KT Corporation 유선전화, 이동통신, 인터넷 등 다양한 서비스와 AI 서비스를 제공하는 대한민국 최대 통신사 중 하나입니다. KT의 AI 푸드태그는 컴퓨터 비전 모델을 활용해 사진 속 음식의 종류와 영양성분 함량을 식별하는 AI 기반 식단관리 솔루션이다. KT가 개발한 비전 모델은 라벨이 지정되지 않은 대량의 이미지 데이터로 사전 학습된 모델을 기반으로 다양한 식품의 영양성분과 칼로리 정보를 분석합니다. AI 푸드태그는 당뇨병 등 만성질환 환자의 식단 관리에 도움을 줄 수 있다. KT는 AWS를 사용했고 아마존 세이지 메이커 이 AI Food Tag 모델을 이전보다 29배 빠르게 훈련하고 모델 증류 기술을 사용하여 생산 배포에 맞게 최적화합니다. 이번 게시물에서는 SageMaker를 사용한 KT의 모델 개발 여정과 성공 사례를 설명합니다.
KT 프로젝트 소개 및 문제점 정의
KT가 사전 학습한 AI 푸드 태그 모델은 ViT(Vision Transformers) 아키텍처를 기반으로 하며, 기존 비전 모델보다 모델 매개변수를 늘려 정확도를 높였습니다. KT는 생산을 위한 모델 크기를 축소하기 위해 지식 증류(KD) 기술을 사용하여 정확도에 큰 영향을 주지 않으면서 모델 매개변수 수를 줄이고 있습니다. 지식 증류를 통해 사전 훈련된 모델을 교사 모델, 경량 출력 모델은 다음과 같이 학습됩니다. 학생 모델, 다음 그림과 같습니다. 경량 학생 모델은 교사보다 모델 매개변수가 적기 때문에 메모리 요구 사항이 줄어들고 더 작고 저렴한 인스턴스에 배포할 수 있습니다. 학생은 교사 모델의 출력을 통해 학습함으로써 정확도가 더 작더라도 허용 가능한 정확도를 유지합니다.

Teacher 모델은 KD 동안 변경되지 않지만 Student 모델은 손실을 계산하기 위한 레이블로 Teacher 모델의 출력 로짓을 사용하여 학습됩니다. 이 KD 패러다임을 사용하면 교사와 학생 모두 훈련을 위해 단일 GPU 메모리에 있어야 합니다. KT는 처음에 내부 온프레미스 환경에서 100개의 GPU(A80 40GB)를 사용하여 학생 모델을 훈련했지만, 300 에포크를 포괄하는 데 약 XNUMX일이 걸렸습니다. 훈련을 가속화하고 더 짧은 시간에 학생 모델을 생성하기 위해 KT는 AWS와 파트너십을 맺었습니다. 두 팀은 함께 모델 훈련 시간을 크게 단축했습니다. 이 게시물에서는 팀이 어떻게 사용했는지 설명합니다. Amazon SageMaker 교육Walk Through California 프로그램, SageMaker 데이터 병렬 처리 라이브러리, Amazon SageMaker 디버거및 Amazon SageMaker 프로파일러 경량 AI 푸드 태그 모델 개발에 성공했습니다.
SageMaker를 사용하여 분산 교육 환경 구축
SageMaker 교육은 다음 다이어그램에 설명된 것처럼 교육 경험을 단순화하고 분산 컴퓨팅에 유용할 수 있는 기능과 도구 모음을 제공하는 AWS의 관리형 기계 학습(ML) 교육 환경입니다.
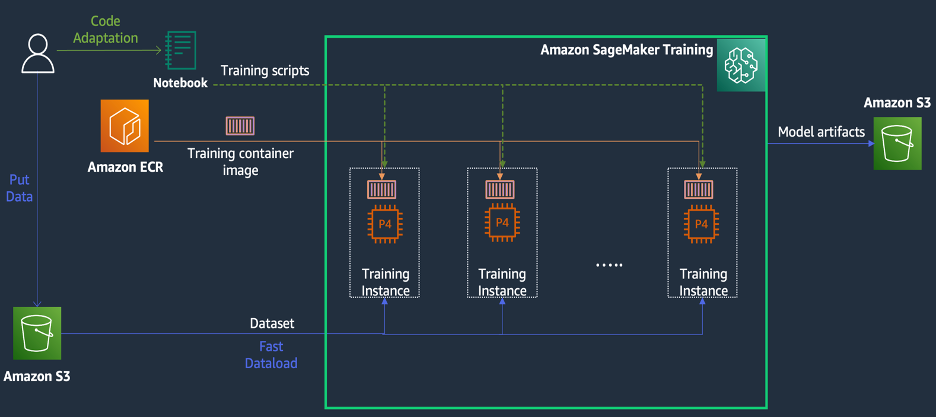
SageMaker 고객은 사전 설치된 다양한 딥 러닝 프레임워크와 모델 교육에 필요한 Linux, NCCL 및 Python 패키지가 포함된 내장 Docker 이미지에 액세스할 수도 있습니다. 모델 교육을 실행하려는 데이터 과학자 또는 ML 엔지니어는 교육 인프라를 구성하거나 Docker 및 다양한 라이브러리의 호환성을 관리하는 부담 없이 이를 수행할 수 있습니다.
1일 워크숍 동안 우리는 KT의 AWS 계정 내에서 SageMaker를 기반으로 분산 교육 구성을 설정하고, SageMaker DDP(분산 데이터 병렬) 라이브러리를 사용하여 KT의 교육 스크립트를 가속화하고, 4ml를 사용하여 교육 작업을 테스트할 수도 있었습니다. p24d.XNUMXxlarge 인스턴스. 이 섹션에서는 AWS 팀과 협력하고 SageMaker를 사용하여 모델을 개발한 KT의 경험을 설명합니다.
개념 증명에서 우리는 분산 교육 중 AWS 인프라에 최적화된 SageMaker DDP 라이브러리를 사용하여 교육 작업 속도를 높이고 싶었습니다. PyTorch DDP에서 SageMaker DDP로 변경하려면 간단히 다음을 선언하면 됩니다. torch_smddp 패키지화하고 백엔드를 다음으로 변경합니다. smddp, 다음 코드와 같이
SageMaker DDP 라이브러리에 대해 자세히 알아보려면 다음을 참조하십시오. SageMaker의 데이터 병렬성 라이브러리.
SageMaker 디버거 및 프로파일러를 사용하여 훈련 속도가 느린 원인 분석
훈련 워크로드를 최적화하고 가속화하는 첫 번째 단계는 병목 현상이 발생하는 위치를 이해하고 진단하는 것입니다. KT의 학습 작업에 대해 데이터 로더, 정방향 전달 및 역방향 전달의 반복당 학습 시간을 측정했습니다.
| 1 반복 시간 – 데이터로더: 0.00053초, 앞으로: 7.77474초, 뒤로: 1.58002 초 |
| 2 반복 시간 – 데이터로더: 0.00063초, 앞으로: 0.67429초, 뒤로: 24.74539 초 |
| 3 반복 시간 – 데이터로더: 0.00061초, 앞으로: 0.90976초, 뒤로: 8.31253 초 |
| 4 반복 시간 – 데이터로더: 0.00060초, 앞으로: 0.60958초, 뒤로: 30.93830 초 |
| 5 반복 시간 – 데이터로더: 0.00080초, 앞으로: 0.83237초, 뒤로: 8.41030 초 |
| 6 반복 시간 – 데이터로더: 0.00067초, 앞으로: 0.75715초, 뒤로: 29.88415 초 |
각 반복에 대한 표준 출력의 시간을 살펴보면 역방향 전달의 실행 시간이 반복마다 크게 변동하는 것을 볼 수 있습니다. 이러한 변화는 일반적이지 않으며 총 훈련 시간에 영향을 미칠 수 있습니다. 이러한 일관되지 않은 훈련 속도의 원인을 찾기 위해 먼저 시스템 모니터(SageMaker Debugger UI)를 활용하여 리소스 병목 현상을 식별하려고 했습니다. 이를 통해 SageMaker Training에서 훈련 작업을 디버깅하고 관리형 훈련 플랫폼과 같은 리소스 상태를 볼 수 있습니다. 설정된 시간(초) 내에 CPU, GPU, 네트워크 및 I/O를 수행합니다.
SageMaker 디버거 UI는 훈련 작업에서 병목 현상을 식별하고 진단하는 데 도움이 될 수 있는 상세하고 필수적인 데이터를 제공합니다. 특히 CPU 활용도 꺾은선형 차트와 인스턴스별 CPU/GPU 활용 히트맵 테이블이 눈길을 끌었습니다.
CPU 사용률 선 차트에서 일부 CPU가 100% 사용되고 있음을 확인했습니다.
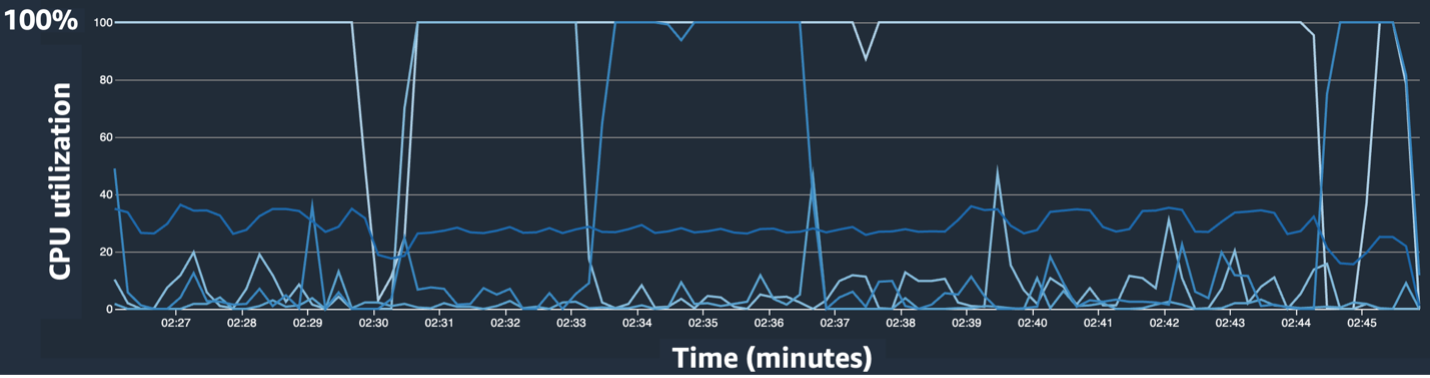
히트 맵(어두운 색상이 더 높은 활용도를 나타냄)에서 우리는 몇몇 CPU 코어가 훈련 전반에 걸쳐 높은 활용도를 보인 반면, GPU 활용도는 시간이 지남에 따라 일관되게 높지 않다는 점을 확인했습니다.

여기서부터 우리는 훈련 속도가 느린 이유 중 하나가 CPU 병목 현상일 것이라고 의심하기 시작했습니다. 우리는 훈련 스크립트 코드를 검토하여 CPU 병목 현상을 일으키는 원인이 있는지 확인했습니다. 가장 의심스러운 부분은 금액이 너무 크다는 것이었습니다. num_workers 데이터 로더에서는 CPU 사용률을 줄이기 위해 이 값을 0 또는 1로 변경했습니다. 그런 다음 훈련 작업을 다시 실행하고 결과를 확인했습니다.
다음 스크린샷은 CPU 병목 현상을 완화한 후의 CPU 사용률 선 차트, GPU 사용률 및 히트맵을 보여줍니다.
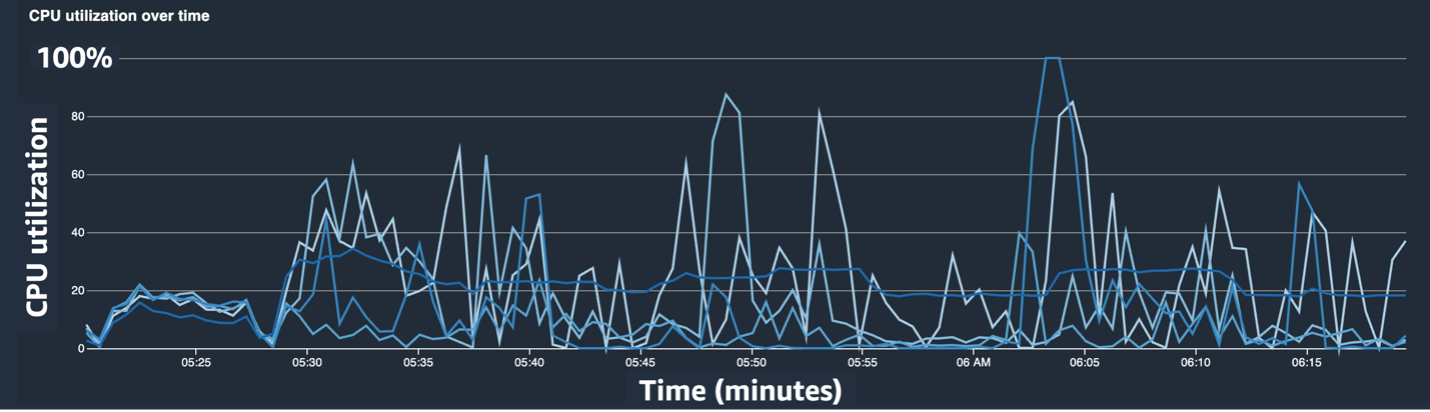


간단히 변경하여 num_workers, CPU 사용률이 크게 감소하고 GPU 사용률이 전반적으로 증가하는 것을 확인했습니다. 이는 훈련 속도를 크게 향상시키는 중요한 변화였습니다. 그럼에도 불구하고 우리는 GPU 활용도를 최적화할 수 있는 부분을 확인하고 싶었습니다. 이를 위해 SageMaker Profiler를 사용했습니다.
SageMaker 프로파일러는 훈련 스크립트 내에서 GPU 및 CPU 사용률 지표와 GPU/CPU의 커널 소비를 추적하는 등 작업별 사용률에 대한 가시성을 제공하여 최적화 단서를 식별하는 데 도움이 됩니다. 이는 사용자가 어떤 작업이 리소스를 소비하는지 이해하는 데 도움이 됩니다. 먼저 SageMaker 프로파일러를 사용하려면 다음을 추가해야 합니다. ProfilerConfig 다음 코드에 표시된 대로 SageMaker SDK를 사용하여 훈련 작업을 호출하는 함수에:
SageMaker Python SDK에서는 다음을 유연하게 추가할 수 있습니다. annotate SageMaker Profiler가 프로파일링이 필요한 교육 스크립트의 코드 또는 단계를 선택하는 기능입니다. 다음은 교육 스크립트에서 SageMaker Profiler에 대해 선언해야 하는 코드의 예입니다.
이전 코드를 추가한 후 훈련 스크립트를 사용하여 훈련 작업을 실행하면 일정 기간 동안 훈련이 실행된 후 GPU 커널에서 소비하는 작업에 대한 정보를 얻을 수 있습니다(다음 그림 참조). KT의 학습 스크립트의 경우 한 에포크 동안 실행해본 결과 다음과 같은 결과를 얻었습니다.
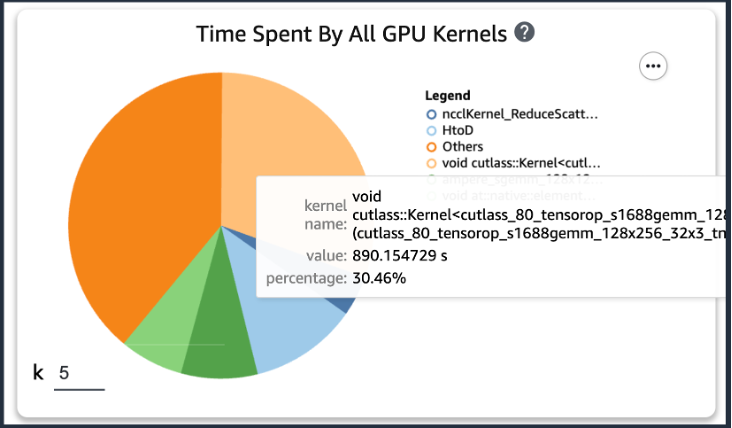
SageMaker Profiler 결과 중 GPU 커널의 연산 소비 시간 상위 XNUMX개를 확인한 결과, KT 훈련 스크립트의 경우 일반 행렬 곱셈(GEMM) 연산인 행렬 곱 연산에 가장 많은 시간이 소모되는 것으로 나타났습니다. GPU에서. SageMaker 프로파일러의 중요한 통찰력을 바탕으로 우리는 이러한 작업을 가속화하고 GPU 활용률을 향상시키는 방법을 조사하기 시작했습니다.
훈련 시간 단축
행렬 곱셈의 계산 시간을 줄이기 위한 다양한 방법을 검토하고 두 가지 PyTorch 함수를 적용했습니다.
ZeroRedundancyOptimizer를 사용한 샤드 최적화 상태
당신이 제로 중복 최적화 프로그램(ZeRO), DeepSpeed/ZeRO 기술은 모델에서 사용되는 메모리의 중복을 제거하여 더 나은 훈련 속도로 대규모 모델을 효율적으로 훈련할 수 있게 해줍니다. ZeroRedundancyOptimizer PyTorch에서는 DDP(Distributed Data Parallel)에서 프로세스당 메모리 사용량을 줄이기 위해 최적화 상태를 샤딩하는 기술을 사용합니다. DDP는 역방향 패스에서 동기화된 기울기를 사용하므로 모든 최적화 프로그램 복제본이 동일한 매개변수 및 기울기 값을 반복하지만 모든 모델 매개변수를 갖는 대신 각 최적화 프로그램 상태는 메모리 사용량을 줄이기 위해 서로 다른 DDP 프로세스에 대해서만 샤딩을 통해 유지됩니다.
이를 사용하려면 기존 최적화 도구를 그대로 두십시오. optimizer_class 그리고 선언하다 ZeroRedundancyOptimizer 나머지 모델 매개변수와 학습률을 매개변수로 사용합니다.
자동 혼합 정밀도
자동 혼합 정밀도(AMP) 일부 작업에는 torch.float32 데이터 유형을 사용합니다. 토치.bfloat16 또는 빠른 계산의 편의와 메모리 사용량 감소를 위해 torch.float16을 사용합니다. 특히 딥 러닝 모델은 일반적으로 계산 시 분수 비트보다 지수 비트에 더 민감하기 때문에 torch.bfloat16은 torch.float32의 지수 비트와 동일하므로 손실을 최소화하면서 빠르게 학습할 수 있습니다. torch.bfloat16은 ml.p100d.4xlarge, ml.p24de.4xlarge 및 ml.p24xlarge와 같은 A5.48 NVIDIA 아키텍처(암페어) 이상의 인스턴스에서만 실행됩니다.
AMP를 적용하려면 다음을 선언하세요. torch.cuda.amp.autocast 위 코드에 표시된 대로 학습 스크립트에서 선언하고 dtype torch.bfloat16으로.
SageMaker 프로파일러의 결과
훈련 스크립트에 두 함수를 적용하고 한 에포크 동안 훈련 작업을 다시 실행한 후 SageMaker Profiler에서 GPU 커널에 대한 상위 XNUMX개 작업 소비 시간을 확인했습니다. 다음 그림은 결과를 보여줍니다.
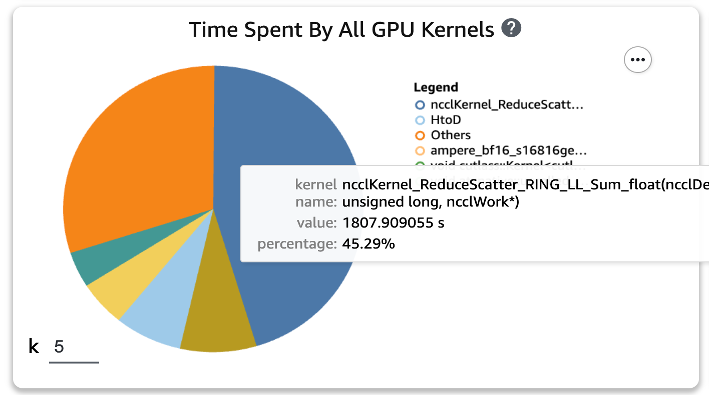
두 개의 Torch 함수를 적용하기 전에 목록의 최상위에 있던 GEMM 작업이 상위 XNUMX개 작업에서 사라지고 일반적으로 분산 교육에서 발생하는 ReduceScatter 작업으로 대체된 것을 확인할 수 있습니다.
KT 증류 모델의 훈련 속도 결과
두 개의 Torch 기능을 적용하여 메모리 절약을 설명하기 위해 훈련 배치 크기를 128개 더 늘렸고, 그 결과 최종 배치 크기는 1152가 아닌 1024가 되었습니다. 최종 학생 모델의 훈련은 하루에 210에포크를 실행할 수 있었습니다. ; KT 내부 훈련 환경과 SageMaker 간의 훈련 시간과 속도 향상은 다음 표에 요약되어 있습니다.
| 교육 환경 | 트레이닝 GPU 사양 | GPU 수 | 교육 시간(시간) | 시대 | 에포크당 시간 | 감속비 |
| KT 내부 교육 환경 | A100(80GB) | 2 | 960 | 300 | 3.20 | 29 |
| 아마존 세이지 메이커 | A100(40GB) | 32 | 24 | 210 | 0.11 | 1 |
AWS의 확장성 덕분에 온프레미스에서 29개가 아닌 32개의 GPU를 사용하여 이전보다 2배 빠르게 훈련 작업을 완료할 수 있었습니다. 결과적으로 SageMaker에서 더 많은 GPU를 사용하면 전체 훈련 비용의 차이 없이 훈련 시간이 크게 줄어들 것입니다.
결론
KT 융합기술센터 AI2XL Lab 박상민(비전AI 서빙기술팀장)은 AI 푸드태그 모델 개발을 위한 AWS와의 협력에 대해 다음과 같이 말했다.
“최근 비전 분야에 트랜스포머 기반 모델이 많아지면서 모델 파라미터와 필요한 GPU 메모리도 늘어나고 있습니다. 우리는 이 문제를 해결하기 위해 경량화 기술을 사용하고 있는데, 한 번 익히는데 한 달 정도 걸릴 정도로 많은 시간이 걸린다. AWS와의 이번 PoC를 통해 SageMaker Profiler와 Debugger의 도움으로 리소스 병목 현상을 식별하고 해결한 후 SageMaker의 데이터 병렬 처리 라이브러리를 사용하여 4개의 ml.p24d에 최적화된 모델 코드로 약 하루 만에 훈련을 완료할 수 있었습니다. XNUMXxlarge 인스턴스.”
SageMaker는 상민 팀의 모델 훈련 및 개발 시간을 몇 주 단축하는 데 도움이 되었습니다.
이번 비전 모델 협업을 바탕으로 AWS와 SageMaker 팀은 KT와 다양한 AI/ML 연구 프로젝트에 지속적으로 협력해 SageMaker 기능을 적용해 모델 개발 및 서비스 생산성을 향상시킬 예정이다.
SageMaker의 관련 기능에 대해 자세히 알아보려면 다음을 확인하십시오.
저자 소개
 최영준AI/ML Expert SA는 개발자, 설계자, 데이터 과학자로서 제조, 하이테크, 금융 등 다양한 산업 분야에서 엔터프라이즈 IT를 경험했습니다. 그는 기계 학습 및 딥 러닝, 특히 하이퍼파라미터 최적화 및 도메인 적응과 같은 주제에 대한 연구를 수행하고 알고리즘과 논문을 발표했습니다. AWS에서 그는 산업 전반의 AI/ML을 전문으로 하며 분산 교육/대규모 모델 및 MLOps 구축을 위해 AWS 서비스를 사용하여 기술 검증을 제공합니다. AI/ML 생태계 확장에 기여하는 것을 목표로 아키텍처를 제안하고 검토합니다.
최영준AI/ML Expert SA는 개발자, 설계자, 데이터 과학자로서 제조, 하이테크, 금융 등 다양한 산업 분야에서 엔터프라이즈 IT를 경험했습니다. 그는 기계 학습 및 딥 러닝, 특히 하이퍼파라미터 최적화 및 도메인 적응과 같은 주제에 대한 연구를 수행하고 알고리즘과 논문을 발표했습니다. AWS에서 그는 산업 전반의 AI/ML을 전문으로 하며 분산 교육/대규모 모델 및 MLOps 구축을 위해 AWS 서비스를 사용하여 기술 검증을 제공합니다. AI/ML 생태계 확장에 기여하는 것을 목표로 아키텍처를 제안하고 검토합니다.
 김정훈 AWS Korea의 계정 SA입니다. 하이테크, 제조, 금융, 공공 부문 등 다양한 산업 분야의 애플리케이션 아키텍처 설계, 개발 및 시스템 모델링 경험을 바탕으로 기업 고객을 위한 AWS 클라우드 여정 및 AWS에서의 워크로드 최적화 작업을 진행하고 있습니다.
김정훈 AWS Korea의 계정 SA입니다. 하이테크, 제조, 금융, 공공 부문 등 다양한 산업 분야의 애플리케이션 아키텍처 설계, 개발 및 시스템 모델링 경험을 바탕으로 기업 고객을 위한 AWS 클라우드 여정 및 AWS에서의 워크로드 최적화 작업을 진행하고 있습니다.
 록 사콩 KT R&D 연구원입니다. 다양한 분야에서 비전 AI에 대한 연구개발을 진행해 왔으며 주로 얼굴 속성(성별/안경, 모자 등)/얼굴과 관련된 얼굴인식 기술을 수행해왔다. 현재 그는 비전 모델을 위한 경량 기술을 연구하고 있습니다.
록 사콩 KT R&D 연구원입니다. 다양한 분야에서 비전 AI에 대한 연구개발을 진행해 왔으며 주로 얼굴 속성(성별/안경, 모자 등)/얼굴과 관련된 얼굴인식 기술을 수행해왔다. 현재 그는 비전 모델을 위한 경량 기술을 연구하고 있습니다.
 마노이 라비 Amazon SageMaker의 수석 제품 관리자입니다. 그는 차세대 AI 제품을 만드는 데 열정을 갖고 있으며 고객이 대규모 기계 학습을 더 쉽게 할 수 있도록 소프트웨어와 도구를 연구하고 있습니다. 그는 Haas 경영대학원에서 MBA를 취득했고 Carnegie Mellon University에서 정보 시스템 관리 석사 학위를 취득했습니다. 여가 시간에는 Manoj는 테니스를 치고 풍경 사진을 찍는 것을 즐깁니다.
마노이 라비 Amazon SageMaker의 수석 제품 관리자입니다. 그는 차세대 AI 제품을 만드는 데 열정을 갖고 있으며 고객이 대규모 기계 학습을 더 쉽게 할 수 있도록 소프트웨어와 도구를 연구하고 있습니다. 그는 Haas 경영대학원에서 MBA를 취득했고 Carnegie Mellon University에서 정보 시스템 관리 석사 학위를 취득했습니다. 여가 시간에는 Manoj는 테니스를 치고 풍경 사진을 찍는 것을 즐깁니다.
 로버트 반 두센 Amazon SageMaker의 수석 제품 관리자입니다. 그는 딥 러닝 교육을 위한 프레임워크, 컴파일러 및 최적화 기술을 이끌고 있습니다.
로버트 반 두센 Amazon SageMaker의 수석 제품 관리자입니다. 그는 딥 러닝 교육을 위한 프레임워크, 컴파일러 및 최적화 기술을 이끌고 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/kts-journey-to-reduce-training-time-for-a-vision-transformers-model-using-amazon-sagemaker/

