
Trong những năm gần đây, những tiến bộ trong thị giác máy tính đã cho phép các nhà nghiên cứu, những người phản ứng đầu tiên và các chính phủ giải quyết vấn đề đầy thách thức trong việc xử lý hình ảnh vệ tinh toàn cầu để hiểu hành tinh của chúng ta và tác động của chúng ta đối với nó. AWS được phát hành gần đây Khả năng không gian địa lý của Amazon SageMaker để cung cấp cho bạn hình ảnh vệ tinh và các mô hình máy học (ML) tiên tiến nhất về không gian địa lý, giảm thiểu các rào cản đối với các loại trường hợp sử dụng này. Để biết thêm thông tin, hãy tham khảo Xem trước: Sử dụng Amazon SageMaker để xây dựng, đào tạo và triển khai các mô hình ML bằng dữ liệu không gian địa lý.
Nhiều cơ quan, bao gồm cả những người phản ứng đầu tiên, đang sử dụng các dịch vụ này để có được nhận thức về tình huống trên quy mô lớn và ưu tiên các nỗ lực cứu trợ ở các khu vực địa lý bị thiên tai tấn công. Thường thì các cơ quan này đang xử lý hình ảnh thảm họa từ các nguồn vệ tinh và độ cao thấp, và dữ liệu này thường không được gắn nhãn và khó sử dụng. Các mô hình thị giác máy tính tiên tiến nhất thường hoạt động kém hiệu quả khi xem các hình ảnh vệ tinh của một thành phố bị bão hoặc cháy rừng tấn công. Do thiếu các bộ dữ liệu này, ngay cả các mô hình ML tiên tiến nhất cũng thường không thể cung cấp độ chính xác cần thiết để dự đoán các phân loại thảm họa tiêu chuẩn của FEMA.
Bộ dữ liệu không gian địa lý chứa siêu dữ liệu hữu ích như tọa độ kinh độ và vĩ độ cũng như dấu thời gian, có thể cung cấp ngữ cảnh cho những hình ảnh này. Điều này đặc biệt hữu ích trong việc cải thiện độ chính xác của ML không gian địa lý cho các cảnh thảm họa, bởi vì những hình ảnh này vốn đã lộn xộn và hỗn loạn. Các tòa nhà ít hình chữ nhật hơn, thảm thực vật bị hư hại kéo dài và các tuyến đường bị gián đoạn do lũ lụt hoặc lở đất. Do việc gắn nhãn cho các bộ dữ liệu khổng lồ này rất tốn kém, thủ công và tốn thời gian, nên việc phát triển các mô hình ML có thể tự động hóa việc gắn nhãn và chú thích hình ảnh là rất quan trọng.
Để đào tạo mô hình này, chúng ta cần một tập hợp con sự thật cơ bản được dán nhãn của Bộ dữ liệu Hình ảnh thiên tai ở độ cao thấp (LADI). Bộ dữ liệu này bao gồm các hình ảnh trên không có chú thích của con người và máy móc do Đội tuần tra hàng không dân dụng thu thập để hỗ trợ các ứng phó thảm họa khác nhau từ năm 2015-2019. Các bộ dữ liệu LADI này tập trung vào các mùa bão ở Đại Tây Dương và các quốc gia ven biển dọc theo Đại Tây Dương và Vịnh Mexico. Hai điểm khác biệt chính là độ cao thấp, phối cảnh xiên của hình ảnh và các đặc điểm liên quan đến thảm họa, hiếm khi được nêu trong các tiêu chuẩn và bộ dữ liệu thị giác máy tính. Các nhóm đã sử dụng các danh mục FEMA hiện có cho các thiệt hại như lũ lụt, mảnh vỡ, lửa và khói hoặc lở đất, điều này đã tiêu chuẩn hóa các danh mục nhãn. Sau đó, giải pháp có thể đưa ra dự đoán về phần còn lại của dữ liệu đào tạo và định tuyến các kết quả có độ tin cậy thấp hơn để con người xem xét.
Trong bài đăng này, chúng tôi mô tả thiết kế và triển khai giải pháp, các phương pháp hay nhất và các thành phần chính của kiến trúc hệ thống.
Tổng quan về giải pháp
Tóm lại, giải pháp liên quan đến việc xây dựng ba đường ống:
- Đường ống dữ liệu – Trích xuất siêu dữ liệu của hình ảnh
- Đường ống học máy – Phân loại và gắn nhãn hình ảnh
- Quy trình đánh giá con người trong vòng lặp – Sử dụng một nhóm con người để xem xét kết quả
Sơ đồ sau minh họa kiến trúc giải pháp.
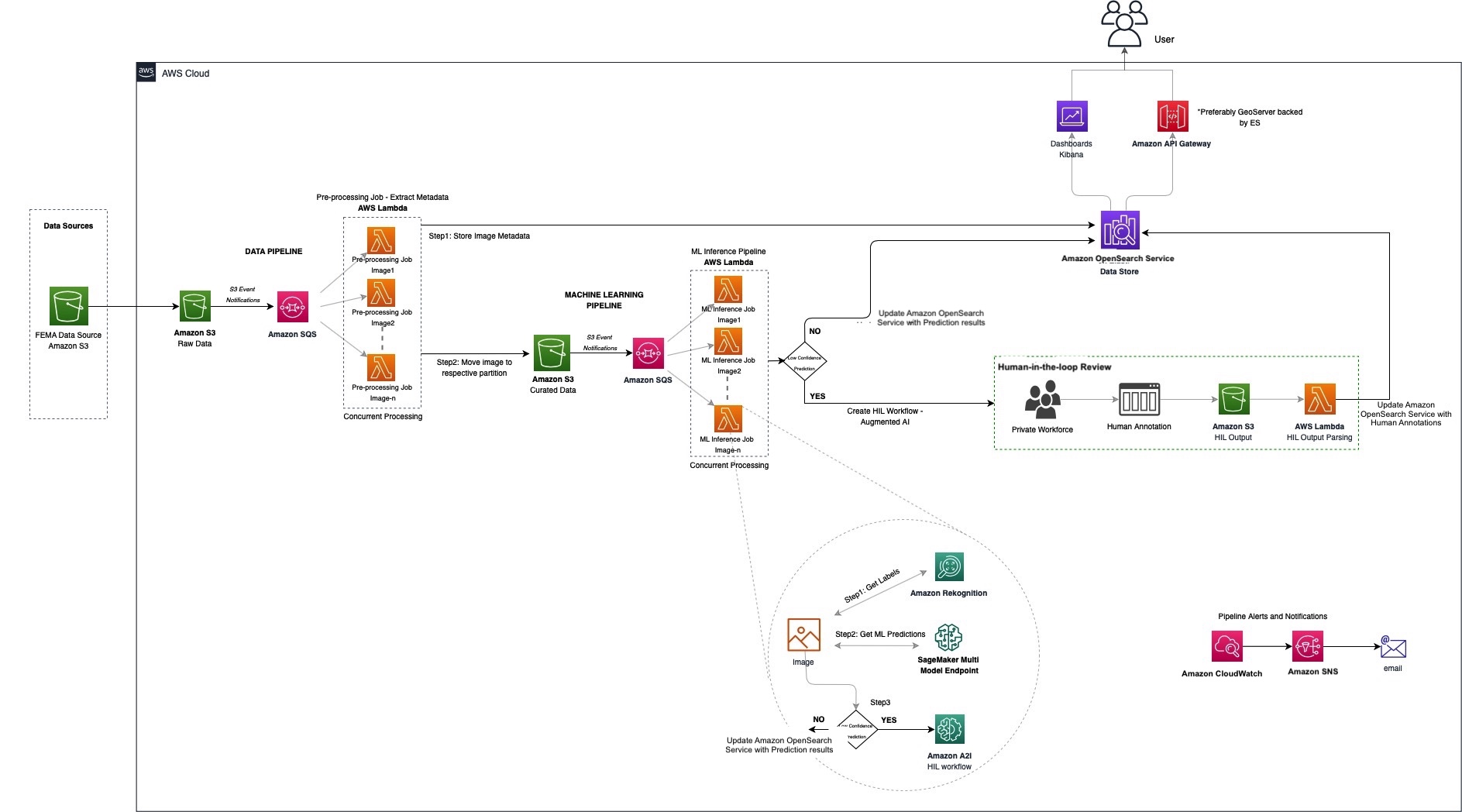
Do tính chất của một hệ thống ghi nhãn như thế này, chúng tôi đã thiết kế một kiến trúc có thể mở rộng theo chiều ngang để xử lý các đợt nhập mà không cần cung cấp quá mức bằng cách sử dụng kiến trúc không có máy chủ. Chúng tôi sử dụng mẫu một-nhiều từ Dịch vụ xếp hàng đơn giản trên Amazon (Amazon SQS) đến AWS Lambda ở nhiều điểm để hỗ trợ các đột biến tiêu hóa này, cung cấp khả năng phục hồi.
Sử dụng hàng đợi SQS để xử lý Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) giúp chúng tôi kiểm soát đồng thời quá trình xử lý xuôi dòng (trong trường hợp này là các hàm Lambda) và xử lý các đợt dữ liệu tăng đột biến. Việc xếp hàng các tin nhắn đến cũng hoạt động như một bộ lưu trữ đệm trong trường hợp có bất kỳ lỗi nào xảy ra ở hạ lưu.
Do nhu cầu song song cao, chúng tôi đã chọn Lambda để xử lý hình ảnh của mình. Lambda là dịch vụ điện toán serverless cho phép chúng tôi chạy mã mà không cần cung cấp hoặc quản lý máy chủ, tạo logic thay đổi quy mô cụm nhận biết khối lượng công việc, duy trì tích hợp sự kiện và quản lý thời gian chạy.
Chúng tôi sử dụng Dịch vụ Tìm kiếm Mở của Amazon làm kho lưu trữ dữ liệu trung tâm của chúng tôi để tận dụng lợi thế của công cụ trực quan tích hợp và khả năng mở rộng cao, OpenSearch Dashboards. Nó cho phép chúng tôi thêm ngữ cảnh vào hình ảnh một cách lặp đi lặp lại mà không cần phải biên dịch lại hoặc thay đổi tỷ lệ và xử lý quá trình phát triển lược đồ.
Nhận thức lại Amazon giúp dễ dàng thêm phân tích hình ảnh và video vào các ứng dụng của chúng tôi, sử dụng công nghệ học sâu, đã được chứng minh, có khả năng mở rộng cao. Với Amazon Rekognition, chúng tôi có cơ sở tốt về các đối tượng được phát hiện.
Trong các phần sau, chúng tôi đi sâu vào từng đường ống một cách chi tiết hơn.
Đường ống dữ liệu
Sơ đồ sau đây cho thấy quy trình làm việc của đường dẫn dữ liệu.
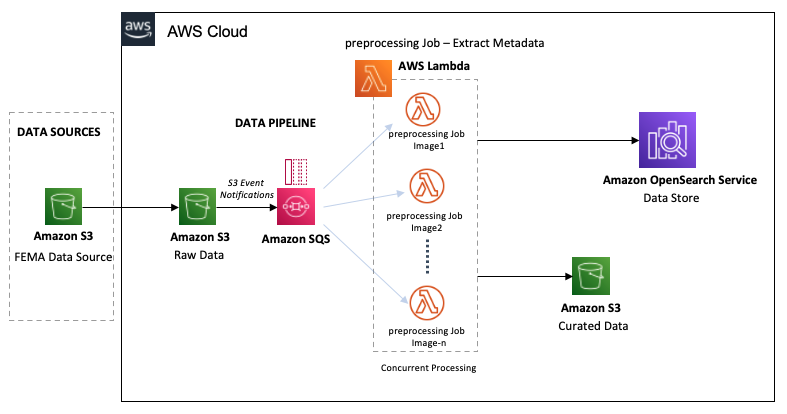
Đường dẫn dữ liệu LADI bắt đầu bằng việc nhập các hình ảnh dữ liệu thô từ Giao thức cảnh báo chung của FEMA (CAP) vào thùng S3. Khi chúng tôi nhập hình ảnh vào vùng lưu trữ dữ liệu thô, chúng được xử lý trong thời gian gần như thực theo hai bước:
- Bộ chứa S3 kích hoạt thông báo sự kiện cho tất cả các lần tạo đối tượng, tạo thông báo trong hàng đợi SQS cho mỗi hình ảnh được nhập.
- Hàng đợi SQS đồng thời gọi các hàm Lambda tiền xử lý trên hình ảnh.
Các hàm Lambda thực hiện các bước tiền xử lý sau:
- Tính toán UUID cho mỗi hình ảnh, cung cấp một mã định danh duy nhất cho mỗi hình ảnh. ID này sẽ xác định hình ảnh trong toàn bộ vòng đời của nó.
- Trích xuất siêu dữ liệu như tọa độ GPS, kích thước hình ảnh, thông tin GIS và vị trí S3 từ hình ảnh và lưu nó vào OpenSearch.
- Dựa trên tra cứu đối với mã FIPS, hàm này sẽ di chuyển hình ảnh vào bộ chứa S3 dữ liệu được quản lý. Chúng tôi phân vùng dữ liệu theo FIPS-State-code/FIPS-County-code/Year/Month của hình ảnh.
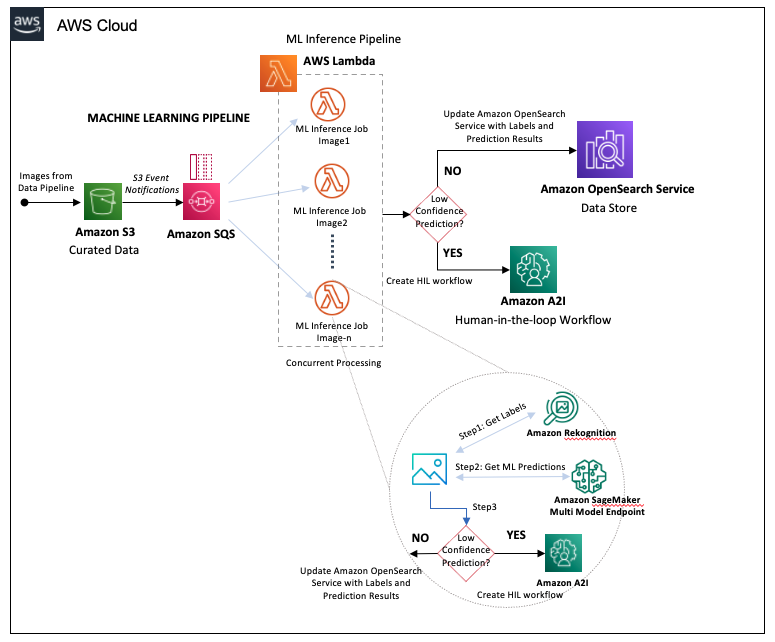
Đường ống học máy
Quy trình ML bắt đầu từ các hình ảnh hạ cánh trong bộ chứa S3 dữ liệu được tuyển chọn trong bước quy trình cung cấp dữ liệu, bước này sẽ kích hoạt các bước sau:
- Amazon S3 tạo một thông báo vào một hàng đợi SQS khác cho từng đối tượng được tạo trong bộ chứa S3 dữ liệu được quản lý.
- Hàng đợi SQS đồng thời kích hoạt các hàm Lambda để chạy công việc suy luận ML trên hình ảnh.
Các hàm Lambda thực hiện các tác vụ sau:
- Gửi từng hình ảnh tới Amazon Rekognition để phát hiện đối tượng, lưu trữ các nhãn được trả về và điểm tin cậy tương ứng.
- Kết hợp đầu ra của Amazon Rekognition thành các tham số đầu vào cho Amazon SageMaker điểm cuối đa mô hình. Điểm cuối này lưu trữ tập hợp các bộ phân loại của chúng tôi, được đào tạo cho các bộ nhãn thiệt hại cụ thể.
- Chuyển kết quả của điểm cuối SageMaker tới AI tăng cường của Amazon (Amazon A2I).
Sơ đồ sau đây minh họa quy trình làm việc của đường ống.
Quy trình đánh giá con người trong vòng lặp
Sơ đồ sau đây minh họa đường ống dẫn con người trong vòng lặp (HIL).
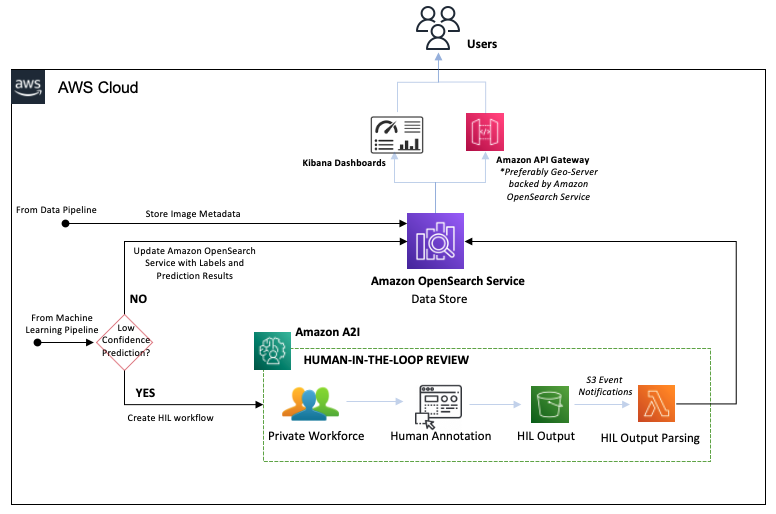
Với Amazon A2I, chúng tôi có thể định cấu hình các ngưỡng sẽ kích hoạt đánh giá của con người bởi một nhóm riêng khi một mô hình đưa ra dự đoán có độ tin cậy thấp. Chúng tôi cũng có thể sử dụng Amazon A2I để tiến hành kiểm tra liên tục các dự đoán của mô hình. Các bước quy trình làm việc như sau:
- Amazon A2I định tuyến các dự đoán có độ tin cậy cao vào OpenSearch Service, cập nhật dữ liệu nhãn của hình ảnh.
- Amazon A2I định tuyến các dự đoán có độ tin cậy thấp tới nhóm riêng để chú thích hình ảnh theo cách thủ công.
- Người đánh giá con người hoàn thành chú thích, tạo tệp đầu ra chú thích con người được lưu trữ trong bộ chứa HIL Output S3.
- Bộ chứa HIL Output S3 kích hoạt một hàm Lambda phân tích cú pháp đầu ra chú thích của con người và cập nhật dữ liệu của hình ảnh trong OpenSearch Service.
Bằng cách định tuyến kết quả chú thích của con người trở lại kho lưu trữ dữ liệu, chúng tôi có thể đào tạo lại các mô hình tập hợp và lặp đi lặp lại cải thiện độ chính xác của mô hình.
Với kết quả chất lượng cao của chúng tôi hiện được lưu trữ trong Dịch vụ Tìm kiếm Mở, chúng tôi có thể thực hiện tìm kiếm không gian địa lý và thời gian thông qua API REST, sử dụng Cổng API Amazon và Máy chủ địa lý. OpenSearch Dashboard cũng cho phép người dùng tìm kiếm và chạy phân tích với bộ dữ liệu này.
Kết quả
Đoạn mã sau đây cho thấy một ví dụ về kết quả của chúng tôi.

Với quy trình mới này, chúng tôi tạo ra một điểm dừng con người cho các mô hình chưa hoạt động đầy đủ. Đường dẫn ML mới này đã được đưa vào sản xuất để sử dụng với một Vi dịch vụ bộ lọc hình ảnh tuần tra hàng không dân sự cho phép lọc các hình ảnh của Đội tuần tra hàng không dân sự ở Puerto Rico. Điều này cho phép những người phản ứng đầu tiên xem mức độ thiệt hại và xem hình ảnh liên quan đến thiệt hại đó sau các cơn bão. Phòng thí nghiệm dữ liệu AWS, Chương trình dữ liệu mở AWS, nhóm Ứng phó thảm họa Amazon và nhóm con người trong vòng lặp của AWS đã làm việc với khách hàng để phát triển một quy trình nguồn mở có thể được sử dụng để phân tích dữ liệu Civil Air Patrol được lưu trữ trong Dữ liệu mở Đăng ký chương trình theo yêu cầu sau bất kỳ thảm họa thiên nhiên nào. Để biết thêm thông tin về kiến trúc đường ống và tổng quan về sự hợp tác và tác động, hãy xem video Tập trung vào ứng phó thảm họa với Trí tuệ nhân tạo tăng cường của Amazon, Chương trình dữ liệu mở AWS và AWS Snowball.
Kết luận
Khi biến đổi khí hậu tiếp tục gia tăng tần suất và cường độ của bão và cháy rừng, chúng tôi tiếp tục nhận thấy tầm quan trọng của việc sử dụng ML để hiểu tác động của những sự kiện này đối với cộng đồng địa phương. Những công cụ mới này có thể đẩy nhanh các nỗ lực ứng phó thảm họa và cho phép chúng tôi sử dụng dữ liệu từ các phân tích sau sự kiện này để cải thiện độ chính xác dự đoán của các mô hình này bằng phương pháp học tích cực. Các mô hình ML mới này có thể tự động hóa chú thích dữ liệu, cho phép chúng tôi suy ra mức độ thiệt hại từ mỗi sự kiện này khi chúng tôi phủ nhãn thiệt hại bằng dữ liệu bản đồ. Dữ liệu tích lũy đó cũng có thể giúp cải thiện khả năng dự đoán thiệt hại của chúng tôi đối với các sự kiện thảm họa trong tương lai, từ đó có thể đưa ra các chiến lược giảm thiểu. Đổi lại, điều này có thể cải thiện khả năng phục hồi của các cộng đồng, nền kinh tế và hệ sinh thái bằng cách cung cấp cho những người ra quyết định thông tin họ cần để phát triển các chính sách dựa trên dữ liệu nhằm giải quyết các mối đe dọa môi trường mới nổi này.
Trong bài đăng trên blog này, chúng tôi đã thảo luận về việc sử dụng thị giác máy tính trên hình ảnh vệ tinh. Giải pháp này có nghĩa là một kiến trúc tham khảo hoặc hướng dẫn bắt đầu nhanh mà bạn có thể tùy chỉnh theo nhu cầu của riêng mình.
Hãy thử và cho chúng tôi biết điều này đã giải quyết trường hợp sử dụng của bạn như thế nào bằng cách để lại phản hồi trong phần nhận xét. Để biết thêm thông tin, xem Khả năng không gian địa lý của Amazon SageMaker.
Về các tác giả
 Vamshi Krishna Enabothala là Kiến trúc sư chuyên gia AI ứng dụng cấp cao tại AWS. Anh ấy làm việc với các khách hàng từ các lĩnh vực khác nhau để tăng tốc các sáng kiến về dữ liệu, phân tích và học máy có tác động cao. Anh ấy đam mê các hệ thống đề xuất, NLP và các lĩnh vực thị giác máy tính trong AI và ML. Ngoài công việc, Vamshi là một người đam mê RC, chế tạo thiết bị RC (máy bay, ô tô và máy bay không người lái), đồng thời cũng thích làm vườn.
Vamshi Krishna Enabothala là Kiến trúc sư chuyên gia AI ứng dụng cấp cao tại AWS. Anh ấy làm việc với các khách hàng từ các lĩnh vực khác nhau để tăng tốc các sáng kiến về dữ liệu, phân tích và học máy có tác động cao. Anh ấy đam mê các hệ thống đề xuất, NLP và các lĩnh vực thị giác máy tính trong AI và ML. Ngoài công việc, Vamshi là một người đam mê RC, chế tạo thiết bị RC (máy bay, ô tô và máy bay không người lái), đồng thời cũng thích làm vườn.
 Morgan Dutton là Giám đốc chương trình kỹ thuật cấp cao của nhóm Amazon Augmented AI và Amazon SageMaker Ground Truth. Cô ấy làm việc với các khách hàng doanh nghiệp, học thuật và khu vực công để đẩy nhanh việc áp dụng máy học và các dịch vụ ML con người trong vòng lặp.
Morgan Dutton là Giám đốc chương trình kỹ thuật cấp cao của nhóm Amazon Augmented AI và Amazon SageMaker Ground Truth. Cô ấy làm việc với các khách hàng doanh nghiệp, học thuật và khu vực công để đẩy nhanh việc áp dụng máy học và các dịch vụ ML con người trong vòng lặp.
 Sandeep Verma là Kiến trúc sư tạo mẫu cấp cao của AWS. Anh ấy thích tìm hiểu sâu về những thách thức của khách hàng và xây dựng nguyên mẫu cho khách hàng để tăng tốc đổi mới. Anh ấy có kiến thức nền tảng về AI/ML, người sáng lập Kiến thức mới và nói chung là đam mê công nghệ. Khi rảnh rỗi, anh ấy thích đi du lịch và trượt tuyết cùng gia đình.
Sandeep Verma là Kiến trúc sư tạo mẫu cấp cao của AWS. Anh ấy thích tìm hiểu sâu về những thách thức của khách hàng và xây dựng nguyên mẫu cho khách hàng để tăng tốc đổi mới. Anh ấy có kiến thức nền tảng về AI/ML, người sáng lập Kiến thức mới và nói chung là đam mê công nghệ. Khi rảnh rỗi, anh ấy thích đi du lịch và trượt tuyết cùng gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/accelerate-disaster-response-with-computer-vision-for-satellite-imagery-using-amazon-sagemaker-and-amazon-augmented-ai/

