カスタマー 360 (C360) すべてのタッチポイントとチャネルにわたる顧客のインタラクションと行動の完全かつ統一されたビューを提供します。このビューは、顧客の行動のパターンと傾向を特定するために使用され、データに基づいた意思決定を行い、ビジネスの成果を向上させることができます。たとえば、C360 を使用して、特定の顧客グループの共感を呼びやすいマーケティング キャンペーンをセグメント化して作成できます。
2022 年に AWS は、米国生産性品質センター (APQC) が実施した調査を委託して、 顧客360のビジネス価値。次の図は、調査から得られた指標の一部を示しています。 C360 を使用している組織は、販売サイクル期間の 43.9% の短縮、顧客生涯価値の 22.8% の増加、市場投入までの時間の 25.3% の短縮、ネット プロモーター スコア (NPS) 評価の 19.1% の向上を達成しました。

C360 がなければ、企業は機会の逸失、不正確なレポート、支離滅裂な顧客エクスペリエンスに直面し、顧客離れにつながります。ただし、C360 ソリューションの構築は複雑になる場合があります。あ ガートナーのマーケティング調査 C14 ソリューションの導入に成功している組織は 360% のみであることがわかりました。これは、360 度のビューが何を意味するかについてのコンセンサスが不足していること、データ品質に関する課題、顧客データに対する部門横断的なガバナンス構造の欠如が原因です。
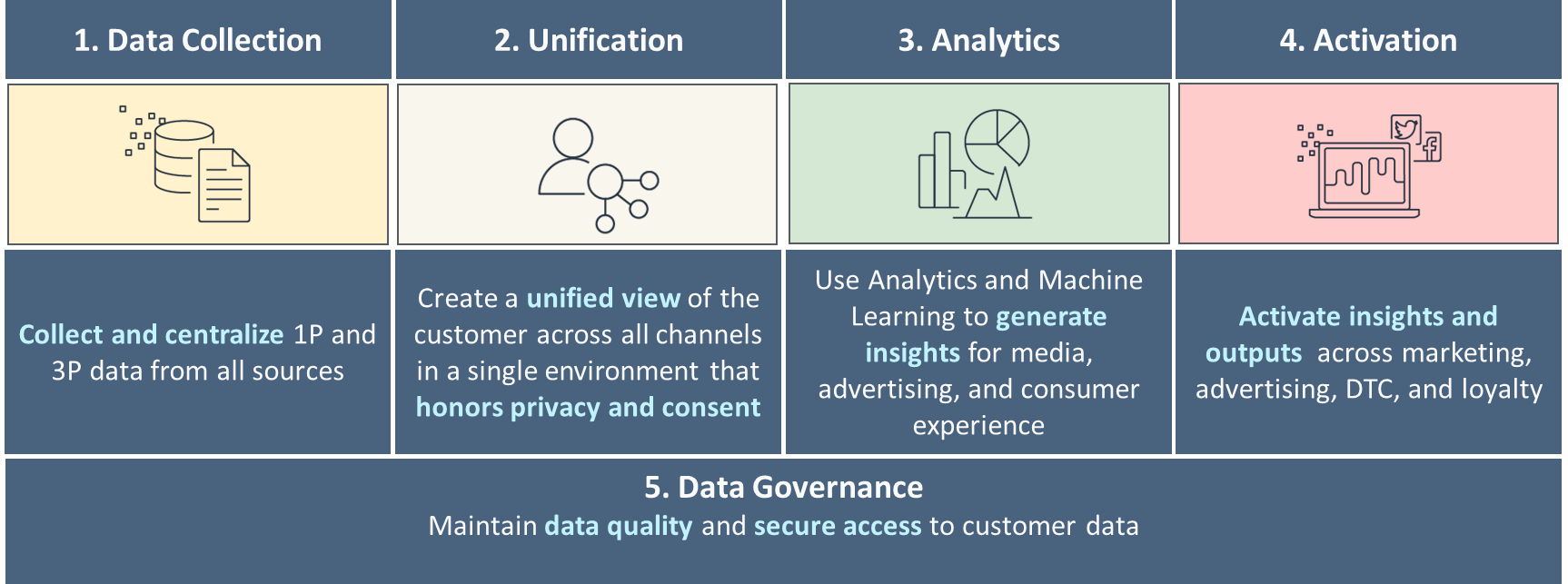
この投稿では、専用の AWS サービスを使用して、C360 のエンドツーエンドのデータ戦略を作成し、これらの課題に対処する顧客データを統合および管理する方法について説明します。 C360 を強化する XNUMX つの柱 (データ収集、統合、分析、アクティベーション、データ ガバナンス) と、実装に使用できるソリューション アーキテクチャで構成されています。
成熟したC360のXNUMXつの柱
C360 の作成に着手するときは、複数のユースケース、顧客データの種類、さまざまなツールを必要とするユーザーとアプリケーションを扱うことになります。適切なデータセットに C360 を構築し、データの品質を維持しながら時間の経過とともに新しいデータセットを追加し、安全に保つには、顧客データに対するエンドツーエンドのデータ戦略が必要です。また、チームが C360 を成熟させる製品を簡単に構築できるようにするツールも提供する必要があります。
次の図に示すように、C360 の XNUMX つの柱に基づいてデータ戦略を構築することをお勧めします。これは、基本的なデータ収集から始まり、固有の顧客に関連するさまざまなチャネルからのデータを統合してリンクし、意思決定のための基本的な分析から高度な分析、さまざまなチャネルを通じたパーソナライズされたエンゲージメントへと進みます。これらの各柱で成熟するにつれて、リアルタイムの顧客シグナルへの対応に向けて進歩していきます。
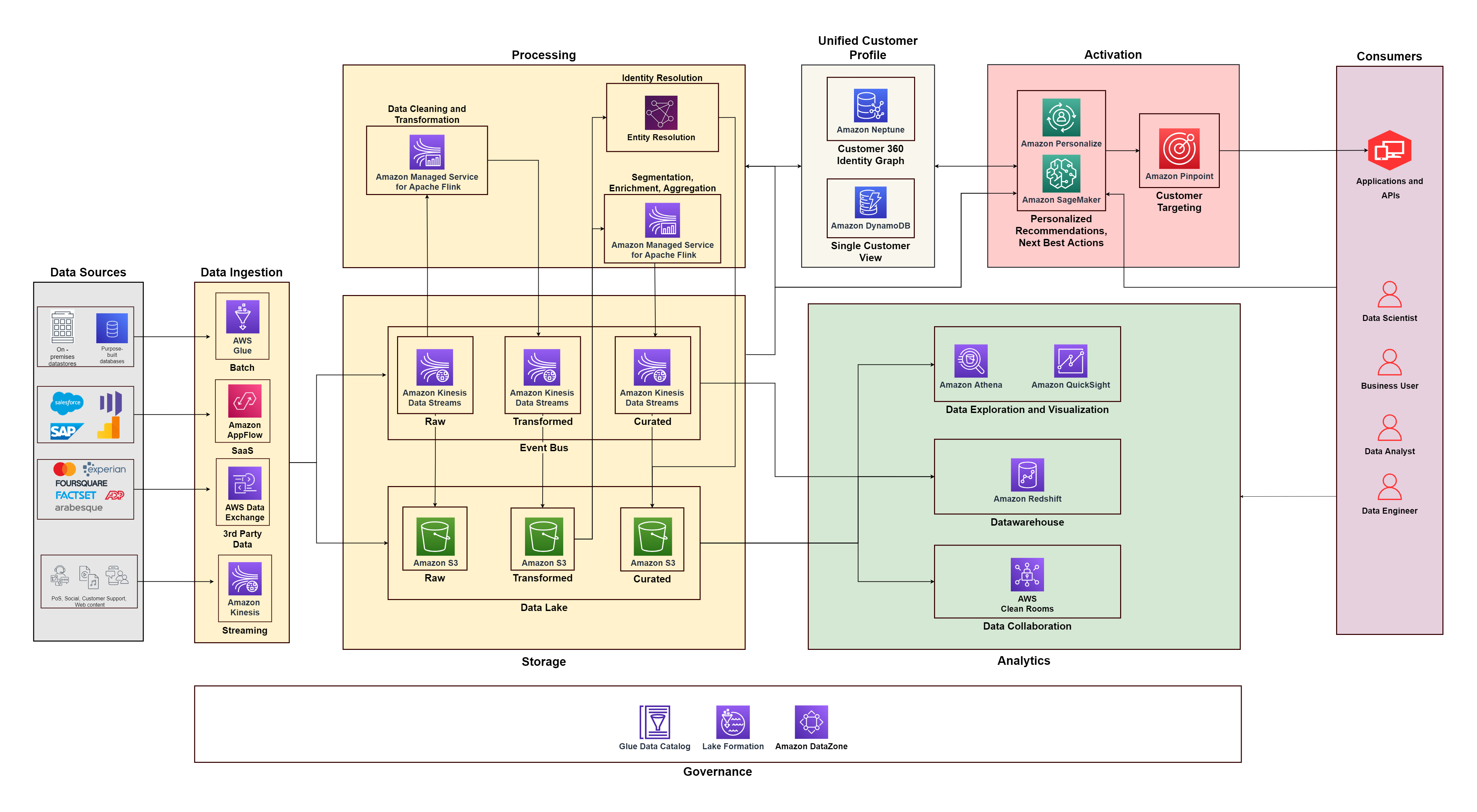
次の図は、構成要素を組み合わせた機能アーキテクチャを示しています。 AWS 上の顧客データ プラットフォーム エンドツーエンドの C360 ソリューションの設計に使用される追加コンポーネントを使用します。これは、この投稿で説明する XNUMX つの柱と一致しています。
柱 1: データ収集
顧客データ プラットフォームの構築を始めると、販売システム、カスタマー サポート、Web およびソーシャル メディア、データ マーケットプレイスなどのさまざまなシステムやタッチポイントからデータを収集する必要があります。データ収集の柱は、取り込み、ストレージ、処理機能の組み合わせであると考えてください。
データの取り込み
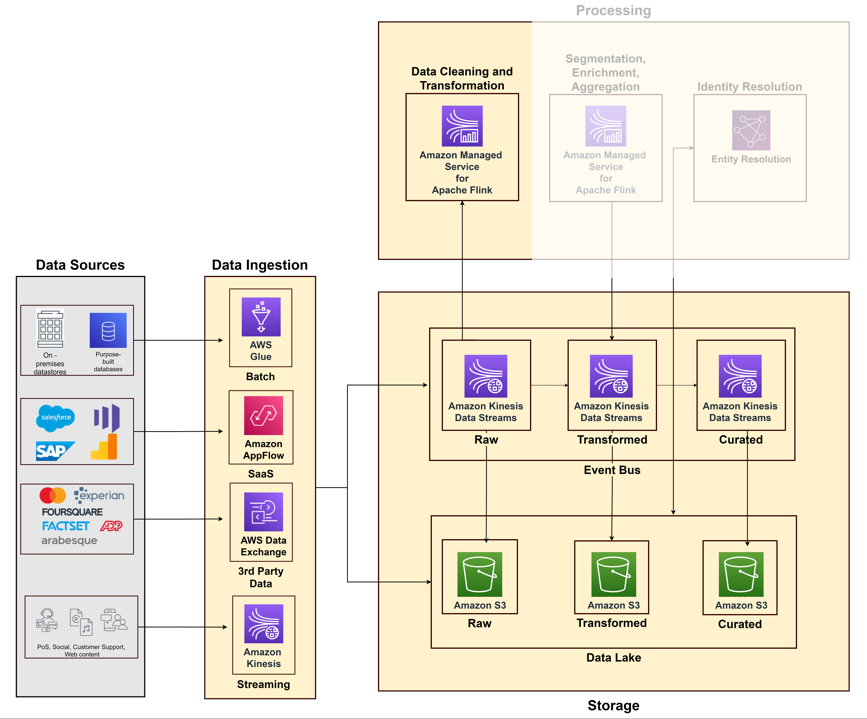
データ ソースの種類 (オンプレミス データ ストア、ファイル、SaaS アプリケーション、サードパーティ データ) やデータ フロー (無制限のストリームまたはバッチ データ) などの要素に基づいて取り込みパイプラインを構築する必要があります。 AWS は、データ取り込みパイプラインを構築するためのさまざまなサービスを提供します。
- AWSグルー は、オンプレミスのデータベースとクラウドのデータ ストアからデータをバッチで取り込むサーバーレス データ統合サービスです。 70 を超えるデータ ソースに接続し、パイプライン インフラストラクチャを管理することなく抽出、変換、読み込み (ETL) パイプラインを構築するのに役立ちます。 AWS Glue データ品質 不良データをチェックして警告するため、ビジネスに悪影響を与える前に問題を簡単に発見して修正できます。
- アマゾンアプリフロー Google Analytics、Salesforce、SAP、Marketo などの Software as a Service (SaaS) アプリケーションからデータを取り込むため、50 を超える SaaS アプリケーションからデータを柔軟に取り込むことができます。
- AWSデータ交換 分析用のサードパーティ データの検索、購読、使用が簡単になります。人口統計データ、広告データ、金融市場データなど、顧客プロファイルの充実に役立つデータ製品を購読できます。
- アマゾンキネシス POS システムからリアルタイムでストリーミング イベント、モバイル アプリや Web サイトからのクリックストリーム データ、ソーシャル メディア データを取り込みます。の使用を検討することもできます ApacheKafkaのAmazonマネージドストリーミング (Amazon MSK) リアルタイムでイベントをストリーミングします。
次の図は、AWS のサービスを使用してさまざまなソース システムからデータを取り込むためのさまざまなパイプラインを示しています。
データストレージ
構造化、半構造化、または非構造化バッチ データは、コスト効率が高く耐久性があるため、オブジェクト ストレージに保存されます。 Amazon シンプル ストレージ サービス (Amazon S3) は、ペタバイト規模のデータを保存できるアーカイブ機能を備えたマネージド ストレージ サービスです。 耐久性の 9 の XNUMX。低遅延が必要なストリーミング データは、次の場所に保存されます。 Amazon Kinesisデータストリーム リアルタイム消費用。これにより、Riot Games のセントラルで見られるように、さまざまな下流消費者に対する即時分析とアクションが可能になります。 暴動イベントバス.
データ処理
生データは、多くの場合、重複や不規則な形式で乱雑になっています。分析できるようにするには、これを処理する必要があります。バッチ データとストリーミング データを使用している場合は、両方を処理できるフレームワークの使用を検討してください。のようなパターン カッパ建築 すべてをストリームとして表示し、処理パイプラインを簡素化します。使用を検討してください Apache Flink 向け Amazon マネージドサービス 加工作業を担当します。 Apache Flink のマネージド サービスを使用すると、ストリーミング データをクリーンアップして変換し、遅延要件に基づいて適切な宛先に送信できます。次を使用してバッチ データ処理を実装することもできます。 アマゾンEMR Apache Spark などのオープンソース フレームワーク上 3.5 倍優れたパフォーマンス 自己管理バージョンよりも。バッチ処理システムまたはストリーミング処理システムを使用するアーキテクチャの決定は、さまざまな要因によって決まります。ただし、顧客データのリアルタイム分析を有効にしたい場合は、Kappa アーキテクチャ パターンを使用することをお勧めします。
第 2 の柱: 統一
さまざまなタッチポイントから届く多様なデータを固有の顧客にリンクするには、匿名ログインを識別し、有用な顧客情報を保存し、それらを外部データにリンクしてより良い洞察を得るとともに、顧客を関心のあるドメインにグループ化する ID 処理ソリューションを構築する必要があります。 ID 処理ソリューションは統合された顧客プロファイルの構築に役立ちますが、これをデータ処理機能の一部として考慮することをお勧めします。次の図は、そのようなソリューションのコンポーネントを示しています。
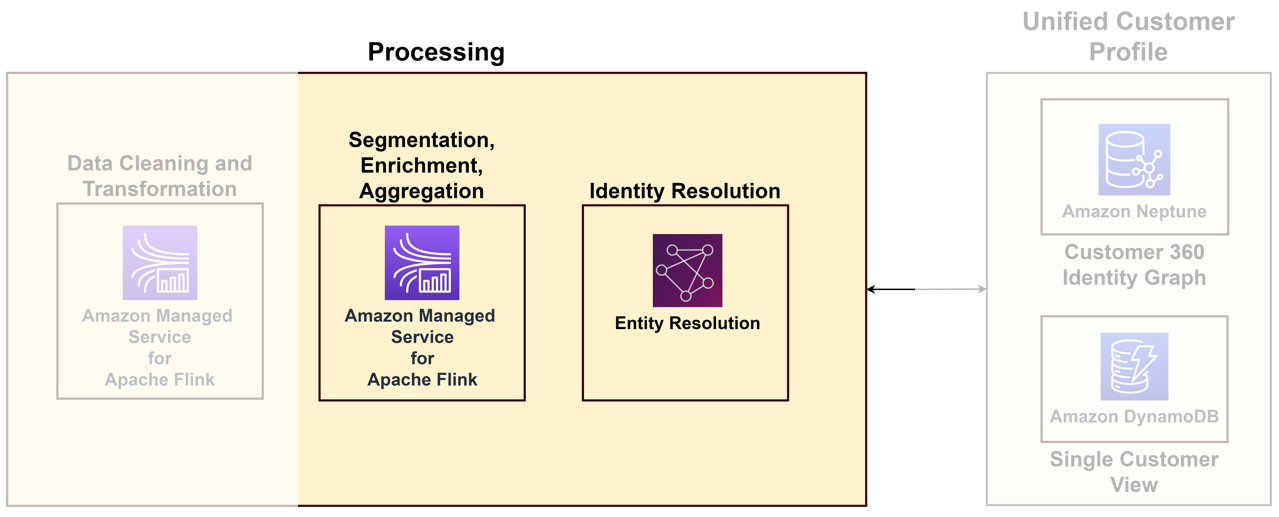
主要なコンポーネントは次のとおりです。
- ID 解決 – ID 解決は重複排除ソリューションであり、Cookie、デバイス ID、IP アドレス、電子メール ID、社内企業 ID などの複数の識別子を、プライバシーを使用して既知の個人または匿名プロファイルにリンクすることにより、レコードを照合して一意の顧客と見込み客を識別します。準拠したメソッド。これは次を使用して実現できます AWS エンティティ解決これにより、ルールと機械学習 (ML) テクニックを使用して、 レコードを照合して ID を解決する。 または、 恒等グラフを構築する アマゾン海王星 顧客の単一の統一されたビューを実現します。
- プロファイルの集約 – 顧客を一意に識別すると、次のことが可能になります。 Apache Flink のマネージド サービスでアプリケーションを構築する 名前からインタラクション履歴まで、すべてのメタデータを統合します。次に、このデータを簡潔な形式に変換します。すべてのトランザクションの詳細を表示する代わりに、集計された支出額と顧客関係管理 (CRM) レコードへのリンクを提供できます。顧客サービスのやり取りについては、平均 CSAT スコアとコール センター システムへのリンクを提供して、コミュニケーション履歴をより深く掘り下げます。
- プロファイルの強化 – 顧客を単一の ID に解決した後、さまざまなデータ ソースを使用して顧客のプロファイルを強化します。エンリッチメントには通常、人口統計データ、行動データ、地理位置情報データの追加が含まれます。使用できます AWS Marketplace のサードパーティデータ製品は AWS Data Exchange を通じて配信されます 収入、消費パターン、信用リスクスコア、その他多くの側面に関する洞察を得ることで、顧客エクスペリエンスをさらに向上させることができます。
- 顧客のセグメンテーション – 顧客のプロファイルを一意に識別して充実させた後、Apache Flink のマネージド サービスのアプリケーションを使用して、年齢、支出、収入、場所などの人口統計に基づいて顧客をセグメント化できます。進むにつれて、次のことを組み込むことができます より正確なターゲティング手法を実現する AI サービス。
ID 処理とセグメント化を行った後は、一意の顧客プロファイルを保存し、その上で下流の消費者が充実した顧客データを使用できるように検索機能とクエリ機能を提供するストレージ機能が必要になります。
次の図は、統合された顧客プロファイルと下流アプリケーションの顧客の単一ビューのための統合の柱を示しています。
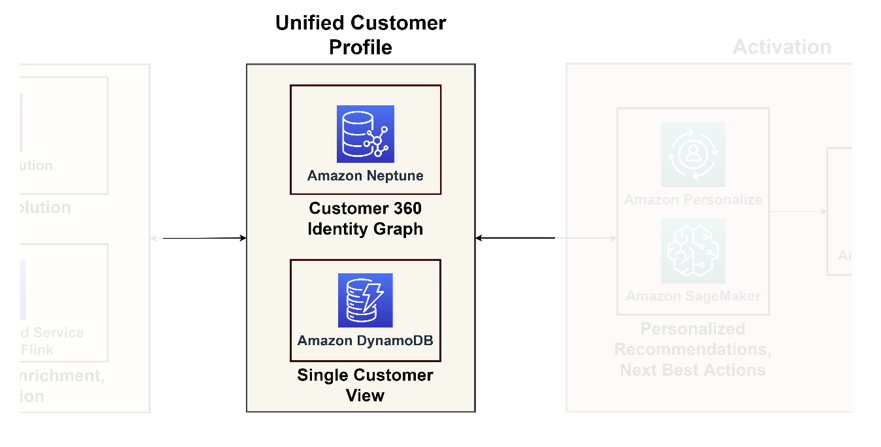
統合された顧客プロファイル
グラフ データベースは、顧客とのやり取りや関係のモデル化に優れており、カスタマー ジャーニーの包括的なビューを提供します。何十億ものプロファイルとインタラクションを扱う場合は、AWS のマネージド グラフ データベース サービスである Neptune の使用を検討できます。などの組織 アルファベットのゼット & Activision Neptune を使用して、1 か月あたり数十億の一意の識別子と、ミリ秒の応答時間で 1 秒あたり数百万のクエリを保存およびクエリすることに成功しました。
単一の顧客ビュー
グラフ データベースは詳細な洞察を提供しますが、通常のアプリケーションでは複雑になる可能性があります。このデータを単一の顧客ビューに統合し、e コマース プラットフォームから CRM システムに至る下流アプリケーションの主な参照として機能させることが賢明です。この統合されたビューは、データ プラットフォームと顧客中心のアプリケーションの間の連絡役として機能します。このような目的には、次の使用をお勧めします。 Amazon DynamoDB 適応性、拡張性、パフォーマンスが高く、最新かつ効率的な顧客データベースが実現します。このデータベースは、顧客に関する新しい情報を学習してフィードバックするアクティベーション システムからの大量の書き込みクエリを受け入れます。
柱 3: 分析
分析の柱は、顧客データに基づいて洞察を生成するのに役立つ機能を定義します。分析戦略は、C360 だけでなく、より広範な組織のニーズに適用されます。同じ機能を使用して、財務レポートを提供したり、運用パフォーマンスを測定したり、データ資産を収益化したりすることもできます。チームがデータを探索し、分析を実行し、下流の要件に合わせてデータを整理し、さまざまなレベルでデータを視覚化する方法に基づいて戦略を立てます。チームが ML を使用して記述的分析から規範的分析に移行できるようにする方法を計画します。
AWS の最新のデータ アーキテクチャ は、専用の安全でスケーラブルなデータ プラットフォームをクラウドに構築する方法を示しています。ここから学び、データ レイクとデータ ウェアハウス全体にわたるクエリ機能を構築します。
次の図は、分析機能をデータ探索、視覚化、データ ウェアハウジング、およびデータ コラボレーションに分類しています。これらの各コンポーネントが C360 のコンテキストでどのような役割を果たしているのかを見てみましょう。

データの探索
データ探索は、不一致、異常値、またはエラーを発見するのに役立ちます。これらを早期に発見することで、チームは C360 のためのよりクリーンなデータ統合を実現でき、それがより正確な分析と予測につながります。データを調査する担当者、その技術的スキル、洞察を得るまでの時間を考慮してください。たとえば、SQL の記述を知っているデータ アナリストは、次を使用して Amazon S3 に存在するデータを直接クエリできます。 アマゾンアテナ。視覚的な探索に興味のあるユーザーは、次を使用して探索できます。 AWS グルー DataBrew。データサイエンティストまたはエンジニアが使用できるのは、 アマゾンEMRスタジオ or Amazon SageMakerスタジオ ノートブックからデータを探索するには、ローコード エクスペリエンスのために、次を使用できます。 AmazonSageMakerデータラングラー。これらのサービスは S3 バケットに直接クエリを実行するため、データがデータ レイクに到着するときにデータを探索でき、洞察を得るまでの時間を短縮できます。
可視化
複雑なデータセットを直感的なビジュアルに変えることは、データ内の隠れたパターンを明らかにするものであり、C360 のユースケースでは非常に重要です。この機能を使用すると、さまざまなニーズに対応するさまざまなレベルのレポートを設計できます。戦略的な概要を提供するエグゼクティブ レポート、運用指標を強調する管理レポート、詳細にまで踏み込んだ詳細なレポートなどです。このような視覚的な明瞭さは、組織がすべての層にわたって情報に基づいた意思決定を行い、顧客の視点を一元化するのに役立ちます。
次の図は、C360 ダッシュボードのサンプルを示しています。 アマゾンクイックサイト。 QuickSight は、スケーラブルなサーバーレス視覚化機能を提供します。 ML 統合により、予測や異常検出、自然言語クエリなどの自動化された洞察を得ることができます。 QuickSight の Amazon Q、さまざまなソースからの直接データ接続、および セッションごとの支払い料金。 QuickSight を使用すると、次のことができます ダッシュボードを外部の Web サイトやアプリケーションに埋め込む、 そしてその スパイス このエンジンにより、大規模な迅速かつインタラクティブなデータ視覚化が可能になります。次のスクリーンショットは、QuickSight 上に構築された C360 ダッシュボードの例を示しています。
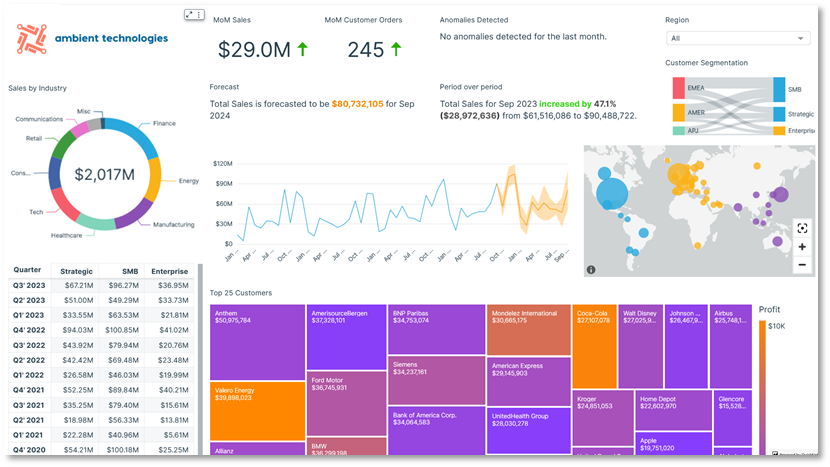
データウェアハウス
データ ウェアハウスは、さまざまなソースからの構造化データを効率的に統合し、多数の同時ユーザーからの分析クエリを処理します。データ ウェアハウスは、C360 ユースケースの膨大な量の顧客データの統一された一貫したビューを提供できます。 Amazonレッドシフト は、大量のデータと多様なワークロードを適切に処理することで、このニーズに対応します。データセット全体で強力な一貫性が提供されるため、組織は顧客に関する信頼性の高い包括的な洞察を得ることができます。これは情報に基づいた意思決定に不可欠です。 Amazon Redshift は、テラバイトからペタバイトまでのデータを分析するためのリアルタイムの洞察と予測分析機能を提供します。と Amazon Redshift MLを使用すると、最小限の開発オーバーヘッドで、データ ウェアハウスに保存されているデータの上に ML を埋め込むことができます。 AmazonRedshiftサーバーレス アプリケーションの構築が簡素化され、企業は豊富なデータ分析機能を簡単に組み込むことができます。
データ連携
安全にできる 集合的なデータセットを協力して分析する を使用して、相互に基盤となるデータを共有またはコピーすることなく、パートナーからデータを取得できます。 AWS クリーンルーム。エンゲージメント チャネルやパートナー データセット全体からの異種データを統合して、顧客の 360 度ビューを形成できます。 AWS Clean Rooms は、クロスチャネルマーケティングの最適化、高度な顧客セグメンテーション、プライバシーに準拠したパーソナライゼーションなどのユースケースを可能にすることで、C360 を強化できます。データセットを安全に結合することで、より豊富な洞察と堅牢なデータ プライバシーを提供し、ビジネス ニーズと規制基準を満たします。
柱 4: アクティベーション
データの価値は古くなるほど減少し、時間の経過とともに機会費用が増加します。アンケートで インターシステムズが実施, 調査対象となった組織の 75% が、時機を逸したデータがビジネスチャンスを妨げたと考えています。別の調査では、 組織の58% (HBR Advisory Council および読者の回答者 560 名のうち) は、リアルタイムの顧客分析を使用して顧客維持率とロイヤルティが向上したと回答しました。
これまでに議論した柱から得られたすべての洞察に基づいてリアルタイムで行動できる能力を構築すると、C360 の成熟度を達成できます。たとえば、この成熟度レベルでは、強化された顧客プロファイルと統合チャネルによって自動的に導き出されたコンテキストに基づいて、顧客感情に基づいて行動できます。そのためには、顧客の感情にどう対処するかについて規範的な意思決定を実装する必要があります。これを大規模に行うには、意思決定に AI/ML サービスを使用する必要があります。次の図は、規範的な分析に ML を使用し、ターゲティングとセグメンテーションに AI サービスを使用して洞察を有効にするアーキテクチャを示しています。
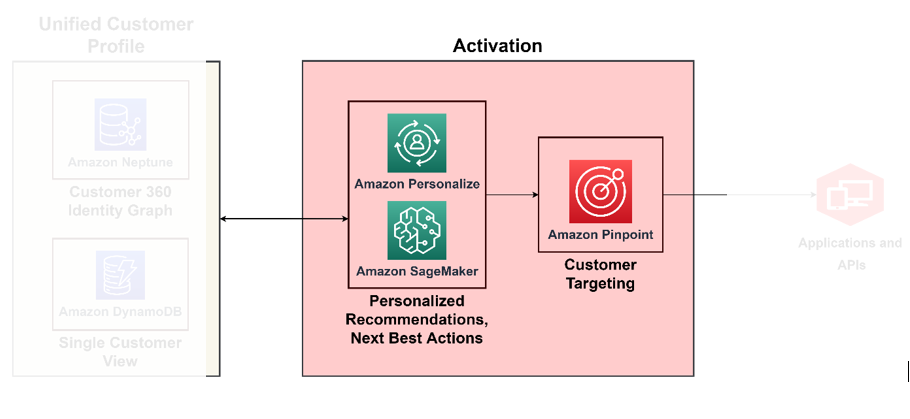
意思決定エンジンに ML を使用する
ML を使用すると、全体的な顧客エクスペリエンスを向上させることができます。予測的な顧客行動モデルを作成し、非常にパーソナライズされたオファーを設計し、適切なインセンティブで適切な顧客をターゲットにすることができます。それらを使用して構築できます アマゾンセージメーカーこれには、データ ラングリング、モデル トレーニング、モデル ホスティング、モデル推論、モデル ドリフト検出、特徴ストレージなど、データ サイエンスのライフサイクルにマッピングされた一連のマネージド サービスが含まれます。 SageMaker を使用すると、 ML モデルを構築して運用可能にするそれらをアプリケーションに注入して、適切なタイミングで適切な人に適切な洞察を提供します。
Amazonパーソナライズ は、コンテキストに応じた推奨事項をサポートしています。これにより、デバイスの種類、場所、時刻などのコンテキスト内で推奨事項を生成することで、その関連性を向上させることができます。チームは、ML の経験がなくても API を使用して、数回クリックするだけで高度なパーソナライゼーション機能を構築できます。詳細については、を参照してください。 Amazon Personalize のビジネスルールを使用して特定の商品を宣伝することで、おすすめをカスタマイズします.
マーケティング、広告、消費者直販、ロイヤルティにわたるチャネルを活性化する
顧客が誰で、誰に連絡を取るべきかがわかったので、大規模なターゲティング キャンペーンを実行するソリューションを構築できます。と アマゾンピンポイント、コミュニケーションをパーソナライズおよびセグメント化して、複数のチャネルにわたって顧客を引き付けることができます。たとえば、Amazon Pinpoint を使用すると、 魅力的な顧客エクスペリエンスを構築する 電子メール、SMS、プッシュ通知、アプリ内通知などのさまざまな通信チャネルを通じて。
柱 5: データ ガバナンス
制御とアクセスのバランスをとった適切なガバナンスを確立することで、ユーザーはデータに対する信頼と自信を得ることができます。顧客が必要としない製品のプロモーションを提供したり、間違った顧客に大量の通知を送りつけたりすることを想像してみてください。データ品質が低いとこのような状況が発生し、最終的には顧客離れにつながる可能性があります。データ品質を検証し、是正措置を講じるプロセスを構築する必要があります。 AWS Glue データ品質 は、事前定義されたルールに基づいて、保存時および転送中のデータの品質を検証するソリューションの構築に役立ちます。
顧客データの部門横断的なガバナンス構造をセットアップするには、組織全体でデータを管理および共有する機能が必要です。と アマゾンデータゾーン、管理者とデータ スチュワードはデータへのアクセスを管理および制御でき、データ エンジニア、データ サイエンティスト、プロダクト マネージャー、アナリスト、その他のビジネス ユーザーなどの消費者は、そのデータを検出、使用、および共同作業して洞察を引き出すことができます。データ アクセスを合理化し、顧客データを検索して使用できるようにし、共有データ資産を使用したチーム コラボレーションを促進し、Web アプリまたはポータル上の API を介してパーソナライズされた分析を提供します。 AWSレイクフォーメーション データが安全にアクセスされることを保証し、適切な人物が適切な理由で適切なデータを参照できるようにします。これは、あらゆる組織における効果的な部門横断的なガバナンスにとって重要です。ビジネスメタデータは、Amazon DataZone によって保存および管理されます。Amazon DataZone は、 AWSGlueデータカタログ。この技術メタデータは、Lake Formation や Amazon DataZone などの他のガバナンス サービスと、Amazon Redshift、Athena、AWS Glue などの分析サービスの両方でも使用されます。

それをすべてまとめる
次の図を参考にして、さまざまな機能を構築および運用するためのプロジェクトとチームを作成できます。たとえば、データ統合チームをデータ収集の柱に集中させることができ、データ アーキテクトやデータ エンジニアなどの機能上の役割を調整できます。分析とデータ サイエンスのプラクティスを構築して、それぞれ分析とアクティベーションの柱に焦点を当てることができます。その後、顧客の ID 処理と顧客の統一されたビューの構築のための専門チームを作成できます。さまざまな部門のデータ スチュワード、セキュリティ管理者、データ ガバナンス ポリシー作成者でデータ ガバナンス チームを設立し、ポリシーを設計および自動化できます。
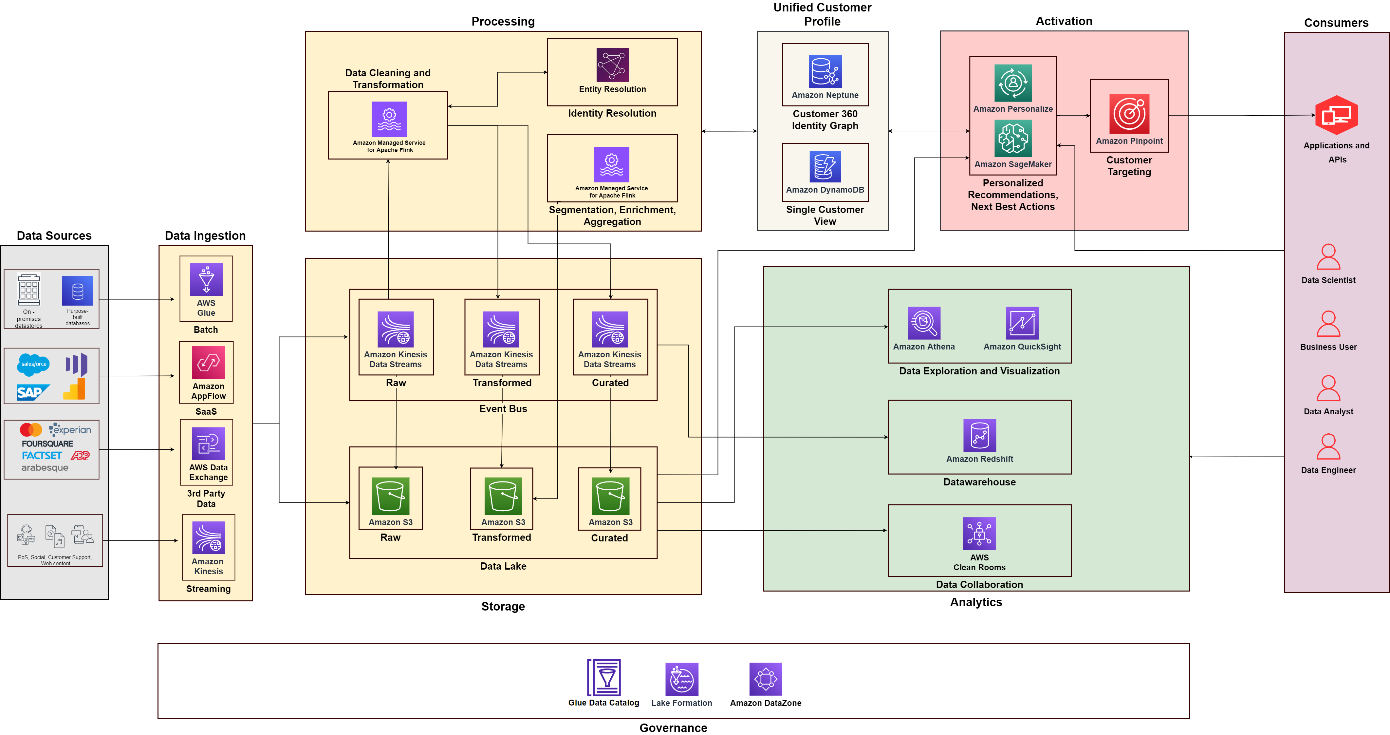
まとめ
組織が顧客ベースについて洞察を得るには、堅牢な C360 機能を構築することが不可欠です。 AWS データベース、分析、AI/ML サービスは、このプロセスを合理化し、スケーラビリティと効率を実現します。思考の指針となる 360 つの柱に従って、組織全体の CXNUMX ビューを定義し、データが正確であることを確認し、顧客データの部門横断的なガバナンスを確立するエンドツーエンドのデータ戦略を構築できます。各柱内で構築する必要がある製品と機能を分類して優先順位を付け、業務に適したツールを選択して、チームに必要なスキルを構築できます。
訪問 AWS for Data のお客様事例 AWS が世界最大の企業から成長中の新興企業に至るまで、カスタマージャーニーをどのように変革しているかを学びましょう。
著者について
 イスマイル・マフルーフ AWS のデータ分析のシニア スペシャリスト ソリューション アーキテクトです。 Ismail は、バッチおよびリアルタイムのストリーミング、ビッグ データ、データ ウェアハウジング、データ レイク ワークロードなど、エンドツーエンドのデータ分析資産全体にわたる組織向けのソリューションの設計に重点を置いています。彼は主に、小売、e コマース、フィンテック、ヘルステック、旅行の組織と連携して、適切に設計されたデータ プラットフォームを使用してビジネス目標を達成しています。
イスマイル・マフルーフ AWS のデータ分析のシニア スペシャリスト ソリューション アーキテクトです。 Ismail は、バッチおよびリアルタイムのストリーミング、ビッグ データ、データ ウェアハウジング、データ レイク ワークロードなど、エンドツーエンドのデータ分析資産全体にわたる組織向けのソリューションの設計に重点を置いています。彼は主に、小売、e コマース、フィンテック、ヘルステック、旅行の組織と連携して、適切に設計されたデータ プラットフォームを使用してビジネス目標を達成しています。
 サンディパン・ボーミック (サンディ) AWS のシニア分析スペシャリスト ソリューション アーキテクトです。彼は、顧客がクラウド内のデータ プラットフォームを最新化し、大規模な分析を安全に実行し、運用上のオーバーヘッドを削減し、費用対効果と持続可能性を高めるために使用を最適化できるよう支援しています。
サンディパン・ボーミック (サンディ) AWS のシニア分析スペシャリスト ソリューション アーキテクトです。彼は、顧客がクラウド内のデータ プラットフォームを最新化し、大規模な分析を安全に実行し、運用上のオーバーヘッドを削減し、費用対効果と持続可能性を高めるために使用を最適化できるよう支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

