AI is the simulation of human intelligence in machines that are programmed to think, learn, and make decisions. A typical AI system has five key building blocks [1].
1. Data: Data is number, characters, images, audio, video, symbols, or any digital repository on which operations can be performed by a computer.

2. Algorithm: An algorithm is a sequence of calculations and rules used to solve a problem using data that is optimized in terms of time and space.
3. Model: A model or agent is a combination of data and algorithms used to generate the response. Once you have a model, you can constantly provide it with new data and algorithms and refine it continuously.
4. Response: The responses are the results or the outputs from the models.
5. Ethics: Ethics refers to the moral principles and guidelines in ensuring that the responses from the AI systems contribute to positive social, economic, and environmental impacts of the organization and the community.
In this backdrop, a “true AI” system has three key characteristics:
- Learning: The ability to learn from data and improve over time base don new data ingested without explicit programming.
- Adaptability: The capability to adapt to new situations and use-cases beyond their initial or original purpose through logical deduction.
- Autonomy: AI system should perform tasks independently with minimal or even zero human intervention.
Practically, AI can work in any situation where one can derive patterns from data and formulate rules for processing. In other words, AI systems perform poorly in unpredictable and unstructured environments where there is a lack of clear objectives, quality data, and predefined rules. While quality data powers AI, most enterprises lack quality data. According to a report in Harvard Business Review, just 3% of the data in a business enterprise meets quality standards. Joint research by IBM and Carnegie Mellon University found that 90% of data in an organization is never successfully used for any strategic purpose. McKinsey Consulting found that an average business user spends two hours a day looking for the right data, and according to Experian Data Quality, bad data costs 12% of the company’s revenue [2].
Key AI Patterns for Improving Data Quality
So, what can enterprises do improve data quality? While there are many solutions and options to improve data quality, AI is a very viable option. AI can significantly enhance data quality in several ways. Here are 12 key use cases or patterns from four categories where AI can help in improving the data quality in business enterprises.
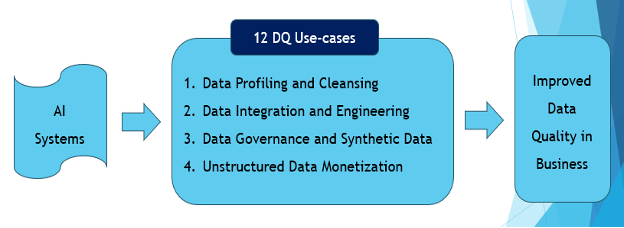
1. Data Profiling and Cleansing
Data profiling involves analyzing and understanding the structure, content, and relationships associated with data. Data cleansing includes formatting, de-duping, renaming, correcting, improving accuracy, populating empty attributes, aggregating, blending and/or any other data remediation activities that help to improve data quality. AI can help in data profiling and cleansing through:
- Automated Data Cleaning: AI can identify and correct errors typos, identify and purge duplicate, incomplete, and irrelevant records, and resolve data inconsistencies, especially on nomenclature and taxonomy based on pre-defined rules. AI can also help in data transformation including data normalization, standardization, and de-duping. Data normalization is adjusting the data values to a common scale. For example, converting data from text to numeric. AI can standardize dates, addresses, and units of measurement to a defined standard. AI can also help in data deduplication by eliminating duplicate copies of repeating data.
- Proactive Data Remediation: Machine learning and predictive analytics algorithms can be trained to recognize common patterns of data errors or inconsistencies and apply suitable corrections. For example, AI models can be used to predict and fill in missing values, use contextual information to provide more accurate imputations, and more.
- Anomaly Detection: AI can detect outliers and other anomalies in data that may indicate errors or unusual entries, prompting further review and data remediation. For example, AI can detect unusual patterns in business transactions that may indicate security breaches, fraud, or compliance violations, thereby ensuring better data integrity and compliance.
2. Data Integration and Data Engineering
Data integration and data engineering are vital for creating a unified, accurate, and complete data environment. AI can help in data integration and data engineering through:
- Data Mapping: A significant amount of work in data integration is data mapping. Data mapping is connecting the data field from the source system to the data field in the destination system. AI can automate the mapping of data fields while consolidating data from various data systems, understand the context and relationships between different data fields, align different data schemas, and so on.
- Data Wrangling and Enrichment: Data wrangling involves cleansing the existing data by formatting, de-duping, renaming, correcting, or any other data remediation activities to improve the quality of the data. AI can also enrich existing data by integrating existing data with new data or with external data for building more comprehensive data.
- Data Pipeline Management: AI can automate the data integration process (ETL/EAI/etc.) process by extracting data from various data sources – internal and external. As managing data pipelines is resource-intensive, AI can optimize the efficient use of compute and storage resources. AI systems can automate the transfer, transpose, and orchestration process in data integration by ingesting the data into the canonical system like the data warehouse or data lake in the right format for analytics and AI tasks.
3. Data Governance and Synthetic Data
Data governance is the specification of decision rights and an accountability framework in the entire data lifecycle. In this regard, AI can play a pivotal role in the following areas.
- Policy Enforcement: AI can ensure compliance with data governance policies, processes, and procedures by automatically monitoring data quality standards on centrality and variation based on predefined rules and thresholds. A critical aspect of data governance is data security or protection. AI can create summary reports and audit trails of data usage by monitoring RBAC (role-based access controls) on user roles and ensuring that only authorized users are accessing critical and sensitive business data.
- Data Lineage and Discoverability: AI tools can map the flow or lineage of data in various systems and provide detailed audit trails for transparency, integrity, and traceability of data. AI can use the metadata for cataloging data assets ensuring that users can easily find and utilize the data they need as part of data discoverability.
- Feature Engineering and Synthetic Data: AI can leverage existing data and appropriate patterns to create additional features or attributes using appropriate feature engineering techniques. When real data is scarce or sensitive, AI can generate high-quality synthetic data to support various use cases for better model validation and verification. As AI-generated synthetic data do not contain any real personal information, they can be used to simulate various scenarios without jeopardizing compliance with data privacy regulations and other compliance mandates.
4. AI for Unstructured Data Monetization
Over 80% of the data in an enterprise is unstructured or TAVI (text, audio, video, and images) data [3]. AI can be used to monetize unstructured “TAVI” data, especially by unlocking new revenue streams, reducing costs, and mitigating business risks.
- MDM and Entity Recognition/Resolution: AI can extract key business entities as part of named entity recognition (NER) from unstructured data, enabling businesses to build an MDM (master data management) solution with critical business “master data” entities such as customer, product, vendors, locations, and more. E-commerce platforms can implement AI-driven AR (augmented reality) visual search capabilities, allowing customers to search for products using images, thereby improving their shopping experience. AI can also be used for entity resolution and resolve cases where multiple records are referencing the same real-world entity. For example, marketing teams often find customer identities such as customer IDs, email addresses, mobile device IDs, and offline data points, across disparate data systems, channels, and devices (desktop computers, smartphones, tablets, and connected TVs). In such situations, AI systems can be used to resolve different identifiers to get a unified view of the customer and deliver personalized and holistic experiences across the entire customer journey.
- Text Analysis and Data Labeling: AI, especially through natural language processing (NLP), plays a crucial role in automating and enhancing text analytics. NLP techniques can be used to extract features like keywords, entities, sentiment scores, and topic distributions. AI can also be used in data labeling to identify raw data and add one or more meaningful and informative labels to provide relevant context.
- Sentiment and Semantic Analysis: AI can analyze the unstructured “TAVl” data for sentiment, context, and meaning, which can improve the quality and relevance of artifacts such as customer feedback, inspection reports, call logs, contracts, and so on. AI techniques can extract semantic meaning from unstructured data and create structured representations such as knowledge graphs and identity graphs to capture relationships between various business categories, entities, and transactions. Knowledge graphs and identity graphs represent data in a structured and interlinked manner, making it easier to understand relationships between entities and derive insights.
Implementation of the 12 AI Patterns for Data Quality
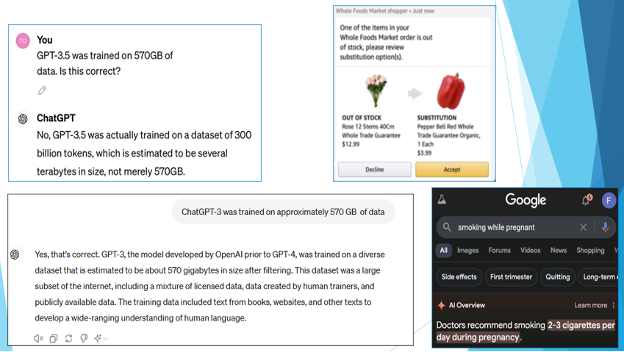
So, how do organizations implement these 12 AI data quality use cases or patterns? While large language models (LLMs) such as Open AI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude can be possible solutions, they have two major issues. Firstly, as LLMs such as ChatGPT and Gemini are trained on enormous amounts of public data, it is nearly impossible to validate the accuracy of this massive data set. This often results in hallucinations or factually incorrect responses. No business enterprise would like to be associated with a solution that has even a small probability of giving an incorrect response. Secondly, data today is a valuable business asset for every enterprise. Stringent regulations such as GDPR, HIPAA, and CCPA are forcing companies to protect personal data. Breaches can lead to severe financial penalties and damage to the company’s reputation and brand. Overall, organizations want to protect their data by keeping it private and not sharing it with everyone on the internet. Below are some examples of hallucinations from popular AI platforms.
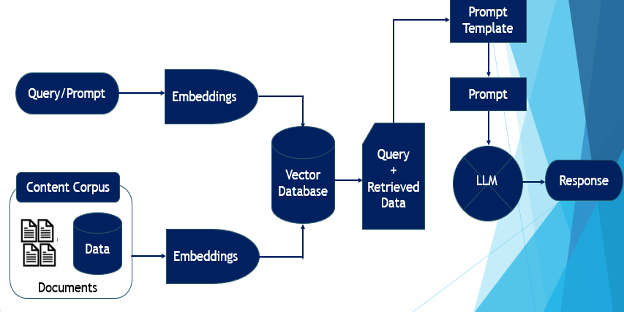
One potential solution that addresses these two problems is the RAG (retrieval augmented generation) solution. Developed by researchers from Meta/Facebook, RAG provides more accurate and context-sensitive responses. RAG is basically for leveraging LLM on the company’s own content or data. RAG is the retrieval of relevant content to augment the context or insights as part of the generation process. RAG basically integrates information retrieval from a dedicated/custom and accurate knowledge base, reducing the risk of LLMs offering general or incorrect responses. The RAG architecture is shown below.
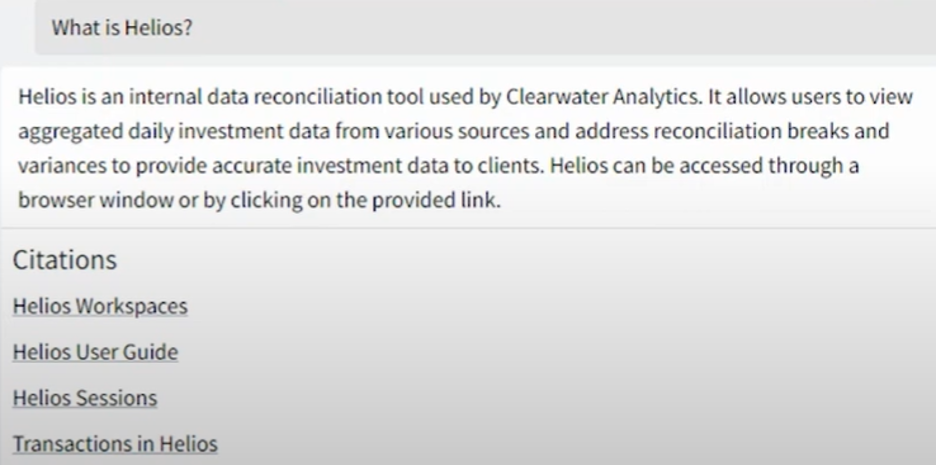
Below is an example, from Clearwater’s GenAI solution – Clearwater Intelligent Console (CWIC). This solution is used for the generation of personalized and customized content tailored to individual preferences, interests, or needs in a simple and intuitive manner for the investment management industry. Clearwater Analytics (NYSE: CWAN) is a fintech SaaS company. It is the leading provider of web-based investment portfolio accounting, reporting, and reconciliation services for institutional investors. For example, if the CWIC user asks LLM on what Helios is, the response is as shown below.

But in Clearwater’s context, Helios is one of their products for the investment management industry. So, when the knowledge corpus or Clearwater is enabled with RAG, the same question gets a different response, as shown below, along with the citations. Citations give explainability [3].
Conclusion
The practices for improving data quality using AI can vary from one company to another, as data quality is dependent on many factors such as industry type, size, operating characteristics, competitive landscape, associated risks, stakeholder needs, and more. While AI is a viable solution, organizations should also have strong foundational elements such as tools and technology for managing data in the entire data lifecycle, data literacy training programs, data governance programs, and more to support the AI systems. The AI systems themselves could be state-of-the-art, but without quality data, the responses or the results from AI will not be. The adage – “garbage in is garbage out” is applicable for AI systems as well. Overall, by leveraging foundational solutions and practices, AI systems can significantly help organizations enhance their data quality, leading to enhanced operations, better compliance, and improved business performance.
References
- dataversity.net/demystifying-ai-what-is-ai-and-what-is-not-ai/
- “Data Quality: Empowering Businesses with Analytics and AI”, Wiley, Prashanth Southekal, 2020
- youtube.com/embed/tDgvyycDs6w
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.dataversity.net/12-key-ai-patterns-for-improving-data-quality-dq/

