What users expect from search engines has evolved over the years. Just returning lexically relevant results quickly is no longer enough for most users. Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. Amazon OpenSearch Service includes many features that allow you to enhance your search experience. We are excited about the OpenSearch Service features and enhancements we’ve added to that toolkit in 2023.
2023 was a year of rapid innovation within the artificial intelligence (AI) and machine learning (ML) space, and search has been a significant beneficiary of that progress. Throughout 2023, Amazon OpenSearch Service invested in enabling search teams to use the latest AI/ML technologies to improve and augment your existing search experiences, without having to rewrite your applications or build bespoke orchestrations, resulting in unlocking rapid development, iteration, and productization. These investments include the introduction of new search methods as well as functionality to simplify implementation of the methods available, which we review in this post.
Background: Lexical and semantic search
Before we get started, let’s review lexical and semantic search.
Lexical search
In lexical search, the search engine compares the words in the search query to the words in the documents, matching word for word. Only items that have words the user typed match the query. Traditional lexical search, based on term frequency models like BM25, is widely used and effective for many search applications. However, lexical search techniques struggle to go beyond the words included in the user’s query, resulting in highly relevant potential results not always being returned.
Semantic search
In semantic search, the search engine uses an ML model to encode text or other media (such as images and videos) from the source documents as a dense vector in a high-dimensional vector space. This is also called embedding the text into the vector space. It similarly codes the query as a vector and then uses a distance metric to find nearby vectors in the multi-dimensional space to find matches. The algorithm for finding nearby vectors is called k-nearest neighbors (k-NN). Semantic search doesn’t match individual query terms—it finds documents whose vector embedding is near the query’s embedding in the vector space and therefore semantically similar to the query. This allows you to return highly relevant items even if they don’t contain any of the words that were in the query.
OpenSearch has provided vector similarity search (k-NN and approximate k-NN) for several years, which has been valuable for customers who adopted it. However, not all customers who have the opportunity to benefit from k-NN have adopted it, due to the significant engineering effort and resources required to do so.
2023 releases: Fundamentals
In 2023 several features and improvements were launched on OpenSearch Service, including new features which are fundamental building blocks for continued search enhancements.
The OpenSearch Compare Search Results tool
The Compare Search Results tool, generally available in OpenSearch Service version 2.11, allows you to compare search results from two ranking techniques side by side, in OpenSearch Dashboards, to determine whether one query produces better results than the other. For customers who are interested in experimenting with the latest search methods powered by ML-assisted models, the ability to compare search results is critical. This can include comparing lexical search, semantic search, and hybrid search techniques to understand the benefits of each technique against your corpus, or adjustments such as field weighting and different stemming or lemmatization strategies.
The following screenshot shows an example of using the Compare Search Results tool.
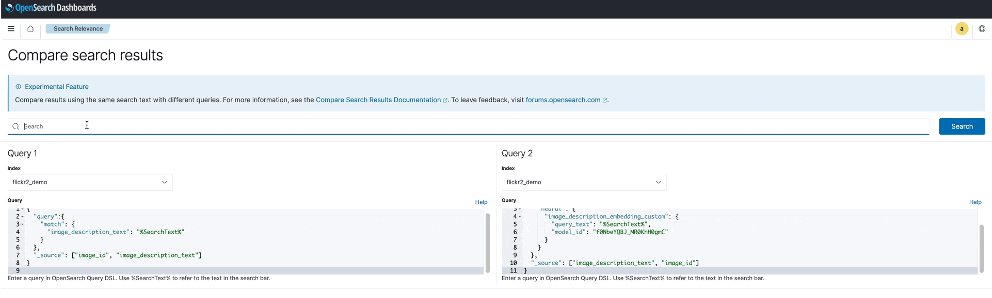
To learn more about semantic search and cross-modal search and experiment with a demo of the Compare Search Results tool, refer to Try semantic search with the Amazon OpenSearch Service vector engine.
Search pipelines
Search practitioners are looking to introduce new ways to enhance search queries as well as results. With the general availability of search pipelines, starting in OpenSearch Service version 2.9, you can build search query and result processing as a composition of modular processing steps, without complicating your application software. By integrating processors for functions such as filters, and with the ability to add a script to run on newly indexed documents, you can make your search applications more accurate and efficient and reduce the need for custom development.
Search pipelines incorporate three built-in processors: filter_query, rename_field, and script request, as well as new developer-focused APIs to enable developers who want to build their own processors to do so. OpenSearch will continue adding additional built-in processors to further expand on this functionality in the coming releases.
The following diagram illustrates the search pipelines architecture.
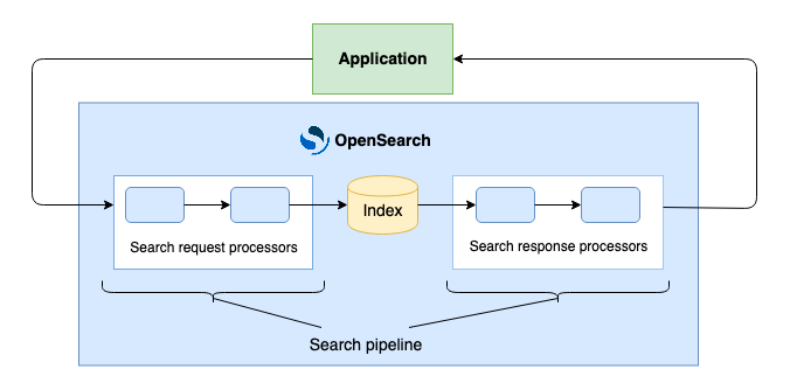
Byte-sized vectors in Lucene
Until now, the k-NN plugin in OpenSearch has supported indexing and querying vectors of type float, with each vector element occupying 4 bytes. This can be expensive in memory and storage, especially for large-scale use cases. With the new byte vector feature in OpenSearch Service version 2.9, you can reduce memory requirements by a factor of 4 and significantly reduce search latency, with minimal loss in quality (recall). To learn more, refer to Byte-quantized vectors in OpenSearch.
Support for new language analyzers
OpenSearch Service previously supported language analyzer plugins such as IK (Chinese), Kuromoji (Japanese), and Seunjeon (Korean), among several others. We added support for Nori (Korean), Sudachi (Japanese), Pinyin (Chinese), and STConvert Analysis (Chinese). These new plugins are available as a new package type, ZIP-PLUGIN, along with the previously supported TXT-DICTIONARY package type. You can navigate to the Packages page of the OpenSearch Service console to associate these plugins to your cluster, or use the AssociatePackage API.
2023 releases: Ease-of-use enhancements
The OpenSearch Service also made improvements in 2023 to enhance ease of use within key search features.
Semantic search with neural search
Previously, implementing semantic search meant that your application was responsible for the middleware to integrate text embedding models into search and ingest, orchestrating the encoding the corpus, and then using a k-NN search at query time.
OpenSearch Service introduced neural search in version 2.9, enabling builders to create and operationalize semantic search applications with significantly reduced undifferentiated heavy lifting. Your application no longer needs to deal with the vectorization of documents and queries; semantic search does that, and invokes k-NN during query time. Semantic search via the neural search feature transforms documents or other media into vector embeddings and indexes both the text and its vector embeddings in a vector index. When you use a neural query during search, neural search converts the query text into a vector embedding, uses vector search to compare the query and document embeddings, and returns the closest results. This functionality was initially released as experimental in OpenSearch Service version 2.4, and is now generally available with version 2.9.
AI/ML connectors to enable AI-powered search features
With OpenSearch Service 2.9, you can use out-of-the-box AI connectors to AWS AI and ML services and third-party alternatives to power features like neural search. For instance, you can connect to external ML models hosted on Amazon SageMaker, which provides comprehensive capabilities to manage models successfully in production. If you want to use the latest foundation models via a fully managed experience, you can use connectors for Amazon Bedrock to power use cases like multimodal search. Our initial release includes a connector to Cohere Embed, and through SageMaker and Amazon Bedrock, you have access to more third-party options. You can configure some of these integrations on your domains through the OpenSearch Service console integrations (see the following screenshot), and even automate model deployment to SageMaker.

Integrated models are cataloged in your OpenSearch Service domain, so that your team can discover the variety of models that are integrated and readily available for use. You even have the option to enable granular security controls on your model and connector resources to govern model and connector level access.
To foster an open ecosystem, we created a framework to empower partners to easily build and publish AI connectors. Technology providers can simply create a blueprint, which is a JSON document that describes secure RESTful communication between OpenSearch and your service. Technology partners can publish their connectors on our community site, and you can immediately use these AI connectors—whether for a self-managed cluster or on OpenSearch Service. You can find blueprints for each connector in the ML Commons GitHub repository.
Hybrid search supported by score combination
Semantic technologies such as vector embeddings for neural search and generative AI large language models (LLMs) for natural language processing have revolutionized search, reducing the need for manual synonym list management and fine-tuning. On the other hand, text-based (lexical) search outperforms semantic search in some important cases, such as part numbers or brand names. Hybrid search, the combination of the two methods, gives 14% higher search relevancy (as measured by NDCG@10—a measure of ranking quality) than BM25 alone, so customers want to use hybrid search to get the best of both. For more information about detailed benchmarking score accuracy and performance, refer to Improve search relevance with hybrid search, generally available in OpenSearch 2.10.
Until now, combining them has been challenging given the different relevancy scales for each method. Previously, to implement a hybrid approach, you had to run multiple queries independently, then normalize and combine scores outside of OpenSearch. With the launch of the new hybrid score combination and normalization query type in OpenSearch Service 2.11, OpenSearch handles score normalization and combination in one query, making hybrid search easier to implement and a more efficient way to improve search relevance.
New search methods
Lastly, OpenSearch Service now features new search methods.
Neural sparse retrieval
OpenSearch Service 2.11 introduced neural sparse search, a new kind of sparse embedding method that is similar in many ways to classic term-based indexing, but with low-frequency words and phrases better represented. Sparse semantic retrieval uses transformer models (such as BERT) to build information-rich embeddings that solve for the vocabulary mismatch problem in a scalable way, while having similar computational cost and latency to lexical search. This new sparse retrieval functionality with OpenSearch offers two modes with different advantages: a document-only mode and a bi-encoder mode. The document-only mode can deliver low-latency performance more comparable to BM25 search, with limitations for advanced syntax as compared to dense methods. The bi-encoder mode can maximize search relevance while performing at higher latencies. With this update, you can now choose the method that works best for your performance, accuracy, and cost requirements.
Multi-modal search
OpenSearch Service 2.11 introduces text and image multimodal search using neural search. This functionality allows you to search image and text pairs, like product catalog items (product image and description), based on visual and semantic similarity. This enables new search experiences that can deliver more relevant results. For instance, you can search for “white blouse” to retrieve products with images that match that description, even if the product title is “cream colored shirt.” The ML model that powers this experience is able to associate semantics and visual characteristics. You can also search by image to retrieve visually similar products or search by both text and image to find the products most similar to a particular product catalog item.
You can now build these capabilities into your application to connect directly to multimodal models and run multimodal search queries without having to build custom middleware. The Amazon Titan Multimodal Embeddings model can be integrated with OpenSearch Service to support this method. Refer to Multimodal search for guidance on how to get started with multimodal semantic search, and look out for more input types to be added in future releases. You can also try out the demo of cross-modal textual and image search, which shows searching for images using textual descriptions.
Summary
OpenSearch Service offers an array of different tools to build your search application, but the best implementation will depend on your corpus and your business needs and goals. We encourage search practitioners to begin testing the search methods available in order to find the right fit for your use case. In 2024 and beyond, you can expect to continue to see this fast pace of search innovation in order to keep the latest and greatest search technologies at the fingertips of OpenSearch search practitioners.
About the Authors
 Dagney Braun is a Senior Manager of Product at Amazon Web Services OpenSearch Team. She is passionate about improving the ease of use of OpenSearch, and expanding the tools available to better support all customer use-cases.
Dagney Braun is a Senior Manager of Product at Amazon Web Services OpenSearch Team. She is passionate about improving the ease of use of OpenSearch, and expanding the tools available to better support all customer use-cases.
 Stavros Macrakis is a Senior Technical Product Manager on the OpenSearch project of Amazon Web Services. He is passionate about giving customers the tools to improve the quality of their search results.
Stavros Macrakis is a Senior Technical Product Manager on the OpenSearch project of Amazon Web Services. He is passionate about giving customers the tools to improve the quality of their search results.
 Dylan Tong is a Senior Product Manager at Amazon Web Services. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearch’s vector database capabilities. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain. Dylan holds a BSc and MEng degree in Computer Science from Cornell University.
Dylan Tong is a Senior Product Manager at Amazon Web Services. He leads the product initiatives for AI and machine learning (ML) on OpenSearch including OpenSearch’s vector database capabilities. Dylan has decades of experience working directly with customers and creating products and solutions in the database, analytics and AI/ML domain. Dylan holds a BSc and MEng degree in Computer Science from Cornell University.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-search-enhancements-2023-roundup/

