Introduction
In AI, two distinct challenges have surfaced: deploying large models in cloud environments, incurring formidable compute costs that impede scalability and profitability, and accommodating resource-constrained edge devices struggling to support complex models. The common thread among these challenges is the imperative to shrink model size without compromising accuracy. Model Quantization, a popular technique, offers a potential solution but raises concerns about potential accuracy trade-offs.

Quantization-aware training emerges as a compelling answer. It seamlessly integrates quantization into the model training process, enabling significant model size reductions, sometimes by two to four times or more, while preserving critical accuracy. This article delves deep into quantization, comparing post-training quantization (PTQ) and quantization-aware training (QAT). Furthermore, we provide practical insights, demonstrating how both methods can be effectively implemented using SuperGradients, an open-source training library developed by Deci.
Additionally, we explore the optimization of Convolutional Neural Networks (CNNs) for mobile and embedded platforms, addressing the unique challenges of size and computational demands. We focus on quantization, examining the role of number representation in optimizing models for mobile and embedded platforms.
Learning Objectives
- Understand the concept of model quantization in AI.
- Learn about typical quantization levels and their trade-offs.
- Differentiate between Quantization-Aware Training (QAT) and Post-training Quantization (PTQ).
- Explore the advantages of model quantization, including memory efficiency and energy savings.
- Discover how model quantization enables broader AI model deployment.
This article was published as a part of the Data Science Blogathon.
Table of contents
Understanding the Need for Model Quantization
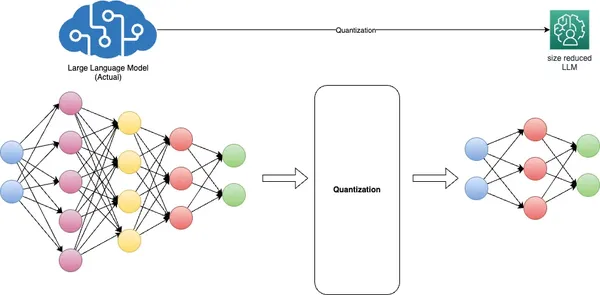
Model quantization, a fundamental technique in deep learning, aims to address critical challenges related to model size, inference speed, and memory efficiency. It accomplishes this by converting model weights from high-precision floating-point representations, typically 32-bit (FP32), to lower-precision floating-point (FP) or integer (INT) formats, such as 16-bit or 8-bit.
The benefits of quantization are twofold. Firstly, it significantly reduces the model’s memory footprint and improves inference speed without causing substantial accuracy degradation. Secondly, it optimizes model performance by reducing memory bandwidth requirements and enhancing cache utilization.
INT8 representation is often colloquially referred to as “quantized” in the context of deep neural networks, but other formats like UINT8 and INT16 are also utilized, depending on the hardware architecture. Different models necessitate distinct quantization approaches, often demanding prior knowledge and meticulous fine-tuning to balance accuracy and model size reduction.
Quantization introduces challenges, particularly with low-precision integer formats such as INT8, owing to their limited dynamic range. Squeezing the expansive dynamic range of FP32 into just 255 values of INT8 can lead to accuracy loss. To mitigate this challenge, per-channel or per-layer scaling adjusts the scale and zero-point values of weight and activation tensors to fit the quantized format better.
Additionally, quantization-aware training simulates the quantization process during model training, allowing the model to adapt to lower precision gracefully. The squeeze, or range estimation, is a vital aspect of this process, achieved through calibration.
In essence, model quantization is indispensable for deploying efficient AI models, striking a delicate balance between accuracy and resource efficiency, particularly on edge devices with limited computational resources.
Techniques for Model Quantization
Quantization Level
Quantization converts a model’s high-precision floating-point weights and activations into lower-precision fixed-point values. The “quantization level” refers to the number of bits representing these fixed-point values. Typical quantization levels are 8-bit, 16-bit, and even binary (1-bit) quantization. Choosing an appropriate quantization level depends on the trade-off between model accuracy and memory, storage, and computation efficiency.
Quantization-Aware Training (QAT) in Detail
Quantization-aware training (QAT) is a technique used during the training of neural networks to prepare them for quantization. It helps the model learn to operate effectively with lower-precision data. Here’s how QAT works:
- During QAT, the model is trained with quantization constraints. These constraints include simulating lower-precision data types (e.g., 8-bit integers) during forward and backward passes.
- A quantization-aware loss function is used, which considers the quantization error to penalize deviations from the full-precision model’s behavior.
- QAT helps the model learn to cope with the quantization-induced loss of precision by adjusting its weights and activations accordingly.
Post-training Quantization (PTQ) vs. Quantization-Aware Training (QAT)
PTQ and QAT are two distinct approaches to model quantization, each with its advantages and implications.

Post-training Quantization (PTQ)
PTQ is a quantization technique applied after a model has undergone full training with standard precision, typically in floating-point representation. In PTQ, the model’s weights and activations are quantized into lower-precision formats, such as 8-bit integers or 16-bit floats, to reduce memory usage and improve inference speed. While PTQ offers simplicity and compatibility with pre-existing models, it may lead to a moderate loss of accuracy due to the post-training conversion.
Quantization-Aware Training (QAT)
QAT, on the other hand, is a more nuanced approach to quantization. It involves fine-tuning the PTQ model with quantization in mind. During QAT, the quantization process, encompassing scaling, clipping, and rounding, is seamlessly integrated into the training process. This allows the model to be trained explicitly to retain its accuracy even after quantization. QAT optimizes model weights to emulate inference-time quantization accurately. During training, it employs “fake” quantization modules to mimic the testing or inference phase behavior, where weights are rounded or clamped to low-precision representations. This approach leads to higher accuracy during real-world inference, as the model is aware of quantization from the outset.
Quantization Algorithms
There are various algorithms and methods for quantizing neural networks. Some standard quantization techniques include:
- Weight Quantization involves quantizing the model’s weights to lower-precision values (e.g., 8-bit integers). Weight quantization can significantly reduce the memory footprint of the model.
- Activation Quantization: Besides quantizing weights, activations can be quantized during inference. This reduces computational requirements and memory usage further.
- Dynamic Quantization: Instead of using a fixed quantization scale, dynamic quantization allows for dynamic scaling of quantization ranges during inference, helping mitigate the loss of accuracy.
- Quantization-Aware Training (QAT): As mentioned earlier, QAT is a training method that incorporates quantization constraints and enables the model to learn to operate with lower-precision data.
- Mixed-Precision Quantization: This technique combines different precision quantization for weights and activations, optimizing for accuracy and efficiency.
- Post-training Quantization with Calibration: In post-training quantization, calibration is used to determine the quantization ranges of weights and activations to minimize the loss of accuracy.
In summary, the choice between Post-training Quantization and Quantization-Aware Training (QAT) hinges on the specific deployment needs and the balance between model performance and efficiency. PTQ offers a more straightforward approach to reducing model size. Still, it can suffer from accuracy loss due to the inherent mismatch between the original full-precision model and its quantized counterpart. On the other hand, QAT integrates quantization constraints directly into the training process, ensuring that the model learns to operate effectively with lower-precision data from the outset.
This results in better accuracy retention and finer control over the quantization process. When maintaining high accuracy is paramount, QAT is often the preferred choice. It empowers deep learning models to strike the delicate balance between optimal performance and efficient utilization of hardware resources. It is particularly well-suited for deployment on resource-constrained devices where accuracy cannot be compromised.
Benefits of Model Quantization
- Faster Inference: Quantized models are faster to deploy and run, making them ideal for real-time applications like voice recognition, image processing, and autonomous vehicles. Reduced precision allows for quicker computations, leading to lower latency.
- Lower Deployment Costs: Smaller model sizes translate to reduced storage and memory requirements, significantly lowering the cost of deploying AI solutions, especially in cloud-based services where storage and computation costs are significant considerations.
- Increased Accessibility: Quantization enables AI to be deployed on resource-constrained devices like smartphones, IoT devices, and edge computing platforms. This extends the reach of AI to a broader audience and opens up new opportunities for applications in remote or underdeveloped areas.
- Improved Privacy and Security: By reducing models’ size, quantization can facilitate on-device AI processing, reducing the need to send sensitive data to centralized servers. This enhances privacy and security by minimizing data exposure to external threats.
- Environmental Impact: Smaller model sizes lead to reduced power consumption, making data centers and cloud infrastructure more energy-efficient. This helps mitigate the environmental impact of large-scale AI deployments.
- Scalability: Quantized models are more accessible to distribute and deploy, allowing for the efficient scaling of AI services to accommodate increasing user demands and traffic without significant infrastructure investments.
- Compatibility: Quantized models are often more compatible with a broader range of hardware, making deploying AI solutions on various devices and platforms more accessible.
- Real-time Applications: Reduced model size and faster inference make quantized models suitable for real-time applications such as augmented reality, virtual reality, and gaming, where low latency is crucial for a seamless user experience.
These benefits collectively make model quantization a vital technique for optimizing AI deployments, ensuring both efficiency and accessibility across a wide range of applications and devices.
Real-world Examples
- Healthcare: In the healthcare sector, model quantization has enabled deploying AI-powered medical imaging solutions on edge devices. Portable ultrasound machines and smartphone apps now utilize quantized models for diagnosing heart conditions and detecting tumors. This reduces the need for expensive, specialized equipment and enables healthcare professionals to provide timely and accurate diagnoses in remote or resource-limited settings.
- Autonomous Vehicles: Quantized models play a crucial role in autonomous vehicles, where real-time decision-making is imperative. Self-driving cars can operate efficiently on embedded hardware by reducing the size of deep learning models for perception and control tasks. This enhances safety, responsiveness, and the ability to navigate complex environments, making autonomous driving a reality.
- Natural Language Processing (NLP): In the field of NLP, quantized models have enabled the deployment of language models on smart speakers, chatbots, and mobile devices. This allows for real-time language understanding and generation, making voice assistants and language translation apps more accessible and responsive to user queries.
- Industrial Automation: Industrial automation leverages quantized models for predictive maintenance and quality control. Edge devices equipped with quantized models can monitor machinery health and detect defects in real-time, minimizing downtime and improving production efficiency in manufacturing plants.
- Retail and E-commerce: Retailers use quantized models for inventory management and customer engagement. Real-time image recognition models deployed on in-store cameras can track product availability and optimize store layouts. Similarly, quantized recommendation systems provide personalized shopping experiences on e-commerce platforms, improving customer satisfaction and sales.
These real-world examples illustrate the versatility and impact of model quantization across various industries, making AI solutions more accessible, efficient, and cost-effective.
Challenges and Considerations
In model quantization, several critical challenges and considerations shape the landscape of efficient AI deployments. A fundamental challenge lies in striking the delicate balance between accuracy and efficiency. Aggressive quantization, while enhancing resource efficiency, can result in significant accuracy loss, making it imperative to tailor the quantization approach to the specific demands of the application.
Moreover, not all AI models are equally amenable to quantization, with the complexity of models playing a pivotal role in their sensitivity to accuracy reductions during quantization. This necessitates carefully evaluating whether quantization suits a given model and use case. The choice between post-training quantization (PTQ) and quantization-aware training (QAT) is equally critical. This decision significantly impacts accuracy, model complexity, and development timelines, underlining the need for developers to make well-informed choices that align with their project’s deployment requirements and available resources. These considerations collectively emphasize the importance of meticulous planning and assessment when implementing model quantization, as they directly influence the intricate trade-offs between model accuracy and resource efficiency in AI applications.
Accuracy Trade-offs
- A detailed examination of the trade-offs between model accuracy and quantization: This section delves into the intricate balance between maintaining model accuracy and achieving resource efficiency through quantization. It explores how aggressive quantization can lead to accuracy loss and the considerations required to make informed decisions regarding the level of quantization that suits specific applications.
Quantization-Aware Training Challenges
- Common challenges faced when implementing QAT and strategies to overcome them: We address the hurdles developers encounter when integrating quantization-aware training (QAT) into the model training process. We also provide insights into strategies and best practices to overcome these challenges, ensuring successful QAT implementation.
Hardware Limitations
- Discussing the role of hardware accelerators in quantized model deployment: This section explores the role of hardware accelerators, such as GPUs, TPUs, and dedicated AI hardware, in the deployment of quantized models. It emphasizes the significance of hardware compatibility and optimization for achieving efficient and high-performance inference with quantized models.
Real-time Object Detection on a Raspberry Pi using Quantized MobileNetV2
1: Hardware Setup

- Introduce your Raspberry Pi model (e.g., Raspberry Pi 4).
- Raspberry Pi Camera Module (or USB webcam for older models)
- Power supply
- MicroSD card with Raspberry Pi OS
- HDMI cable, monitor, keyboard, and mouse (for initial setup)
- Emphasize the need for deploying a lightweight model on the Raspberry Pi due to its resource constraints.
2: Software Installation
- Set up the Raspberry Pi with Raspberry Pi OS (formerly Raspbian).
- Install Python and the required libraries:
sudo apt update
sudo apt install python3-pip
pip3 install opencv-python-headless
pip3 install opencv-python
pip3 install numpy
pip3 install tensorflow==2.73: Data Collection and Preprocessing
- Collect or access a dataset for object detection (e.g., COCO dataset).
- Labeling objects of interest in images using tools like LabelImg.
- Converting annotations to the required format (e.g., TFRecord) for TensorFlow.
4: Import Necessary Libraries
import argparse # For command-line argument parsing
import cv2 # OpenCV library for computer vision tasks
import imutils # Utility functions for working with images and video
import numpy as np # NumPy for numerical operations
import tensorflow as tf # TensorFlow for machine learning and deep learning5: Model Quantization
- Quantize a pre-trained MobileNetV2 model using TensorFlow:
import tensorflow as tf # Load the pre-trained model
model = tf.keras.applications.MobileNetV2(weights='imagenet', input_shape=(224, 224, 3)) # Quantize the model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
tflite_quantized_model = converter.convert() # Save the quantized model
with open('quantized_mobilenetv2.tflite', 'wb') as f: f.write(tflite_quantized_model)Step 5: Deployment and Real-time Inference6: Argument Parsing
- “argparse” is used to parse command-line arguments. Here, it’s configured to accept the path to the custom-trained model, the labels file, and a confidence threshold.
# Parse command-line arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to your custom trained model")
ap.add_argument("-l", "--labels", required=True, help="path to your class labels file")
ap.add_argument("-c", "--confidence", type=float, default=0.2, help="minimum probability to filter weak detections")
args = vars(ap.parse_args())
7: Model Loading and Label Loading
- The code loads the custom-trained object detection model and class labels.
# Load your custom-trained model and labels
print("[INFO] loading model...")
model = tf.saved_model.load(args["model"]) # Load the custom-trained TensorFlow model
with open(args["labels"], "r") as f: CLASSES = f.read().strip().split("n") # Load class labels from a file
8: Video Stream Initialization
- It sets up the video stream, which captures frames from the default camera.
# Initialize video stream
print("[INFO] starting video stream...")
cap = cv2.VideoCapture(0) # Initialize the video stream (0 for the default camera)
fps = cv2.getTickFrequency()
start_time = cv2.getTickCount()
9: Real-time Object Detection Loop
- The main loop captures frames from the video stream, performs object detection using the custom model, and displays the results on the frame.
- Detected objects are drawn as bounding boxes with labels and confidence scores.
while True: # Read a frame from the video stream ret, frame = cap.read() frame = imutils.resize(frame, width=800) # Resize the frame for better processing speed # Perform object detection using the custom model detections = model(frame) # Loop over detected objects for detection in detections['detection_boxes']: # Extract bounding box coordinates startY, startX, endY, endX = detection[0], detection[1], detection[2], detection[3] # Draw bounding box and label on the frame label = CLASSES[0] # Replace with your class label logic confidence = 1.0 # Replace with your confidence score logic color = (0, 255, 0) # Green color for bounding box (you can change this) cv2.rectangle(frame, (startX, startY), (endX, endY), color, 2) text = "{}: {:.2f}%".format(label, confidence * 100) cv2.putText(frame, text, (startX, startY - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Display the frame with object detection results cv2.imshow("Custom Object Detection", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break # Break the loop if 'q' key is pressed # Clean up
cap.release() # Release the video stream
cv2.destroyAllWindows() # Close OpenCV windows
10: Performance Evaluation
- Measure the inference speed and resource utilization on the Raspberry Pi using time and system monitoring tools (htop).
- Discuss any trade-offs between accuracy and efficiency observed during the project.
11: Conclusion and Insights
- Summarize the essential findings and emphasize how model quantization enabled real-time object detection on a resource-constrained device like the Raspberry Pi.
- Highlight this project’s practicality and real-world applications, such as deploying object detection in security cameras or robotics.
By following these steps and using the provided Python code, learners can build a real-time object detection system on a Raspberry Pi, demonstrating the benefits of model quantization for efficient AI applications on edge devices.
Conclusion
Model quantization is a pivotal technique that profoundly influences the landscape of AI deployment. It empowers resource-constrained mobile and edge devices by enabling them to run AI applications efficiently and enhances the scalability and cost-effectiveness of cloud-based AI services. The impact of quantization reverberates across the AI ecosystem, making AI more accessible, responsive, and environmentally friendly.
Furthermore, quantization aligns with emerging AI trends, like federated learning and AI at the edge, opening up new frontiers of innovation. As we witness the continued evolution of AI, model quantization stands as a vital tool, ensuring that AI can reach a broader audience, deliver real-time insights, and adapt to the evolving demands of diverse industries. In this dynamic landscape, model quantization serves as a bridge between AI’s power and its deployment’s practicality, forging a path toward more efficient, accessible, and sustainable AI solutions.
Key Takeaways
- Model quantization is vital for deploying large AI models on resource-constrained devices.
- Quantization levels, like 8-bit or 16-bit, reduce model size and improve efficiency.
- Quantization-Aware Training (QAT) presser Quantization-aware training quantifies training during training.
- Post-training quantization (PTQ) simplifies but may reduce accuracy, requiring fine-tuning.
- The choice depends on specific deployment needs and the balance between accuracy and efficiency, which is crucial for resource-constrained devices.
Frequently Asked Questions
A: Model quantization in AI is a technique that involves reducing the precision of a neural network model’s weights and activations. It converts high-precision floating-point values to lower-precision fixed-point or integer representations, making the model more memory-efficient and faster to execute.
A: Common quantization levels include 8-bit, 16-bit, and binary (1-bit) quantization. The choice of quantization level depends on the balance between model accuracy and memory/storage/compute efficiency required for a specific application.
A: QAT incorporates quantization constraints during training, allowing the model to adapt to lower-precision computations. PTQ, on the other hand, quantizes a pre-trained model after standard training, potentially requiring fine-tuning to regain lost accuracy.
A: Model quantization offers advantages such as reduced memory footprint, improved inference speed, energy efficiency, broader deployment on resource-constrained devices, cost savings, and enhanced privacy and security due to smaller model sizes.
A: Choosing QAT when maintaining model accuracy is a priority. QAT ensures better accuracy retention by integrating quantization constraints during training, making it ideal when accuracy is paramount. PTQ is more straightforward but may require additional fine-tuning to recover accuracy. The choice depends on specific deployment needs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2023/11/model-quantization-for-large-scale-deployment/

