딥 러닝에 빠져보세요(D2L.ai)는 누구나 딥 러닝에 접근할 수 있도록 해주는 오픈 소스 교과서입니다. PyTorch, JAX, TensorFlow 및 MXNet의 자체 포함 코드가 있는 대화형 Jupyter 노트북과 실제 예제, 설명 그림 및 수학이 특징입니다. 지금까지 캠브리지 대학, 스탠포드 대학, 매사추세츠 공과 대학, 카네기 멜론 대학, 칭화 대학 등 전 세계 2개 이상의 대학에서 D400L을 채택했습니다. 이 작품은 중국어, 일본어, 한국어, 포르투갈어, 터키어, 베트남어로도 제공되며 스페인어 및 기타 언어도 출시할 계획입니다.
지속적으로 최신 상태로 유지되고, 여러 저자가 작성하고, 여러 언어로 제공되는 온라인 책을 보유하는 것은 어려운 일입니다. 이 게시물에서는 D2L.ai가 다음을 사용하여 이 문제를 해결하는 데 사용한 솔루션을 제시합니다. 활성 사용자 지정 번역(ACT) 기능 of 아마존 번역 다국어 자동 번역 파이프라인 구축
사용 방법을 시연합니다. AWS 관리 콘솔 과 Amazon Translate 공개 API 자동 기계 배치 번역을 제공하고 영어와 중국어, 영어와 스페인어의 두 언어 쌍 간의 번역을 분석합니다. 또한 번역 품질과 효율성을 보장하기 위해 이 자동 번역 파이프라인에서 Amazon Translate를 사용할 때 모범 사례를 권장합니다.
솔루션 개요
Amazon Translate의 ACT 기능을 사용하여 여러 언어에 대한 자동 번역 파이프라인을 구축했습니다. ACT를 사용하면 맞춤형 번역 예제를 제공하여 즉석에서 번역 출력을 사용자 정의할 수 있습니다. 병렬 데이터. 병렬 데이터는 소스 언어의 텍스트 예제 모음과 하나 이상의 대상 언어로 된 원하는 번역으로 구성됩니다. 번역하는 동안 ACT는 병렬 데이터에서 가장 관련성이 높은 세그먼트를 자동으로 선택하고 해당 세그먼트 쌍을 기반으로 즉시 번역 모델을 업데이트합니다. 그 결과 병렬 데이터의 스타일 및 내용과 더 잘 일치하는 번역이 생성됩니다.
아키텍처에는 여러 하위 파이프라인이 포함되어 있습니다. 각 하위 파이프라인은 영어에서 중국어로, 영어에서 스페인어로 등과 같은 하나의 언어 번역을 처리합니다. 여러 번역 하위 파이프라인을 병렬로 처리할 수 있습니다. 각 하위 파이프라인에서 먼저 사람이 번역한 D2L 서적의 꼬리가 달린 번역 예제의 고품질 데이터 세트를 사용하여 Amazon Translate에서 병렬 데이터를 구축합니다. 그런 다음 런타임에 맞춤형 기계 번역 출력을 즉석에서 생성하여 더 나은 품질과 정확도를 달성합니다.
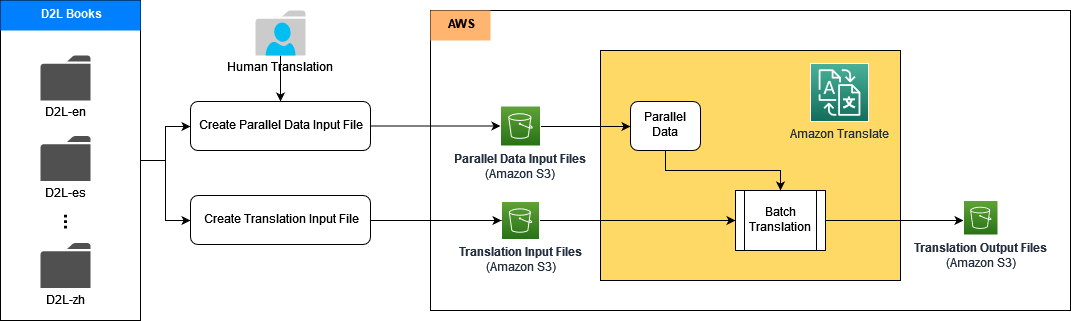
다음 섹션에서는 ACT와 함께 Amazon Translate를 사용하여 각 번역 파이프라인을 구축하는 방법을 보여줍니다. 아마존 세이지 메이커 과 아마존 단순 스토리지 서비스 (아마존 S3).
먼저 소스 문서, 참조 문서 및 병렬 데이터 교육 세트를 S3 버킷에 넣습니다. 그런 다음 Amazon Translate 공개 API를 사용하여 번역 프로세스를 실행하기 위해 SageMaker에서 Jupyter 노트북을 구축합니다.
사전 조건
이 게시물의 단계를 따르려면 다음과 같은 AWS 계정이 있는지 확인하십시오.
- 에 액세스 AWS 자격 증명 및 액세스 관리 (IAM) 역할 및 정책 구성용
- Amazon Translate, SageMaker 및 Amazon S3에 대한 액세스
- 소스 문서, 참조 문서, 병렬 데이터 데이터 세트 및 번역 출력을 저장하는 S3 버킷
ACT를 사용하여 Amazon Translate에 대한 IAM 역할 및 정책 생성
IAM 역할에는 Amazon Translate에 대한 사용자 지정 신뢰 정책이 포함되어야 합니다.
이 역할에는 원본 문서가 포함된 Amazon S3의 입력 폴더 및 하위 폴더에 대한 Amazon Translate 읽기 액세스 권한과 번역된 문서가 포함된 출력 S3 버킷 및 폴더에 대한 읽기/쓰기 액세스 권한을 부여하는 권한 정책도 있어야 합니다.
번역 작업을 위해 SageMaker에서 Jupyter 노트북을 실행하려면 SageMaker 실행 역할에 인라인 권한 정책을 부여해야 합니다. 이 역할은 Amazon Translate 서비스 역할을 SageMaker 노트북이 지정된 S3 버킷의 소스 및 번역된 문서에 액세스할 수 있도록 허용하는 SageMaker에 전달합니다.
병렬 데이터 학습 샘플 준비
ACT의 병렬 데이터는 예를 들어 소스 언어(영어)와 대상 언어(중국어)의 쌍과 같은 텍스트 예제 쌍 목록으로 구성된 입력 파일에 의해 훈련되어야 합니다. 입력 파일은 TMX, CSV 또는 TSV 형식일 수 있습니다. 다음 스크린샷은 CSV 입력 파일의 예를 보여줍니다. 첫 번째 열은 소스 언어 데이터(영어)이고 두 번째 열은 대상 언어 데이터(중국어)입니다. 다음 예제는 D2L-en 책과 D2L-zh 책에서 추출한 것입니다.

Amazon Translate에서 사용자 지정 병렬 데이터 교육 수행
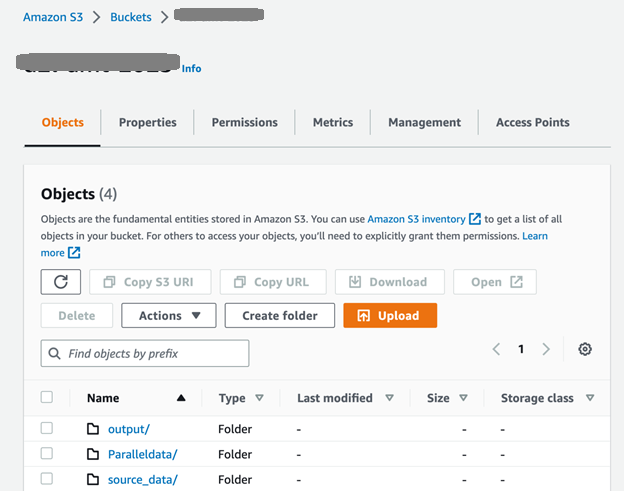
먼저 다음 스크린샷과 같이 S3 버킷과 폴더를 설정합니다. 그만큼 source_data 폴더에는 번역 이전의 소스 문서가 포함되어 있습니다. 일괄 번역 후 생성된 문서는 출력 폴더에 넣습니다. 그만큼 ParallelData 폴더에는 이전 단계에서 준비된 병렬 데이터 입력 파일이 있습니다.
입력 파일을 업로드한 후 source_data 폴더에서 CreateParallelData API Amazon Translate에서 병렬 데이터 생성 작업을 실행하려면:
새로운 교육 데이터 세트로 기존 병렬 데이터를 업데이트하려면 다음을 사용할 수 있습니다. 업데이트ParallelData API:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
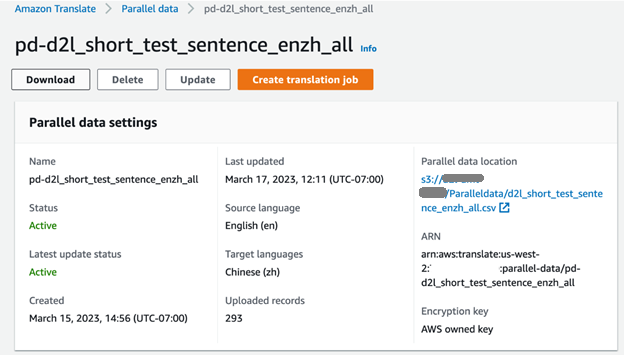
Amazon Translate 콘솔에서 훈련 작업 진행 상황을 확인할 수 있습니다. 작업이 완료되면 병렬 데이터 상태가 다음과 같이 표시됩니다. 최근활동 사용할 준비가 되었습니다.
병렬 데이터를 사용하여 비동기 배치 번역 실행
일괄 번역은 여러 개의 원본 문서를 대상 언어로 된 문서로 자동 번역하는 프로세스에서 수행할 수 있습니다. 이 프로세스에는 소스 문서를 S3 버킷의 입력 폴더에 업로드한 다음 StartTextTranslationJob API 비동기 번역 작업을 시작하기 위한 Amazon Translate:
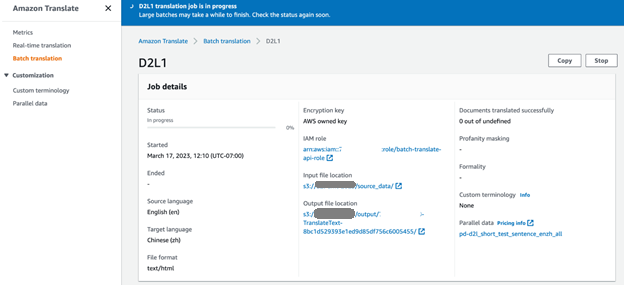
대량 번역을 위해 D2L 책(D2L-en)에서 영어로 된 XNUMX개의 소스 문서를 선택했습니다. Amazon Translate 콘솔에서 번역 작업 진행 상황을 모니터링할 수 있습니다. 작업 상태가 다음으로 변경될 때 진행완료, S2 버킷 출력 폴더에서 중국어(D3L-zh)로 번역된 문서를 찾을 수 있습니다.
번역 품질 평가
Amazon Translate에서 ACT 기능의 효과를 입증하기 위해 병렬 데이터 없이 Amazon Translate 실시간 번역이라는 기존 방법을 적용하여 동일한 문서를 처리하고 출력을 ACT로 일괄 번역 출력과 비교했습니다. BLEU(BiLingual Evaluation Understudy) 점수를 사용하여 두 방법 간의 번역 품질을 벤치마킹했습니다. 기계 번역 결과물의 품질을 정확하게 측정하는 유일한 방법은 전문가의 검토를 받고 품질을 평가하는 것입니다. 그러나 BLEU는 두 출력 간의 상대적인 품질 개선 추정치를 제공합니다. BLEU 점수는 일반적으로 0-1 사이의 숫자입니다. 기계 번역과 참조 인간 번역의 유사성을 계산합니다. 점수가 높을수록 자연어 이해(NLU)의 품질이 우수함을 나타냅니다.
우리는 영어에서 중국어로(en에서 zh로), 중국어에서 영어로(zh에서 en로), 영어에서 스페인어로(en에서 es로), 스페인어에서 영어로(es에서 en로)의 네 가지 파이프라인에서 일련의 문서를 테스트했습니다. 다음 그림은 ACT를 사용한 번역이 모든 번역 파이프라인에서 더 높은 평균 BLEU 점수를 생성했음을 보여줍니다.
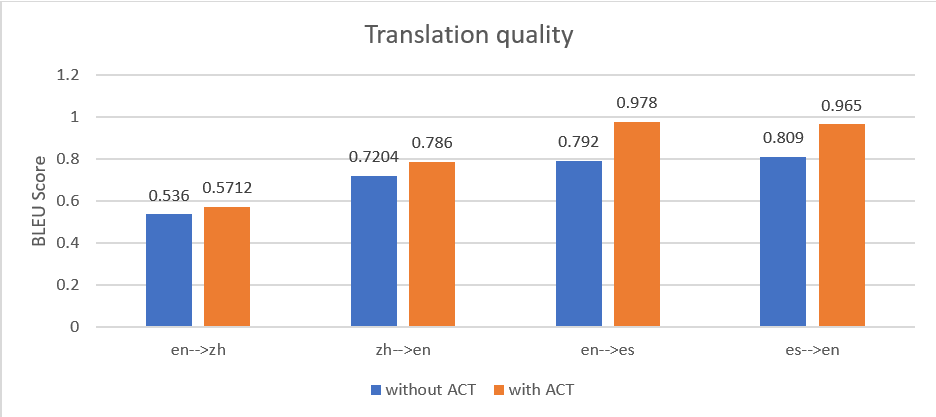
또한 병렬 데이터 쌍이 더 세분화될수록 번역 성능이 더 좋아지는 것을 관찰했습니다. 예를 들어, 10개의 항목이 포함된 단락 쌍과 함께 다음과 같은 병렬 데이터 입력 파일을 사용합니다.

동일한 콘텐츠에 대해 문장 쌍과 16개 항목이 있는 다음과 같은 병렬 데이터 입력 파일을 사용합니다.

두 병렬 데이터 입력 파일을 사용하여 Amazon Translate에서 두 개의 병렬 데이터 엔터티를 구성한 다음 동일한 소스 문서로 두 개의 배치 번역 작업을 생성했습니다. 다음 그림은 출력 번역을 비교합니다. 영중 번역과 중영 번역 모두에서 문장 쌍이 있는 병렬 데이터를 사용한 출력이 단락 쌍이 있는 병렬 데이터를 사용한 출력보다 성능이 우수함을 보여줍니다.
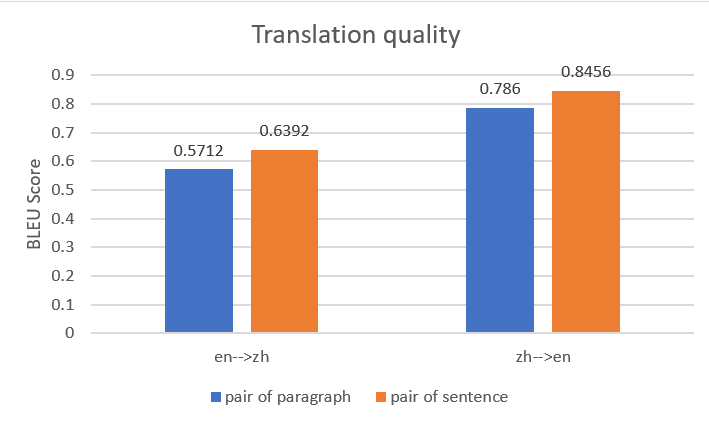
이러한 벤치마크 분석에 대해 자세히 알아보려면 다음을 참조하십시오. "Dive into Deep Learning"을 위한 자동 기계 번역 및 동기화.
정리
향후 반복되는 비용을 방지하려면 생성한 리소스를 정리하는 것이 좋습니다.
- Amazon Translate 콘솔에서 생성한 병렬 데이터를 선택하고 .. 또는 다음을 사용할 수 있습니다. 삭제ParallelData API 또는 AWS 명령 줄 인터페이스 (AWS CLI) 병렬 데이터 삭제 병렬 데이터를 삭제하는 명령입니다.
- S3 버킷 삭제 소스 및 참조 문서, 번역된 문서 및 병렬 데이터 입력 파일을 호스팅하는 데 사용됩니다.
- IAM 역할 및 정책을 삭제합니다. 지침은 다음을 참조하십시오. 역할 또는 인스턴스 프로필 삭제 과 IAM 정책 삭제.
결론
이 솔루션을 통해 인간 번역가의 작업량을 80% 줄이는 동시에 번역 품질을 유지하고 다국어를 지원하는 것을 목표로 합니다. 이 솔루션을 사용하여 번역 품질과 효율성을 개선할 수 있습니다. 다른 언어에 대한 솔루션 아키텍처 및 번역 품질을 더욱 개선하기 위해 노력하고 있습니다.
귀하의 피드백은 언제나 환영합니다. 댓글 섹션에 생각과 질문을 남겨주세요.
저자 소개
 바이 윤페이 AWS의 선임 솔루션 아키텍트입니다. AI/ML, 데이터 과학 및 분석에 대한 배경 지식을 갖춘 Yunfei는 고객이 AWS 서비스를 채택하여 비즈니스 결과를 제공하도록 돕습니다. 그는 복잡한 기술적 과제를 극복하고 전략적 목표를 추진하는 AI/ML 및 데이터 분석 솔루션을 설계합니다. Yunfei는 전자 및 전기 공학 박사 학위를 받았습니다. 업무 외 시간에 Yunfei는 독서와 음악을 즐깁니다.
바이 윤페이 AWS의 선임 솔루션 아키텍트입니다. AI/ML, 데이터 과학 및 분석에 대한 배경 지식을 갖춘 Yunfei는 고객이 AWS 서비스를 채택하여 비즈니스 결과를 제공하도록 돕습니다. 그는 복잡한 기술적 과제를 극복하고 전략적 목표를 추진하는 AI/ML 및 데이터 분석 솔루션을 설계합니다. Yunfei는 전자 및 전기 공학 박사 학위를 받았습니다. 업무 외 시간에 Yunfei는 독서와 음악을 즐깁니다.
 레이첼 후 AWS Machine Learning University(MLU)의 응용 과학자입니다. 그녀는 ML Operations(MLOps) 및 Accelerator Computer Vision을 포함한 몇 가지 과정 설계를 이끌었습니다. Rachel은 AWS 수석 연사이며 AWS re:Invent, NVIDIA GTC, KDD 및 MLOps Summit을 포함한 최고의 컨퍼런스에서 연설했습니다. AWS에 합류하기 전에 Rachel은 자연어 처리 모델을 구축하는 기계 학습 엔지니어로 일했습니다. 일 외에는 요가, 궁극의 프리스비, 독서, 여행을 즐깁니다.
레이첼 후 AWS Machine Learning University(MLU)의 응용 과학자입니다. 그녀는 ML Operations(MLOps) 및 Accelerator Computer Vision을 포함한 몇 가지 과정 설계를 이끌었습니다. Rachel은 AWS 수석 연사이며 AWS re:Invent, NVIDIA GTC, KDD 및 MLOps Summit을 포함한 최고의 컨퍼런스에서 연설했습니다. AWS에 합류하기 전에 Rachel은 자연어 처리 모델을 구축하는 기계 학습 엔지니어로 일했습니다. 일 외에는 요가, 궁극의 프리스비, 독서, 여행을 즐깁니다.
![]() 왓슨 스리바산 AWS의 자연어 처리 서비스인 Amazon Translate의 수석 제품 관리자입니다. 주말에는 그가 태평양 북서부에서 야외 활동을 하는 것을 볼 수 있습니다.
왓슨 스리바산 AWS의 자연어 처리 서비스인 Amazon Translate의 수석 제품 관리자입니다. 주말에는 그가 태평양 북서부에서 야외 활동을 하는 것을 볼 수 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- EVM 금융. 탈중앙화 금융을 위한 통합 인터페이스. 여기에서 액세스하십시오.
- 퀀텀미디어그룹. IR/PR 증폭. 여기에서 액세스하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

