Veriler üretken yapay zekanızı farklılaştıran unsurdur ve başarılı bir üretken yapay zeka uygulama, kapsamlı bir veri stratejisi içeren sağlam bir veri stratejisine bağlıdır. Veri yönetimi yaklaşmak. Kurumsal kullanım örnekleri için büyük dil modelleriyle (LLM'ler) çalışmak, sorumlu yapay zekayı desteklemek için kalite ve gizlilik hususlarının uygulanmasını gerektirir. Ancak silolanmış kaynaklardan oluşturulan kurumsal veriler, veri entegrasyon stratejisinin eksikliğiyle birleştiğinde, üretken yapay zeka uygulamaları için verilerin sağlanmasında zorluklar yaratıyor. Uçtan uca bir ihtiyaç veri yönetimi stratejisi Verilerin alınması, saklanması ve sorgulanmasından yapay zeka (AI) ve makine öğrenimi (ML) modellerinin analiz edilmesine, görselleştirilmesine ve çalıştırılmasına kadar yolculuğun her adımında veri yönetimi ve veri yönetimi, kuruluşlar için büyük önem taşımaya devam ediyor.
Bu yazıda, kullanıcı istemlerine verilen yanıtların doğruluğunu ve uygunluğunu güvenli, emniyetli ve şeffaf bir şekilde geliştirmek için LLM'ler tarafından kullanılan verileri yönetmek için kritik bir yapı taşı olan üretken AI uygulama veri boru hatlarının veri yönetişimi ihtiyaçlarını tartışıyoruz. Kuruluşlar bunu, Erişim Artırılmış Üretim (RAG), ince ayar ve temel modellerle sürekli ön eğitim gibi yaklaşımlarla özel verileri kullanarak yapıyor.
Veri yönetişimi, tüm bu yaklaşımlar arasında kritik bir yapı taşıdır ve ortaya çıkan iki odak alanı görüyoruz. İlk olarak, birçok LLM kullanım durumu, veri ambarlarından alınan yapılandırılmış verilere ek olarak belgeler, transkriptler ve görüntüler gibi yapılandırılmamış verilerden alınması gereken kurumsal bilgiye dayanır. Yapılandırılmamış veriler genellikle silolanmış sistemlerde farklı formatlarda depolanır ve genellikle yapılandırılmış verilerle aynı düzeyde titizlikle yönetilmez veya yönetilmez. İkincisi, üretken yapay zeka uygulamaları, geleneksel uygulamalara göre daha fazla sayıda veri etkileşimi sağlar; bu da veri güvenliği, gizlilik ve erişim kontrolü politikalarının üretken yapay zeka kullanıcı iş akışlarının bir parçası olarak uygulanmasını gerektirir.
Bu yazıda, yapılandırılmış ve yapılandırılmamış kurumsal bilgi kaynaklarına odaklanarak AWS'de üretken yapay zeka uygulamaları oluşturmaya yönelik veri yönetişimini ve kullanıcı istek-yanıt iş akışları sırasında veri yönetişiminin rolünü ele alıyoruz.
Kullanım örneğine genel bakış
Müşteri desteği yapay zeka asistanının bir örneğini inceleyelim. Aşağıdaki şekil, bir kullanıcı istemiyle başlatılan tipik konuşma iş akışını göstermektedir.

İş akışı aşağıdaki önemli veri yönetimi adımlarını içerir:
- Kullanıcı erişim kontrolünü ve güvenlik politikalarını isteyin.
- İlgili verilere dayalı olarak izinleri ayıklamak ve istemdeki kullanıcı rolüne ve izinlere göre sonuçları filtrelemek için erişim politikaları.
- Kişisel olarak tanımlanabilir bilgiler (PII) düzenlemeleri gibi veri gizliliği politikalarını uygulayın.
- Ayrıntılı erişim kontrolünü zorunlu kılın.
- Hassas bilgiler ve uyumluluk politikaları için kullanıcı rolü izinlerini verin.
Kurumsal bağlamı içeren bir yanıt sağlamak için, her kullanıcı isteminin, veri ambarındaki yapılandırılmış verilerden ve kurumsal veri gölünden gelen yapısal olmayan verilerden elde edilen içgörülerin bir kombinasyonu ile güçlendirilmesi gerekir. Arka uçta, kurumsal veri gölünü yenileyen toplu veri mühendisliği süreçlerinin, yapılandırılmamış verileri alacak, dönüştürecek ve yönetecek şekilde genişletilmesi gerekiyor. Dönüşümün bir parçası olarak, veri gizliliğini sağlamak için nesnelerin işlenmesi gerekir (örneğin, PII düzenlemesi). Son olarak, erişim kontrol politikalarının aynı zamanda yapılandırılmamış veri nesnelerine de genişletilmesi gerekmektedir. vektör veri depoları.
Veri yönetişiminin kurumsal bilgi kaynağı veri hatlarına ve kullanıcı istek-yanıt iş akışlarına nasıl uygulanabileceğine bakalım.
Kurumsal bilgi: Veri yönetimi
Aşağıdaki şekil, veri ardışık düzenleri ve veri yönetişimini uygulamaya yönelik iş akışı için veri yönetişimiyle ilgili hususları özetlemektedir.
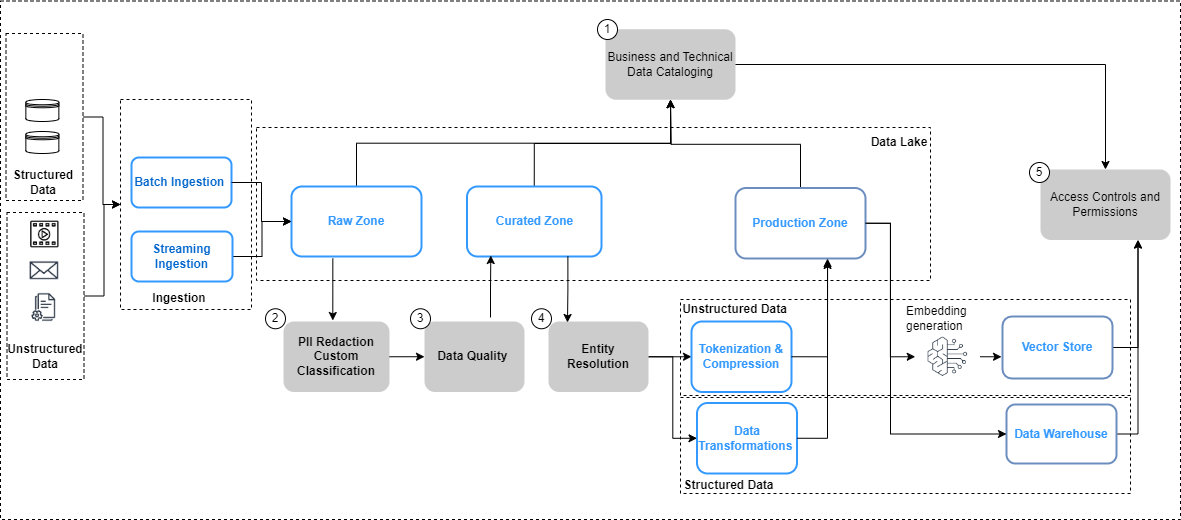
Yukarıdaki şekilde, veri mühendisliği ardışık düzenleri aşağıdaki veri yönetimi adımlarını içerir:
- Veri gelişimi yoluyla bir katalog oluşturun ve güncelleyin.
- Veri gizliliği politikalarını uygulayın.
- Veri kalitesini veri türüne ve kaynağa göre uygulayın.
- Yapılandırılmış ve yapılandırılmamış veri kümelerini birbirine bağlayın.
- Yapılandırılmış ve yapılandırılmamış veri kümeleri için birleşik, ayrıntılı erişim denetimleri uygulayın.
Veri hatlarındaki önemli değişikliklerden bazılarına, yani veri kataloglama, veri kalitesi ve vektör yerleştirme güvenliğine daha ayrıntılı olarak bakalım.
Veri keşfedilebilirliği
İyi tanımlanmış satır ve sütunlarda yönetilen yapılandırılmış verilerin aksine, yapılandırılmamış veriler nesneler olarak depolanır. Kullanıcıların verileri keşfedebilmesi ve kavrayabilmesi için ilk adım, kaynak sistemlerde oluşturulan ve yakalanan meta verileri kullanarak kapsamlı bir katalog oluşturmaktır. Bu, nesnelerin (belgeler ve transkript dosyaları gibi) ilgili kaynak sistemlerden ham bölgeye alınmasıyla başlar. Data Lake in Amazon Basit Depolama Hizmeti (Amazon S3) kendi yerel formatlarında (önceki şekilde gösterildiği gibi). Buradan nesne meta verileri (dosya sahibi, oluşturulma tarihi ve gizlilik düzeyi gibi) çıkartılmış ve Amazon S3 yetenekleri kullanılarak sorgulandı. Meta veriler veri kaynağına göre değişiklik gösterebilir ve gerekli tüm meta verileri tamamlamak için alanların incelenmesi ve gerektiğinde gerekli alanların türetilmesi önemlidir. Örneğin, içerik gizliliği gibi bir öznitelik kaynak uygulamada belge düzeyinde etiketlenmemişse, bunun meta veri çıkarma sürecinin bir parçası olarak türetilmesi ve veri kataloğuna bir öznitelik olarak eklenmesi gerekebilir. Alma işleminin, sürekli olarak yeni nesnelerin yanı sıra nesne güncellemelerini de (değişiklikler, silmeler) yakalaması gerekir. Ayrıntılı uygulama kılavuzu için bkz. AWS AI/ML ve analiz hizmetlerini kullanarak yapılandırılmamış veri yönetimi ve idaresi. İş sözlükleri ve teknik veri katalogları arasındaki keşif ve iç gözlemi daha da basitleştirmek için şunları kullanabilirsiniz: Amazon Veri Bölgesi iş kullanıcılarının veri silolarında depolanan verileri keşfetmesi ve paylaşması için.
Veri gizliliği
Kurumsal bilgi kaynakları genellikle kişisel bilgileri ve diğer hassas verileri (adresler ve Sosyal Güvenlik numaraları gibi) içerir. Veri gizliliği politikalarınıza göre, bu öğelerin alt kullanım senaryolarında kullanılmadan önce kaynaklarda işlenmesi (maskelenmesi, simgeleştirilmesi veya çıkarılması) gerekir. Amazon S3'teki ham bölgeden nesnelerin, aşağı yönlü üretken yapay zeka modelleri tarafından tüketilmeden önce işlenmesi gerekir. Burada önemli bir gereklilik PII tanımlama ve düzeltmeile uygulayabileceğiniz Amazon Kavramak. Verilerin bağlamını etkilemeden tüm hassas verileri çıkarmanın her zaman mümkün olmayacağını unutmamak önemlidir. Anlamsal bağlam üretken yapay zeka modeli çıktılarının doğruluğunu ve alaka düzeyini belirleyen temel faktörlerden biridir ve kullanım senaryosundan geriye doğru çalışmak ve gizlilik kontrolleri ile model performansı arasında gerekli dengeyi kurmak kritik öneme sahiptir.
Veri zenginleştirme
Ayrıca nesnelerden ek meta verilerin çıkarılması gerekebilir. Amazon Comprehen aşağıdakiler için yetenekler sağlar: varlık tanıma (örneğin, poliçe numaraları ve talep numaraları gibi alana özgü verilerin tanımlanması) ve özel sınıflandırma (örneğin, müşteri hizmetleri sohbet metnini sorun açıklamasına göre kategorize etmek). Ayrıca, müşteriler gibi önemli varlıkların bütünsel bir resmini oluşturmak için yapılandırılmamış ve yapılandırılmış verileri birleştirmeniz gerekebilir. Örneğin, bir havayolu sadakat senaryosunda, müşteri etkileşimlerine ilişkin yapılandırılmamış veri yakalamayı (müşteri sohbet transkriptleri ve müşteri incelemeleri gibi) yapılandırılmış veri sinyalleriyle (bilet satın almalar ve mil kullanımı gibi) daha eksiksiz bir sadakat oluşturmak için bağlamanın önemli bir değeri olacaktır. Daha sonra daha iyi ve daha alakalı seyahat önerilerinin sunulmasını sağlayabilecek müşteri profili. AWS Varlık Çözümü kayıtların eşleştirilmesine ve bağlanmasına yardımcı olan bir makine öğrenimi hizmetidir. Bu hizmet, müşteriler, ürünler vb. gibi önemli varlıklar hakkında daha derin, daha bağlantılı veriler oluşturmak için ilgili bilgi kümelerinin birbirine bağlanmasına yardımcı olur ve bu da LLM çıktılarının kalitesini ve alaka düzeyini daha da artırabilir. Bu, Amazon S3'teki dönüştürülmüş bölgede mevcuttur ve vektör depoları, ince ayarlar veya LLM'lerin eğitimi için alt akışta tüketilmeye hazırdır. Bu dönüşümlerin ardından veriler Amazon S3'teki seçilmiş bölgede kullanıma sunulabilir.
Veri kalitesi
Üretken yapay zekanın tam potansiyelini gerçekleştirmeye yönelik kritik bir faktör, modelleri eğitmek için kullanılan verilerin kalitesine ve ayrıca bir kullanıcı girdisine model yanıtını artırmak ve geliştirmek için kullanılan verilere bağlıdır. Modelleri ve sonuçlarını doğruluk, önyargı ve güvenilirlik bağlamında anlamak, modelleri oluşturmak ve eğitmek için kullanılan verilerin kalitesiyle doğru orantılıdır.
Amazon SageMaker Model Monitörü Model veri kalitesi sapması ve model kalitesi metrikleri sapması içindeki sapmaların proaktif bir şekilde algılanmasını sağlar. Ayrıca modelinizin tahminlerindeki ve özellik ilişkilendirmelerindeki sapma sapmasını da izler. Daha fazla ayrıntı için bkz. Amazon SageMaker Model Monitor kullanarak üretim içi makine öğrenimi modellerini büyük ölçekte izleme. Modelinizdeki önyargıyı tespit etmek sorumlu yapay zekanın temel yapı taşıdır ve Amazon SageMaker Netleştirin Negatif veya daha az doğru sonuç üretebilecek potansiyel önyargının tespit edilmesine yardımcı olur. Daha fazlasını öğrenmek için bkz. Amazon SageMaker Clarify'ın önyargının tespit edilmesine nasıl yardımcı olduğunu öğrenin.
Üretken yapay zekanın daha yeni bir odak noktası, kurumsal ve özel veri depolarından gelen istemlerdeki verilerin kullanımı ve kalitesidir. Burada dikkate alınması gereken yeni ortaya çıkan en iyi uygulama şudur: sola kayErken ve proaktif kalite güvence mekanizmalarına güçlü bir vurgu yapan. Üretken yapay zeka uygulamaları için verileri işlemek üzere tasarlanan veri hatları bağlamında bu, daha sonra veri kalitesi sorunlarının potansiyel etkisini azaltmak için veri kalitesi sorunlarının daha erken tanımlanması ve çözülmesi anlamına gelir. AWS Glue Veri Kalitesi yalnızca veri göllerinizde, veri ambarlarınızda ve işlemsel veritabanlarınızda bekleyen verilerinizin kalitesini ölçmek ve izlemekle kalmaz, aynı zamanda verilerinizin güvenli olduğundan emin olmak için ayıklama, dönüştürme ve yükleme (ETL) işlem hatlarınızdaki kalite sorunlarının erken tespit edilmesine ve düzeltilmesine de olanak tanır. Tüketilmeden önce kalite standartlarını karşılar. Daha fazla ayrıntı için bkz. AWS Glue Data Catalog'dan AWS Glue Data Quality'ye Başlarken.
Vektör mağaza yönetimi
Vektör veritabanlarına yerleştirmeler Anlamsal arama ve halüsinasyonları azaltma gibi özellikleri etkinleştirerek üretken yapay zeka uygulamalarının zekasını ve yeteneklerini yükseltin. Eklemeler genellikle özel ve hassas veriler içerir ve verilerin şifrelenmesi, kullanıcı girişi iş akışında önerilen bir adımdır. Amazon OpenSearch Sunucusuz Vektör yerleştirmelerinizi saklar ve arar ve kullanımda olmayan verilerinizi şifreler. AWS Anahtar Yönetim Hizmeti (AWS KMS). Daha fazla ayrıntı için bkz. Amazon OpenSearch Serverless için vektör motoruyla tanışın, şimdi önizlemede. Benzer şekilde, AWS'deki ek vektör motoru seçenekleri arasında şunlar yer almaktadır: Amazon Kendrası ve Amazon Aurora'sı, kullanımda olmayan verilerinizi AWS KMS ile şifreleyin. Daha fazla bilgi için bkz. Kullanımda olmayan şifreleme ve Verileri şifreleme kullanarak koruma.
Gömmeler bir vektör deposunda oluşturulduğundan ve saklandığından, verilere erişimin rol tabanlı erişim kontrolü (RBAC) ile kontrol edilmesi, genel güvenliğin sürdürülmesinde temel bir gereklilik haline gelir. Amazon Açık Arama Hizmeti sağlar ince taneli erişim kontrolleri (FGAC) özellikleri ile AWS Kimlik ve Erişim Yönetimi (IAM) ile ilişkilendirilebilecek kurallar Amazon Cognito'su kullanıcılar. İlgili kullanıcı erişim kontrol mekanizmaları da tarafından sağlanmaktadır. OpenSearch Sunucusuz, Amazon Kendrasıve Aurora. Daha fazla bilgi edinmek için bkz. Amazon OpenSearch Serverless için veri erişim kontrolü, Belirteçlerle belgelere kullanıcı erişimini denetleme, ve Amazon Aurora için kimlik ve erişim yönetimi, Sırasıyla.
Kullanıcı istek-yanıt iş akışları
Veri yönetişim düzlemindeki kontrollerin, genel yönetim planının bir parçası olarak üretken yapay zeka uygulamasına entegre edilmesi gerekir. çözüm dağıtımı veri güvenliği (rol tabanlı erişim kontrollerine dayalı) ve veri gizliliği (hassas verilere rol tabanlı erişime dayalı) politikalarına uygunluğu sağlamak. Aşağıdaki şekil veri yönetişimini uygulamaya yönelik iş akışını göstermektedir.
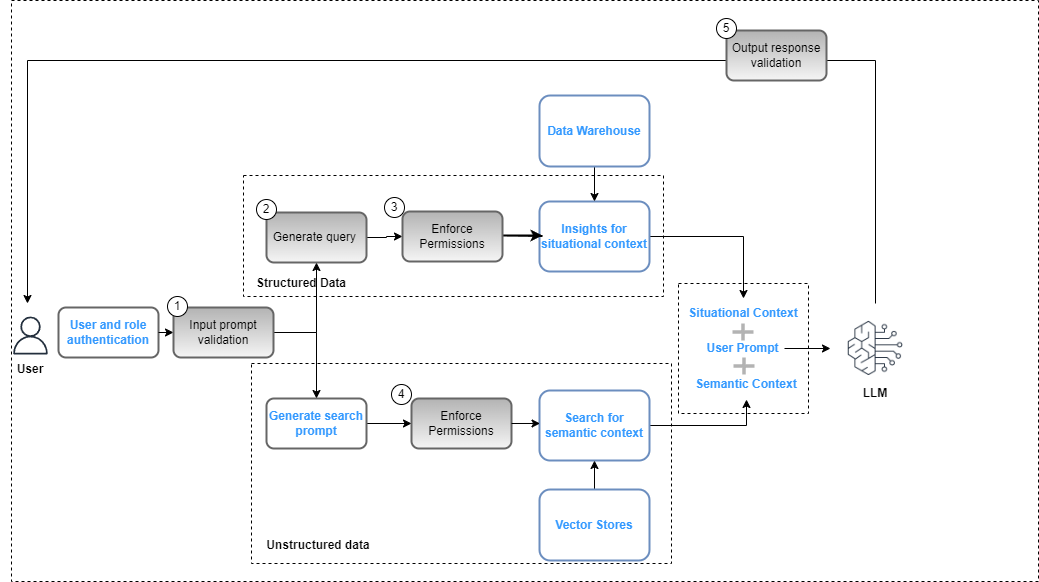
İş akışı aşağıdaki önemli veri yönetimi adımlarını içerir:
- Uyumluluk politikalarına uyum için geçerli bir girdi istemi sağlayın (örneğin önyargı ve toksisite).
- Bilgi istemi anahtar sözcüklerini veri kataloğuyla eşleştirerek bir sorgu oluşturun.
- Kullanıcı rolüne göre FGAC ilkelerini uygulayın.
- Kullanıcı rolüne göre RBAC ilkelerini uygulayın.
- Kullanıcı rolü izinlerine ve uyumluluk politikalarına göre yanıta veri ve içerik düzenlemesi uygulayın.
Bilgi istemi döngüsünün bir parçası olarak, Amazon Comprehend gibi bir hizmet kullanılarak uyumluluk politikalarıyla uyum sağlamak için kullanıcı isteminin ayrıştırılması ve anahtar kelimelerin çıkarılması gerekir (bkz. Amazon Comprehend için Yenilik – Toksisite Tespiti) Veya Amazon Ana Kayası için Korkuluklar (önizleme). Bu doğrulandığında, istem yapılandırılmış verilerin çıkarılmasını gerektiriyorsa, ilgili veri tablolarını ve alanlarını çıkarmak ve veri ambarından bir sorgu oluşturmak için anahtar kelimeler veri kataloğuna (iş veya teknik) karşı kullanılabilir. Kullanıcı izinleri kullanılarak değerlendirilir AWS Göl Oluşumu İlgili verileri filtrelemek için. Yapılandırılmamış veriler durumunda arama sonuçları, vektör deposunda uygulanan kullanıcı izin politikalarına göre kısıtlanır. Son bir adım olarak, LLM'den gelen çıktı yanıtının kullanıcı izinlerine (veri gizliliğini ve güvenliğini sağlamak için) ve güvenliğe uygunluğa (örneğin önyargı ve toksisite yönergeleri) göre değerlendirilmesi gerekir.
Bu süreç RAG uygulamasına özel olmasına ve diğer LLM uygulama stratejilerine uygulanabilir olmasına rağmen ek kontroller vardır:
- Hızlı mühendislik – Çağrılacak bilgi istemi şablonlarına erişimin aşağıdakilere göre kısıtlanması gerekir: erişim kontrolleri iş mantığıyla güçlendirilmiştir.
- İnce ayar modelleri ve eğitim temel modelleri – Amazon S3'teki seçilmiş bölgedeki nesnelerin temel modellerde ince ayar yapmak için eğitim verileri olarak kullanıldığı durumlarda izin politikalarının aşağıdakilerle yapılandırılması gerekir: Amazon S3 kimlik ve erişim yönetimi gereksinimlere göre kova veya nesne düzeyinde.
Özet
Veri yönetimi, kuruluşların kurumsal üretken yapay zeka uygulamaları oluşturmasını sağlamak açısından kritik öneme sahiptir. Kurumsal kullanım örnekleri gelişmeye devam ettikçe, gizlilik, güvenlik ve kalite politikalarıyla uyumu sağlamak amacıyla yeni, çeşitli, yapılandırılmamış veri kümelerini yönetmek ve yönetmek için veri altyapısını genişletmeye ihtiyaç duyulacaktır. Bu politikaların, kullanıcı etkileşimi iş akışlarının yanı sıra kurumsal bilgi tabanının veri alımı, depolanması ve yönetiminin bir parçası olarak uygulanması ve yönetilmesi gerekir. Bu, üretken yapay zeka uygulamalarının yalnızca yanlış veya yanlış bilgi paylaşma riskini en aza indirmekle kalmayıp, aynı zamanda zararlı veya iftira niteliğinde sonuçlara yol açabilecek önyargı ve toksisiteden de korunmasını sağlar. AWS'de veri yönetimi hakkında daha fazla bilgi edinmek için bkz. Veri Yönetişimi nedir?
Sonraki gönderilerde, üretken yapay zeka kullanım örneklerini desteklemek için veri altyapısı yönetişiminin nasıl genişletileceğine ilişkin uygulama rehberliği sunacağız.
Yazarlar Hakkında
 Krishna Rupanagunta AWS'de Veri ve Yapay Zeka Uzmanlarından oluşan bir ekibe liderlik ediyor. Kendisi ve ekibi, Veri, Analitik ve AI/ML'yi kullanarak daha hızlı yenilik yapmalarına ve daha iyi kararlar almalarına yardımcı olmak için müşterilerle birlikte çalışıyor. Kendisine LinkedIn üzerinden ulaşılabilir.
Krishna Rupanagunta AWS'de Veri ve Yapay Zeka Uzmanlarından oluşan bir ekibe liderlik ediyor. Kendisi ve ekibi, Veri, Analitik ve AI/ML'yi kullanarak daha hızlı yenilik yapmalarına ve daha iyi kararlar almalarına yardımcı olmak için müşterilerle birlikte çalışıyor. Kendisine LinkedIn üzerinden ulaşılabilir.
 İmtiaz (Taz) Sayed AWS'de Analitik alanında WW Teknoloji Lideridir. Veri ve analitikle ilgili her konuda toplulukla etkileşimde bulunmaktan hoşlanıyor. Kendisine LinkedIn üzerinden ulaşılabilir.
İmtiaz (Taz) Sayed AWS'de Analitik alanında WW Teknoloji Lideridir. Veri ve analitikle ilgili her konuda toplulukla etkileşimde bulunmaktan hoşlanıyor. Kendisine LinkedIn üzerinden ulaşılabilir.
 Raghvender Arni (Arni) AWS Industries bünyesinde Müşteri Hızlandırma Ekibine (CAT) liderlik etmektedir. CAT, müşteriyle yüz yüze görüşen bulut mimarları, yazılım mühendisleri, veri bilimcileri ve yapay zeka/makine öğrenimi uzmanları ve tasarımcılarından oluşan, gelişmiş prototip oluşturma yoluyla yenilikçiliği destekleyen ve uzmanlaşmış teknik uzmanlık aracılığıyla bulut operasyonel mükemmelliğini destekleyen, küresel, çapraz işlevlere sahip bir ekiptir.
Raghvender Arni (Arni) AWS Industries bünyesinde Müşteri Hızlandırma Ekibine (CAT) liderlik etmektedir. CAT, müşteriyle yüz yüze görüşen bulut mimarları, yazılım mühendisleri, veri bilimcileri ve yapay zeka/makine öğrenimi uzmanları ve tasarımcılarından oluşan, gelişmiş prototip oluşturma yoluyla yenilikçiliği destekleyen ve uzmanlaşmış teknik uzmanlık aracılığıyla bulut operasyonel mükemmelliğini destekleyen, küresel, çapraz işlevlere sahip bir ekiptir.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

