Amazon SageMaker-Studio bietet Datenwissenschaftlern eine vollständig verwaltete Lösung zum interaktiven Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen (ML). Bei der Arbeit an ihren ML-Aufgaben beginnen Datenwissenschaftler ihren Arbeitsablauf typischerweise damit, relevante Datenquellen zu entdecken und eine Verbindung zu ihnen herzustellen. Anschließend verwenden sie SQL, um Daten aus verschiedenen Quellen zu untersuchen, zu analysieren, zu visualisieren und zu integrieren, bevor sie sie in ihrem ML-Training und ihrer ML-Inferenz verwenden. Früher mussten Datenwissenschaftler häufig mit mehreren Tools zur Unterstützung von SQL in ihrem Arbeitsablauf jonglieren, was die Produktivität beeinträchtigte.
Wir freuen uns, Ihnen mitteilen zu können, dass JupyterLab-Notebooks in SageMaker Studio jetzt über integrierte Unterstützung für SQL verfügen. Datenwissenschaftler können jetzt:
- Stellen Sie eine Verbindung zu beliebten Datendiensten her, einschließlich Amazonas Athena, Amazon RedShift, Amazon DataZoneund Snowflake direkt in den Notizbüchern
- Durchsuchen und suchen Sie nach Datenbanken, Schemas, Tabellen und Ansichten und zeigen Sie Daten in der Vorschau in der Notebook-Oberfläche an
- Mischen Sie SQL- und Python-Code im selben Notebook, um Daten effizient zu erkunden und zu transformieren und in ML-Projekten zu verwenden
- Nutzen Sie Funktionen zur Entwicklerproduktivität wie SQL-Befehlsvervollständigung, Unterstützung bei der Codeformatierung und Syntaxhervorhebung, um die Codeentwicklung zu beschleunigen und die Gesamtproduktivität der Entwickler zu verbessern
Darüber hinaus können Administratoren Verbindungen zu diesen Datendiensten sicher verwalten, sodass Datenwissenschaftler auf autorisierte Daten zugreifen können, ohne die Anmeldeinformationen manuell verwalten zu müssen.
In diesem Beitrag führen wir Sie durch die Einrichtung dieser Funktion in SageMaker Studio und führen Sie durch die verschiedenen Funktionen dieser Funktion. Anschließend zeigen wir, wie Sie das SQL-Erlebnis im Notebook verbessern können, indem Sie die Text-to-SQL-Funktionen von Advanced Large Language Models (LLMs) nutzen, um komplexe SQL-Abfragen mit Text in natürlicher Sprache als Eingabe zu schreiben. Um es schließlich einem breiteren Benutzerpublikum zu ermöglichen, SQL-Abfragen aus Eingaben in natürlicher Sprache in ihren Notebooks zu generieren, zeigen wir Ihnen, wie Sie diese Text-to-SQL-Modelle mit bereitstellen Amazon Sage Maker Endpunkte.
Lösungsüberblick
Mit der SQL-Integration von SageMaker Studio JupyterLab Notebook können Sie jetzt eine Verbindung zu beliebten Datenquellen wie Snowflake, Athena, Amazon Redshift und Amazon DataZone herstellen. Mit dieser neuen Funktion können Sie verschiedene Funktionen ausführen.
Sie können beispielsweise Datenquellen wie Datenbanken, Tabellen und Schemata direkt aus Ihrem JupyterLab-Ökosystem visuell erkunden. Wenn Ihre Notebook-Umgebungen auf SageMaker Distribution 1.6 oder höher laufen, suchen Sie auf der linken Seite Ihrer JupyterLab-Oberfläche nach einem neuen Widget. Diese Ergänzung verbessert die Datenzugänglichkeit und -verwaltung in Ihrer Entwicklungsumgebung.
Wenn Sie derzeit nicht die empfohlene SageMaker-Distribution (1.5 oder niedriger) oder eine benutzerdefinierte Umgebung verwenden, finden Sie weitere Informationen im Anhang.
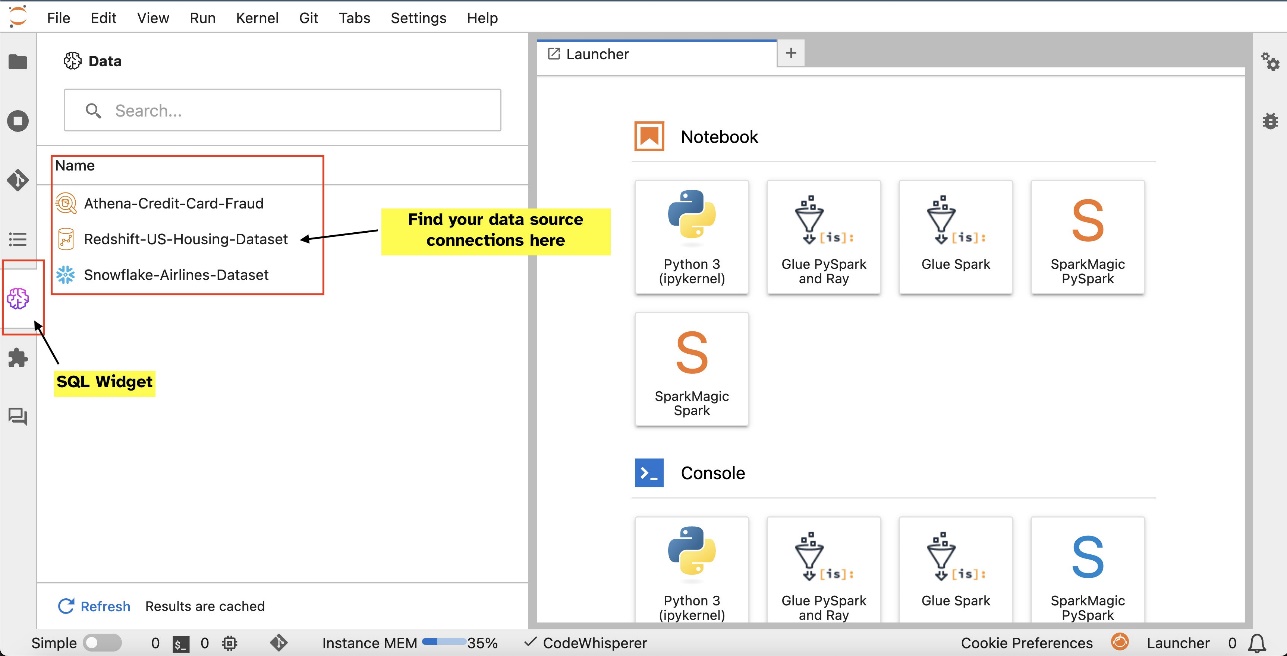
Nachdem Sie Verbindungen eingerichtet haben (siehe nächster Abschnitt), können Sie Datenverbindungen auflisten, Datenbanken und Tabellen durchsuchen und Schemata überprüfen.
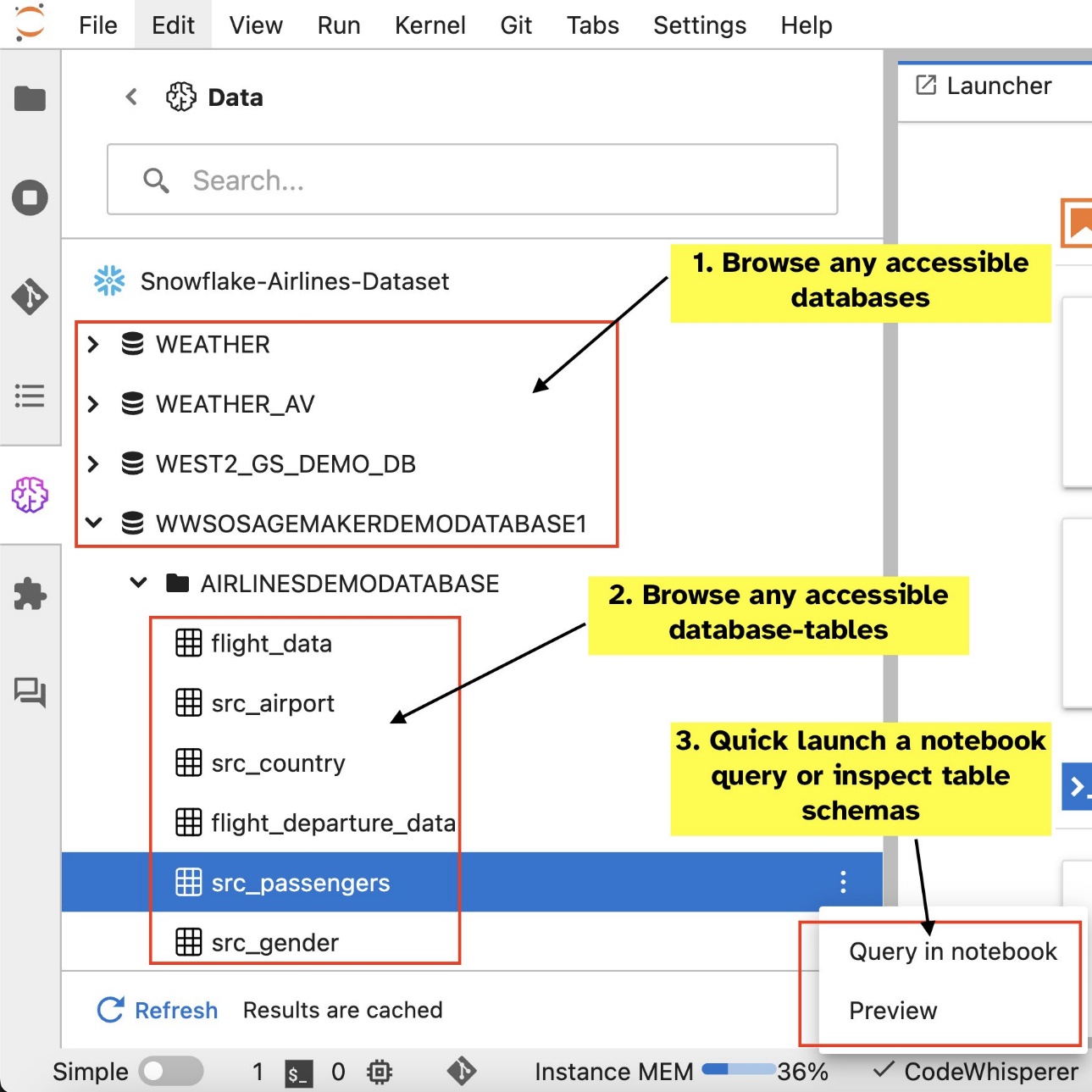
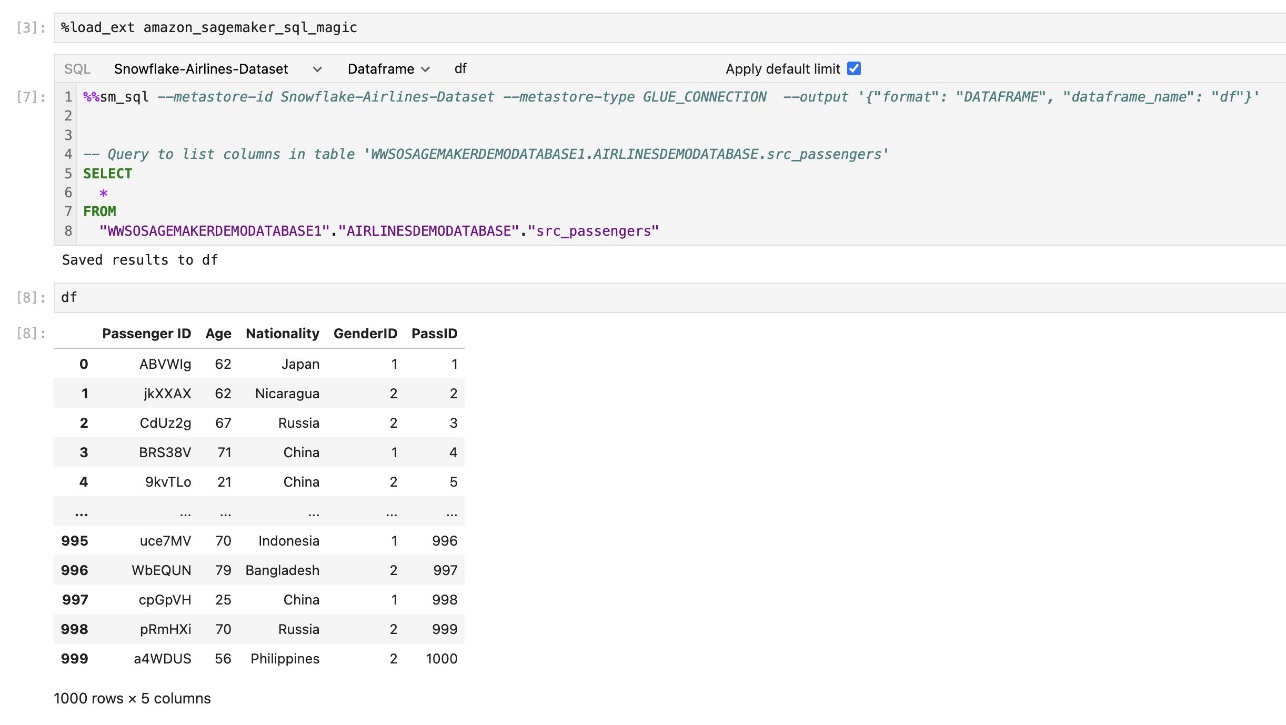
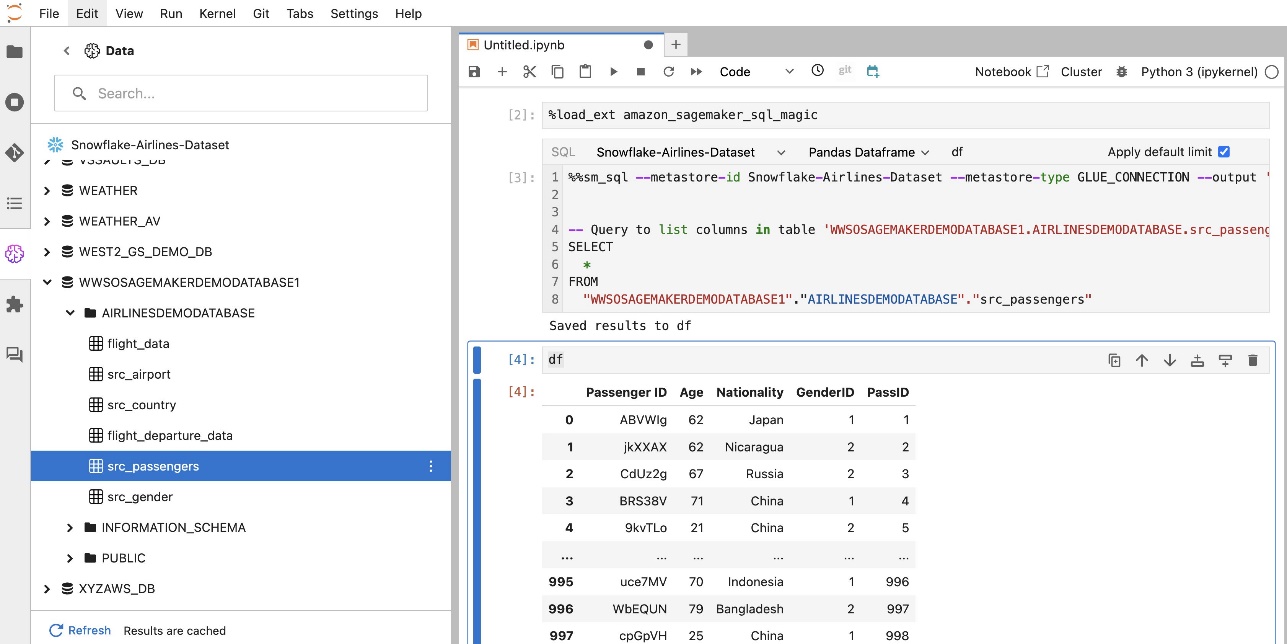
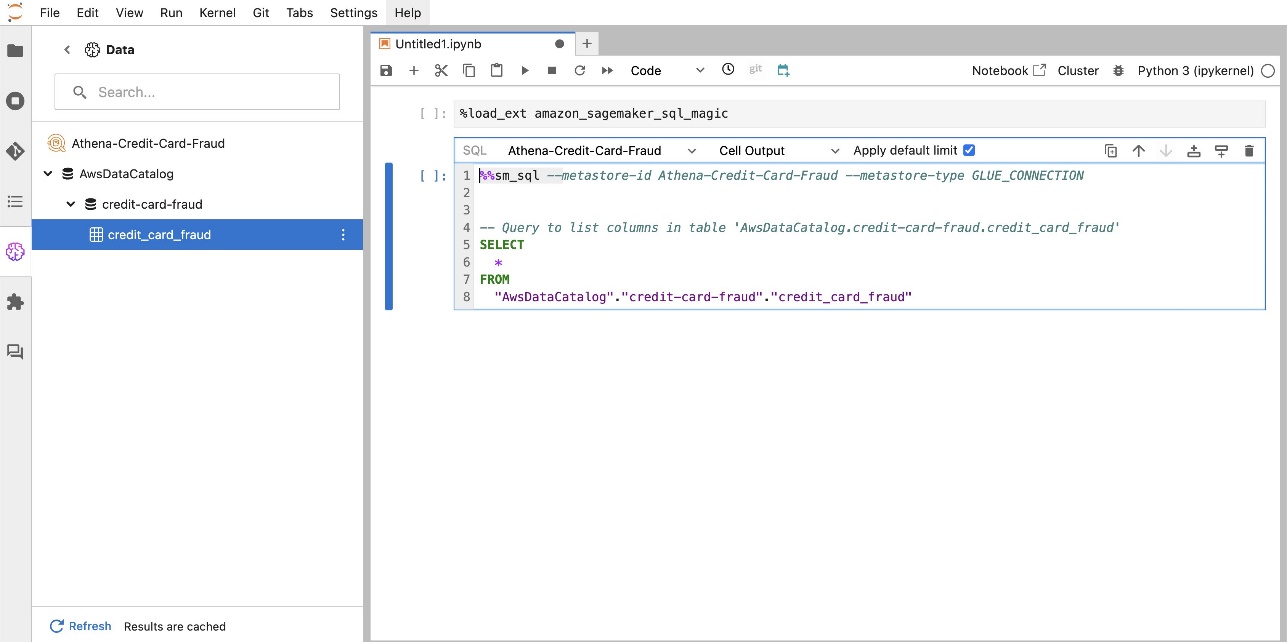
Mit der integrierten SQL-Erweiterung von SageMaker Studio JupyterLab können Sie SQL-Abfragen auch direkt von einem Notebook aus ausführen. Jupyter-Notebooks können mithilfe von zwischen SQL- und Python-Code unterscheiden %%sm_sql magischer Befehl, der oben in jeder Zelle platziert werden muss, die SQL-Code enthält. Dieser Befehl signalisiert JupyterLab, dass es sich bei den folgenden Anweisungen um SQL-Befehle und nicht um Python-Code handelt. Die Ausgabe einer Abfrage kann direkt im Notebook angezeigt werden, was die nahtlose Integration von SQL- und Python-Workflows in Ihre Datenanalyse erleichtert.
Die Ausgabe einer Abfrage kann visuell als HTML-Tabellen dargestellt werden, wie im folgenden Screenshot dargestellt.

Sie können auch an a geschrieben werden Pandas DataFrame.
Voraussetzungen:
Stellen Sie sicher, dass Sie die folgenden Voraussetzungen erfüllt haben, um die Notebook-SQL-Erfahrung von SageMaker Studio nutzen zu können:
- SageMaker Studio V2 – Stellen Sie sicher, dass Sie die aktuellste Version Ihres verwenden SageMaker Studio-Domäne und Benutzerprofile. Wenn Sie derzeit SageMaker Studio Classic verwenden, lesen Sie hier Migration von Amazon SageMaker Studio Classic.
- IAM-Rolle – SageMaker erfordert eine AWS Identity and Access Management and (IAM)-Rolle, die einer SageMaker Studio-Domäne oder einem Benutzerprofil zugewiesen werden soll, um Berechtigungen effektiv zu verwalten. Möglicherweise ist eine Aktualisierung der Ausführungsrolle erforderlich, um das Durchsuchen von Daten und die SQL-Ausführungsfunktion bereitzustellen. Die folgende Beispielrichtlinie ermöglicht Benutzern das Gewähren, Auflisten und Ausführen AWS-Kleber, Athene, Amazon Simple Storage-Service (Amazon S3), AWS Secrets Managerund Amazon Redshift-Ressourcen:
- JupyterLab Space – Sie benötigen Zugriff auf das aktualisierte SageMaker Studio und JupyterLab Space mit SageMaker-Verteilung v1.6 oder spätere Image-Versionen. Wenn Sie benutzerdefinierte Images für JupyterLab Spaces oder ältere Versionen der SageMaker-Distribution (Version 1.5 oder niedriger) verwenden, finden Sie im Anhang Anweisungen zur Installation der erforderlichen Pakete und Module, um diese Funktion in Ihren Umgebungen zu aktivieren. Weitere Informationen zu SageMaker Studio JupyterLab Spaces finden Sie unter Steigern Sie die Produktivität mit Amazon SageMaker Studio: Einführung von JupyterLab Spaces und generativen KI-Tools.
- Anmeldeinformationen für den Datenquellenzugriff – Für diese Notebook-Funktion von SageMaker Studio ist der Zugriff mit Benutzername und Passwort auf Datenquellen wie Snowflake und Amazon Redshift erforderlich. Erstellen Sie einen benutzernamen- und passwortbasierten Zugriff auf diese Datenquellen, falls Sie noch keinen haben. Der OAuth-basierte Zugriff auf Snowflake ist zum jetzigen Zeitpunkt keine unterstützte Funktion.
- Laden Sie SQL-Magie – Bevor Sie SQL-Abfragen aus einer Jupyter-Notebook-Zelle ausführen, müssen Sie unbedingt die SQL Magics-Erweiterung laden. Verwenden Sie den Befehl
%load_ext amazon_sagemaker_sql_magicum diese Funktion zu aktivieren. Darüber hinaus können Sie Folgendes ausführen%sm_sql?Befehl, um eine umfassende Liste der unterstützten Optionen für die Abfrage aus einer SQL-Zelle anzuzeigen. Zu diesen Optionen gehören unter anderem das Festlegen eines Standardabfragelimits von 1,000, das Ausführen einer vollständigen Extraktion und das Einfügen von Abfrageparametern. Dieses Setup ermöglicht eine flexible und effiziente SQL-Datenbearbeitung direkt in Ihrer Notebook-Umgebung.
Erstellen Sie Datenbankverbindungen
Die integrierten SQL-Browsing- und Ausführungsfunktionen von SageMaker Studio werden durch AWS Glue-Verbindungen erweitert. Eine AWS Glue-Verbindung ist ein AWS Glue-Datenkatalogobjekt, das wichtige Daten wie Anmeldeinformationen, URI-Zeichenfolgen und VPC-Informationen (Virtual Private Cloud) für bestimmte Datenspeicher speichert. Diese Verbindungen werden von AWS Glue-Crawlern, Jobs und Entwicklungsendpunkten verwendet, um auf verschiedene Arten von Datenspeichern zuzugreifen. Sie können diese Verbindungen sowohl für Quell- als auch für Zieldaten verwenden und sogar dieselbe Verbindung für mehrere Crawler oder ETL-Jobs (Extrahieren, Transformieren und Laden) wiederverwenden.
Um SQL-Datenquellen im linken Bereich von SageMaker Studio zu erkunden, müssen Sie zunächst AWS Glue-Verbindungsobjekte erstellen. Diese Verbindungen erleichtern den Zugriff auf verschiedene Datenquellen und ermöglichen die Erkundung ihrer schematischen Datenelemente.
In den folgenden Abschnitten führen wir den Prozess der Erstellung SQL-spezifischer AWS Glue-Konnektoren durch. Dadurch können Sie auf Datensätze in einer Vielzahl von Datenspeichern zugreifen, diese anzeigen und erkunden. Ausführlichere Informationen zu AWS Glue-Verbindungen finden Sie unter Verbindung zu Daten herstellen.
Erstellen Sie eine AWS Glue-Verbindung
Die einzige Möglichkeit, Datenquellen in SageMaker Studio zu integrieren, sind AWS Glue-Verbindungen. Sie müssen AWS Glue-Verbindungen mit bestimmten Verbindungstypen erstellen. Zum jetzigen Zeitpunkt ist der einzige unterstützte Mechanismus zum Erstellen dieser Verbindungen die Verwendung von AWS-Befehlszeilenschnittstelle (AWS-CLI).
JSON-Datei mit Verbindungsdefinition
Wenn Sie eine Verbindung zu verschiedenen Datenquellen in AWS Glue herstellen, müssen Sie zunächst eine JSON-Datei erstellen, die die Verbindungseigenschaften definiert – die sogenannte Verbindungsdefinitionsdatei. Diese Datei ist für den Aufbau einer AWS Glue-Verbindung von entscheidender Bedeutung und sollte alle erforderlichen Konfigurationen für den Zugriff auf die Datenquelle detailliert beschreiben. Aus Sicherheitsgründen wird empfohlen, Secrets Manager zu verwenden, um vertrauliche Informationen wie Passwörter sicher zu speichern. In der Zwischenzeit können andere Verbindungseigenschaften direkt über AWS Glue-Verbindungen verwaltet werden. Dieser Ansatz stellt sicher, dass vertrauliche Anmeldeinformationen geschützt sind und gleichzeitig die Verbindungskonfiguration zugänglich und verwaltbar bleibt.
Das Folgende ist ein Beispiel für eine JSON-Verbindungsdefinition:
Beim Einrichten von AWS Glue-Verbindungen für Ihre Datenquellen müssen einige wichtige Richtlinien befolgt werden, um sowohl Funktionalität als auch Sicherheit zu gewährleisten:
- Stringifizierung von Eigenschaften - Innerhalb des
PythonPropertiesStellen Sie sicher, dass alle Eigenschaften vorhanden sind stringifizierte Schlüssel-Wert-Paare. Es ist wichtig, doppelte Anführungszeichen ordnungsgemäß zu umgehen, indem Sie bei Bedarf das Zeichen Backslash () verwenden. Dies hilft, das richtige Format beizubehalten und Syntaxfehler in Ihrem JSON zu vermeiden. - Umgang mit sensiblen Informationen – Es ist zwar möglich, alle Verbindungseigenschaften darin einzubeziehen
PythonProperties, ist es ratsam, vertrauliche Details wie Passwörter nicht direkt in diese Eigenschaften aufzunehmen. Verwenden Sie stattdessen Secrets Manager für den Umgang mit vertraulichen Informationen. Dieser Ansatz schützt Ihre sensiblen Daten, indem er sie in einer kontrollierten und verschlüsselten Umgebung abseits der Hauptkonfigurationsdateien speichert.
Erstellen Sie eine AWS Glue-Verbindung mit der AWS CLI
Nachdem Sie alle erforderlichen Felder in Ihre JSON-Verbindungsdefinitionsdatei aufgenommen haben, können Sie mit der AWS CLI und dem folgenden Befehl eine AWS Glue-Verbindung für Ihre Datenquelle herstellen:
Dieser Befehl initiiert eine neue AWS Glue-Verbindung basierend auf den in Ihrer JSON-Datei aufgeführten Spezifikationen. Im Folgenden finden Sie eine kurze Aufschlüsselung der Befehlskomponenten:
- -Region – Dies gibt die AWS-Region an, in der Ihre AWS Glue-Verbindung erstellt wird. Es ist wichtig, die Region auszuwählen, in der sich Ihre Datenquellen und andere Dienste befinden, um die Latenz zu minimieren und die Anforderungen an die Datenresidenz einzuhalten.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Dieser Parameter weist die AWS CLI an, die Eingabekonfiguration aus einer lokalen Datei zu lesen, die Ihre Verbindungsdefinition im JSON-Format enthält.
Sie sollten in der Lage sein, AWS Glue-Verbindungen mit dem vorherigen AWS CLI-Befehl von Ihrem Studio JupyterLab-Terminal aus zu erstellen. Auf der Reichen Sie das Menü, wählen Sie Neu und Terminal.

Besitzt das create-connection Wenn der Befehl erfolgreich ausgeführt wird, sollte Ihre Datenquelle im SQL-Browserbereich aufgeführt sein. Wenn Ihre Datenquelle nicht aufgeführt ist, wählen Sie Inspiration um den Cache zu aktualisieren.

Erstellen Sie eine Snowflake-Verbindung
In diesem Abschnitt konzentrieren wir uns auf die Integration einer Snowflake-Datenquelle mit SageMaker Studio. Das Erstellen von Snowflake-Konten, Datenbanken und Warehouses fällt nicht in den Rahmen dieses Beitrags. Informationen zu den ersten Schritten mit Snowflake finden Sie im Snowflake-Benutzerhandbuch. In diesem Beitrag konzentrieren wir uns auf die Erstellung einer Snowflake-Definitions-JSON-Datei und den Aufbau einer Snowflake-Datenquellenverbindung mit AWS Glue.
Erstellen Sie ein Secrets Manager-Geheimnis
Sie können eine Verbindung zu Ihrem Snowflake-Konto herstellen, indem Sie entweder eine Benutzer-ID und ein Kennwort oder private Schlüssel verwenden. Um eine Verbindung mit einer Benutzer-ID und einem Passwort herzustellen, müssen Sie Ihre Anmeldeinformationen sicher im Secrets Manager speichern. Wie bereits erwähnt, ist es zwar möglich, diese Informationen unter PythonProperties einzubetten, es wird jedoch nicht empfohlen, vertrauliche Informationen im Nur-Text-Format zu speichern. Stellen Sie stets sicher, dass vertrauliche Daten sicher behandelt werden, um potenzielle Sicherheitsrisiken zu vermeiden.
Um Informationen im Secrets Manager zu speichern, führen Sie die folgenden Schritte aus:
- Wählen Sie in der Secrets Manager-Konsole aus Speichern Sie ein neues Geheimnis.
- Aussichten für Geheimer Typ, wählen Andere Art von Geheimnis.
- Wählen Sie für das Schlüssel-Wert-Paar Klartext und geben Sie Folgendes ein:
- Geben Sie einen Namen für Ihr Geheimnis ein, z
sm-sql-snowflake-secret. - Belassen Sie die anderen Einstellungen als Standard oder passen Sie sie bei Bedarf an.
- Erschaffe das Geheimnis.
Erstellen Sie eine AWS Glue-Verbindung für Snowflake
Wie bereits erwähnt, sind AWS Glue-Verbindungen für den Zugriff auf jede Verbindung von SageMaker Studio aus unerlässlich. Eine Liste finden Sie hier alle unterstützten Verbindungseigenschaften für Snowflake. Im Folgenden finden Sie ein Beispiel für eine JSON-Verbindungsdefinition für Snowflake. Ersetzen Sie die Platzhalterwerte durch die entsprechenden Werte, bevor Sie sie auf der Festplatte speichern:
Um ein AWS Glue-Verbindungsobjekt für die Snowflake-Datenquelle zu erstellen, verwenden Sie den folgenden Befehl:
Dieser Befehl erstellt eine neue Snowflake-Datenquellenverbindung in Ihrem SQL-Browserbereich, die durchsuchbar ist, und Sie können von Ihrer JupyterLab-Notebookzelle aus SQL-Abfragen dafür ausführen.
Erstellen Sie eine Amazon Redshift-Verbindung
Amazon Redshift ist ein vollständig verwalteter Data Warehouse-Dienst im Petabyte-Bereich, der die Analyse aller Ihrer Daten mit Standard-SQL vereinfacht und die Kosten senkt. Das Verfahren zum Erstellen einer Amazon Redshift-Verbindung entspricht weitgehend dem für eine Snowflake-Verbindung.
Erstellen Sie ein Secrets Manager-Geheimnis
Ähnlich wie beim Snowflake-Setup müssen Sie zum Herstellen einer Verbindung zu Amazon Redshift mithilfe einer Benutzer-ID und eines Kennworts die Secrets-Informationen sicher im Secrets Manager speichern. Führen Sie die folgenden Schritte aus:
- Wählen Sie in der Secrets Manager-Konsole aus Speichern Sie ein neues Geheimnis.
- Aussichten für Geheimer Typ, wählen Anmeldeinformationen für den Amazon-Redshift-Cluster.
- Geben Sie die Anmeldeinformationen ein, mit denen Sie sich angemeldet haben, um auf Amazon Redshift als Datenquelle zuzugreifen.
- Wählen Sie den Redshift-Cluster aus, der den Geheimnissen zugeordnet ist.
- Geben Sie einen Namen für das Geheimnis ein, z
sm-sql-redshift-secret. - Belassen Sie die anderen Einstellungen als Standard oder passen Sie sie bei Bedarf an.
- Erschaffe das Geheimnis.
Indem Sie diese Schritte befolgen, stellen Sie sicher, dass Ihre Verbindungsanmeldeinformationen sicher gehandhabt werden, und nutzen die robusten Sicherheitsfunktionen von AWS, um sensible Daten effektiv zu verwalten.
Erstellen Sie eine AWS Glue-Verbindung für Amazon Redshift
Um eine Verbindung mit Amazon Redshift mithilfe einer JSON-Definition einzurichten, füllen Sie die erforderlichen Felder aus und speichern Sie die folgende JSON-Konfiguration auf der Festplatte:
Um ein AWS Glue-Verbindungsobjekt für die Redshift-Datenquelle zu erstellen, verwenden Sie den folgenden AWS CLI-Befehl:
Dieser Befehl erstellt eine Verbindung in AWS Glue, die mit Ihrer Redshift-Datenquelle verknüpft ist. Wenn der Befehl erfolgreich ausgeführt wird, können Sie Ihre Redshift-Datenquelle im SageMaker Studio JupyterLab-Notizbuch sehen und können SQL-Abfragen ausführen und Datenanalysen durchführen.

Erstellen Sie eine Athena-Verbindung
Athena ist ein vollständig verwalteter SQL-Abfragedienst von AWS, der die Analyse von in Amazon S3 gespeicherten Daten mithilfe von Standard-SQL ermöglicht. Um eine Athena-Verbindung als Datenquelle im SQL-Browser des JupyterLab-Notebooks einzurichten, müssen Sie eine Athena-Beispielverbindungsdefinition JSON erstellen. Die folgende JSON-Struktur konfiguriert die notwendigen Details für die Verbindung mit Athena und gibt den Datenkatalog, das S3-Staging-Verzeichnis und die Region an:
Um ein AWS Glue-Verbindungsobjekt für die Athena-Datenquelle zu erstellen, verwenden Sie den folgenden AWS CLI-Befehl:
Wenn der Befehl erfolgreich ist, können Sie direkt über den SQL-Browser in Ihrem SageMaker Studio JupyterLab-Notizbuch auf den Athena-Datenkatalog und die Tabellen zugreifen.
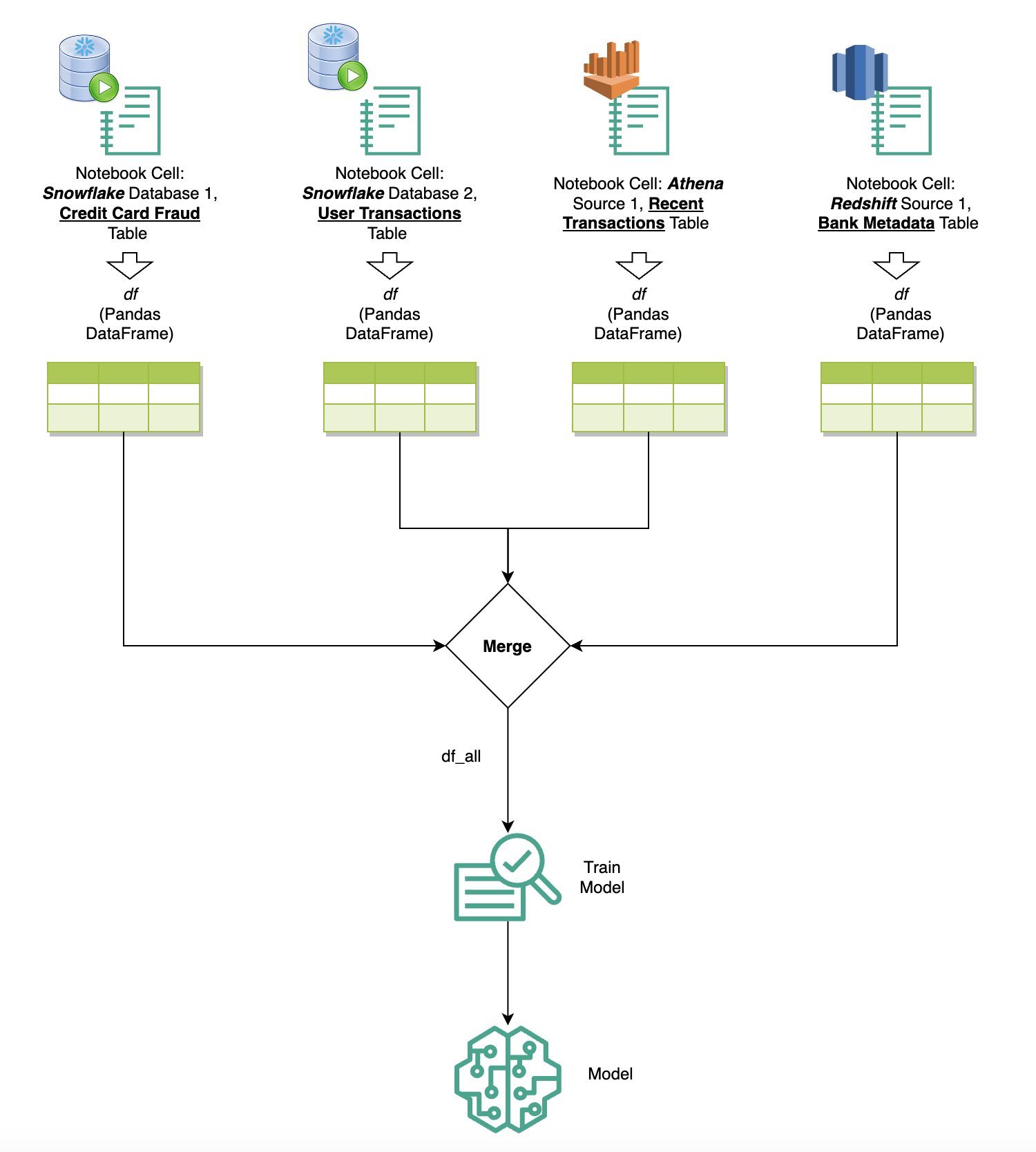
Fragen Sie Daten aus mehreren Quellen ab
Wenn Sie über den integrierten SQL-Browser und die Notebook-SQL-Funktion mehrere Datenquellen in SageMaker Studio integriert haben, können Sie schnell Abfragen ausführen und mühelos zwischen Datenquellen-Backends in nachfolgenden Zellen innerhalb eines Notebooks wechseln. Diese Funktion ermöglicht nahtlose Übergänge zwischen verschiedenen Datenbanken oder Datenquellen während Ihres Analyse-Workflows.
Sie können Abfragen für eine vielfältige Sammlung von Datenquellen-Backends ausführen und die Ergebnisse zur weiteren Analyse oder Visualisierung direkt in den Python-Bereich übertragen. Dies wird durch die erleichtert %%sm_sql Der magische Befehl ist in SageMaker Studio-Notizbüchern verfügbar. Um die Ergebnisse Ihrer SQL-Abfrage in einen Pandas-DataFrame auszugeben, gibt es zwei Möglichkeiten:
- Wählen Sie in der Symbolleiste Ihrer Notebookzelle den Ausgabetyp aus Datenrahmen und benennen Sie Ihre DataFrame-Variable
- Hängen Sie den folgenden Parameter an Ihren an
%%sm_sqlBefehl:
Das folgende Diagramm veranschaulicht diesen Arbeitsablauf und zeigt, wie Sie mühelos Abfragen über verschiedene Quellen in nachfolgenden Notebook-Zellen ausführen und ein SageMaker-Modell mithilfe von Trainingsjobs oder direkt im Notebook mithilfe lokaler Datenverarbeitung trainieren können. Darüber hinaus zeigt das Diagramm, wie die integrierte SQL-Integration von SageMaker Studio die Extraktions- und Erstellungsprozesse direkt in der vertrauten Umgebung einer JupyterLab-Notebook-Zelle vereinfacht.
Text to SQL: Verwendung natürlicher Sprache zur Verbesserung der Abfrageerstellung
SQL ist eine komplexe Sprache, die Kenntnisse über Datenbanken, Tabellen, Syntax und Metadaten erfordert. Mithilfe generativer künstlicher Intelligenz (KI) können Sie heute komplexe SQL-Abfragen schreiben, ohne dass umfassende SQL-Kenntnisse erforderlich sind. Die Weiterentwicklung von LLMs hat erhebliche Auswirkungen auf die auf der Verarbeitung natürlicher Sprache (NLP) basierende SQL-Generierung und ermöglicht die Erstellung präziser SQL-Abfragen aus Beschreibungen natürlicher Sprache – eine Technik, die als Text-to-SQL bezeichnet wird. Es ist jedoch wichtig, die inhärenten Unterschiede zwischen menschlicher Sprache und SQL anzuerkennen. Die menschliche Sprache kann manchmal mehrdeutig oder ungenau sein, wohingegen SQL strukturiert, explizit und eindeutig ist. Diese Lücke zu schließen und natürliche Sprache präzise in SQL-Abfragen umzuwandeln, kann eine gewaltige Herausforderung darstellen. Wenn sie mit geeigneten Eingabeaufforderungen ausgestattet sind, können LLMs helfen, diese Lücke zu schließen, indem sie die Absicht hinter der menschlichen Sprache verstehen und entsprechend genaue SQL-Abfragen generieren.
Mit der Veröffentlichung der in SageMaker Studio integrierten SQL-Abfragefunktion erleichtert SageMaker Studio die Überprüfung von Datenbanken und Schemata sowie das Erstellen, Ausführen und Debuggen von SQL-Abfragen, ohne jemals die Jupyter-Notebook-IDE verlassen zu müssen. In diesem Abschnitt wird untersucht, wie die Text-to-SQL-Funktionen erweiterter LLMs die Generierung von SQL-Abfragen mithilfe natürlicher Sprache in Jupyter-Notebooks erleichtern können. Wir nutzen das hochmoderne Text-to-SQL-Modell defog/sqlcoder-7b-2 in Verbindung mit Jupyter AI, einem generativen KI-Assistenten, der speziell für Jupyter-Notebooks entwickelt wurde, um komplexe SQL-Abfragen aus natürlicher Sprache zu erstellen. Durch die Verwendung dieses erweiterten Modells können wir mühelos und effizient komplexe SQL-Abfragen in natürlicher Sprache erstellen und so unsere SQL-Erfahrung in Notebooks verbessern.
Notebook-Prototyping mit dem Hugging Face Hub
Um mit dem Prototyping zu beginnen, benötigen Sie Folgendes:
- GitHub-Code – Der in diesem Abschnitt vorgestellte Code ist im Folgenden verfügbar GitHub Repo und durch Verweis auf die Beispiel Notizbuch.
- JupyterLab Space – Der Zugriff auf einen SageMaker Studio JupyterLab Space, der durch GPU-basierte Instanzen unterstützt wird, ist unerlässlich. Für die
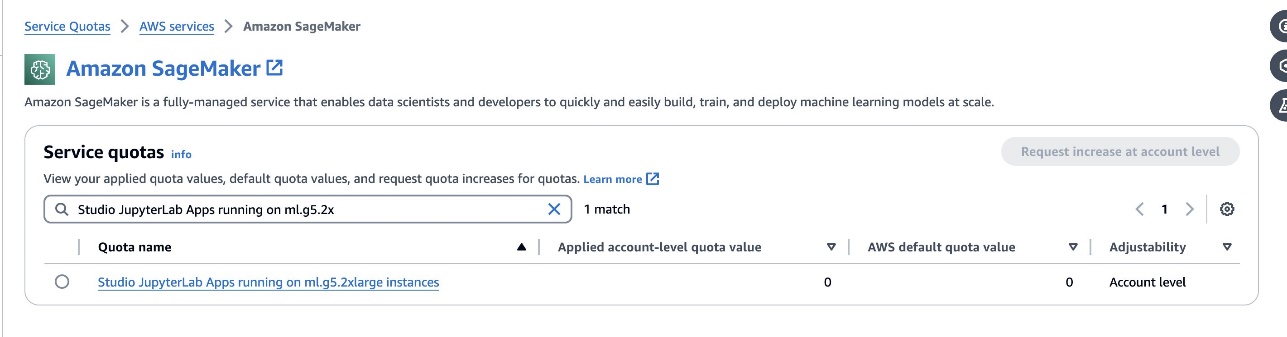
defog/sqlcoder-7b-2Modell, ein 7B-Parametermodell, die Verwendung einer ml.g5.2xlarge-Instanz wird empfohlen. Alternativen wie z.Bdefog/sqlcoder-70b-alpha oderdefog/sqlcoder-34b-alphasind auch für die Konvertierung von natürlicher Sprache in SQL geeignet, für die Prototypenerstellung sind jedoch möglicherweise größere Instanztypen erforderlich. Stellen Sie sicher, dass Sie über das Kontingent zum Starten einer GPU-gestützten Instanz verfügen, indem Sie zur Service Quotas-Konsole navigieren, nach SageMaker suchen und nachStudio JupyterLab Apps running on <instance type>.
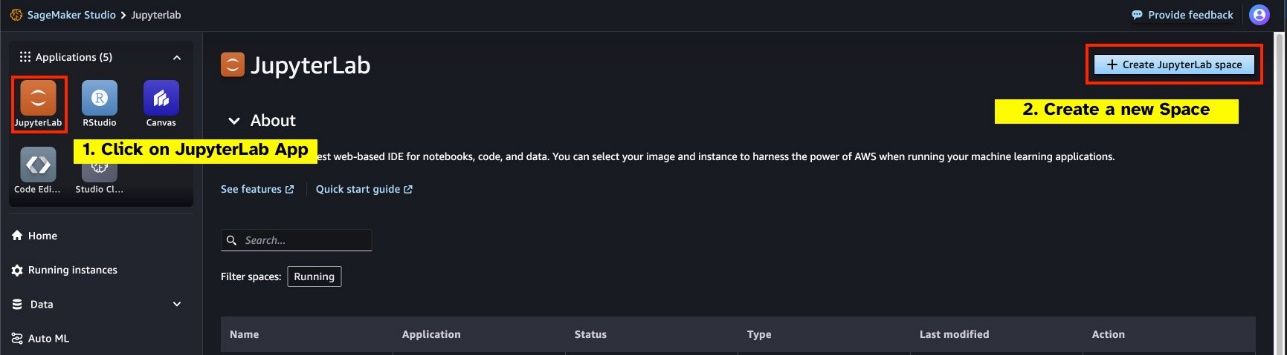
Starten Sie einen neuen GPU-gestützten JupyterLab Space von Ihrem SageMaker Studio aus. Es wird empfohlen, einen neuen JupyterLab Space mit mindestens 75 GB zu erstellen Amazon Elastic Block-Shop (Amazon EBS) Speicher für ein 7B-Parametermodell.

- Face Hub umarmen – Wenn Ihre SageMaker Studio-Domäne Zugriff auf das Herunterladen von Modellen hat Face Hub umarmen, können Sie die
AutoModelForCausalLMKlasse von Huggingface/Transformers um Modelle automatisch herunterzuladen und an Ihre lokalen GPUs anzuheften. Die Modellgewichte werden im Cache Ihres lokalen Computers gespeichert. Siehe den folgenden Code:
Nachdem das Modell vollständig heruntergeladen und in den Speicher geladen wurde, sollten Sie einen Anstieg der GPU-Auslastung auf Ihrem lokalen Computer beobachten. Dies weist darauf hin, dass das Modell die GPU-Ressourcen aktiv für Rechenaufgaben nutzt. Sie können dies in Ihrem eigenen JupyterLab-Bereich überprüfen, indem Sie Folgendes ausführen nvidia-smi (für eine einmalige Anzeige) oder nvidia-smi —loop=1 (um jede Sekunde zu wiederholen) von Ihrem JupyterLab-Terminal aus.
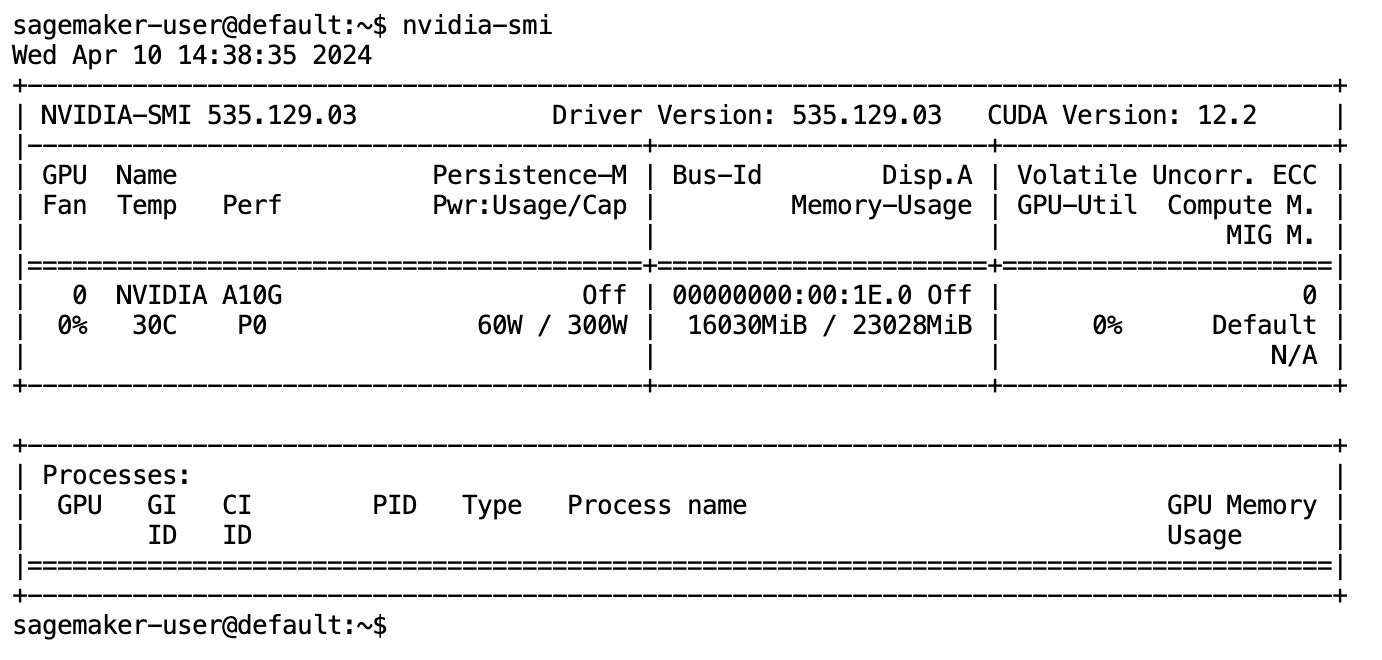
Text-to-SQL-Modelle zeichnen sich dadurch aus, dass sie die Absicht und den Kontext einer Benutzeranfrage verstehen, selbst wenn die verwendete Sprache umgangssprachlich oder mehrdeutig ist. Der Prozess umfasst die Übersetzung natürlichsprachlicher Eingaben in die richtigen Datenbankschemaelemente, wie z. B. Tabellennamen, Spaltennamen und Bedingungen. Ein handelsübliches Text-to-SQL-Modell kennt jedoch nicht automatisch die Struktur Ihres Data Warehouse und die spezifischen Datenbankschemata und ist auch nicht in der Lage, den Inhalt einer Tabelle ausschließlich auf der Grundlage von Spaltennamen genau zu interpretieren. Um diese Modelle effektiv zum Generieren praktischer und effizienter SQL-Abfragen aus natürlicher Sprache zu nutzen, ist es notwendig, das SQL-Textgenerierungsmodell an Ihr spezifisches Warehouse-Datenbankschema anzupassen. Diese Anpassung wird durch die Verwendung von erleichtert LLM-Eingabeaufforderungen. Das Folgende ist eine empfohlene Eingabeaufforderungsvorlage für das Text-to-SQL-Modell defog/sqlcoder-7b-2, unterteilt in vier Teile:
- Aufgabe – In diesem Abschnitt sollte eine übergeordnete Aufgabe angegeben werden, die vom Modell ausgeführt werden soll. Es sollte den Typ des Datenbank-Backends (z. B. Amazon RDS, PostgreSQL oder Amazon Redshift) enthalten, um das Modell auf nuancierte syntaktische Unterschiede aufmerksam zu machen, die sich auf die Generierung der endgültigen SQL-Abfrage auswirken können.
- Anweisungen – Dieser Abschnitt sollte Aufgabengrenzen und Domänenbewusstsein für das Modell definieren und möglicherweise einige Beispiele enthalten, die das Modell bei der Generierung fein abgestimmter SQL-Abfragen unterstützen.
- Datenbankschema – Dieser Abschnitt sollte Ihre Warehouse-Datenbankschemata detailliert beschreiben und die Beziehungen zwischen Tabellen und Spalten skizzieren, um dem Modell das Verständnis der Datenbankstruktur zu erleichtern.
- Antworten – Dieser Abschnitt ist für das Modell reserviert, um die SQL-Abfrageantwort auf die Eingabe in natürlicher Sprache auszugeben.
Ein Beispiel für das in diesem Abschnitt verwendete Datenbankschema und die Eingabeaufforderung finden Sie im GitHub-Repository.
Beim Prompt Engineering geht es nicht nur darum, Fragen oder Aussagen zu formulieren; Es handelt sich um eine differenzierte Kunst und Wissenschaft, die die Qualität der Interaktionen mit einem KI-Modell erheblich beeinflusst. Die Art und Weise, wie Sie eine Eingabeaufforderung erstellen, kann die Art und Nützlichkeit der Reaktion der KI tiefgreifend beeinflussen. Diese Fähigkeit ist von entscheidender Bedeutung für die Maximierung des Potenzials von KI-Interaktionen, insbesondere bei komplexen Aufgaben, die spezielles Verständnis und detaillierte Antworten erfordern.
Es ist wichtig, die Möglichkeit zu haben, die Antwort eines Modells für eine bestimmte Eingabeaufforderung schnell zu erstellen und zu testen und die Eingabeaufforderung basierend auf der Antwort zu optimieren. JupyterLab-Notebooks bieten die Möglichkeit, sofortiges Modellfeedback von einem Modell zu erhalten, das auf lokaler Rechenleistung ausgeführt wird, die Eingabeaufforderung zu optimieren und die Reaktion eines Modells weiter zu optimieren oder ein Modell vollständig zu ändern. In diesem Beitrag verwenden wir ein JupyterLab-Notebook von SageMaker Studio, das von der NVIDIA A5.2G 10-GB-GPU von ml.g24xlarge unterstützt wird, um die Text-zu-SQL-Modellinferenz auf dem Notebook auszuführen und unsere Modellaufforderung interaktiv zu erstellen, bis die Antwort des Modells ausreichend abgestimmt ist, um sie bereitzustellen Antworten, die direkt in den SQL-Zellen von JupyterLab ausführbar sind. Um Modellinferenzen auszuführen und gleichzeitig Modellantworten zu streamen, verwenden wir eine Kombination aus model.generate und TextIteratorStreamer wie im folgenden Code definiert:
Die Ausgabe des Modells kann mit SageMaker SQL-Magie dekoriert werden %%sm_sql ..., wodurch das JupyterLab-Notebook die Zelle als SQL-Zelle identifizieren kann.
Hosten Sie Text-to-SQL-Modelle als SageMaker-Endpunkte
Am Ende der Prototyping-Phase haben wir unser bevorzugtes Text-to-SQL-LLM, ein effektives Eingabeaufforderungsformat und einen geeigneten Instanztyp zum Hosten des Modells (entweder Single-GPU oder Multi-GPU) ausgewählt. SageMaker erleichtert das skalierbare Hosting benutzerdefinierter Modelle durch die Verwendung von SageMaker-Endpunkten. Diese Endpunkte können nach bestimmten Kriterien definiert werden, was den Einsatz von LLMs als Endpunkte ermöglicht. Mit dieser Funktion können Sie die Lösung auf ein breiteres Publikum skalieren und Benutzern die Möglichkeit geben, mithilfe benutzerdefinierter gehosteter LLMs SQL-Abfragen aus Eingaben in natürlicher Sprache zu generieren. Das folgende Diagramm veranschaulicht diese Architektur.

Um Ihr LLM als SageMaker-Endpunkt zu hosten, generieren Sie mehrere Artefakte.
Das erste Artefakt sind Modellgewichte. Bereitstellung der SageMaker Deep Java Library (DJL). Mit Containern können Sie Konfigurationen über ein Meta einrichten dienende.Eigenschaften Datei, mit der Sie steuern können, wie Modelle beschafft werden – entweder direkt vom Hugging Face Hub oder durch Herunterladen von Modellartefakten von Amazon S3. Wenn Sie angeben model_id=defog/sqlcoder-7b-2, DJL Serving wird versuchen, dieses Modell direkt vom Hugging Face Hub herunterzuladen. Es können jedoch bei jeder Bereitstellung oder elastischen Skalierung des Endpunkts Gebühren für den eingehenden/ausgehenden Netzwerkverkehr anfallen. Um diese Gebühren zu vermeiden und möglicherweise den Download von Modellartefakten zu beschleunigen, wird empfohlen, die Verwendung zu überspringen model_id in serving.properties und speichern Sie Modellgewichte als S3-Artefakte und geben Sie sie nur mit an s3url=s3://path/to/model/bin.
Das Speichern eines Modells (mit seinem Tokenizer) auf der Festplatte und das Hochladen auf Amazon S3 kann mit nur wenigen Codezeilen durchgeführt werden:
Sie verwenden auch eine Datenbank-Eingabeaufforderungsdatei. In diesem Setup besteht die Datenbank-Eingabeaufforderung aus Task, Instructions, Database Schema und Answer sections. Für die aktuelle Architektur weisen wir jedem Datenbankschema eine separate Eingabeaufforderungsdatei zu. Es besteht jedoch die Flexibilität, dieses Setup zu erweitern, um mehrere Datenbanken pro Eingabeaufforderungsdatei einzubeziehen, sodass das Modell zusammengesetzte Verknüpfungen zwischen Datenbanken auf demselben Server ausführen kann. Während unserer Prototyping-Phase speichern wir die Datenbankeingabe als Textdatei mit dem Namen <Database-Glue-Connection-Name>.prompt, Wobei Database-Glue-Connection-Name entspricht dem Verbindungsnamen, der in Ihrer JupyterLab-Umgebung sichtbar ist. Dieser Beitrag bezieht sich beispielsweise auf eine Snowflake-Verbindung mit dem Namen Airlines_Dataset, daher wird die Datenbank-Eingabeaufforderungsdatei benannt Airlines_Dataset.prompt. Diese Datei wird dann auf Amazon S3 gespeichert und anschließend von unserer Modellbereitstellungslogik gelesen und zwischengespeichert.
Darüber hinaus ermöglicht diese Architektur allen autorisierten Benutzern dieses Endpunkts, SQL-Abfragen in natürlicher Sprache zu definieren, zu speichern und zu generieren, ohne dass mehrere Neubereitstellungen des Modells erforderlich sind. Wir verwenden Folgendes Beispiel einer Datenbank-Eingabeaufforderung um die Text-to-SQL-Funktionalität zu demonstrieren.
Als Nächstes generieren Sie eine benutzerdefinierte Modelldienstlogik. In diesem Abschnitt skizzieren Sie eine benutzerdefinierte Inferenzlogik mit dem Namen model.py. Dieses Skript soll die Leistung und Integration unserer Text-to-SQL-Dienste optimieren:
- Definieren Sie die Caching-Logik der Datenbank-Eingabeaufforderungsdatei – Um die Latenz zu minimieren, implementieren wir eine benutzerdefinierte Logik zum Herunterladen und Zwischenspeichern von Datenbank-Eingabeaufforderungsdateien. Dieser Mechanismus stellt sicher, dass Eingabeaufforderungen jederzeit verfügbar sind, und reduziert so den mit häufigen Downloads verbundenen Aufwand.
- Definieren Sie eine benutzerdefinierte Modellinferenzlogik – Um die Inferenzgeschwindigkeit zu erhöhen, wird unser Text-zu-SQL-Modell im Float16-Präzisionsformat geladen und dann in ein DeepSpeed-Modell konvertiert. Dieser Schritt ermöglicht eine effizientere Berechnung. Darüber hinaus legen Sie innerhalb dieser Logik fest, welche Parameter Benutzer während Inferenzaufrufen anpassen können, um die Funktionalität an ihre Bedürfnisse anzupassen.
- Definieren Sie benutzerdefinierte Eingabe- und Ausgabelogik – Die Einrichtung klarer und angepasster Eingabe-/Ausgabeformate ist für eine reibungslose Integration mit nachgelagerten Anwendungen unerlässlich. Eine solche Anwendung ist JupyterAI, die wir im folgenden Abschnitt besprechen.
Zusätzlich enthalten wir a serving.properties Datei, die als globale Konfigurationsdatei für Modelle fungiert, die mithilfe der DJL-Bereitstellung gehostet werden. Weitere Informationen finden Sie unter Konfigurationen und Einstellungen.
Zuletzt können Sie auch a hinzufügen requirements.txt Datei, um zusätzliche Module zu definieren, die für die Inferenz erforderlich sind, und alles zur Bereitstellung in einen Tarball zu packen.
Siehe folgenden Code:
Integrieren Sie Ihren Endpunkt mit dem SageMaker Studio Jupyter AI-Assistenten
Jupyter-KI ist ein Open-Source-Tool, das generative KI auf Jupyter-Notebooks bringt und eine robuste und benutzerfreundliche Plattform für die Erforschung generativer KI-Modelle bietet. Es steigert die Produktivität in JupyterLab und Jupyter-Notebooks, indem es Funktionen wie %%ai Magic zum Erstellen eines generativen KI-Spielplatzes in Notebooks, eine native Chat-Benutzeroberfläche in JupyterLab für die Interaktion mit KI als Gesprächsassistent und Unterstützung für eine breite Palette von LLMs von bereitstellt Anbieter mögen Amazonas-Titan, AI21, Anthropic, Cohere und Hugging Face oder verwaltete Dienste wie Amazonas Grundgestein und SageMaker-Endpunkte. Für diesen Beitrag nutzen wir die sofort einsatzbereite Integration von Jupyter AI mit SageMaker-Endpunkten, um die Text-to-SQL-Funktion in JupyterLab-Notebooks zu integrieren. Das Jupyter AI-Tool ist in allen SageMaker Studio JupyterLab Spaces vorinstalliert, die von unterstützt werden SageMaker Distribution-Bilder; Endbenutzer müssen keine zusätzlichen Konfigurationen vornehmen, um die Jupyter AI-Erweiterung für die Integration in einen von SageMaker gehosteten Endpunkt zu verwenden. In diesem Abschnitt besprechen wir die beiden Möglichkeiten, das integrierte Jupyter AI-Tool zu verwenden.
Jupyter-KI in einem Notebook mit Magie
Jupyter-KIs %%ai Mit Magic Command können Sie Ihre SageMaker Studio JupyterLab-Notizbücher in eine reproduzierbare generative KI-Umgebung umwandeln. Um mit der Verwendung von KI-Magien zu beginnen, stellen Sie sicher, dass Sie die zu verwendende Erweiterung jupyter_ai_magics geladen haben %%ai Magie und zusätzlich laden amazon_sagemaker_sql_magic benutzen %%sm_sql Magie:
Um von Ihrem Notebook aus einen Aufruf an Ihren SageMaker-Endpunkt auszuführen, verwenden Sie: %%ai Geben Sie für den magischen Befehl die folgenden Parameter an und strukturieren Sie den Befehl wie folgt:
- –Regionsname – Geben Sie die Region an, in der Ihr Endpunkt bereitgestellt wird. Dadurch wird sichergestellt, dass die Anfrage an den richtigen geografischen Standort weitergeleitet wird.
- –request-schema – Fügen Sie das Schema der Eingabedaten hinzu. Dieses Schema beschreibt das erwartete Format und die erwarteten Typen der Eingabedaten, die Ihr Modell zum Verarbeiten der Anfrage benötigt.
- –Antwortpfad – Definieren Sie den Pfad innerhalb des Antwortobjekts, in dem sich die Ausgabe Ihres Modells befindet. Dieser Pfad wird verwendet, um die relevanten Daten aus der von Ihrem Modell zurückgegebenen Antwort zu extrahieren.
- -f (optional) - Das ist ein Ausgabeformatierer Flag, das den Typ der vom Modell zurückgegebenen Ausgabe angibt. Wenn es sich bei der Ausgabe im Kontext eines Jupyter-Notebooks um Code handelt, sollte dieses Flag entsprechend gesetzt werden, um die Ausgabe als ausführbaren Code oben in einer Jupyter-Notebook-Zelle zu formatieren, gefolgt von einem Freitext-Eingabebereich für die Benutzerinteraktion.
Beispielsweise könnte der Befehl in einer Jupyter-Notebook-Zelle wie der folgende Code aussehen:
Jupyter AI-Chatfenster
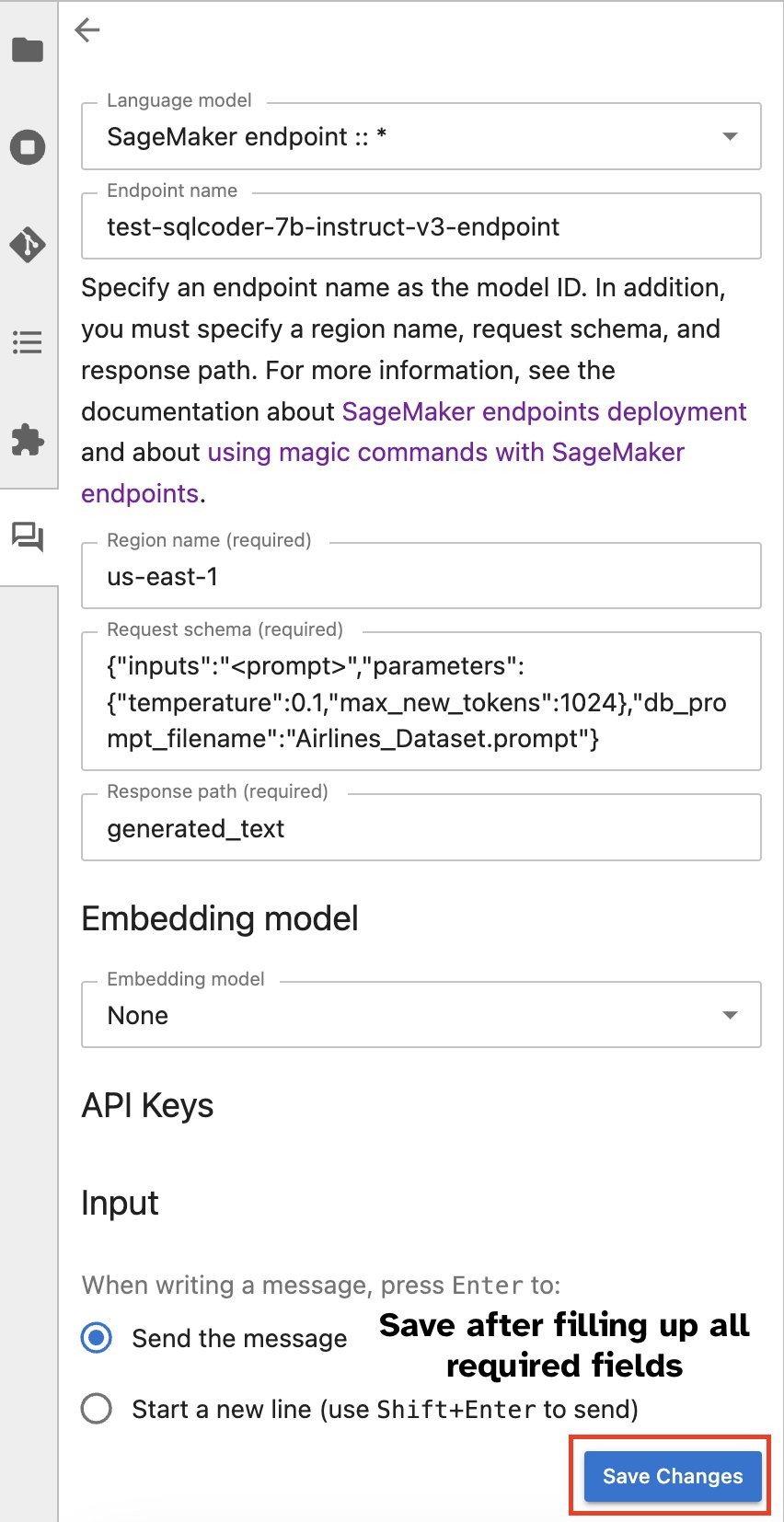
Alternativ können Sie über eine integrierte Benutzeroberfläche mit SageMaker-Endpunkten interagieren und so den Prozess der Generierung von Abfragen oder der Teilnahme am Dialog vereinfachen. Bevor Sie mit Ihrem SageMaker-Endpunkt chatten, konfigurieren Sie die relevanten Einstellungen in Jupyter AI für den SageMaker-Endpunkt, wie im folgenden Screenshot gezeigt.
 |
 |
Zusammenfassung
SageMaker Studio vereinfacht und rationalisiert jetzt den Arbeitsablauf von Datenwissenschaftlern durch die Integration der SQL-Unterstützung in JupyterLab-Notebooks. Dadurch können sich Datenwissenschaftler auf ihre Aufgaben konzentrieren, ohne mehrere Tools verwalten zu müssen. Darüber hinaus ermöglicht die neue integrierte SQL-Integration in SageMaker Studio es Datenpersonen, mühelos SQL-Abfragen mit Text in natürlicher Sprache als Eingabe zu generieren und so ihren Arbeitsablauf zu beschleunigen.
Wir empfehlen Ihnen, diese Funktionen in SageMaker Studio zu erkunden. Weitere Informationen finden Sie unter Bereiten Sie Daten mit SQL in Studio vor.
Anhang
Aktivieren Sie den SQL-Browser und die Notebook-SQL-Zelle in benutzerdefinierten Umgebungen
Wenn Sie kein SageMaker Distribution-Image oder Distribution-Images 1.5 oder niedriger verwenden, führen Sie die folgenden Befehle aus, um die SQL-Browsing-Funktion in Ihrer JupyterLab-Umgebung zu aktivieren:
Verschieben Sie das SQL-Browser-Widget
JupyterLab-Widgets ermöglichen eine Verschiebung. Je nach Wunsch können Sie Widgets auf beide Seiten des JupyterLab-Widgetbereichs verschieben. Wenn Sie möchten, können Sie die Richtung des SQL-Widgets auf die gegenüberliegende Seite (von rechts nach links) der Seitenleiste verschieben, indem Sie einfach mit der rechten Maustaste auf das Widget-Symbol klicken und auswählen Seitenleistenseite wechseln.
 |
 |
Über die Autoren
 Pranav Murthy ist ein AI/ML Specialist Solutions Architect bei AWS. Er konzentriert sich darauf, Kunden beim Erstellen, Trainieren, Bereitstellen und Migrieren von Workloads für maschinelles Lernen (ML) zu SageMaker zu unterstützen. Zuvor arbeitete er in der Halbleiterindustrie und entwickelte große Modelle für Computer Vision (CV) und Natural Language Processing (NLP), um Halbleiterprozesse mithilfe modernster ML-Techniken zu verbessern. In seiner Freizeit spielt er gerne Schach und reist. Sie finden Pranav auf LinkedIn.
Pranav Murthy ist ein AI/ML Specialist Solutions Architect bei AWS. Er konzentriert sich darauf, Kunden beim Erstellen, Trainieren, Bereitstellen und Migrieren von Workloads für maschinelles Lernen (ML) zu SageMaker zu unterstützen. Zuvor arbeitete er in der Halbleiterindustrie und entwickelte große Modelle für Computer Vision (CV) und Natural Language Processing (NLP), um Halbleiterprozesse mithilfe modernster ML-Techniken zu verbessern. In seiner Freizeit spielt er gerne Schach und reist. Sie finden Pranav auf LinkedIn.
 Varun Schah ist ein Software-Ingenieur, der an Amazon SageMaker Studio bei Amazon Web Services arbeitet. Sein Schwerpunkt liegt auf der Entwicklung interaktiver ML-Lösungen, die die Datenverarbeitung und Datenaufbereitung vereinfachen. In seiner Freizeit unternimmt Varun gerne Outdoor-Aktivitäten wie Wandern und Skifahren und ist immer bereit, neue, aufregende Orte zu entdecken.
Varun Schah ist ein Software-Ingenieur, der an Amazon SageMaker Studio bei Amazon Web Services arbeitet. Sein Schwerpunkt liegt auf der Entwicklung interaktiver ML-Lösungen, die die Datenverarbeitung und Datenaufbereitung vereinfachen. In seiner Freizeit unternimmt Varun gerne Outdoor-Aktivitäten wie Wandern und Skifahren und ist immer bereit, neue, aufregende Orte zu entdecken.
 Sumedha Swamy ist Hauptproduktmanager bei Amazon Web Services, wo er das SageMaker Studio-Team bei seiner Mission leitet, die bevorzugte IDE für Datenwissenschaft und maschinelles Lernen zu entwickeln. In den vergangenen 15 Jahren widmete er sich der Entwicklung von Verbraucher- und Unternehmensprodukten, die auf maschinellem Lernen basieren.
Sumedha Swamy ist Hauptproduktmanager bei Amazon Web Services, wo er das SageMaker Studio-Team bei seiner Mission leitet, die bevorzugte IDE für Datenwissenschaft und maschinelles Lernen zu entwickeln. In den vergangenen 15 Jahren widmete er sich der Entwicklung von Verbraucher- und Unternehmensprodukten, die auf maschinellem Lernen basieren.
 Bosco Albuquerque ist Sr. Partner Solutions Architect bei AWS und verfügt über mehr als 20 Jahre Erfahrung in der Arbeit mit Datenbank- und Analyseprodukten von Anbietern von Unternehmensdatenbanken und Cloud-Anbietern. Er hat Technologieunternehmen dabei geholfen, Datenanalyselösungen und -produkte zu entwerfen und zu implementieren.
Bosco Albuquerque ist Sr. Partner Solutions Architect bei AWS und verfügt über mehr als 20 Jahre Erfahrung in der Arbeit mit Datenbank- und Analyseprodukten von Anbietern von Unternehmensdatenbanken und Cloud-Anbietern. Er hat Technologieunternehmen dabei geholfen, Datenanalyselösungen und -produkte zu entwerfen und zu implementieren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

