In dit bericht laten we zien hoe u structureel snoeien op basis van neurale architectuurzoekopdrachten (NAS) kunt gebruiken om een verfijnd BERT-model te comprimeren om de modelprestaties te verbeteren en de inferentietijden te verkorten. Vooraf getrainde taalmodellen (PLM's) ondergaan een snelle commerciële en zakelijke adoptie op het gebied van productiviteitstools, klantenservice, zoeken en aanbevelingen, automatisering van bedrijfsprocessen en het creëren van inhoud. Het implementeren van PLM-inferentie-eindpunten gaat doorgaans gepaard met hogere latentie en hogere infrastructuurkosten vanwege de rekenvereisten en verminderde rekenefficiëntie vanwege het grote aantal parameters. Het snoeien van een PLM vermindert de omvang en complexiteit van het model, terwijl de voorspellende mogelijkheden behouden blijven. Gesnoeide PLM's bereiken een kleinere geheugenvoetafdruk en een lagere latentie. We demonstreren dat door een PLM te snoeien en het aantal parameters en de validatiefouten voor een specifieke doeltaak uit te wisselen, en kunnen snellere responstijden bereiken in vergelijking met het basis-PLM-model.
Multi-objectieve optimalisatie is een gebied van besluitvorming dat meer dan één objectieve functie optimaliseert, zoals geheugengebruik, trainingstijd en computerbronnen, om tegelijkertijd te optimaliseren. Structureel snoeien is een techniek om de omvang en rekenvereisten van PLM te verminderen door lagen of neuronen/knooppunten te snoeien, terwijl wordt geprobeerd de nauwkeurigheid van het model te behouden. Door lagen te verwijderen, bereikt structureel snoeien hogere compressiesnelheden, wat leidt tot hardwarevriendelijke gestructureerde sparsity die runtimes en responstijden verkort. Het toepassen van een structurele snoeitechniek op een PLM-model resulteert in een lichter model met een lagere geheugenvoetafdruk dat, wanneer het wordt gehost als een inferentie-eindpunt in SageMaker, een verbeterde resource-efficiëntie en lagere kosten biedt in vergelijking met de oorspronkelijke, verfijnde PLM.
De concepten die in dit bericht worden geïllustreerd, kunnen worden toegepast op applicaties die PLM-functies gebruiken, zoals aanbevelingssystemen, sentimentanalyse en zoekmachines. U kunt deze aanpak met name gebruiken als u speciale machine learning (ML)- en datawetenschapsteams heeft die hun eigen PLM-modellen verfijnen met behulp van domeinspecifieke datasets en een groot aantal inferentie-eindpunten implementeren met behulp van Amazon Sage Maker. Een voorbeeld is een online detailhandelaar die een groot aantal inferentie-eindpunten inzet voor tekstsamenvatting, productcatalogusclassificatie en productfeedback-sentimentclassificatie. Een ander voorbeeld kan een zorgaanbieder zijn die PLM-inferentie-eindpunten gebruikt voor de classificatie van klinische documenten, herkenning van benoemde entiteiten uit medische rapporten, medische chatbots en stratificatie van patiëntrisico's.
Overzicht oplossingen
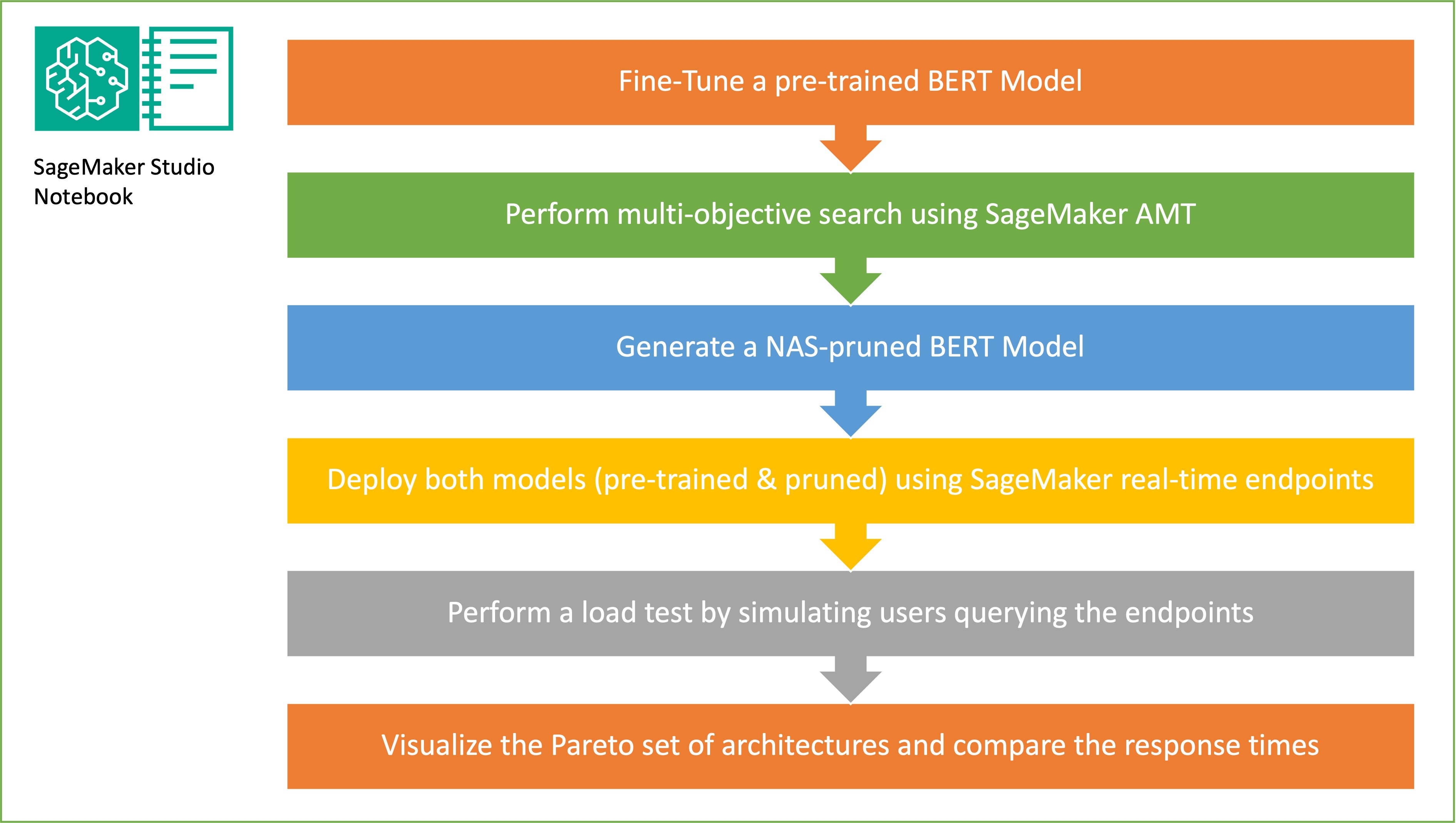
In deze sectie presenteren we de algehele workflow en leggen we de aanpak uit. Eerst gebruiken we een Amazon SageMaker Studio notitieboekje om een vooraf getraind BERT-model te verfijnen op een doeltaak met behulp van een domeinspecifieke dataset. BERT (Bidirectionele Encoder Representaties van Transformers) is een vooraf getraind taalmodel gebaseerd op de transformator architectuur gebruikt voor taken op het gebied van natuurlijke taalverwerking (NLP). Neural Architecture Search (NAS) is een aanpak voor het automatiseren van het ontwerp van kunstmatige neurale netwerken en is nauw verwant aan hyperparameteroptimalisatie, een veelgebruikte aanpak op het gebied van machine learning. Het doel van NAS is om de optimale architectuur voor een bepaald probleem te vinden door een groot aantal kandidaat-architecturen te doorzoeken met behulp van technieken zoals gradiëntvrije optimalisatie of door de gewenste statistieken te optimaliseren. De prestaties van de architectuur worden doorgaans gemeten met behulp van statistieken zoals validatieverlies. SageMaker automatische modelafstemming (AMT) automatiseert het vervelende en complexe proces van het vinden van de optimale combinaties van hyperparameters van het ML-model die de beste modelprestaties opleveren. AMT maakt gebruik van intelligente zoekalgoritmen en iteratieve evaluaties met behulp van een reeks hyperparameters die u opgeeft. Het kiest de hyperparameterwaarden die een model creëren dat het beste presteert, zoals gemeten aan de hand van prestatiestatistieken zoals nauwkeurigheid en F-1-score.
De in dit bericht beschreven verfijningsaanpak is generiek en kan worden toegepast op elke op tekst gebaseerde dataset. De taak die aan de BERT PLM is toegewezen, kan een op tekst gebaseerde taak zijn, zoals sentimentanalyse, tekstclassificatie of vraag en antwoord. In deze demo is de doeltaak een binair classificatieprobleem waarbij BERT wordt gebruikt om uit een dataset die bestaat uit een verzameling paren tekstfragmenten te identificeren of de betekenis van het ene tekstfragment kan worden afgeleid uit het andere fragment. Wij gebruiken de Gegevensset voor tekstuele gevolgen herkennen uit de GLUE-benchmarksuite. We voeren een zoekopdracht met meerdere doelstellingen uit met behulp van SageMaker AMT om de subnetwerken te identificeren die optimale afwegingen bieden tussen het aantal parameters en de nauwkeurigheid van de voorspelling voor de doeltaak. Bij het uitvoeren van een zoekopdracht met meerdere doelstellingen beginnen we met het definiëren van de nauwkeurigheid en het aantal parameters als de doelstellingen die we willen optimaliseren.
Binnen het BERT PLM-netwerk kunnen er modulaire, op zichzelf staande subnetwerken zijn waardoor het model over gespecialiseerde mogelijkheden beschikt, zoals taalbegrip en kennisrepresentatie. BERT PLM maakt gebruik van een meerkoppig zelfaandacht-subnetwerk en een feed-forward subnetwerk. Dankzij een meerkoppige zelfaandachtslaag kan BERT verschillende posities van een enkele reeks met elkaar in verband brengen om een representatie van de reeks te berekenen door meerdere hoofden in staat te stellen meerdere contextsignalen te behandelen. De invoer wordt opgesplitst in meerdere subruimten en zelfaandacht wordt op elk van de subruimten afzonderlijk toegepast. Met meerdere koppen in een transformator-PLM kan het model gezamenlijk informatie uit verschillende representatie-subruimten verwerken. Een feed-forward-subnetwerk is een eenvoudig neuraal netwerk dat de uitvoer van het meerkoppige zelfaandacht-subnetwerk overneemt, de gegevens verwerkt en de uiteindelijke encoderrepresentaties retourneert.
Het doel van willekeurige subnetwerkbemonstering is om kleinere BERT-modellen te trainen die goed genoeg kunnen presteren bij doeltaken. We nemen een steekproef uit 100 willekeurige subnetwerken uit het verfijnde basis-BERT-model en evalueren 10 netwerken tegelijkertijd. De getrainde subnetwerken worden geëvalueerd op de objectieve meetgegevens en het uiteindelijke model wordt gekozen op basis van de gevonden compromissen tussen de objectieve meetgegevens. Wij visualiseren de Pareto voorkant voor de bemonsterde subnetwerken, die het gesnoeide model bevatten dat de optimale afweging biedt tussen modelnauwkeurigheid en modelgrootte. We selecteren het kandidaat-subnetwerk (door NAS gesnoeid BERT-model) op basis van de modelgrootte en modelnauwkeurigheid die we bereid zijn in te ruilen. Vervolgens hosten we de eindpunten, het vooraf getrainde BERT-basismodel en het door de NAS gesnoeide BERT-model met behulp van SageMaker. Om belastingtests uit te voeren, gebruiken we Sprinkhaan, een open source load-testtool die u kunt implementeren met Python. We voeren belastingtests uit op beide eindpunten met behulp van Locust en visualiseren de resultaten met behulp van het Pareto-front om de wisselwerking tussen responstijden en nauwkeurigheid voor beide modellen te illustreren. Het volgende diagram geeft een overzicht van de workflow die in dit bericht wordt uitgelegd.
Voorwaarden
Voor deze functie zijn de volgende vereisten vereist:
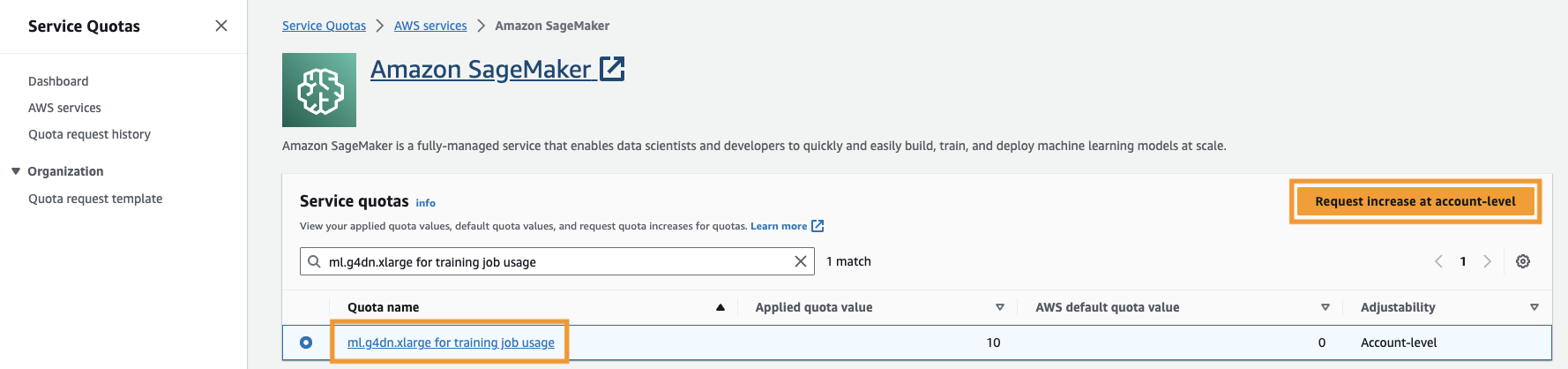
Je moet ook de servicequotum om toegang te krijgen tot ten minste drie exemplaren van ml.g4dn.xlarge-instanties in SageMaker. Het instantietype ml.g4dn.xlarge is de kostenefficiënte GPU-instantie waarmee u PyTorch native kunt uitvoeren. Voer de volgende stappen uit om het servicequotum te verhogen:
- Navigeer op de console naar Servicequota.
- Voor Beheer quota's, kiezen Amazon Sage Maker, kies dan Bekijk quota.

- Zoek naar “ml-g4dn.xlarge voor gebruik van trainingstaken” en selecteer het quotumitem.
- Kies Verhoging op accountniveau aanvragen.
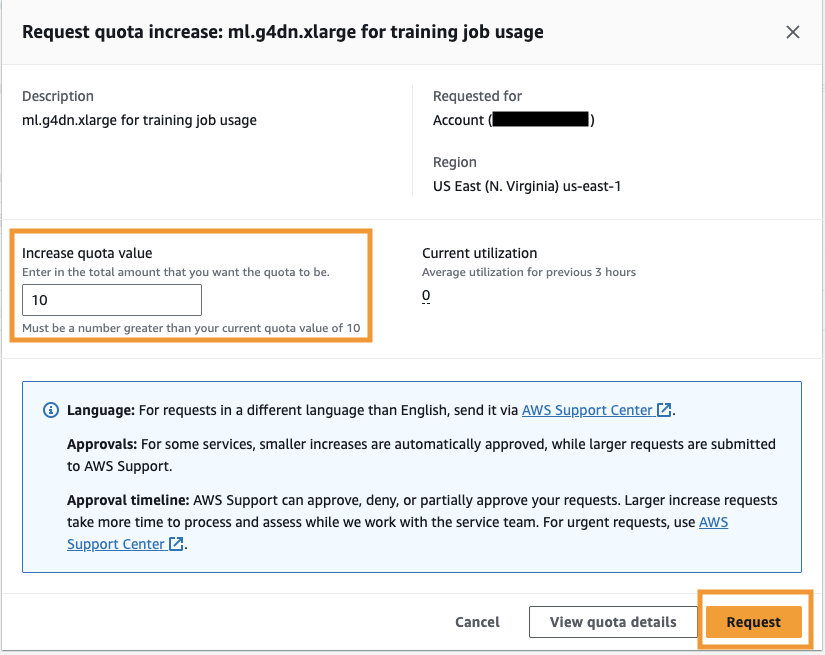
- Voor Verhoog de quotumwaarde, voer een waarde van 5 of hoger in.
- Kies Aanvraag.
Het kan enige tijd duren voordat de aangevraagde quotagoedkeuring is voltooid, afhankelijk van de accountmachtigingen.
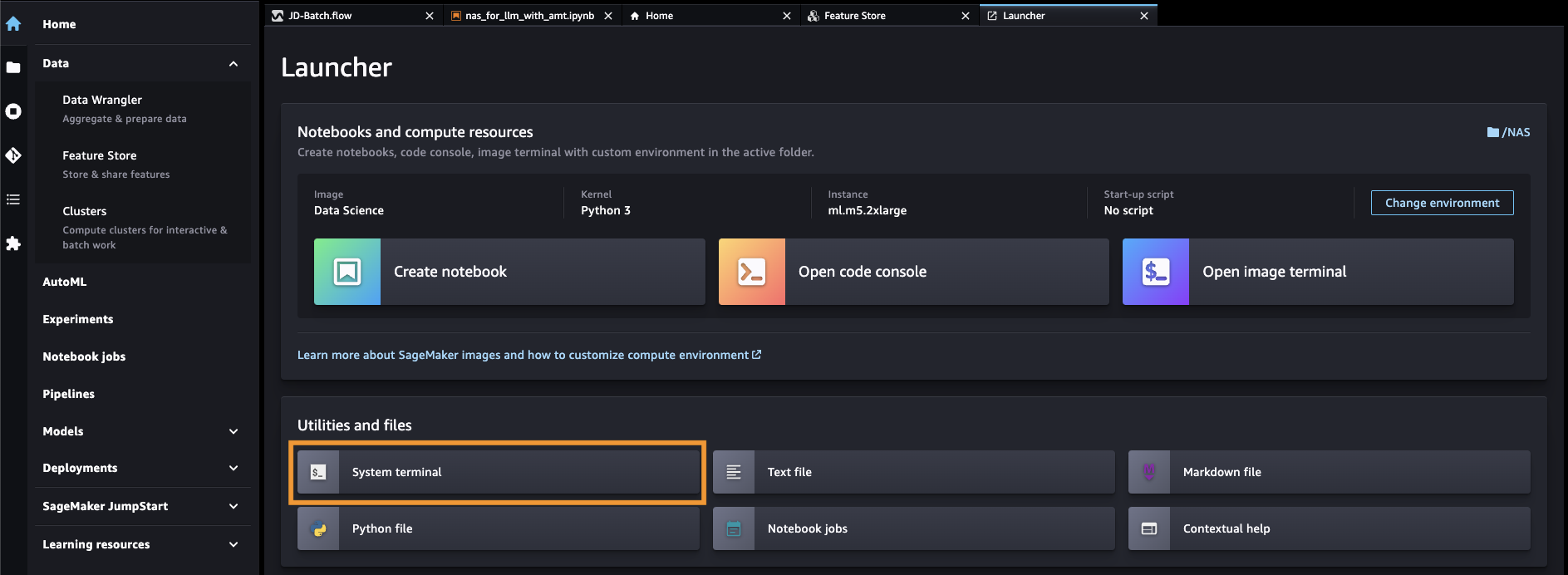
- Open SageMaker Studio vanuit de SageMaker-console.

- Kies Systeemterminal voor Hulpprogramma's en bestanden.
- Voer de volgende opdracht uit om het GitHub repo naar de SageMaker Studio-instantie:
- Navigeer naar
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Open het bestand
nas_for_llm_with_amt.ipynb. - Stel de omgeving in met een
ml.g4dn.xlargebijvoorbeeld en kies kies.
Zet het vooraf getrainde BERT-model op
In deze sectie importeren we de dataset Recognizing Textual Entailment uit de datasetbibliotheek en splitsen we de dataset op in trainings- en validatiesets. Deze dataset bestaat uit zinnenparen. De taak van de BERT PLM is om, gegeven twee tekstfragmenten, te herkennen of de betekenis van het ene tekstfragment uit het andere fragment kan worden afgeleid. In het volgende voorbeeld kunnen we de betekenis van de eerste zin afleiden uit de tweede zin:
We laden de tekstuele herkenningsdataset uit de LIJM benchmarkingsuite via de datasetbibliotheek van Hugging Face binnen ons trainingsscript (./training.py). We hebben de originele trainingsdataset van GLUE opgesplitst in een trainings- en validatieset. In onze aanpak verfijnen we het basis-BERT-model met behulp van de trainingsdataset. Vervolgens voeren we een zoekopdracht met meerdere doelstellingen uit om de set subnetwerken te identificeren die optimaal in evenwicht zijn tussen de objectieve statistieken. We gebruiken de trainingsdataset uitsluitend voor het verfijnen van het BERT-model. We gebruiken echter validatiegegevens voor de zoekopdracht met meerdere doelstellingen door de nauwkeurigheid van de holdout-validatiegegevensset te meten.
Verfijn de BERT PLM met behulp van een domeinspecifieke dataset
De typische gebruiksscenario's voor een onbewerkt BERT-model omvatten de voorspelling van de volgende zin of gemaskeerde taalmodellering. Om het basis-BERT-model te gebruiken voor downstream-taken zoals tekstuele herkenning van gevolgen, moeten we het model verder verfijnen met behulp van een domeinspecifieke dataset. U kunt een verfijnd BERT-model gebruiken voor taken zoals reeksclassificatie, het beantwoorden van vragen en tokenclassificatie. Voor de doeleinden van deze demo gebruiken we echter het verfijnde model voor binaire classificatie. We verfijnen het vooraf getrainde BERT-model met de trainingsdataset die we eerder hebben voorbereid, met behulp van de volgende hyperparameters:
We slaan het controlepunt van de modeltraining op in een Amazon eenvoudige opslagservice (Amazon S3) bucket, zodat het model kan worden geladen tijdens het op de NAS gebaseerde zoeken met meerdere doelstellingen. Voordat we het model trainen, definiëren we de statistieken zoals tijdperk, trainingsverlies, aantal parameters en validatiefout:
Nadat het fijnafstellingsproces is gestart, duurt het ongeveer 15 minuten om de trainingstaak te voltooien.
Voer een zoekopdracht met meerdere doelstellingen uit om subnetwerken te selecteren en de resultaten te visualiseren
In de volgende stap voeren we een zoekopdracht met meerdere doelstellingen uit op het verfijnde basis-BERT-model door willekeurige subnetwerken te bemonsteren met behulp van SageMaker AMT. Om toegang te krijgen tot een subnetwerk binnen het supernetwerk (het verfijnde BERT-model), maskeren we alle componenten van de PLM die geen deel uitmaken van het subnetwerk. Het maskeren van een supernetwerk om subnetwerken in een PLM te vinden, is een techniek die wordt gebruikt om patronen in het gedrag van het model te isoleren en te identificeren. Houd er rekening mee dat Hugging Face-transformatoren de verborgen grootte nodig hebben om een veelvoud te zijn van het aantal hoofden. De verborgen grootte in een transformator-PLM bepaalt de grootte van de vectorruimte met verborgen toestand, wat van invloed is op het vermogen van het model om complexe representaties en patronen in de gegevens te leren. In een BERT PLM heeft de verborgen toestandsvector een vaste grootte (768). We kunnen de verborgen grootte niet veranderen, en daarom moet het aantal heads [1, 3, 6, 12] zijn.
In tegenstelling tot optimalisatie met één doel hebben we in de omgeving met meerdere doelstellingen doorgaans geen enkele oplossing die tegelijkertijd alle doelstellingen optimaliseert. In plaats daarvan streven we ernaar een reeks oplossingen te verzamelen die alle andere oplossingen domineren in ten minste één doelstelling (zoals validatiefout). Nu kunnen we de zoektocht met meerdere doelstellingen via AMT starten door de statistieken in te stellen die we willen verminderen (validatiefout en aantal parameters). De willekeurige subnetwerken worden gedefinieerd door de parameter max_jobs en het aantal gelijktijdige taken wordt gedefinieerd door de parameter max_parallel_jobs. De code om het modelcontrolepunt te laden en het subnetwerk te evalueren is beschikbaar in de evaluate_subnetwork.py scripts.
De AMT-afstemmingstaak duurt ongeveer 2 uur en 20 minuten. Nadat de AMT-afstemmingstaak succesvol is uitgevoerd, parseren we de geschiedenis van de taak en verzamelen we de configuraties van het subnetwerk, zoals het aantal heads, het aantal lagen, het aantal eenheden en de bijbehorende statistieken zoals validatiefout en aantal parameters. De volgende schermafbeelding toont de samenvatting van een succesvolle AMT-tunertaak.
Vervolgens visualiseren we de resultaten met behulp van een Pareto-set (ook bekend als Pareto-grens of Pareto-optimale set), die ons helpt optimale sets subnetwerken te identificeren die alle andere subnetwerken domineren in de objectieve metriek (validatiefout):
Eerst verzamelen we de gegevens van de AMT-afstemmingstaak. Vervolgens plotten we de Pareto-set met behulp van matplotlob.pyplot met aantal parameters op de x-as en validatiefout op de y-as. Dit impliceert dat wanneer we van het ene subnetwerk van de Pareto-set naar het andere gaan, we ofwel de prestaties of de modelgrootte moeten opofferen, maar de andere moeten verbeteren. Uiteindelijk biedt de Pareto-set ons de flexibiliteit om het subnetwerk te kiezen dat het beste bij onze voorkeuren past. We kunnen beslissen hoeveel we de omvang van ons netwerk willen verkleinen en hoeveel prestaties we bereid zijn op te offeren.

Implementeer het verfijnde BERT-model en het NAS-geoptimaliseerde subnetwerkmodel met behulp van SageMaker
Vervolgens implementeren we het grootste model in onze Pareto-set dat leidt tot de kleinste mate van prestatiedegeneratie tot a SageMaker-eindpunt. Het beste model is het model dat een optimale afweging biedt tussen de validatiefout en het aantal parameters voor onze use case.
Model vergelijking
We hebben een vooraf getraind basis-BERT-model genomen, dit verfijnd met behulp van een domeinspecifieke dataset, een NAS-zoekopdracht uitgevoerd om dominante subnetwerken te identificeren op basis van de objectieve statistieken, en het gesnoeide model op een SageMaker-eindpunt geïmplementeerd. Daarnaast hebben we het vooraf getrainde basis-BERT-model gebruikt en het basismodel op een tweede SageMaker-eindpunt geïmplementeerd. Vervolgens renden we belasting testen door Locust te gebruiken op beide inferentie-eindpunten en de prestaties te evalueren in termen van responstijd.
Eerst importeren we de benodigde Locust- en Boto3-bibliotheken. Vervolgens construeren we metagegevens van het verzoek en leggen we de starttijd vast die moet worden gebruikt voor het testen van de belasting. Vervolgens wordt de payload via de BotoClient doorgegeven aan de SageMaker-eindpuntaanroep-API om echte gebruikersverzoeken te simuleren. We gebruiken Locust om meerdere virtuele gebruikers te spawnen om parallel verzoeken te verzenden en de eindpuntprestaties onder belasting te meten. Tests worden uitgevoerd door respectievelijk het aantal gebruikers voor elk van de twee eindpunten te vergroten. Nadat de tests zijn voltooid, voert Locust een CSV-bestand met aanvraagstatistieken uit voor elk van de geïmplementeerde modellen.
Vervolgens genereren we de responstijdgrafieken van de CSV-bestanden die zijn gedownload na het uitvoeren van de tests met Locust. Het doel van het uitzetten van de responstijd versus het aantal gebruikers is het analyseren van de resultaten van de belastingtests door de impact van de responstijd van de modeleindpunten te visualiseren. In het volgende diagram kunnen we zien dat het door de NAS gesnoeide model-eindpunt een lagere responstijd behaalt vergeleken met het basis-BERT-model-eindpunt.
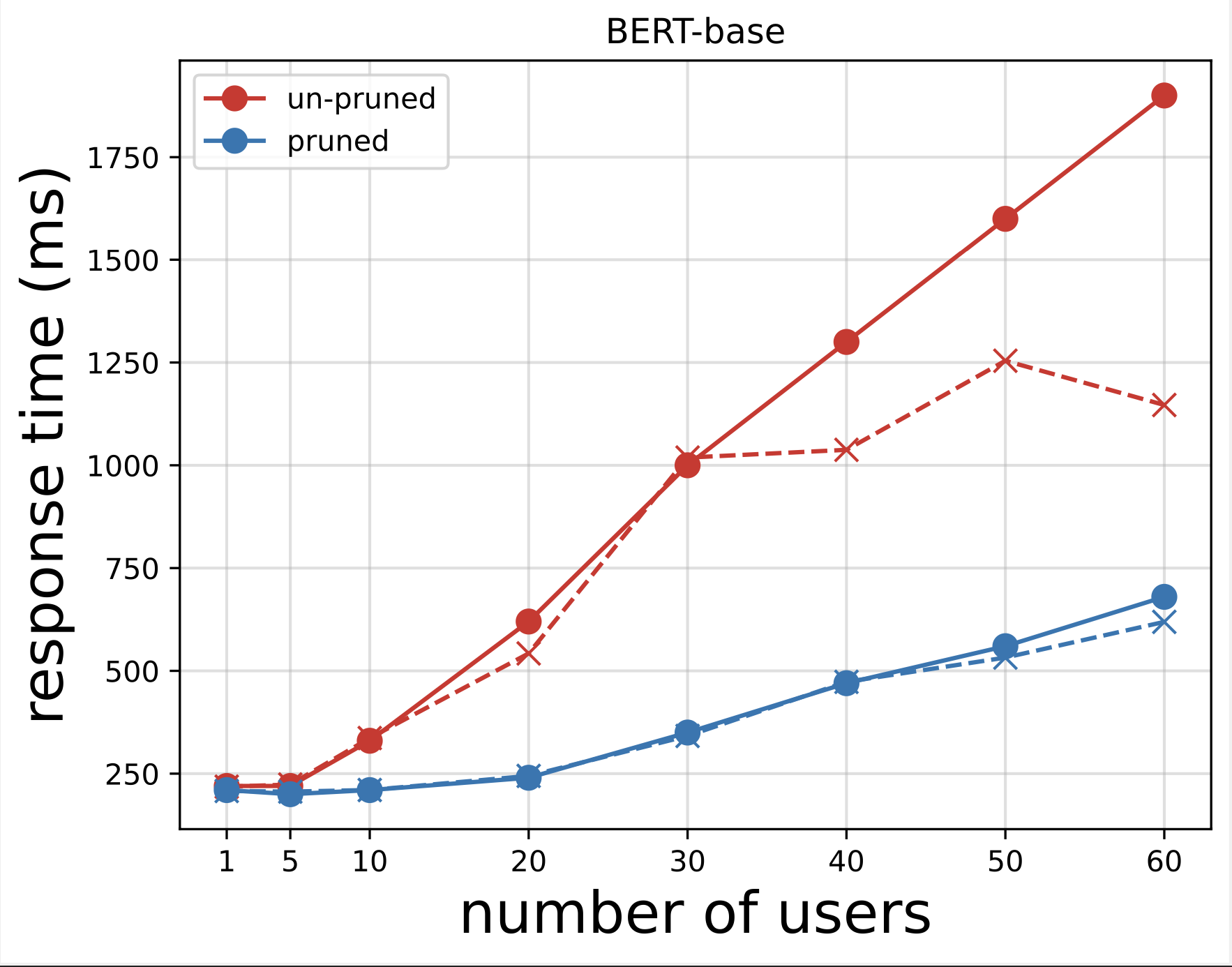
In de tweede grafiek, die een uitbreiding is van de eerste grafiek, zien we dat SageMaker na ongeveer 70 gebruikers het basiseindpunt van het BERT-model begint te beperken en een uitzondering genereert. Voor het door de NAS gesnoeide eindpunt vindt de beperking echter plaats tussen 90 en 100 gebruikers en met een lagere responstijd.

Uit de twee grafieken zien we dat het gesnoeide model een snellere responstijd heeft en beter schaalt in vergelijking met het niet-gesnoeide model. Naarmate we het aantal inferentie-eindpunten opschalen, zoals het geval is bij gebruikers die een groot aantal inferentie-eindpunten inzetten voor hun PLM-applicaties, beginnen de kostenvoordelen en prestatieverbetering behoorlijk substantieel te worden.
Opruimen
Voer de volgende stappen uit om de SageMaker-eindpunten voor het verfijnde basis-BERT-model en het door de NAS gesnoeide model te verwijderen:
- Kies op de SageMaker-console Gevolgtrekking en Eindpunten in het navigatievenster.
- Selecteer het eindpunt en verwijder het.
U kunt ook vanuit het SageMaker Studio-notebook de volgende opdrachten uitvoeren door de eindpuntnamen op te geven:
Conclusie
In dit bericht hebben we besproken hoe je NAS kunt gebruiken om een verfijnd BERT-model te snoeien. We hebben eerst een basis-BERT-model getraind met behulp van domeinspecifieke gegevens en dit geïmplementeerd op een SageMaker-eindpunt. We hebben een zoekopdracht met meerdere doelstellingen uitgevoerd op het verfijnde basis-BERT-model met behulp van SageMaker AMT voor een doeltaak. We visualiseerden het Pareto-front, selecteerden het Pareto-optimale NAS-geoptimaliseerde BERT-model en implementeerden het model op een tweede SageMaker-eindpunt. We hebben belastingtests uitgevoerd met Locust om gebruikers te simuleren die beide eindpunten bevragen, en de responstijden gemeten en vastgelegd in een CSV-bestand. We hebben voor beide modellen de responstijd uitgezet tegen het aantal gebruikers.
We hebben waargenomen dat het gesnoeide BERT-model aanzienlijk beter presteerde op het gebied van zowel de responstijd als de throttling-drempel. We concludeerden dat het door de NAS gesnoeide model beter bestand was tegen een verhoogde belasting van het eindpunt, en een lagere responstijd handhaafde, zelfs als meer gebruikers het systeem belastten in vergelijking met het basis-BERT-model. U kunt de NAS-techniek die in dit bericht wordt beschreven op elk groot taalmodel toepassen om een gesnoeid model te vinden dat de doeltaak met een aanzienlijk lagere responstijd kan uitvoeren. U kunt de aanpak verder optimaliseren door naast validatieverlies latentie als parameter te gebruiken.
Hoewel we in dit bericht NAS gebruiken, is kwantisering een andere veelgebruikte benadering om PLM-modellen te optimaliseren en te comprimeren. Kwantisering vermindert de precisie van de gewichten en activeringen in een getraind netwerk van 32-bits drijvende komma naar lagere bitbreedtes, zoals 8-bits of 16-bits gehele getallen, wat resulteert in een gecomprimeerd model dat snellere gevolgtrekkingen genereert. Kwantisering vermindert het aantal parameters niet; in plaats daarvan vermindert het de precisie van de bestaande parameters om een gecomprimeerd model te krijgen. NAS-snoei verwijdert overtollige netwerken in een PLM, waardoor een schaars model ontstaat met minder parameters. Meestal worden NAS-pruning en kwantisering samen gebruikt om grote PLM's te comprimeren om de modelnauwkeurigheid te behouden, validatieverliezen te verminderen terwijl de prestaties worden verbeterd en de modelgrootte te verkleinen. De andere veelgebruikte technieken om de omvang van PLM's te verkleinen zijn onder meer kennis distillatie, matrixfactorisatie en destillatiecascades.
De aanpak die in de blogpost wordt voorgesteld, is geschikt voor teams die SageMaker gebruiken om de modellen te trainen en te verfijnen met behulp van domeinspecifieke gegevens en de eindpunten in te zetten om gevolgtrekkingen te genereren. Als u op zoek bent naar een volledig beheerde service die een keuze biedt uit goed presterende basismodellen die nodig zijn om generatieve AI-applicaties te bouwen, overweeg dan om Amazonebodem. Als u op zoek bent naar vooraf getrainde, open source-modellen voor een breed scala aan zakelijke toepassingen en toegang wilt tot oplossingssjablonen en voorbeeldnotebooks, overweeg dan om Amazon SageMaker JumpStart. Een vooraf getrainde versie van het Hugging Face BERT-basismodel dat we in dit bericht hebben gebruikt, is ook verkrijgbaar bij SageMaker JumpStart.
Over de auteurs
 Aparajithan Vaidyanathan is een Principal Enterprise Solutions Architect bij AWS. Hij is een cloudarchitect met meer dan 24 jaar ervaring in het ontwerpen en ontwikkelen van zakelijke, grootschalige en gedistribueerde softwaresystemen. Hij is gespecialiseerd in Generatieve AI en Machine Learning Data Engineering. Hij is een ambitieuze marathonloper en zijn hobby's zijn wandelen, fietsen en tijd doorbrengen met zijn vrouw en twee jongens.
Aparajithan Vaidyanathan is een Principal Enterprise Solutions Architect bij AWS. Hij is een cloudarchitect met meer dan 24 jaar ervaring in het ontwerpen en ontwikkelen van zakelijke, grootschalige en gedistribueerde softwaresystemen. Hij is gespecialiseerd in Generatieve AI en Machine Learning Data Engineering. Hij is een ambitieuze marathonloper en zijn hobby's zijn wandelen, fietsen en tijd doorbrengen met zijn vrouw en twee jongens.
 Aaron Klein is een Sr Applied Scientist bij AWS die werkt aan geautomatiseerde machine learning-methoden voor diepe neurale netwerken.
Aaron Klein is een Sr Applied Scientist bij AWS die werkt aan geautomatiseerde machine learning-methoden voor diepe neurale netwerken.
 Jacek Golebiowski is Sr Applied Scientist bij AWS.
Jacek Golebiowski is Sr Applied Scientist bij AWS.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

