Giới thiệu
Tại trung tâm của khoa học dữ liệu số liệu thống kê dối trá, đã tồn tại trong nhiều thế kỷ nhưng về cơ bản vẫn rất cần thiết trong thời đại kỹ thuật số ngày nay. Tại sao? Bởi vì các khái niệm thống kê cơ bản là xương sống của phân tích dữ liệu, cho phép chúng tôi hiểu được lượng dữ liệu khổng lồ được tạo ra hàng ngày. Nó giống như trò chuyện với dữ liệu, trong đó số liệu thống kê giúp chúng ta đặt câu hỏi phù hợp và hiểu được câu chuyện mà dữ liệu muốn kể.
Từ dự đoán xu hướng trong tương lai và đưa ra quyết định dựa trên dữ liệu đến kiểm tra các giả thuyết và đo lường hiệu suất, số liệu thống kê là công cụ cung cấp thông tin chuyên sâu đằng sau các quyết định dựa trên dữ liệu. Đó là cầu nối giữa dữ liệu thô và những hiểu biết sâu sắc có thể hành động, khiến nó trở thành một phần không thể thiếu của khoa học dữ liệu.
Trong bài viết này, tôi đã tổng hợp 15 khái niệm thống kê cơ bản hàng đầu mà mọi người mới bắt đầu khoa học dữ liệu nên biết!

Mục lục
1. Lấy mẫu thống kê và thu thập dữ liệu
Chúng ta sẽ tìm hiểu một số khái niệm thống kê cơ bản, nhưng việc hiểu dữ liệu của chúng ta đến từ đâu và cách chúng ta thu thập dữ liệu đó là điều cần thiết trước khi đi sâu vào đại dương dữ liệu. Đây là nơi các quần thể, mẫu và các kỹ thuật lấy mẫu khác nhau phát huy tác dụng.
Hãy tưởng tượng chúng ta muốn biết chiều cao trung bình của người dân trong một thành phố. Việc đo lường tất cả mọi người là điều thiết thực nên chúng tôi lấy một nhóm (mẫu) nhỏ hơn đại diện cho tổng thể lớn hơn. Bí quyết nằm ở cách chúng tôi chọn mẫu này. Các kỹ thuật như lấy mẫu ngẫu nhiên, phân tầng hoặc cụm đảm bảo mẫu của chúng tôi được thể hiện tốt, giảm thiểu sai lệch và làm cho kết quả của chúng tôi đáng tin cậy hơn.
Bằng cách hiểu rõ về quần thể và mẫu, chúng tôi có thể tự tin mở rộng hiểu biết sâu sắc của mình từ mẫu đến toàn bộ quần thể, đưa ra quyết định sáng suốt mà không cần phải khảo sát tất cả mọi người.
2. Các loại dữ liệu và thang đo
Dữ liệu có nhiều loại khác nhau và việc biết loại dữ liệu bạn đang xử lý là rất quan trọng để chọn đúng công cụ và kỹ thuật thống kê.
Dữ liệu định lượng và định tính
- Dữ liệu định lượng: Loại dữ liệu này là tất cả về con số. Nó có thể đo lường được và có thể được sử dụng để tính toán toán học. Dữ liệu định lượng cho chúng ta biết “bao nhiêu” hoặc “bao nhiêu”, chẳng hạn như số lượng người dùng truy cập trang web hoặc nhiệt độ trong thành phố. Nó đơn giản và khách quan, cung cấp một bức tranh rõ ràng thông qua các giá trị số.
- Dữ liệu định tính: Ngược lại, dữ liệu định tính liên quan đến các đặc điểm và mô tả. Đó là về “loại nào” hoặc “danh mục nào”. Hãy coi nó như dữ liệu mô tả chất lượng hoặc thuộc tính, chẳng hạn như màu sắc của một chiếc ô tô hoặc thể loại sách. Dữ liệu này mang tính chủ quan, dựa trên quan sát hơn là đo lường.
Bốn thang đo lường
- Quy mô danh nghĩa: Đây là hình thức đo lường đơn giản nhất được sử dụng để phân loại dữ liệu mà không có thứ tự cụ thể. Ví dụ bao gồm các loại ẩm thực, nhóm máu hoặc quốc tịch. Đó là về việc ghi nhãn mà không có bất kỳ giá trị định lượng nào.
- Thang đo thứ tự: Dữ liệu có thể được sắp xếp hoặc sắp xếp ở đây nhưng khoảng cách giữa các giá trị không được xác định. Hãy nghĩ đến một cuộc khảo sát về mức độ hài lòng với các lựa chọn như hài lòng, trung lập và không hài lòng. Nó cho chúng ta biết thứ tự chứ không phải khoảng cách giữa các thứ hạng.
- Thang đo khoảng: Khoảng thời gian chia tỷ lệ dữ liệu thứ tự và định lượng sự khác biệt giữa các mục. Tuy nhiên, thực tế không có điểm 10. Một ví dụ điển hình là nhiệt độ tính bằng độ C; sự khác biệt giữa 20°C và 20°C cũng giống như giữa 30°C và 0°C, nhưng XNUMX°C không có nghĩa là không có nhiệt độ.
- Thang đo tỉ lệ: Thang đo có nhiều thông tin nhất có tất cả các đặc tính của thang đo khoảng cộng với điểm 0 có ý nghĩa, cho phép so sánh chính xác về độ lớn. Ví dụ bao gồm cân nặng, chiều cao và thu nhập. Ở đây, chúng ta có thể nói cái này nhiều gấp đôi cái kia.
KHAI THÁC. Thống kê mô tả
Hãy tưởng tượng thống kê mô tả là buổi hẹn hò đầu tiên với dữ liệu của bạn. Đó là việc tìm hiểu những điều cơ bản, những nét khái quát mô tả những gì trước mắt bạn. Thống kê mô tả có hai loại chính: xu hướng trung tâm và các thước đo biến thiên.
Biện pháp của xu hướng trung ương: Đây giống như trọng tâm của dữ liệu. Chúng cung cấp cho chúng tôi một giá trị điển hình hoặc đại diện cho tập dữ liệu của chúng tôi.
Nghĩa là: Giá trị trung bình được tính bằng cách cộng tất cả các giá trị và chia cho số giá trị. Nó giống như đánh giá tổng thể của một nhà hàng dựa trên tất cả các đánh giá. Công thức toán học cho mức trung bình được đưa ra dưới đây:

Trung bình: Giá trị ở giữa khi dữ liệu được sắp xếp từ nhỏ nhất đến lớn nhất. Nếu số quan sát là số chẵn thì đó là trung bình cộng của hai số ở giữa. Nó được sử dụng để tìm điểm giữa của cây cầu.
Nếu n chẵn thì số trung vị là trung bình cộng của hai số ở giữa.
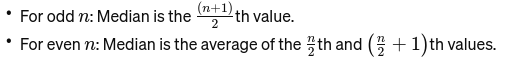
Mode: Nó là giá trị xuất hiện thường xuyên nhất trong tập dữ liệu. Hãy coi nó như món ăn phổ biến nhất tại một nhà hàng.
Các biện pháp biến đổi: Trong khi thước đo xu hướng trung tâm đưa chúng ta đến trung tâm, thước đo độ biến thiên cho chúng ta biết về mức độ lan rộng hoặc phân tán.
Phạm vi: Sự khác biệt giữa giá trị cao nhất và thấp nhất. Nó đưa ra một ý tưởng cơ bản về sự lây lan.
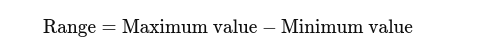
Phương sai: Đo khoảng cách giữa mỗi số trong tập hợp với giá trị trung bình và do đó cách xa mọi số khác trong tập hợp. Đối với một mẫu, nó được tính toán như sau:
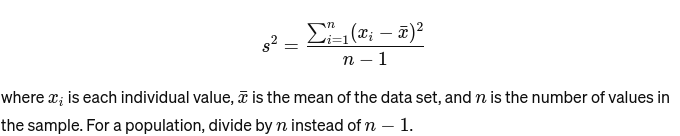
Độ lệch chuẩn: Căn bậc hai của phương sai cung cấp thước đo khoảng cách trung bình so với giá trị trung bình. Nó giống như việc đánh giá độ đồng nhất của kích cỡ bánh của người thợ làm bánh. Nó được biểu diễn dưới dạng:
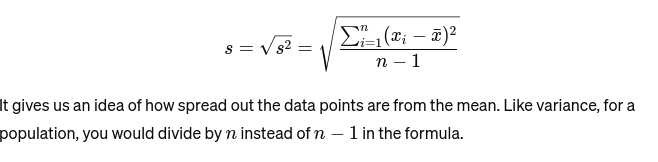
Trước khi chúng ta chuyển sang khái niệm thống kê cơ bản tiếp theo, đây là Hướng dẫn cho người mới bắt đầu về phân tích thống kê dành cho bạn!
4. Trực quan hóa dữ liệu
Trực quan hóa dữ liệu là nghệ thuật và khoa học kể chuyện bằng dữ liệu. Nó biến những kết quả phức tạp từ phân tích của chúng ta thành thứ gì đó hữu hình và dễ hiểu. Điều quan trọng là phân tích dữ liệu khám phá, trong đó mục tiêu là khám phá các mô hình, mối tương quan và hiểu biết sâu sắc về dữ liệu mà chưa đưa ra kết luận chính thức.
- Đồ thị và biểu đồ: Bắt đầu với những điều cơ bản, biểu đồ thanh, biểu đồ đường và biểu đồ hình tròn cung cấp những hiểu biết cơ bản về dữ liệu. Chúng là những ABC về trực quan hóa dữ liệu, cần thiết cho bất kỳ người kể chuyện dữ liệu nào.
Chúng ta có một ví dụ về biểu đồ thanh (trái) và biểu đồ đường (phải) bên dưới.
- Trực quan hóa nâng cao: Khi chúng tôi tìm hiểu sâu hơn, bản đồ nhiệt, biểu đồ phân tán và biểu đồ cho phép phân tích nhiều sắc thái hơn. Những công cụ này giúp xác định xu hướng, phân phối và các ngoại lệ.
Dưới đây là một ví dụ về biểu đồ phân tán và biểu đồ

Trực quan hóa là cầu nối giữa dữ liệu thô và nhận thức của con người, cho phép chúng tôi diễn giải và hiểu các tập dữ liệu phức tạp một cách nhanh chóng.
5. Cơ bản về xác suất
Xác suất là ngữ pháp của ngôn ngữ thống kê. Đó là về cơ hội hoặc khả năng xảy ra các sự kiện. Hiểu các khái niệm về xác suất là điều cần thiết để diễn giải các kết quả thống kê và đưa ra dự đoán.
- Sự kiện độc lập và phụ thuộc:
- Sự kiện độc lập: Kết quả của một sự kiện không ảnh hưởng đến kết quả của sự kiện khác. Giống như việc tung một đồng xu, việc có được mặt ngửa trong một lần tung không làm thay đổi tỷ lệ cược cho lần tung tiếp theo.
- Sự kiện phụ thuộc: Kết quả của một sự kiện ảnh hưởng đến kết quả của sự kiện khác. Ví dụ: nếu bạn rút một lá bài từ một bộ bài và không thay thế nó, cơ hội rút một lá bài cụ thể khác của bạn sẽ thay đổi.
Xác suất cung cấp nền tảng để đưa ra suy luận về dữ liệu và rất quan trọng để hiểu ý nghĩa thống kê và kiểm tra giả thuyết.
6. Phân phối xác suất chung
Phân bố xác suất giống như các loài khác nhau trong hệ sinh thái thống kê, mỗi loài thích nghi với phạm vi ứng dụng của nó.
- Phân phối bình thường: Thường được gọi là đường cong hình chuông vì hình dạng của nó, sự phân bổ này được đặc trưng bởi giá trị trung bình và độ lệch chuẩn. Đó là một giả định phổ biến trong nhiều thử nghiệm thống kê vì nhiều biến số được phân phối tự nhiên theo cách này trong thế giới thực.
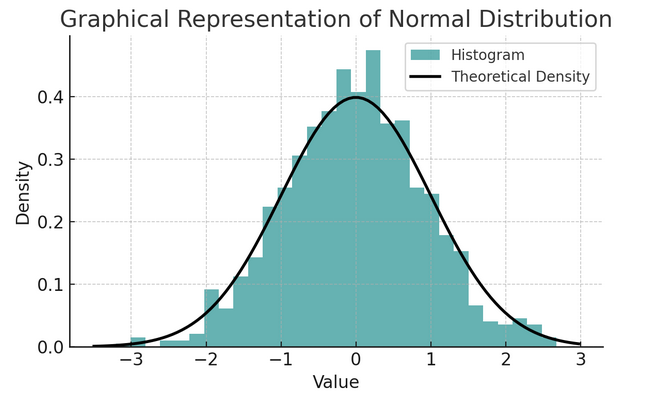
Một bộ quy tắc được gọi là quy tắc thực nghiệm hoặc quy tắc 68-95-99.7 tóm tắt các đặc điểm của phân phối chuẩn, mô tả cách dữ liệu được trải rộng xung quanh giá trị trung bình.
Quy tắc 68-95-99.7 (Quy tắc thực nghiệm)
Quy tắc này áp dụng cho phân phối hoàn toàn bình thường và nêu ra những điều sau:
- 68% của dữ liệu nằm trong một độ lệch chuẩn (σ) của giá trị trung bình (μ).
- 95% của dữ liệu nằm trong hai độ lệch chuẩn của giá trị trung bình.
- Xấp xỉ 99.7% của dữ liệu nằm trong ba độ lệch chuẩn của giá trị trung bình.
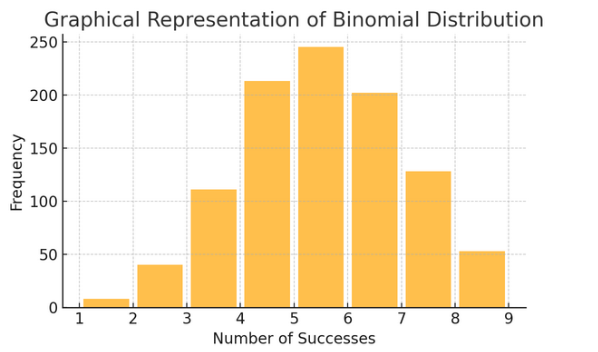
Phân phối nhị thức: Phân phối này áp dụng cho các tình huống có hai kết quả (như thành công hoặc thất bại) được lặp lại nhiều lần. Nó giúp mô hình hóa các sự kiện như tung đồng xu hoặc làm bài kiểm tra đúng/sai.
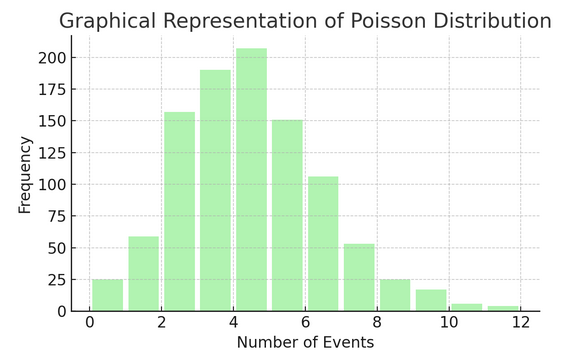
Phân phối Poisson đếm số lần điều gì đó xảy ra trong một khoảng thời gian hoặc không gian cụ thể. Điều này lý tưởng cho các tình huống mà các sự kiện diễn ra độc lập và liên tục, chẳng hạn như email bạn nhận được hàng ngày.
Mỗi bản phân phối có bộ công thức và đặc điểm riêng và việc chọn công thức và đặc điểm phù hợp tùy thuộc vào bản chất dữ liệu của bạn và nội dung bạn đang cố gắng tìm hiểu. Hiểu được những phân bố này cho phép các nhà thống kê và nhà khoa học dữ liệu mô hình hóa các hiện tượng trong thế giới thực và dự đoán chính xác các sự kiện trong tương lai.
7 . Kiểm tra giả thuyết
Nghĩ về kiểm tra giả thuyết như công việc thám tử trong thống kê. Đó là một phương pháp để kiểm tra xem một lý thuyết cụ thể về dữ liệu của chúng tôi có đúng hay không. Quá trình này bắt đầu với hai giả thuyết đối lập nhau:
- Giả thuyết không (H0): Đây là giả định mặc định, cho thấy có tác dụng hoặc sự khác biệt. Nó có nghĩa là “Không” mới ở đây.”
- Giả thuyết thay thế Al “(H1 hoặc Ha): Điều này thách thức hiện trạng, đề xuất một hiệu ứng hoặc một sự khác biệt. Nó tuyên bố, "Có điều gì đó thú vị đang diễn ra."
Ví dụ: Kiểm tra xem một chương trình ăn kiêng mới có dẫn đến giảm cân so với việc không tuân theo bất kỳ chế độ ăn kiêng nào hay không.
- Giả thuyết không (H0): Chương trình ăn kiêng mới không dẫn đến giảm cân (không có sự khác biệt về việc giảm cân giữa những người theo chương trình ăn kiêng mới và những người không thực hiện).
- Giả thuyết thay thế (H1): Chương trình ăn kiêng mới dẫn đến giảm cân (sự khác biệt trong việc giảm cân giữa những người tuân theo và những người không thực hiện).
Kiểm tra giả thuyết liên quan đến việc lựa chọn giữa hai giả thuyết này dựa trên bằng chứng (dữ liệu của chúng tôi).
Mức độ lỗi và ý nghĩa loại I và II:
- Lỗi loại I: Điều này xảy ra khi chúng ta bác bỏ giả thuyết không một cách sai lầm. Nó kết án một người vô tội.
- Lỗi loại II: Điều này xảy ra khi chúng ta không bác bỏ được một giả thuyết không sai. Nó cho phép một người có tội được tự do.
- Mức ý nghĩa (α): Đây là ngưỡng để quyết định có bao nhiêu bằng chứng đủ để bác bỏ giả thuyết không. Nó thường được đặt ở mức 5% (0.05), cho thấy nguy cơ xảy ra lỗi Loại I là 5%.
8. Khoảng tin cậy
Khoảng tin cậy cung cấp cho chúng tôi một phạm vi giá trị trong đó chúng tôi mong đợi tham số tổng thể hợp lệ (như giá trị trung bình hoặc tỷ lệ) sẽ giảm với mức độ tin cậy nhất định (thường là 95%). Nó giống như việc dự đoán tỷ số cuối cùng của một đội thể thao với một sai số nhất định; chúng tôi đang nói: “Chúng tôi tin tưởng 95% rằng điểm số thực sự sẽ nằm trong phạm vi này”.
Việc xây dựng và diễn giải các khoảng tin cậy giúp chúng tôi hiểu được độ chính xác của các ước tính của mình. Khoảng càng rộng thì ước tính của chúng ta càng kém chính xác và ngược lại.
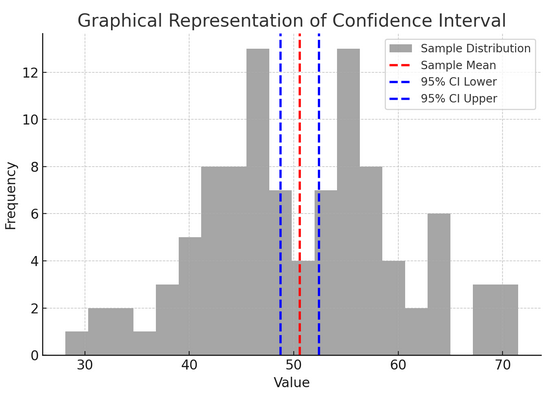
Hình trên minh họa khái niệm khoảng tin cậy (CI) trong thống kê, sử dụng phân bố mẫu và khoảng tin cậy 95% xung quanh giá trị trung bình mẫu.
Dưới đây là bảng phân tích các thành phần quan trọng trong hình:
- Phân phối mẫu (Biểu đồ màu xám): Điều này thể hiện sự phân bổ của 100 điểm dữ liệu được tạo ngẫu nhiên từ phân phối chuẩn với giá trị trung bình là 50 và độ lệch chuẩn là 10. Biểu đồ mô tả trực quan cách các điểm dữ liệu được phân bổ xung quanh giá trị trung bình.
- Giá trị trung bình mẫu (Đường đứt nét màu đỏ): Dòng này cho biết giá trị trung bình (trung bình) của dữ liệu mẫu. Nó đóng vai trò là ước tính điểm mà chúng ta xây dựng khoảng tin cậy. Trong trường hợp này, nó đại diện cho giá trị trung bình của tất cả các giá trị mẫu.
- Khoảng tin cậy 95% (Đường đứt nét màu xanh): Hai đường này đánh dấu giới hạn dưới và giới hạn trên của khoảng tin cậy 95% xung quanh giá trị trung bình mẫu. Khoảng được tính bằng cách sử dụng sai số chuẩn của giá trị trung bình (SEM) và điểm Z tương ứng với mức độ tin cậy mong muốn (1.96 cho độ tin cậy 95%). Khoảng tin cậy cho thấy chúng ta tin cậy 95% rằng giá trị trung bình của tổng thể nằm trong phạm vi này.
9. Mối tương quan và nhân quả
Mối tương quan và nhân quả thường bị lẫn lộn, nhưng chúng khác nhau:
- Tương quan: Chỉ ra mối quan hệ hoặc liên kết giữa hai biến. Khi cái này thay đổi thì cái kia cũng có xu hướng thay đổi. Mối tương quan được đo bằng hệ số tương quan nằm trong khoảng từ -1 đến 1. Giá trị gần hơn với 1 hoặc -1 biểu thị mối quan hệ chặt chẽ, trong khi 0 cho thấy không có mối quan hệ nào.
- Nguyên nhân: Nó ngụ ý rằng những thay đổi trong một biến sẽ trực tiếp gây ra những thay đổi ở một biến khác. Đó là một khẳng định mạnh mẽ hơn mối tương quan và đòi hỏi phải kiểm tra nghiêm ngặt.
Chỉ vì hai biến có mối tương quan với nhau không có nghĩa là biến này gây ra biến kia. Đây là một trường hợp điển hình về việc không nhầm lẫn “mối tương quan” với “quan hệ nhân quả”.
10. Hồi quy tuyến tính đơn giản
Đơn giản hồi quy tuyến tính là một cách để mô hình hóa mối quan hệ giữa hai biến bằng cách khớp phương trình tuyến tính với dữ liệu quan sát được. Một biến được coi là biến giải thích (độc lập) và biến còn lại là biến phụ thuộc.
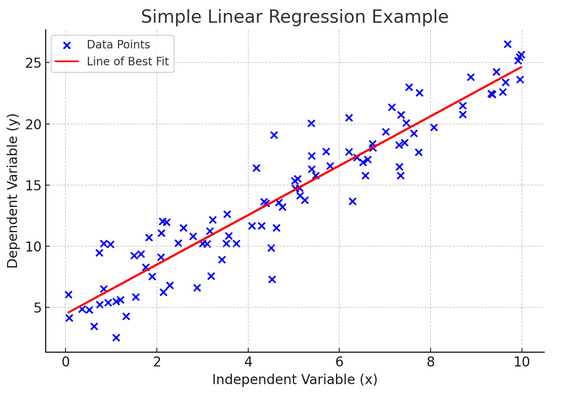
Hồi quy tuyến tính đơn giản giúp chúng ta hiểu những thay đổi trong biến độc lập ảnh hưởng đến biến phụ thuộc như thế nào. Đây là một công cụ mạnh mẽ để dự đoán và là nền tảng cho nhiều mô hình thống kê phức tạp khác. Bằng cách phân tích mối quan hệ giữa hai biến số, chúng ta có thể đưa ra những dự đoán sáng suốt về cách chúng sẽ tương tác.
Hồi quy tuyến tính đơn giản giả định mối quan hệ tuyến tính giữa biến độc lập (biến giải thích) và biến phụ thuộc. Nếu mối quan hệ giữa hai biến này không tuyến tính thì các giả định của hồi quy tuyến tính đơn giản có thể bị vi phạm, có khả năng dẫn đến những dự đoán hoặc diễn giải không chính xác. Vì vậy, việc xác minh mối quan hệ tuyến tính trong dữ liệu là điều cần thiết trước khi áp dụng hồi quy tuyến tính đơn giản.
11. Hồi quy tuyến tính bội
Hãy nghĩ về hồi quy tuyến tính đa biến như một phần mở rộng của hồi quy tuyến tính đơn giản. Tuy nhiên, thay vì cố gắng dự đoán kết quả với một hiệp sĩ mặc áo giáp sáng ngời (máy dự đoán), bạn có cả một đội. Nó giống như nâng cấp từ một trận bóng rổ một chọi một lên nỗ lực của cả đội, trong đó mỗi người chơi (người dự đoán) mang đến những kỹ năng riêng biệt. Ý tưởng là để xem một số biến số cùng nhau ảnh hưởng như thế nào đến một kết quả.
Tuy nhiên, với một nhóm lớn hơn sẽ gặp phải thách thức trong việc quản lý các mối quan hệ, được gọi là đa cộng tuyến. Nó xảy ra khi những người dự đoán quá gần nhau và chia sẻ thông tin tương tự nhau. Hãy tưởng tượng hai cầu thủ bóng rổ liên tục cố gắng thực hiện cùng một cú đánh; họ có thể cản đường nhau. Hồi quy có thể khiến chúng ta khó thấy được sự đóng góp riêng biệt của từng yếu tố dự đoán, có khả năng làm sai lệch sự hiểu biết của chúng ta về những biến số nào là quan trọng.
12. Hồi quy logistic
Trong khi hồi quy tuyến tính dự đoán các kết quả liên tục (như nhiệt độ hoặc giá cả), hồi quy logistic được sử dụng khi kết quả đã xác định (như có/không, thắng/thua). Hãy tưởng tượng bạn đang cố gắng dự đoán liệu một đội sẽ thắng hay thua dựa trên nhiều yếu tố khác nhau; hồi quy logistic là chiến lược phù hợp của bạn.
Nó biến đổi phương trình tuyến tính sao cho đầu ra của nó nằm trong khoảng từ 0 đến 1, biểu thị xác suất thuộc về một danh mục cụ thể. Nó giống như có một thấu kính ma thuật chuyển đổi các điểm số liên tục thành một góc nhìn rõ ràng “cái này hoặc cái kia”, cho phép chúng ta dự đoán các kết quả mang tính phân loại.
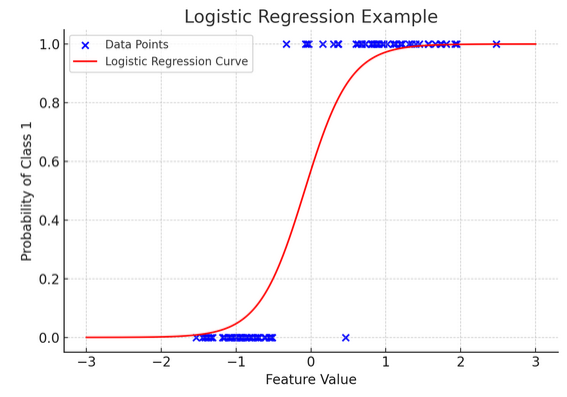
Biểu diễn đồ họa minh họa một ví dụ về hồi quy logistic được áp dụng cho tập dữ liệu phân loại nhị phân tổng hợp. Các chấm màu xanh biểu thị các điểm dữ liệu, với vị trí của chúng dọc theo trục x biểu thị giá trị đối tượng và trục y biểu thị danh mục (0 hoặc 1). Đường cong màu đỏ thể hiện dự đoán của mô hình hồi quy logistic về xác suất thuộc về loại 1 (ví dụ: “thắng”) đối với các giá trị đặc trưng khác nhau. Như bạn có thể thấy, đường cong chuyển đổi suôn sẻ từ xác suất của loại 0 sang loại 1, thể hiện khả năng của mô hình trong việc dự đoán các kết quả phân loại dựa trên tính năng liên tục cơ bản.
Công thức hồi quy logistic được đưa ra bởi:

Công thức này sử dụng hàm logistic để chuyển đổi đầu ra của phương trình tuyến tính thành xác suất từ 0 đến 1. Phép biến đổi này cho phép chúng ta hiểu kết quả đầu ra là xác suất thuộc về một danh mục cụ thể dựa trên giá trị của biến độc lập xx.
13. Thử nghiệm ANOVA và Chi-Square
ANOVA (Phân tích phương sai) và Kiểm tra Chi-Square giống như những thám tử trong thế giới thống kê, giúp chúng ta giải quyết những bí ẩn khác nhau. TÔIt cho phép chúng tôi so sánh các phương tiện giữa nhiều nhóm để xem liệu có ít nhất một nhóm khác biệt về mặt thống kê hay không. Hãy coi nó như việc nếm thử các mẫu từ một số mẻ bánh quy để xác định xem có mẻ nào có mùi vị khác biệt đáng kể hay không.
Mặt khác, bài kiểm tra Chi-Square được sử dụng cho dữ liệu phân loại. Nó giúp chúng tôi hiểu liệu có mối liên hệ đáng kể nào giữa hai biến phân loại hay không. Ví dụ: có mối quan hệ nào giữa thể loại âm nhạc yêu thích của một người và nhóm tuổi của họ không? Bài kiểm tra Chi-Square giúp trả lời những câu hỏi như vậy.
14. Định lý giới hạn trung tâm và tầm quan trọng của nó trong khoa học dữ liệu
Sản phẩm Định lý giới hạn trung tâm (CLT) là một nguyên tắc thống kê cơ bản gần như kỳ diệu. Nó cho chúng ta biết rằng nếu bạn lấy đủ mẫu từ một tổng thể và tính giá trị trung bình của chúng, thì những giá trị trung bình đó sẽ hình thành một phân phối chuẩn (đường cong hình chuông), bất kể phân bố ban đầu của tổng thể là gì. Điều này cực kỳ hữu ích vì nó cho phép chúng ta suy luận về các quần thể ngay cả khi chúng ta không biết chính xác sự phân bổ của chúng.
Trong khoa học dữ liệu, CLT củng cố nhiều kỹ thuật, cho phép chúng tôi sử dụng các công cụ được thiết kế cho dữ liệu được phân phối thông thường ngay cả khi dữ liệu của chúng tôi ban đầu không đáp ứng các tiêu chí đó. Nó giống như tìm một bộ chuyển đổi phổ quát cho các phương pháp thống kê, làm cho nhiều công cụ mạnh mẽ có thể áp dụng được trong nhiều tình huống hơn.
15. Sự đánh đổi độ lệch-phương sai
In mô hình dự đoán và học máy, Các sự cân bằng phương sai lệch là một khái niệm quan trọng làm nổi bật sự căng thẳng giữa hai loại lỗi chính có thể khiến mô hình của chúng ta trở nên sai lầm. Xu hướng đề cập đến lỗi từ các mô hình quá đơn giản không nắm bắt tốt các xu hướng cơ bản. Hãy tưởng tượng bạn đang cố gắng nối một đường thẳng qua một con đường cong; bạn sẽ bỏ lỡ dấu ấn. Ngược lại, Phương sai từ các mô hình quá phức tạp ghi lại nhiễu trong dữ liệu như thể nó là một mẫu thực tế — giống như truy tìm từng khúc quanh và rẽ vào một con đường gập ghềnh, nghĩ rằng đó là con đường phía trước.
Nghệ thuật nằm ở việc cân bằng cả hai điều này để giảm thiểu tổng số lỗi, tìm ra điểm phù hợp mà mô hình của bạn vừa phải—đủ phức tạp để nắm bắt các mẫu chính xác nhưng đủ đơn giản để bỏ qua nhiễu ngẫu nhiên. Nó giống như việc chỉnh dây đàn guitar; âm thanh sẽ không ổn nếu quá chặt hoặc quá lỏng. Sự đánh đổi độ lệch-phương sai là về việc tìm kiếm sự cân bằng hoàn hảo giữa hai điều này. Sự cân bằng sai lệch-phương sai là bản chất của việc điều chỉnh các mô hình thống kê của chúng tôi để hoạt động tốt nhất trong việc dự đoán kết quả một cách chính xác.
Kết luận
Từ lấy mẫu thống kê đến cân bằng độ lệch-phương sai, những nguyên tắc này không chỉ là khái niệm học thuật mà còn là công cụ thiết yếu để phân tích dữ liệu sâu sắc. Họ trang bị cho các nhà khoa học dữ liệu đầy tham vọng những kỹ năng để biến dữ liệu khổng lồ thành những hiểu biết sâu sắc có thể hành động, nhấn mạnh số liệu thống kê là xương sống của việc ra quyết định và đổi mới dựa trên dữ liệu trong thời đại kỹ thuật số.
Chúng ta có bỏ sót khái niệm thống kê cơ bản nào không? Hãy cho chúng tôi biết trong phần bình luận bên dưới đây.
Khám phá của chúng tôi hướng dẫn thống kê từ đầu đến cuối để khoa học dữ liệu biết về chủ đề này!
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

