Nhóm Thiết kế và Xây dựng của Amazon EU (Amazon D&C) là nhóm kỹ thuật thiết kế và xây dựng các Kho hàng của Amazon trên khắp Châu Âu và khu vực MENA. Quá trình thiết kế và triển khai dự án liên quan đến nhiều loại Yêu cầu thông tin (RFI) về các yêu cầu kỹ thuật liên quan đến Amazon và các nguyên tắc dành riêng cho dự án. Những yêu cầu này bao gồm từ việc truy xuất đơn giản các giá trị thiết kế cơ sở, đến xem xét các đề xuất kỹ thuật có giá trị, đến phân tích báo cáo và kiểm tra tuân thủ. Ngày nay, những vấn đề này được giải quyết bởi Nhóm kỹ thuật trung tâm, bao gồm các chuyên gia về chủ đề (SME), những người có thể trả lời các câu hỏi chuyên môn kỹ thuật cao như vậy và cung cấp dịch vụ này cho tất cả các bên liên quan và các nhóm trong suốt vòng đời dự án. Nhóm nghiên cứu đang tìm kiếm một trí tuệ nhân tạo giải pháp trả lời câu hỏi để nhanh chóng có được thông tin và tiến hành thiết kế kỹ thuật của họ. Đáng chú ý, những trường hợp sử dụng này không chỉ giới hạn ở nhóm Amazon D&C mà còn có thể áp dụng cho phạm vi rộng hơn của Dịch vụ kỹ thuật toàn cầu liên quan đến triển khai dự án. Toàn bộ các bên liên quan và các nhóm tham gia vào vòng đời dự án có thể được hưởng lợi từ giải pháp trả lời câu hỏi AI tổng quát, vì nó sẽ cho phép truy cập nhanh vào thông tin quan trọng, hợp lý hóa quy trình thiết kế kỹ thuật và quản lý dự án.
Các giải pháp AI tổng quát hiện có để trả lời câu hỏi chủ yếu dựa trên Truy xuất thế hệ tăng cường (GIẺ). RAG tìm kiếm tài liệu thông qua mô hình ngôn ngữ lớn (LLM) nhúng và vectơ, tạo ngữ cảnh từ kết quả tìm kiếm thông qua phân cụm và sử dụng ngữ cảnh như một lời nhắc tăng cường để suy luận mô hình nền tảng nhằm nhận được câu trả lời. Phương pháp này kém hiệu quả hơn đối với các tài liệu kỹ thuật cao từ Amazon D&C chứa dữ liệu phi cấu trúc quan trọng như trang tính, bảng, danh sách, số liệu và hình ảnh Excel. Trong trường hợp này, tác vụ trả lời câu hỏi sẽ hoạt động tốt hơn bằng cách tinh chỉnh LLM với các tài liệu. Tinh chỉnh điều chỉnh và điều chỉnh trọng số của LLM được đào tạo trước để cải thiện chất lượng và độ chính xác của mô hình.
Để giải quyết những thách thức này, chúng tôi trình bày một khuôn khổ mới với RAG và LLM được tinh chỉnh. Giải pháp sử dụng Khởi động Amazon SageMaker làm dịch vụ cốt lõi cho việc tinh chỉnh và suy luận mô hình. Trong bài đăng này, chúng tôi không chỉ cung cấp giải pháp mà còn thảo luận về các bài học kinh nghiệm và các phương pháp hay nhất khi triển khai giải pháp trong các trường hợp sử dụng trong thế giới thực. Chúng tôi so sánh và đối chiếu cách các phương pháp và LLM nguồn mở khác nhau được thực hiện trong trường hợp sử dụng của chúng tôi và thảo luận cách tìm ra sự cân bằng giữa hiệu suất mô hình và chi phí tài nguyên tính toán.
Tổng quan về giải pháp
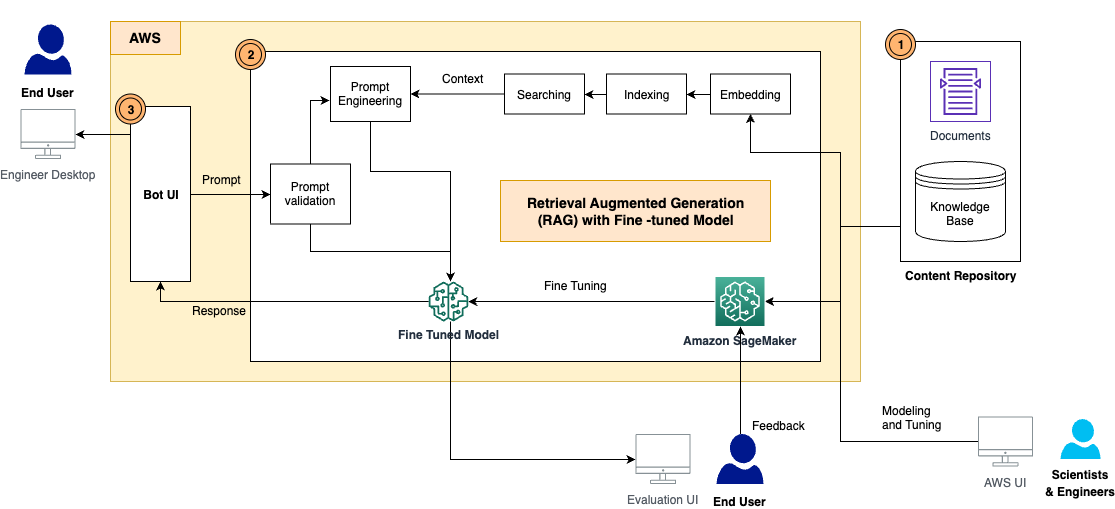
Giải pháp có các thành phần sau, như được hiển thị trong sơ đồ kiến trúc:
- Kho nội dung – Nội dung của D&C bao gồm nhiều loại tài liệu mà con người có thể đọc được với nhiều định dạng khác nhau, chẳng hạn như tệp PDF, trang Excel, trang wiki, v.v. Trong giải pháp này, chúng tôi đã lưu trữ những nội dung này trong một Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) và sử dụng chúng làm cơ sở kiến thức để truy xuất thông tin cũng như suy luận. Trong tương lai, chúng tôi sẽ xây dựng các bộ điều hợp tích hợp để truy cập nội dung trực tiếp từ nơi họ sống.
- Khung RAG với LLM được tinh chỉnh - Gồm các tiểu phần sau:
- Khung RAG – Thao tác này sẽ truy xuất dữ liệu liên quan từ tài liệu, tăng cường lời nhắc bằng cách thêm dữ liệu được truy xuất trong ngữ cảnh và chuyển dữ liệu đó đến LLM được tinh chỉnh để tạo đầu ra.
- LLM tinh chỉnh – Chúng tôi xây dựng tập dữ liệu huấn luyện từ các tài liệu, nội dung và tiến hành tinh chỉnh trên mô hình nền tảng. Sau khi điều chỉnh, mô hình đã học được kiến thức từ nội dung D&C và do đó có thể trả lời các câu hỏi một cách độc lập.
- Mô-đun xác thực nhanh chóng – Điều này đo lường sự trùng khớp ngữ nghĩa giữa lời nhắc của người dùng và tập dữ liệu để tinh chỉnh. Nếu LLM được tinh chỉnh để trả lời câu hỏi này thì bạn có thể suy ra mô hình được tinh chỉnh để có câu trả lời. Nếu không, bạn có thể sử dụng RAG để tạo phản hồi.
- LangChain - Chúng tôi sử dụng LangChain để xây dựng quy trình làm việc nhằm trả lời các câu hỏi được gửi đến.
- Giao diện người dùng cuối – Đây là giao diện chatbot nhằm nắm bắt các câu hỏi, thắc mắc của người dùng và đưa ra câu trả lời từ phản hồi RAG và LLM.
Trong các phần tiếp theo, chúng tôi trình bày cách tạo quy trình làm việc RAG và xây dựng các mô hình tinh chỉnh.
RAG với các mô hình nền tảng của SageMaker JumpStart
RAG kết hợp sức mạnh của các mô hình nền tảng truy xuất dày đặc được huấn luyện trước và các mô hình nền tảng tuần tự (seq2seq). Để trả lời câu hỏi từ tài liệu của Amazon D&C, chúng ta cần chuẩn bị trước những điều sau:
- Nhúng và lập chỉ mục tài liệu bằng mô hình nhúng LLM – Chúng tôi chia nhiều tài liệu thành các phần nhỏ dựa trên cấu trúc chương và phần tài liệu, đã thử nghiệm với mô hình Amazon GPT-J-6B trên SageMaker JumpStart để tạo chỉ mục và lưu trữ chỉ mục trong kho vectơ FAISS
- Mô hình nền tảng được đào tạo trước để tạo phản hồi từ lời nhắc – Chúng tôi đã thử nghiệm với các mẫu Flan-T5 XL, Flan-T5 XXL và Falcon-7B trên SageMaker JumpStart
Quá trình trả lời câu hỏi được triển khai bởi LangChain, đây là một khuôn khổ để phát triển các ứng dụng được cung cấp bởi các mô hình ngôn ngữ. Quy trình làm việc trong chuỗi bao gồm các bước sau:
- Nhận câu hỏi từ người dùng.
- Thực hiện tìm kiếm ngữ nghĩa trên các tài liệu được lập chỉ mục thông qua THẤT BẠI để có được K khối tài liệu phù hợp nhất.
- Xác định mẫu lời nhắc, chẳng hạn như
- Tăng cường các khối tài liệu được truy xuất dưới dạng
{context}và câu hỏi của người dùng là{question}trong lời nhắc. - Nhắc mô hình nền móng bằng dấu nhắc không bắn được xây dựng.
- Trả lại kết quả đầu ra của mô hình cho người dùng.
Chúng tôi đã thử nghiệm 125 câu hỏi về yêu cầu và thông số kỹ thuật của Amazon D&C và RAG đã trả lời tốt cho một số câu hỏi. Trong ví dụ sau, RAG với mẫu Flan-T5-XXL đã cung cấp phản hồi chính xác từ các phần bên phải của tài liệu.
| câu hỏi | Các yêu cầu về hệ thống ống nước đối với đài phun nước uống và máy làm mát nước là gì? (Mục 22 47 00) |
| Câu trả lời dự kiến | Chủ đầu tư phải cung cấp các thanh phân phối nước, sàn đứng tại không gian tường Kho liền kề với lối vào của mỗi khối nhà vệ sinh phục vụ Kho và ở vị trí tương đương liền kề với khối nhà vệ sinh Phòng thay đồ. Các đơn vị phải phù hợp với tiêu chuẩn của Amazon. Số lượng và vị trí cuối cùng phải được thỏa thuận với Amazon trước khi lắp đặt. Tối thiểu hai thiết bị phân phối nước làm mát ở nhiệt độ phòng sẽ được cung cấp tại mỗi địa điểm. Máy làm mát nước hoặc thanh nước – Nhà phát triển phải cung cấp nguồn nước uống được theo yêu cầu cho các máy làm mát nước hoặc thanh nước từ xa trong toàn bộ cơ sở. Nhà phát triển phải cung cấp các điểm cấp nước, thoát nước và bất kỳ dịch vụ điện nào được yêu cầu trong Phòng nghỉ của các quán nước do Nhà thầu cung cấp dịch vụ ăn uống cung cấp. |
| Câu trả lời RAG (nhúng GPT-J-6B với Flan-T5-XXL) | Chủ đầu tư phải cung cấp các thanh phân phối nước, sàn đứng tại không gian tường Kho liền kề với lối vào của mỗi khối nhà vệ sinh phục vụ Kho và ở vị trí tương đương liền kề với khối nhà vệ sinh Phòng thay đồ. Các đơn vị phải phù hợp với tiêu chuẩn của Amazon. Số lượng và vị trí cuối cùng phải được thỏa thuận với Amazon trước khi lắp đặt. Tối thiểu hai thiết bị phân phối nước làm mát ở nhiệt độ phòng sẽ được cung cấp tại mỗi địa điểm. Máy làm mát nước hoặc thanh nước – Nhà phát triển phải cung cấp nguồn nước uống được theo yêu cầu cho các máy làm mát nước hoặc thanh nước từ xa trong toàn bộ cơ sở. Nhà phát triển phải cung cấp các điểm cấp nước, thoát nước và bất kỳ dịch vụ điện nào được yêu cầu trong Phòng nghỉ của các quán nước do Nhà thầu cung cấp dịch vụ ăn uống cung cấp. |
Tuy nhiên, chúng tôi nhận thấy rằng RAG không cung cấp câu trả lời rõ ràng và chính xác cho những câu hỏi mang tính cụ thể và mang tính kỹ thuật cao hơn, chẳng hạn như hướng dẫn, con số và số liệu. Như được hiển thị trong ví dụ sau, khi dự kiến sẽ có đầu ra thứ nguyên kỹ thuật, RAG không thể cung cấp câu trả lời cụ thể, chủ yếu là do quá trình nhúng và tìm kiếm không thể trả về ngữ cảnh ngắn gọn.
| câu hỏi | Yêu cầu về Chiều cao sàn đối với bê tông tầng một P2 là bao nhiêu? |
| Câu trả lời dự kiến | 7,50 m AFFL |
| Câu trả lời RAG (nhúng GPT-J-6B với Flan-T5-XXL) | P2 Bê tông tầng XNUMX |
Điều này cần phải được cải thiện vì ảo giác không được chấp nhận do mức độ nghiêm trọng của hậu quả trong trường hợp sử dụng này.
Tinh chỉnh LLM trên SageMaker
Để giải quyết thách thức này và cải thiện chất lượng phản hồi, chúng tôi thực hiện một cách tiếp cận mới để tinh chỉnh mô hình LLM bằng cách sử dụng các tài liệu cho nhiệm vụ trả lời câu hỏi. Mô hình sẽ được huấn luyện để học trực tiếp các kiến thức tương ứng từ tài liệu. Không giống như RAG, nó không phụ thuộc vào việc tài liệu có được nhúng và lập chỉ mục chính xác hay không cũng như liệu thuật toán tìm kiếm ngữ nghĩa có đủ hiệu quả để trả về nội dung phù hợp nhất từ cơ sở dữ liệu vectơ hay không.
Để chuẩn bị tập dữ liệu huấn luyện để tinh chỉnh, chúng tôi trích xuất thông tin từ tài liệu D&C và xây dựng dữ liệu theo định dạng sau:
- Hướng dẫn – Mô tả nhiệm vụ và cung cấp một phần lời nhắc
- Đầu vào – Cung cấp thêm ngữ cảnh để được tổng hợp vào lời nhắc
- Phản ứng – Đầu ra của mô hình
Trong quá trình đào tạo, chúng tôi thêm phím hướng dẫn, phím nhập và phím phản hồi cho từng phần, kết hợp chúng vào lời nhắc đào tạo và mã hóa nó. Sau đó, dữ liệu được cung cấp cho người huấn luyện trong SageMaker để tạo ra mô hình tinh chỉnh.
Để đẩy nhanh quá trình đào tạo và giảm chi phí tài nguyên máy tính, chúng tôi đã sử dụng Tinh chỉnh thông số hiệu quả (PEFT) với Thích ứng cấp thấp (LoRA) kỹ thuật. PEFT cho phép chúng tôi chỉ tinh chỉnh một số lượng nhỏ các tham số mô hình bổ sung và LoRA thể hiện việc cập nhật trọng số với hai ma trận nhỏ hơn thông qua phân tách thứ hạng thấp. Với PEFT và LoRA trên lượng tử hóa 8 bit (một thao tác nén giúp giảm hơn nữa dung lượng bộ nhớ của mô hình và tăng tốc hiệu suất đào tạo và suy luận), chúng tôi có thể điều chỉnh việc đào tạo 125 cặp câu hỏi-câu trả lời trong phiên bản g4dn.x với một GPU duy nhất.
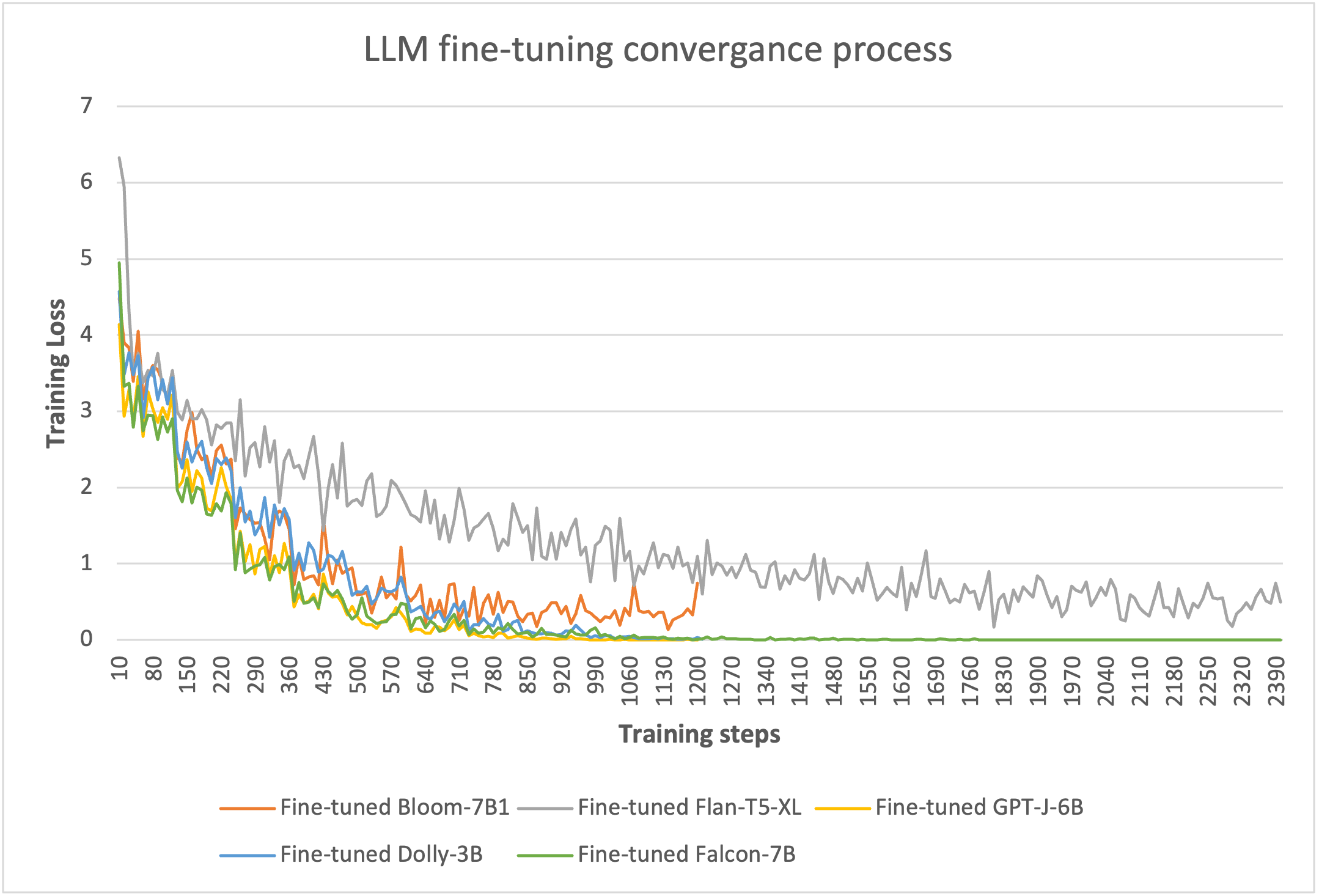
Để chứng minh tính hiệu quả của việc tinh chỉnh, chúng tôi đã thử nghiệm với nhiều LLM trên SageMaker. Chúng tôi đã chọn năm mẫu kích thước nhỏ: Bloom-7B, Flan-T5-XL, GPT-J-6B và Falcon-7B trên SageMaker JumpStart và Dolly-3B từ Ôm mặt trên SageMaker.
Thông qua đào tạo dựa trên LoRA 8 bit, chúng tôi có thể giảm các tham số có thể huấn luyện xuống không quá 5% tổng trọng lượng của mỗi mô hình. Quá trình đào tạo mất 10–20 kỷ nguyên để hội tụ, như thể hiện trong hình dưới đây. Đối với mỗi mô hình, các quy trình tinh chỉnh có thể phù hợp trên một GPU duy nhất của phiên bản g4dn.x, giúp tối ưu hóa chi phí tài nguyên điện toán.
Suy luận mô hình tinh chỉnh được triển khai trên SageMaker
Chúng tôi đã triển khai mô hình tinh chỉnh cùng với khung RAG trong một nút GPU g4dn.x duy nhất trên SageMaker và so sánh kết quả suy luận cho 125 câu hỏi. Hiệu suất của mô hình được đo bằng hai số liệu. Một là ĐỎ (Điểm số của Nghiên cứu sinh định hướng thu hồi để đánh giá Gisting), một điểm số phổ biến xử lý ngôn ngữ tự nhiên (NLP) phương pháp đánh giá mô hình tính toán thương số của các từ phù hợp dưới tổng số từ trong câu tham chiếu. Cái khác là sự tương đồng về ngữ nghĩa (văn bản) điểm, đo lường mức độ gần gũi của hai phần ý nghĩa văn bản bằng cách sử dụng mô hình biến đổi để mã hóa các câu để có được phần nhúng của chúng, sau đó sử dụng thước đo độ tương tự cosin để tính điểm tương tự của chúng. Từ thực nghiệm, chúng ta có thể thấy hai thước đo này khá nhất quán trong việc trình bày chất lượng câu trả lời cho các câu hỏi.
Trong bảng và hình dưới đây, chúng ta có thể thấy rằng mô hình Falcon-7B được tinh chỉnh mang lại chất lượng phản hồi tốt nhất và các mô hình Flan-T5-XL và Dolly-3B cũng tạo ra phản hồi chính xác.
| . | RAG_GPT-J-6B_Flan-T5-XL | RAG_GPT-J-6B_Flan-T5-XXL | Tinh chỉnh Bloom-7B1 | Tinh chỉnh Flan-T5-XL | Tinh chỉnh GPT-J-6B | Tinh chỉnh Dolly-3B | Falcon-7B được tinh chỉnh |
| Điểm ROUGE | 0.1938 | 0.2747 | 0.3914 | 0.4977 | 0.3740 | 0.6991 | 0.9459 |
| Điểm tương đồng về ngữ nghĩa | 0.4121 | 0.4786 | 0.5666 | 0.7205 | 0.5414 | 0.8147 | 0.9774 |

Sau đây là một câu trả lời mẫu từ các mô hình. RAG với mẫu Flan-T5-XL mang lại phản hồi có tính ảo giác cao, trong khi phản hồi từ RAG với mẫu Flan-T5-XXL lớn hơn phù hợp hơn nhưng vẫn không thể truyền tải đầy đủ thông điệp mong đợi. So sánh, tất cả các mẫu được tinh chỉnh (Flan-T5-XL, Dolly-3B và Falcon-7B) đều có thể đưa ra phản hồi chính xác nhất như câu trả lời mong đợi.
| câu hỏi | Các yêu cầu đối với Chất bịt kín/Chất làm cứng sau mài là gì? (TS0004 – phần 2.8) |
| Câu trả lời dự kiến | Chất bịt kín/chất làm cứng gốc Lithium sẽ được sử dụng sau bất kỳ quy trình mài/chà nào được thực hiện trên Sàn AR. Vui lòng tham khảo Quy trình SCA tầng TGC /0007 AR. Các giải pháp thay thế sẽ được xem xét nhưng phải được Amazon và Nhà tư vấn sàn phê duyệt. |
| Trả lời từ RAG (nhúng GPT-J-6B với Flan-T5-XL) | Chất làm cứng bê tông xuyên thấu phải được thảo luận tại cuộc họp trước khi đổ và phải được Tư vấn sàn và Amazon phê duyệt |
| Trả lời từ RAG (nhúng GPT-J-6B với Flan-T5-XXL) | Hợp chất được đề xuất phải được thảo luận tại cuộc họp trước khi đổ và phải được Tư vấn sàn và Amazon phê duyệt. Các giải pháp thay thế sẽ được xem xét nhưng phải được Amazon và Nhà tư vấn sàn phê duyệt. |
| Câu trả lời từ Flan-T5-XL tinh chỉnh | Chất bịt kín/chất làm cứng gốc Lithium sẽ được sử dụng sau bất kỳ quy trình mài/chà nào được thực hiện trên Sàn AR. Vui lòng tham khảo Quy trình SCA tầng TGC /0007 AR. Các giải pháp thay thế sẽ được xem xét nhưng phải được Amazon và Nhà tư vấn sàn phê duyệt. |
| Câu trả lời từ Dolly-3B được tinh chỉnh | Chất bịt kín/chất làm cứng gốc Lithium sẽ được sử dụng sau bất kỳ quy trình mài/chà nào được thực hiện trên Sàn AR. Vui lòng tham khảo Quy trình SCA tầng TGC /0007 AR. Các giải pháp thay thế sẽ được xem xét nhưng phải được Amazon và Nhà tư vấn sàn phê duyệt. |
| Câu trả lời từ Falcon-7B được tinh chỉnh | Chất bịt kín/chất làm cứng gốc Lithium sẽ được sử dụng sau bất kỳ quy trình mài/chà nào được thực hiện trên Sàn AR. Vui lòng tham khảo Quy trình SCA tầng TGC /0007 AR. Các giải pháp thay thế sẽ được xem xét nhưng phải được Amazon và Nhà tư vấn sàn phê duyệt. |
Nguyên mẫu giải pháp và kết quả
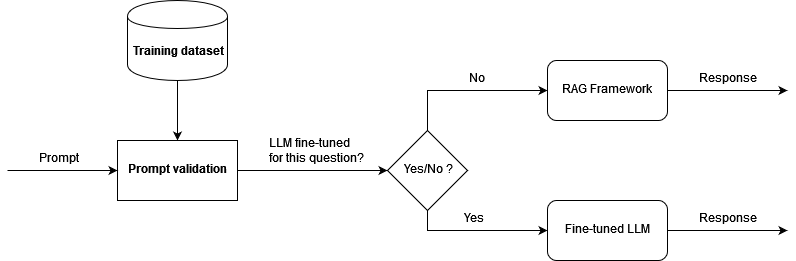
Chúng tôi đã phát triển một nguyên mẫu dựa trên kiến trúc được trình bày và tiến hành thử nghiệm khái niệm để chứng minh kết quả. Để tận dụng cả khung RAG và LLM được tinh chỉnh, đồng thời để giảm ảo giác, trước tiên chúng tôi xác thực câu hỏi đến về mặt ngữ nghĩa. Nếu câu hỏi nằm trong số dữ liệu huấn luyện để tinh chỉnh (mô hình tinh chỉnh đã có kiến thức để đưa ra câu trả lời chất lượng cao), thì chúng tôi sẽ hướng câu hỏi đó như một lời nhắc để suy ra mô hình tinh chỉnh. Nếu không, câu hỏi sẽ đi qua LangChain và nhận được phản hồi từ RAG. Sơ đồ sau đây minh họa quy trình làm việc này.
Chúng tôi đã kiểm tra kiến trúc bằng tập dữ liệu kiểm tra gồm 166 câu hỏi, trong đó có 125 câu hỏi dùng để tinh chỉnh mô hình và 41 câu hỏi bổ sung mà mô hình tinh chỉnh chưa được đào tạo. Khung RAG với mô hình nhúng và mô hình Falcon-7B được tinh chỉnh đã mang lại kết quả chất lượng cao với điểm ROUGE là 0.7898 và điểm tương đồng về ngữ nghĩa là 0.8781. Như được hiển thị trong các ví dụ sau, khung có thể tạo ra câu trả lời cho các câu hỏi của người dùng rất khớp với tài liệu D&C.
Hình ảnh sau đây là tài liệu ví dụ đầu tiên của chúng tôi.

Ảnh chụp màn hình sau đây hiển thị đầu ra của bot.

Bot cũng có thể phản hồi bằng dữ liệu từ bảng hoặc danh sách và hiển thị số liệu cho các câu hỏi tương ứng. Ví dụ: chúng tôi sử dụng tài liệu sau.

Ảnh chụp màn hình sau đây hiển thị đầu ra của bot.

Chúng ta cũng có thể sử dụng tài liệu có hình, như trong ví dụ sau.

Ảnh chụp màn hình sau đây hiển thị đầu ra của bot kèm theo văn bản và hình ảnh.

Ảnh chụp màn hình sau đây hiển thị đầu ra của bot chỉ bằng hình vẽ.
Bài học kinh nghiệm và thực tiễn tốt nhất
Thông qua thiết kế giải pháp và thử nghiệm với nhiều LLM, chúng tôi đã học được cách đảm bảo chất lượng và hiệu suất cho nhiệm vụ trả lời câu hỏi trong giải pháp AI tổng quát. Chúng tôi khuyên bạn nên áp dụng các phương pháp hay nhất sau đây khi áp dụng giải pháp cho các trường hợp sử dụng tính năng trả lời câu hỏi của mình:
- RAG cung cấp câu trả lời hợp lý cho các câu hỏi kỹ thuật. Hiệu suất phụ thuộc nhiều vào việc nhúng và lập chỉ mục tài liệu. Đối với các tài liệu có tính phi cấu trúc cao, bạn có thể cần một số thao tác thủ công để phân chia và bổ sung tài liệu một cách chính xác trước khi nhúng và lập chỉ mục LLM.
- Việc tìm kiếm chỉ mục rất quan trọng để xác định đầu ra cuối cùng của RAG. Bạn nên điều chỉnh đúng thuật toán tìm kiếm để đạt được mức độ chính xác cao và đảm bảo RAG tạo ra các phản hồi phù hợp hơn.
- Các LLM được tinh chỉnh có thể học thêm kiến thức từ các tài liệu phi cấu trúc và kỹ thuật cao, đồng thời sở hữu kiến thức trong mô hình mà không phụ thuộc vào tài liệu sau khi đào tạo. Điều này đặc biệt hữu ích cho những trường hợp không thể chịu đựng được ảo giác.
- Để đảm bảo chất lượng phản hồi của mô hình, định dạng tập dữ liệu huấn luyện để tinh chỉnh phải sử dụng mẫu lời nhắc dành riêng cho nhiệm vụ được xác định chính xác. Quy trình suy luận phải tuân theo cùng một khuôn mẫu để tạo ra các phản hồi giống con người.
- LLM thường đi kèm với mức giá đáng kể và đòi hỏi nguồn lực đáng kể cũng như chi phí cắt cổ. Bạn có thể sử dụng PEFT và LoRA cũng như các kỹ thuật lượng tử hóa để giảm nhu cầu về sức mạnh tính toán và tránh chi phí suy luận và đào tạo cao.
- SageMaker JumpStart cung cấp các LLM được đào tạo trước dễ truy cập để tinh chỉnh, suy luận và triển khai. Nó có thể tăng tốc đáng kể việc thiết kế và triển khai giải pháp AI tổng quát của bạn.
Kết luận
Với khung RAG và LLM được tinh chỉnh trên SageMaker, chúng tôi có thể cung cấp phản hồi giống như con người cho các câu hỏi và lời nhắc của người dùng, từ đó cho phép người dùng truy xuất thông tin chính xác một cách hiệu quả từ một khối lượng lớn tài liệu không có cấu trúc và không có tổ chức. Chúng tôi sẽ tiếp tục phát triển giải pháp, chẳng hạn như cung cấp mức độ phản hồi theo ngữ cảnh cao hơn từ các tương tác trước đó và tinh chỉnh thêm các mô hình từ phản hồi của con người.
Phản hồi của bạn luôn được chào đón; hãy để lại suy nghĩ và câu hỏi của bạn trong phần bình luận.
Giới thiệu về tác giả
 Vân Phi Bạch là Kiến trúc sư giải pháp cấp cao tại AWS. Với nền tảng về AI/ML, khoa học dữ liệu và phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Ông thiết kế các giải pháp AI/ML và phân tích dữ liệu để vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei có bằng Tiến sĩ về Kỹ thuật Điện và Điện tử. Ngoài công việc, Yunfei thích đọc sách và âm nhạc.
Vân Phi Bạch là Kiến trúc sư giải pháp cấp cao tại AWS. Với nền tảng về AI/ML, khoa học dữ liệu và phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Ông thiết kế các giải pháp AI/ML và phân tích dữ liệu để vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei có bằng Tiến sĩ về Kỹ thuật Điện và Điện tử. Ngoài công việc, Yunfei thích đọc sách và âm nhạc.
 Burak Gozluklu là Kiến trúc sư Giải pháp Chuyên gia ML chính có trụ sở tại Boston, MA. Burak có hơn 15 năm kinh nghiệm trong ngành về mô hình mô phỏng, khoa học dữ liệu và công nghệ ML. Anh giúp khách hàng toàn cầu áp dụng các công nghệ AWS và đặc biệt là các giải pháp AI/ML để đạt được mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Kỹ thuật Hàng không Vũ trụ tại METU, bằng Thạc sĩ Kỹ thuật Hệ thống và bằng tiến sĩ về động lực học hệ thống tại MIT ở Cambridge, MA. Burak đam mê yoga và thiền định.
Burak Gozluklu là Kiến trúc sư Giải pháp Chuyên gia ML chính có trụ sở tại Boston, MA. Burak có hơn 15 năm kinh nghiệm trong ngành về mô hình mô phỏng, khoa học dữ liệu và công nghệ ML. Anh giúp khách hàng toàn cầu áp dụng các công nghệ AWS và đặc biệt là các giải pháp AI/ML để đạt được mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Kỹ thuật Hàng không Vũ trụ tại METU, bằng Thạc sĩ Kỹ thuật Hệ thống và bằng tiến sĩ về động lực học hệ thống tại MIT ở Cambridge, MA. Burak đam mê yoga và thiền định.
 Elad Dwek là Giám đốc Công nghệ Xây dựng tại Amazon. Với nền tảng về xây dựng và quản lý dự án, Elad giúp các nhóm áp dụng các công nghệ mới và quy trình dựa trên dữ liệu để thực hiện các dự án xây dựng. Anh ấy xác định các nhu cầu và giải pháp, đồng thời tạo điều kiện phát triển các thuộc tính riêng biệt. Elad có bằng MBA và bằng Cử nhân Kỹ thuật Kết cấu. Ngoài công việc, Elad thích tập yoga, làm đồ mộc và đi du lịch cùng gia đình.
Elad Dwek là Giám đốc Công nghệ Xây dựng tại Amazon. Với nền tảng về xây dựng và quản lý dự án, Elad giúp các nhóm áp dụng các công nghệ mới và quy trình dựa trên dữ liệu để thực hiện các dự án xây dựng. Anh ấy xác định các nhu cầu và giải pháp, đồng thời tạo điều kiện phát triển các thuộc tính riêng biệt. Elad có bằng MBA và bằng Cử nhân Kỹ thuật Kết cấu. Ngoài công việc, Elad thích tập yoga, làm đồ mộc và đi du lịch cùng gia đình.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/a-generative-ai-powered-solution-on-amazon-sagemaker-to-help-amazon-eu-design-and-construction/

