개요
ChatGPT
현대 비즈니스의 역동적인 환경에서 기계 학습과 운영(MLOps)의 교차점은 판매 전환 최적화에 대한 기존 접근 방식을 재편하는 강력한 힘으로 등장했습니다. 이 기사에서는 MLOps 전략이 판매 전환 성공을 혁신하는 데 있어 혁신적인 역할을 수행하는 방법을 소개합니다. 기업이 효율성 향상과 고객 상호 작용 강화를 위해 노력함에 따라 기계 학습 기술을 운영에 통합하는 것이 중요해졌습니다. 이 탐색에서는 MLOps를 활용하여 영업 프로세스를 간소화할 뿐만 아니라 잠재 고객을 충성도 높은 고객으로 전환하는 데 있어 전례 없는 성공을 거두는 혁신적인 전략을 공개합니다. 우리와 함께 복잡한 과정을 탐험해 보세요. MLOps 전략적 적용이 판매 전환의 환경을 어떻게 재편하고 있는지 알아보세요.
학습 목표
- 판매 최적화 모델의 중요성
- 데이터 정리, 데이터 세트 변환, 데이터 세트 전처리
- Kedro 및 Deepcheck를 사용하여 엔드투엔드 사기 탐지 구축
- Streamlit 및 Huggingface를 사용하여 모델 배포
이 기사는 데이터 과학 블로그.
차례
판매 최적화 모델이란 무엇입니까?
판매 최적화 모델은 제품 판매를 극대화하고 전환율을 향상시키기 위한 엔드투엔드 기계 학습 모델입니다. 이 모델은 노출수, 연령 그룹, 성별, 클릭률, 클릭당 비용과 같은 여러 매개변수를 입력으로 사용합니다. 모델을 훈련하면 모델은 광고를 본 후 제품을 구매할 사람의 수를 예측합니다.
필수 전제조건
1) 저장소 복제
git clone https://github.com/ashishk831/Final-THC.git
cd Final-THC2) 가상환경 생성 및 활성화
#create a virtual environment
python3 -m venv SOP
#Activate your virtual environment in your project folder
source SOP/bin/activate
pip install -r requirements.txt4) Kedro, Kedro-viz, Streamlit 및 Deepcheck를 설치합니다.
pip install streamlit
pip install Deepcheck
pip install Kedro
pip install Kedro-viz데이터 설명
Kaggle의 데이터 세트에서 Python 구현을 사용하여 기본적인 데이터 분석을 수행해 보겠습니다. 데이터세트를 다운로드하려면 여기를 클릭해 문의해주세요.
import pandas as pd
import numpy as np
df = pd.read_csv('KAG_conversion_data.csv')
df.head()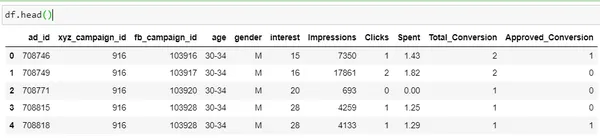
| 단 | 상품 설명 |
| 광고_ID | 각 광고의 고유 ID |
| xyz_campaign_id | XYZ 회사의 각 광고 캠페인과 연결된 ID |
| fb_campaign_id | Facebook이 각 캠페인을 추적하는 방법과 연결된 ID |
| 나이 | 광고를 보는 사람의 나이 |
| 성별 | 추가할 사람의 성별이 표시됩니다. |
| 관심 | 개인의 관심 분야가 속하는 카테고리를 지정하는 코드(관심 분야는 해당 개인의 Facebook 공개 프로필에 언급된 바와 같음) |
| 노출 | 광고가 게재된 횟수입니다. |
| 클릭 | 해당 광고에 대한 클릭수입니다. |
| 보낸 | 해당 광고를 표시하기 위해 회사 xyz가 Facebook에 지불한 금액 |
| 금액 변환 |
금액 광고를 본 후 제품에 대해 문의한 사람 수 |
| 승인 변환 |
금액 광고를 본 후 제품을 구매한 사람 수 |
여기서는 “승인된 전환”가 대상 열입니다. 우리의
목표는 사람들이 제품을 본 후 제품 판매를 늘릴 수 있는 모델을 디자인하는 것입니다.
광고.
Kedro를 사용한 모델 개발
이 프로젝트를 엔드 투 엔드로 구축하기 위해 Kedro 도구를 사용할 것입니다. Kedro는 프로덕션에 바로 사용할 수 있는 기계 학습 모델을 구축하는 데 사용되는 오픈 소스 도구로, 다양한 이점을 제공합니다.
- 복잡성 처리: 성공적인 테스트 후 프로덕션으로 푸시할 수 있는 테스트 데이터를 위한 구조를 제공합니다.
- 표준화: 프로젝트에 대한 표준 템플릿을 제공합니다. 다른 사람들이 이해하기 쉽게 만듭니다.
- 생산 준비: 재현 가능하고 유지 관리가 가능하며 모듈식 실험으로 전환할 수 있는 탐색적 코드를 사용하여 코드를 프로덕션 환경으로 쉽게 푸시할 수 있습니다.
상세 보기: Kedro 프레임워크 연습
파이프라인 구조
Kedro에서 프로젝트를 생성하려면 아래 단계를 따르세요.
#create project
kedro new
#create pipeline
kedro pipeline create <pipeline-name>
#Run kedro
kedro run
#Visualizing pipeline
kedro vizkedro를 사용하여 아래와 같은 엔드투엔드 모델 파이프라인을 설계합니다.
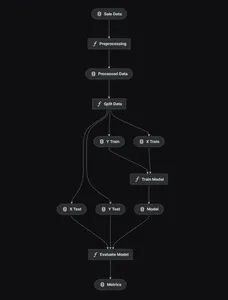
데이터 전처리
- 누락된 값을 확인하고 처리합니다.
- CTR과 CPC라는 두 개의 새 항목을 만듭니다.
- 열 변수를 숫자로 변환합니다.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
def preprocessing(data: pd.DataFrame):
data.gender = data.gender.apply(lambda x: 1 if x=="M" else 0)
data['CTR'] = ((data['Clicks']/data['Impressions'])*100)
data['CPC'] = data['Spent']/data['Clicks']
data['CPC'] = data['CPC'].replace(np.nan,0)
encoder=LabelEncoder()
encoder.fit(data["age"])
data["age"]=encoder.transform(data["age"])
#data.Approved_Conversion = data.Approved_Conversion.apply(lambda x: 0 if x==0 else 1)
preprocessed_data = data.copy()
return preprocessed_data데이터 분할
import pandas as pd
from sklearn.model_selection import train_test_split
def split_data(processed_data: pd.DataFrame):
X = processed_data[['ad_id', 'age', 'gender', 'interest', 'Spent',
'Total_Conversion','CTR', 'CPC']]
y = processed_data["Approved_Conversion"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1,
random_state=42)
return X_train, X_test, y_train, y_test위의 데이터 세트는 모델 학습 목적의 학습 데이터 세트와 테스트 데이터 세트로 구분됩니다.
모델 훈련
from sklearn.ensemble import RandomForestRegressor
def train_model(X_train, y_train):
model = RandomForestRegressor(n_estimators = 50, random_state = 0, max_samples=0.75)
model.fit(X_train, y_train)
return model
RandomForestRegressor 모듈을 사용하여 모델을 학습할 것입니다. RandomForestRegressor를 사용하면 n_estimators, random_state 및 max_samples와 같은 다른 매개변수를 전달합니다.
평가
import numpy as np
import logging
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, max_error
def evaluate_model(model, X_test, y_test):
y_pred = model.predict(X_test)
mae=mean_absolute_error(y_test, y_pred)
mse=mean_squared_error(y_test, y_pred)
rmse=np.sqrt(mse)
r2score=r2_score(y_test, y_pred)
me = max_error(y_test, y_pred)
print("MAE Of Model is: ",mae)
print("MSE Of Model is: ",mse)
print("RMSE Of Model is: ",rmse)
print("R2_Score Of Model is: ",r2score)
logger = logging.getLogger(__name__)
logger.info("Model has a coefficient R^2 of %.3f on test data.", r2score)
return {"r2_score": r2score, "mae": mae, "max_error": me}모델이 훈련되면 MAE, MSE, RMSE 및 R2 점수와 같은 주요 지표를 사용하여 평가됩니다.
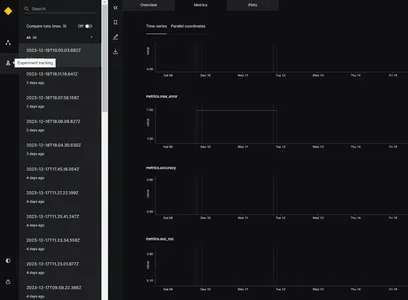
실험 추적기
모델 성능을 추적하고 최상의 모델을 선택하기 위해 실험 추적기를 사용합니다. 실험 추적기의 기능은 응용 프로그램이 실행될 때 실험에 대한 모든 정보를 저장하는 것입니다. Kedro에서 실험 추적기를 활성화하려면 Catalog.xml 파일을 업데이트하면 됩니다. 버전이 지정된 매개변수는 True로 설정되어야 합니다. 아래는 예시입니다
model:
type: pickle.PickleDataSet
filepath: data/06_models/model.pkl
backend: pickle
versioned: True이는 모델 결과를 추적하고 모델 버전을 저장하는 데 도움이 됩니다. 여기서는 개발 단계에서 모델 성능을 추적하기 위해 평가 단계에서 실험 추적기를 사용합니다.
모델이 실행되면 이미지에 표시된 것처럼 다양한 타임스탬프에 대해 MAE, MSE, RMSE 및 R2 점수와 같은 다양한 평가 지표가 생성됩니다. 위의 평가 지표를 바탕으로 최상의 모델을 선택할 수 있습니다.
Deepcheck: 데이터 및 모델 모니터링용
모델이 프로덕션 환경에 배포되면 시간이 지남에 따라 데이터 품질이 변경될 가능성이 있으며 이 모델로 인해 성능도 변경될 수 있습니다. 이 문제를 해결하려면 프로덕션 환경에서 데이터를 모니터링해야 합니다. 이를 위해 우리는 오픈 소스 도구인 Deepcheck를 사용할 것입니다. Deepcheck에는 모델 코드와 쉽게 통합할 수 있는 Label-drift 및 Feature-Drift와 같은 내장 라이브러리가 있습니다.
- FeatureDrift: – 드리프트는 모델 성능 저하로 인해 시간이 지남에 따라 데이터 분포가 변경되는 것을 의미합니다. FeaturDift는 데이터 세트의 단일 기능에서 변경이 발생했음을 의미합니다.
- Labeldrift: – Labeldrift는 시간이 지남에 따라 데이터 세트의 정답 레이블이 변경될 때 발생합니다. 주로 라벨 기준의 변경으로 인해 발생합니다.
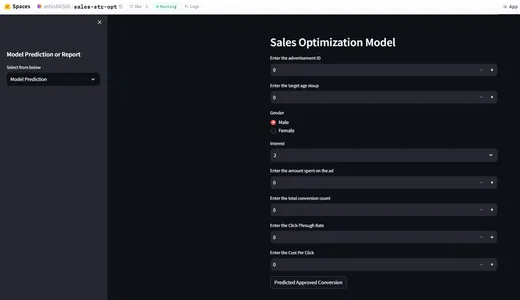
모델 예측 및 모니터링을 Streamlit과 통합
이제 전환율을 확인하기 위해 주어진 입력 매개변수에 대한 예측을 수행하는 모델과 상호 작용하는 사용자 인터페이스를 구축하겠습니다.
import streamlit as st
import pandas as pd
import joblib
import numpy as np
st.sidebar.header("Model Prediction or Report")
selected_report = st.sidebar.selectbox("Select from below", ["Model Prediction",
"Data Integrity","Feature Drift", "Label Drift"])
if selected_report=="Model Prediction":
st.header("Sales Optimization Model")
#def predict(ad_id, age, gender, interest, Impressions, Clicks, Spent,
#Total_Conversion, CTR, CPC):
def predict(ad_id, age, gender, interest, Spent, Total_Conversion, CTR, CPC):
if gender == 'Male':
gender = 0
else:
gender = 1
ad_id = int(ad_id)
age = int(age)
gender = int(gender)
interest = int(interest)
#Impressions = int(Impressions)
#Clicks = int(Clicks)
Spent = float(Spent)
Total_Conversion = int(Total_Conversion)
CTR = float(CTR*0.000001)
CPC = float(CPC)
input=np.array([[ad_id, age, gender, interest, Spent,
Total_Conversion, CTR, CPC]]).astype(np.float64)
model = joblib.load('model/model.pkl')
# Make prediction
prediction = model.predict(input)
prediction= np.round(prediction)
# Return the predicted value for Approved_Conversion
return prediction
ad_id = st.number_input('Enter the advertisement ID',min_value = 0)
age = st.number_input('Enter the target age stoup',min_value = 0)
gender = st.radio("Gender",('Male','Female'))
interest = st.selectbox('Interest', [2, 7, 10, 15, 16, 18, 19, 20, 21, 22, 23,
24, 25,
26, 27, 28, 29, 30, 31, 32, 36, 63, 64, 65, 66, 100, 101, 102,
103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114])
#Impressions = st.number_input('Enter the number of impressions',min_value = 0)
#Clicks = st.number_input('Enter the number of clicks',min_value = 0)
Spent = st.number_input('Enter the amount spent on the ad',min_value = 0)
Total_Conversion = st.number_input('Enter the total conversion count',
min_value = 0)
CTR = st.number_input('Enter the Click-Through Rate',min_value = 0)
CPC = st.number_input('Enter the Cost Per Click',min_value = 0)
if st.button("Predicted Approved Conversion"):
output = predict(ad_id, age, gender, interest, Spent, Total_Conversion,
CTR, CPC)
st.success("Approved Conversion Rate :{}".format(output))
else:
st.header("Sales Model Monitoring Report")
report_file_name = "report/"+ selected_report.replace(" ", "") + ".html"
HtmlFile = open(report_file_name, 'r', encoding='utf-8')
source_code = HtmlFile.read()
st.components.v1.html(source_code, width=1200, height=1500, scrolling=True)
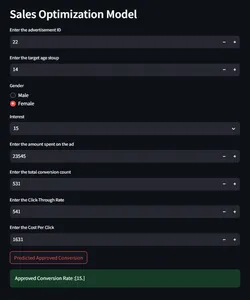
HuggingFace를 사용한 배포
이제 엔드 투 엔드 판매 최적화 모델을 구축했으므로 HuggingFace를 사용하여 모델을 배포하겠습니다. Huggingface에서는 모델 배포를 위해 README.md 파일을 구성해야 합니다. Huggingface는 CI/CD를 담당합니다. 파일이 변경될 때마다 변경 사항을 추적하고 앱을 다시 배포합니다. 다음은 readme.md 파일 구성입니다.
title: {{Sale-str-opt}}
emoji: {{Sale-str-opt}}
colorFrom: {{colorFrom}}
colorTo: {{colorTo}}
sdk: {{sdk}}
sdk_version: {{sdkVersion}}
app_file: app.py
pinned: falseHuggingFace 앱 데모
클라우드 버전을 보려면 클릭하세요. 여기를 클릭해 문의해주세요.
결론
- 기계 학습 앱은 알려지지 않은 시장에서 테스트 전환율을 제공하여 기업이 제품 수요를 알 수 있도록 돕습니다.
- 판매 최적화 모델을 사용하면 비즈니스에서 올바른 대상 그룹을 타겟팅할 수 있습니다.
- 이 응용 프로그램은 비즈니스 수익을 높이는 데 도움이 됩니다.
- 실시간으로 데이터를 모니터링하면 모델 변경 및 사용자 행동 변화를 추적하는 데 도움이 될 수도 있습니다.
자주하는 질문
A. 판매 최적화 모델의 목적은 광고를 본 후 제품을 구매할 고객 수를 예측하는 것입니다.
A. 데이터 모니터링은 데이터세트와 모델 동작을 추적하는 데 도움이 됩니다.
A. 예, Hugingface는 기본 기능인 2 vCPU, 16GB RAM을 사용하면 무료로 사용할 수 있습니다.
A. 모델 모니터링 단계에서 보고서를 선택하는 데 엄격한 규칙은 없습니다. deepcheck에는 모델 드리프트, 분포 드리프트와 같은 많은 내장 라이브러리가 있습니다.
A. Streamlit은 로컬 배포를 도와 개발 단계에서 오류를 수정하는 데 도움이 됩니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2024/01/mlops-strategies-for-sales-conversion-success/

