모델 튜닝은 기계 학습(ML) 모델에 대한 최적의 매개변수 및 구성을 찾는 실험 프로세스로, 유효성 검사 데이터 세트를 통해 원하는 최상의 결과를 얻을 수 있습니다. 성능 메트릭을 사용한 단일 목표 최적화는 ML 모델을 조정하는 가장 일반적인 접근 방식입니다. 그러나 예측 성능 외에도 특정 응용 프로그램에 대해 고려해야 할 여러 목표가 있을 수 있습니다. 예를 들어,
- 공정성 – 여기서의 목표는 특히 인간이 알고리즘 결정에 종속될 때 데이터의 특정 하위 그룹 간 모델 결과의 편향을 완화하도록 모델을 장려하는 것입니다. 예를 들어, 신용 대출 신청은 정확할 뿐만 아니라 다양한 모집단 하위 그룹에 편향되지 않아야 합니다.
- 추론 시간 – 여기서 목표는 모델 호출 중 추론 시간을 줄이는 것입니다. 예를 들어, 음성 인식 시스템은 동일한 언어의 다양한 방언을 정확하게 이해해야 할 뿐만 아니라 비즈니스 프로세스에서 허용되는 지정된 시간 제한 내에서 작동해야 합니다.
- 에너지 효율성 – 여기서 목표는 더 작은 에너지 효율적인 모델을 교육하는 것입니다. 예를 들어, 신경망 모델은 모바일 장치에서 사용하기 위해 압축되므로 네트워크를 통과하는 데 필요한 FLOPS의 수를 줄임으로써 자연스럽게 에너지 소비를 줄입니다.
다목적 최적화 방법은 원하는 메트릭 간의 서로 다른 장단점을 나타냅니다. 여기에는 동시에 충족되는 여러 메트릭에 대한 제약 조건 집합에 따라 목적 함수의 전역 최소값을 찾는 작업이 포함될 수 있습니다.
Amazon SageMaker 자동 모델 튜닝(AMT) 알고리즘과 하이퍼파라미터 범위를 사용하여 데이터 세트에서 많은 SageMaker 교육 작업을 실행하여 최상의 모델 버전을 찾습니다. 그런 다음 사용자가 정의한 메트릭(예: 정확도, auc, 재현율)으로 측정된 대로 최상의 성능을 발휘하는 모델을 생성하는 하이퍼파라미터 값을 선택합니다. Amazon SageMaker 자동 모델 튜닝을 사용하면 데이터 세트에서 교육 작업을 실행하여 최상의 모델 버전을 찾을 수 있습니다. 여러 검색 전략, Bayesian, Random search, Grid search, Hyperband 등이 있습니다.
Amazon SageMaker 명확화 데이터 준비 중, 모델 교육 후 및 배포된 모델에서 잠재적 편향을 감지할 수 있습니다. 현재 선택할 수 있는 21가지 측정항목을 제공합니다. 이러한 측정항목은 명확하게 하다 파이썬 패키지 및 github 저장소 여기에서 지금 확인해 보세요.. Amazon SageMaker Clarify의 메트릭으로 편향을 측정하는 방법에 대해 자세히 알아볼 수 있습니다. Amazon SageMaker Clarify가 편향을 감지하는 데 어떻게 도움이 되는지 알아보십시오..
이 블로그에서는 Amazon SageMaker AMT로 ML 모델을 자동으로 조정하여 단일 결합 메트릭을 생성하여 정확성과 공정성 목표를 모두 달성하는 방법을 보여줍니다. 다음과 같은 정확도 지표로 신용 위험 예측의 금융 서비스 사용 사례를 시연합니다. 곡선 아래 면적(AUC) 성능 및 편향 메트릭을 측정하기 위해 예측된 레이블의 양수 비율의 차이(DPPL) SageMaker Clarify에서 다양한 인구 통계 그룹에 대한 모델 예측의 불균형을 측정합니다. 이 예제의 코드는 다음에서 사용할 수 있습니다. GitHub의.
신용 리스크 예측의 공정성
신용 대출 업계는 대출 신청을 처리하기 위해 신용 점수에 크게 의존합니다. 일반적으로 신용 점수는 신청자의 대출 및 상환 이력을 반영하며 대출 기관은 개인의 신용도를 판단할 때 이를 참조합니다. 결제 회사와 은행은 특정 애플리케이션과 관련된 위험을 식별하고 경쟁력 있는 신용 상품을 제공할 수 있는 시스템을 구축하는 데 관심이 있습니다. 기계 학습(ML) 모델을 사용하여 과거 지원자 데이터를 처리하고 신용 위험 프로필을 예측하는 시스템을 구축할 수 있습니다. 데이터에는 지원자의 재정 및 고용 이력, 인구 통계, 새로운 신용/대출 상황이 포함될 수 있습니다. 특정 지원자가 미래에 불이행할지 여부를 예측하는 모델에는 항상 약간의 통계적 불확실성이 있습니다. 시스템은 시간이 지남에 따라 불이행할 수 있는 응용 프로그램을 거부하는 것과 결국에는 신뢰할 수 있는 응용 프로그램을 수락하는 것 사이에서 절충점을 제공해야 합니다.
이러한 시스템의 비즈니스 소유자는 기존 및 향후 규정 준수 요구 사항에 따라 모델의 유효성과 품질을 보장해야 합니다. 그들은 고객을 공정하게 대우하고 의사 결정에 투명성을 제공할 의무가 있습니다. 그들은 긍정적인 모델 예측이 다양한 그룹(예: 성별, 인종, 민족, 이민 상태 등) 간에 불균형하지 않도록 하기를 원할 수 있습니다. 필요한 데이터가 수집되면 ML 모델 교육은 일반적으로 분류 정확도 또는 AUC 점수와 같은 메트릭을 사용하여 기본 목표로 예측 성능을 최적화합니다. 또는 주어진 성능 목표가 있는 모델을 공정성 메트릭으로 제한하여 특정 요구 사항이 유지되도록 할 수 있습니다. 모델을 제한하는 그러한 기술 중 하나는 공정성 인식 하이퍼파라미터 튜닝입니다. 이러한 전략을 적용하면 최상의 후보 모델이 높은 예측 성능을 유지하면서 제약이 없는 모델보다 바이어스가 낮을 수 있습니다.
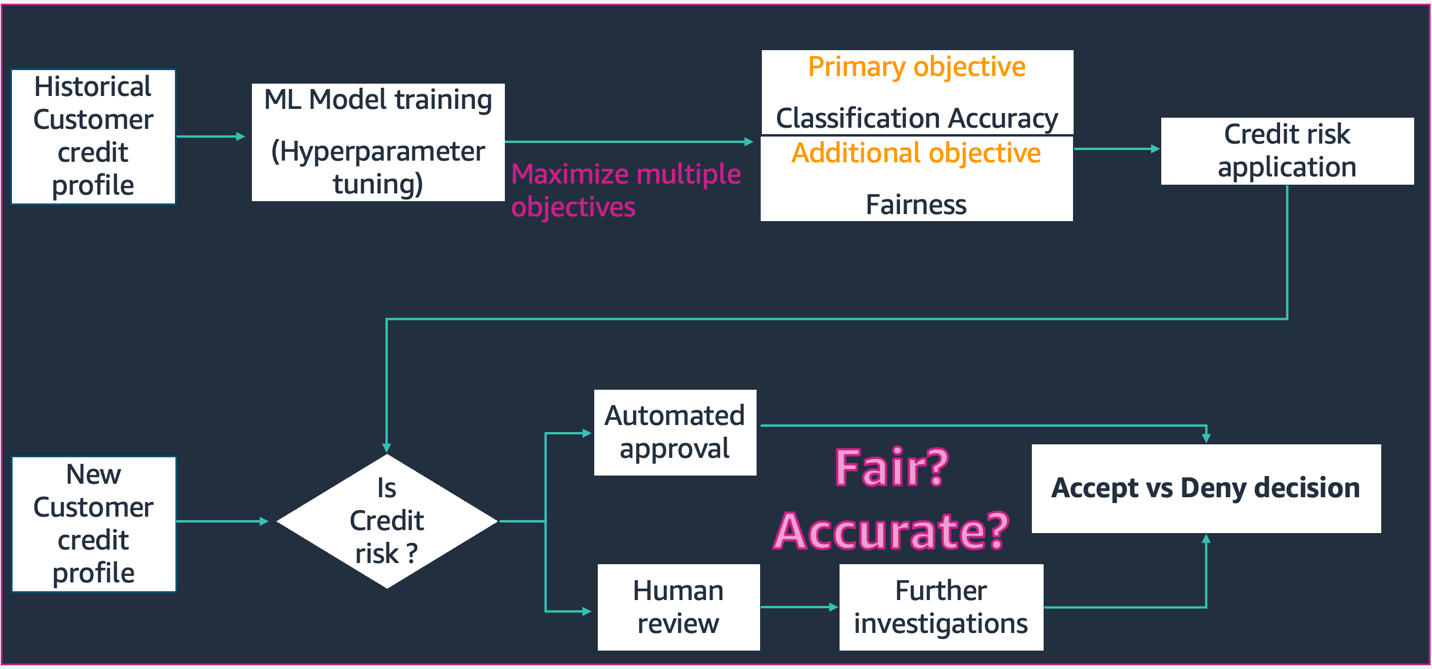
이 회로도에 묘사된 시나리오에서,
- ML 모델은 과거 고객 신용 프로필 데이터로 구축됩니다. 모델 교육 및 하이퍼파라미터 튜닝 프로세스는 분류 정확도 및 공정성을 비롯한 여러 목표를 극대화합니다. 모델은 프로덕션 시스템의 기존 비즈니스 프로세스에 배포됩니다.
- 새 고객 신용 프로필은 신용 위험에 대해 평가됩니다. 위험도가 낮은 경우 자동화된 프로세스를 거칠 수 있습니다. 고위험 애플리케이션에는 최종 승인 또는 거부 결정 전에 사람의 검토가 포함될 수 있습니다.
설계 및 개발, 배포 및 운영 중에 수집된 결정 및 메트릭은 다음을 사용하여 문서화할 수 있습니다. SageMaker 모델 카드 그리고 이해관계자들과 공유합니다.
이 사용 사례는 SageMaker 자동 모델 튜닝을 통해 정확성과 공정성의 결합된 객관적 지표에 대한 하이퍼파라미터를 미세 조정하여 특정 그룹에 대한 모델 편향을 줄이는 방법을 보여줍니다. 우리는 South German Credit 데이터 세트(남부 독일 신용 데이터 세트).
지원자 데이터는 다음 범주로 나눌 수 있습니다.
- 인구 통계학
- 재무 데이터
- 고용 기록
- 대출 목적
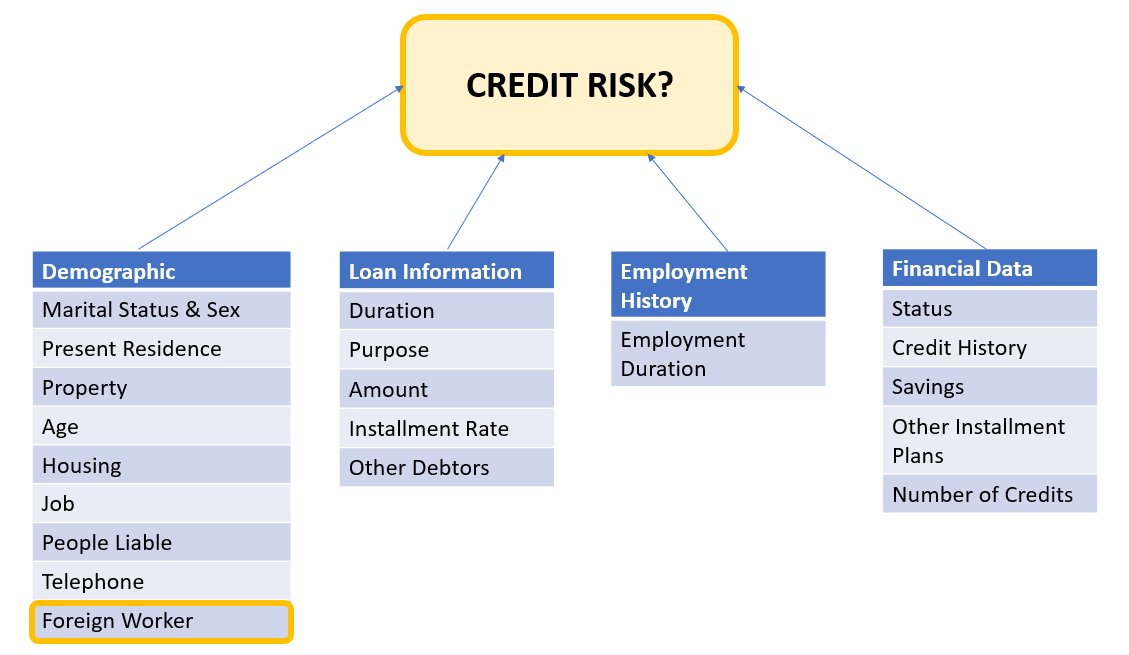
이 예에서는 특히 '외국인 근로자' 인구 통계를 살펴보고 특정 하위 그룹에 대해 높은 정확도와 낮은 편향으로 신용 신청 결정을 예측하는 모델을 조정합니다.
여러 가지가있다. 편향 메트릭 데이터의 특정 하위 그룹과 관련하여 시스템의 공정성을 평가하는 데 사용할 수 있습니다. 여기서는 예측 레이블의 양수 비율 차이의 절대값을 사용합니다(DPPL) SageMaker Clarify에서. 간단히 말해서 DPPL은 비외국인 근로자와 외국인 근로자 간의 긍정적인 등급(우수한 신용) 할당의 차이를 측정합니다.
예를 들어 전체 외국인 근로자의 4.5%가 모델에 의해 긍정적인 라벨이 지정되고 모든 비외국인 근로자의 13.7%가 긍정적인 라벨이 지정된 경우 DPPL = 0.137 – 0.045 = 0.092.
솔루션 아키텍처
아래 그림은 Amazon SageMaker에서 XGBoost를 사용하는 자동 모델 튜닝 작업의 아키텍처에 대한 높은 수준의 개요를 보여줍니다.

솔루션에서 SageMaker Processing은 Amazon S3의 교육 데이터 세트를 전처리합니다. Amazon SageMaker 자동 조정은 연결된 EC2 인스턴스 및 EBS 볼륨을 사용하여 여러 SageMaker 교육 작업을 인스턴스화합니다. 알고리즘용 컨테이너(XGBoost)는 각 작업의 Amazon ECR에서 로드됩니다. SageMaker AMT는 지정된 알고리즘 스크립트와 다양한 하이퍼파라미터를 사용하여 사전 처리된 데이터 세트에서 많은 교육 작업을 실행하여 최상의 모델 버전을 찾습니다. 출력 지표는 모니터링을 위해 Amazon CloudWatch에 기록됩니다.
이 사용 사례에서 튜닝하는 하이퍼파라미터는 다음과 같습니다.
- η – 과적합을 방지하기 위해 업데이트에 사용되는 단계 크기 축소.
- min_child_weight – 자식에 필요한 인스턴스 가중치(헤시안)의 최소 합계.
- 감마 – 트리의 리프 노드에서 추가 분할을 만드는 데 필요한 최소 손실 감소.
- 최대 _ 깊이 – 트리의 최대 깊이.
SageMaker AMT에서 사용할 수 있는 이러한 하이퍼파라미터 및 기타 항목의 정의는 찾을 수 있습니다. 여기에서 지금 확인해 보세요..
먼저, 자동 모델 튜닝으로 하이퍼파라미터를 튜닝하기 위한 단일 성능 목표 메트릭의 기본 시나리오를 시연합니다. 그런 다음 성능 메트릭과 공정성 메트릭의 조합으로 지정된 다목적 메트릭의 최적화된 시나리오를 시연합니다.
단일 메트릭 하이퍼파라미터 튜닝(기준선)
개별 교육 작업을 평가하기 위해 튜닝 작업에 대한 여러 지표를 선택할 수 있습니다. 아래 코드 스니펫에 따라 단일 목표 측정항목을 다음과 같이 지정합니다. objective_metric_name. 하이퍼파라미터 튜닝 작업은 선택한 목표 지표에 대해 최상의 값을 제공한 훈련 작업을 반환합니다.
이 기본 시나리오에서는 아래와 같이 AUC(Area Under Curve)를 조정합니다. 우리는 AUC만 최적화하고 공정성과 같은 다른 메트릭은 최적화하지 않는다는 점에 유의해야 합니다.
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner hyperparameter_ranges = {'eta': ContinuousParameter(0, 1), 'min_child_weight': IntegerParameter(1, 10), 'gamma': IntegerParameter(1, 5), 'max_depth': IntegerParameter(1, 10)} objective_metric_name = 'validation:auc' tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10,
) tuning_job_name = "xgb-tuner-{}".format(strftime("%d-%H-%M-%S", gmtime()))
inputs = {'train': train_data_path, 'validation': val_data_path}
tuner.fit(inputs, job_name=tuning_job_name)
tuner.wait()
tuner_metrics = sagemaker.HyperparameterTuningJobAnalytics(tuning_job_name)이런 맥락에서 max jobs 단일 교육 작업을 조정할 횟수를 지정하고 거기에서 최상의 교육 작업을 찾을 수 있습니다.
다중 목표 하이퍼파라미터 튜닝(공정성 최적화)
우리는 이 문서에 설명된 대로 하이퍼파라미터 튜닝을 통해 여러 목표 메트릭을 최적화하려고 합니다. 종이. 그러나 SageMaker AMT는 여전히 단일 지표만 입력으로 허용합니다.
이 문제를 해결하기 위해 여러 메트릭을 단일 메트릭 함수로 표현하고 이 메트릭을 최적화합니다.
- 최대M(y1 ,y2 ,θ)
- y1 ,y2 는 서로 다른 메트릭입니다. 예를 들어 AUC 점수 및 DPPL.
- M(⋅,⋅,θ)는 스칼라화 함수이며 고정 매개변수로 매개변수화됩니다.
가중치가 높을수록 모델 튜닝에서 특정 목표에 유리합니다. 가중치는 경우에 따라 주의할 수 있으며 사용 사례에 따라 다른 가중치를 시도해야 할 수도 있습니다. 이 예에서는 AUC 및 DPPL에 대한 가중치가 휴리스틱하게 설정되었습니다. 이것이 코드에서 어떻게 보이는지 살펴보겠습니다. 성능을 위한 AUC 점수와 공정성을 위한 DPPL의 조합 함수를 기반으로 단일 메트릭을 반환하는 훈련 작업을 볼 수 있습니다. 여러 목표에 대한 하이퍼파라미터 최적화 범위는 단일 목표와 동일합니다. 유효성 검사 메트릭을 "auc"로 전달하고 있지만 뒤에서는 아래 함수 목록에서 마지막으로 설명한 대로 결합된 메트릭 함수의 결과를 반환하고 있습니다.
다음은 Multi Objective 최적화 기능입니다.
objective_metric_name = 'validation:auc'
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
max_jobs=100,
max_parallel_jobs=10
)AUC 점수를 계산하는 기능은 다음과 같습니다.
def eval_auc_score(predt, dtrain):
fY = [1 if p > 0.5 else 0 for p in predt]
y = dtrain.get_label()
auc_score = roc_auc_score(y, fY)
return auc_score다음은 DPPL 점수를 계산하는 기능입니다.
def eval_dppl(predt, dtrain):
dtrain_np = dmatrix_to_numpy(dtrain)
# groups: an np array containing 1 or 2
groups = dtrain_np[:, -1]
# sensitive_facet_index: boolean column indicating sensitive group
sensitive_facet_index = pd.Series(groups - 1, dtype=bool)
# positive_predicted_label_index: boolean column indicating positive predicted labels
positive_label_index = pd.Series(predt > 0.5)
return abs(DPPL(predt, sensitive_facet_index, positive_label_index))다음은 Combined Metric의 기능입니다.
def eval_combined_metric(predt, dtrain):
auc_score = eval_auc_score(predt, dtrain)
DPPL = eval_dppl(predt, dtrain)
# Assign weight of 3 to AUC and 1 to DPPL
# Maximize (1-DPPL) for the purpose of minimizing DPPL combined_metric = ((3*auc_score)+(1-DPPL))/4 print("DPPL, AUC Score, Combined Metric: ", DPPL, auc_score, combined_metric)
return "auc", combined_metric실험 및 결과
바이어스 데이터 세트를 위한 합성 데이터 생성
원본 South German Credit 데이터 세트에는 1000개의 레코드가 포함되어 있으며 모델 예측의 편향이 외국인 근로자에게 불리한 데이터 세트를 생성하기 위해 종합적으로 100개의 레코드를 추가로 생성했습니다. 이는 실제 세계에서 나타날 수 있는 편견을 시뮬레이션하기 위해 수행됩니다. "신용불량" 신청자로 분류된 외국인 근로자의 신규 기록은 동일한 분류를 가진 기존 외국인 근로자로부터 추정되었습니다.
합성 데이터를 생성하는 많은 라이브러리/기술이 있으며 우리는 합성 데이터 보관소 (DPPLV).
다음 코드 스니펫에서 남부 독일 신용 데이터 세트를 사용하여 DPPLV로 합성 데이터가 생성되는 방식을 확인할 수 있습니다.
# Parameters for generated data
# How many rows of synthetic data
num_rows = 100 # Select all foreign workers who were accepted (foreign_worker value 1 credit_risk 1)
ForeignWorkerData = training_data.loc[(training_data['foreign_worker'] == 1) & (training_data['credit_risk'] == 1)] # Fit Foreign Worker data to SDV model
model = GaussianCopula()
model.fit(ForeignWorkerData) # Generate Synthetic foreign worker data based on rows stated
SynthForeignWorkers = model.sample(Rows)원본 데이터 세트에서 허용된 외국인 근로자를 기반으로 100개의 새로운 외국인 근로자 합성 레코드를 생성했습니다. 이제 해당 레코드를 가져와 "credit_risk" 레이블을 0(신용 불량)으로 변환합니다. 이렇게 하면 이러한 외국인 근로자를 부당하게 신용 불량으로 표시하여 데이터 세트에 편향을 삽입합니다.
SynthForeignWorkers.loc[SynthForeignWorkers['credit_risk'] == 1, 'credit_risk'] = 0아래 그래프를 통해 데이터 세트의 편향을 살펴봅니다.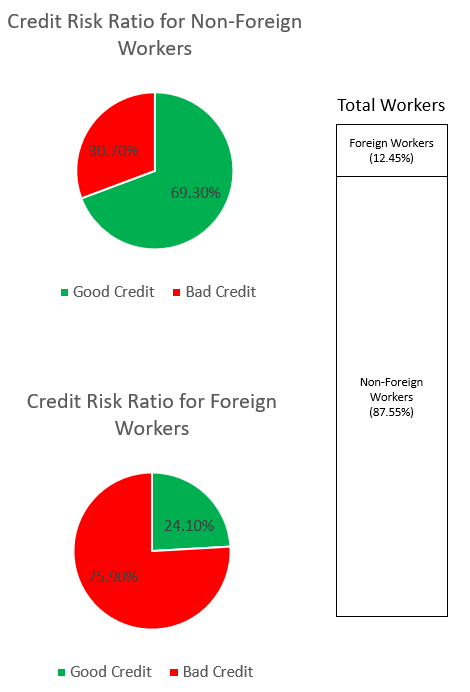
상단의 파이 그래프는 신용 불량 또는 신용 불량으로 분류된 비외국인 근로자의 비율을 보여주고 하단 파이 그래프는 외국인 근로자의 비율을 보여줍니다. '신용불량'으로 분류된 외국인 근로자의 비율은 75.90%로 동일하게 분류된 비외국인 근로자의 30.70%를 크게 상회합니다. 스택 막대는 외국인 및 비외국인 근로자 범주에서 전체 근로자의 거의 유사한 백분율 분석을 표시합니다.
우리는 ML 모델이 데이터의 명시적 기능 또는 암시적 프록시 기능을 통해 외국인 근로자에 대한 강한 편견을 학습하지 않도록 하고자 합니다. 추가 공정성 목표를 통해 ML 모델을 안내하여 외국인 근로자에 대한 낮은 신용도 편향을 완화합니다.
성능과 공정성을 모두 조정한 후 모델 성능
이 차트는 SageMaker AMT에서 실행하는 최대 100개의 조정 작업과 그에 상응하는 결합된 목표 메트릭 값의 밀도 플롯을 보여줍니다. 우리가 설정했지만 max jobs 100까지 사용자 임의로 변경 가능합니다. 결합된 메트릭은 AUC와 DPPL의 조합으로 다음 함수를 사용했습니다. (3*AUC + (1-DPPL)) / 4. (DPPL) 대신 (1-DPPL)을 사용하는 이유는 가능한 가장 낮은 DPPL에 대한 결합된 목표를 최대화하고 싶기 때문입니다(DPPL이 낮을수록 외국인 근로자에 대한 편견이 낮아짐을 의미함). 플롯은 AMT가 가장 높은 결합된 평가 메트릭 값인 0.68을 반환하는 XGBoost 모델에 대한 최상의 하이퍼파라미터를 식별하는 데 어떻게 도움이 되는지 보여줍니다.
메트릭이 결합된 모델 성능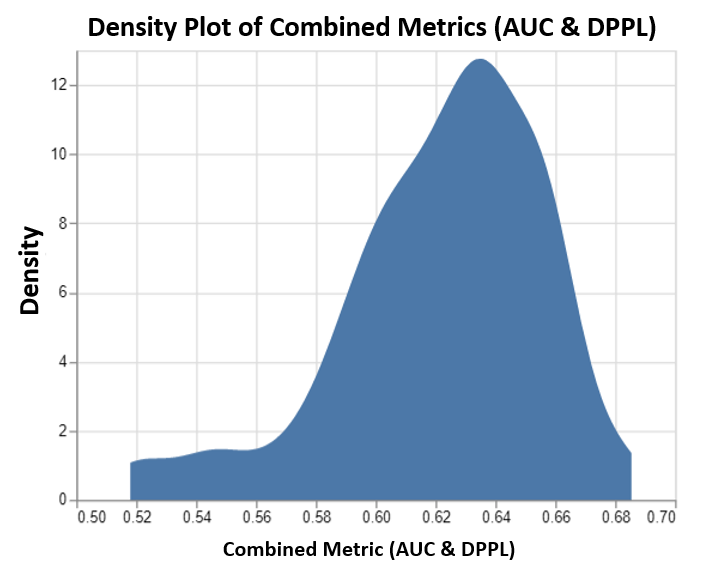
아래에서 AUC 및 DPPL의 개별 메트릭에 대한 파레토 프런트 차트를 살펴봅니다. 여기에서는 Pareto Front 차트를 사용하여 여러 목표(이 경우에는 두 개의 메트릭 값(AUC 및 DPPL)) 간의 장단점을 시각적으로 나타냅니다. 곡선 전면에 있는 점은 똑같이 좋은 것으로 간주되며 한 메트릭은 다른 메트릭을 저하시키지 않고는 개선할 수 없습니다. Pareto 차트를 사용하면 두 메트릭 측면에서 기준선(빨간색 원)에 대해 서로 다른 작업이 어떻게 수행되었는지 확인할 수 있습니다. 또한 가장 최적의 작업(녹색 삼각형)을 보여줍니다. 빨간색 원과 녹색 삼각형의 위치는 결합된 메트릭이 실제로 예상대로 수행되고 두 메트릭에 대해 진정으로 최적화되는지 이해할 수 있기 때문에 중요합니다. 파레토 프런트 차트를 생성하는 코드는 다음의 노트북에 포함되어 있습니다. GitHub의.
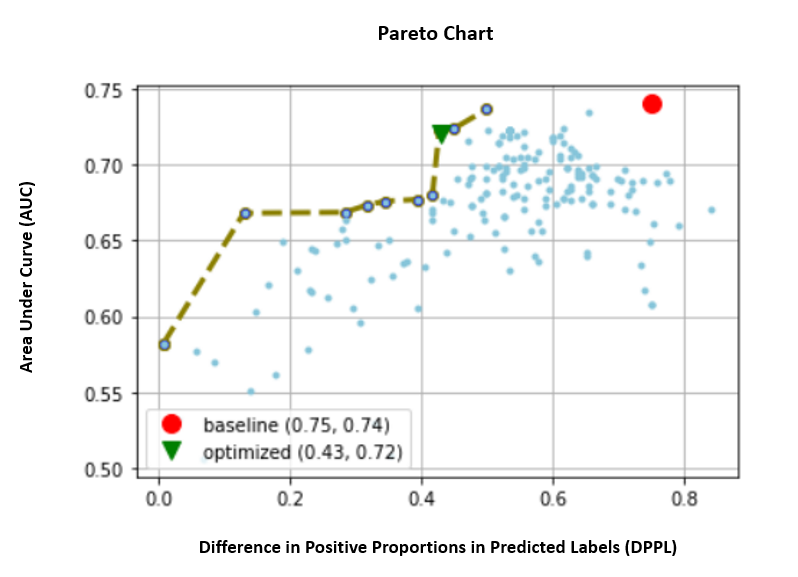
이 시나리오에서는 DPPL 값이 낮을수록 바람직하고(편향이 적음) AUC가 높을수록 좋습니다(성능 향상).
여기서 기준선(빨간색 원)은 목표 메트릭이 AUC 단독인 시나리오를 나타냅니다. 즉, 베이스라인은 DPPL을 전혀 고려하지 않고 AUC에 대해서만 최적화합니다(공정성을 위한 미세 조정 없음). 기준선의 AUC 점수는 0.74로 양호하지만 DPPL 점수는 0.75로 공정성에서는 좋지 않습니다.
최적화된 모델(녹색 삼각형)은 AUC:DPPL에 대한 가중치 비율이 3:1인 결합 메트릭에 대해 미세 조정될 때 최상의 후보 모델을 나타냅니다. 최적화된 모델의 AUC 점수는 0.72로 양호하고 DPPL 점수는 0.43(낮은 편향)으로 낮습니다. 이 조정 작업은 DPPL이 AUC를 크게 떨어뜨리지 않고 기준선보다 훨씬 낮을 수 있는 모델 구성을 찾았습니다. DPPL 점수가 더 낮은 모델은 Pareto Front를 따라 녹색 삼각형을 더 왼쪽으로 이동하여 식별할 수 있습니다. 따라서 우리는 외국인 근로자 하위 그룹에 대한 공정성과 우수한 성과를 내는 모델이라는 결합된 목표를 달성했습니다.
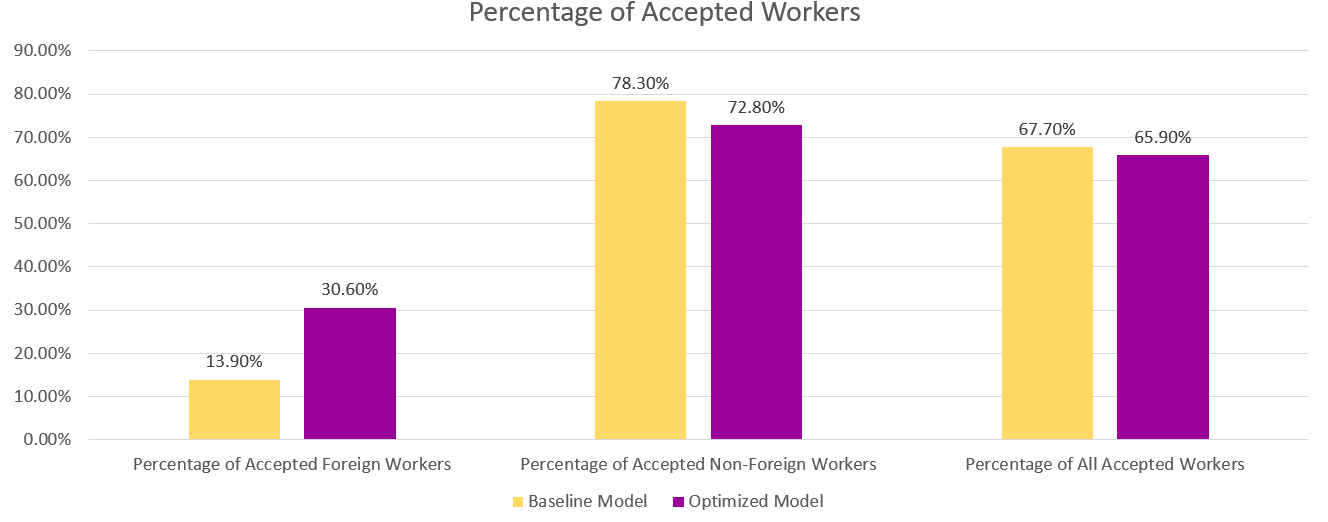
아래 차트에서 기본 모델과 최적화된 모델의 예측 결과를 볼 수 있습니다. 성과와 공정성을 결합한 최적화된 모델은 기본 모델의 30.6%에 비해 13.9%의 외국인 근로자에 대해 긍정적인 결과를 예측합니다. 따라서 최적화된 모델은 이 하위 그룹에 대한 모델 편향을 줄입니다.
결론
이 블로그는 실제 애플리케이션을 위한 SageMaker 자동 모델 튜닝을 사용하여 다중 목표 최적화를 구현하는 방법을 보여줍니다. 많은 경우 실제 세계에서 수집된 데이터는 특정 하위 그룹에 대해 편향될 수 있습니다. 자동 모델 튜닝을 사용한 다중 목표 최적화를 통해 고객은 정확성 외에도 공정성을 최적화하는 ML 모델을 쉽게 구축할 수 있습니다. 신용 위험 예측의 예를 시연하고 특히 외국인 근로자에 대한 공정성을 살펴봅니다. 우리는 고성능으로 모델을 계속 훈련시키면서 공정성과 같은 다른 메트릭을 최대화할 수 있음을 보여줍니다. 읽은 내용이 흥미로웠다면 Github에 호스팅된 코드 예제를 사용해 볼 수 있습니다. 여기에서 지금 확인해 보세요..
저자 소개
 무니시 다브라 Amazon Web Services(AWS)의 선임 솔루션 아키텍트입니다. 그의 현재 초점 영역은 AI/ML, 데이터 분석 및 관찰 가능성입니다. 그는 확장 가능한 분산 시스템을 설계하고 구축하는 데 강력한 배경을 가지고 있습니다. 그는 고객이 AWS에서 비즈니스를 혁신하고 변혁하도록 돕는 일을 즐깁니다. 링크드인: /mdabra
무니시 다브라 Amazon Web Services(AWS)의 선임 솔루션 아키텍트입니다. 그의 현재 초점 영역은 AI/ML, 데이터 분석 및 관찰 가능성입니다. 그는 확장 가능한 분산 시스템을 설계하고 구축하는 데 강력한 배경을 가지고 있습니다. 그는 고객이 AWS에서 비즈니스를 혁신하고 변혁하도록 돕는 일을 즐깁니다. 링크드인: /mdabra
 하산 푸나 왈라 AWS의 수석 AI/ML 전문가 솔루션 아키텍트인 Hasan은 고객이 AWS의 프로덕션 환경에서 기계 학습 애플리케이션을 설계하고 배포할 수 있도록 지원합니다. 그는 데이터 과학자, 기계 학습 실무자 및 소프트웨어 개발자로서 12년 이상의 경력을 가지고 있습니다. 여가 시간에 Hasan은 자연을 탐험하고 친구 및 가족과 함께 시간을 보내는 것을 좋아합니다.
하산 푸나 왈라 AWS의 수석 AI/ML 전문가 솔루션 아키텍트인 Hasan은 고객이 AWS의 프로덕션 환경에서 기계 학습 애플리케이션을 설계하고 배포할 수 있도록 지원합니다. 그는 데이터 과학자, 기계 학습 실무자 및 소프트웨어 개발자로서 12년 이상의 경력을 가지고 있습니다. 여가 시간에 Hasan은 자연을 탐험하고 친구 및 가족과 함께 시간을 보내는 것을 좋아합니다.
 모하마드(모) 타신 AWS의 어소시에이트 AI/ML 전문가 솔루션 아키텍트입니다. Moh는 책임감 있는 AI 개념에 대해 학생들을 가르친 경험이 있으며 클라우드 기반 아키텍처를 통해 이러한 개념을 전달하는 데 열정적입니다. 여가 시간에는 웨이트 트레이닝, 게임, 자연 탐험을 즐깁니다.
모하마드(모) 타신 AWS의 어소시에이트 AI/ML 전문가 솔루션 아키텍트입니다. Moh는 책임감 있는 AI 개념에 대해 학생들을 가르친 경험이 있으며 클라우드 기반 아키텍처를 통해 이러한 개념을 전달하는 데 열정적입니다. 여가 시간에는 웨이트 트레이닝, 게임, 자연 탐험을 즐깁니다.
 마싱첸 AWS의 응용 과학자입니다. 그는 SageMaker 자동 모델 튜닝 서비스 팀에서 일하고 있습니다.
마싱첸 AWS의 응용 과학자입니다. 그는 SageMaker 자동 모델 튜닝 서비스 팀에서 일하고 있습니다.
 라훌 수레카 인도에 본사를 둔 AWS의 엔터프라이즈 솔루션 아키텍트입니다. Rahul은 여러 산업 부문에서 대규모 비즈니스 혁신 프로그램을 설계하고 주도하는 데 22년 이상의 경험을 가지고 있습니다. 관심 분야는 데이터 및 분석, 스트리밍, AI/ML 애플리케이션입니다.
라훌 수레카 인도에 본사를 둔 AWS의 엔터프라이즈 솔루션 아키텍트입니다. Rahul은 여러 산업 부문에서 대규모 비즈니스 혁신 프로그램을 설계하고 주도하는 데 22년 이상의 경험을 가지고 있습니다. 관심 분야는 데이터 및 분석, 스트리밍, AI/ML 애플리케이션입니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/tune-ml-models-for-additional-objectives-like-fairness-with-sagemaker-automatic-model-tuning/

