Introduction
Recently, Large Language Models (LLMs) have made great advancements. One of the most notable breakthroughs is ChatGPT, which is designed to interact with users through conversations, maintain the context, handle follow-up questions, and correct itself. However, ChatGPT is limited in processing visual information since it’s trained with a single language modality.
Visual Foundation Models have shown potential in computer vision with their ability to understand and generate complex images. It is built based on ChatGPT and incorporates Visual Foundation Models to bridge this gap. A Prompt Manager is proposed to support this integration, clearly informing ChatGPT of each VFM’s ability, specifying input-output formats, converting visual information to language format, and handling Visual Foundation Model histories, priorities, and conflicts. Using the Prompt Manager, ChatGPT can leverage Visual Foundation Models iteratively until it meets user requirements or reaches the ending condition.
For example, a user uploads an image of a red flower and requests a blue flower, based on predicted depth, made into a cartoon. Visual ChatGPT applies related Visual Foundation Models, such as depth estimation and depth-to-image models, to generate the requested output.

Learning Objectives
- Understand the foundational concepts of “Visual Foundation Models” and their potential in computer vision.
- Learn about the Visual ChatGPT system architecture and components.
- Understand how its system works, including how it iteratively invokes Visual Foundation Models to provide answers to user queries.
- Learn how to set up the Visual ChatGPT environment.
- Understand its potential applications.
- Understand the limitations of the Visual ChatGPT system.
This article was published as a part of the Data Science Blogathon.
Table of Contents
The Visual ChatGPT: System Architecture
The text describes how Visual ChatGPT works to generate responses to user queries. The system involves a series of Visual Foundation Models and intermediate outputs from those models to get the final response.
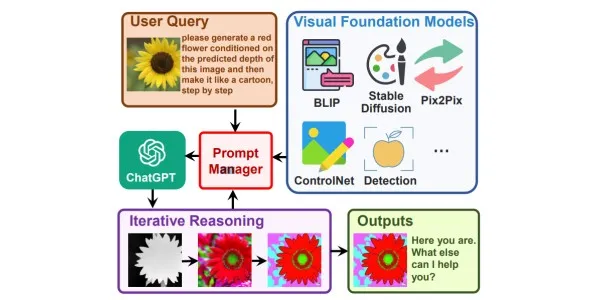
1. Components
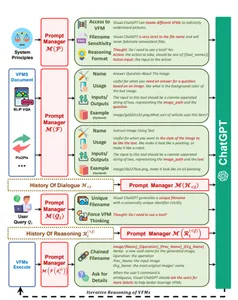
- System principle: The System Principle provides the basic rules for Visual ChatGPT.
- Visual Foundation Model: It is the combination of various Visual Foundation Models, where each foundation model contains a determined function with explicit inputs and outputs.
- History of Dialogue: Following the conversation from the point of the first interaction with the system or a request for it.
- User query: what the user wants to do can be queried in the form of a user query.
- History of Reasoning: Used to solve complex questions with the collaboration of multiple Visual Foundation Models. All previous reasoning histories from multiple Visual Foundation Models are combined for a certain conversation round.
- Intermediate Answer: It attempts to obtain the final answer to a complex query by gradually invoking various Visual Foundation Models in a logical manner, resulting in several intermediate answers.
- Prompt Manager: The Prompt Manager converts all visual signals into language so that the ChatGPT model can understand them. The text provides a formal definition of Visual ChatGPT, including its basic rules and the different components involved. Overview of it. The left side shows a three-round dialogue. The figure’s middle parts show how it continuously invokes Visual Foundation Models and provides answers. The right side of the figure shows the process of the second QA.
2. Overview
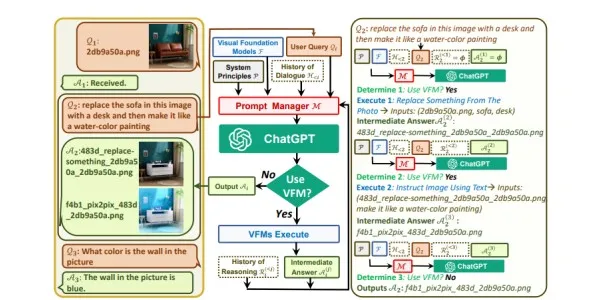
The text provides a formal definition of Visual ChatGPT, including its basic rules and the different components involved. The center displays the flowchart of how it iteratively invoke Visual Foundation Models and provides replies. The left side displays a three-round interaction. The right side displays the second QA’s thorough process.
3. Overview of the Prompt Manager
How to Setup Visual ChatGPT?

Commands
# create a new environment
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
#install pytorch with pip or conda command based on your CUDA version. For example
# below command is for the CUDA version 11.7
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
# Start Visual ChatGPT !
python visual_chatgpt.pyDemo
Here is the URL for the Demo.
Applications of Visual ChatGPT
Visual ChatGPT can perform a variety of Computer vision tasks and image pre-processing like the ones below using text.
- Synthetic Image Generation: The user can ask it to generate any image with its description. Visual ChatGPT will generate the same within seconds, depending on the computing power of the machine it’s running on. Its backend Image Generation is based on Stable Diffusion, which is an open-source framework trained to generate images from text.
- Changing the image’s background: It can be in-paint or out-paint, just like stable diffusion. The user can ask the chatbot to change or edit the background of the image with any description. A stable diffusion model will inpaint the background at the backend as per the text description.
- Edge detection on the images: A user can ask it to highlight the edges of any image in grayscale or other formats. Visual ChatGPT will utilize a combination of its pretrained models and OpenCV at the backend to highlight the edges of the image. This is helpful in many scenarios, like using edge images and original images as combined input to train models like conditional GANs.
- Replacing or removing the objects in an image: The user can edit, remove, or modify any part or object in the image with just a simple text description. For example, a user can ask the chatbot to change a cat’s face to that of a dog, and Visual ChatGPT will be able to create the same. This feature requires more computing power.
Limitations
Although Visual ChatGPT is a promising method for multi-modal communication, it has a number of drawbacks.
- Heavily relies on ChatGPT and Visual Foundation Models, so the accuracy and effectiveness of these models influence its performance.
- Requires a substantial amount of prompt engineering, which can be time-consuming and requires computer vision and natural language processing proficiency.
- Visual ChatGPT may invoke multiple Visual Foundation Models when handling specific tasks, which can result in limited real-time capabilities compared to expert models specifically trained.
- The ability to easily plug and unplug foundation models may raise security and privacy concerns, so careful consideration and automatic checks are necessary to ensure that sensitive data is not exposed or compromised.

Conclusion
Visual ChatGPT, an open system, allows users to interact with ChatGPT beyond the language format by incorporating different Visual Foundation Models. To achieve this, a series of prompts are designed to help ChatGPT understand visual information and solve complex visual questions step-by-step. The system’s potential and competence are demonstrated through experiments and selected cases. However, there are concerns regarding unsatisfactory results due to Visual Foundation Model failures and prompt instability. A self-correction module is necessary to check the consistency between execution results and human intentions and make corresponding edits. This behavior increases the model’s inference time but leads to more complex thinking. Future work will address this issue.
Key Takeaways
- Visual ChatGPT is a system that incorporates Visual Foundation Models into ChatGPT to enable it to process visual information.
- The Prompt Manager is a key component of this system, and it informs ChatGPT about each Visual Foundation Model’s capabilities, input-output formats, and histories.
- Visual ChatGPT allows users to perform various computer vision tasks and image pre-processing using text or voice commands, including synthetic image generation, background modification, edge detection, and object replacement or removal.
- The system provides a detailed overview of its components and architecture and instructions for setting it up.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2023/03/power-of-visual-chatgpt-conversations-with-ai-and-images/

