오늘날 금융 서비스, 의료 및 생명 과학, 여행 및 숙박, 미디어 및 엔터테인먼트, 통신, SaaS(Software as a Service), 독점 모델 제공업체 등 모든 산업 분야의 고객은 대규모 언어 모델(LLM)을 사용하여 다음을 수행하고 있습니다. QnA(질문 응답) 챗봇, 검색 엔진, 지식 베이스와 같은 애플리케이션을 구축하세요. 이것들 생성 적 AI 애플리케이션은 기존 비즈니스 프로세스를 자동화하는 데 사용될 뿐만 아니라 이러한 애플리케이션을 사용하는 고객의 경험을 변화시키는 기능도 갖추고 있습니다. LLM과 같은 발전이 이루어지면서 Mixtral-8x7B 지시, 다음과 같은 아키텍처의 파생물 전문가 혼합(MoE), 고객은 생성 AI 애플리케이션의 성능과 정확성을 향상시키는 동시에 더 넓은 범위의 폐쇄형 및 오픈 소스 모델을 효과적으로 사용할 수 있는 방법을 지속적으로 찾고 있습니다.
LLM 출력의 정확성과 성능을 향상시키기 위해 일반적으로 다음과 같은 미세 조정과 같은 다양한 기술이 사용됩니다. 매개변수 효율적 미세 조정(PEFT), 인간 피드백으로부터 강화 학습(RLHF), 그리고 공연 지식 증류. 그러나 생성적 AI 애플리케이션을 구축할 때 외부 지식의 동적 통합을 허용하고 기존 기본 모델을 세부 조정할 필요 없이 생성에 사용되는 정보를 제어할 수 있는 대체 솔루션을 사용할 수 있습니다. 이것이 바로 우리가 논의한 더 비싸고 강력한 미세 조정 대안이 아닌 생성적 AI 애플리케이션을 위한 검색 증강 생성(RAG)이 등장하는 곳입니다. 일상적인 작업에 복잡한 RAG 애플리케이션을 구현하는 경우 부정확한 검색, 문서의 크기 및 복잡성 증가, 컨텍스트 오버플로 등 RAG 시스템과 관련된 일반적인 문제에 직면할 수 있으며, 이는 생성된 답변의 품질과 신뢰성에 큰 영향을 미칠 수 있습니다. .
이 게시물에서는 개발자가 기존 생성 AI 애플리케이션을 개선할 수 있도록 상황별 압축과 같은 기술 외에도 LangChain 및 상위 문서 검색기와 같은 도구를 사용하여 응답 정확도를 향상시키는 RAG 패턴에 대해 설명합니다.
솔루션 개요
이 게시물에서는 BGE Large En 임베딩 모델과 결합된 Mixtral-8x7B Instruct 텍스트 생성을 사용하여 상위 문서 검색 도구 및 상황별 압축 기술을 사용하여 Amazon SageMaker 노트북에서 RAG QnA 시스템을 효율적으로 구성하는 방법을 보여줍니다. 다음 다이어그램은 이 솔루션의 아키텍처를 보여줍니다.
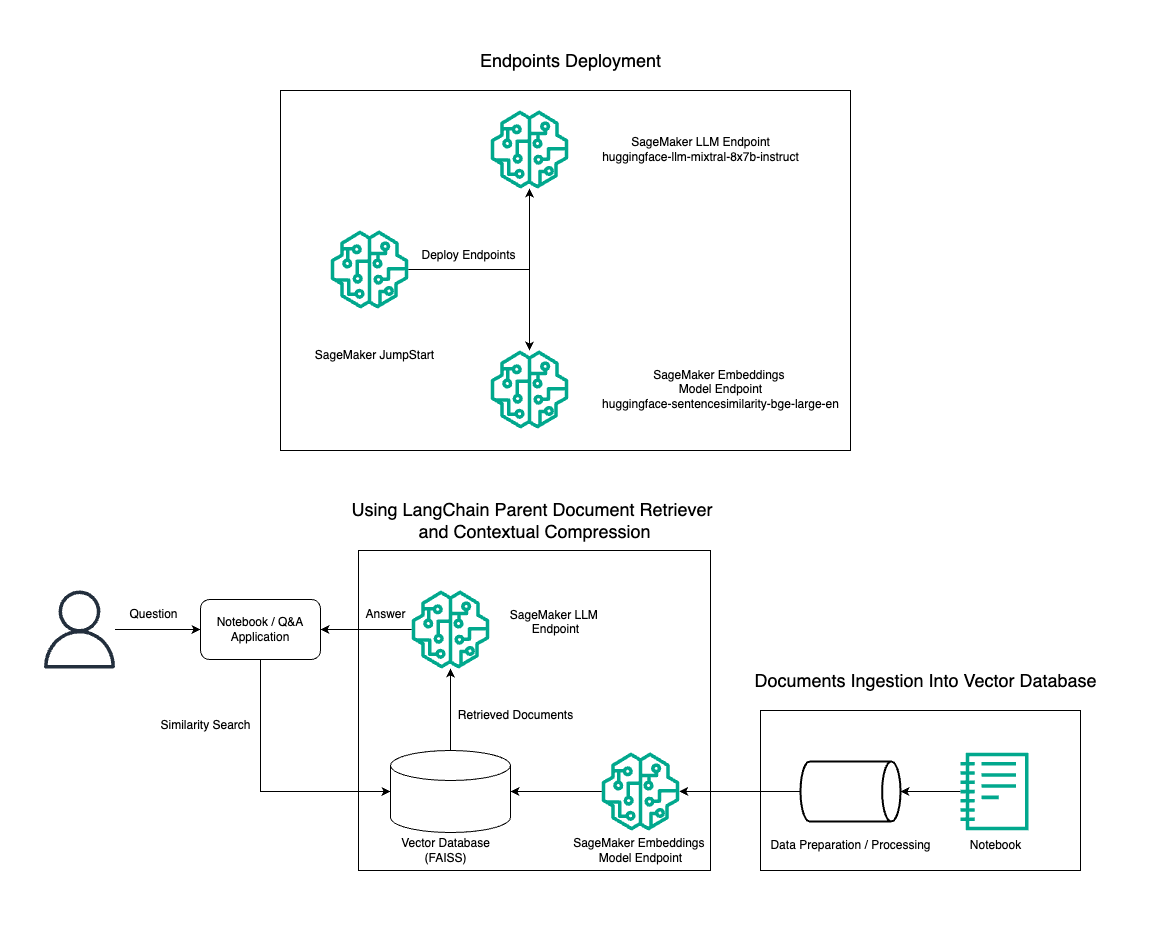
다음을 사용하여 몇 번의 클릭만으로 이 솔루션을 배포할 수 있습니다. Amazon SageMaker 점프스타트는 콘텐츠 작성, 코드 생성, 질문 답변, 카피라이팅, 요약, 분류 및 정보 검색과 같은 다양한 사용 사례에 대한 최첨단 기반 모델을 제공하는 완전 관리형 플랫폼입니다. 빠르고 쉽게 배포할 수 있는 사전 훈련된 모델 컬렉션을 제공하여 기계 학습(ML) 애플리케이션의 개발 및 배포를 가속화합니다. SageMaker JumpStart의 주요 구성 요소 중 하나는 다양한 작업을 위해 Mixtral-8x7B와 같은 사전 훈련된 모델의 방대한 카탈로그를 제공하는 모델 허브입니다.
Mixtral-8x7B는 MoE 아키텍처를 사용합니다. 이 아키텍처를 사용하면 신경망의 여러 부분이 다양한 작업을 전문화하여 여러 전문가 간에 작업 부하를 효과적으로 나눌 수 있습니다. 이 접근 방식을 사용하면 기존 아키텍처에 비해 더 큰 모델을 효율적으로 훈련하고 배포할 수 있습니다.
MoE 아키텍처의 주요 장점 중 하나는 확장성입니다. 여러 전문가에게 워크로드를 분산함으로써 MoE 모델은 더 큰 데이터 세트에서 교육을 받고 동일한 크기의 기존 모델보다 더 나은 성능을 얻을 수 있습니다. 또한 MoE 모델은 특정 입력에 대해 일부 전문가만 활성화하면 되기 때문에 추론 중에 더 효율적일 수 있습니다.
AWS의 Mixtral-8x7B Instruct에 대한 자세한 내용은 다음을 참조하십시오. 이제 Amazon SageMaker JumpStart에서 Mixtral-8x7B를 사용할 수 있습니다.. Mixtral-8x7B 모델은 제한 없이 사용할 수 있도록 허용되는 Apache 2.0 라이센스에 따라 제공됩니다.
이번 포스팅에서는 어떻게 사용할 수 있는지 알아보겠습니다. 랭체인 효과적이고 보다 효율적인 RAG 애플리케이션을 생성합니다. LangChain은 LLM을 사용하여 애플리케이션을 구축하도록 설계된 오픈 소스 Python 라이브러리입니다. LLM을 지식 기반, 검색 시스템 및 기타 AI 도구와 같은 다른 구성 요소와 결합하여 강력하고 사용자 정의 가능한 응용 프로그램을 만들기 위한 유연한 모듈식 프레임워크를 제공합니다.
Mixtral-8x7B를 사용하여 SageMaker에서 RAG 파이프라인을 구성하는 방법을 안내합니다. 우리는 BGE Large En 임베딩 모델과 함께 Mixtral-8x7B Instruct 텍스트 생성 모델을 사용하여 SageMaker 노트북에서 RAG를 사용하는 효율적인 QnA 시스템을 생성합니다. ml.t3.medium 인스턴스를 사용하여 SageMaker에서 생성된 API 엔드포인트를 통해 액세스할 수 있는 SageMaker JumpStart를 통해 LLM을 배포하는 방법을 보여줍니다. 이 설정을 통해 LangChain을 사용하여 고급 RAG 기술을 탐색, 실험 및 최적화할 수 있습니다. 또한 FAISS Embedding 저장소를 RAG 워크플로우에 통합하여 시스템 성능을 향상시키기 위해 임베딩을 저장하고 검색하는 역할을 강조합니다.
SageMaker 노트북에 대해 간략하게 살펴보겠습니다. 더 자세한 단계별 지침은 다음을 참조하세요. SageMaker Jumpstart GitHub 리포지토리에서 Mixtral을 사용한 고급 RAG 패턴.
고급 RAG 패턴의 필요성
고급 RAG 패턴은 인간과 유사한 텍스트를 처리, 이해 및 생성하는 LLM의 현재 기능을 향상시키는 데 필수적입니다. 문서의 크기와 복잡성이 증가함에 따라 단일 임베딩으로 문서의 여러 측면을 표현하면 구체성이 손실될 수 있습니다. 문서의 일반적인 본질을 포착하는 것이 중요하지만, 문서 내의 다양한 하위 컨텍스트를 인식하고 표현하는 것도 마찬가지로 중요합니다. 이는 큰 문서를 작업할 때 자주 직면하게 되는 문제입니다. RAG의 또 다른 과제는 검색 시 문서 저장소 시스템이 수집 시 처리할 특정 쿼리를 인식하지 못한다는 것입니다. 이로 인해 쿼리와 가장 관련성이 높은 정보가 텍스트 아래에 숨겨질 수 있습니다(컨텍스트 오버플로). 실패를 완화하고 기존 RAG 아키텍처를 개선하려면 고급 RAG 패턴(상위 문서 검색기 및 상황별 압축)을 사용하여 검색 오류를 줄이고 답변 품질을 향상하며 복잡한 질문 처리를 활성화할 수 있습니다.
이 게시물에서 설명하는 기술을 사용하면 외부 지식 검색 및 통합과 관련된 주요 과제를 해결하여 애플리케이션이 보다 정확하고 상황에 맞는 응답을 제공할 수 있습니다.
다음 섹션에서는 방법을 알아봅니다. 상위 문서 검색기 과 상황별 압축 우리가 논의한 몇 가지 문제를 해결하는 데 도움이 될 수 있습니다.
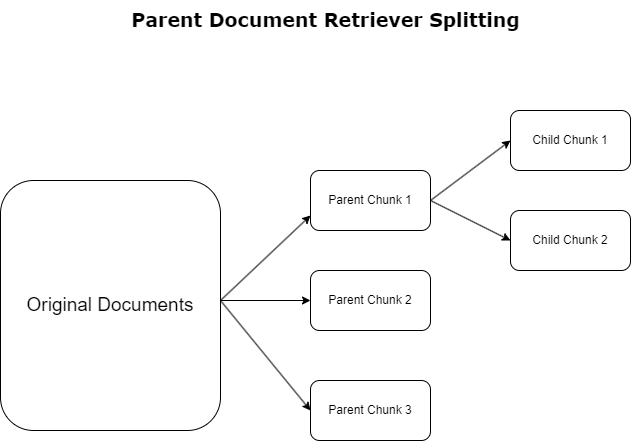
상위 문서 검색기
이전 섹션에서는 RAG 애플리케이션이 광범위한 문서를 처리할 때 직면하게 되는 문제를 강조했습니다. 이러한 과제를 해결하기 위해, 상위 문서 검색기 들어오는 문서를 다음과 같이 분류하고 지정합니다. 상위 문서. 이러한 문서는 포괄적인 성격으로 인식되지만 임베딩을 위해 원래 형식으로 직접 활용되지는 않습니다. 전체 문서를 단일 임베딩으로 압축하는 대신 상위 문서 검색기는 이러한 상위 문서를 하위 문서. 각 하위 문서는 더 넓은 상위 문서의 고유한 측면이나 주제를 포착합니다. 이러한 하위 세그먼트를 식별한 후 개별 임베딩이 각각에 할당되어 특정 주제의 본질을 포착합니다(다음 다이어그램 참조). 검색하는 동안 상위 문서가 호출됩니다. 이 기술은 목표가 명확하면서도 광범위한 검색 기능을 제공하여 LLM에 더 넓은 관점을 제공합니다. 상위 문서 검색기는 LLM에 두 가지 이점을 제공합니다. 즉, 정확하고 관련성 있는 정보 검색을 위한 하위 문서 삽입의 특수성과 응답 생성을 위한 상위 문서 호출이 결합되어 계층화되고 철저한 컨텍스트로 LLM의 출력이 풍부해집니다.
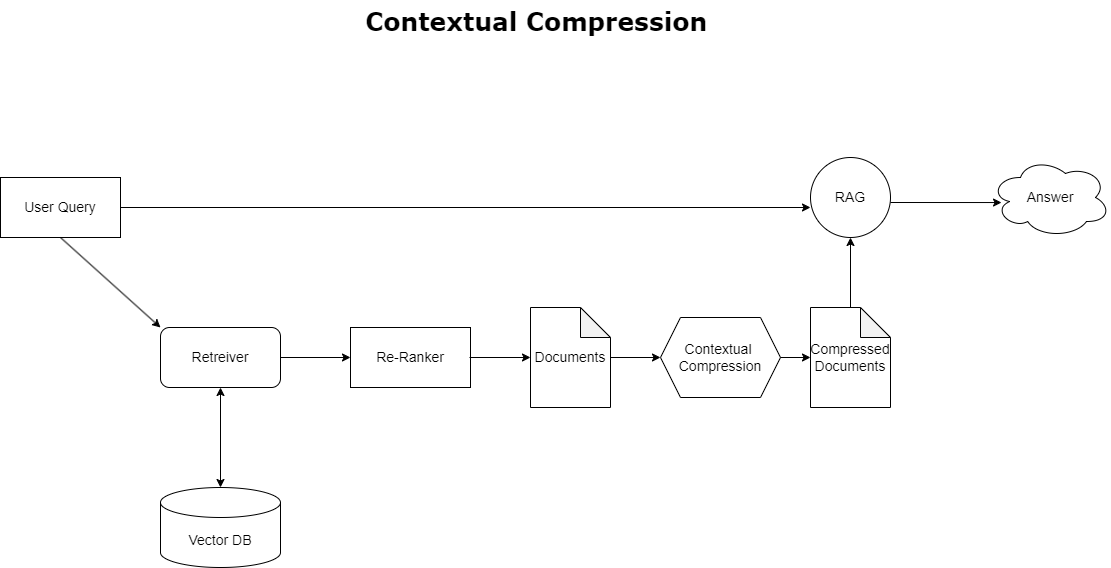
상황별 압축
앞에서 설명한 컨텍스트 오버플로 문제를 해결하려면 다음을 사용할 수 있습니다. 상황별 압축 검색된 문서를 쿼리 컨텍스트에 맞게 압축하고 필터링하여 관련 정보만 유지하고 처리합니다. 이는 다음 다이어그램에 설명된 것처럼 초기 문서 가져오기를 위한 기본 검색기와 관련성을 기반으로 콘텐츠를 완전히 제외하거나 내용을 축소하여 이러한 문서를 정제하기 위한 문서 압축기의 조합을 통해 달성됩니다. 상황별 압축 검색기를 통해 촉진되는 이러한 간소화된 접근 방식은 대량의 정보에서 필수적인 것만 추출하고 활용하는 방법을 제공함으로써 RAG 애플리케이션 효율성을 크게 향상시킵니다. 이는 정보 과부하 및 관련 없는 데이터 처리 문제를 정면으로 해결하여 응답 품질을 향상시키고, 보다 비용 효과적인 LLM 운영 및 보다 원활한 전체 검색 프로세스를 제공합니다. 본질적으로 이는 정보를 현재 쿼리에 맞게 조정하는 필터이므로 더 나은 성능과 사용자 만족을 위해 RAG 애플리케이션을 최적화하려는 개발자에게 꼭 필요한 도구입니다.
사전 조건
SageMaker를 처음 사용하는 경우 다음을 참조하세요. Amazon SageMaker 개발 가이드.
솔루션을 시작하기 전에, AWS 계정 생성. AWS 계정을 생성하면 계정의 모든 AWS 서비스 및 리소스에 대한 완전한 액세스 권한을 갖는 SSO(Single Sign-On) 자격 증명을 얻게 됩니다. 이 ID를 AWS 계정이라고 합니다. 루트 사용자.
로그인 AWS 관리 콘솔 계정을 생성하는 데 사용한 이메일 주소와 암호를 사용하면 계정의 모든 AWS 리소스에 완전히 액세스할 수 있습니다. 일상적인 작업, 심지어 관리 작업에도 루트 사용자를 사용하지 않는 것이 좋습니다.
대신 다음 사항을 준수하세요. 보안 모범 사례 in AWS 자격 증명 및 액세스 관리 (IAM) 및 관리 사용자 및 그룹 생성. 그런 다음 루트 사용자 자격 증명을 안전하게 잠그고 이를 사용하여 몇 가지 계정 및 서비스 관리 작업만 수행합니다.
Mixtral-8x7b 모델에는 ml.g5.48xlarge 인스턴스가 필요합니다. SageMaker JumpStart는 100개 이상의 다양한 오픈 소스 및 타사 기반 모델에 액세스하고 배포하는 단순화된 방법을 제공합니다. 하기 위해 SageMaker JumpStart에서 Mixtral-8x7B를 호스팅하기 위한 엔드포인트 실행, 엔드포인트 사용을 위해 ml.g5.48xlarge 인스턴스에 액세스하려면 서비스 할당량 증가를 요청해야 할 수도 있습니다. 당신은 할 수 있습니다 요청 서비스 할당량 증가 콘솔을 통해, AWS 명령 줄 인터페이스 (AWS CLI) 또는 이러한 추가 리소스에 대한 액세스를 허용하는 API입니다.
SageMaker 노트북 인스턴스 설정 및 종속성 설치
시작하려면 SageMaker 노트북 인스턴스를 생성하고 필요한 종속성을 설치하십시오. 다음을 참조하세요. GitHub 레포 성공적인 설정을 보장합니다. 노트북 인스턴스를 설정한 후 모델을 배포할 수 있습니다.
선호하는 IDE(통합 개발 환경)에서 노트북을 로컬로 실행할 수도 있습니다. Jupyter 노트북 랩이 설치되어 있는지 확인하세요.
모델 배포
SageMaker JumpStart에 Mixtral-8X7B Instruct LLM 모델을 배포합니다.
SageMaker JumpStart에 BGE Large En 임베딩 모델을 배포합니다.
LangChain 설정
필요한 모든 라이브러리를 가져오고 Mixtral-8x7B 모델 및 BGE Large En 임베딩 모델을 배포한 후 이제 LangChain을 설정할 수 있습니다. 단계별 지침은 다음을 참조하세요. GitHub 레포.
데이터 준비
이 게시물에서 우리는 QnA를 수행하기 위한 텍스트 코퍼스로 Amazon의 주주에게 보낸 편지를 몇 년간 사용합니다. 데이터 준비에 대한 자세한 단계는 다음을 참조하세요. GitHub 레포.
질문 답변
데이터가 준비되면 벡터 저장소를 감싸고 LLM에 대한 입력을 받는 LangChain에서 제공하는 래퍼를 사용할 수 있습니다. 이 래퍼는 다음 단계를 수행합니다.
- 입력 질문을 받아보세요.
- 질문 삽입을 만듭니다.
- 관련 문서를 가져옵니다.
- 문서와 질문을 프롬프트에 통합하세요.
- 프롬프트로 모델을 호출하고 읽기 쉬운 방식으로 답변을 생성합니다.
이제 벡터 저장소가 준비되었으므로 질문을 시작할 수 있습니다.
레귤러 리트리버 체인
이전 시나리오에서는 질문에 대한 상황 인식 답변을 얻을 수 있는 빠르고 간단한 방법을 살펴보았습니다. 이제 RetrievalQA의 도움으로 더욱 사용자 정의 가능한 옵션을 살펴보겠습니다. 여기서는 chain_type 매개변수를 사용하여 가져온 문서를 프롬프트에 추가하는 방법을 사용자 정의할 수 있습니다. 또한 검색해야 하는 관련 문서 수를 제어하려면 다음 코드에서 k 매개변수를 변경하여 다양한 출력을 볼 수 있습니다. 많은 시나리오에서 LLM이 답변을 생성하는 데 사용한 소스 문서를 알고 싶을 수 있습니다. 다음을 사용하여 해당 문서를 출력으로 가져올 수 있습니다. return_source_documents, LLM 프롬프트의 컨텍스트에 추가된 문서를 반환합니다. RetrievalQA를 사용하면 모델에 특정한 사용자 정의 프롬프트 템플릿을 제공할 수도 있습니다.
질문을 해보자:
상위 문서 검색기 체인
다음의 도움으로 더욱 발전된 RAG 옵션을 살펴보겠습니다. 상위 문서 검색자. 문서 검색 작업을 할 때 정확한 임베딩을 위해 문서의 작은 덩어리를 저장하는 것과 더 많은 컨텍스트를 보존하기 위해 더 큰 문서를 저장하는 것 사이에서 절충안이 발생할 수 있습니다. 상위 문서 검색기는 작은 데이터 덩어리를 분할하고 저장하여 균형을 유지합니다.
우리는 parent_splitter 원본 문서를 상위 문서라고 하는 더 큰 덩어리로 나누고 child_splitter 원본 문서에서 더 작은 하위 문서를 만들려면:
그런 다음 하위 문서는 임베딩을 사용하여 벡터 저장소에서 인덱싱됩니다. 이를 통해 유사성을 기반으로 관련 하위 문서를 효율적으로 검색할 수 있습니다. 관련 정보를 검색하기 위해 상위 문서 검색기는 먼저 벡터 저장소에서 하위 문서를 가져옵니다. 그런 다음 해당 하위 문서의 상위 ID를 조회하고 해당하는 더 큰 상위 문서를 반환합니다.
질문을 해보자:
상황별 압축 체인
다음과 같은 또 다른 고급 RAG 옵션을 살펴보겠습니다. 상황별 압축. 검색과 관련된 한 가지 과제는 일반적으로 데이터를 시스템에 수집할 때 문서 저장 시스템이 직면하게 될 특정 쿼리를 알지 못한다는 것입니다. 이는 쿼리와 가장 관련성이 높은 정보가 관련 없는 텍스트가 많이 포함된 문서에 묻혀 있을 수 있음을 의미합니다. 신청서를 통해 전체 문서를 전달하면 LLM 통화 비용이 더 많이 들고 응답도 좋지 않을 수 있습니다.
상황별 압축 검색기는 관련 데이터가 많은 텍스트를 포함하는 문서 내에 묻혀 있을 수 있는 문서 저장 시스템에서 관련 정보를 검색하는 문제를 해결합니다. 주어진 쿼리 컨텍스트를 기반으로 검색된 문서를 압축하고 필터링하여 가장 관련성이 높은 정보만 반환합니다.
상황별 압축 검색기를 사용하려면 다음이 필요합니다.
- 베이스 리트리버 – 쿼리를 기반으로 스토리지 시스템에서 문서를 가져오는 초기 검색기입니다.
- 문서 압축기 – 이 구성요소는 처음에 검색된 문서를 가져와 개별 문서의 내용을 줄이거나 관련 없는 문서를 모두 삭제하여 문서를 단축하고, 쿼리 컨텍스트를 사용하여 관련성을 결정합니다.
LLM 체인 추출기로 상황별 압축 추가
먼저 기본 검색기를 다음과 같이 감싸십시오. ContextualCompressionRetriever. 당신은 LLMChain추출기, 처음에 반환된 문서를 반복하고 각 문서에서 쿼리와 관련된 콘텐츠만 추출합니다.
다음을 사용하여 체인을 초기화합니다. ContextualCompressionRetriever 과 LLMChainExtractor 다음을 통해 프롬프트를 전달합니다. chain_type_kwargs 논의.
질문을 해보자:
LLM 체인 필터로 문서 필터링
XNUMXD덴탈의 LLM체인필터 LLM 체인을 사용하여 문서 내용을 조작하지 않고 처음에 검색된 문서 중 필터링할 문서와 반환할 문서를 결정하는 약간 더 간단하지만 더 강력한 압축기입니다.
다음을 사용하여 체인을 초기화합니다. ContextualCompressionRetriever 과 LLMChainFilter 다음을 통해 프롬프트를 전달합니다. chain_type_kwargs 논의.
질문을 해보자:
결과 비교
다음 표에서는 기술에 따라 다양한 쿼리의 결과를 비교합니다.
| 기술 | 쿼리 1 | 쿼리 2 | 비교 |
| AWS는 어떻게 발전했나요? | 아마존은 왜 성공하는가? | ||
| 레귤러 리트리버 체인 출력 | AWS(Amazon Web Services)는 초기에는 수익성이 없었던 투자에서 강력한 수익성을 갖춘 85억 달러 규모의 연간 매출 실행률 비즈니스로 발전하여 다양한 서비스와 기능을 제공하고 Amazon 포트폴리오의 중요한 부분이 되었습니다. 회의론과 단기적인 역풍에도 불구하고 AWS는 지속적으로 혁신하고, 신규 고객을 유치하고, 활성 고객을 마이그레이션하여 민첩성, 혁신, 비용 효율성 및 보안과 같은 이점을 제공했습니다. 또한 AWS는 새로운 기능을 제공하고 고객에게 가능한 변화를 제공하기 위해 칩 개발을 포함한 장기 투자를 확대했습니다. | Amazon은 기술 인프라 서비스, 디지털 독서 장치, 음성 기반 개인 비서 및 타사 시장과 같은 새로운 비즈니스 모델과 같은 새로운 영역으로의 지속적인 혁신과 확장으로 성공했습니다. 주문 처리 및 운송 네트워크의 급속한 확장에서 볼 수 있듯이 신속하게 운영을 확장하는 능력도 성공에 기여합니다. 또한 Amazon은 프로세스 최적화 및 효율성 향상에 중점을 두어 생산성을 향상하고 비용을 절감했습니다. Amazon Business의 사례는 다양한 부문에서 전자상거래 및 물류 강점을 활용하는 회사의 역량을 강조합니다. | 일반 검색기 체인의 응답을 기반으로 긴 답변을 제공하지만 컨텍스트 오버플로로 인해 문제가 발생하고 제공된 쿼리에 대한 응답과 관련하여 코퍼스의 중요한 세부 정보를 언급하지 못한다는 것을 알 수 있습니다. 일반 검색 체인은 깊이나 상황에 맞는 통찰력으로 미묘한 차이를 포착할 수 없으므로 잠재적으로 문서의 중요한 측면이 누락될 수 있습니다. |
| 상위 문서 검색기 출력 | AWS(Amazon Web Services)는 2년에 기능이 부족한 Elastic Compute Cloud(EC2006) 서비스를 처음 출시하면서 시작하여 전 세계 한 지역의 한 데이터 센터에서 Linux 운영 체제 인스턴스만 사용하여 하나의 인스턴스 크기만 제공했습니다. , 모니터링, 로드 밸런싱, 자동 크기 조정 또는 영구 스토리지와 같은 많은 주요 기능이 없습니다. 그러나 AWS의 성공으로 그들은 누락된 기능을 신속하게 반복하고 추가할 수 있었으며, 결국 컴퓨팅, 스토리지 및 네트워킹의 다양한 특징, 크기 및 최적화를 제공하도록 확장했을 뿐만 아니라 자체 칩(Graviton)을 개발하여 가격과 성능을 더욱 높일 수 있었습니다. . AWS의 반복적인 혁신 프로세스에는 고객 요구 사항을 충족하고 장기적인 고객 경험, 충성도 및 주주 수익을 개선하기 위해 20년 이상에 걸쳐 재무 및 인적 자원에 대한 상당한 투자가 필요했으며, 종종 성과를 거두기 훨씬 이전에 이루어졌습니다. | Amazon은 끊임없이 혁신하고, 변화하는 시장 상황에 적응하고, 다양한 시장 부문에서 고객 요구를 충족하는 능력으로 인해 성공을 거두었습니다. 이는 비즈니스 고객에게 선택, 가치 및 편의성을 제공함으로써 연간 총 매출이 약 35억 달러에 달하는 Amazon 비즈니스의 성공에서 분명하게 드러납니다. 전자상거래 및 물류 역량에 대한 Amazon의 투자를 통해 Buy with Prime과 같은 서비스 생성도 가능해졌습니다. 이 서비스는 소비자 직접 웹사이트를 운영하는 판매자가 조회에서 구매로의 전환을 유도하는 데 도움이 됩니다. | 상위 문서 검색기는 고객 피드백을 기반으로 새로운 기능을 추가하는 반복 프로세스와 기능이 부족한 초기 출시부터 지배적인 시장 위치까지의 세부 여정을 포함하여 AWS 성장 전략의 세부 사항을 자세히 조사하는 동시에 풍부한 컨텍스트 응답을 제공합니다. . 응답은 기술 혁신과 시장 전략부터 조직 효율성과 고객 중심에 이르기까지 광범위한 측면을 다루며, 사례와 함께 성공에 기여하는 요소에 대한 전체적인 관점을 제공합니다. 이는 상위 문서 검색기의 타겟이면서도 광범위한 검색 기능 때문일 수 있습니다. |
| LLM 체인 추출기: 상황별 압축 출력 | AWS는 Amazon 내부의 소규모 프로젝트로 시작하여 상당한 자본 투자가 필요하고 회사 내부와 외부 모두에서 회의적인 시각에 직면하면서 발전했습니다. 그러나 AWS는 잠재적인 경쟁사보다 앞서 나갔고 고객과 Amazon에 가져올 수 있는 가치를 믿었습니다. AWS는 지속적인 투자를 위해 장기적인 노력을 기울여 3,300년에 2022개 이상의 새로운 기능과 서비스를 출시했습니다. AWS는 고객이 기술 인프라를 관리하는 방식을 변화시켰으며 강력한 수익성을 갖춘 연간 85억 달러 규모의 매출 실행률 기업이 되었습니다. AWS는 또한 초기 출시 이후 추가 기능과 서비스로 EC2를 강화하는 등 지속적으로 제품을 개선해 왔습니다. | 제공된 맥락에 따르면, Amazon의 성공은 도서 판매 플랫폼에서 활발한 제2019자 판매자 생태계를 갖춘 글로벌 시장으로의 전략적 확장, AWS에 대한 조기 투자, Kindle 및 Alexa 도입의 혁신, 실질적인 성장에 기인합니다. 이러한 성장으로 인해 주문 처리 센터 공간이 확장되고, 라스트 마일 운송 네트워크가 구축되었으며, 생산성과 비용 절감에 최적화된 새로운 분류 센터 네트워크가 구축되었습니다. | LLM 체인 추출기는 핵심 사항을 포괄적으로 다루는 것과 불필요한 깊이를 피하는 것 사이의 균형을 유지합니다. 이는 쿼리의 컨텍스트에 맞게 동적으로 조정되므로 출력은 직접적으로 관련성이 있고 포괄적입니다. |
| LLM 체인 필터: 상황별 압축 출력 | AWS(Amazon Web Services)는 처음에는 기능이 부족했지만 고객 피드백을 기반으로 빠르게 반복하여 필요한 기능을 추가함으로써 발전했습니다. 이러한 접근 방식을 통해 AWS는 2년에 제한된 기능으로 EC2006를 출시한 후 추가 인스턴스 크기, 데이터 센터, 지역, 운영 체제 옵션, 모니터링 도구, 로드 밸런싱, 자동 크기 조정 및 영구 스토리지와 같은 새로운 기능을 지속적으로 추가할 수 있었습니다. 시간이 지나면서 AWS는 고객 요구 사항, 민첩성, 혁신, 비용 효율성 및 보안에 중점을 두어 기능이 부족한 서비스에서 수십억 달러 규모의 비즈니스로 변모했습니다. AWS는 현재 연간 85억 달러의 수익을 올리고 있으며 매년 3,300개 이상의 새로운 기능과 서비스를 제공하여 스타트업부터 다국적 기업, 공공 부문 조직에 이르기까지 다양한 고객에게 서비스를 제공하고 있습니다. | Amazon은 혁신적인 비즈니스 모델, 지속적인 기술 발전, 전략적 조직 변화로 인해 성공을 거두었습니다. 이 회사는 다양한 제품과 서비스를 위한 전자상거래 플랫폼, 제3자 마켓플레이스, 클라우드 인프라 서비스(AWS), Kindle e-reader, Alexa 음성 기반 개인 비서 등 새로운 아이디어를 도입하여 기존 산업을 지속적으로 혁신해 왔습니다. . 또한 Amazon은 비용과 배송 시간을 줄이기 위해 미국 주문 처리 네트워크를 재구성하는 등 효율성을 높이기 위해 구조적 변화를 이루어 성공에 더욱 기여했습니다. | LLM 체인 추출기와 유사하게 LLM 체인 필터는 핵심 사항을 다루더라도 간결하고 상황에 맞는 답변을 찾는 고객에게 효율적인 결과를 제공합니다. |
이러한 다양한 기술을 비교하면 AWS가 단순한 서비스에서 복잡한 수십억 달러 규모의 개체로 전환하는 과정을 자세히 설명하거나 Amazon의 전략적 성공을 설명하는 것과 같은 맥락에서 일반 검색 체인은 더 정교한 기술이 제공하는 정밀도가 부족하다는 것을 알 수 있습니다. 덜 타겟화된 정보로 이어집니다. 논의된 고급 기술 간에는 눈에 띄는 차이점이 거의 없지만 일반 리트리버 체인보다 훨씬 더 많은 정보를 제공합니다.
애플리케이션에 RAG를 구현하려는 의료, 통신 및 금융 서비스와 같은 업계 고객의 경우 일반 검색 체인의 정밀도 제공, 중복 방지 및 효과적인 정보 압축의 한계로 인해 이러한 요구 사항을 충족하는 데 적합하지 않습니다. 보다 발전된 상위 문서 검색기 및 상황별 압축 기술을 사용합니다. 이러한 기술은 방대한 양의 정보를 정제하여 필요한 집중적이고 영향력 있는 통찰력을 제공하는 동시에 가격 대비 성능을 향상시키는 데 도움을 줍니다.
정리
노트북 실행이 완료되면 사용 중인 리소스에 대한 요금이 발생하지 않도록 생성한 리소스를 삭제하세요.
결론
이 게시물에서는 정보를 처리하고 생성하는 LLM의 기능을 향상시키기 위해 상위 문서 검색기 및 상황별 압축 체인 기술을 구현할 수 있는 솔루션을 제시했습니다. 우리는 SageMaker JumpStart에서 사용할 수 있는 Mixtral-8x7B Instruct 및 BGE Large En 모델을 사용하여 이러한 고급 RAG 기술을 테스트했습니다. 또한 임베딩 및 문서 청크를 위한 영구 스토리지 사용과 엔터프라이즈 데이터 저장소와의 통합을 살펴보았습니다.
우리가 수행한 기술은 LLM 모델이 외부 지식에 액세스하고 통합하는 방식을 개선할 뿐만 아니라 결과의 품질, 관련성 및 효율성을 크게 향상시킵니다. 이러한 고급 RAG 기술을 통해 대규모 텍스트 말뭉치 검색을 언어 생성 기능과 결합함으로써 LLM은 보다 사실적이고 일관되며 상황에 적합한 응답을 생성하여 다양한 자연어 처리 작업 전반에 걸쳐 성능을 향상시킬 수 있습니다.
SageMaker JumpStart는 이 솔루션의 중심에 있습니다. SageMaker JumpStart를 사용하면 광범위한 오픈 소스 및 비공개 소스 모델에 액세스하여 ML 시작 프로세스를 간소화하고 신속한 실험 및 배포가 가능합니다. 이 솔루션 배포를 시작하려면 GitHub 레포.
저자에 관하여
 니티인 비제아스와란 AWS의 솔루션스 아키텍트입니다. 그의 관심 분야는 생성 AI와 AWS AI Accelerator입니다. 그는 컴퓨터 과학 및 생물정보학 학사 학위를 보유하고 있습니다. Niithiyn은 Generative AI GTM 팀과 긴밀히 협력하여 AWS 고객이 다양한 측면에서 지원하고 생성 AI 채택을 가속화합니다. 그는 Dallas Mavericks의 열렬한 팬이며 운동화 수집을 즐깁니다.
니티인 비제아스와란 AWS의 솔루션스 아키텍트입니다. 그의 관심 분야는 생성 AI와 AWS AI Accelerator입니다. 그는 컴퓨터 과학 및 생물정보학 학사 학위를 보유하고 있습니다. Niithiyn은 Generative AI GTM 팀과 긴밀히 협력하여 AWS 고객이 다양한 측면에서 지원하고 생성 AI 채택을 가속화합니다. 그는 Dallas Mavericks의 열렬한 팬이며 운동화 수집을 즐깁니다.
 세바스티안 부스티요 AWS의 솔루션스 아키텍트입니다. 그는 생성 AI 및 컴퓨팅 가속기에 대한 깊은 열정으로 AI/ML 기술에 중점을 두고 있습니다. AWS에서 그는 고객이 생성 AI를 통해 비즈니스 가치를 실현하도록 돕습니다. 일하지 않을 때에는 완벽한 스페셜티 커피 한 잔을 끓여 아내와 함께 세계를 탐험하는 것을 즐깁니다.
세바스티안 부스티요 AWS의 솔루션스 아키텍트입니다. 그는 생성 AI 및 컴퓨팅 가속기에 대한 깊은 열정으로 AI/ML 기술에 중점을 두고 있습니다. AWS에서 그는 고객이 생성 AI를 통해 비즈니스 가치를 실현하도록 돕습니다. 일하지 않을 때에는 완벽한 스페셜티 커피 한 잔을 끓여 아내와 함께 세계를 탐험하는 것을 즐깁니다.
 아르만도 디아즈 AWS의 솔루션스 아키텍트입니다. 그는 생성적 AI, AI/ML 및 데이터 분석에 중점을 두고 있습니다. AWS에서 Armando는 고객이 최첨단 생성 AI 기능을 시스템에 통합하여 혁신과 경쟁 우위를 강화할 수 있도록 지원합니다. 일하지 않을 때는 아내, 가족과 함께 시간을 보내고, 하이킹을 즐기고, 세계 여행을 즐깁니다.
아르만도 디아즈 AWS의 솔루션스 아키텍트입니다. 그는 생성적 AI, AI/ML 및 데이터 분석에 중점을 두고 있습니다. AWS에서 Armando는 고객이 최첨단 생성 AI 기능을 시스템에 통합하여 혁신과 경쟁 우위를 강화할 수 있도록 지원합니다. 일하지 않을 때는 아내, 가족과 함께 시간을 보내고, 하이킹을 즐기고, 세계 여행을 즐깁니다.
 파루크 사비르 박사 AWS의 수석 인공 지능 및 기계 학습 전문가 솔루션 설계자입니다. 그는 오스틴에 있는 텍사스 대학교에서 전기 공학 박사 및 석사 학위를, 조지아 공과 대학에서 컴퓨터 공학 석사 학위를 받았습니다. 그는 15년 이상의 경력을 가지고 있으며 대학생들을 가르치고 멘토링하는 것을 좋아합니다. AWS에서 그는 고객이 데이터 과학, 기계 학습, 컴퓨터 비전, 인공 지능, 수치 최적화 및 관련 도메인에서 비즈니스 문제를 공식화하고 해결하도록 돕습니다. 텍사스주 댈러스에 거주하는 그와 그의 가족은 여행과 장거리 자동차 여행을 좋아합니다.
파루크 사비르 박사 AWS의 수석 인공 지능 및 기계 학습 전문가 솔루션 설계자입니다. 그는 오스틴에 있는 텍사스 대학교에서 전기 공학 박사 및 석사 학위를, 조지아 공과 대학에서 컴퓨터 공학 석사 학위를 받았습니다. 그는 15년 이상의 경력을 가지고 있으며 대학생들을 가르치고 멘토링하는 것을 좋아합니다. AWS에서 그는 고객이 데이터 과학, 기계 학습, 컴퓨터 비전, 인공 지능, 수치 최적화 및 관련 도메인에서 비즈니스 문제를 공식화하고 해결하도록 돕습니다. 텍사스주 댈러스에 거주하는 그와 그의 가족은 여행과 장거리 자동차 여행을 좋아합니다.
 마르코 푸니오 생성적 AI 전략, 응용 AI 솔루션에 중점을 두고 고객이 AWS에서 하이퍼스케일할 수 있도록 연구를 수행하는 솔루션 아키텍트입니다. Marco는 핀테크, 의료 및 생명과학, 서비스형 소프트웨어(Software-as-a-Service), 가장 최근에는 통신 산업 분야에서 경험을 쌓은 디지털 네이티브 클라우드 자문가입니다. 그는 기계 학습, 인공 지능, 인수 합병에 대한 열정을 지닌 자격을 갖춘 기술자입니다. Marco는 워싱턴 주 시애틀에 거주하며 여가 시간에 글쓰기, 읽기, 운동 및 애플리케이션 구축을 즐깁니다.
마르코 푸니오 생성적 AI 전략, 응용 AI 솔루션에 중점을 두고 고객이 AWS에서 하이퍼스케일할 수 있도록 연구를 수행하는 솔루션 아키텍트입니다. Marco는 핀테크, 의료 및 생명과학, 서비스형 소프트웨어(Software-as-a-Service), 가장 최근에는 통신 산업 분야에서 경험을 쌓은 디지털 네이티브 클라우드 자문가입니다. 그는 기계 학습, 인공 지능, 인수 합병에 대한 열정을 지닌 자격을 갖춘 기술자입니다. Marco는 워싱턴 주 시애틀에 거주하며 여가 시간에 글쓰기, 읽기, 운동 및 애플리케이션 구축을 즐깁니다.
 AJ 디미네 AWS의 솔루션스 아키텍트입니다. 그는 생성적 AI, 서버리스 컴퓨팅 및 데이터 분석을 전문으로 합니다. 그는 기계 학습 기술 분야 커뮤니티의 활발한 회원/멘토이며 다양한 AI/ML 주제에 대한 여러 과학 논문을 발표했습니다. 그는 스타트업부터 기업까지 다양한 고객과 협력하여 AWSome 생성 AI 솔루션을 개발합니다. 그는 고급 데이터 분석을 위해 대규모 언어 모델을 활용하고 실제 문제를 해결하는 실용적인 응용 프로그램을 탐색하는 데 특히 열정적입니다. 업무 외적으로는 여행을 좋아하는 AJ는 현재 전 세계 모든 나라를 방문하는 것을 목표로 53개국에 거주하고 있다.
AJ 디미네 AWS의 솔루션스 아키텍트입니다. 그는 생성적 AI, 서버리스 컴퓨팅 및 데이터 분석을 전문으로 합니다. 그는 기계 학습 기술 분야 커뮤니티의 활발한 회원/멘토이며 다양한 AI/ML 주제에 대한 여러 과학 논문을 발표했습니다. 그는 스타트업부터 기업까지 다양한 고객과 협력하여 AWSome 생성 AI 솔루션을 개발합니다. 그는 고급 데이터 분석을 위해 대규모 언어 모델을 활용하고 실제 문제를 해결하는 실용적인 응용 프로그램을 탐색하는 데 특히 열정적입니다. 업무 외적으로는 여행을 좋아하는 AJ는 현재 전 세계 모든 나라를 방문하는 것을 목표로 53개국에 거주하고 있다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

