5.48xlarge für die Endpunktnutzung und ml.p3.2xlarge für die Endpunktnutzung.
Abhängig von der Verfügbarkeit des Instanztyps kann es einige Stunden dauern, bis die Dienstkontingentanfrage genehmigt wird.
Stellen Sie SageMaker-Grundlagenmodelle bereit
SageMaker ist ein vollständig verwalteter Dienst für maschinelles Lernen (ML), mit dem Entwickler schnell und einfach ML-Modelle erstellen und trainieren können. Führen Sie die folgenden Schritte aus, um die Grundmodelle Llama 2 13b Chat und Stable Diffusion 2.1 bereitzustellen Amazon SageMaker-Studio:
- Erstellen Sie eine SageMaker-Domäne. Anweisungen finden Sie unter Onboarding zur Amazon SageMaker-Domäne mithilfe der Schnelleinrichtung.
Eine Domäne richtet den gesamten Speicher ein und ermöglicht Ihnen das Hinzufügen von Benutzern für den Zugriff auf SageMaker.
- Wählen Sie in der SageMaker-Konsole Studio im Navigationsbereich und wählen Sie dann aus Open Studio.
- Beim Starten von Studio unter SageMaker-JumpStart Wählen Sie im Navigationsbereich Modelle, Notizbücher, Lösungen.
- Suchen Sie in der Suchleiste nach „Llama 2 13b Chat“.
- Der BereitstellungskonfigurationZ. SageMaker-Hostinginstanz, wählen ml.g5.48xgroß und für Endpunktname, eingeben
meta-textgeneration-llama-2-13b-f. - Auswählen Bereitstellen.
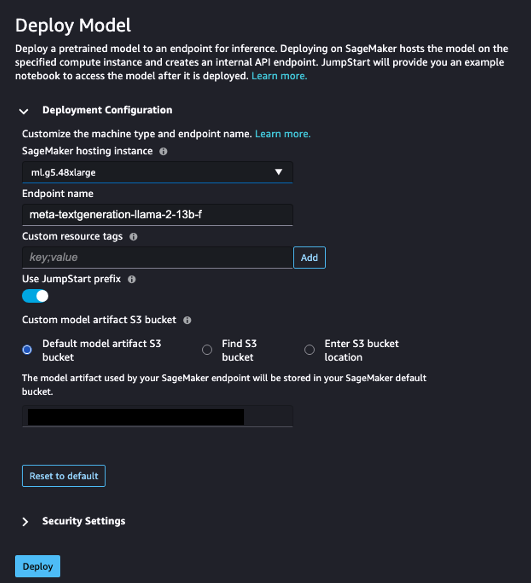
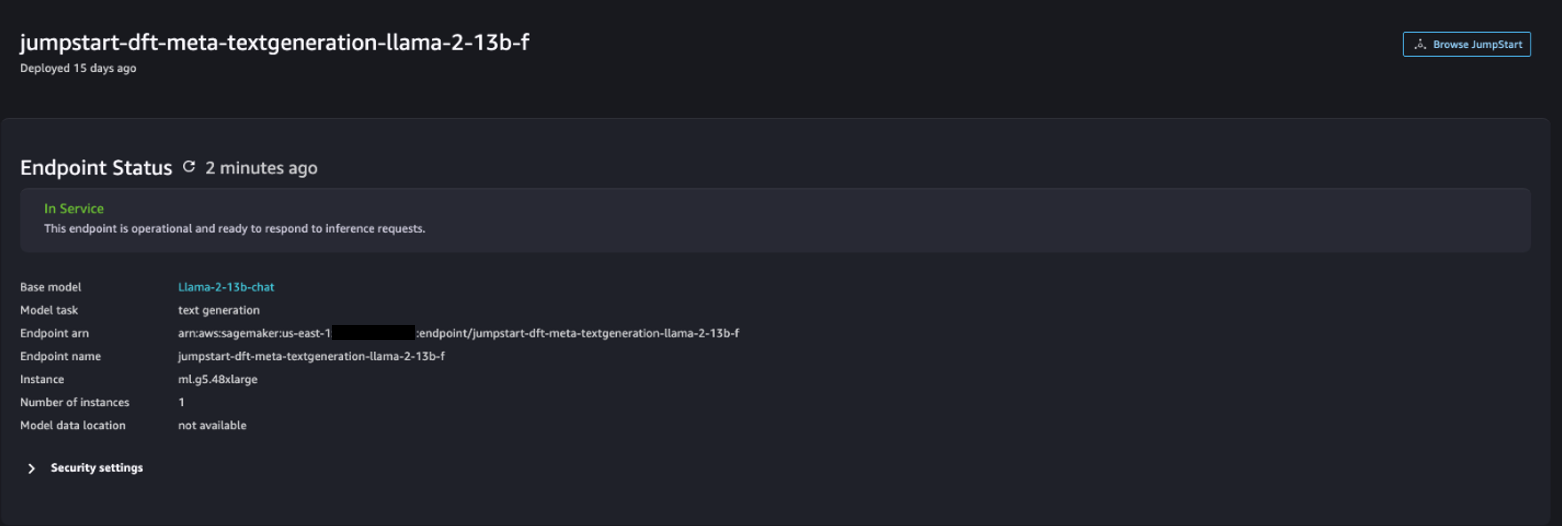
Nachdem die Bereitstellung erfolgreich war, sollten Sie Folgendes sehen können In Service Status.
- Auf dem Modelle, Notizbücher, Lösungen Suchen Sie auf der Seite nach Stable Diffusion 2.1.
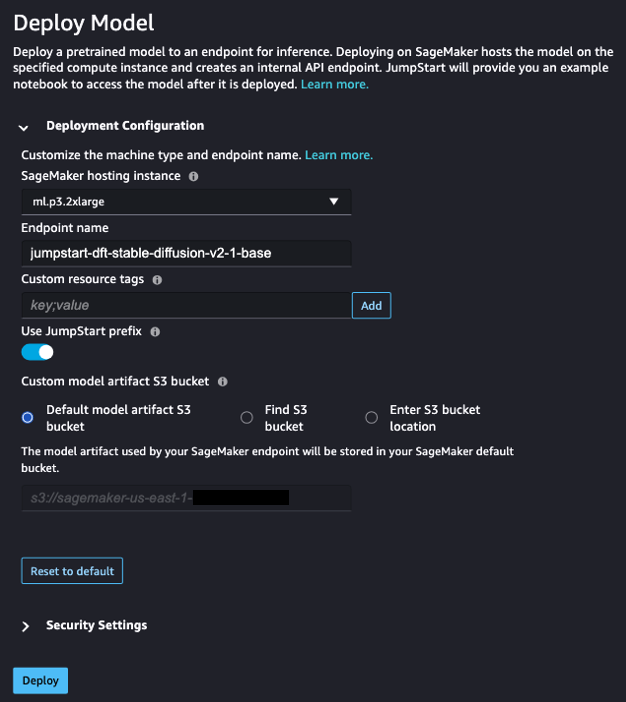
- Der BereitstellungskonfigurationZ. SageMaker-Hostinginstanz, wählen ml.p3.2xgroß und für Endpunktname, eingeben
jumpstart-dft-stable-diffusion-v2-1-base. - Auswählen Deploy.
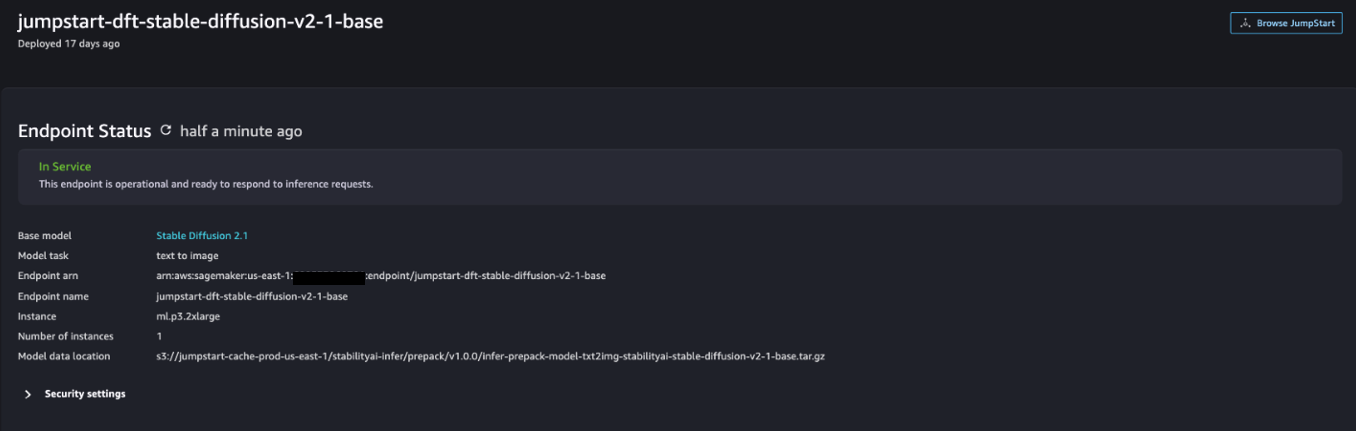
Nachdem die Bereitstellung erfolgreich war, sollten Sie Folgendes sehen können In Service Status.
Stellen Sie Lambda- und IAM-Berechtigungen mithilfe von AWS CloudFormation bereit
In diesem Abschnitt wird beschrieben, wie Sie einen CloudFormation-Stack starten können, der eine Lambda-Funktion bereitstellt, die Ihre Benutzeranfrage verarbeitet, den von Ihnen bereitgestellten SageMaker-Endpunkt aufruft und alle erforderlichen IAM-Berechtigungen bereitstellt. Führen Sie die folgenden Schritte aus:
- Navigieren Sie zu der GitHub-Repository und laden Sie die CloudFormation-Vorlage herunter (
lambda.cfn.yaml) auf Ihren lokalen Computer. - Wählen Sie in der CloudFormation-Konsole die aus Stapel erstellen Dropdown-Menü und wählen Sie Mit neuen Ressourcen (Standard).
- Auf dem Vorlage angeben Seite auswählen Laden Sie eine Vorlagendatei hoch und Datei auswählen.
- Wähle die
lambda.cfn.yamlDatei, die Sie heruntergeladen haben, und wählen Sie dann Weiter. - Auf dem Geben Sie die Stapeldetails an Geben Sie auf der Seite „Stack“ einen Stack-Namen und den API-Schlüssel ein, den Sie in den Voraussetzungen erhalten haben, und wählen Sie dann „ Weiter.
- Auf dem Konfigurieren Sie die Stapeloptionen Seite wählen Weiter.
- Überprüfen und bestätigen Sie die Änderungen und wählen Sie aus Absenden.
Richten Sie die Web-Benutzeroberfläche ein
In diesem Abschnitt werden die Schritte zum Ausführen der Web-Benutzeroberfläche beschrieben (erstellt mit Cloudscape-Designsystem) auf Ihrem lokalen Computer:
- Navigieren Sie in der IAM-Konsole zum Benutzer
functionUrl. - Auf dem Sicherheitsanmeldedaten Tab, wählen Sie Zugangsschlüssel erstellen.
- Auf dem Greifen Sie auf wichtige Best Practices und Alternativen zu Seite auswählen Befehlszeilenschnittstelle (CLI) und wählen Sie Weiter.
- Auf dem Beschreibungs-Tag festlegen Seite wählen Zugangsschlüssel erstellen.
- Kopieren Sie den Zugangsschlüssel und den geheimen Zugangsschlüssel.
- Auswählen Erledigt .
- Navigieren Sie zu der GitHub-Repository und laden Sie die
react-llm-chat-studioCode. - Starten Sie den Ordner in Ihrer bevorzugten IDE und öffnen Sie ein Terminal.
- Navigieren
src/configs/aws.jsonund geben Sie den Zugangsschlüssel und den geheimen Zugangsschlüssel ein, den Sie erhalten haben. - Geben Sie im Terminal folgende Befehle ein:
- Offen http://localhost:3000 in Ihrem Browser und beginnen Sie mit Ihren Modellen zu interagieren!
Um Chat Studio zu verwenden, wählen Sie im Dropdown-Menü ein Basismodell aus und geben Sie Ihre Anfrage in das Textfeld ein. Um KI-generierte Bilder zusammen mit der Antwort zu erhalten, fügen Sie am Ende Ihrer Abfrage den Ausdruck „mit Bildern“ hinzu.
Fügen Sie weitere SageMaker-Grundlagenmodelle hinzu
Sie können die Leistungsfähigkeit dieser Lösung weiter erweitern, um zusätzliche SageMaker-Grundlagenmodelle einzubeziehen. Da jedes Modell beim Aufruf seines SageMaker-Endpunkts unterschiedliche Eingabe- und Ausgabeformate erwartet, müssen Sie Transformationscode in die Lambda-Funktion callSageMakerEndpoints schreiben, um eine Schnittstelle mit dem Modell herzustellen.
In diesem Abschnitt werden die allgemeinen Schritte und Codeänderungen beschrieben, die zum Implementieren eines zusätzlichen Modells Ihrer Wahl erforderlich sind. Beachten Sie, dass für die Schritte 6–8 Grundkenntnisse der Python-Sprache erforderlich sind.
- Stellen Sie in SageMaker Studio das SageMaker-Grundmodell Ihrer Wahl bereit.
- Auswählen SageMaker-JumpStart und Starten Sie JumpStart-Assets.
- Wählen Sie Ihren neu bereitgestellten Modellendpunkt aus und wählen Sie Notizbuch öffnen.
- Suchen Sie auf der Notebook-Konsole nach den Nutzlastparametern.
Dies sind die Felder, die das neue Modell erwartet, wenn es seinen SageMaker-Endpunkt aufruft. Der folgende Screenshot zeigt ein Beispiel.

- Navigieren Sie auf der Lambda-Konsole zu
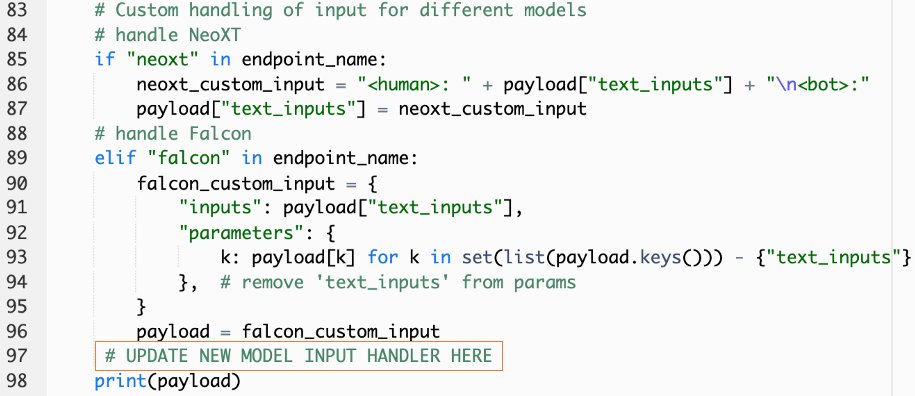
callSageMakerEndpoints. - Fügen Sie einen benutzerdefinierten Eingabehandler für Ihr neues Modell hinzu.
Im folgenden Screenshot haben wir die Eingabe für Falcon 40B Instruct BF16 und GPT NeoXT Chat Base 20B FP16 transformiert. Sie können Ihre benutzerdefinierte Parameterlogik wie angegeben einfügen, um die Eingabetransformationslogik mit Bezug auf die von Ihnen kopierten Nutzlastparameter hinzuzufügen.
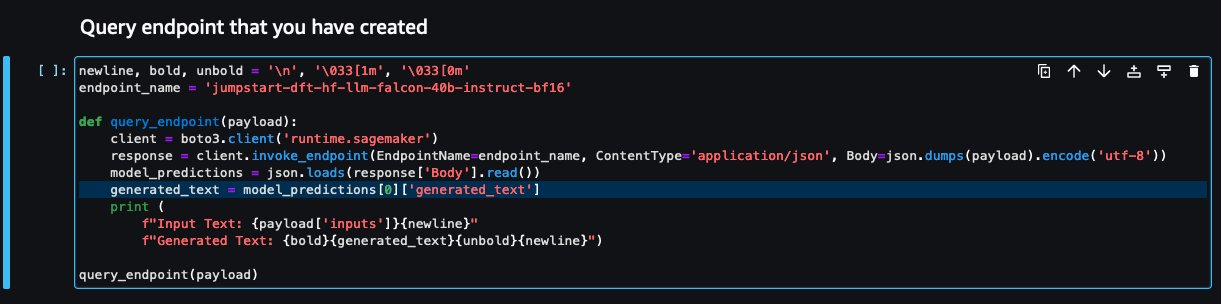
- Kehren Sie zur Notebook-Konsole zurück und suchen Sie
query_endpoint.
Diese Funktion gibt Ihnen eine Vorstellung davon, wie Sie die Ausgabe der Modelle transformieren können, um die endgültige Textantwort zu extrahieren.
- Mit Bezug auf den Code in
query_endpoint, fügen Sie einen benutzerdefinierten Ausgabehandler für Ihr neues Modell hinzu.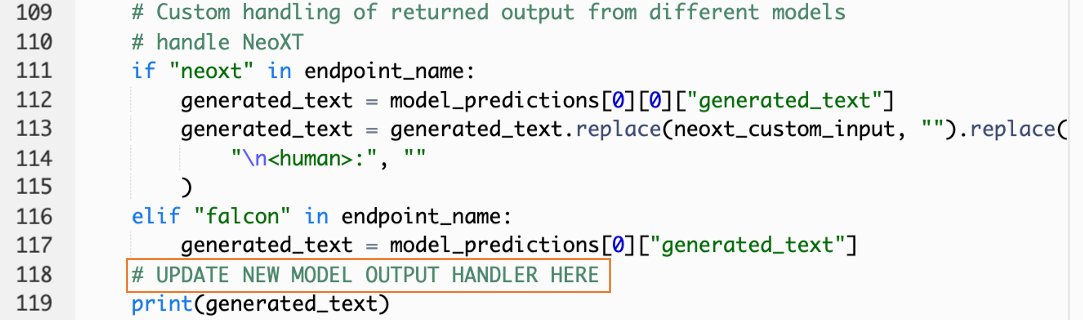
- Auswählen Bereitstellen.
- Öffnen Sie Ihre IDE, starten Sie die
react-llm-chat-studioGeben Sie den Code ein und navigieren Sie zusrc/configs/models.json. - Fügen Sie Ihren Modellnamen und Modellendpunkt hinzu und geben Sie die Nutzlastparameter aus Schritt 4 unten ein
payloadmit dem folgenden Format: - Aktualisieren Sie Ihren Browser, um mit Ihrem neuen Modell zu interagieren!
Stellen Sie die Anwendung mit Amplify bereit
Amplify ist eine Komplettlösung, mit der Sie Ihre Anwendung schnell und effizient bereitstellen können. In diesem Abschnitt werden die Schritte zum Bereitstellen von Chat Studio auf einem beschrieben Amazon CloudFront Verteilung mit Amplify, wenn Sie Ihre Anwendung mit anderen Benutzern teilen möchten.
- Navigieren Sie zu der
react-llm-chat-studioCodeordner, den Sie zuvor erstellt haben. - Geben Sie im Terminal die folgenden Befehle ein und folgen Sie den Setup-Anweisungen:
- Initialisieren Sie ein neues Amplify-Projekt mit dem folgenden Befehl. Geben Sie einen Projektnamen ein, akzeptieren Sie die Standardkonfigurationen und wählen Sie AWS-Zugriffsschlüssel wenn Sie aufgefordert werden, die Authentifizierungsmethode auszuwählen.
- Hosten Sie das Amplify-Projekt mit dem folgenden Befehl. Wählen Amazon CloudFront und S3 wenn Sie aufgefordert werden, den Plugin-Modus auszuwählen.
- Erstellen Sie abschließend das Projekt und stellen Sie es mit dem folgenden Befehl bereit:
- Öffnen Sie nach erfolgreicher Bereitstellung die in Ihrem Browser angegebene URL und beginnen Sie mit der Interaktion mit Ihren Modellen!
Aufräumen
Führen Sie die folgenden Schritte aus, um zukünftige Gebühren zu vermeiden:
- Löschen Sie den CloudFormation-Stack. Anweisungen finden Sie unter Löschen eines Stacks in der AWS CloudFormation-Konsole.
- Löschen Sie den SageMaker JumpStart-Endpunkt. Anweisungen finden Sie unter Endpunkte und Ressourcen löschen.
- Löschen Sie die SageMaker-Domäne. Anweisungen finden Sie unter Löschen Sie eine Amazon SageMaker-Domäne.
Zusammenfassung
In diesem Beitrag haben wir erklärt, wie man eine Web-Benutzeroberfläche für die Verbindung mit auf AWS bereitgestellten LLMs erstellt.
Mit dieser Lösung können Sie auf benutzerfreundliche Weise mit Ihrem LLM interagieren und ein Gespräch führen, um den LLM zu testen oder Fragen zu stellen und bei Bedarf eine Collage aus Bildern und Videos zu erhalten.
Sie können diese Lösung auf verschiedene Arten erweitern, z. B. um zusätzliche Fundamentmodelle zu integrieren, Integration mit Amazon Kendra um eine ML-gestützte intelligente Suche zum Verständnis von Unternehmensinhalten und mehr zu ermöglichen!
Wir laden Sie zum Experimentieren ein Verschiedene vorab trainierte LLMs sind auf AWS verfügbar, oder bauen Sie darauf auf oder erstellen Sie sogar Ihre eigenen LLMs in SageMaker. Teilen Sie uns Ihre Fragen und Erkenntnisse in den Kommentaren mit und haben Sie Spaß!
Über die Autoren
 Jarrett Yeo Shan Wei ist Associate Cloud Architect bei AWS Professional Services, der den öffentlichen Sektor in ASEAN abdeckt, und setzt sich dafür ein, Kunden bei der Modernisierung und Migration in die Cloud zu unterstützen. Er hat fünf AWS-Zertifizierungen erhalten und auf der 8. Internationalen KI-Konferenz einen Forschungsbericht über Maschinenensembles zur Gradientenverstärkung veröffentlicht. In seiner Freizeit konzentriert sich Jarrett auf die generative KI-Szene bei AWS und trägt dazu bei.
Jarrett Yeo Shan Wei ist Associate Cloud Architect bei AWS Professional Services, der den öffentlichen Sektor in ASEAN abdeckt, und setzt sich dafür ein, Kunden bei der Modernisierung und Migration in die Cloud zu unterstützen. Er hat fünf AWS-Zertifizierungen erhalten und auf der 8. Internationalen KI-Konferenz einen Forschungsbericht über Maschinenensembles zur Gradientenverstärkung veröffentlicht. In seiner Freizeit konzentriert sich Jarrett auf die generative KI-Szene bei AWS und trägt dazu bei.
 Tammy Lim Lee Xin ist Associate Cloud Architect bei AWS. Sie nutzt Technologie, um Kunden dabei zu helfen, die gewünschten Ergebnisse auf ihrem Weg zur Cloud-Einführung zu erzielen, und ist begeistert von KI/ML. Außerhalb der Arbeit reist sie gerne, wandert und verbringt Zeit mit Familie und Freunden.
Tammy Lim Lee Xin ist Associate Cloud Architect bei AWS. Sie nutzt Technologie, um Kunden dabei zu helfen, die gewünschten Ergebnisse auf ihrem Weg zur Cloud-Einführung zu erzielen, und ist begeistert von KI/ML. Außerhalb der Arbeit reist sie gerne, wandert und verbringt Zeit mit Familie und Freunden.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/create-a-web-ui-to-interact-with-llms-using-amazon-sagemaker-jumpstart/

