Sở thú kỹ thuật số cung cấp các dịch vụ nội địa hóa và truyền thông toàn diện để điều chỉnh nội dung phim và truyền hình gốc cho phù hợp với các ngôn ngữ, khu vực và nền văn hóa khác nhau. Nó làm cho việc toàn cầu hóa trở nên dễ dàng hơn đối với những người sáng tạo nội dung giỏi nhất thế giới. Được những tên tuổi lớn nhất trong ngành giải trí tin cậy, ZOO Digital cung cấp các dịch vụ bản địa hóa và truyền thông chất lượng cao trên quy mô lớn, bao gồm lồng tiếng, phụ đề, viết kịch bản và tuân thủ.
Quy trình bản địa hóa điển hình yêu cầu ghi nhật ký người nói theo cách thủ công, trong đó luồng âm thanh được phân đoạn dựa trên danh tính của người nói. Quá trình tốn thời gian này phải được hoàn thành trước khi nội dung có thể được lồng tiếng sang ngôn ngữ khác. Với các phương pháp thủ công, một tập phim dài 30 phút có thể mất từ 1 đến 3 giờ để bản địa hóa. Thông qua tự động hóa, ZOO Digital đặt mục tiêu đạt được bản địa hóa trong vòng chưa đầy 30 phút.
Trong bài đăng này, chúng tôi thảo luận về việc triển khai các mô hình học máy (ML) có thể mở rộng để ghi nhật ký nội dung phương tiện bằng cách sử dụng Amazon SageMaker, tập trung vào WhisperX mô hình.
Tiểu sử
Tầm nhìn của ZOO Digital là cung cấp sự thay đổi nội dung được bản địa hóa nhanh hơn. Mục tiêu này bị cản trở bởi tính chất chuyên sâu thủ công của công việc cùng với lực lượng lao động nhỏ gồm những người có kỹ năng có thể bản địa hóa nội dung theo cách thủ công. ZOO Digital hợp tác với hơn 11,000 dịch giả tự do và bản địa hóa hơn 600 triệu từ chỉ riêng trong năm 2022. Tuy nhiên, nguồn cung nhân lực có tay nghề đang bị vượt xa do nhu cầu về nội dung ngày càng tăng, đòi hỏi phải tự động hóa để hỗ trợ quy trình bản địa hóa.
Với mục đích đẩy nhanh quá trình bản địa hóa quy trình làm việc nội dung thông qua học máy, ZOO Digital đã tham gia AWS Prototyping, một chương trình đầu tư của AWS để cùng xây dựng khối lượng công việc với khách hàng. Sự tham gia này tập trung vào việc cung cấp giải pháp chức năng cho quy trình bản địa hóa, đồng thời cung cấp đào tạo thực hành cho các nhà phát triển ZOO Digital trên SageMaker, Phiên âm Amazonvà Amazon Dịch.
Thử thách khách hàng
Sau khi phiên âm tiêu đề (một bộ phim hoặc một tập của một bộ phim truyền hình dài tập), người nói phải được chỉ định cho từng đoạn lời nói để có thể chỉ định chính xác cho các nghệ sĩ lồng tiếng được chọn đóng vai các nhân vật. Quá trình này được gọi là ghi nhật ký người nói. ZOO Digital phải đối mặt với thách thức trong việc ghi nhật ký nội dung trên quy mô lớn nhưng vẫn đảm bảo hiệu quả về mặt kinh tế.
Tổng quan về giải pháp
Trong nguyên mẫu này, chúng tôi đã lưu trữ các tệp phương tiện gốc ở một nơi được chỉ định Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Bộ chứa S3 này được định cấu hình để phát ra một sự kiện khi phát hiện thấy các tệp mới trong đó, kích hoạt AWS Lambda chức năng. Để biết hướng dẫn về cách định cấu hình trình kích hoạt này, hãy tham khảo hướng dẫn Sử dụng trình kích hoạt Amazon S3 để gọi hàm Lambda. Sau đó, hàm Lambda gọi điểm cuối SageMaker để suy luận bằng cách sử dụng Máy khách thời gian chạy Boto3 SageMaker.
Sản phẩm WhisperX mô hình, dựa trên Lời thì thầm của OpenAI, thực hiện phiên âm và nhật ký cho nội dung phương tiện. Nó được xây dựng dựa trên Thì thầm nhanh hơn triển khai lại, cung cấp khả năng phiên âm nhanh hơn tới bốn lần với việc căn chỉnh dấu thời gian ở cấp độ từ được cải thiện so với Whisper. Ngoài ra, nó còn giới thiệu tính năng ghi nhật ký loa, không có trong mẫu Whisper gốc. WhisperX sử dụng mô hình Whisper để phiên âm, Wav2Vec2 mô hình để tăng cường căn chỉnh dấu thời gian (đảm bảo đồng bộ hóa văn bản được phiên âm với dấu thời gian âm thanh) và chú thích nhỏ mô hình cho nhật ký. FFmpeg được sử dụng để tải âm thanh từ phương tiện nguồn, hỗ trợ nhiều các định dạng phương tiện truyền thông. Kiến trúc mô hình mô-đun và minh bạch cho phép linh hoạt vì mỗi thành phần của mô hình có thể được hoán đổi khi cần thiết trong tương lai. Tuy nhiên, điều cần lưu ý là WhisperX thiếu các tính năng quản lý đầy đủ và không phải là sản phẩm cấp doanh nghiệp. Nếu không có bảo trì và hỗ trợ, nó có thể không phù hợp để triển khai sản xuất.
Trong lần hợp tác này, chúng tôi đã triển khai và đánh giá WhisperX trên SageMaker bằng cách sử dụng điểm cuối suy luận không đồng bộ để lưu trữ mô hình. Điểm cuối không đồng bộ của SageMaker hỗ trợ kích thước tải lên lên tới 1 GB và kết hợp các tính năng tự động thay đổi quy mô giúp giảm thiểu đột biến lưu lượng truy cập một cách hiệu quả và tiết kiệm chi phí trong thời gian thấp điểm. Điểm cuối không đồng bộ đặc biệt phù hợp để xử lý các tệp lớn, chẳng hạn như phim và phim truyền hình dài tập trong trường hợp sử dụng của chúng tôi.
Sơ đồ sau đây minh họa các yếu tố cốt lõi của các thử nghiệm mà chúng tôi đã thực hiện trong lần hợp tác này.

Trong các phần sau, chúng tôi đi sâu vào chi tiết về việc triển khai mô hình WhisperX trên SageMaker và đánh giá hiệu suất nhật ký.
Tải xuống mô hình và các thành phần của nó
WhisperX là một hệ thống bao gồm nhiều mô hình để sao chép, căn chỉnh bắt buộc và nhật ký. Để SageMaker vận hành trơn tru mà không cần tìm nạp các thành phần lạ của mô hình trong quá trình suy luận, điều cần thiết là phải tải xuống trước tất cả các thành phần lạ của mô hình. Sau đó, những thành phần lạ này được tải vào vùng chứa phân phối SageMaker trong quá trình bắt đầu. Vì những mô hình này không thể truy cập trực tiếp nên chúng tôi cung cấp mô tả và mã mẫu từ nguồn WhisperX, cung cấp hướng dẫn cách tải xuống mô hình và các thành phần của nó.
WhisperX sử dụng sáu mô hình:
Hầu hết các mô hình này có thể được lấy từ Ôm mặt sử dụng thư viện ôm mặt_hub. Chúng tôi sử dụng như sau download_hf_model() để truy xuất các tạo phẩm mô hình này. Cần có mã thông báo truy cập từ Ôm mặt, được tạo sau khi chấp nhận thỏa thuận người dùng cho các mô hình pyannote sau:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
Mô hình VAD được lấy từ Amazon S3 và mô hình Wav2Vec2 được lấy từ mô-đun torchaudio.pipelines. Dựa trên đoạn mã sau, chúng ta có thể truy xuất tất cả các tạo phẩm của mô hình, bao gồm cả các tạo phẩm từ Ôm mặt và lưu chúng vào thư mục mô hình cục bộ được chỉ định:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Chọn Bộ chứa AWS Deep Learning thích hợp để phân phát mô hình
Sau khi các tạo phẩm mô hình được lưu bằng mã mẫu trước đó, bạn có thể chọn các tạo phẩm dựng sẵn AWS Deep Learning Container (DLC) từ sau Repo GitHub. Khi chọn hình ảnh Docker, hãy xem xét các cài đặt sau: framework (Ôm mặt), tác vụ (suy luận), phiên bản Python và phần cứng (ví dụ: GPU). Chúng tôi khuyên bạn nên sử dụng hình ảnh sau: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Hình ảnh này có tất cả các gói hệ thống cần thiết được cài đặt sẵn, chẳng hạn như ffmpeg. Hãy nhớ thay thế [REGION] bằng Khu vực AWS bạn đang sử dụng.
Đối với các gói Python cần thiết khác, hãy tạo một requirements.txt tập tin với danh sách các gói và phiên bản của chúng. Các gói này sẽ được cài đặt khi AWS DLC được xây dựng. Sau đây là các gói bổ sung cần thiết để lưu trữ mô hình WhisperX trên SageMaker:
Tạo tập lệnh suy luận để tải mô hình và chạy suy luận
Tiếp theo, chúng ta tạo một tùy chỉnh inference.py tập lệnh để phác thảo cách tải mô hình WhisperX và các thành phần của nó vào vùng chứa cũng như cách chạy quy trình suy luận. Kịch bản chứa hai chức năng: model_fn và transform_fn. Các model_fn hàm được gọi để tải các mô hình từ vị trí tương ứng của chúng. Sau đó, các mô hình này được chuyển đến transform_fn chức năng trong quá trình suy luận, trong đó các quá trình sao chép, căn chỉnh và nhật ký được thực hiện. Sau đây là mẫu mã cho inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Trong thư mục của mô hình, cùng với requirements.txt tập tin, đảm bảo sự hiện diện của inference.py trong một thư mục con mã. Các models thư mục sẽ giống như sau:
Tạo tarball của các mô hình
Sau khi tạo mô hình và thư mục mã, bạn có thể sử dụng các dòng lệnh sau để nén mô hình thành tarball (tệp .tar.gz) và tải mô hình đó lên Amazon S3. Tại thời điểm viết bài, sử dụng mô hình V2 lớn có tốc độ nhanh hơn, tarball thu được đại diện cho mô hình SageMaker có kích thước 3 GB. Để biết thêm thông tin, hãy tham khảo Các mẫu lưu trữ mô hình trong Amazon SageMaker, Phần 2: Bắt đầu triển khai các mô hình thời gian thực trên SageMaker.
Tạo mô hình SageMaker và triển khai điểm cuối với bộ dự đoán không đồng bộ
Bây giờ bạn có thể tạo mô hình SageMaker, cấu hình điểm cuối và điểm cuối không đồng bộ với AsyncPredictor bằng cách sử dụng tarball mô hình được tạo ở bước trước. Để biết hướng dẫn, hãy tham khảo Tạo một điểm cuối suy luận không đồng bộ.
Đánh giá hiệu suất diarization
Để đánh giá hiệu suất ghi nhật ký của mô hình WhisperX trong nhiều tình huống khác nhau, chúng tôi đã chọn ba tập, mỗi tập từ hai tựa tiếng Anh: một tựa phim truyền hình gồm các tập dài 30 phút và một tựa phim tài liệu gồm các tập dài 45 phút. Chúng tôi đã sử dụng bộ công cụ đo lường của pyannote, pyannote.metrics, để tính toán tỷ lệ lỗi nhật ký (DER). Trong quá trình đánh giá, các bản ghi chép được chép lại và ghi nhật ký theo cách thủ công do ZOO cung cấp được coi là sự thật cơ bản.
Chúng tôi đã xác định DER như sau:
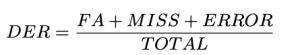
Tổng số: là độ dài của video sự thật mặt đất. FA (Báo động sai) là độ dài của các đoạn được coi là lời nói trong các dự đoán nhưng không phải là sự thật cơ bản. Bỏ lỡ là độ dài của các đoạn được coi là lời nói trong sự thật cơ bản, nhưng không phải trong dự đoán. lỗi, Còn gọi là Lẫn lộn, là độ dài của các đoạn được gán cho những người nói khác nhau trong dự đoán và sự thật cơ bản. Tất cả các đơn vị được đo bằng giây. Các giá trị điển hình cho DER có thể khác nhau tùy thuộc vào ứng dụng, tập dữ liệu cụ thể và chất lượng của hệ thống nhật ký. Lưu ý rằng DER có thể lớn hơn 1.0. DER thấp hơn thì tốt hơn.
Để có thể tính toán DER cho một phần phương tiện, cần phải ghi nhật ký sự thật cơ bản cũng như các đầu ra được sao chép và ghi nhật ký của WhisperX. Chúng phải được phân tích cú pháp và tạo ra danh sách các bộ dữ liệu chứa nhãn người nói, thời gian bắt đầu phân đoạn giọng nói và thời gian kết thúc phân đoạn giọng nói cho từng phân đoạn giọng nói trong phương tiện truyền thông. Nhãn loa không cần phải khớp giữa WhisperX và nhật ký sự thật trên mặt đất. Kết quả chủ yếu dựa vào thời gian của các phân đoạn. pyannote.metrics lấy các bộ dữ liệu phân tích sự thật cơ bản và phân tích đầu ra này (được gọi trong tài liệu pyannote.metrics là tài liệu tham khảo và giả thuyết) để tính DER. Bảng sau đây tóm tắt kết quả của chúng tôi.
| Loại video | DER | Chính xác | Bỏ lỡ | lỗi | Báo động sai |
| Kịch | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Tài liệu | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Trung bình | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Những kết quả này cho thấy sự khác biệt đáng kể về hiệu suất giữa tựa phim chính kịch và phim tài liệu, trong đó mô hình đạt được kết quả tốt hơn đáng kể (sử dụng DER làm thước đo tổng hợp) cho các tập phim truyền hình so với tựa phim tài liệu. Phân tích kỹ hơn về các tiêu đề sẽ cung cấp thông tin chi tiết về các yếu tố tiềm ẩn góp phần vào khoảng cách hiệu suất này. Một yếu tố quan trọng có thể là sự xuất hiện thường xuyên của nhạc nền chồng chéo với lời nói trong tiêu đề phim tài liệu. Mặc dù phương tiện tiền xử lý để nâng cao độ chính xác của quá trình lọc dữ liệu, chẳng hạn như loại bỏ tiếng ồn xung quanh để tách giọng nói, nằm ngoài phạm vi của nguyên mẫu này, nhưng nó mở ra con đường cho công việc trong tương lai có khả năng nâng cao hiệu suất của WhisperX.
Kết luận
Trong bài đăng này, chúng tôi đã khám phá mối quan hệ hợp tác giữa AWS và ZOO Digital, sử dụng các kỹ thuật máy học với SageMaker và mô hình WhisperX để nâng cao quy trình ghi nhật ký. Nhóm AWS đóng vai trò then chốt trong việc hỗ trợ ZOO tạo nguyên mẫu, đánh giá và tìm hiểu cách triển khai hiệu quả các mô hình ML tùy chỉnh, được thiết kế đặc biệt cho nhật ký. Điều này bao gồm việc kết hợp tính năng tự động điều chỉnh quy mô để có khả năng mở rộng bằng SageMaker.
Khai thác AI để nhật ký sẽ giúp tiết kiệm đáng kể cả chi phí và thời gian khi tạo nội dung bản địa hóa cho ZOO. Bằng cách hỗ trợ người ghi âm trong việc tạo và nhận dạng người nói một cách nhanh chóng và chính xác, công nghệ này giải quyết được tính chất truyền thống tốn thời gian và dễ xảy ra lỗi của công việc. Quy trình thông thường thường bao gồm nhiều lần chuyển qua video và các bước kiểm soát chất lượng bổ sung để giảm thiểu lỗi. Việc áp dụng AI để ghi nhật ký cho phép tiếp cận có mục tiêu và hiệu quả hơn, từ đó tăng năng suất trong khung thời gian ngắn hơn.
Chúng tôi đã phác thảo các bước chính để triển khai mô hình WhisperX trên điểm cuối không đồng bộ SageMaker và khuyến khích bạn tự mình thử bằng cách sử dụng mã được cung cấp. Để biết thêm thông tin chi tiết về các dịch vụ và công nghệ của ZOO Digital, hãy truy cập Trang web chính thức của Zoo Digital. Để biết chi tiết về cách triển khai mô hình OpenAI Whisper trên SageMaker và các tùy chọn suy luận khác nhau, hãy tham khảo Lưu trữ Mô hình thì thầm trên Amazon SageMaker: khám phá các tùy chọn suy luận. Hãy chia sẻ suy nghĩ của bạn trong các ý kiến.
Về các tác giả
 Ying Hou, Tiến sĩ, là Kiến trúc sư nguyên mẫu học máy tại AWS. Lĩnh vực quan tâm chính của cô bao gồm Deep Learning, tập trung vào GenAI, Thị giác máy tính, NLP và dự đoán dữ liệu chuỗi thời gian. Trong thời gian rảnh rỗi, cô thích dành những khoảnh khắc vui vẻ bên gia đình, đắm mình trong tiểu thuyết và đi bộ đường dài trong các công viên quốc gia của Vương quốc Anh.
Ying Hou, Tiến sĩ, là Kiến trúc sư nguyên mẫu học máy tại AWS. Lĩnh vực quan tâm chính của cô bao gồm Deep Learning, tập trung vào GenAI, Thị giác máy tính, NLP và dự đoán dữ liệu chuỗi thời gian. Trong thời gian rảnh rỗi, cô thích dành những khoảnh khắc vui vẻ bên gia đình, đắm mình trong tiểu thuyết và đi bộ đường dài trong các công viên quốc gia của Vương quốc Anh.
 Ethan Cumberland là Kỹ sư nghiên cứu AI tại ZOO Digital, nơi anh nghiên cứu việc sử dụng AI và Machine Learning làm công nghệ hỗ trợ để cải thiện quy trình làm việc về giọng nói, ngôn ngữ và bản địa hóa. Anh có kiến thức nền tảng về công nghệ phần mềm và nghiên cứu trong lĩnh vực bảo mật và chính sách, tập trung vào việc trích xuất thông tin có cấu trúc từ web và tận dụng các mô hình ML nguồn mở để phân tích và làm phong phú dữ liệu được thu thập.
Ethan Cumberland là Kỹ sư nghiên cứu AI tại ZOO Digital, nơi anh nghiên cứu việc sử dụng AI và Machine Learning làm công nghệ hỗ trợ để cải thiện quy trình làm việc về giọng nói, ngôn ngữ và bản địa hóa. Anh có kiến thức nền tảng về công nghệ phần mềm và nghiên cứu trong lĩnh vực bảo mật và chính sách, tập trung vào việc trích xuất thông tin có cấu trúc từ web và tận dụng các mô hình ML nguồn mở để phân tích và làm phong phú dữ liệu được thu thập.
 Gaurav Kaila lãnh đạo nhóm Tạo nguyên mẫu AWS tại Vương quốc Anh và Ireland. Nhóm của ông làm việc với khách hàng ở nhiều ngành khác nhau để lên ý tưởng và hợp tác phát triển các khối lượng công việc quan trọng trong kinh doanh với nhiệm vụ đẩy nhanh việc áp dụng các dịch vụ AWS.
Gaurav Kaila lãnh đạo nhóm Tạo nguyên mẫu AWS tại Vương quốc Anh và Ireland. Nhóm của ông làm việc với khách hàng ở nhiều ngành khác nhau để lên ý tưởng và hợp tác phát triển các khối lượng công việc quan trọng trong kinh doanh với nhiệm vụ đẩy nhanh việc áp dụng các dịch vụ AWS.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

