Giới thiệu
Phân tích và trực quan hóa dữ liệu là những công cụ mạnh mẽ cho phép chúng ta hiểu các tập dữ liệu phức tạp và truyền đạt thông tin chi tiết một cách hiệu quả. Trong cuộc khám phá sâu sắc về dữ liệu xung đột trong thế giới thực này, chúng tôi đi sâu vào thực tế nghiệt ngã và sự phức tạp của các xung đột. Trọng tâm của chúng tôi là Manipur, một bang ở phía đông bắc Ấn Độ, không may bị tàn phá bởi bạo lực và bất ổn kéo dài. Sử dụng Dự án dữ liệu sự kiện và địa điểm xung đột vũ trang (ACLED) [1], chúng tôi bắt tay vào hành trình phân tích dữ liệu chuyên sâu để khám phá bản chất nhiều mặt của các xung đột.
Mục tiêu học tập
- Đạt được trình độ thành thạo về kỹ thuật phân tích dữ liệu cho bộ dữ liệu ACLED.
- Phát triển kỹ năng trực quan hóa dữ liệu hiệu quả để giao tiếp.
- Hiểu tác động của bạo lực đối với nhóm dân số dễ bị tổn thương.
- Có được cái nhìn sâu sắc về các khía cạnh thời gian và không gian của các cuộc xung đột.
- Hỗ trợ các phương pháp tiếp cận dựa trên bằng chứng để giải quyết các nhu cầu nhân đạo.
Bài báo này đã được xuất bản như một phần của Blogathon Khoa học Dữ liệu.
Mục lục
Xung đột lợi ích
Không có tổ chức hoặc tổ chức cụ thể nào chịu trách nhiệm về việc phân tích và giải thích được trình bày trong blog này. Mục đích hoàn toàn là để thể hiện tiềm năng của khoa học dữ liệu trong phân tích xung đột. Hơn nữa, không có lợi ích hoặc thành kiến cá nhân nào liên quan đến những phát hiện này, đảm bảo một cách tiếp cận khách quan để hiểu các động lực xung đột. Thúc đẩy việc sử dụng các phương pháp dựa trên dữ liệu như một công cụ để nâng cao hiểu biết sâu sắc và cung cấp thông tin cho các cuộc thảo luận rộng hơn về phân tích xung đột.
Thực hiện
Tại sao tập dữ liệu ACLED?
Bằng cách tận dụng sức mạnh của kỹ thuật khoa học dữ liệu trên tập dữ liệu ACLED. Chúng tôi có thể rút ra những hiểu biết sâu sắc không chỉ góp phần hiểu rõ tình hình ở Manipur mà còn làm sáng tỏ các khía cạnh nhân đạo liên quan đến bạo lực. Các Sách mã ACLED là hướng dẫn tham khảo toàn diện cung cấp thông tin chi tiết về sơ đồ mã hóa và các biến được sử dụng trong bộ dữ liệu này [2].
Tầm quan trọng của ACLED nằm ở khả năng phân tích dữ liệu đồng cảm, giúp nâng cao hiểu biết của chúng ta về bạo lực ở Manipur, làm sáng tỏ các nhu cầu nhân đạo và góp phần giải quyết và giảm thiểu bạo lực. Nó thúc đẩy một tương lai hòa bình và hòa nhập cho các cộng đồng bị ảnh hưởng.
Thông qua phân tích dựa trên dữ liệu này, chúng tôi không chỉ có thể làm sáng tỏ những hiểu biết sâu sắc có giá trị mà còn có thể nêu bật cái giá phải trả về con người do bạo lực ở Manipur. Bằng cách xem xét kỹ lưỡng dữ liệu ACLED, tôi hy vọng chúng ta có thể làm sáng tỏ tác động đối với dân thường, tình trạng di dời bắt buộc và khả năng tiếp cận các dịch vụ thiết yếu, từ đó vẽ nên một bức tranh toàn diện về thực tế nhân đạo phải đối mặt trong khu vực.
Sự kiện xung đột
Bước đầu tiên, chúng ta sẽ khám phá các sự kiện xung đột ở Manipur bằng cách sử dụng bộ dữ liệu ACLED. Đoạn mã dưới đây đọc tập dữ liệu ACLED cho Ấn Độ và lọc dữ liệu cụ thể cho Manipur, dẫn đến tập dữ liệu được lọc có hình dạng (số hàng, số cột). Hình dạng của dữ liệu được lọc sau đó sẽ được in.
import pandas as pd #import country specific csv downloaded from acleddata.com file_path = './acled_India.csv' all_data = pd.read_csv(file_path) # Filter the data for Manipur df_filtered = all_data.loc[all_data['admin1'] == "Manipur"] shape = df_filtered.shape print("Filtered Data Shape:", shape) #Output: #Filtered Data Shape: (4495, 31)Số lượng hàng trong dữ liệu ACLED thể hiện số lượng sự kiện hoặc sự cố riêng lẻ được ghi lại trong tập dữ liệu. Mỗi hàng thường tương ứng với một sự kiện cụ thể, chẳng hạn như xảy ra xung đột, biểu tình hoặc bạo lực và chứa nhiều thuộc tính hoặc cột khác nhau cung cấp thông tin về sự kiện, chẳng hạn như địa điểm, ngày tháng, các bên tham gia và các chi tiết liên quan khác.
Bằng cách đếm số hàng trong tập dữ liệu ACLED, bạn có thể xác định tổng số sự kiện hoặc sự cố được ghi lại trong dữ liệu. Bằng cách lọc tập dữ liệu dành riêng cho Manipur, chúng tôi đã thu được tập dữ liệu đã lọc chứa thông tin về các sự kiện hoặc sự cố riêng lẻ được ghi lại từ tháng 2016 năm 9 đến ngày 2023 tháng 4495 năm XNUMX. Tổng số sự kiện hoặc sự cố được ghi lại ở Manipur là XNUMX hàng, cung cấp thông tin chi tiết về phạm vi và quy mô của xung đột hoặc các sự kiện được ACLED theo dõi.
Bước tiếp theo, chúng tôi tính tổng các giá trị null dọc theo các cột (trục=0) trong DataFrame df_filtered. Nó cung cấp thông tin chi tiết về số lượng giá trị bị thiếu trong mỗi cột của tập dữ liệu được lọc.
df_filtered.isnull().sum(axis = 0) # Output: count of null values in each column
# event_id_cnty: 0 null values
# event_date: 0 null values
# year: 0 null values
# time_precision: 0 null values
# disorder_type: 0 null values
# event_type: 0 null values
# sub_event_type: 0 null values
# actor1: 0 null values
# assoc_actor_1: 1887 null values
# inter1: 0 null values
# actor2: 3342 null values
# assoc_actor_2: 4140 null values
# inter2: 0 null values
# interaction: 0 null values
# civilian_targeting: 4153 null values
# iso: 0 null values
# region: 0 null values
# country: 0 null values
# admin1: 0 null values
# admin2: 0 null values
# admin3: 0 null values
# location: 0 null values
# latitude: 0 null values
# longitude: 0 null values
# geo_precision: 0 null values
# source: 0 null values
# source_scale: 0 null values
# notes: 0 null values
# fatalities: 0 null values
# tags: 1699 null values
# timestamp: 0 null valuesĐoạn mã bên dưới xuất ra số lượng giá trị duy nhất trong mỗi cột.
n = df_filtered.nunique(axis=0) print("No.of.unique values in each column:n", n) # Output:
# No.of.unique values in each column:
# event_id_cnty: 4495
# event_date: 1695
# year: 8
# time_precision: 3
# disorder_type: 4
# event_type: 6
# sub_event_type: 17
# actor1: 66
# assoc_actor_1: 323
# inter1: 8
# actor2: 61
# assoc_actor_2: 122
# inter2: 9
# interaction: 28
# civilian_targeting: 1
# iso: 1
# region: 1
# country: 1
# admin1: 1
# admin2: 16
# admin3: 37
# location: 495
# latitude: 485
# longitude: 480
# geo_precision: 3
# source: 233
# source_scale: 12
# notes: 4462
# fatalities: 10
# tags: 97
# timestamp: 1070
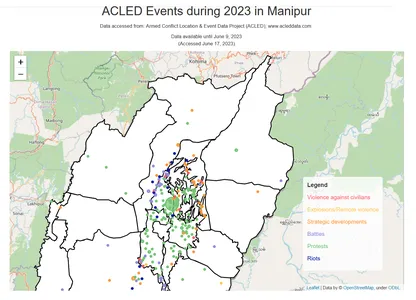
Bản đồ tương tác sử dụng thư viện Folium để trực quan hóa các sự kiện ACLED
Về mặt địa lý, Manipur được chia thành hai vùng riêng biệt: vùng thung lũng và vùng đồi núi. Vùng thung lũng nằm ở trung tâm Manipur, tương đối bằng phẳng và được bao quanh bởi những ngọn đồi. Đây là khu vực đông dân nhất và sản xuất nông nghiệp nhất của bang. Mặt khác, vùng đồi núi bao gồm các ngọn đồi và núi xung quanh, mang lại địa hình đồi núi hiểm trở hơn.
Mã dưới đây tạo một bản đồ tương tác bằng thư viện Folium để trực quan hóa các sự kiện ACLED xảy ra ở Manipur trong những năm 2022 và 2023. Nó vẽ các sự kiện dưới dạng các điểm đánh dấu vòng tròn trên bản đồ, với mỗi màu của điểm đánh dấu đại diện cho năm tương ứng. Nó cũng thêm một lớp GeoJSON để hiển thị ranh giới của Manipur và bao gồm tiêu đề bản đồ, phần ghi công và chú giải cho biết mã màu của các năm. Bản đồ cuối cùng được hiển thị với tất cả các yếu tố này.
import folium # Filter the data for the years 2022 and 2023 df_filtered22_23 = df_filtered[(df_filtered['year'] == 2022) | (df_filtered['year'] == 2023)] # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file manipur_geojson = 'Manipur.geojson' # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define color palette for different years color_palette = {2022: 'red', 2023: 'blue'} # Plot the events on the map with different colors based on the year for index, row in df_filtered22_23.iterrows(): folium.CircleMarker([row['latitude'], row['longitude']], radius=3, color=color_palette[row['year']], fill=True, fill_color=color_palette[row['year']], fill_opacity=0.5).add_to(map) # Add map features folium.TileLayer('cartodbpositron').add_to(map) # Set the map's center and zoom level map.fit_bounds(map.get_bounds()) map.get_root().html.add_child(folium.Element(legend_html)) # Display the map mapĐầu ra:
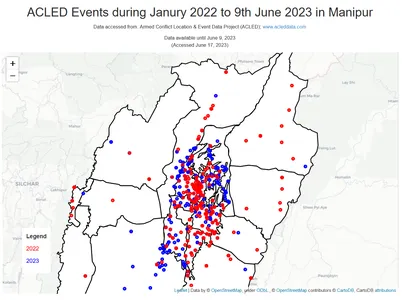
Bạn có thể thấy rằng, các sự kiện tập trung nhiều hơn ở khu vực thung lũng trung tâm. Điều này có thể là do các yếu tố khác nhau như mật độ dân số, cơ sở hạ tầng, khả năng tiếp cận và động lực chính trị xã hội lịch sử. Khu vực thung lũng trung tâm, nơi có mật độ dân cư đông đúc hơn và kinh tế phát triển hơn, có khả năng chứng kiến nhiều sự cố và sự kiện hơn so với khu vực đồi núi.
Các loại sự kiện ACLED
ACLED event_type đề cập đến việc phân loại các loại sự kiện khác nhau được ghi lại trong bộ dữ liệu ACLED. Những loại sự kiện này ghi lại các hoạt động và sự cố khác nhau liên quan đến xung đột, bạo lực, biểu tình và các sự kiện được quan tâm khác. Một số loại sự kiện trong bộ dữ liệu ACLED bao gồm bạo lực chống lại dân thường, vụ nổ/bạo lực từ xa, biểu tình, bạo loạn, v.v. Những loại sự kiện này cung cấp cái nhìn sâu sắc về bản chất và động lực của các xung đột và sự cố liên quan được ghi lại trong cơ sở dữ liệu ACLED.
Mã bên dưới tạo biểu đồ thanh với các sự kiện được nhóm theo năm, trực quan hóa các loại sự kiện ở Manipur, Ấn Độ trong những năm qua.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Đầu ra:
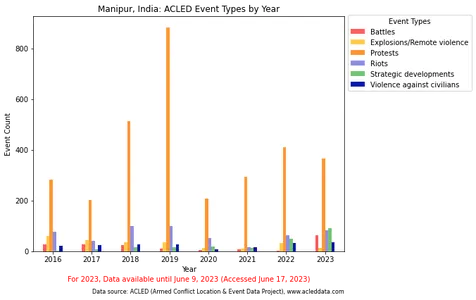
Đáng chú ý, việc hiển thị trực quan các loại sự kiện trong biểu đồ thanh đã làm nổi bật sự thống trị của danh mục “Biểu tình”, điều này có thể che khuất sự khác biệt tương đối và khiến việc so sánh chính xác các loại sự kiện khác trở nên khó khăn. Hình ảnh trực quan đã được điều chỉnh bằng cách loại trừ hoặc tách danh mục “Biểu tình”, dẫn đến so sánh rõ ràng hơn về các loại sự kiện còn lại.
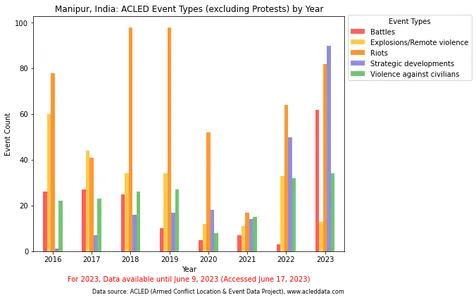
Đoạn mã bên dưới lọc loại sự kiện “Biểu tình” khỏi dữ liệu. Sau đó, nó nhóm các sự kiện còn lại theo năm và hiển thị chúng trong biểu đồ thanh, loại trừ danh mục “Biểu tình” chiếm ưu thế. Hình ảnh trực quan thu được cung cấp cái nhìn rõ ràng hơn về các loại sự kiện theo năm.
import pandas as pd import matplotlib.pyplot as plt df_filteredevent = df_filtered.copy() df_filteredevent['event_date'] = pd.to_datetime(df_filteredevent['event_date']) # Filter out the "Protests" event type df_filteredevent = df_filteredevent[df_filteredevent['event_type'] != 'Protests'] # Group the data by year df_cross_event = df_filteredevent.groupby(df_filteredevent['event_date'].dt.year)
['event_type'].value_counts().unstack() # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the bar chart fig, ax = plt.subplots(figsize=(10, 6)) df_cross_event.plot.bar(ax=ax, color=color_palette) # Set the x-axis tick labels to display only the year ax.set_xticklabels(df_cross_event.index, rotation=0) # Set the legend ax.legend(title='Event Types', bbox_to_anchor=(1, 1.02), loc='upper left') # Set the axis labels and title ax.set_xlabel('Year') ax.set_ylabel('Event Count') ax.set_title('Manipur, India: ACLED Event Types (excluding Protests) by Year') # Adjust the padding and layout plt.tight_layout(rect=[0, 0, 0.95, 1]) # Display the plot plt.show()Đầu ra:
Trực quan hóa Động lực sự kiện: Ánh xạ các loại và tần suất sự kiện
Chúng tôi sử dụng bản đồ tương tác để vẽ các sự kiện trên bản đồ với kích thước và màu sắc điểm đánh dấu khác nhau dựa trên loại và tần suất sự kiện. Nó thể hiện sự phân bố không gian và cường độ của các sự kiện khác nhau, cho phép xác định nhanh chóng các mô hình, điểm nóng và xu hướng. Cách tiếp cận này tăng cường tính năng động về mặt địa lý của các sự kiện, tạo điều kiện thuận lợi cho việc ra quyết định dựa trên dữ liệu và cho phép phân bổ nguồn lực hiệu quả và các biện pháp can thiệp có mục tiêu để đáp ứng với các mô hình và tần suất đã xác định.
Các sự kiện được vẽ dưới dạng điểm đánh dấu vòng tròn trên bản đồ, với màu sắc và kích thước khác nhau dựa trên loại sự kiện và tần suất tương ứng.
import folium import json # Filter the data for the year 2023 df_filtered23 = df_filtered[df_filtered['year'] == 2023] # Calculate the event count for each location event_counts = df_filtered23.groupby(['latitude', 'longitude']).size().
reset_index(name='count') # Create a map instance map = folium.Map(location=[24.8170, 93.9368], zoom_start=8) # Load Manipur boundaries from GeoJSON file with open('Manipur.geojson') as f: manipur_geojson = json.load(f) # Create a GeoJSON layer for Manipur boundaries and add it to the map folium.GeoJson(manipur_geojson, style_function=lambda feature: { 'fillColor': 'white', 'color': 'black', 'weight': 2, 'fillOpacity': 1 }).add_to(map) # Define a custom color palette inspired by ACLED thematic categories event_type_palette = { 'Violence against civilians': '#FF5C5C', # Dark orange 'Explosions/Remote violence': '#FFC94C', # Bright yellow 'Strategic developments': '#FF9633', # Light orange 'Battles': '#8E8EE1', # Purple 'Protests': '#72C472', # Green 'Riots': '#0818A8' # Zaffre } # Plot the events on the map with varying marker size and color based on # the event type and frequency for index, row in event_counts.iterrows(): location = (row['latitude'], row['longitude']) count = row['count'] # Get the event type for the current location event_type = df_filtered23[(df_filtered23['latitude'] == row['latitude']) & (df_filtered23['longitude'] == row['longitude'])] ['event_type'].values[0] folium.CircleMarker( location=location, radius=2 + count * 0.1, color=event_type_palette[event_type], fill=True, fill_color=event_type_palette[event_type], fill_opacity=0.7 ).add_to(map) # Add legends for the year 2023 legend_html = """ <div style="position: fixed; bottom: 50px; right: 50px; z-index: 1000; font-size: 14px; background-color: rgba(255, 255, 255, 0.8); padding: 10px; border-radius: 5px;"> <p><strong>Legend</strong></p> <p><span style="color: #FF5C5C;">Violence against civilians</span></p> <p><span style="color: #FFC94C;">Explosions/Remote violence</span></p> <p><span style="color: #FF9633;">Strategic developments</span></p> <p><span style="color: #8E8EE1;">Battles</span></p> <p><span style="color: #72C472;">Protests</span></p> <p><span style="color: #0818A8;">Riots</span></p> </div> """ map.get_root().html.add_child(folium.Element(legend_html)) # Display the map map Đầu ra:
Các tác nhân chính của xung đột
Trong bước này, chúng tôi hiểu rõ hơn về các thực thể hoặc nhóm khác nhau liên quan đến cuộc xung đột hoặc sự kiện ở Manipur. Trong tập dữ liệu ACLED, “diễn viên1” đề cập đến tác nhân chính tham gia vào một sự kiện được ghi lại. Nó đại diện cho thực thể hoặc nhóm chính chịu trách nhiệm khởi xướng hoặc tham gia vào một xung đột hoặc sự kiện cụ thể. Cột “diễn viên1” cung cấp thông tin về danh tính của tác nhân chính, chẳng hạn như chính phủ, nhóm nổi dậy, dân quân dân tộc hoặc các thực thể khác liên quan đến xung đột hoặc sự kiện. Mỗi giá trị duy nhất trong cột “actor1” đại diện cho một tác nhân hoặc nhóm riêng biệt liên quan đến các sự kiện được ghi lại.
Sau đó, trực quan hóa số lượng giá trị của 'actor1' bằng đoạn mã bên dưới:
Mã này lọc DataFrame dựa trên số lượng giá trị của cột 'actor1', chỉ chọn những giá trị có số lượng lớn hơn hoặc bằng 5. Sau đó, mã này sẽ hiển thị dữ liệu kết quả.
import matplotlib.pyplot as plt # Filter the DataFrame based on value counts >= 5 filtered_df = df_filtered[(df_filtered['year'] != 2023)]['actor1'].
value_counts().loc[lambda x: x >= 5] # Create a figure and axes for the horizontal bar chart fig, ax = plt.subplots(figsize=(8, 6)) # Define the color palette color_palette = ['#FF5C5C', '#FFC94C', '#FF9633', '#8E8EE1', '#72C472', '#0818A8'] # Plot the horizontal bar chart filtered_df.plot.barh(ax=ax, color=color_palette) # Add labels and title ax.set_xlabel('Count') ax.set_ylabel('Actor1') ax.set_title('Value Counts of Actor1 (>= 5) (January 2016 to 9th December 2022)', pad=55) # Set the data availability information data_info = "Accessed on June 17, 2023" # Add credits and data availability information plt.text(0.5, 1.1, "Data accessed from:", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.05, "Armed Conflict Location & Event Data Project (ACLED); www.acleddata.com", ha='center', transform=ax.transAxes, fontsize=10) plt.text(0.5, 1.0, data_info, ha='center', transform=ax.transAxes, fontsize=10) # Display the count next to each bar for i, v in enumerate(filtered_df.values): ax.text(v + 3, i, str(v), color='black') # Display the plots plt.tight_layout() plt.show() Đầu ra:
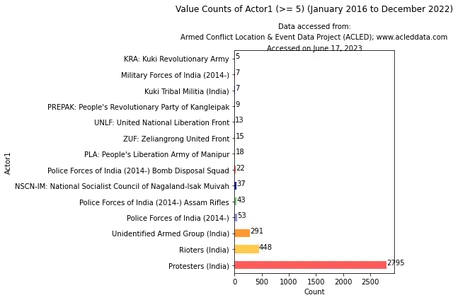
Biểu đồ thể hiện dữ liệu từ tháng 2016 năm 9 đến ngày 2022 tháng 5 năm 5. Ngoài ra, điều kiện “số lượng lớn hơn hoặc bằng XNUMX” có nghĩa là chỉ những tác nhân có tần suất xuất hiện từ XNUMX trở lên mới được đưa vào phân tích và hiển thị trong biểu đồ .
Như được hiển thị trong đoạn mã bên dưới, chúng tôi sử dụng các hình ảnh trực quan sau đây để so sánh số lượng danh mục trong khoảng thời gian từ năm 2022 đến năm 2023.
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip
(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Adjust the spacing between lines plt.subplots_adjust(top=0.9) # Display the plot plt.show()Đầu ra:
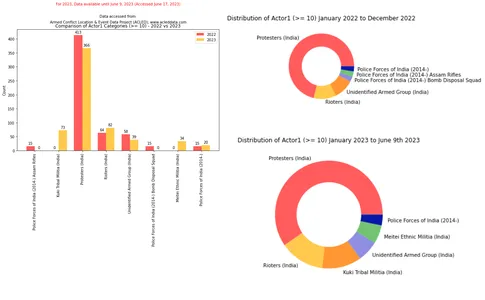
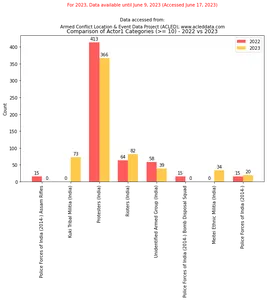
Bạn có thể so sánh dữ liệu ACLED của Manipur cho năm 2022 và dữ liệu cho đến ngày 9 tháng 2023 năm XNUMX bằng cách sử dụng đoạn mã bên dưới:
import matplotlib.pyplot as plt import numpy as np # Filter the DataFrame for the year 2022 filtered_df_2022 = df_filtered[df_filtered['year'] == 2022]['actor1'].
value_counts().loc[lambda x: x >= 10] # Filter the DataFrame for the year 2023 filtered_df_2023 = df_filtered[df_filtered['year'] == 2023]['actor1'].
value_counts().loc[lambda x: x >= 10] # Get the unique categories that appear more than 10 in either DataFrame categories = set(filtered_df_2022.index).union(set(filtered_df_2023.index)) # Create a dictionary to store the category counts category_counts = {'2022': [], '2023': []} # Iterate over the categories for category in categories: # Add the count for 2022 if available, otherwise add 0 category_counts['2022'].append(filtered_df_2022.get(category, 0)) # Add the count for 2023 if available, otherwise add 0 category_counts['2023'].append(filtered_df_2023.get(category, 0)) # Exclude categories with count 0 non_zero_categories = [category for category, count_2022, count_2023 in zip(categories, category_counts['2022'], category_counts['2023']) if count_2022 > 0 or count_2023 > 0] # Create a figure and axes for the bar chart fig, ax = plt.subplots(figsize=(10, 6)) # Set the x-axis positions x = np.arange(len(non_zero_categories)) # Set the width of the bars width = 0.35 # Plot the bar chart for 2022 bars_2022 = ax.bar(x - width/2, category_counts['2022'], width, color=color_palette[0], label='2022') # Plot the bar chart for 2023 bars_2023 = ax.bar(x + width/2, category_counts['2023'], width, color=color_palette[1], label='2023') # Set the x-axis tick labels and rotate them for better visibility ax.set_xticks(x) ax.set_xticklabels(non_zero_categories, rotation=90) # Set the y-axis label ax.set_ylabel('Count') # Set the title and legend ax.set_title('Comparison of Actor1 Categories (>= 10) - 2022 vs 2023') ax.legend() # Add count values above each bar for rect in bars_2022 + bars_2023: height = rect.get_height() ax.annotate(f'{height}', xy=(rect.get_x() + rect.get_width() / 2, height), xytext=(0, 3), textcoords="offset points", ha='center', va='bottom') # Display the plot plt.show() Đầu ra:
Phân tích cường độ xung đột
Đoạn mã tiếp theo chuẩn bị dữ liệu để phân tích hoặc hiển thị thêm bằng cách chuyển đổi cột 'event_date' thành datetime. Thực hiện lập bảng chéo và cơ cấu lại DataFrame để tạo điều kiện giải thích và sử dụng dễ dàng hơn. Nó sử dụng hàm pd.crosstab() để tạo bảng chéo (bảng tần số) giữa 'event_date' (được chuyển đổi thành khoảng thời gian hàng tháng bằng cách sử dụng dt.to_ Period('m')) và cột 'inter1' trong 'df_filtered'. Sau đó, nhóm DataFrame đã lọc theo 'event_date' và tính tổng số 'tử vong' cho mỗi ngày. Tính toán và cộng tổng số ca tử vong theo tháng vào DataFrame được lập bảng chéo hiện có, dẫn đến 'df_conflicts'. Nó bao gồm cả dữ liệu sự kiện được phân loại và thông tin tử vong tương ứng để phân tích thêm.
Triển khai mã
import pandas as pd # Convert 'event_date' column to datetime data type df_filtered['event_date'] = pd.to_datetime(df_filtered['event_date']) # Perform the crosstab operation df_cross = pd.crosstab(df_filtered['event_date'].dt.to_period('m'), df_filtered['inter1']) # Rename the columns df_cross.columns = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Convert the period index to date df_cross['event_date'] = df_cross.index.to_timestamp() # Reset the index df_cross.reset_index(drop=True, inplace=True) df2 = df_filtered.copy() df2['event_date'] = pd.to_datetime(df2['event_date']) fatality_filtered = (df2 .filter(['event_date','fatalities']) .groupby(['event_date']) .fatalities .sum() ) df_fatality_filtered = fatality_filtered.to_frame().reset_index() df_fatality_month= df_fatality_filtered.resample('M', on="event_date").sum() df_fatality_month = df_fatality_month.reset_index() df_fatalities = df_fatality_month.drop(columns=['event_date']) df_concat = pd.concat([df_cross, df_fatalities], axis=1) df_conflicts = df_concat.copy() Đầu ra:
Mã trực quan hóa việc phân tích cường độ xung đột cho các sự kiện hàng tháng ở Manipur được phân loại theo loại tác nhân, được tính theo tỷ lệ tử vong được báo cáo. Độ rộng của các đường dựa trên số người tử vong đối với từng loại tác nhân. Kiểu phân tích này cho phép chúng tôi xác định các mô hình và tác động tương đối của các loại tác nhân khác nhau liên quan đến xung đột. Cung cấp những hiểu biết sâu sắc có giá trị để phân tích sâu hơn và ra quyết định trong các nghiên cứu xung đột.
import plotly.graph_objects as go fig = go.Figure() fig.add_trace(go.Scatter( name='State Forces', x=df_conflicts['event_date'].dt.strftime('%Y-%m'), y=df_conflicts['State Forces'], mode='markers+lines', marker=dict(color='darkviolet', size=4), showlegend=True )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']+df_conflicts['fatalities']/5, mode='lines', marker=dict(color="#444"), line=dict(width=1), hoverinfo='skip', showlegend=False )) fig.add_trace(go.Scatter( name='Fatality weight', x=df_conflicts['event_date'], y=df_conflicts['State Forces']-df_conflicts['fatalities']/5, marker=dict(color="#444"), line=dict(width=1), mode='lines', fillcolor='rgba(68, 68, 68, 0.3)', fill='tonexty', hoverinfo='text', hovertemplate='<br>%{x|%bn%Y}<br><i>Fatalities: %{text}</i>', text=['{}'.format(i) for i in df_conflicts['fatalities']], showlegend=False )) #similiray insert add_trace for other event types too here... fig.update_xaxes( dtick="M3", # Set the tick frequency to 3 months (quarterly) tickformat="%bn%Y" ) fig.update_layout( yaxis_title='No: of Events', title={ 'text': 'Conflict Intensity Analysis: Events in Manipur categorized by actor type, weighted by reported fatalities', 'y': 0.95, 'x': 0.5, 'xanchor': 'center', 'yanchor': 'top', 'font': {'size': 20} }, annotations=[ dict( text="January 2016 to June 9th 2023|Data accessed from: Armed Conflict Location & Event Data Project (ACLED),www.acleddata.com", xref="paper", yref="paper", x=0.5, y=1.06, showarrow=False, font={'size': 12} ) ], hovermode="x", xaxis=dict( showgrid=False ), yaxis=dict( showgrid=False ) ) fig.data[0].marker.size = 4 fig.data[3].marker.size = 4 fig.data[6].marker.size = 4 fig.data[9].marker.size = 4 fig.data[12].marker.size = 4 fig.data[15].marker.size = 4 fig.data[18].marker.size = 4 fig.data[21].marker.size = 4 fig.show()Đầu ra:
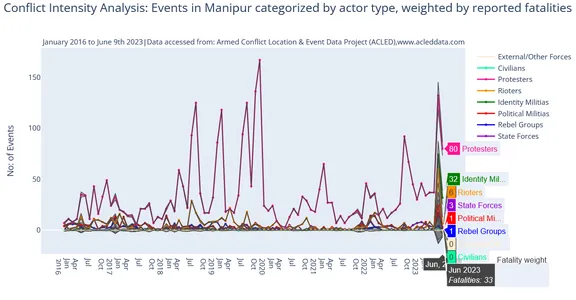
Giá trị biến cao hơn (trong trường hợp này là 'Người biểu tình') so với các biến khác trong biểu đồ nhiều đường. Nó có thể bóp méo nhận thức, gây khó khăn cho việc so sánh và giải thích chính xác xu hướng của các biến số khác nhau. Sự thống trị của một biến có thể giảm đi vì việc đánh giá những thay đổi tương đối và mối quan hệ giữa các biến khác trở nên khó khăn. Hình ảnh trực quan có thể bị ảnh hưởng, với hình ảnh bị nén hoặc lộn xộn, mất chi tiết ở các biến có giá trị thấp hơn và sự nhấn mạnh không cân bằng có thể làm sai lệch cách diễn giải.
Để giảm thiểu những nhược điểm này và có cái nhìn rõ ràng về cường độ xung đột gần đây, chúng tôi đã lọc dữ liệu cho các sự kiện xung đột năm 2023 và 2022 và dưới đây là kết quả đầu ra:
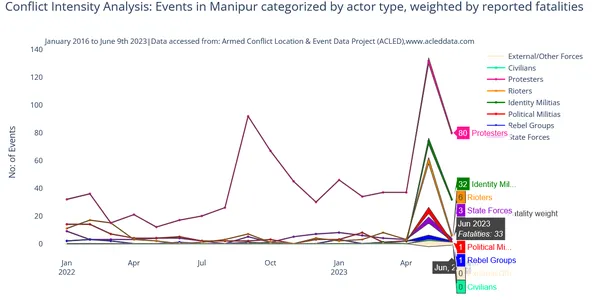
Đặt ngày làm chỉ mục để phân tích xu hướng xung đột bằng cách sử dụng dữ liệu hàng ngày và lấy khung dữ liệu bên dưới để phân tích thêm.
Phân tích xu hướng xung đột và đường trung bình cán
Trong phân tích xu hướng xung đột, khung thời gian luân phiên 30 ngày và 7 ngày là phổ biến. Chúng được sử dụng để tính toán mức trung bình luân phiên hoặc phương tiện dữ liệu liên quan đến xung đột trong một khoảng thời gian cụ thể.
Cửa sổ cuộn đề cập đến một khoảng thời gian có kích thước cố định di chuyển dọc theo dòng thời gian, bao gồm một số điểm dữ liệu được chỉ định trong khoảng đó. Ví dụ: trong khoảng thời gian luân phiên 30 ngày, khoảng thời gian bao gồm ngày hiện tại cộng với 29 ngày trước đó. Trong cửa sổ luân phiên 7 ngày, khoảng thời gian bao gồm ngày hiện tại cộng với 6 ngày trước đó, biểu thị giá trị dữ liệu của một tuần.
Đường trung bình động được tính bằng cách lấy giá trị trung bình của các điểm dữ liệu trong cửa sổ. Nó cung cấp sự trình bày mượt mà của dữ liệu, giảm các biến động ngắn hạn và làm nổi bật các xu hướng dài hạn.
Bằng cách tính toán các phương tiện luân chuyển 30 ngày và 7 ngày trong phân tích xung đột, các nhà phân tích có thể hiểu rõ hơn về mô hình và xu hướng tổng thể của các sự kiện xung đột theo thời gian. Nó có thể xác định các xu hướng dài hạn đồng thời nắm bắt những biến động ngắn hạn của dữ liệu. Những đường trung bình động này có thể giúp tiết lộ các mô hình cơ bản và cung cấp một bức tranh rõ ràng hơn về sự phát triển của động lực xung đột.
Mã Đoạn
Đoạn mã dưới đây tạo ra các sơ đồ cho từng tình huống xung đột.
import matplotlib.pyplot as plt import pandas as pd # Variables to calculate rolling means for variables = ['State Forces', 'Rebel Groups', 'Political Militias', 'Identity Militias', 'Rioters', 'Protesters', 'Civilians', 'External/Other Forces'] # Calculate rolling means for each variable data_7d_rol = {} data_30d_rol = {} for variable in variables: data_7d_rol[variable] = data_ts[variable].rolling(window=7, min_periods=1).mean() data_30d_rol[variable] = data_ts[variable].rolling(window=30, min_periods=1).mean() # Plotting separate graphs for each variable for variable in variables: fig, ax = plt.subplots(figsize=(11, 4)) # Plotting 7-day rolling mean ax.plot(data_ts.index, data_7d_rol[variable], linewidth=2, label='7-d Rolling Mean') # Plotting 30-day rolling mean ax.plot(data_ts.index, data_30d_rol[variable], color='0.2', linewidth=3, label='30-d Rolling Mean') # Beautification of plot ax.legend() ax.set_xlabel('Year') ax.set_ylabel('Events accounted by ' + variable) ax.set_title('Trends in ' + variable + ' Conflicts') # Add main heading and subheading fig.suptitle(main_title, fontsize=14, fontweight='bold', y=1.05) #ax.text(0.5, -0.25, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') ax.text(0.5, 0.95, sub_title, transform=ax.transAxes, fontsize=10, color='red', ha='center') plt.tight_layout() plt.show() Đầu ra:
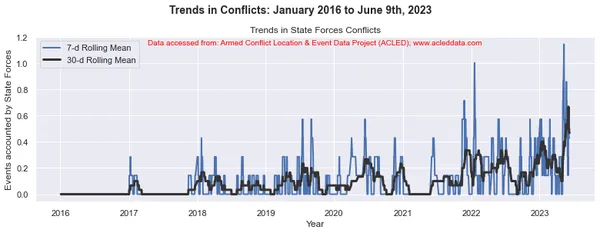
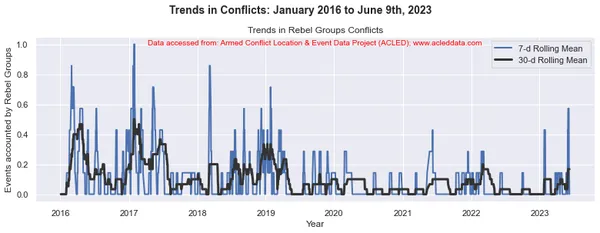
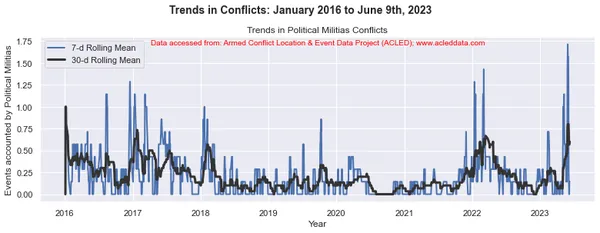
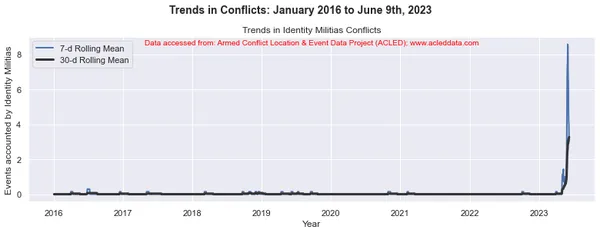

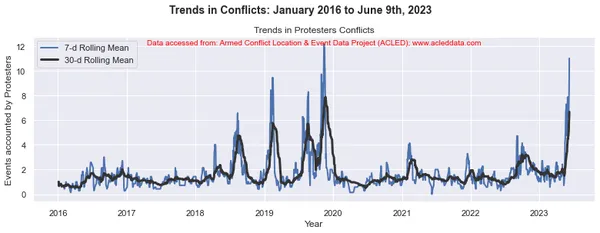
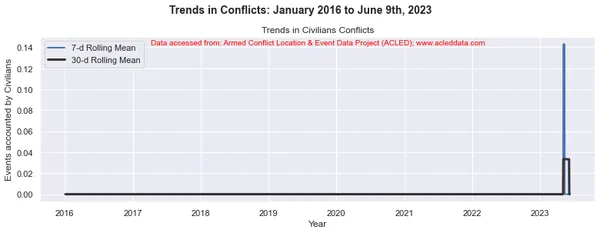
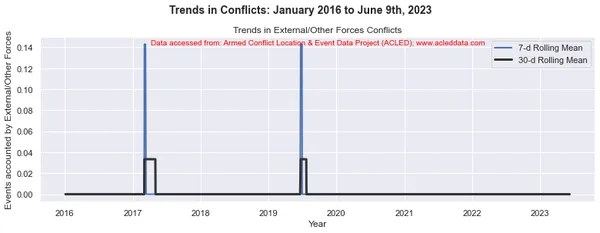
Chú thích: Các sơ đồ được tạo và phân tích dữ liệu được thực hiện trong blog này chỉ nhằm mục đích chứng minh việc áp dụng các kỹ thuật khoa học dữ liệu. Những phân tích này không đưa ra những kết luận hay giải thích dứt khoát về động lực phức tạp của các cuộc xung đột. Tiếp cận phân tích xung đột một cách thận trọng, thừa nhận bản chất nhiều mặt của xung đột và nhu cầu hiểu biết toàn diện và cụ thể về bối cảnh ngoài phạm vi phân tích này.
Kết luận
Blog khám phá các sự kiện và mô hình xung đột ở Manipur, Ấn Độ bằng cách sử dụng phân tích dữ liệu ACLED. Để trực quan hóa các sự kiện ACLED ở Manipur, hãy sử dụng bản đồ tương tác và các hình ảnh trực quan khác. Phân tích các loại sự kiện ở Manipur cho thấy nhiều hoạt động và sự cố khác nhau liên quan đến xung đột, bạo lực, biểu tình và các sự kiện đáng quan tâm khác. Để hiểu xu hướng của các sự kiện xung đột, chúng tôi đã tính toán khoảng thời gian luân chuyển 30 ngày và 7 ngày. Các đường trung bình động này cung cấp sự thể hiện mượt mà của dữ liệu, giảm các biến động ngắn hạn và làm nổi bật các xu hướng dài hạn. Nhìn chung, những phát hiện này có thể góp phần hiểu rõ hơn về động lực xung đột trong khu vực và có thể hỗ trợ quá trình nghiên cứu và ra quyết định sâu hơn.
Chìa khóa chính
- Phân tích dữ liệu ACLED tương tác: Đi sâu vào dữ liệu xung đột trong thế giới thực và hiểu rõ hơn.
- Bản đồ tương tác trực quan hóa động lực không gian và thời gian của các xung đột.
- Nhấn mạnh tầm quan trọng của việc trực quan hóa và phân tích dữ liệu để hiểu hiệu quả.
- Việc xác định các tác nhân chính sẽ tiết lộ các thực thể chính đang định hình bối cảnh xung đột.
- Tính toán trung bình luân phiên phát hiện ra những biến động ngắn hạn và xu hướng dài hạn trong xung đột.
Hy vọng bạn tìm thấy bài viết này thông tin. Hãy liên hệ với tôi trên LinkedIn. Hãy kết nối và hướng tới việc tận dụng dữ liệu để tạo ra thay đổi tích cực.
Những câu hỏi thường gặp
A. Bộ dữ liệu ACLED (Dự án dữ liệu sự kiện và vị trí xung đột vũ trang) là nguồn tài nguyên toàn diện giúp theo dõi và ghi lại thông tin chi tiết về các sự kiện xung đột trên toàn thế giới, bao gồm bạo lực chính trị, biểu tình và bạo loạn. Nó góp phần phân tích các sự kiện xung đột bằng cách cung cấp cho các nhà nghiên cứu và nhà hoạch định chính sách những hiểu biết có giá trị về mô hình, động lực và các tác nhân liên quan, hỗ trợ đưa ra quyết định sáng suốt và nghiên cứu liên quan đến xung đột.
A. Bản đồ và trực quan hóa tương tác cho phép khám phá và phân tích các mô hình xung đột theo không gian và thời gian bằng cách cung cấp dữ liệu trình bày trực quan cho phép xác định các xu hướng, điểm nóng và mối tương quan, nâng cao hiểu biết về động lực xung đột.
A. Điều quan trọng là phải hình dung và so sánh cẩn thận các loại sự kiện, đặc biệt khi một danh mục chiếm ưu thế trong tập dữ liệu, để tránh làm lu mờ những khác biệt tương đối và đánh giá chính xác tầm quan trọng cũng như động lực của các loại sự kiện khác.
A. Việc xác định và phân tích các tác nhân chính liên quan đến xung đột cung cấp cái nhìn sâu sắc về các thực thể và nhóm chủ chốt chịu trách nhiệm khởi xướng hoặc tham gia vào các sự kiện, giúp hiểu rõ động lực, động cơ và sự tương tác tiềm năng giữa các tác nhân khác nhau.
A. Tính toán trung bình luân phiên giúp trình bày trơn tru các sự cố xung đột bằng cách tính trung bình các điểm dữ liệu trong một khoảng thời gian cụ thể, cho phép xác định cả những biến động ngắn hạn và xu hướng dài hạn trong dữ liệu.
dự án
1. Raleigh, Clionadh, Andrew Linke, Håvard Hegre và Joakim Karlsen. (2010). “Giới thiệu Dữ liệu Sự kiện và Vị trí Xung đột Vũ trang ACLED.” Tạp chí Nghiên cứu Hòa bình 47(5) 651-660.
2. ACLED. (2023). “Sách mã về dự án dữ liệu sự kiện và địa điểm xung đột vũ trang (ACLED), 2023.
Phương tiện hiển thị trong bài viết này không thuộc sở hữu của Analytics Vidhya và được sử dụng theo quyết định riêng của Tác giả.
Sản phẩm liên quan
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2023/06/exploring-conflict-trends-and-patterns-manipur-acled-data-analysis/

