“Dữ liệu là trung tâm của mọi ứng dụng, quy trình và quyết định kinh doanh. Khi dữ liệu được sử dụng để cải thiện trải nghiệm của khách hàng và thúc đẩy sự đổi mới, nó có thể dẫn đến tăng trưởng kinh doanh.”
– Swami Sivasubramanian, Phó Giám đốc Cơ sở dữ liệu, Phân tích và Học máy tại AWS tại Với cách tiếp cận không có ETL, AWS đang giúp các nhà xây dựng hiện thực hóa các phân tích gần như thời gian thực.
Khách hàng trong các ngành đang ngày càng được thúc đẩy bởi dữ liệu nhiều hơn và tìm cách tăng doanh thu, giảm chi phí cũng như tối ưu hóa hoạt động kinh doanh của họ bằng cách triển khai phân tích gần thời gian thực về dữ liệu giao dịch, từ đó nâng cao tính linh hoạt. Dựa trên nhu cầu của khách hàng và phản hồi của họ, AWS đang đầu tư và phát triển đều đặn theo hướng hiện thực hóa tầm nhìn không ETL của chúng tôi để các nhà xây dựng có thể tập trung hơn vào việc tạo ra giá trị từ dữ liệu thay vì chuẩn bị dữ liệu để phân tích.
Của chúng tôi không ETL Hội nhập với Amazon RedShift tạo điều kiện thuận lợi cho việc di chuyển dữ liệu từ điểm này sang điểm khác để sẵn sàng cho hoạt động phân tích, trí tuệ nhân tạo (AI) và máy học (ML) bằng cách sử dụng Amazon Redshift trên hàng petabyte dữ liệu. Trong vài giây dữ liệu giao dịch được ghi vào hỗ trợ Cơ sở dữ liệu AWS, zero-ETL giúp dữ liệu có sẵn trong Amazon Redshift một cách liền mạch, loại bỏ nhu cầu xây dựng và duy trì các đường dẫn dữ liệu phức tạp thực hiện các hoạt động trích xuất, chuyển đổi và tải (ETL).
Để giúp bạn tập trung vào việc tạo ra giá trị từ dữ liệu thay vì đầu tư thời gian và nguồn lực vào việc xây dựng và quản lý quy trình ETL giữa cơ sở dữ liệu giao dịch và kho dữ liệu, chúng tôi đã công bố bốn giải pháp tích hợp zero-ETL cơ sở dữ liệu AWS với Amazon Redshift tại AWS re:Invent 2023:
Trong bài đăng này, chúng tôi cung cấp hướng dẫn từng bước về cách bắt đầu với phân tích hoạt động gần thời gian thực bằng cách sử dụng Tích hợp zero-ETL của Amazon Aurora PostgreSQL với Amazon Redshift.
Tổng quan về giải pháp
Để tạo tích hợp zero-ETL, bạn chỉ định một Phiên bản tương thích với Amazon Aurora PostgreSQL cụm (tương thích với PostgreSQL 15.4 và hỗ trợ zero-ETL) làm nguồn và kho dữ liệu Redshift làm mục tiêu. Việc tích hợp sao chép dữ liệu từ cơ sở dữ liệu nguồn vào kho dữ liệu đích.
Bạn phải tạo các cụm được cung cấp Aurora PostgreSQL DB trong Môi trường xem trước cơ sở dữ liệu Amazon RDS và dịch chuyển đỏ cụm xem trước được cung cấp or nhóm làm việc xem trước không có máy chủ, tại Khu vực AWS Miền Đông Hoa Kỳ (Ohio). Đối với Amazon Redshift, hãy đảm bảo rằng bạn chọn bản xem trước_2023 để sử dụng tích hợp ETL bằng XNUMX.
Sơ đồ sau minh họa kiến trúc được triển khai trong bài viết này.
Sau đây là các bước cần thiết để thiết lập tích hợp zero-ETL cho giải pháp này. Để có hướng dẫn bắt đầu đầy đủ, hãy tham khảo Làm việc với tích hợp Aurora zero-ETL với Amazon Redshift và Làm việc với tích hợp zero-ETL.
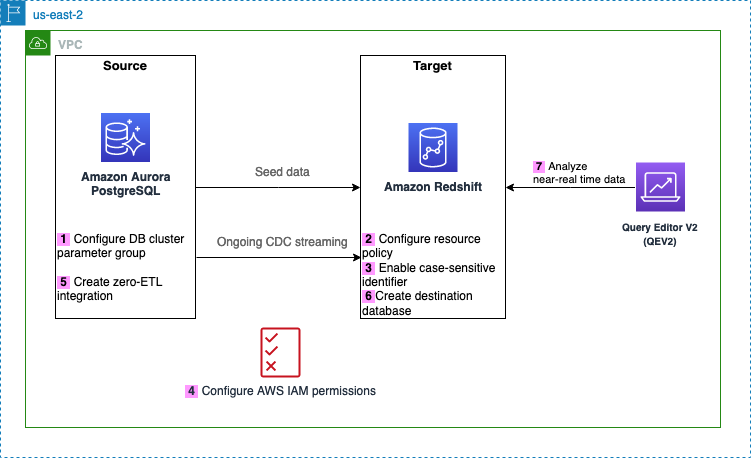
Sau Bước 1, bạn cũng có thể bỏ qua Bước 2–4 và trực tiếp bắt đầu tạo tích hợp zero-ETL từ Bước 5, trong trường hợp đó Amazon RDS sẽ hiển thị thông báo về các cấu hình bị thiếu và bạn có thể chọn Sửa nó cho tôi để cho phép Amazon RDS tự động định cấu hình các bước.
- Định cấu hình nguồn Aurora PostgreSQL bằng nhóm tham số cụm DB tùy chỉnh.
- Định cấu hình Amazon Redshift không có máy chủ đích với chính sách tài nguyên cần thiết cho không gian tên của nó.
- Cập nhật nhóm làm việc Redshift Serverless để bật số nhận dạng phân biệt chữ hoa chữ thường.
- Định cấu hình các quyền cần thiết.
- Tạo tích hợp zero-ETL.
- Tạo cơ sở dữ liệu từ tích hợp trong Amazon Redshift.
- Bắt đầu phân tích dữ liệu giao dịch gần thời gian thực.
Định cấu hình nguồn Aurora PostgreSQL với nhóm tham số cụm DB tùy chỉnh
Đối với cụm cơ sở dữ liệu Aurora PostgreSQL, bạn phải tạo nhóm tham số tùy chỉnh trong Môi trường xem trước cơ sở dữ liệu Amazon RDS, ở Khu vực Miền Đông Hoa Kỳ (Ohio). Bạn có thể truy cập trực tiếp vào Môi trường xem trước Amazon RDS.
Để tạo cơ sở dữ liệu Aurora PostgreSQL, hãy hoàn thành các bước sau:
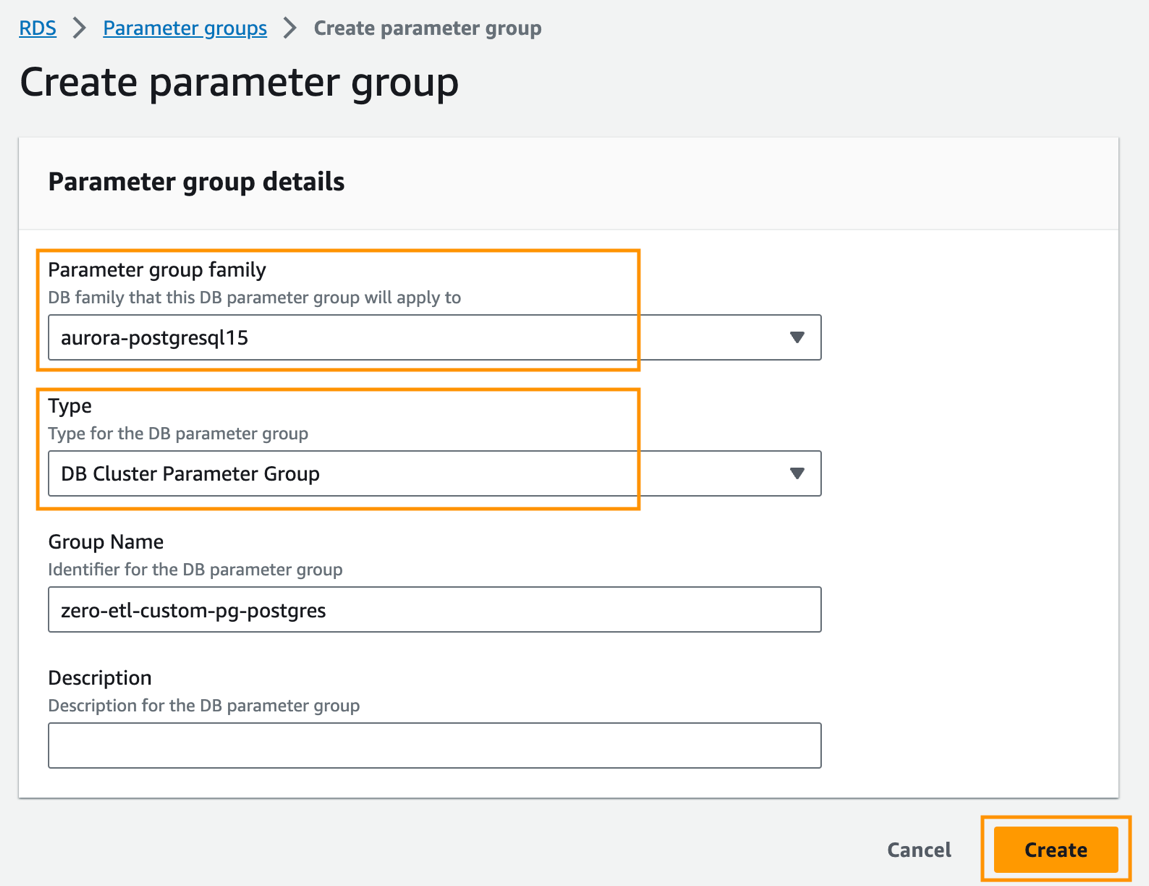
- Trên bảng điều khiển Amazon RDS, chọn Nhóm thông số trong khung điều hướng.
- Chọn Tạo nhóm thông số.
- Trong Họ nhóm thông số, chọn
aurora-postgresql15. - Trong Kiểu, chọn
DB Cluster Parameter Group. - Trong Tên nhóm, hãy nhập tên (ví dụ:
zero-etl-custom-pg-postgres). - Chọn Tạo.
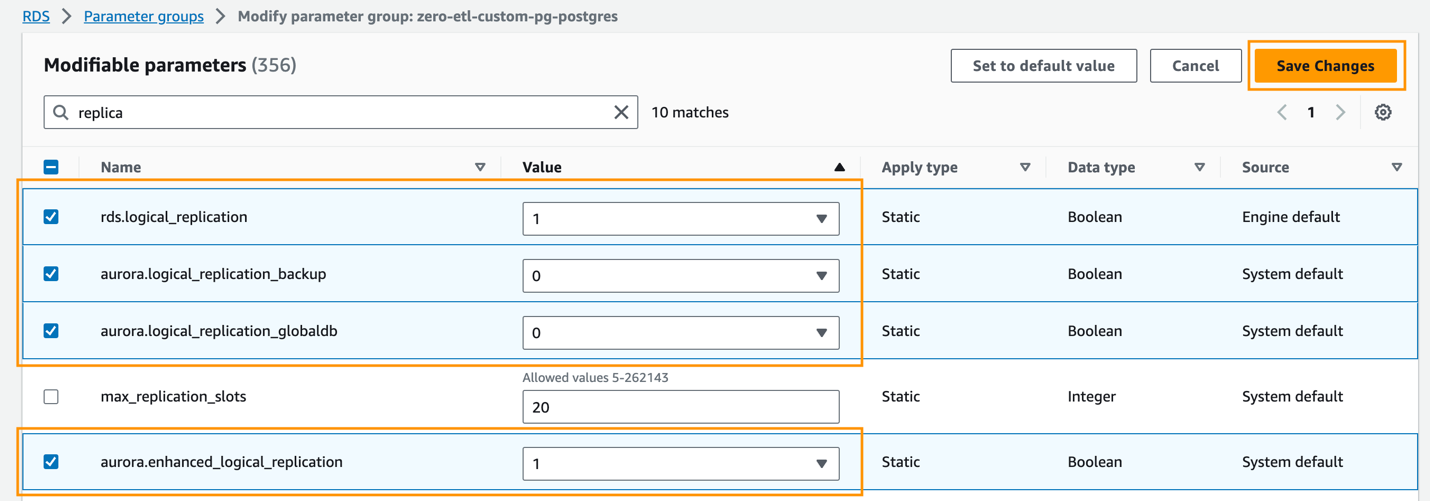
Việc tích hợp zero-ETL của Aurora PostgreSQL với Amazon Redshift yêu cầu các giá trị cụ thể cho Thông số cụm Aurora DB, yêu cầu sao chép logic nâng cao (aurora.enhanced_logic_replication).
- trên Nhóm thông số trang, chọn nhóm tham số mới được tạo.
- trên Hoạt động menu, chọn Chỉnh sửa.
- Đặt Aurora PostgreSQL sau (Gia đình Aurora-postgresql15) cài đặt tham số cụm:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Việc bật sao chép logic nâng cao (aurora.enhanced_logic_replication) sẽ tự động đặt tham số REPLICA IDENTITY thành FULL, nghĩa là tất cả các giá trị cột đều được ghi vào nhật ký ghi trước (WAL).
- Chọn Lưu Thay đổi.
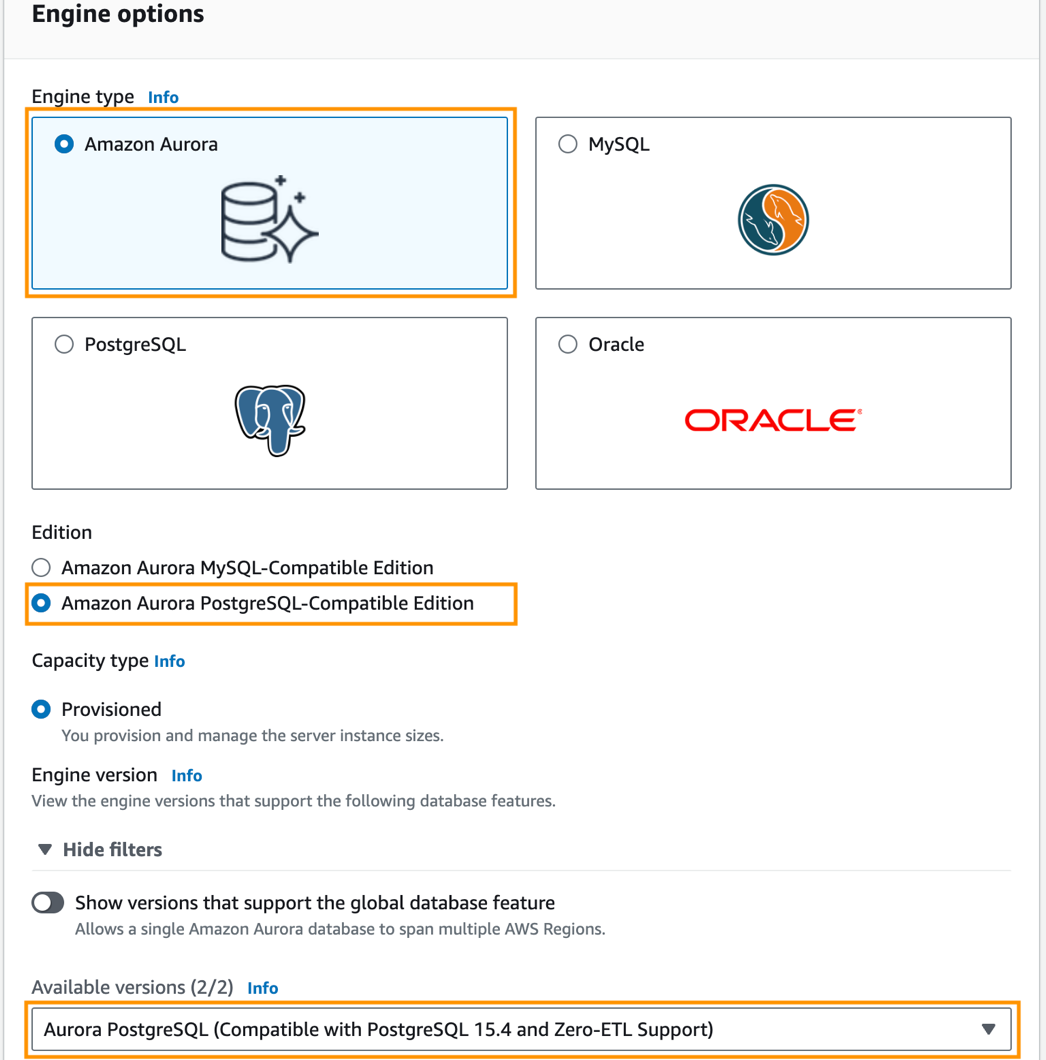
- Chọn Cơ sở dữ liệu trong ngăn điều hướng, sau đó chọn Tạo cơ sở dữ liệu.

- Trong Loại động cơ, lựa chọn Amazon cực quang.
- Trong Phiên bản, lựa chọn Phiên bản tương thích với Amazon Aurora PostgreSQL.
- Trong Các phiên bản có sẵn, chọn Aurora PostgreSQL (tương thích với PostgreSQL 15.4 và Hỗ trợ Zero-ETL).
- Trong Templates, lựa chọn Sản lượng.
- Trong mã định danh cụm DB, đi vào
zero-etl-source-pg.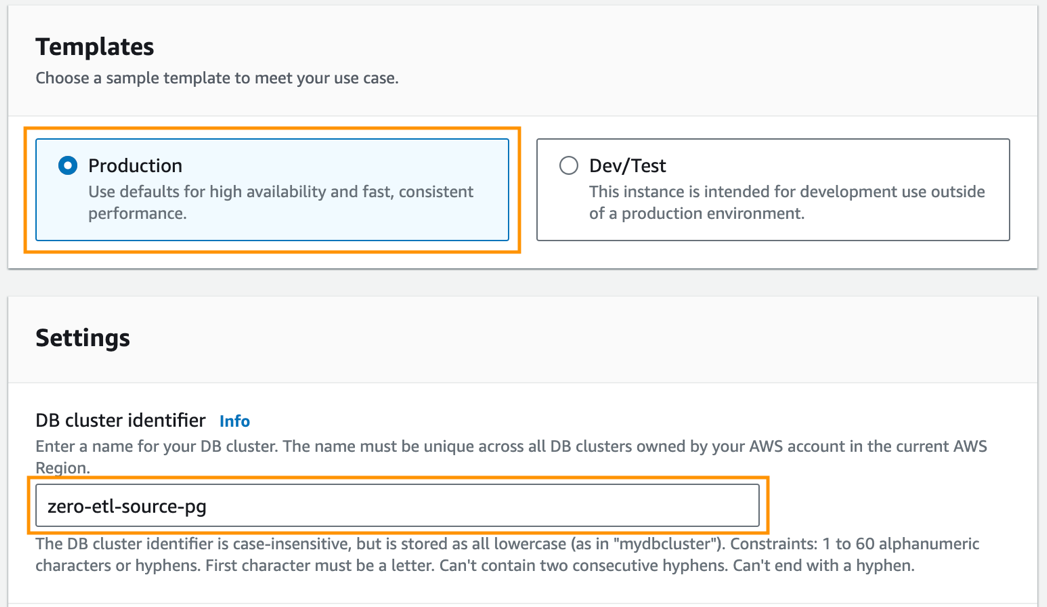
- Theo Cài đặt thông tin xác thực, nhập mật khẩu cho Mật khẩu cấp cao hoặc sử dụng tùy chọn để tự động tạo mật khẩu cho bạn.
- Trong tạp chí Phần cấu hình sơ thẩm, lựa chọn Các lớp tối ưu hóa bộ nhớ.
- Chọn kích thước phiên bản phù hợp (mặc định là
db.r5.2xlarge).
- Theo Cấu hình bổ sung, Cho Nhóm tham số cụm DB, chọn nhóm tham số bạn đã tạo trước đó (
zero-etl-custom-pg-postgres).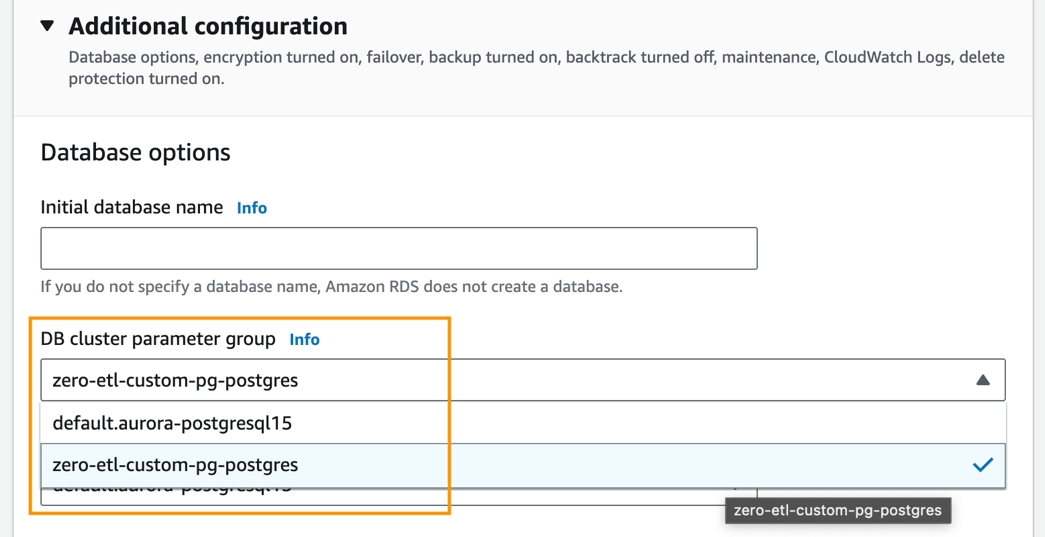
- Để nguyên cài đặt mặc định cho các cấu hình còn lại.
- Chọn Tạo cơ sở dữ liệu.
Trong vài phút, thao tác này sẽ tạo ra một cụm Aurora PostgreSQL, với một phiên bản trình ghi và một trình đọc, với trạng thái thay đổi từ Tạo đến Có Sẵn. Cụm Aurora PostgreSQL mới được tạo sẽ là nguồn cho việc tích hợp zero-ETL.
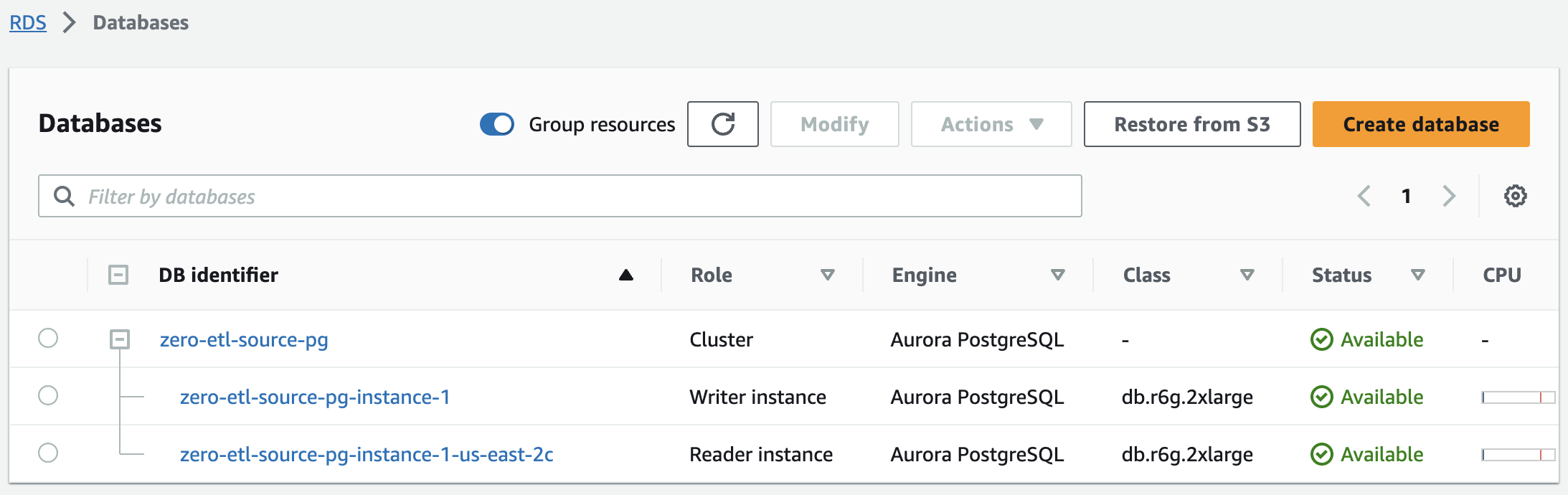
Bước tiếp theo là tạo cơ sở dữ liệu có tên trong Amazon Aurora PostgreSQL để tích hợp zero-ETL.
Mô hình tài nguyên PostgreSQL cho phép bạn tạo nhiều cơ sở dữ liệu trong một cụm. Do đó, trong bước tạo tích hợp zero-ETL, bạn cần chỉ định cơ sở dữ liệu nào bạn muốn sử dụng làm nguồn cho tích hợp của mình.
Khi thiết lập PostgreSQL, bạn sẽ có sẵn ba cơ sở dữ liệu tiêu chuẩn: template0, template1 và postgres. Bất cứ khi nào bạn tạo một cơ sở dữ liệu mới trong PostgreSQL, thực tế là bạn đang dựa trên một trong ba cơ sở dữ liệu này trong cụm của mình. Cơ sở dữ liệu được tạo trong quá trình tạo cụm Aurora PostgreSQL dựa trên template0. Các CREATE DATABASE lệnh hoạt động bằng cách sao chép cơ sở dữ liệu hiện có và nếu không được chỉ định rõ ràng, theo mặc định, nó sẽ sao chép cơ sở dữ liệu hệ thống tiêu chuẩn template1. Đối với cơ sở dữ liệu được đặt tên để tích hợp zero-ETL, cơ sở dữ liệu phải được tạo bằng template1 chứ không phải template0. Vì vậy, nếu tên cơ sở dữ liệu ban đầu được thêm vào dưới Cấu hình bổ sung, nó sẽ được tạo bằng template0 và không thể được sử dụng để tích hợp ETL bằng XNUMX.
- Để tạo cơ sở dữ liệu có tên mới bằng cách sử dụng
CREATE DATABASEtrong cụm Aurora PostgreSQL mớizero-etl-source-pg, trước tiên hãy lấy điểm cuối của phiên bản trình ghi của cụm PostgreSQL.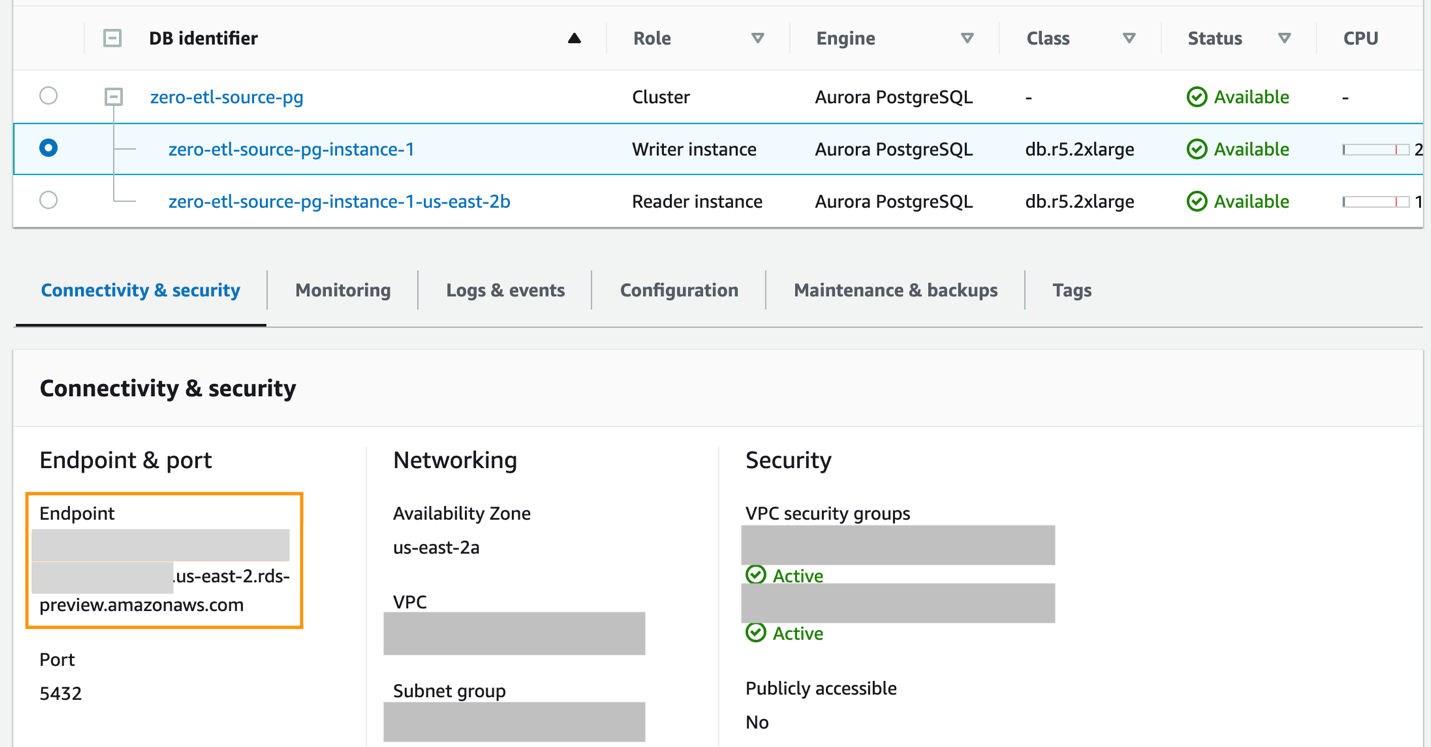
- Từ một thiết bị đầu cuối hoặc sử dụng Đám mây AWS, SSH vào cụm PostgreSQL và chạy các lệnh sau để cài đặt psql và tạo cơ sở dữ liệu mới
zeroetl_db:
Thêm template template1 là tùy chọn, vì theo mặc định, nếu không được đề cập, CREATE DATABASE sẽ sử dụng template1.
Bạn cũng có thể kết nối thông qua máy khách và tạo cơ sở dữ liệu. tham khảo Kết nối với cụm cơ sở dữ liệu Aurora PostgreSQL để biết các tùy chọn kết nối với cụm PostgreSQL.
Định cấu hình Redshift Serverless làm đích
Sau khi tạo cụm cơ sở dữ liệu nguồn Aurora PostgreSQL, bạn đặt cấu hình kho dữ liệu mục tiêu Redshift. Kho dữ liệu phải đáp ứng các yêu cầu sau:
- Được tạo ở dạng xem trước (chỉ dành cho nguồn Aurora PostgreSQL)
- Sử dụng loại nút RA3 (ra3.16xlarge, ra3.4xlarge hoặc ra3.xlplus) với ít nhất hai nút hoặc Redshift Serverless
- Đã mã hóa (nếu sử dụng cụm được cung cấp)
Đối với bài đăng này, chúng tôi tạo và định cấu hình nhóm làm việc và không gian tên Redshift Serverless làm kho dữ liệu mục tiêu, theo các bước sau:
- Trên bảng điều khiển Amazon Redshift, hãy chọn Bảng điều khiển không có máy chủ trong khung điều hướng.
Vì tích hợp zero-ETL cho Amazon Aurora PostgreSQL với Amazon Redshift đã được triển khai ở dạng bản xem trước (không dành cho mục đích sản xuất) nên bạn cần tạo kho dữ liệu đích trong môi trường xem trước.
- Chọn Tạo nhóm làm việc xem trước.
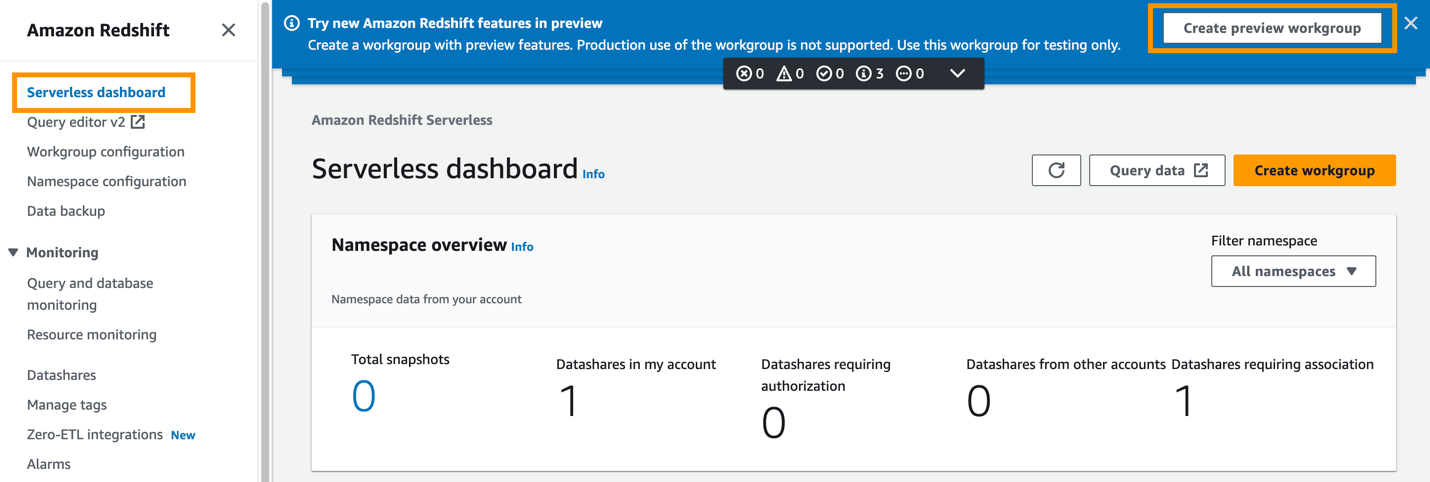
Bước đầu tiên là định cấu hình nhóm làm việc Redshift Serverless.
- Trong tên nhóm làm việc, hãy nhập tên (ví dụ:
zero-etl-target-rs-wg).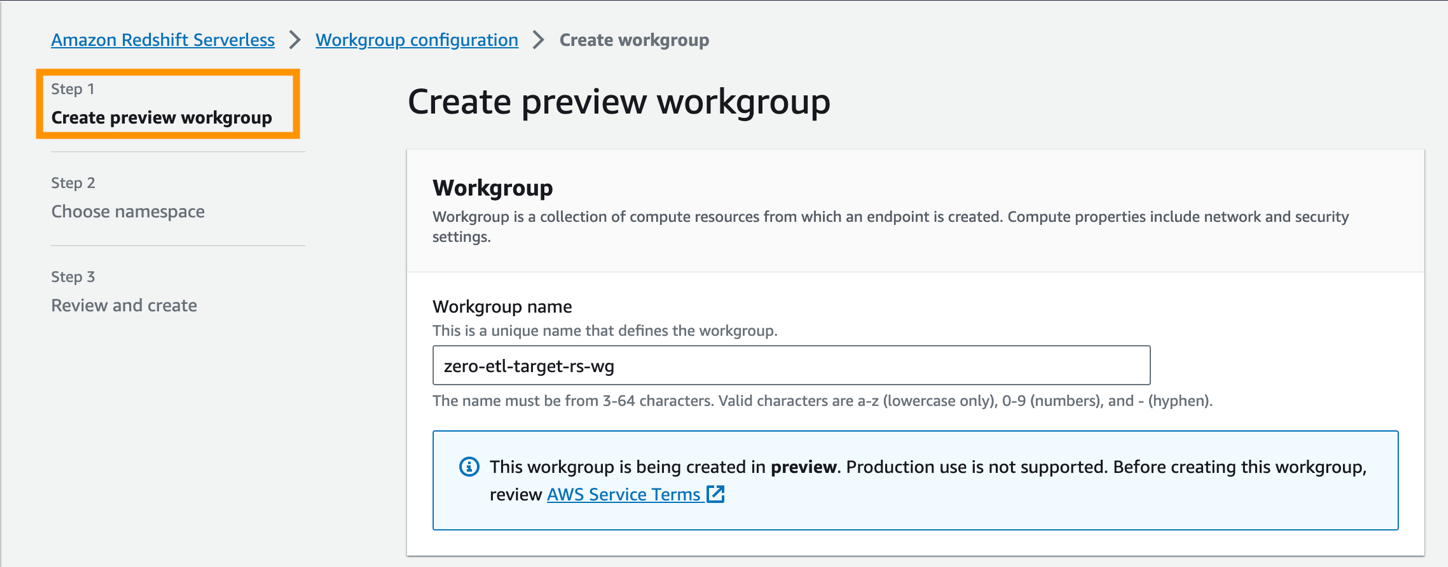
- Ngoài ra, bạn có thể chọn dung lượng để giới hạn tài nguyên tính toán của kho dữ liệu. Công suất có thể được cấu hình theo mức tăng 8, từ 8–512 RPU. Đối với bài đăng này, đặt cái này thành
8RPU. - Chọn Sau.

Tiếp theo, bạn cần định cấu hình không gian tên của kho dữ liệu.
- Chọn Tạo một không gian tên mới.
- Trong Không gian tên, hãy nhập tên (ví dụ:
zero-etl-target-rs-ns). - Chọn Sau.
- Chọn Tạo nhóm làm việc.
- Sau khi nhóm làm việc và không gian tên được tạo, hãy chọn Cấu hình không gian tên trong ngăn điều hướng và mở cấu hình không gian tên.
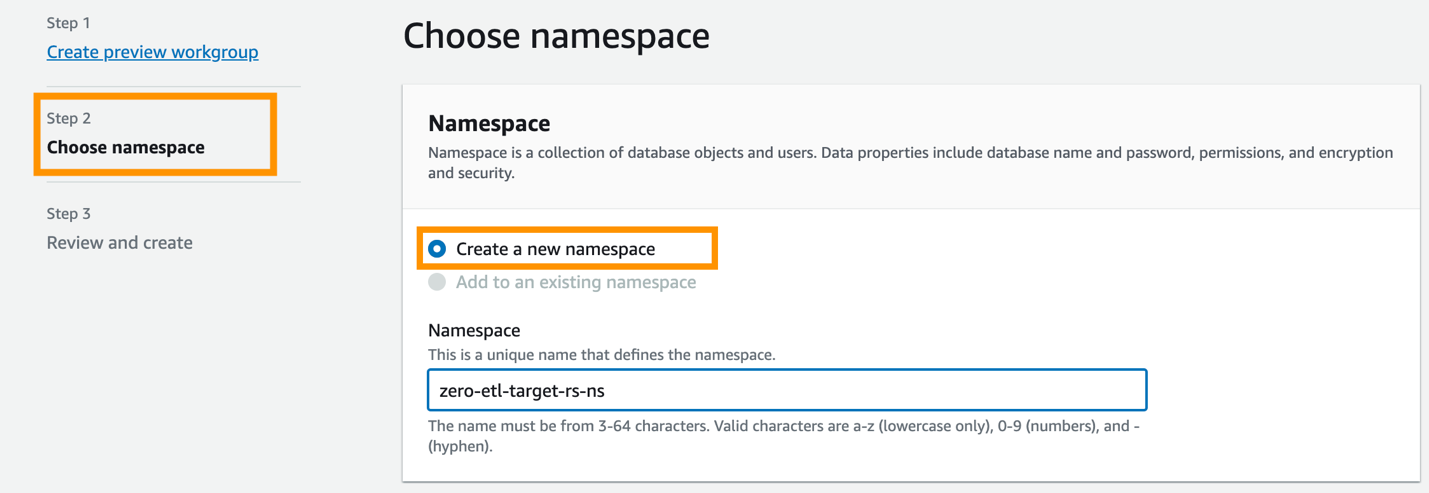
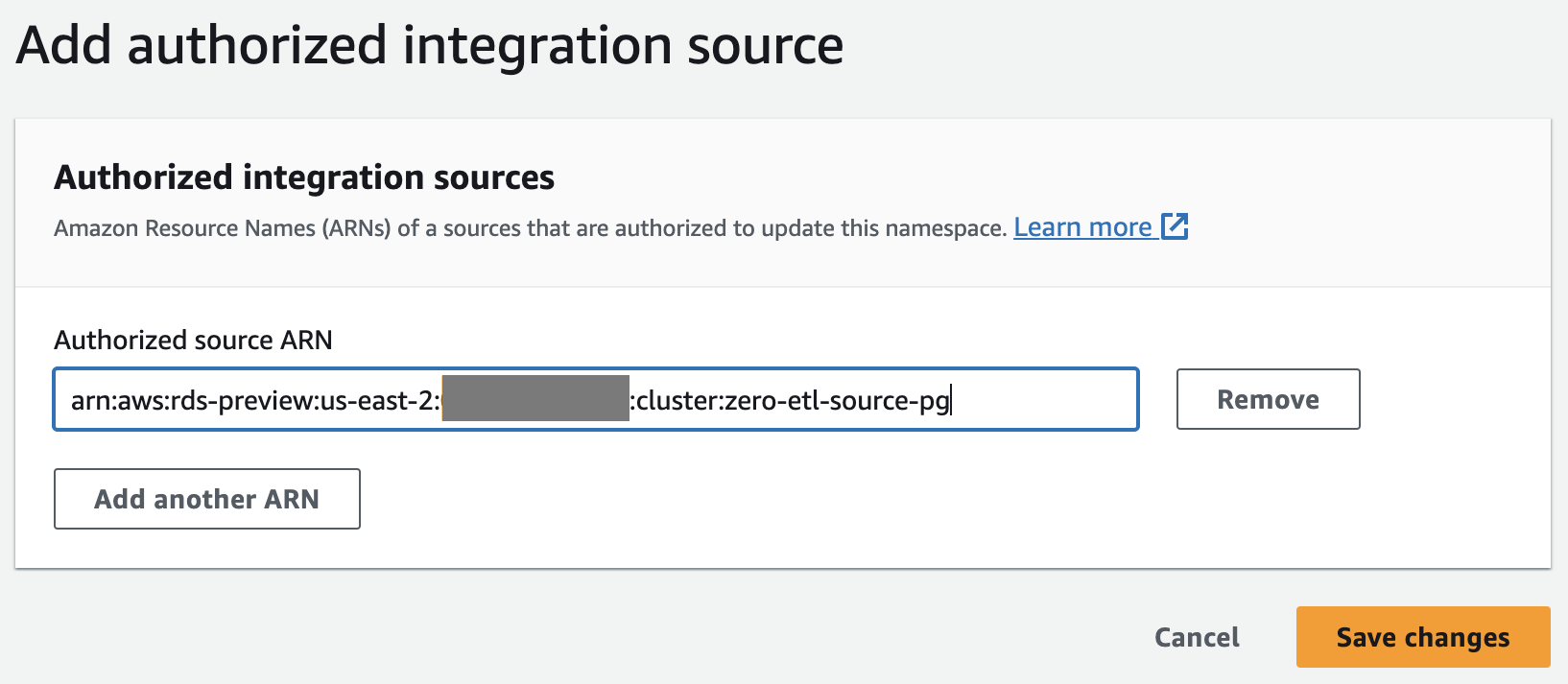
- trên chính sách tài nguyên tab, chọn Thêm hiệu trưởng được ủy quyền.
Hiệu trưởng được ủy quyền xác định người dùng hoặc vai trò có thể tạo tích hợp không ETL vào kho dữ liệu.

- Trong ID tài khoản AWS hoặc ARN chính của IAM, bạn có thể nhập ARN của người dùng hoặc vai trò AWS hoặc ID của tài khoản AWS mà bạn muốn cấp quyền truy cập để tạo tích hợp không ETL. (ID tài khoản được lưu trữ dưới dạng ARN.)
- Chọn Lưu các thay đổi.
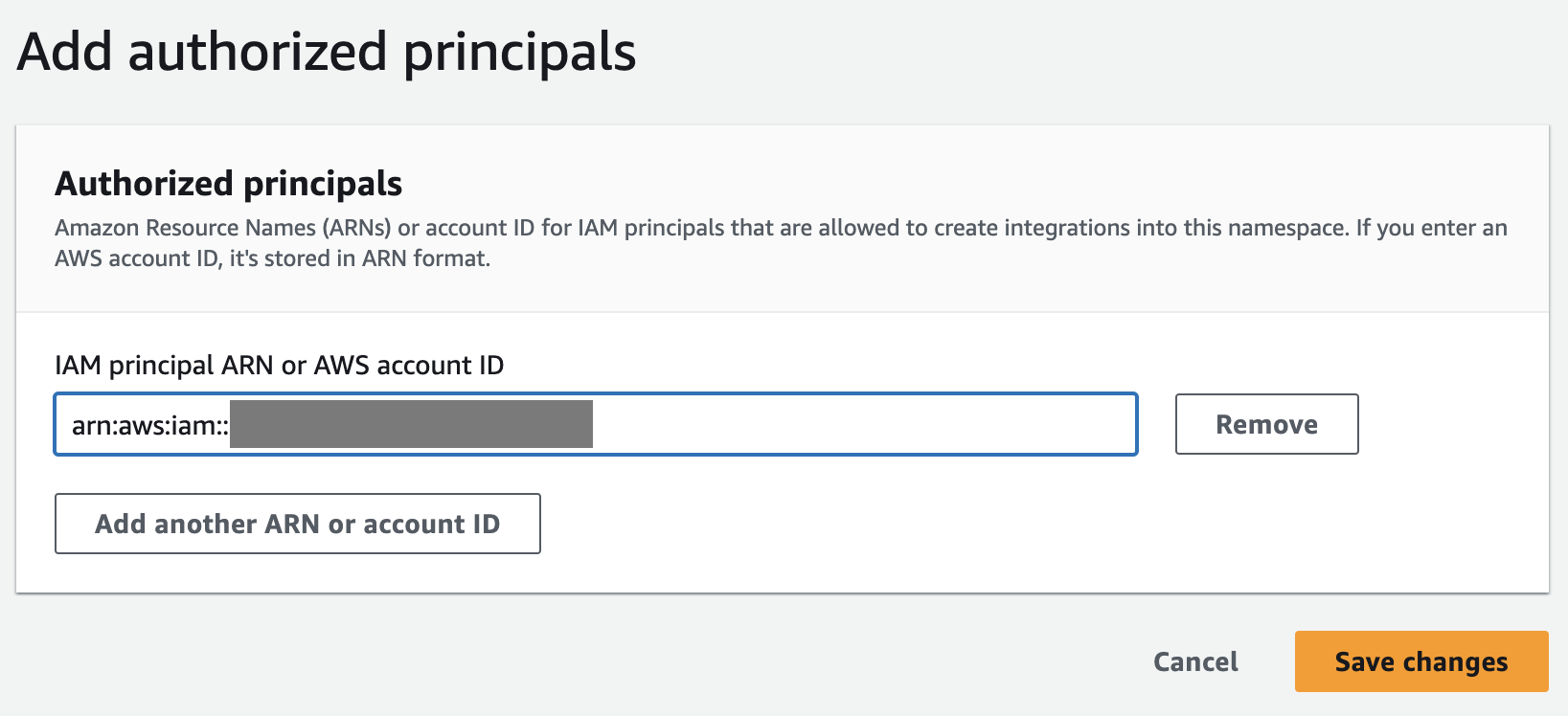
Sau khi định cấu hình Hiệu trưởng được ủy quyền, bạn cần cho phép cơ sở dữ liệu nguồn cập nhật kho dữ liệu Redshift của mình. Do đó, bạn phải thêm cơ sở dữ liệu nguồn làm nguồn tích hợp được ủy quyền vào không gian tên.
- Chọn Thêm nguồn tích hợp được ủy quyền.
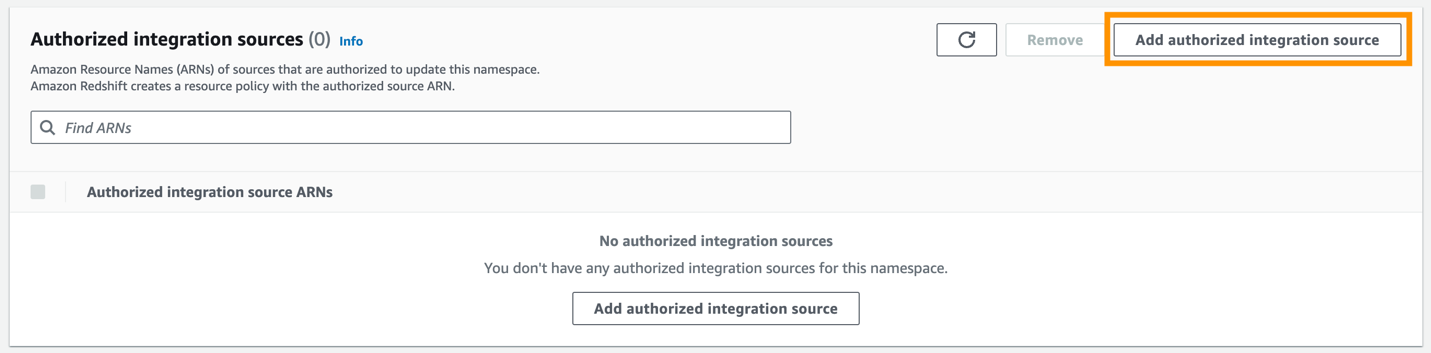
- Trong ARN nguồn được ủy quyền, hãy nhập ARN của cụm Aurora PostgreSQL vì đó là nguồn của tích hợp zero-ETL.
Bạn có thể lấy ARN của cụm Aurora PostgreSQL trên bảng điều khiển Amazon RDS, Cấu hình tab dưới Tên tài nguyên Amazon.
- Chọn Lưu các thay đổi.
Cập nhật nhóm làm việc Redshift Serverless để bật số nhận dạng phân biệt chữ hoa chữ thường
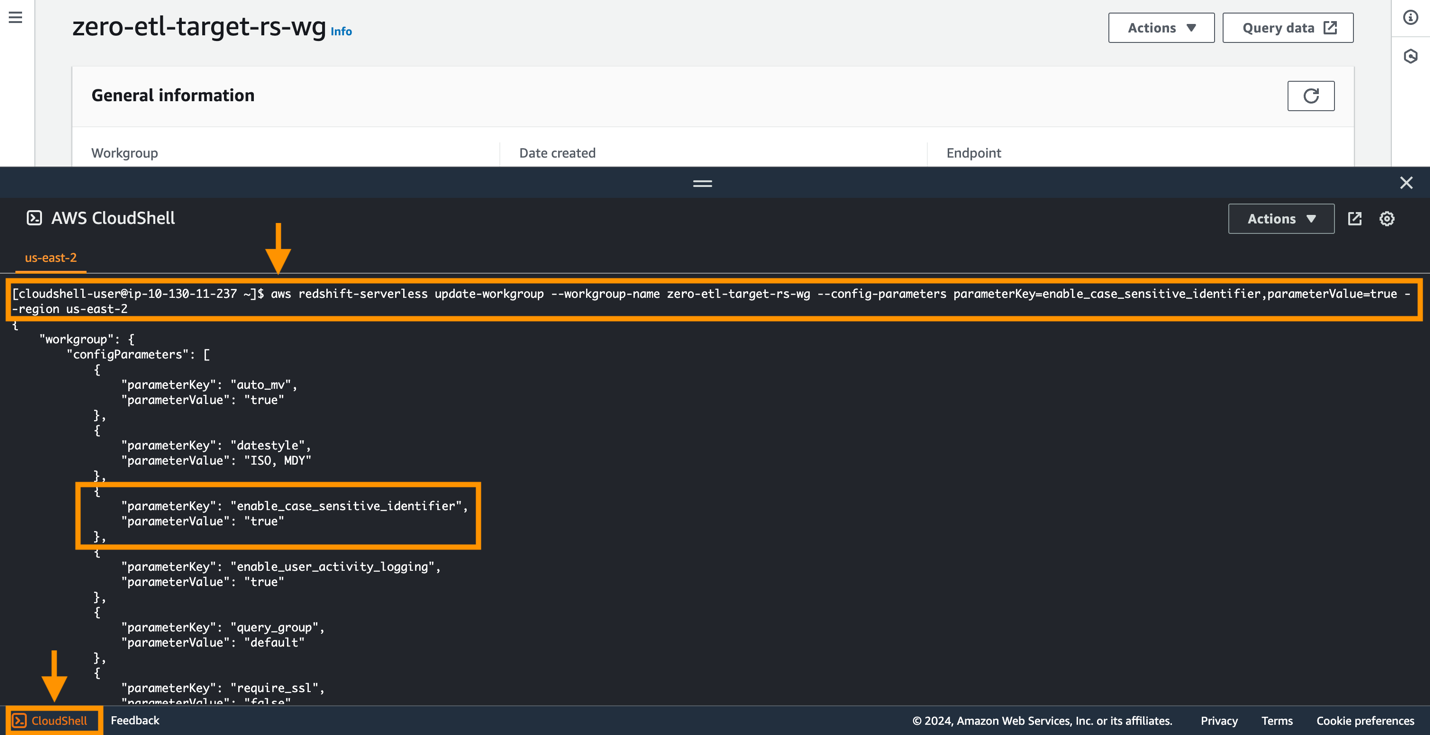
Theo mặc định, Amazon Aurora PostgreSQL có phân biệt chữ hoa chữ thường và tính năng phân biệt chữ hoa chữ thường bị tắt trên tất cả các cụm được cung cấp và nhóm làm việc Redshift Serverless. Để tích hợp thành công, tham số phân biệt chữ hoa chữ thường Enable_case_sensitive_identifier phải được kích hoạt cho kho dữ liệu.
Để sửa đổi enable_case_sensitive_identifier tham số trong nhóm làm việc Redshift Serverless, bạn cần sử dụng Giao diện dòng lệnh AWS (AWS CLI), vì bảng điều khiển Amazon Redshift hiện không hỗ trợ sửa đổi các giá trị tham số Redshift Serverless. Chạy lệnh sau để cập nhật tham số:
Một cách đơn giản để kết nối với AWS CLI là sử dụng CloudShell, một shell dựa trên trình duyệt cung cấp quyền truy cập dòng lệnh vào các tài nguyên và công cụ AWS trực tiếp từ trình duyệt. Ảnh chụp màn hình sau minh họa cách chạy lệnh trong CloudShell.
Định cấu hình các quyền cần thiết
Để tạo tích hợp zero-ETL, người dùng hoặc vai trò của bạn phải có tệp đính kèm chính sách dựa trên danh tính với sự phù hợp Quản lý truy cập và nhận dạng AWS (IAM) quyền. Chủ tài khoản AWS có thể cấu hình các quyền cần thiết dành cho người dùng hoặc vai trò có thể tạo tích hợp không ETL. Chính sách mẫu cho phép hiệu trưởng liên quan thực hiện các hành động sau:
- Tạo tích hợp zero-ETL cho cụm Aurora DB nguồn.
- Xem và xóa tất cả tích hợp zero-ETL.
- Tạo tích hợp gửi đến vào kho dữ liệu mục tiêu. Amazon Redshift có định dạng ARN khác dành cho loại được cung cấp và không có máy chủ:
- Cụm được cung cấp –
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Không có máy chủ –
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Quyền này không bắt buộc nếu cùng một tài khoản sở hữu kho dữ liệu Redshift và tài khoản này là chủ được ủy quyền cho kho dữ liệu đó.
Hoàn thành các bước sau để định cấu hình quyền:
- Trên bảng điều khiển IAM, chọn Điều Luật trong khung điều hướng.
- Chọn Tạo chính sách.
- Tạo một chính sách mới có tên là tích hợp rds bằng cách sử dụng JSON sau đây. Đối với bản xem trước Amazon Aurora PostgreSQL, tất cả ARN và hành động trong Môi trường xem trước cơ sở dữ liệu Amazon RDS có -preview được thêm vào không gian tên dịch vụ. Do đó, trong chính sách sau, thay vì rds, bạn cần sử dụng
rds-preview. Ví dụ,rds-preview:CreateIntegration.
- Đính kèm chính sách bạn đã tạo với quyền của người dùng hoặc vai trò IAM của bạn.
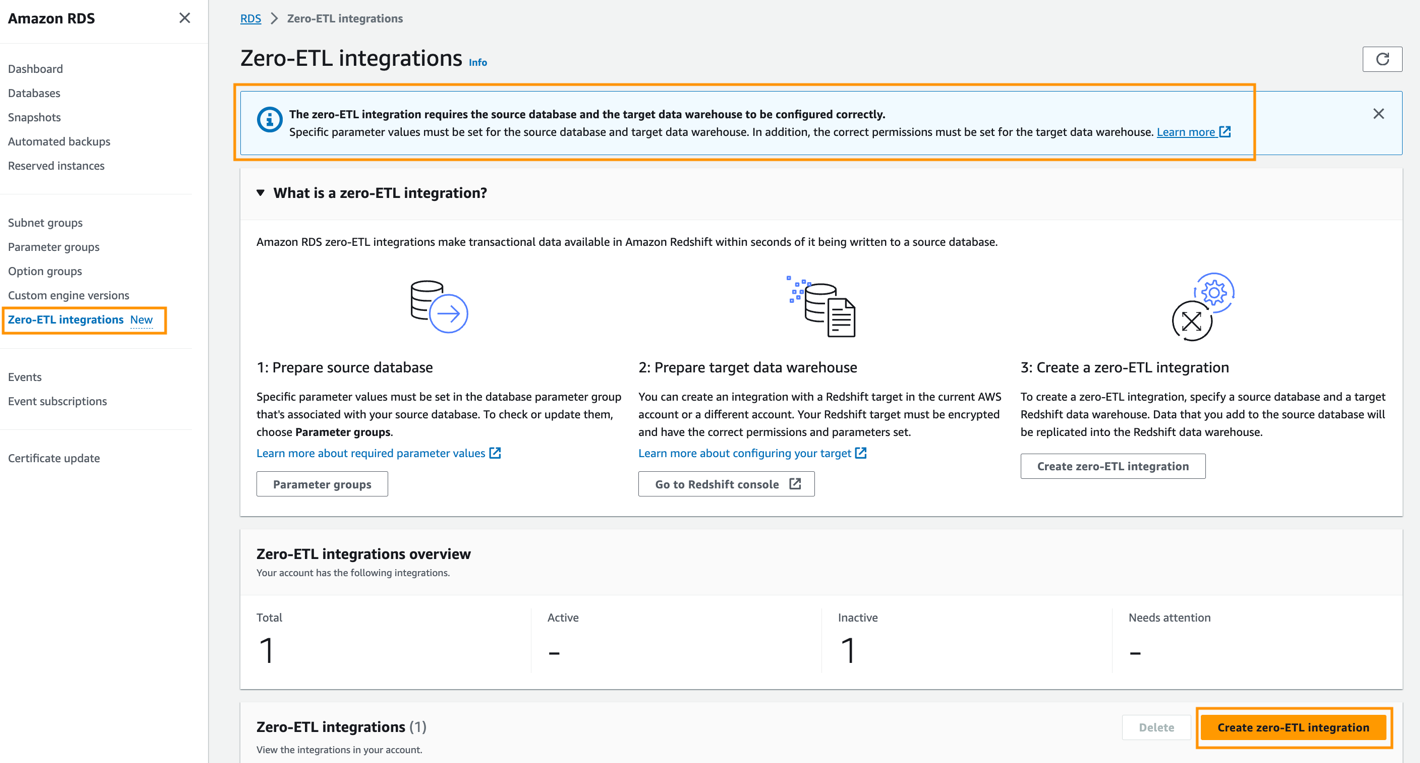
Tạo tích hợp zero-ETL
Để tạo tích hợp zero-ETL, hãy hoàn tất các bước sau:
- Trên bảng điều khiển Amazon RDS, chọn Tích hợp Zero-ETL trong khung điều hướng.
- Chọn Tạo tích hợp zero-ETL.
- Trong Mã định danh tích hợp, nhập tên, ví dụ
zero-etl-demo. - Chọn Sau.

- Trong Cơ sở dữ liệu nguồn, chọn Duyệt cơ sở dữ liệu RDS.
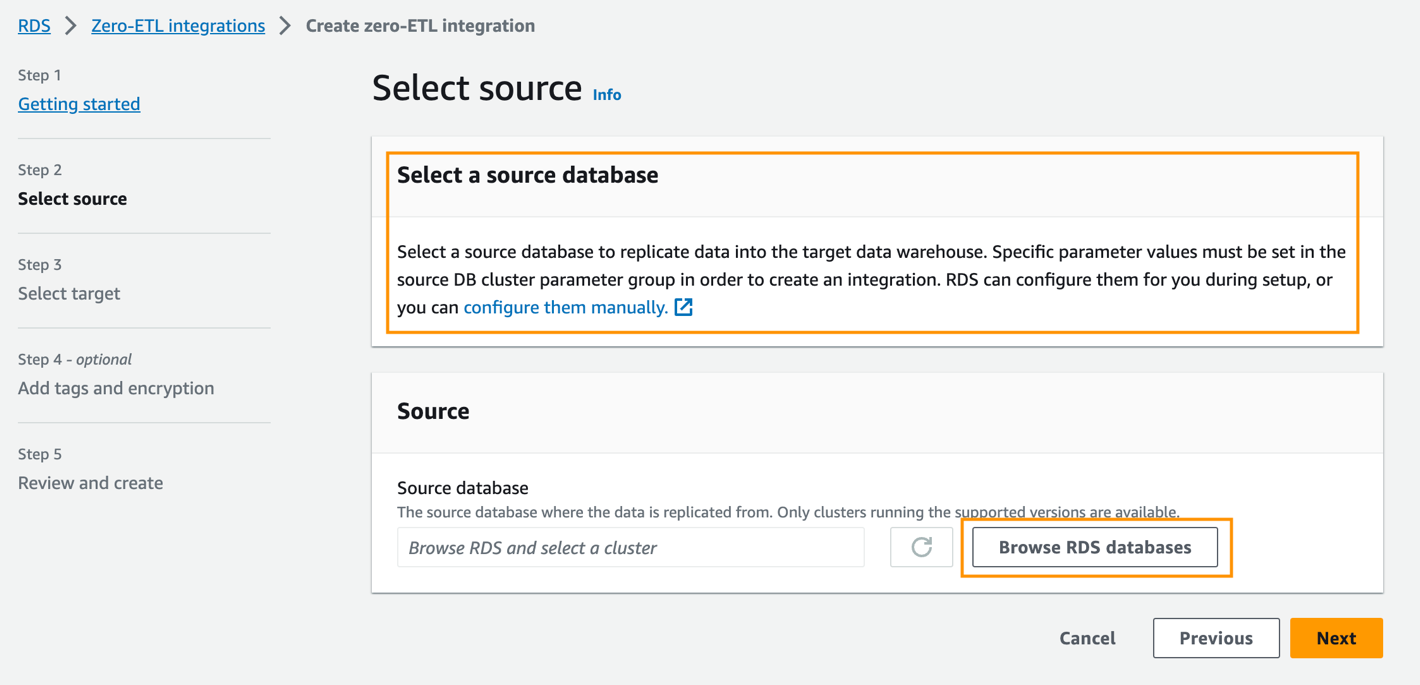
- Chọn cơ sở dữ liệu nguồn
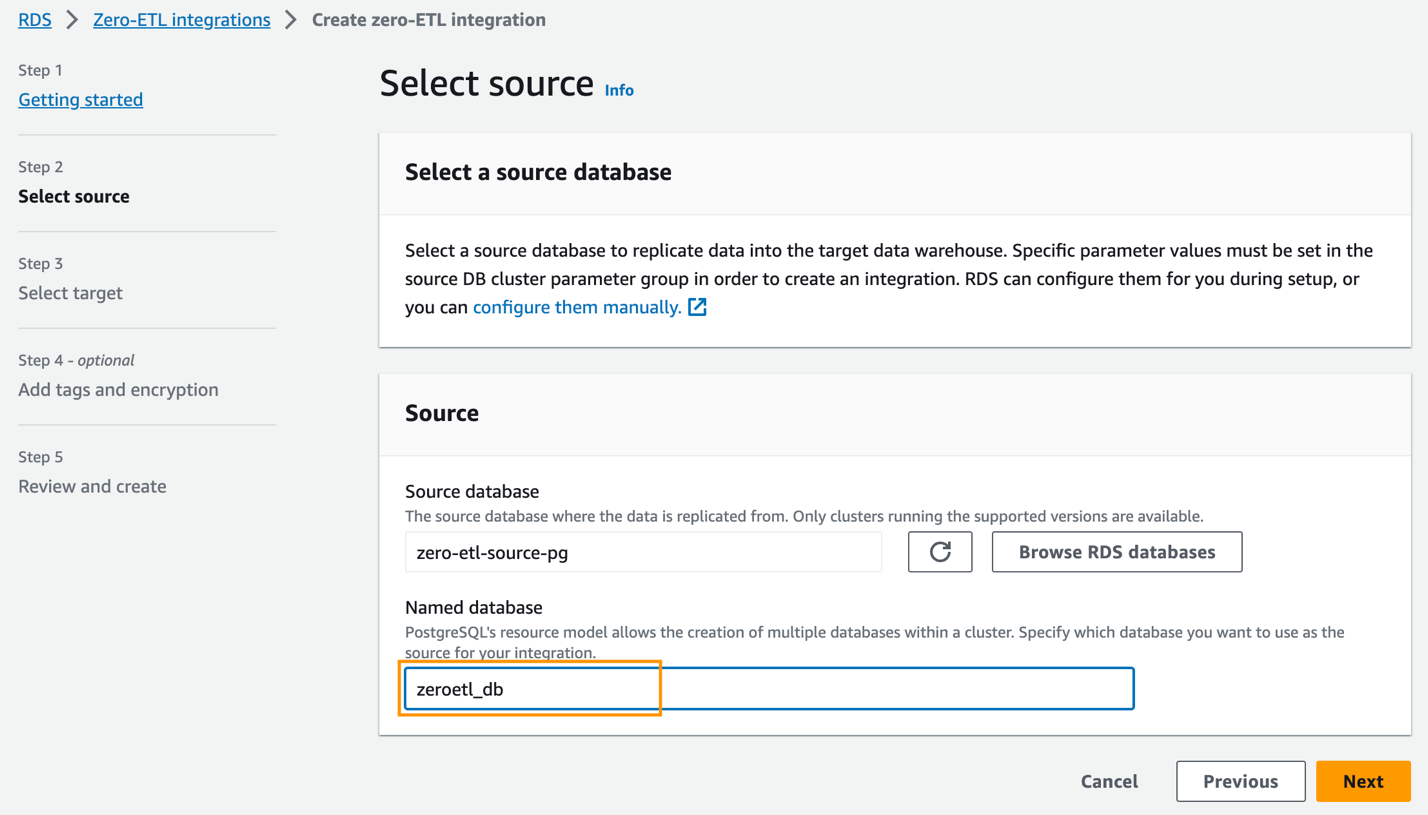
zero-etl-source-pgVà chọn Chọn. - Trong Cơ sở dữ liệu được đặt tên, nhập tên của cơ sở dữ liệu mới được tạo trong Amazon Aurora PostgreSQL (
zeroetl-db). - Chọn Sau.
- Trong tạp chí Phần mục tiêu, Cho Tài khoản AWS, lựa chọn Sử dụng tài khoản hiện tại.
- Trong Kho dữ liệu Amazon Redshift, chọn Duyệt qua kho dữ liệu Redshift.

Chúng tôi thảo luận về Chỉ định một tài khoản khác tùy chọn sau trong phần này.
- Chọn không gian tên đích Redshift Serverless (
zero-etl-target-rs-ns), và lựa chọn Chọn.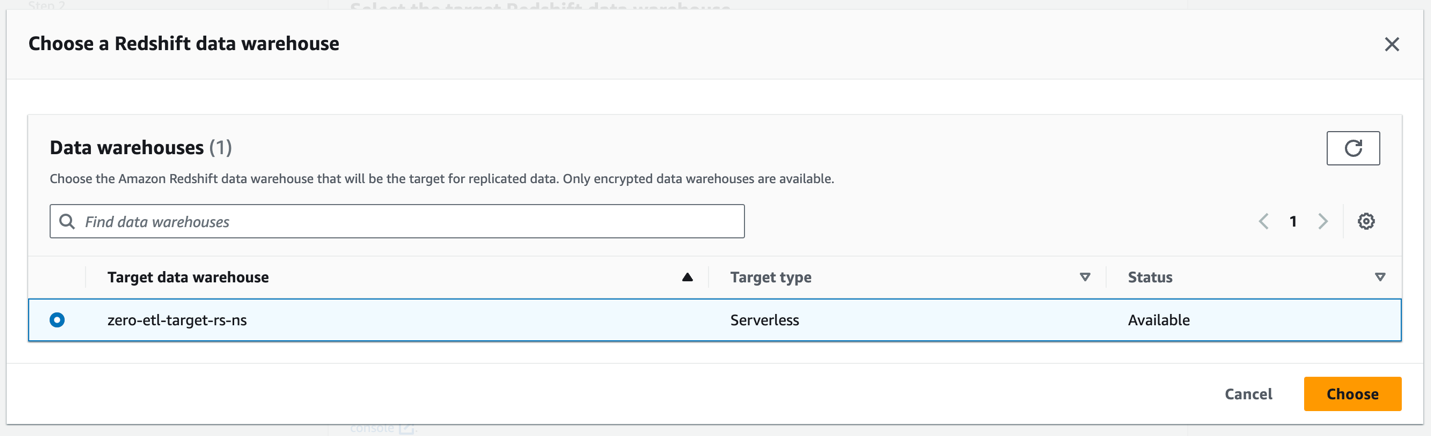
- Thêm thẻ và mã hóa, nếu có, rồi chọn Tiếp theo.
- Xác minh tên tích hợp, nguồn, đích và các cài đặt khác rồi chọn Tạo tích hợp zero-ETL.
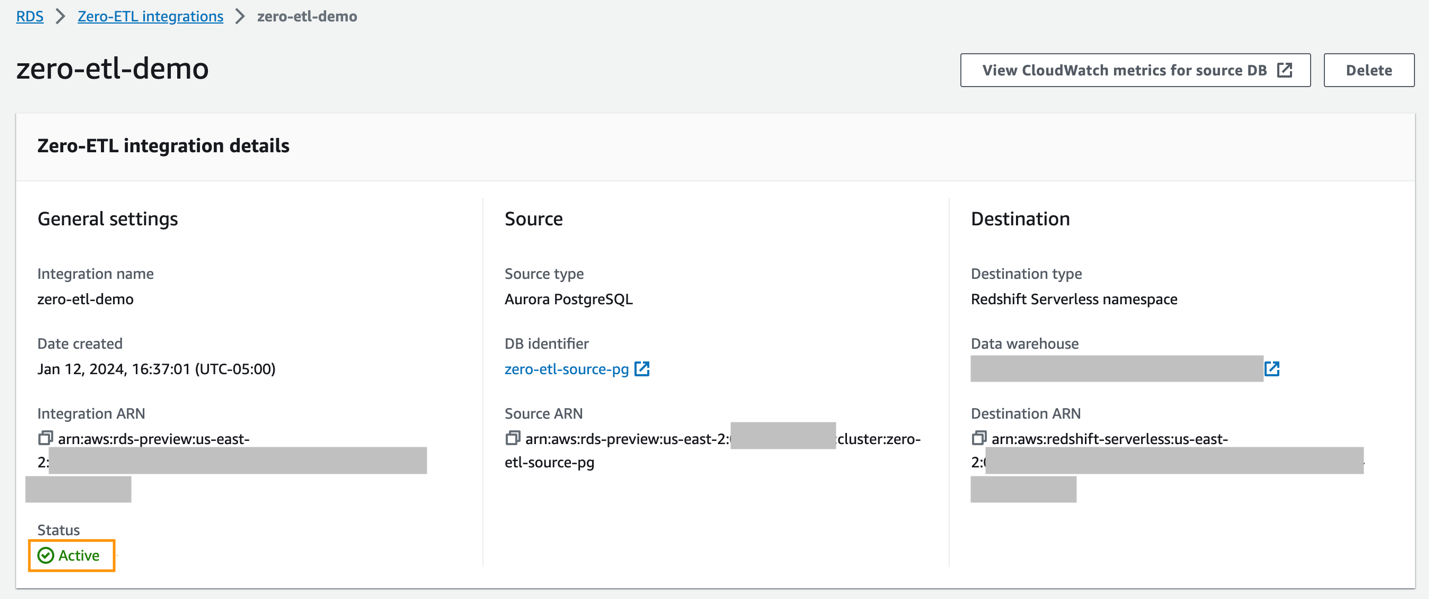
Bạn có thể chọn tích hợp trên bảng điều khiển Amazon RDS để xem chi tiết và theo dõi tiến trình của nó. Mất khoảng 30 phút để thay đổi trạng thái từ Tạo đến hoạt động, tùy thuộc vào kích thước của tập dữ liệu đã có sẵn trong nguồn.
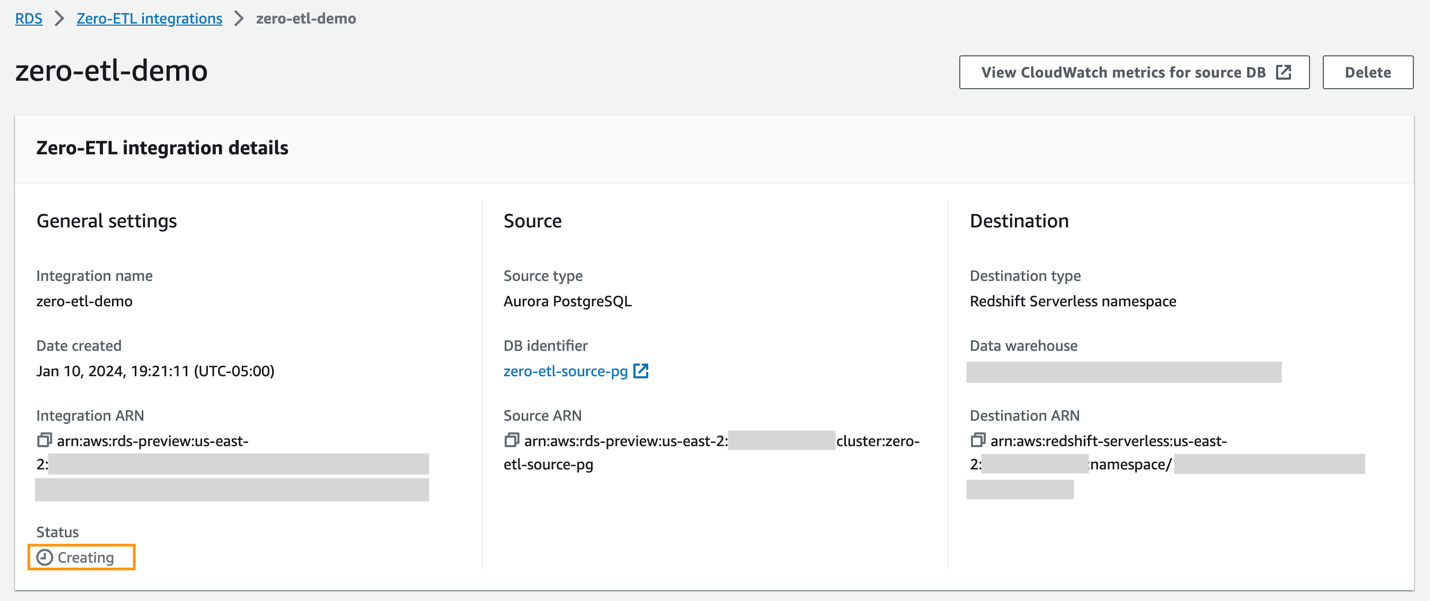
Để chỉ định kho dữ liệu Redshift mục tiêu trong một tài khoản AWS khác, bạn phải tạo một vai trò cho phép người dùng trong tài khoản hiện tại truy cập vào tài nguyên trong tài khoản mục tiêu. Để biết thêm thông tin, hãy tham khảo Cung cấp quyền truy cập cho người dùng IAM trong một tài khoản AWS khác mà bạn sở hữu.
Tạo một vai trò trong tài khoản đích với các quyền sau:
Vai trò phải có chính sách tin cậy sau, chính sách này chỉ định ID tài khoản đích. Bạn có thể thực hiện việc này bằng cách tạo một vai trò với một thực thể đáng tin cậy làm ID tài khoản AWS trong một tài khoản khác.
Ảnh chụp màn hình sau đây minh họa việc tạo này trên bảng điều khiển IAM.
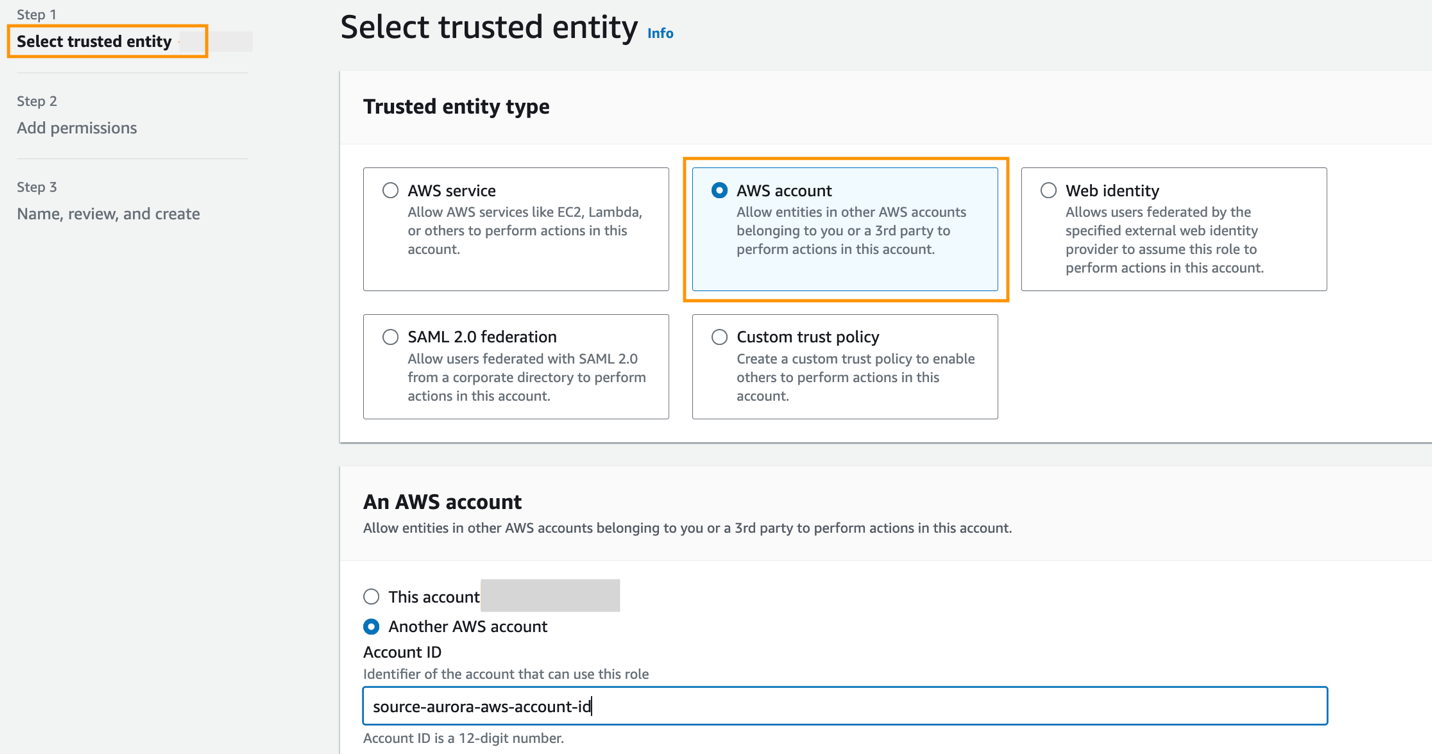
Sau đó, trong khi tạo tích hợp zero-ETL, cho Chỉ định một tài khoản khác, hãy chọn ID tài khoản đích và tên của vai trò bạn đã tạo.
Tạo cơ sở dữ liệu từ tích hợp trong Amazon Redshift
Để tạo cơ sở dữ liệu của bạn, hãy hoàn thành các bước sau:
- Trên bảng điều khiển Redshift Serverless, điều hướng đến
zero-etl-target-rs-nskhông gian tên. - Chọn Dữ liệu truy vấn để mở trình soạn thảo truy vấn v2.

- Kết nối với kho dữ liệu Redshift Serverless bằng cách chọn Tạo kết nối.
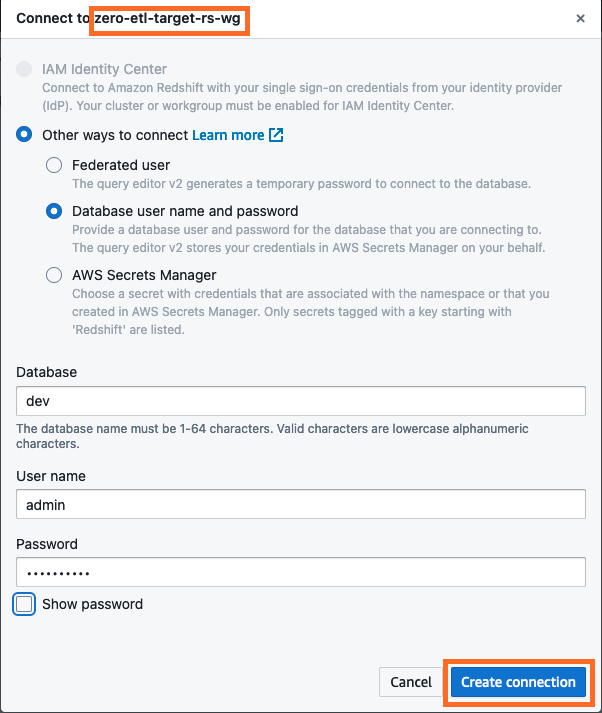
- Có được
integration_idtừsvv_integrationbảng hệ thống: - Sử dụng
integration_idtừ bước trước để tạo cơ sở dữ liệu mới từ quá trình tích hợp. Bạn cũng phải bao gồm một tham chiếu đến cơ sở dữ liệu được đặt tên trong cụm mà bạn đã chỉ định khi tạo tiện ích tích hợp.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
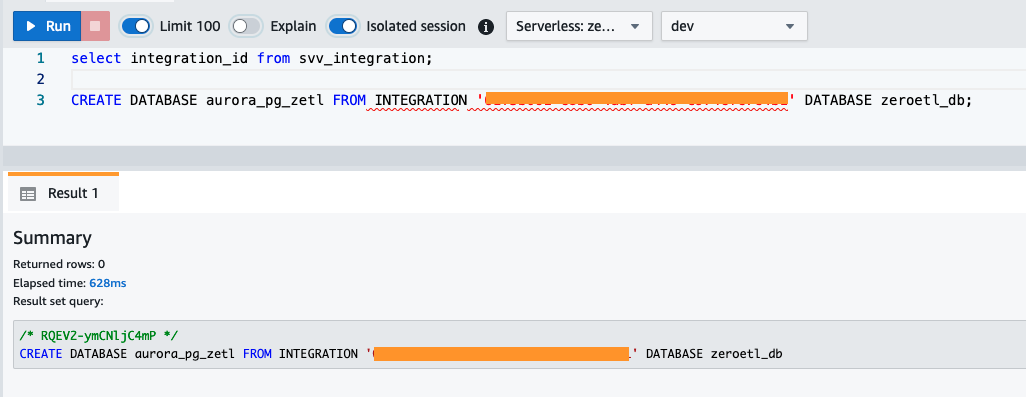
Quá trình tích hợp hiện đã hoàn tất và toàn bộ ảnh chụp nhanh của nguồn sẽ phản ánh như ở đích. Những thay đổi đang diễn ra sẽ được đồng bộ hóa gần như theo thời gian thực.
Phân tích dữ liệu giao dịch gần thời gian thực
Giờ đây, bạn có thể bắt đầu phân tích dữ liệu gần thời gian thực từ nguồn Amazon Aurora PostgreSQL đến mục tiêu Amazon Redshift:
- Kết nối với cơ sở dữ liệu Aurora PostgreSQL nguồn của bạn. Trong bản demo này, chúng tôi sử dụng psql để kết nối với Amazon Aurora PostgreSQL:

- Tạo một bảng mẫu có khóa chính. Đảm bảo rằng tất cả các bảng được sao chép từ nguồn tới đích đều có khóa chính. Các bảng không có khóa chính không thể được sao chép sang mục tiêu.
- Chèn dữ liệu giả vào bảng quốc gia và xác minh xem dữ liệu có được tải đúng cách hay không:

Dữ liệu mẫu này bây giờ sẽ được sao chép trong Amazon Redshift.
Phân tích dữ liệu nguồn ở đích
Trên bảng thông tin Redshift Serverless, hãy mở trình soạn thảo truy vấn v2 và kết nối với cơ sở dữ liệu aurora_pg_zetl bạn đã tạo trước đó.
Chạy truy vấn sau để xác thực việc sao chép thành công dữ liệu nguồn vào Amazon Redshift:
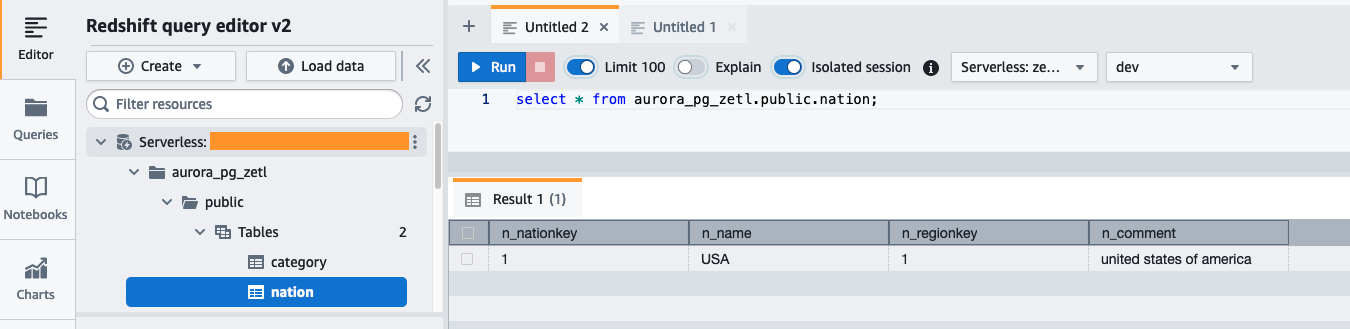
Bạn cũng có thể sử dụng truy vấn sau để xác thực hoạt động chụp nhanh ban đầu hoặc hoạt động thu thập dữ liệu thay đổi đang diễn ra (CDC):
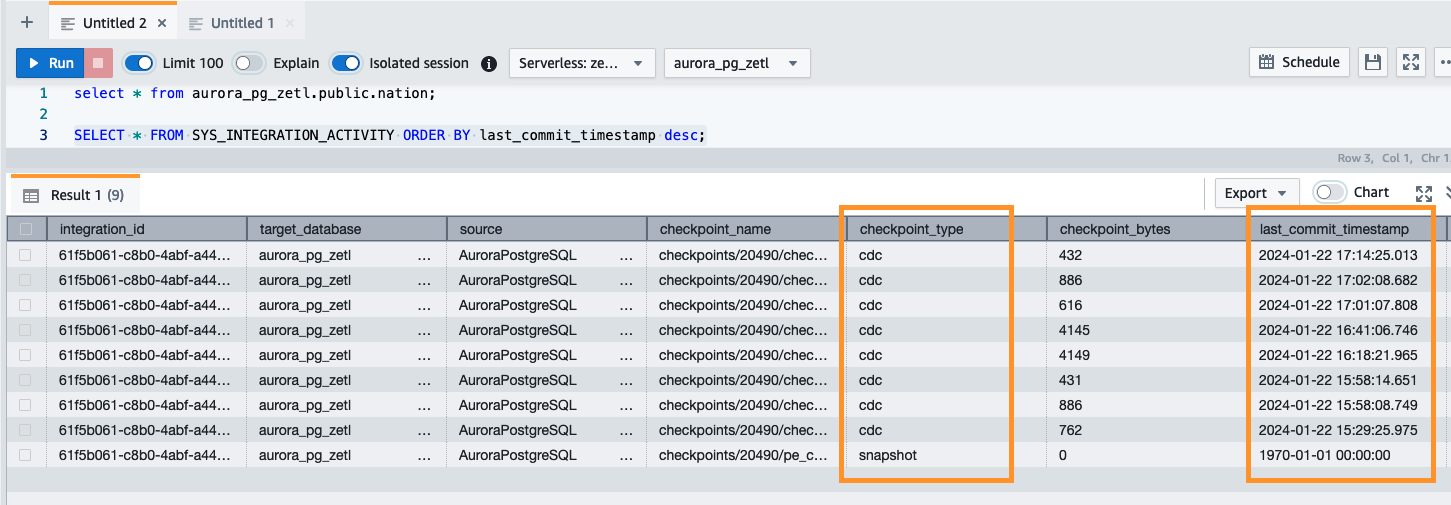
Giám sát
Có một số tùy chọn để lấy số liệu về hiệu suất và trạng thái tích hợp zero-ETL của Aurora PostgreSQL với Amazon Redshift.
Nếu bạn điều hướng đến bảng điều khiển Amazon Redshift, bạn có thể chọn Tích hợp Zero-ETL trong ngăn điều hướng. Bạn có thể chọn tích hợp zero-ETL mà bạn muốn và hiển thị amazoncloudwatch các chỉ số liên quan đến tích hợp. Các số liệu này cũng có sẵn trực tiếp trong CloudWatch.
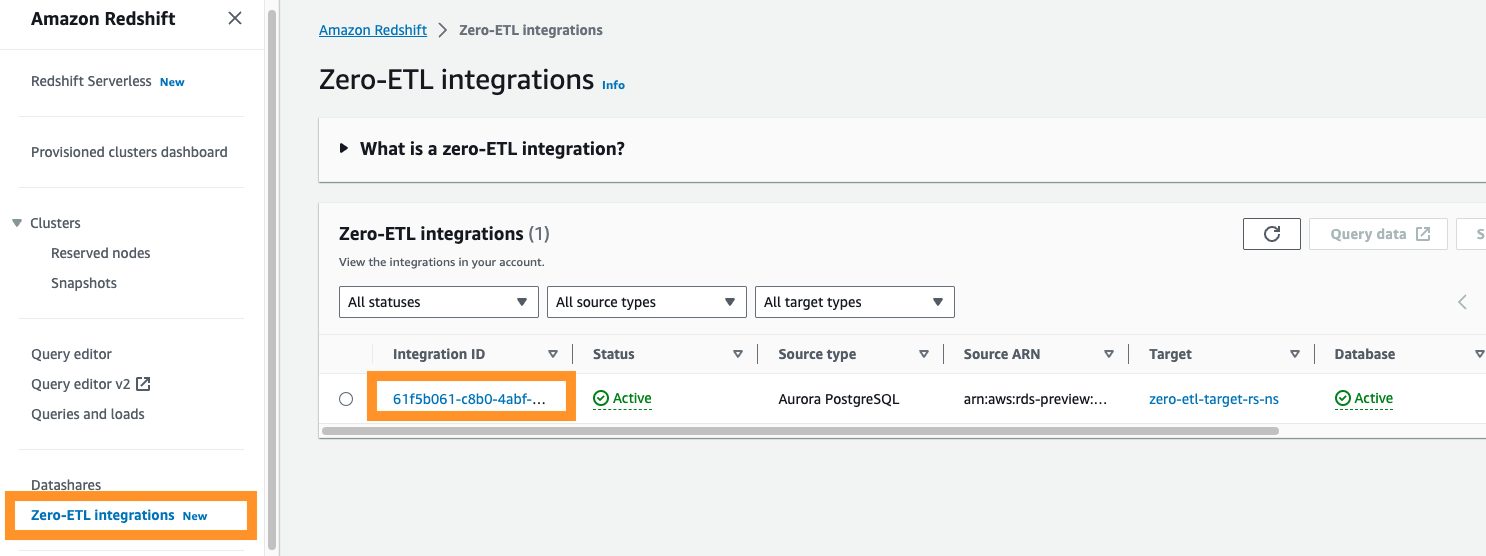
Đối với mỗi tích hợp, có hai tab có sẵn thông tin:
- Số liệu tích hợp – Hiển thị các số liệu như số lượng bảng được sao chép thành công và chi tiết độ trễ
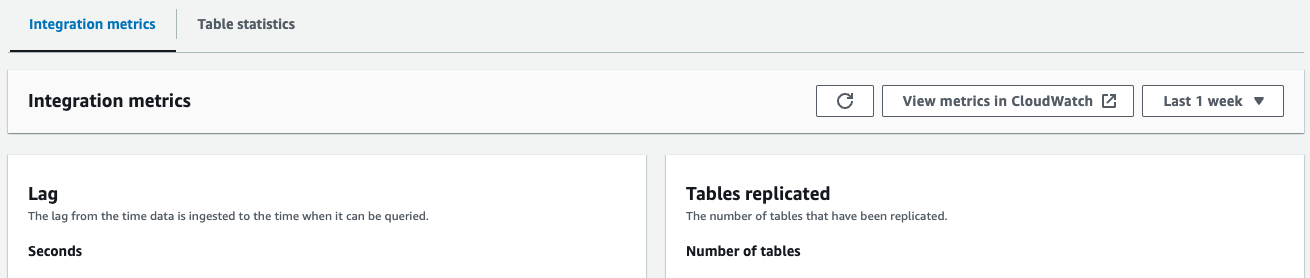
- Bảng thống kê – Hiển thị chi tiết về từng bảng được sao chép từ Amazon Aurora PostgreSQL sang Amazon Redshift
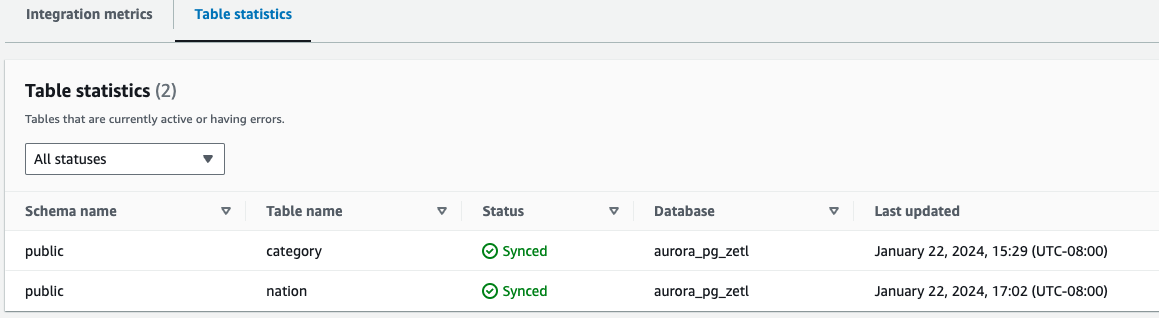
Ngoài các số liệu CloudWatch, bạn có thể truy vấn các thông tin sau chế độ xem hệ thống, cung cấp thông tin về sự tích hợp:
Làm sạch
Khi bạn xóa tích hợp không ETL, dữ liệu giao dịch của bạn sẽ không bị xóa khỏi Aurora hoặc Amazon Redshift nhưng Aurora không gửi dữ liệu mới tới Amazon Redshift.
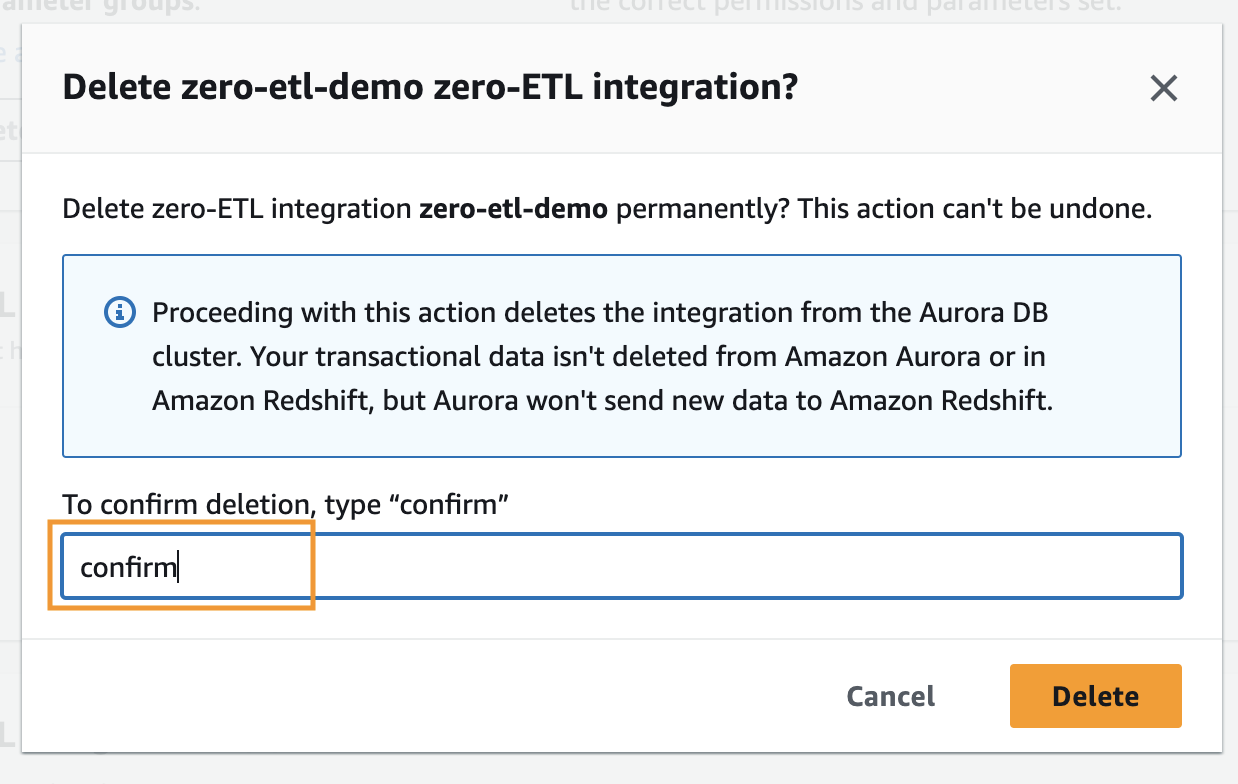
Để xóa tích hợp zero-ETL, hãy hoàn tất các bước sau:
- Trên bảng điều khiển Amazon RDS, chọn Tích hợp Zero-ETL trong khung điều hướng.
- Chọn tích hợp zero-ETL mà bạn muốn xóa và chọn Xóa bỏ.

- Để xác nhận việc xóa, hãy nhập xác nhận và chọn Xóa bỏ.
Kết luận
Trong bài đăng này, chúng tôi đã giải thích cách bạn có thể thiết lập tích hợp zero-ETL từ Amazon Aurora PostgreSQL sang Amazon Redshift, một tính năng giúp giảm nỗ lực duy trì quy trình dữ liệu và cho phép phân tích dữ liệu vận hành và giao dịch gần như theo thời gian thực.
Để tìm hiểu thêm về tích hợp zero-ETL, hãy tham khảo Làm việc với tích hợp Aurora zero-ETL với Amazon Redshift và Hạn chế.
Về các tác giả
 Raks Khare là Kiến trúc sư Giải pháp Chuyên gia Phân tích tại AWS có trụ sở tại Pennsylvania. Anh ấy giúp khách hàng kiến trúc các giải pháp phân tích dữ liệu ở quy mô lớn trên nền tảng AWS.
Raks Khare là Kiến trúc sư Giải pháp Chuyên gia Phân tích tại AWS có trụ sở tại Pennsylvania. Anh ấy giúp khách hàng kiến trúc các giải pháp phân tích dữ liệu ở quy mô lớn trên nền tảng AWS.
 Juan Luis Polo Garzon là Kiến trúc sư giải pháp chuyên gia liên kết tại AWS, chuyên về khối lượng công việc phân tích. Anh có kinh nghiệm giúp khách hàng thiết kế, xây dựng và hiện đại hóa các giải pháp phân tích dựa trên đám mây của họ. Ngoài công việc, anh ấy thích đi du lịch, hoạt động ngoài trời, đi bộ đường dài và tham dự các sự kiện âm nhạc trực tiếp.
Juan Luis Polo Garzon là Kiến trúc sư giải pháp chuyên gia liên kết tại AWS, chuyên về khối lượng công việc phân tích. Anh có kinh nghiệm giúp khách hàng thiết kế, xây dựng và hiện đại hóa các giải pháp phân tích dựa trên đám mây của họ. Ngoài công việc, anh ấy thích đi du lịch, hoạt động ngoài trời, đi bộ đường dài và tham dự các sự kiện âm nhạc trực tiếp.
 Sushmita Barthakur là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services, hỗ trợ khách hàng Doanh nghiệp xây dựng khối lượng công việc của họ trên AWS. Với nền tảng vững chắc về Phân tích dữ liệu và Quản lý dữ liệu, cô có nhiều kinh nghiệm giúp khách hàng kiến trúc và xây dựng Giải pháp phân tích và thông minh doanh nghiệp, cả tại chỗ và đám mây. Sushmita sống ở Tampa, FL và thích đi du lịch, đọc sách và chơi quần vợt.
Sushmita Barthakur là Kiến trúc sư giải pháp cấp cao tại Amazon Web Services, hỗ trợ khách hàng Doanh nghiệp xây dựng khối lượng công việc của họ trên AWS. Với nền tảng vững chắc về Phân tích dữ liệu và Quản lý dữ liệu, cô có nhiều kinh nghiệm giúp khách hàng kiến trúc và xây dựng Giải pháp phân tích và thông minh doanh nghiệp, cả tại chỗ và đám mây. Sushmita sống ở Tampa, FL và thích đi du lịch, đọc sách và chơi quần vợt.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

