Giới thiệu
Trong thế giới của trí tuệ nhân tạo, hãy tưởng tượng một kỹ thuật học tập cho phép máy móc xây dựng kiến thức hiện có và giải quyết những thách thức mới bằng kiến thức chuyên môn. Kỹ thuật độc đáo này được gọi là học chuyển giao. Trong những năm gần đây, chúng ta đã chứng kiến sự mở rộng về khả năng và ứng dụng của các mô hình tổng quát. Chúng ta có thể sử dụng phương pháp học chuyển giao để đơn giản hóa việc đào tạo các mô hình tổng quát. Hãy tưởng tượng một nghệ sĩ lành nghề, thông thạo nhiều loại hình nghệ thuật khác nhau, có thể dễ dàng tạo ra một kiệt tác bằng cách sử dụng các kỹ năng đa dạng của họ. Tương tự, học chuyển giao trao quyền cho máy móc sử dụng kiến thức thu được trong một lĩnh vực để vượt trội trong lĩnh vực khác. Khả năng chuyển giao kiến thức tuyệt vời, đáng kinh ngạc này đã mở ra một thế giới tiềm năng về trí tuệ nhân tạo.
Mục tiêu học tập
Trong bài viết này, chúng tôi sẽ
- Hiểu rõ hơn về khái niệm học chuyển giao và khám phá những lợi thế mà nó mang lại trong thế giới học máy.
- Ngoài ra, chúng ta sẽ khám phá các ứng dụng khác nhau trong thế giới thực trong đó việc học chuyển tiếp được sử dụng một cách hiệu quả.
- Sau đó, hiểu được quy trình từng bước xây dựng mô hình phân loại cử chỉ tay oẳn tù tì.
- Khám phá cách áp dụng các kỹ thuật học chuyển giao để đào tạo và kiểm tra mô hình của bạn một cách hiệu quả.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Chuyển giao học tập
Hãy tưởng tượng bạn là một đứa trẻ và háo hức muốn học cách đi xe đạp lần đầu tiên. Bạn sẽ khó giữ được sự cân bằng và học hỏi. Lúc đó bạn phải học lại mọi thứ từ đầu. Nhớ giữ thăng bằng, cầm lái, sử dụng phanh, mọi thứ sẽ tốt nhất. Phải mất rất nhiều thời gian và sau nhiều lần thử không thành công, cuối cùng bạn cũng sẽ học được mọi thứ.
Tương tự, hãy tưởng tượng bây giờ nếu bạn muốn học lái xe mô tô. Trong trường hợp này, bạn không cần phải học mọi thứ từ đầu như thời thơ ấu. Bây giờ bạn đã biết nhiều điều rồi. Bạn đã có một số kỹ năng như cách giữ thăng bằng, cách điều khiển tay lái và cách sử dụng phanh. Bây giờ, bạn phải chuyển giao tất cả các kỹ năng này và học các kỹ năng bổ sung như sử dụng bánh răng. Giúp bạn dễ dàng hơn nhiều và mất ít thời gian hơn để học. Bây giờ, hãy hiểu việc học chuyển giao từ góc độ kỹ thuật.
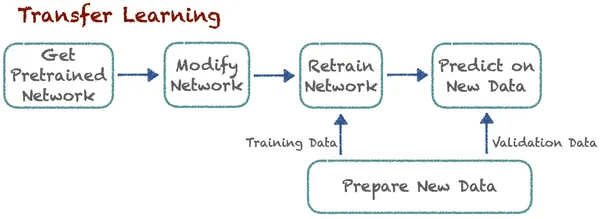
Học chuyển tiếp cải thiện việc học trong một nhiệm vụ mới bằng cách chuyển giao kiến thức từ một bài học liên quan mà các chuyên gia đã khám phá. Kỹ thuật này cho phép các thuật toán ghi nhớ công việc mới bằng cách sử dụng các mô hình được đào tạo trước. Giả sử có một thuật toán phân loại chó và mèo. Giờ đây, các chuyên gia sử dụng cùng một mô hình đã được huấn luyện trước với một số sửa đổi để phân loại ô tô và xe tải. Ý tưởng cơ bản ở đây là phân loại. Ở đây, việc học các nhiệm vụ mới dựa trên các bài học đã biết trước đó. Thuật toán có thể lưu trữ và truy cập kiến thức đã học trước đó.
Lợi ích của việc học chuyển tiếp
- Học nhanh hơn: Vì mô hình không học từ đầu nên việc học các nhiệm vụ mới mất rất ít thời gian. Nó sử dụng kiến thức được đào tạo trước, giảm đáng kể thời gian đào tạo và tài nguyên tính toán. Mô hình cần có sự khởi đầu thuận lợi. Bằng cách này, nó có lợi ích là học nhanh hơn.
- Cải thiện hiệu suất: Các mô hình sử dụng phương pháp học chuyển giao sẽ đạt được hiệu suất tốt hơn, đặc biệt là khi chúng tinh chỉnh mô hình được đào tạo trước cho một nhiệm vụ liên quan, so với các mô hình học mọi thứ từ đầu. Điều này dẫn đến độ chính xác và hiệu quả cao hơn.
- Hiệu quả dữ liệu: Chúng tôi biết rằng việc đào tạo các mô hình deep learning đòi hỏi rất nhiều dữ liệu. Tuy nhiên, chúng tôi cần các bộ dữ liệu nhỏ hơn cho các mô hình học chuyển giao vì chúng kế thừa kiến thức từ miền nguồn. Vì vậy, nó làm giảm nhu cầu về lượng lớn dữ liệu được dán nhãn.
- Tiết kiệm tài nguyên: Việc xây dựng và duy trì các mô hình quy mô lớn từ đầu có thể tốn nhiều tài nguyên. Học tập chuyển giao cho phép các tổ chức sử dụng các nguồn lực hiện có một cách hiệu quả. Và chúng tôi không cần nhiều tài nguyên để có đủ dữ liệu đào tạo.
- Học liên tục: Học tập liên tục có thể đạt được bằng cách học chuyển giao. Các mô hình có thể liên tục học hỏi và thích ứng với dữ liệu, nhiệm vụ hoặc môi trường mới. Vì vậy, nó đạt được khả năng học tập liên tục, điều này rất cần thiết trong học máy.
- Kết quả hiện đại: Học tập chuyển giao đã đóng một vai trò quan trọng trong việc đạt được kết quả tiên tiến. Nó đã đạt được kết quả tiên tiến trong nhiều cuộc thi và điểm chuẩn về máy học. Bây giờ nó đã trở thành một kỹ thuật tiêu chuẩn trong lĩnh vực này.
Ứng dụng của học tập chuyển tiếp
Học chuyển giao tương tự như việc sử dụng kiến thức hiện có của bạn để làm cho việc học những điều mới trở nên đơn giản hơn. Đó là một kỹ thuật mạnh mẽ được sử dụng rộng rãi trên các lĩnh vực khác nhau để nâng cao khả năng của các chương trình máy tính. Bây giờ, hãy cùng khám phá một số lĩnh vực chung trong đó việc học chuyển giao đóng một vai trò quan trọng.
Tầm nhìn máy tính:
nhiều thị giác máy tính các nhiệm vụ sử dụng rộng rãi phương pháp học chuyển giao, đặc biệt là trong phát hiện đối tượng, trong đó các chuyên gia tinh chỉnh các mô hình được đào tạo trước như ResNet, VGG hoặc MobileNet cho các nhiệm vụ nhận dạng đối tượng cụ thể. Một số mô hình như FaceNet và OpenFace sử dụng phương pháp học chuyển giao để nhận dạng khuôn mặt trong các điều kiện ánh sáng, tư thế và góc độ khác nhau. Các mô hình được đào tạo trước cũng được điều chỉnh cho các nhiệm vụ phân loại hình ảnh. Chúng bao gồm phân tích hình ảnh y tế, giám sát động vật hoang dã và kiểm soát chất lượng trong sản xuất.
Xử lý ngôn ngữ tự nhiên (NLP):
Có một số mô hình học chuyển giao như Chứng nhận và GPT nơi các mô hình này được tinh chỉnh để phân tích cảm tính. Để họ có thể hiểu được cảm xúc của văn bản trong nhiều tình huống khác nhau, mô hình Transformer của Google sử dụng phương pháp học chuyển giao để dịch văn bản giữa các ngôn ngữ.
Xe tự hành:
Việc áp dụng phương pháp học chuyển giao trong xe tự trị là một lĩnh vực phát triển nhanh chóng và quan trọng trong ngành công nghiệp ô tô. Có nhiều phân đoạn trong lĩnh vực này sử dụng phương pháp học chuyển giao. Một số là phát hiện đối tượng, nhận dạng đối tượng, lập kế hoạch đường đi, dự đoán hành vi, tổng hợp cảm biến, kiểm soát giao thông, v.v.
Tạo nội dung:
Tạo nội dung là một ứng dụng thú vị của việc học chuyển giao. GPT-3 (Generative Pre-training Transformer 3) đã được đào tạo trên một lượng lớn dữ liệu văn bản. Nó có thể tạo ra nội dung sáng tạo trong nhiều lĩnh vực. GPT-3 và các mô hình khác tạo ra nội dung sáng tạo, bao gồm nghệ thuật, âm nhạc, kể chuyện và tạo mã.
Hệ thống khuyến nghị:
Chúng ta đều biết những lợi ích của hệ thống khuyến nghị. Nó chỉ đơn giản là làm cho cuộc sống của chúng tôi đơn giản hơn một chút và vâng, chúng tôi cũng sử dụng phương pháp học chuyển tiếp ở đây. Nhiều nền tảng trực tuyến, bao gồm Netflix và YouTube, sử dụng phương pháp học chuyển giao để đề xuất phim và video dựa trên sở thích của người dùng.
Tìm hiểu: Hiểu về học chuyển giao cho học sâu
Tăng cường các mô hình sáng tạo
Các mô hình sáng tạo là một trong những khái niệm thú vị và mang tính cách mạng nhất trong lĩnh vực trí tuệ nhân tạo đang phát triển nhanh chóng. Theo nhiều cách, học chuyển giao có thể cải thiện chức năng và hiệu suất của các mô hình AI tổng quát như GAN (Mạng đối thủ sáng tạo) or VAE (Bộ mã hóa tự động biến thiên). Một trong những lợi ích chính của học chuyển giao là nó cho phép các mô hình sử dụng kiến thức thu được vào các nhiệm vụ liên quan khác nhau. Chúng tôi biết rằng các mô hình sáng tạo đòi hỏi phải đào tạo chuyên sâu. Để đạt được kết quả tốt hơn, việc đào tạo nó trên các tập dữ liệu lớn là điều cần thiết, một phương pháp được khuyến khích mạnh mẽ bởi phương pháp học chuyển giao. Thay vì bắt đầu lại từ đầu, các mô hình có thể bắt đầu hoạt động với kiến thức đã có từ trước.
Trong trường hợp GAN hoặc VAE, các chuyên gia có thể đào tạo trước bộ phận phân biệt hoặc bộ mã hóa-giải mã của mô hình trên tập dữ liệu hoặc miền rộng hơn. Điều này có thể tăng tốc quá trình đào tạo. Các mô hình sáng tạo thường cần lượng lớn dữ liệu theo miền cụ thể để tạo ra nội dung chất lượng cao. Học chuyển có thể giải quyết vấn đề này vì nó chỉ yêu cầu các bộ dữ liệu nhỏ hơn. Nó cũng tạo điều kiện cho việc học tập liên tục và thích ứng với các mô hình sáng tạo.
Học chuyển giao đã tìm thấy những ứng dụng thực tế trong việc cải thiện các mô hình AI tổng quát. Nó đã được sử dụng để điều chỉnh các mô hình dựa trên văn bản như GPT-3 để tạo hình ảnh và viết mã. Trong trường hợp của GAN, việc học chuyển giao có thể giúp tạo ra những hình ảnh siêu thực. Khi AI sáng tạo ngày càng trở nên tốt hơn, việc học chuyển giao sẽ cực kỳ quan trọng trong việc giúp nó làm được những điều xuất sắc hơn nữa.
MobileNet V2
Google đã tạo ra MobileNetV2, một kiến trúc mạng thần kinh được đào tạo trước mạnh mẽ được sử dụng rộng rãi trong thị giác máy tính và các ứng dụng học sâu. Ban đầu, họ dự định mô hình này sẽ xử lý và phân tích hình ảnh một cách nhanh chóng, nhằm đạt được hiệu suất vượt trội trong nhiều tác vụ khác nhau. Hiện tại nó là một lựa chọn được ưa chuộng cho nhiều tác vụ thị giác máy tính. MobileNetV2 được thiết kế đặc biệt để nhẹ và hiệu quả. Nó cần một số lượng tham số tương đối nhỏ và đạt được kết quả ấn tượng, có độ chính xác cao.
Bất chấp tính hiệu quả của nó, MobileNetV2 vẫn duy trì độ chính xác cao trong các tác vụ thị giác máy tính khác nhau. MobileNetV2 giới thiệu khái niệm phần dư nghịch đảo. Không giống như phần dư truyền thống, trong đó đầu ra của một lớp được thêm vào đầu vào của nó, phần dư đảo ngược sử dụng kết nối phím tắt để thêm thông tin vào quá trình sản xuất. Nó làm cho mô hình sâu hơn và hiệu quả hơn.
Phần dư đảo ngược sử dụng kết nối phím tắt để thêm thông tin vào quá trình sản xuất, không giống như phần dư truyền thống trong đó đầu ra của một lớp được thêm vào đầu vào của nó. Bạn có thể lấy mô hình MobileNetV2 được đào tạo trước này và tinh chỉnh nó cho các ứng dụng cụ thể. Vì vậy, nó tiết kiệm rất nhiều thời gian cũng như tài nguyên tính toán, dẫn đến giảm chi phí tính toán. Vì tính hiệu quả và hiệu quả của nó, MobileNetV2 được sử dụng rộng rãi trong công nghiệp và nghiên cứu. TensorFlow Hub cung cấp khả năng truy cập dễ dàng vào các mô hình MobileNetV2 đã được đào tạo trước. Việc tích hợp mô hình vào các dự án dựa trên Tensorflow giúp việc tích hợp trở nên đơn giản.
Phân loại Rock-Paper-Kéo
Hãy bắt đầu xây dựng một máy học mô hình cho nhiệm vụ phân loại oẳn tù tì. Chúng tôi sẽ sử dụng kỹ thuật học chuyển giao để thực hiện. Để làm được điều đó, chúng tôi sử dụng mô hình được đào tạo trước MobileNet V2.

Bộ dữ liệu Rock-Paper-Kéo
Bộ dữ liệu 'Rock Paper Scissors' là tập hợp gồm 2,892 hình ảnh. Nó bao gồm các bàn tay đa dạng ở cả ba tư thế khác nhau. Đó là,
- Đá: Nắm tay siết chặt.
- Giấy: Lòng bàn tay mở.
- Cây kéo: Hai ngón tay duỗi thẳng tạo thành chữ V.
Các hình ảnh bao gồm bàn tay của những người thuộc các chủng tộc, lứa tuổi và giới tính khác nhau. Tất cả các bức ảnh đều có nền trắng trơn giống nhau. Sự đa dạng này làm cho nó trở thành một nguồn tài nguyên quý giá cho các ứng dụng học máy và thị giác máy tính. Điều này giúp ngăn chặn cả việc trang bị quá mức và thiếu trang bị.
Đang tải và khám phá bộ dữ liệu
Hãy bắt đầu bằng cách nhập các thư viện cơ bản cần thiết. Dự án này yêu cầu tensorflow, tensorflow hub, tensorflow bộ dữ liệu cho tập dữ liệu, matplotlib để trực quan hóa, numpy và os.
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
import matplotlib.pylab as plt
import numpy as np
import os
Sử dụng bộ dữ liệu tensorflow, tải bộ dữ liệu “Rock Paper Scissors”. Ở đây, chúng tôi đang cung cấp bốn tham số cho nó. Chúng ta phải đề cập đến tên của tập dữ liệu mà chúng ta cần tải. Đây là oẳn tù tì. Để yêu cầu thông tin về tập dữ liệu, hãy đặt with_info thành True. Tiếp theo, để tải tập dữ liệu ở định dạng được giám sát, hãy đặt as_supervised thành True.
Và cuối cùng, xác định các phần tách mà chúng ta muốn tải. Ở đây, chúng ta cần huấn luyện và kiểm tra các phân vùng. Tải tập dữ liệu và thông tin vào các biến tương ứng.
datasets, info = tfds.load( name='rock_paper_scissors', # Specify the name of the dataset you want to load. with_info=True, # To request information about the dataset as_supervised=True, # Load the dataset in a supervised format. split=['train', 'test'] # Define the splits you want to load.
)
In thông tin
Bây giờ in thông tin. Nó sẽ xuất bản tất cả các chi tiết của tập dữ liệu. Đó là tên, phiên bản, mô tả, tài nguyên tập dữ liệu gốc, tính năng, tổng số hình ảnh, số phân tách, tác giả và nhiều chi tiết khác.
info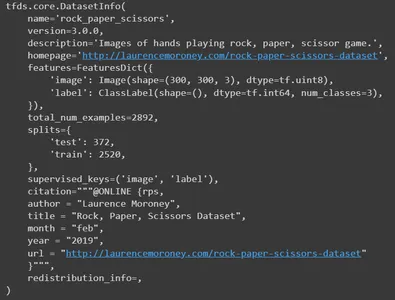
Bây giờ, hãy in một số hình ảnh mẫu từ tập dữ liệu huấn luyện.
train, info_train = tfds.load(name='rock_paper_scissors', with_info=True, split='train')
tfds.show_examples(info_train,train)
Trước tiên, chúng tôi tải tập dữ liệu “Rock Paper Scissors” cho bọn trẻ. Load(), chỉ định riêng phần đào tạo và kiểm tra. Sau đó, chúng tôi ghép các tập dữ liệu huấn luyện và kiểm tra bằng phương thức .concatenate(). Cuối cùng, chúng tôi xáo trộn tập dữ liệu kết hợp bằng phương thức .shuffle() với kích thước bộ đệm 3000. Bây giờ, bạn có một biến tập dữ liệu duy nhất kết hợp dữ liệu huấn luyện và kiểm tra.
dataset=datasets[0].concatenate(datasets[1])
dataset=dataset.shuffle(3000)Chúng ta phải chia toàn bộ tập dữ liệu thành các tập dữ liệu huấn luyện, kiểm tra và xác thực bằng các phương thức Skip() và take(). Chúng tôi sử dụng 600 mẫu đầu tiên của tập dữ liệu để xác thực. Sau đó, chúng tôi tạo tập dữ liệu tạm thời bằng cách loại trừ 600 hình ảnh ban đầu. Trong tập dữ liệu tạm thời này, chúng tôi chọn 400 ảnh đầu tiên để thử nghiệm. Một lần nữa, trong tập dữ liệu huấn luyện, nó sẽ lấy tất cả các ảnh của tập dữ liệu tạm thời sau khi bỏ qua 400 hình ảnh đầu tiên.
Dưới đây là tóm tắt về cách phân chia dữ liệu:
- rsp_val: 600 ví dụ để xác thực.
- rsp_test: 400 mẫu để thử nghiệm.
- rsp_train: Các ví dụ còn lại để huấn luyện.
rsp_val=dataset.take(600)
rsp_test_temp=dataset.skip(600)
rsp_test=rsp_test_temp.take(400)
rsp_train=rsp_test_temp.skip(400)Vì vậy, hãy xem có bao nhiêu hình ảnh trong tập dữ liệu huấn luyện.
len(list(rsp_train)) #1892
#It has 1892 images in totalXử lý dữ liệu
Bây giờ, hãy thực hiện một số tiền xử lý cho tập dữ liệu của chúng tôi. Để làm được điều đó, chúng ta sẽ xác định thang đo hàm. Chúng ta sẽ chuyển hình ảnh và nhãn tương ứng của nó làm đối số cho nó. Sử dụng phương thức cast, chúng ta sẽ chuyển đổi kiểu dữ liệu của hình ảnh thành float32. Sau đó, trong bước tiếp theo, chúng ta phải chuẩn hóa các giá trị pixel của hình ảnh. Nó chia tỷ lệ các giá trị pixel của hình ảnh thành phạm vi [0, 1]. Thay đổi kích thước hình ảnh là bước tiền xử lý phổ biến để đảm bảo rằng tất cả hình ảnh đầu vào đều có kích thước chính xác, thường được yêu cầu khi đào tạo các mô hình deep learning. Vì vậy, chúng tôi sẽ trả về hình ảnh có kích thước [224,224]. Đối với các nhãn, chúng tôi sẽ thực hiện mã hóa onehot. Nhãn sẽ được chuyển đổi thành vectơ được mã hóa một lần nếu bạn có ba lớp (Đá, Giấy, Kéo). Vector này đang được trả lại.
Ví dụ: nếu nhãn là 1 (Giấy) thì nó sẽ được chuyển thành [0, 1, 0]. Ở đây, mỗi phần tử tương ứng với một lớp. Số “1” được đặt ở vị trí tương ứng với loại cụ thể đó (Giấy). Tương tự, đối với nhãn đá, vectơ sẽ là [1, 0, 0] và đối với nhãn kéo sẽ là [0, 0, 1].
Mã
def scale(image, label): image = tf.cast(image, tf.float32) image /= 255.0 return tf.image.resize(image,[224,224]), tf.one_hot(label, 3)Bây giờ, hãy xác định một hàm để tạo các tập dữ liệu theo lô và được xử lý trước để đào tạo, kiểm tra và xác thực. Áp dụng hàm tỷ lệ được xác định trước cho cả ba bộ dữ liệu. Xác định kích thước lô là 64 và chuyển nó làm đối số. Điều này phổ biến trong học sâu, trong đó các mô hình thường được đào tạo trên hàng loạt dữ liệu thay vì các ví dụ riêng lẻ. Chúng ta cần xáo trộn tập dữ liệu tàu để tránh trang bị quá mức. Cuối cùng, trả về tất cả ba bộ dữ liệu được chia tỷ lệ.
def get_dataset(batch_size=64): train_dataset_scaled = rsp_train.map(scale).shuffle(1900).batch(batch_size) test_dataset_scaled = rsp_test.map(scale).batch(batch_size) val_dataset_scaled = rsp_val.map(scale).batch(batch_size) return train_dataset_scaled, test_dataset_scaled, val_dataset_scaledTải ba tập dữ liệu riêng lẻ bằng hàm get_dataset. Sau đó, tạo bộ nhớ đệm và bộ dữ liệu xác thực. Bộ nhớ đệm là một kỹ thuật có giá trị để cải thiện hiệu suất tải dữ liệu, đặc biệt khi bạn có đủ bộ nhớ để lưu trữ tập dữ liệu. Bộ nhớ đệm có nghĩa là dữ liệu được tải vào bộ nhớ và được giữ ở đó để truy cập nhanh hơn trong các bước đào tạo và xác thực. Điều này có thể tăng tốc độ đào tạo, đặc biệt nếu quá trình đào tạo của bạn bao gồm nhiều kỷ nguyên, vì nó tránh tải nhiều lần cùng một dữ liệu từ bộ lưu trữ.
train_dataset, test_dataset, val_dataset = get_dataset()
train_dataset.cache()
val_dataset.cache()Đang tải mô hình được đào tạo trước
Sử dụng Tensorflow Hub, tải trình trích xuất tính năng MobileNet V2 đã được đào tạo trước. Và cấu hình nó như một lớp trong một Mô hình máy ảnh. Mô hình MobileNet này được đào tạo trên một tập dữ liệu lớn và có thể được sử dụng để trích xuất các đặc điểm từ hình ảnh. Bây giờ, hãy tạo một lớp máy ảnh bằng trình trích xuất tính năng MobileNet V2. Ở đây, chỉ định input_shape là (224, 224, 3). Điều này chỉ ra rằng mô hình mong đợi hình ảnh đầu vào có kích thước 224×224 pixel và ba kênh màu (RGB). Đặt thuộc tính có thể huấn luyện của lớp này thành Sai. Việc làm này cho thấy rằng bạn không muốn tinh chỉnh mô hình MobileNet V2 đã được đào tạo trước trong quá trình đào tạo của mình. Nhưng bạn có thể thêm các lớp tùy chỉnh của mình lên trên nó.
feature_extractor = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor_layer = hub.KerasLayer(feature_extractor, input_shape=(224,224,3))
feature_extractor_layer.trainable = FalseXây dựng mô hình
Đã đến lúc xây dựng mô hình TensorFlow Keras Sequential bằng cách thêm các lớp vào lớp trích xuất tính năng MobileNet V2. Đối với feature_extractor_layer, chúng tôi sẽ thêm một lớp bỏ học. Chúng tôi sẽ đặt tỷ lệ bỏ học là 0.5 ở đây. Phương pháp chính quy hóa này là những gì chúng tôi làm để tránh trang bị quá mức. Trong quá trình đào tạo, nếu tỷ lệ bỏ học được đặt thành 0.5, mô hình sẽ giảm trung bình 50% số đơn vị. Sau đó, chúng tôi thêm một lớp dày đặc với ba đơn vị đầu ra và trong bước này, chúng tôi sử dụng chức năng kích hoạt 'softmax'. 'Softmax' là hàm kích hoạt được sử dụng rộng rãi để giải các bài toán phân loại nhiều lớp. Nó tính toán phân bố xác suất trên mỗi lớp của hình ảnh đầu vào (Đá, Giấy, Kéo). Sau đó, in bản tóm tắt của mô hình.
model = tf.keras.Sequential([ feature_extractor_layer, tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(3,activation='softmax')
]) model.summary()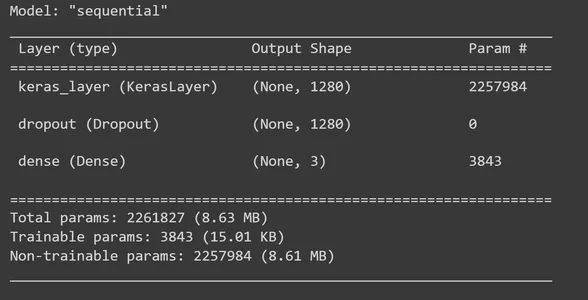
Đã đến lúc biên dịch mô hình của chúng tôi. Để làm điều này, chúng tôi sử dụng trình tối ưu hóa Adam và hàm mất C.ategoricalCrossentropy. Đối số from_logits=True chỉ ra rằng đầu ra của mô hình của bạn tạo ra nhật ký thô (điểm không chuẩn hóa) thay vì phân phối xác suất. Để theo dõi trong quá trình đào tạo, chúng tôi sử dụng các số liệu về độ chính xác.
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True), metrics=['acc'])Các chức năng được gọi là gọi lại có thể được thực thi ở các giai đoạn đào tạo khác nhau, bao gồm cả khi kết thúc mỗi đợt hoặc kỷ nguyên. Trong ngữ cảnh này, chúng tôi xác định lệnh gọi lại tùy chỉnh trong TensorFlow Keras với mục đích thu thập và ghi lại các giá trị mất mát và độ chính xác ở cấp lô trong quá trình đào tạo.
class CollectBatchStats(tf.keras.callbacks.Callback): def __init__(self): self.batch_losses = [] self.batch_acc = [] def on_train_batch_end(self, batch, logs=None): self.batch_losses.append(logs['loss']) self.batch_acc.append(logs['acc']) self.model.reset_metrics()Bây giờ, tạo một đối tượng của lớp đã tạo. Sau đó, huấn luyện mô hình bằng phương thức fit_generator. Để làm được điều này, chúng ta cần cung cấp các thông số cần thiết. Chúng tôi cần một tập dữ liệu huấn luyện đề cập đến số lượng kỷ nguyên cần huấn luyện, tập dữ liệu xác thực và đặt lệnh gọi lại.
batch_stats_callback = CollectBatchStats() history = model.fit_generator(train_dataset, epochs=5, validation_data=val_dataset, callbacks = [batch_stats_callback])Hình dung
Sử dụng matplotlib, vẽ biểu đồ tổn thất đào tạo qua các bước đào tạo bằng cách sử dụng dữ liệu được thu thập bởi lệnh gọi lại CollectBatchStats. Chúng ta có thể quan sát mức độ tổn thất được tối ưu hóa như thế nào tại hiện trường khi quá trình đào tạo diễn ra.
plt.figure()
plt.ylabel("Loss")
plt.xlabel("Training Steps")
plt.ylim([0,2])
plt.plot(batch_stats_callback.batch_losses)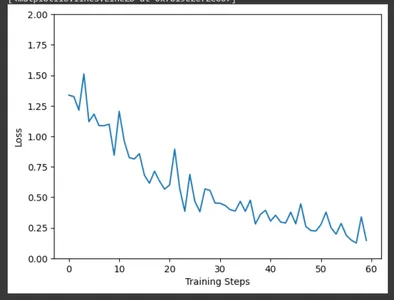
Tương tự, vẽ đồ thị chính xác qua các bước huấn luyện. Ở đây cũng vậy, chúng ta có thể quan sát sự gia tăng độ chính xác khi quá trình đào tạo tiến triển.
plt.figure()
plt.ylabel("Accuracy")
plt.xlabel("Training Steps")
plt.ylim([0,1])
plt.plot(batch_stats_callback.batch_acc)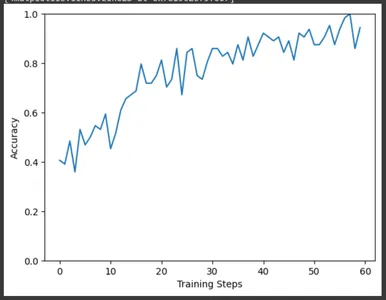
Đánh giá và kết quả
Đã đến lúc đánh giá mô hình của chúng tôi bằng cách sử dụng tập dữ liệu thử nghiệm. Biến kết quả sẽ chứa các kết quả đánh giá, bao gồm mất kiểm tra và bất kỳ số liệu nào khác mà bạn đã xác định trong quá trình biên dịch mô hình. Trích xuất độ mất kiểm tra và độ chính xác kiểm tra từ mảng kết quả và in chúng. Chúng tôi sẽ bị mất 0.14 và độ chính xác khoảng 96% cho mô hình của chúng tôi.
result=model.evaluate(test_dataset)
test_loss = result[0] # Test loss
test_accuracy = result[1] # Test accuracy
print(f"Test Loss: {test_loss}")
print(f"Test Accuracy: {test_accuracy}") #Test Loss: 0.14874716103076935
#Test Accuracy: 0.9674999713897705
Cùng xem dự đoán qua một số hình ảnh thử nghiệm nhé. Vòng lặp này lặp qua mười mẫu đầu tiên trong tập dữ liệu rsp_test. Áp dụng chức năng chia tỷ lệ để xử lý trước hình ảnh và nhãn. Chúng tôi thực hiện chia tỷ lệ hình ảnh và mã hóa một lần của thương hiệu. Nó sẽ in nhãn thực tế (được chuyển đổi từ định dạng được mã hóa một lần) và nhãn được dự đoán (dựa trên lớp có xác suất cao nhất trong các dự đoán).
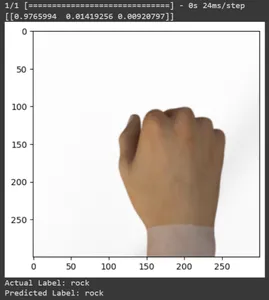
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])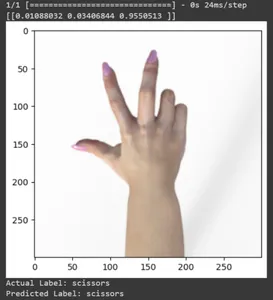
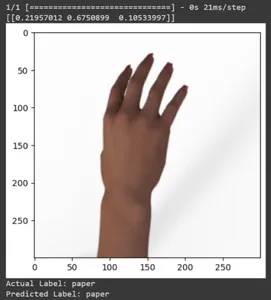
Hãy in dự đoán của tất cả các hình ảnh thử nghiệm. Nó sẽ tạo dự báo cho toàn bộ tập dữ liệu thử nghiệm bằng mô hình TensorFlow Keras đã được huấn luyện của bạn, sau đó trích xuất nhãn lớp (chỉ số lớp) có xác suất cao nhất cho mỗi dự đoán.
np.argmax(model.predict(test_dataset),axis=1)In ma trận nhầm lẫn cho các dự đoán của mô hình. Ma trận nhầm lẫn cung cấp thông tin phân tích chi tiết về cách các dự đoán của mô hình phù hợp với các nhãn. Đây là một công cụ có giá trị để đánh giá hiệu suất của mô hình phân loại. Nó cung cấp cho mỗi lớp kết quả dương tính thật, âm tính thật và dương tính giả.
for f0,f1 in rsp_test.map(scale).batch(400): y=np.argmax(f1, axis=1) y_pred=np.argmax(model.predict(f0),axis=1) print(tf.math.confusion_matrix(labels=y, predictions=y_pred, num_classes=3)) #Output tf.Tensor(
[[142 3 0] [ 1 131 1] [ 0 1 121]], shape=(3, 3), dtype=int32) Lưu và tải mô hình đã đào tạo
Lưu mô hình được đào tạo. Để khi cần sử dụng mô hình, bạn không phải dạy lại mọi thứ từ đầu. Bạn phải tải mô hình và sử dụng nó để dự đoán.
model.save('./path/', save_format='tf')Hãy kiểm tra mô hình bằng cách tải nó.
loaded_model = tf.keras.models.load_model('path')Tương tự, giống như chúng ta đã làm trước đó, hãy kiểm tra mô hình với một số hình ảnh mẫu trong tập dữ liệu thử nghiệm.
for test_sample in rsp_test.take(10): image, label = test_sample[0], test_sample[1] image_scaled, label_arr= scale(test_sample[0], test_sample[1]) image_scaled = np.expand_dims(image_scaled, axis=0) img = tf.keras.preprocessing.image.img_to_array(image) pred=loaded_model.predict(image_scaled) print(pred) plt.figure() plt.imshow(image) plt.show() print("Actual Label: %s" % info.features["label"].names[label.numpy()]) print("Predicted Label: %s" % info.features["label"].names[np.argmax(pred)])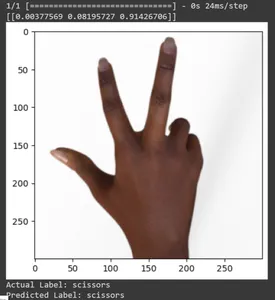
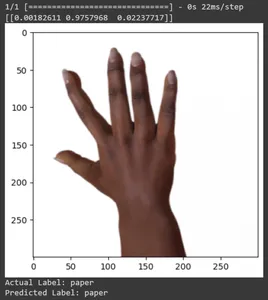
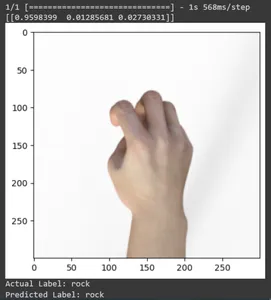
Kết luận
Trong bài viết này, chúng tôi đã áp dụng phương pháp học chuyển giao cho nhiệm vụ phân loại Rock-Paper-Scissors. Chúng tôi đã sử dụng mô hình Mobilenet V2 đã được đào tạo trước cho nhiệm vụ này. Mô hình của chúng tôi đang hoạt động thành công với độ chính xác khoảng 96%. Trong các hình ảnh dự đoán, chúng ta có thể thấy mô hình của chúng ta dự đoán tốt đến mức nào. Ba bức ảnh cuối cùng cho thấy nó hoàn hảo đến mức nào, ngay cả khi tư thế tay không hoàn hảo. Để tượng trưng cho “cái kéo”, hãy mở ba ngón tay thay vì sử dụng cấu hình hai ngón tay. Đối với “Rock”, đừng nắm chặt hoàn toàn nắm tay. Tuy nhiên, mô hình của chúng tôi vẫn có thể hiểu lớp tương ứng và dự đoán một cách hoàn hảo.
Chìa khóa chính
- Học chuyển giao là tất cả về việc chuyển giao kiến thức. Kiến thức thu được trong nhiệm vụ trước sẽ được sử dụng để học một công việc mới.
- Học chuyển giao có tiềm năng cách mạng hóa lĩnh vực học máy. Nó cung cấp một số lợi ích, bao gồm học tập tăng tốc và hiệu suất được cải thiện.
- Học chuyển giao thúc đẩy việc học tập liên tục, trong đó các mô hình có thể thay đổi theo thời gian để xử lý thông tin, nhiệm vụ hoặc môi trường mới.
- Đó là một phương pháp linh hoạt và hiệu quả giúp nâng cao hiệu quả và hiệu quả của các mô hình học máy.
- Trong bài viết này, chúng ta đã tìm hiểu tất cả về học chuyển tiếp, lợi ích và ứng dụng của nó. Chúng tôi cũng đã triển khai bằng cách sử dụng mô hình được đào tạo trước trên tập dữ liệu mới để thực hiện nhiệm vụ phân loại oẳn tù tì.
Những câu hỏi thường gặp (FAQs)
A. Học chuyển tiếp là sự cải thiện việc học trong một nhiệm vụ mới thông qua việc chuyển giao kiến thức từ một bài học liên quan đã được khám phá. Kỹ thuật này cho phép các thuật toán ghi nhớ công việc mới bằng cách sử dụng các mô hình được đào tạo trước.
A. Bạn có thể điều chỉnh dự án này cho phù hợp với các tác vụ phân loại hình ảnh khác bằng cách thay thế tập dữ liệu Rock-Paper-Scissors bằng tập dữ liệu của bạn. Ngoài ra, bạn còn phải tinh chỉnh mô hình theo yêu cầu của công việc mới.
A. MobileNet V2 là mô hình trích xuất tính năng được đào tạo trước có sẵn trong TensorFlow Hub. Trong các kịch bản học chuyển giao, những người thực hành thường sử dụng MobileNetV2 làm công cụ trích xuất tính năng. Họ tinh chỉnh mô hình MobileNetV2 được đào tạo trước cho một nhiệm vụ cụ thể bằng cách kết hợp các lớp dành riêng cho nhiệm vụ trên đó. Cách tiếp cận của ông cho phép đào tạo nhanh chóng và hiệu quả về các nhiệm vụ thị giác máy tính khác nhau.
A. TensorFlow là một khung máy học nguồn mở được phát triển bởi Google. Được sử dụng rộng rãi để xây dựng và đào tạo các mô hình học máy và mô hình học tập cường độ cao.
A. Tinh chỉnh là một kỹ thuật học chuyển giao được chia sẻ, trong đó bạn lấy một mô hình được đào tạo trước và đào tạo thêm về nhiệm vụ cụ thể của mình với tỷ lệ học tập thấp hơn. Điều này cho phép mô hình điều chỉnh kiến thức của nó phù hợp với các sắc thái của nhiệm vụ mục tiêu.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/10/transfer-learning-a-rock-paper-scissors-case-study/

