이 게시물은 LSEG의 Low Latency Group의 Pramod Nayak, LakshmiKanth Mannem 및 Vivek Aggarwal과 공동 작성되었습니다.
거래 비용 분석(TCA)은 거래자, 포트폴리오 관리자 및 중개인이 거래 전 및 거래 후 분석을 위해 널리 사용하며 거래 비용과 거래 전략의 효율성을 측정하고 최적화하는 데 도움이 됩니다. 이 게시물에서는 옵션 매수-매도 스프레드를 분석합니다. LSEG 틱 내역 – PCAP 다음을 사용하는 데이터세트 Apache Spark용 Amazon Athena. 대규모 데이터 세트의 경우에도 인프라 설정이나 Spark 구성에 대해 걱정할 필요 없이 데이터에 액세스하고, 데이터에 적용할 사용자 지정 함수를 정의하고, 데이터 세트를 쿼리 및 필터링하고, 분석 결과를 시각화하는 방법을 보여줍니다.
배경
OPRA(옵션 가격 보고 기관)는 미국 옵션에 대한 최종 판매 보고서, 시세 및 관련 정보를 수집, 통합 및 배포하는 중요한 증권 정보 처리자 역할을 합니다. 18개의 활성 미국 옵션 거래소와 1.5만 개 이상의 적격 계약을 통해 OPRA는 포괄적인 시장 데이터를 제공하는 데 중추적인 역할을 합니다.
5년 2024월 48일, SIAC(Securities Industry Automation Corporation)는 OPRA 피드를 96개에서 37.3개 멀티캐스트 채널로 업그레이드할 예정입니다. 이번 개선의 목표는 미국 옵션 시장의 거래 활동 및 변동성 확대에 대응하여 기호 분포 및 라인 용량 활용도를 최적화하는 것입니다. SIAC는 기업이 초당 최대 XNUMXGBit의 최대 데이터 속도에 대비할 것을 권장했습니다.
업그레이드를 통해 게시된 데이터의 전체 양이 즉시 변경되지는 않지만 OPRA는 훨씬 더 빠른 속도로 데이터를 전파할 수 있습니다. 이러한 전환은 동적 옵션 시장의 요구를 해결하는 데 매우 중요합니다.
OPRA는 150.4년 3분기에 하루 최대 2023억 개의 메시지를 기록하고 하루에 400억 개의 메시지에 대한 용량 헤드룸 요구 사항을 포함하여 가장 방대한 피드 중 하나로 돋보입니다. 모든 단일 메시지를 캡처하는 것은 거래 비용 분석, 시장 유동성 모니터링, 거래 전략 평가 및 시장 조사에 중요합니다.
데이터에 대하여
LSEG 틱 내역 – PCAP 30PB가 넘는 클라우드 기반 리포지토리로 초고품질 글로벌 시장 데이터를 보유하고 있습니다. 이 데이터는 전 세계 주요 기본 및 백업 교환 데이터 센터에 전략적으로 배치된 중복 캡처 프로세스를 사용하여 교환 데이터 센터 내에서 직접 꼼꼼하게 캡처됩니다. LSEG의 캡처 기술은 무손실 데이터 캡처를 보장하고 나노초 타임스탬프 정밀도를 위해 GPS 시간 소스를 사용합니다. 또한 모든 데이터 격차를 원활하게 메우기 위해 정교한 데이터 차익거래 기술이 사용됩니다. 캡처 후 데이터는 세심한 처리 및 중재를 거친 다음 다음을 사용하여 Parquet 형식으로 정규화됩니다. LSEG의 실시간 울트라 다이렉트 (RTUD) 피드 핸들러.
분석용 데이터 준비에 필수적인 정규화 프로세스는 하루에 최대 6TB의 압축된 Parquet 파일을 생성합니다. 방대한 양의 데이터는 여러 거래소에 걸쳐 있고 다양한 특성을 특징으로 하는 수많은 옵션 계약을 특징으로 하는 OPRA의 포괄적 특성에 기인합니다. 옵션 거래소의 증가된 시장 변동성과 시장 조성 활동은 OPRA에 게시되는 데이터의 양에 더욱 기여합니다.
Tick History – PCAP의 속성을 통해 회사는 다음을 포함한 다양한 분석을 수행할 수 있습니다.
- 거래 전 분석 – 잠재적인 무역 영향을 평가하고 과거 데이터를 기반으로 다양한 실행 전략을 탐색합니다.
- 거래 후 평가 – 벤치마크와 비교하여 실제 실행 비용을 측정하여 실행 전략의 성과를 평가합니다.
- 최적화 실행 – 과거 시장 패턴을 기반으로 실행 전략을 미세 조정하여 시장 영향을 최소화하고 전체 거래 비용을 절감합니다.
- 위험 관리 – 슬리피지 패턴 식별, 이상값 식별, 거래 활동과 관련된 위험을 사전에 관리
- 성과 기여 – 포트폴리오 성과를 분석할 때 투자 결정과 거래 결정의 영향을 분리합니다.
LSEG Tick History – PCAP 데이터 세트는 다음에서 사용할 수 있습니다. AWS 데이터 교환 다음에서 액세스할 수 있습니다. AWS Marketplace. 과 Amazon S3용 AWS 데이터 교환, LSEG에서 직접 PCAP 데이터에 액세스할 수 있습니다. 아마존 단순 스토리지 서비스 (Amazon S3) 버킷을 사용하면 기업이 자체 데이터 사본을 저장할 필요가 없습니다. 이 접근 방식은 데이터 관리 및 저장을 간소화하여 클라이언트가 사용, 통합 및 사용 편의성을 통해 고품질 PCAP 또는 정규화된 데이터에 즉시 액세스할 수 있도록 합니다. 상당한 데이터 저장 공간 절약.
Apache Spark용 Athena
분석적인 노력을 위해, Apache Spark용 Athena Athena 콘솔 또는 Athena API를 통해 액세스할 수 있는 단순화된 노트북 환경을 제공하므로 대화형 Apache Spark 애플리케이션을 구축할 수 있습니다. 최적화된 Spark 런타임을 통해 Athena는 Spark 엔진 수를 1초 미만으로 동적으로 확장하여 페타바이트 규모의 데이터 분석을 돕습니다. 또한 pandas 및 NumPy와 같은 일반적인 Python 라이브러리가 완벽하게 통합되어 복잡한 애플리케이션 논리를 생성할 수 있습니다. 유연성은 노트북에서 사용하기 위한 사용자 정의 라이브러리 가져오기까지 확장됩니다. Athena for Spark는 대부분의 개방형 데이터 형식을 수용하며 다음과 원활하게 통합됩니다. AWS 접착제 데이터 카탈로그.
데이터 세트
이 분석을 위해 우리는 17년 2023월 XNUMX일의 LSEG Tick History – PCAP OPRA 데이터 세트를 사용했습니다. 이 데이터 세트는 다음 구성 요소로 구성됩니다.
- 최적의 입찰 및 제안(BBO) – 특정 거래소에서 증권에 대한 최고 입찰가와 최저 입찰가를 보고합니다.
- 전국 최고 입찰 및 제안(NBBO) – 모든 거래소에서 최고 입찰가와 최저 입찰가를 보고합니다.
- 거래 – 모든 거래소에서 완료된 거래를 기록합니다.
데이터 세트에는 다음과 같은 데이터 볼륨이 포함됩니다.
- 거래 – 약 160개의 압축된 Parquet 파일에 분산된 60MB
- BBO – 약 2.4개의 압축된 Parquet 파일에 300TB 분산
- NBBO – 약 2.8개의 압축된 Parquet 파일에 200TB 분산
분석 개요
거래 비용 분석(TCA)을 위한 OPRA 틱 내역 데이터 분석에는 특정 거래 이벤트에 대한 시장 시세 및 거래를 면밀히 조사하는 작업이 포함됩니다. 우리는 이 연구의 일부로 다음 측정항목을 사용합니다.
- 호가 스프레드(QS) – BBO 요청과 BBO 입찰의 차이로 계산됩니다.
- 유효 확산(ES) – 거래가격과 BBO 중간점의 차이로 계산(BBO 매수+(BBO 매도 – BBO 매수)/2)
- 유효/호가 스프레드(EQF) – (ES / QS) * 100으로 계산됩니다.
우리는 거래 전과 거래 후 1개의 간격(거래 직후, 10초, 60초, XNUMX초)에 추가로 이러한 스프레드를 계산합니다.
Apache Spark용 Athena 구성
Apache Spark용 Athena를 구성하려면 다음 단계를 완료하세요.
- Athena 콘솔에서 시작하기, 고르다 PySpark 및 Spark SQL을 사용하여 데이터 분석.
- Athena Spark를 처음 사용하는 경우 다음을 선택하세요. 작업 그룹 만들기.

- 럭셔리 작업 그룹 이름¸ 다음과 같이 작업 그룹의 이름을 입력하십시오.
tca-analysis.
- . 분석 엔진 섹션에서 선택 아파치 스파크.
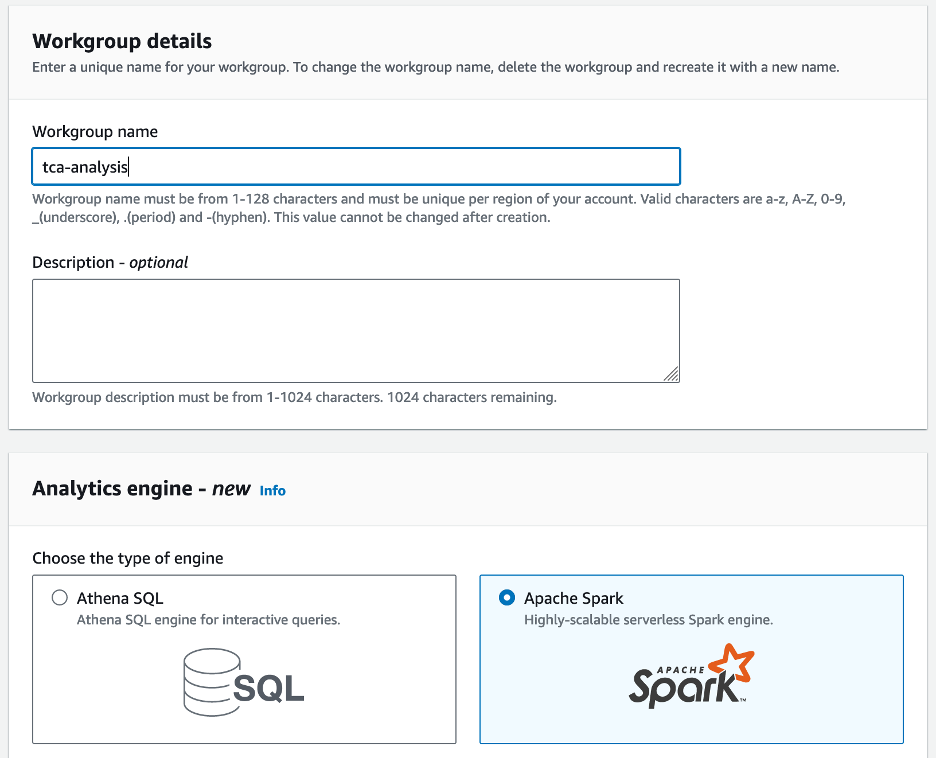
- . 추가 구성 섹션에서 선택할 수 있습니다. 기본값 사용 또는 사용자 정의를 제공 AWS 자격 증명 및 액세스 관리 (IAM) 역할 및 계산 결과를 위한 Amazon S3 위치입니다.
- 왼쪽 메뉴에서 작업 그룹 만들기.
- 작업그룹을 생성한 후 노트북 탭하고 선택 노트 만들기.
- 다음과 같이 노트북 이름을 입력하세요.
tca-analysis-with-tick-history.
- 왼쪽 메뉴에서 만들기 노트북을 만들 수 있습니다.
노트북을 실행하세요
Spark 작업 그룹을 이미 생성한 경우 노트북 편집기 실행 아래에 시작하기.
노트북이 생성되면 대화형 노트북 편집기로 리디렉션됩니다.

이제 노트북에 다음 코드를 추가하고 실행할 수 있습니다.
분석 생성
분석을 생성하려면 다음 단계를 완료하세요.
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
- BBO, NBBO 및 거래를 위한 데이터 프레임을 생성합니다.
bbo_quote = spark.read.parquet(f"s3://<bucket>/mt=bbo_quote/f=opra/dt=2023-05-17/*")
bbo_quote.createOrReplaceTempView("bbo_quote")
nbbo_quote = spark.read.parquet(f"s3://<bucket>/mt=nbbo_quote/f=opra/dt=2023-05-17/*")
nbbo_quote.createOrReplaceTempView("nbbo_quote")
trades = spark.read.parquet(f"s3://<bucket>/mt=trade/f=opra/dt=2023-05-17/29_1.parquet")
trades.createOrReplaceTempView("trades")
- 이제 거래 비용 분석에 사용할 거래를 식별할 수 있습니다.
filtered_trades = spark.sql("select Product, Price,Quantity, ReceiptTimestamp, MarketParticipant from trades")
다음 출력을 얻습니다.
+---------------------+---------------------+---------------------+-------------------+-----------------+
|Product |Price |Quantity |ReceiptTimestamp |MarketParticipant|
+---------------------+---------------------+---------------------+-------------------+-----------------+
|QQQ 230518C00329000|1.1700000000000000000|10.0000000000000000000|1684338565538021907,NYSEArca|
|QQQ 230518C00329000|1.1700000000000000000|20.0000000000000000000|1684338576071397557,NASDAQOMXPHLX|
|QQQ 230518C00329000|1.1600000000000000000|1.0000000000000000000|1684338579104713924,ISE|
|QQQ 230518C00329000|1.1400000000000000000|1.0000000000000000000|1684338580263307057,NASDAQOMXBX_Options|
|QQQ 230518C00329000|1.1200000000000000000|1.0000000000000000000|1684338581025332599,ISE|
+---------------------+---------------------+---------------------+-------------------+-----------------+
앞으로는 거래상품(tp), 거래가격(tpr), 거래시간(tt)에 대해 강조표시된 거래정보를 활용합니다.
- 여기서는 분석을 위한 여러 도우미 함수를 만듭니다.
def calculate_es_qs_eqf(df, trade_price):
df['BidPrice'] = df['BidPrice'].astype('double')
df['AskPrice'] = df['AskPrice'].astype('double')
df["ES"] = ((df["AskPrice"]-df["BidPrice"])/2) - trade_price
df["QS"] = df["AskPrice"]-df["BidPrice"]
df["EQF"] = (df["ES"]/df["QS"])*100
return df
def get_trade_before_n_seconds(trade_time, df, seconds=0, groupby_col = None):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] < nseconds].groupby(groupby_col).last()
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
ret_df = ret_df.reset_index()
return ret_df
def get_trade_after_n_seconds(trade_time, df, seconds=0, groupby_col = None):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] > nseconds].groupby(groupby_col).first()
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
ret_df = ret_df.reset_index()
return ret_df
def get_nbbo_trade_before_n_seconds(trade_time, df, seconds=0):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] < nseconds].iloc[-1:]
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
return ret_df
def get_nbbo_trade_after_n_seconds(trade_time, df, seconds=0):
nseconds=seconds*1000000000
nseconds += trade_time
ret_df = df[df['ReceiptTimestamp'] > nseconds].iloc[:1]
ret_df['BidPrice'] = ret_df['BidPrice'].astype('double')
ret_df['AskPrice'] = ret_df['AskPrice'].astype('double')
return ret_df
- 다음 함수에서는 거래 전후의 모든 시세를 포함하는 데이터 세트를 생성합니다. Athena Spark는 데이터 세트 처리를 위해 시작할 DPU 수를 자동으로 결정합니다.
def get_tca_analysis_via_df_single_query(trade_product, trade_price, trade_time):
# BBO quotes
bbos = spark.sql(f"SELECT Product, ReceiptTimestamp, AskPrice, BidPrice, MarketParticipant FROM bbo_quote where Product = '{trade_product}';")
bbos = bbos.toPandas()
bbo_just_before = get_trade_before_n_seconds(trade_time, bbos, seconds=0, groupby_col='MarketParticipant')
bbo_just_after = get_trade_after_n_seconds(trade_time, bbos, seconds=0, groupby_col='MarketParticipant')
bbo_1s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=1, groupby_col='MarketParticipant')
bbo_10s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=10, groupby_col='MarketParticipant')
bbo_60s_after = get_trade_after_n_seconds(trade_time, bbos, seconds=60, groupby_col='MarketParticipant')
all_bbos = pd.concat([bbo_just_before, bbo_just_after, bbo_1s_after, bbo_10s_after, bbo_60s_after], ignore_index=True, sort=False)
bbos_calculated = calculate_es_qs_eqf(all_bbos, trade_price)
#NBBO quotes
nbbos = spark.sql(f"SELECT Product, ReceiptTimestamp, AskPrice, BidPrice, BestBidParticipant, BestAskParticipant FROM nbbo_quote where Product = '{trade_product}';")
nbbos = nbbos.toPandas()
nbbo_just_before = get_nbbo_trade_before_n_seconds(trade_time,nbbos, seconds=0)
nbbo_just_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=0)
nbbo_1s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=1)
nbbo_10s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=10)
nbbo_60s_after = get_nbbo_trade_after_n_seconds(trade_time, nbbos, seconds=60)
all_nbbos = pd.concat([nbbo_just_before, nbbo_just_after, nbbo_1s_after, nbbo_10s_after, nbbo_60s_after], ignore_index=True, sort=False)
nbbos_calculated = calculate_es_qs_eqf(all_nbbos, trade_price)
calc = pd.concat([bbos_calculated, nbbos_calculated], ignore_index=True, sort=False)
return calc
- 이제 선택한 거래의 정보를 사용하여 TCA 분석 기능을 호출해 보겠습니다.
tp = "QQQ 230518C00329000"
tpr = 1.16
tt = 1684338579104713924
c = get_tca_analysis_via_df_single_query(tp, tpr, tt)
분석 결과 시각화
이제 시각화에 사용하는 데이터 프레임을 만들어 보겠습니다. 각 데이터 프레임에는 각 데이터 피드(BBO, NBBO)에 대한 5가지 시간 간격 중 하나에 대한 인용문이 포함되어 있습니다.
bbo = c[c['MarketParticipant'].isin(['BBO'])]
bbo_bef = bbo[bbo['ReceiptTimestamp'] < tt]
bbo_aft_0 = bbo[bbo['ReceiptTimestamp'].between(tt,tt+1000000000)]
bbo_aft_1 = bbo[bbo['ReceiptTimestamp'].between(tt+1000000000,tt+10000000000)]
bbo_aft_10 = bbo[bbo['ReceiptTimestamp'].between(tt+10000000000,tt+60000000000)]
bbo_aft_60 = bbo[bbo['ReceiptTimestamp'] > (tt+60000000000)]
nbbo = c[~c['MarketParticipant'].isin(['BBO'])]
nbbo_bef = nbbo[nbbo['ReceiptTimestamp'] < tt]
nbbo_aft_0 = nbbo[nbbo['ReceiptTimestamp'].between(tt,tt+1000000000)]
nbbo_aft_1 = nbbo[nbbo['ReceiptTimestamp'].between(tt+1000000000,tt+10000000000)]
nbbo_aft_10 = nbbo[nbbo['ReceiptTimestamp'].between(tt+10000000000,tt+60000000000)]
nbbo_aft_60 = nbbo[nbbo['ReceiptTimestamp'] > (tt+60000000000)]
다음 섹션에서는 다양한 시각화를 생성하기 위한 예제 코드를 제공합니다.
거래 전에 QS와 NBBO를 플롯합니다.
거래 전 견적 스프레드와 NBBO를 표시하려면 다음 코드를 사용하세요.
fig = px.bar(title="Quoted Spread Before The Trade",
x=bbo_bef.MarketParticipant,
y=bbo_bef['QS'],
labels={'x': 'Market', 'y':'Quoted Spread'})
fig.add_hline(y=nbbo_bef.iloc[0]['QS'],
line_width=1, line_dash="dash", line_color="red",
annotation_text="NBBO", annotation_font_color="red")
%plotly fig

거래 후 각 시장과 NBBO에 대한 QS를 플롯합니다.
다음 코드를 사용하여 거래 직후 각 시장 및 NBBO에 대한 견적 스프레드를 표시합니다.
fig = px.bar(title="Quoted Spread After The Trade",
x=bbo_aft_0.MarketParticipant,
y=bbo_aft_0['QS'],
labels={'x': 'Market', 'y':'Quoted Spread'})
fig.add_hline(
y=nbbo_aft_0.iloc[0]['QS'],
line_width=1, line_dash="dash", line_color="red",
annotation_text="NBBO", annotation_font_color="red")
%plotly fig

BBO에 대한 각 시간 간격 및 각 시장에 대한 QS를 플롯합니다.
다음 코드를 사용하여 BBO에 대한 각 시간 간격 및 각 시장에 대한 견적 스프레드를 표시합니다.
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['QS']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['QS']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['QS']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['QS']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['QS'])])
fig.update_layout(barmode='group',title="BBO Quoted Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Quoted Spread'})
%plotly fig

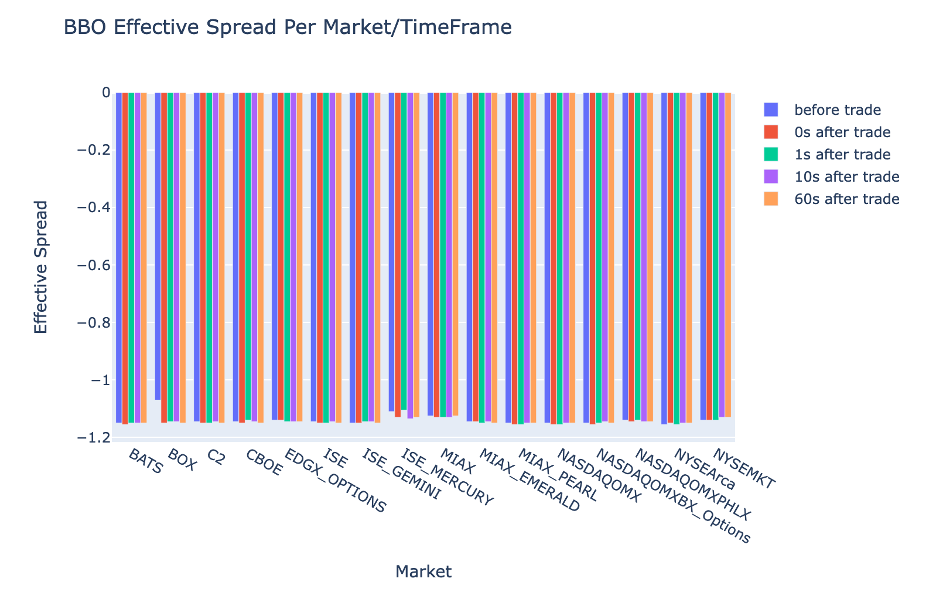
BBO에 대한 각 시간 간격 및 시장에 대한 ES를 플롯합니다.
다음 코드를 사용하여 BBO의 각 시간 간격 및 시장에 대한 유효 스프레드를 표시합니다.
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['ES']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['ES']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['ES']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['ES']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['ES'])])
fig.update_layout(barmode='group',title="BBO Effective Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Effective Spread'})
%plotly fig
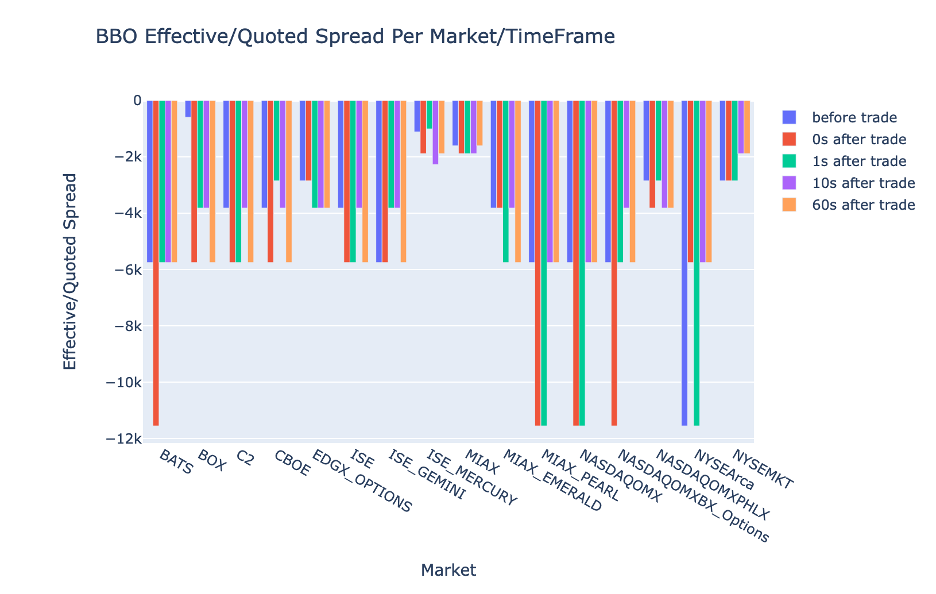
BBO에 대한 각 시간 간격 및 시장에 대한 EQF를 플롯합니다.
다음 코드를 사용하여 BBO의 각 시간 간격 및 시장에 대한 유효/견적 스프레드를 표시합니다.
fig = go.Figure(data=[
go.Bar(name="before trade", x=bbo_bef.MarketParticipant.unique(), y=bbo_bef['EQF']),
go.Bar(name="0s after trade", x=bbo_aft_0.MarketParticipant.unique(), y=bbo_aft_0['EQF']),
go.Bar(name="1s after trade", x=bbo_aft_1.MarketParticipant.unique(), y=bbo_aft_1['EQF']),
go.Bar(name="10s after trade", x=bbo_aft_10.MarketParticipant.unique(), y=bbo_aft_10['EQF']),
go.Bar(name="60s after trade", x=bbo_aft_60.MarketParticipant.unique(), y=bbo_aft_60['EQF'])])
fig.update_layout(barmode='group',title="BBO Effective/Quoted Spread Per Market/TimeFrame",
xaxis={'title':'Market'},
yaxis={'title':'Effective/Quoted Spread'})
%plotly fig
Athena Spark 계산 성능
코드 블록을 실행하면 Athena Spark는 계산을 완료하는 데 필요한 DPU 수를 자동으로 결정합니다. 마지막 코드 블록에서 tca_analysis 함수를 사용하면 실제로 Spark에 데이터를 처리하도록 지시한 다음 결과 Spark 데이터 프레임을 Pandas 데이터 프레임으로 변환합니다. 이는 분석에서 가장 집약적인 처리 부분을 구성하며, Athena Spark가 이 블록을 실행하면 진행률 표시줄, 경과 시간, 현재 데이터를 처리하고 있는 DPU 수가 표시됩니다. 예를 들어 다음 계산에서 Athena Spark는 18개의 DPU를 활용하고 있습니다.

Athena Spark 노트북을 구성할 때 사용할 수 있는 최대 DPU 수를 설정할 수 있는 옵션이 있습니다. 기본값은 20개의 DPU이지만 Athena Spark가 분석을 실행하기 위해 자동으로 확장되는 방법을 보여주기 위해 이 계산을 10, 20, 40개의 DPU로 테스트했습니다. 우리는 Athena Spark가 선형적으로 확장되는 것을 관찰했습니다. 노트북이 최대 15개의 DPU로 구성된 경우에는 21분 10초가 걸렸고, 노트북이 8개의 DPU로 구성된 경우에는 23분 20초가 걸렸으며, 노트북이 최대 4개의 DPU로 구성된 경우에는 44분 40초가 걸렸습니다. XNUMX개의 DPU로 구성됩니다. Athena Spark는 DPU 사용량을 기준으로 초당 요금을 청구하므로 이러한 계산 비용은 비슷하지만 최대 DPU 값을 더 높게 설정하면 Athena Spark가 분석 결과를 훨씬 빠르게 반환할 수 있습니다. Athena Spark 가격에 대한 자세한 내용을 보려면 클릭하세요. 여기에서 지금 확인해 보세요..
결론
이 게시물에서는 LSEG Tick History-PCAP의 충실도 높은 OPRA 데이터를 사용하여 Athena Spark를 사용하여 거래 비용 분석을 수행하는 방법을 시연했습니다. 적시에 OPRA 데이터를 사용할 수 있고 Amazon S3용 AWS Data Exchange의 접근성 혁신이 보완되어 중요한 거래 결정에 대해 실행 가능한 통찰력을 생성하려는 기업의 분석 시간이 전략적으로 단축됩니다. OPRA는 매일 약 7TB의 정규화된 Parquet 데이터를 생성하며, OPRA 데이터를 기반으로 분석을 제공하기 위한 인프라를 관리하는 것은 어렵습니다.
Tick History – OPRA 데이터용 PCAP에 대한 대규모 데이터 처리를 처리하는 Athena의 확장성은 AWS에서 신속하고 확장 가능한 분석 솔루션을 원하는 조직에게 매력적인 선택이 됩니다. 이 게시물에서는 AWS 생태계와 Tick History-PCAP 데이터 간의 원활한 상호 작용과 금융 기관이 이러한 시너지 효과를 활용하여 중요한 거래 및 투자 전략에 대한 데이터 기반 의사 결정을 내릴 수 있는 방법을 보여줍니다.
저자에 관하여
 프라모드 나약 LSEG의 Low Latency Group 제품 관리 이사입니다. Pramod는 소프트웨어 개발, 분석 및 데이터 관리에 중점을 두고 금융 기술 업계에서 10년 이상의 경험을 보유하고 있습니다. Pramod는 전직 소프트웨어 엔지니어였으며 시장 데이터와 퀀트 트레이딩에 열정을 갖고 있습니다.
프라모드 나약 LSEG의 Low Latency Group 제품 관리 이사입니다. Pramod는 소프트웨어 개발, 분석 및 데이터 관리에 중점을 두고 금융 기술 업계에서 10년 이상의 경험을 보유하고 있습니다. Pramod는 전직 소프트웨어 엔지니어였으며 시장 데이터와 퀀트 트레이딩에 열정을 갖고 있습니다.
 락쉬미칸스 만넴 LSEG의 Low Latency 그룹의 제품 관리자입니다. 그는 지연 시간이 짧은 시장 데이터 산업을 위한 데이터 및 플랫폼 제품에 중점을 두고 있습니다. LakshmiKanth는 고객이 시장 데이터 요구 사항에 가장 적합한 솔루션을 구축할 수 있도록 지원합니다.
락쉬미칸스 만넴 LSEG의 Low Latency 그룹의 제품 관리자입니다. 그는 지연 시간이 짧은 시장 데이터 산업을 위한 데이터 및 플랫폼 제품에 중점을 두고 있습니다. LakshmiKanth는 고객이 시장 데이터 요구 사항에 가장 적합한 솔루션을 구축할 수 있도록 지원합니다.
 비벡 아가르왈 LSEG Low Latency Group의 수석 데이터 엔지니어입니다. Vivek은 캡처된 시장 데이터 피드와 참조 데이터 피드의 처리 및 전달을 위한 데이터 파이프라인을 개발하고 유지 관리하는 일을 하고 있습니다.
비벡 아가르왈 LSEG Low Latency Group의 수석 데이터 엔지니어입니다. Vivek은 캡처된 시장 데이터 피드와 참조 데이터 피드의 처리 및 전달을 위한 데이터 파이프라인을 개발하고 유지 관리하는 일을 하고 있습니다.
 알켓 메무샤즈 AWS 금융 서비스 시장 개발 팀의 수석 설계자입니다. Alket은 파트너 및 고객과 협력하여 가장 까다로운 자본 시장 워크로드도 AWS 클라우드에 배포하는 기술 전략을 담당하고 있습니다.
알켓 메무샤즈 AWS 금융 서비스 시장 개발 팀의 수석 설계자입니다. Alket은 파트너 및 고객과 협력하여 가장 까다로운 자본 시장 워크로드도 AWS 클라우드에 배포하는 기술 전략을 담당하고 있습니다.

