Sự gia tăng của tìm kiếm theo ngữ cảnh và ngữ nghĩa đã làm cho việc tìm kiếm của các doanh nghiệp thương mại điện tử và bán lẻ trở nên dễ dàng đối với người tiêu dùng. Các công cụ tìm kiếm và hệ thống đề xuất được hỗ trợ bởi AI tổng hợp có thể cải thiện trải nghiệm tìm kiếm sản phẩm theo cấp số nhân bằng cách hiểu các truy vấn ngôn ngữ tự nhiên và trả về kết quả chính xác hơn. Điều này nâng cao trải nghiệm tổng thể của người dùng, giúp khách hàng tìm thấy chính xác những gì họ đang tìm kiếm.
Dịch vụ Tìm kiếm Mở của Amazon bây giờ hỗ trợ cosine tương tự số liệu cho các chỉ số k-NN. Độ tương tự cosin đo cosin của góc giữa hai vectơ, trong đó góc cosin nhỏ hơn biểu thị độ tương tự cao hơn giữa các vectơ. Với độ tương tự cosin, bạn có thể đo hướng giữa hai vectơ, điều này làm cho nó trở thành một lựa chọn tốt cho một số ứng dụng tìm kiếm ngữ nghĩa cụ thể.
Trong bài đăng này, chúng tôi trình bày cách xây dựng công cụ tìm kiếm văn bản và hình ảnh theo ngữ cảnh cho các đề xuất sản phẩm bằng cách sử dụng Mô hình nhúng đa phương thức của Amazon Titan, có sẵn trong nền tảng Amazon, với Amazon OpenSearch Serverless.
Mô hình nhúng đa phương thức được thiết kế để tìm hiểu các cách biểu diễn chung của các phương thức khác nhau như văn bản, hình ảnh và âm thanh. Bằng cách đào tạo trên các tập dữ liệu quy mô lớn chứa hình ảnh và chú thích tương ứng, mô hình nhúng đa phương thức học cách nhúng hình ảnh và văn bản vào không gian tiềm ẩn được chia sẻ. Sau đây là tổng quan cấp cao về cách hoạt động của nó về mặt khái niệm:
- Bộ mã hóa riêng biệt – Các mô hình này có bộ mã hóa riêng cho từng phương thức—bộ mã hóa văn bản cho văn bản (ví dụ: BERT hoặc RoBERTa), bộ mã hóa hình ảnh cho hình ảnh (ví dụ: CNN cho hình ảnh) và bộ mã hóa âm thanh cho âm thanh (ví dụ: các mô hình như Wav2Vec) . Mỗi bộ mã hóa tạo ra các phần nhúng ghi lại các đặc điểm ngữ nghĩa của các phương thức tương ứng của chúng
- Hợp nhất phương thức – Các phần nhúng từ bộ mã hóa đơn phương thức được kết hợp bằng cách sử dụng các lớp mạng thần kinh bổ sung. Mục đích là để tìm hiểu sự tương tác và mối tương quan giữa các phương thức. Các phương pháp hợp nhất phổ biến bao gồm ghép nối, hoạt động theo phần tử, gộp và cơ chế chú ý.
- Không gian đại diện được chia sẻ – Các lớp tổng hợp giúp chiếu các phương thức riêng lẻ vào một không gian biểu diễn chung. Bằng cách đào tạo trên các tập dữ liệu đa phương thức, mô hình sẽ tìm hiểu một không gian nhúng chung trong đó các phần nhúng từ mỗi phương thức đại diện cho cùng một nội dung ngữ nghĩa cơ bản gần nhau hơn.
- Nhiệm vụ hạ nguồn – Sau đó, các phần nhúng đa phương thức chung được tạo ra có thể được sử dụng cho các tác vụ xuôi dòng khác nhau như truy xuất, phân loại hoặc dịch đa phương thức. Mô hình sử dụng mối tương quan giữa các phương thức để cải thiện hiệu suất của các tác vụ này so với việc nhúng phương thức riêng lẻ. Ưu điểm chính là khả năng hiểu các tương tác và ngữ nghĩa giữa các phương thức như văn bản, hình ảnh và âm thanh thông qua mô hình hóa chung.
Tổng quan về giải pháp
Giải pháp này cung cấp cách triển khai để xây dựng nguyên mẫu công cụ tìm kiếm được hỗ trợ bằng mô hình ngôn ngữ lớn (LLM) để truy xuất và đề xuất các sản phẩm dựa trên truy vấn văn bản hoặc hình ảnh. Chúng tôi trình bày chi tiết các bước để sử dụng một Phần mềm nhúng đa phương thức của Amazon Titan mô hình để mã hóa hình ảnh và văn bản thành các phần nhúng, nhập các phần nhúng vào chỉ mục Dịch vụ tìm kiếm mở và truy vấn chỉ mục bằng Dịch vụ tìm kiếm mở chức năng k-hàng xóm gần nhất (k-NN).
Giải pháp này bao gồm các thành phần sau:
- Mô hình nhúng đa phương thức của Amazon Titan – Mô hình nền tảng (FM) này tạo ra các phần nhúng của hình ảnh sản phẩm được sử dụng trong bài đăng này. Với Bộ nhúng đa phương thức của Amazon Titan, bạn có thể tạo các phần nhúng cho nội dung của mình và lưu trữ chúng trong cơ sở dữ liệu vectơ. Khi người dùng cuối gửi bất kỳ kết hợp văn bản và hình ảnh nào dưới dạng truy vấn tìm kiếm, mô hình sẽ tạo các nội dung nhúng cho truy vấn tìm kiếm và khớp chúng với các nội dung nhúng được lưu trữ để cung cấp kết quả tìm kiếm và đề xuất có liên quan cho người dùng cuối. Bạn có thể tùy chỉnh thêm mô hình để nâng cao hiểu biết về nội dung độc đáo của bạn và cung cấp kết quả có ý nghĩa hơn bằng cách sử dụng các cặp văn bản-hình ảnh để tinh chỉnh. Theo mặc định, mô hình tạo vectơ (phần nhúng) có 1,024 kích thước và được truy cập thông qua Amazon Bedrock. Bạn cũng có thể tạo các kích thước nhỏ hơn để tối ưu hóa tốc độ và hiệu suất
- Amazon OpenSearch Serverless – Đây là cấu hình không có máy chủ theo yêu cầu cho Dịch vụ OpenSearch. Chúng tôi sử dụng Amazon OpenSearch Serverless làm cơ sở dữ liệu vectơ để lưu trữ các phần nhúng được tạo bởi mô hình Embeddings đa phương thức Amazon Titan. Một chỉ mục được tạo trong bộ sưu tập Amazon OpenSearch Serverless đóng vai trò là kho vectơ cho giải pháp Thế hệ tăng cường truy xuất (RAG) của chúng tôi.
- Xưởng sản xuất Amazon SageMaker – Đây là môi trường phát triển tích hợp (IDE) cho máy học (ML). Những người thực hành ML có thể thực hiện tất cả các bước phát triển ML—từ chuẩn bị dữ liệu của bạn đến xây dựng, đào tạo và triển khai các mô hình ML.
Thiết kế giải pháp bao gồm hai phần: lập chỉ mục dữ liệu và tìm kiếm theo ngữ cảnh. Trong quá trình lập chỉ mục dữ liệu, bạn xử lý hình ảnh sản phẩm để tạo phần nhúng cho những hình ảnh này rồi đưa vào kho dữ liệu vectơ. Các bước này được hoàn thành trước các bước tương tác của người dùng.
Trong giai đoạn tìm kiếm theo ngữ cảnh, truy vấn tìm kiếm (văn bản hoặc hình ảnh) từ người dùng được chuyển đổi thành nội dung nhúng và tìm kiếm tương tự được chạy trên cơ sở dữ liệu vectơ để tìm hình ảnh sản phẩm tương tự dựa trên tìm kiếm tương tự. Sau đó bạn hiển thị các kết quả tương tự hàng đầu. Tất cả mã cho bài đăng này đều có sẵn trong Repo GitHub.
Sơ đồ sau minh họa kiến trúc giải pháp.
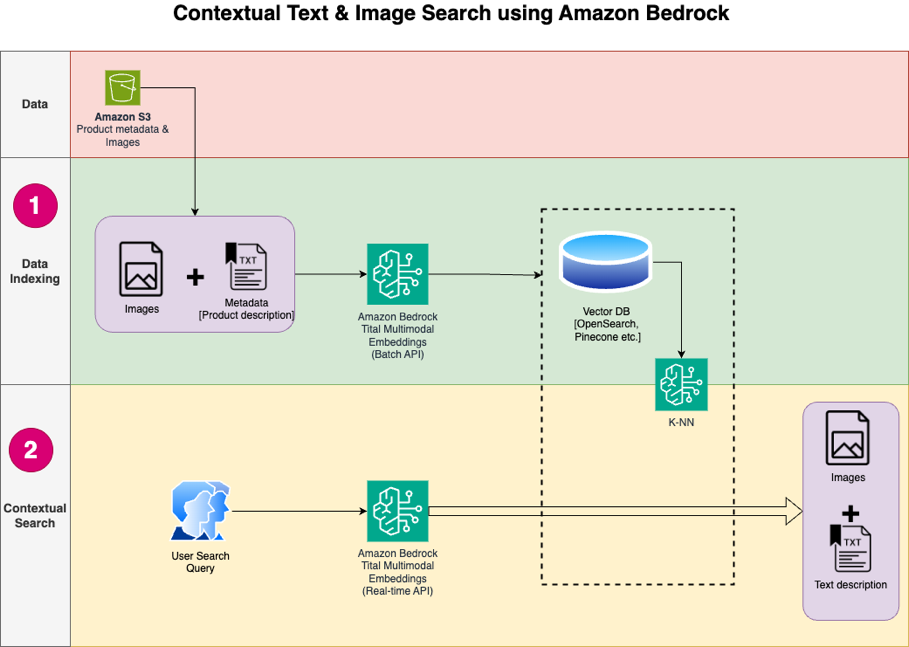
Sau đây là các bước quy trình giải pháp:
- Tải xuống văn bản và hình ảnh mô tả sản phẩm từ công chúng Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) xô.
- Xem xét và chuẩn bị dữ liệu.
- Tạo nội dung nhúng cho hình ảnh sản phẩm bằng mô hình Nhúng đa phương thức Amazon Titan (amazon.titan-embed-image-v1). Nếu bạn có số lượng lớn hình ảnh và mô tả, bạn có thể tùy ý sử dụng Suy luận hàng loạt cho Amazon Bedrock.
- Lưu trữ các phần nhúng vào Amazon OpenSearch Serverless làm công cụ tìm kiếm.
- Cuối cùng, tìm nạp truy vấn của người dùng bằng ngôn ngữ tự nhiên, chuyển đổi nó thành các phần nhúng bằng cách sử dụng mô hình Nhúng đa phương thức Amazon Titan và thực hiện tìm kiếm k-NN để nhận được kết quả tìm kiếm có liên quan.
Chúng tôi sử dụng SageMaker Studio (không hiển thị trong sơ đồ) làm IDE để phát triển giải pháp.
Các bước này sẽ được thảo luận chi tiết trong các phần sau. Chúng tôi cũng bao gồm ảnh chụp màn hình và chi tiết về đầu ra.
Điều kiện tiên quyết
Để triển khai giải pháp được cung cấp trong bài đăng này, bạn cần có những điều sau:
- An Tài khoản AWS và sự quen thuộc với FM, Amazon Bedrock, Amazon SageMakervà Dịch vụ OpenSearch.
- Mô hình Nhúng đa phương thức Amazon Titan được kích hoạt trong Amazon Bedrock. Bạn có thể xác nhận nó được kích hoạt trên Truy cập mô hình trang của bảng điều khiển Amazon Bedrock. Nếu tính năng Nhúng đa phương thức của Amazon Titan được bật, trạng thái truy cập sẽ hiển thị là Chấp thuận quyền truy cập, như thể hiện trong ảnh chụp màn hình sau đây.

Nếu mô hình không có sẵn, hãy cho phép truy cập vào mô hình bằng cách chọn Quản lý quyền truy cập mô hình, lựa chọn Phần mềm nhúng đa phương thức Amazon Titan G1và lựa chọn Yêu cầu quyền truy cập mô hình. Mô hình được kích hoạt để sử dụng ngay lập tức.

Thiết lập giải pháp
Khi các bước tiên quyết hoàn tất, bạn đã sẵn sàng thiết lập giải pháp:
- Trong tài khoản AWS của bạn, hãy mở bảng điều khiển SageMaker và chọn Studio trong khung điều hướng.
- Chọn tên miền và hồ sơ người dùng của bạn, sau đó chọn Mở Studio.
Tên miền và tên hồ sơ người dùng của bạn có thể khác.

- Chọn Thiết bị đầu cuối hệ thống Dưới Các tiện ích và tệp.
- Chạy lệnh sau để sao chép Repo GitHub đến phiên bản SageMaker Studio:
- Điều hướng đến
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2ethư mục. - Mở
titan_mm_embed_search_blog.ipynbsổ tay.
Chạy giải pháp
Mở tập tin titan_mm_embed_search_blog.ipynb và sử dụng hạt nhân Data Science Python 3. Trên chạy menu, chọn Chạy tất cả các ô để chạy mã trong sổ ghi chép này.
Sổ ghi chép này thực hiện các bước sau:
- Cài đặt các gói và thư viện cần thiết cho giải pháp này.
- Tải công khai có sẵn Bộ dữ liệu đối tượng Amazon Berkeley và siêu dữ liệu trong khung dữ liệu gấu trúc.
Bộ dữ liệu là tập hợp gồm 147,702 danh sách sản phẩm với siêu dữ liệu đa ngôn ngữ và 398,212 hình ảnh danh mục độc đáo. Đối với bài đăng này, bạn chỉ sử dụng hình ảnh sản phẩm và tên sản phẩm bằng tiếng Anh Mỹ. Bạn sử dụng khoảng 1,600 sản phẩm.

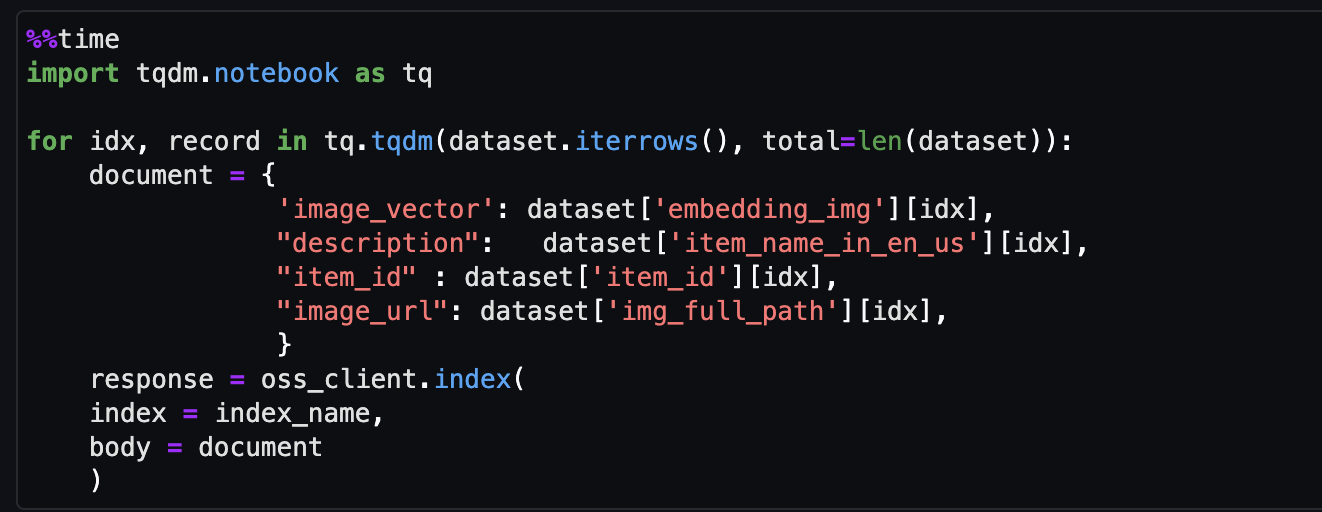
- Tạo nội dung nhúng cho hình ảnh mục bằng cách sử dụng mô hình Nhúng đa phương thức Amazon Titan bằng cách sử dụng
get_titan_multomodal_embedding()chức năng. Để dễ hiểu, chúng tôi đã định nghĩa tất cả các hàm quan trọng được sử dụng trong sổ tay này trongutils.pytập tin.

Tiếp theo, bạn tạo và thiết lập kho lưu trữ vectơ Amazon OpenSearch Serverless (bộ sưu tập và lập chỉ mục).
- Trước khi tạo chỉ mục và bộ sưu tập tìm kiếm vectơ mới, trước tiên bạn phải tạo ba chính sách Dịch vụ OpenSearch liên quan: chính sách bảo mật mã hóa, chính sách bảo mật mạng và chính sách truy cập dữ liệu.

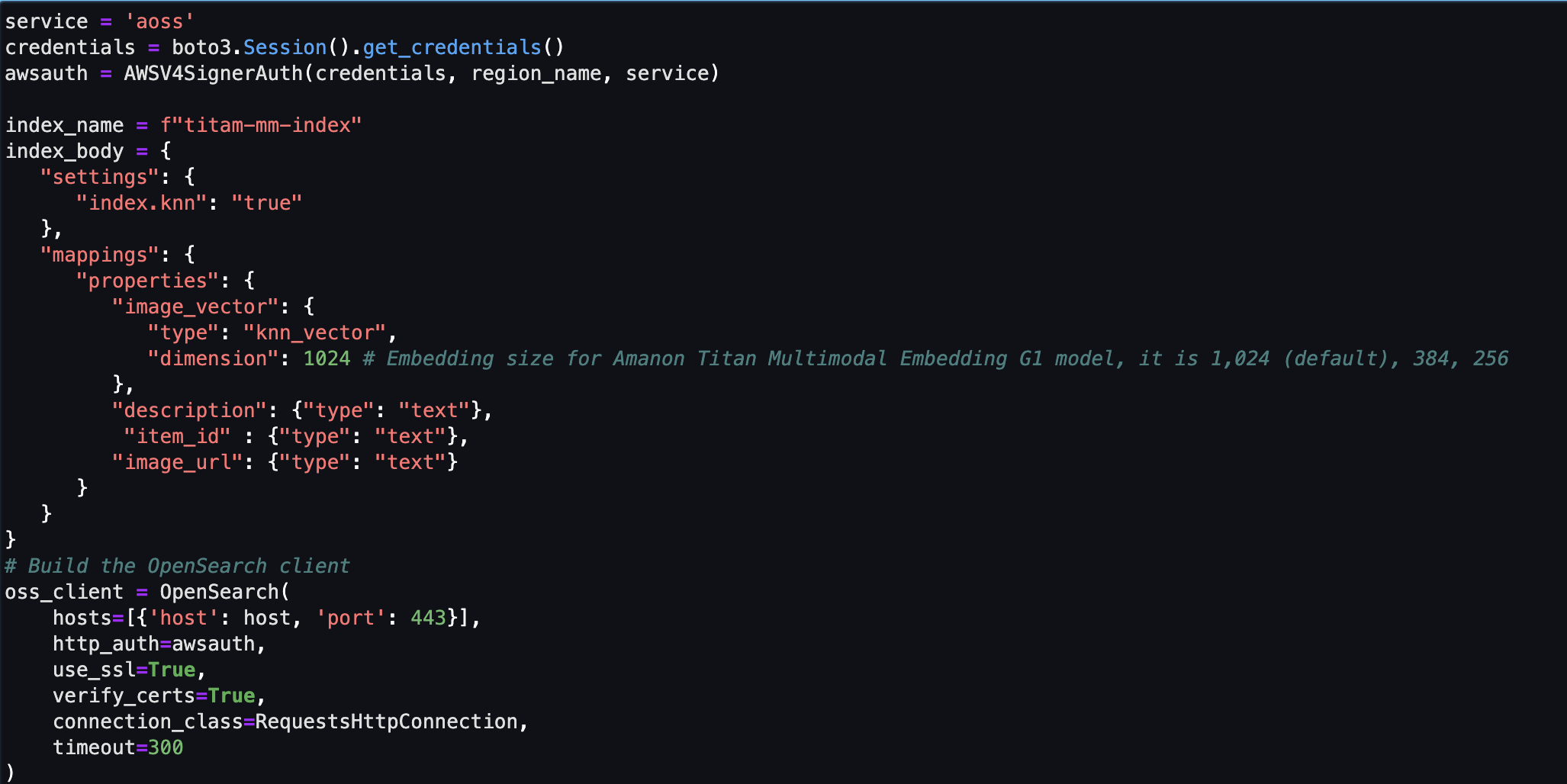
- Cuối cùng, nhập hình ảnh nhúng vào chỉ mục vectơ.
Bây giờ bạn có thể thực hiện tìm kiếm đa phương thức theo thời gian thực.
Chạy tìm kiếm theo ngữ cảnh
Trong phần này, chúng tôi hiển thị kết quả tìm kiếm theo ngữ cảnh dựa trên truy vấn văn bản hoặc hình ảnh.
Đầu tiên, hãy thực hiện tìm kiếm hình ảnh dựa trên kiểu nhập văn bản. Trong ví dụ sau, chúng tôi sử dụng kiểu nhập văn bản “ly đồ uống” và gửi nó tới công cụ tìm kiếm để tìm các mục tương tự.
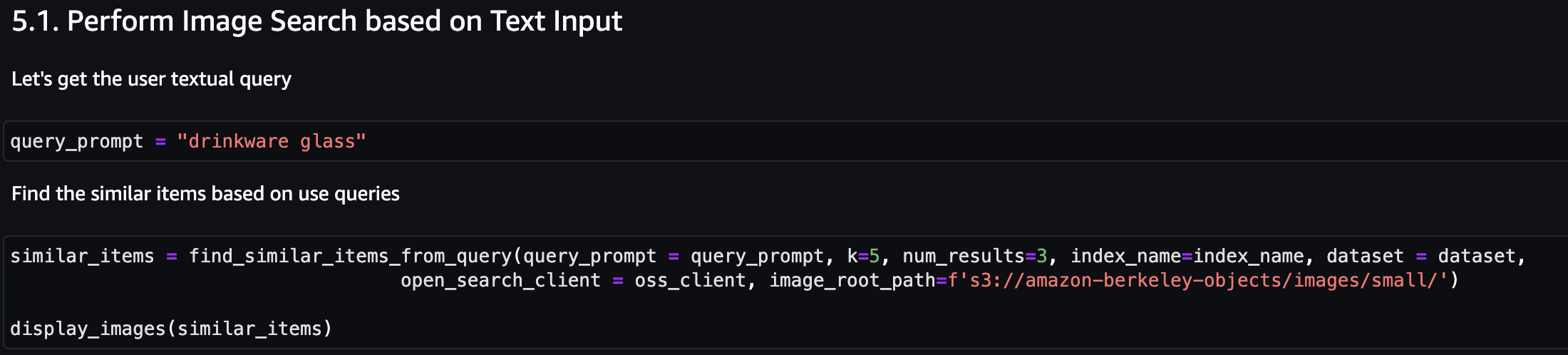
Ảnh chụp màn hình sau đây cho thấy kết quả.

Bây giờ chúng ta hãy xem kết quả dựa trên một hình ảnh đơn giản. Hình ảnh đầu vào được chuyển đổi thành các vectơ nhúng và dựa trên tìm kiếm tương tự, mô hình sẽ trả về kết quả.
Bạn có thể sử dụng bất kỳ hình ảnh nào, nhưng đối với ví dụ sau, chúng tôi sử dụng hình ảnh ngẫu nhiên từ tập dữ liệu dựa trên ID mục (ví dụ: item_id = “B07JCDQWM6”), sau đó gửi hình ảnh này đến công cụ tìm kiếm để tìm các mục tương tự.

Ảnh chụp màn hình sau đây cho thấy kết quả.

Làm sạch
Để tránh phát sinh phí trong tương lai, hãy xóa các tài nguyên được sử dụng trong giải pháp này. Bạn có thể thực hiện việc này bằng cách chạy phần dọn dẹp của sổ ghi chép.

Kết luận
Bài đăng này trình bày hướng dẫn sử dụng mô hình Nhúng đa phương thức Amazon Titan trong Amazon Bedrock để xây dựng các ứng dụng tìm kiếm theo ngữ cảnh mạnh mẽ. Cụ thể, chúng tôi đã trình diễn một ví dụ về ứng dụng tìm kiếm danh sách sản phẩm. Chúng tôi đã thấy cách mô hình nhúng cho phép khám phá thông tin từ hình ảnh và dữ liệu văn bản một cách hiệu quả và chính xác, từ đó nâng cao trải nghiệm người dùng khi tìm kiếm các mục có liên quan.
Giải pháp nhúng đa phương thức của Amazon Titan giúp bạn tăng cường trải nghiệm tìm kiếm, đề xuất và cá nhân hóa đa phương thức chính xác hơn và phù hợp với ngữ cảnh hơn cho người dùng cuối. Ví dụ: một công ty nhiếp ảnh có hàng trăm triệu hình ảnh có thể sử dụng mô hình này để hỗ trợ chức năng tìm kiếm của mình, do đó người dùng có thể tìm kiếm hình ảnh bằng cách sử dụng cụm từ, hình ảnh hoặc kết hợp hình ảnh và văn bản.
Mô hình Nhúng đa phương thức Amazon Titan trong Amazon Bedrock hiện có sẵn ở các Khu vực AWS Miền Đông Hoa Kỳ (Bắc Virginia) và Miền Tây Hoa Kỳ (Oregon). Để tìm hiểu thêm, hãy tham khảo Các mô hình Trình tạo hình ảnh Amazon Titan, Nhúng đa phương thức và Văn bản hiện có sẵn trên Amazon Bedrock, Các Trang sản phẩm Amazon Titan, và Hướng dẫn sử dụng Amazon Bedrock. Để bắt đầu với Phần mềm nhúng đa phương thức của Amazon Titan trong Amazon Bedrock, hãy truy cập Bảng điều khiển Amazon Bedrock.
Bắt đầu xây dựng với mô hình nhúng đa phương thức Amazon Titan trong nền tảng Amazon hôm nay.
Về các tác giả
 Sandeep Singh là Nhà khoa học dữ liệu AI sáng tạo cấp cao tại Amazon Web Services, giúp các doanh nghiệp đổi mới bằng AI sáng tạo. Anh ấy chuyên về AI sáng tạo, Trí tuệ nhân tạo, Học máy và Thiết kế hệ thống. Anh đam mê phát triển các giải pháp tiên tiến được hỗ trợ bởi AI/ML để giải quyết các vấn đề kinh doanh phức tạp cho các ngành đa dạng, tối ưu hóa hiệu quả và khả năng mở rộng.
Sandeep Singh là Nhà khoa học dữ liệu AI sáng tạo cấp cao tại Amazon Web Services, giúp các doanh nghiệp đổi mới bằng AI sáng tạo. Anh ấy chuyên về AI sáng tạo, Trí tuệ nhân tạo, Học máy và Thiết kế hệ thống. Anh đam mê phát triển các giải pháp tiên tiến được hỗ trợ bởi AI/ML để giải quyết các vấn đề kinh doanh phức tạp cho các ngành đa dạng, tối ưu hóa hiệu quả và khả năng mở rộng.
 Mani Khanuja là Trưởng nhóm công nghệ – Chuyên gia AI sáng tạo, tác giả cuốn sách Học máy ứng dụng và Điện toán hiệu suất cao trên AWS, đồng thời là thành viên Ban Giám đốc dành cho Phụ nữ trong Ban Tổ chức Giáo dục Sản xuất. Cô lãnh đạo các dự án học máy trong nhiều lĩnh vực khác nhau như thị giác máy tính, xử lý ngôn ngữ tự nhiên và AI tổng hợp. Cô phát biểu tại các hội nghị nội bộ và bên ngoài như AWS re:Invent, Women in Manufacturing West, hội thảo trực tuyến trên YouTube và GHC 23. Khi rảnh rỗi, cô thích chạy bộ dài dọc bãi biển.
Mani Khanuja là Trưởng nhóm công nghệ – Chuyên gia AI sáng tạo, tác giả cuốn sách Học máy ứng dụng và Điện toán hiệu suất cao trên AWS, đồng thời là thành viên Ban Giám đốc dành cho Phụ nữ trong Ban Tổ chức Giáo dục Sản xuất. Cô lãnh đạo các dự án học máy trong nhiều lĩnh vực khác nhau như thị giác máy tính, xử lý ngôn ngữ tự nhiên và AI tổng hợp. Cô phát biểu tại các hội nghị nội bộ và bên ngoài như AWS re:Invent, Women in Manufacturing West, hội thảo trực tuyến trên YouTube và GHC 23. Khi rảnh rỗi, cô thích chạy bộ dài dọc bãi biển.
 Rupinder Grewal là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao của AWS. Anh hiện tập trung vào việc phân phát các mô hình và MLOps trên Amazon SageMaker. Trước khi đảm nhận vai trò này, anh từng là Kỹ sư máy học xây dựng và lưu trữ các mô hình. Ngoài công việc, anh thích chơi quần vợt và đạp xe trên những con đường mòn trên núi.
Rupinder Grewal là Kiến trúc sư giải pháp chuyên gia AI/ML cấp cao của AWS. Anh hiện tập trung vào việc phân phát các mô hình và MLOps trên Amazon SageMaker. Trước khi đảm nhận vai trò này, anh từng là Kỹ sư máy học xây dựng và lưu trữ các mô hình. Ngoài công việc, anh thích chơi quần vợt và đạp xe trên những con đường mòn trên núi.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

