この投稿は、Capitec の Preshen Goobiah および Johan Olivier との共同執筆です。
Apache Spark は、大規模なデータ ワークロードを処理することで有名な、広く使用されているオープンソース分散処理システムです。 これは、Spark 開発者の間で頻繁に使用されています。 アマゾンEMR, アマゾンセージメーカー, AWSグルー およびカスタム Spark アプリケーション。
Amazonレッドシフト Apache Spark とのシームレスな統合を提供し、Amazon Redshift でプロビジョニングされたクラスターとクラスターの両方で Redshift データに簡単にアクセスできるようにします。 AmazonRedshiftサーバーレス。 この統合により、AWS 分析および機械学習 (ML) ソリューションの可能性が拡大し、より幅広いアプリケーションがデータ ウェアハウスにアクセスできるようになります。
Apache Spark の Amazon Redshift 統合を使用すると、Java、Scala、Python、SQL、R などの一般的な言語を使用して Spark アプリケーションを簡単に開発でき、すぐに開始できます。アプリケーションは、最適なパフォーマンスとトランザクションの一貫性を維持しながら、Amazon Redshift データ ウェアハウスとのシームレスな読み取りと書き込みを行うことができます。 さらに、プッシュダウンの最適化によるパフォーマンスの向上の恩恵を受け、操作の効率がさらに向上します。
カピテック, 21万人以上のリテールバンキング顧客を抱える南アフリカ最大のリテール銀行は、南アフリカの人々がより良い生活を送れるよう、銀行業務を支援するため、シンプルで手頃な価格で利用しやすい金融サービスを提供することを目指しています。 この投稿では、Capitec の共有サービス機能プラットフォーム チームによるオープンソース Amazon Redshift コネクタの統合の成功について説明します。 Apache Spark の Amazon Redshift 統合を利用した結果、開発者の生産性は 10 倍に向上し、機能生成パイプラインが合理化され、データの重複がゼロに減少しました。
ビジネスチャンス
Capitec の小売クレジット部門全体で AWS Glue で構築された 19 の機能を利用する範囲には 93 の予測モデルがあります。 フィーチャレコードは、Amazon Redshift に保存されているファクトとディメンションで強化されます。 Apache PySpark が機能の作成に選択されたのは、さまざまなソースからのデータをラングリングするための高速、分散型、スケーラブルなメカニズムを提供するためです。
これらの運用機能は、ビジネス内でのリアルタイムの定期ローン申請、クレジット カード申請、毎月の信用状況のバッチ監視、日次給与のバッチ識別を可能にする上で重要な役割を果たします。
データ調達の問題
PySpark データ パイプラインの信頼性を確保するには、ディメンション テーブルとファクト テーブルの両方からの一貫したレコード レベルのデータがエンタープライズ データ ウェアハウス (EDW) に保存されていることが不可欠です。 これらのテーブルは、実行時に Enterprise Data Lake (EDL) のテーブルと結合されます。
機能開発中に、データ エンジニアは EDW へのシームレスなインターフェイスを必要とします。 このインターフェイスを使用すると、EDW から必要なデータにアクセスしてデータ パイプラインに統合できるため、機能の効率的な開発とテストが可能になります。
これまでの解決プロセス
以前のソリューションでは、製品チームのデータ エンジニアは、Redshift データを手動で Spark に公開するのに 30 回の実行につき XNUMX 分を費やしていました。 手順には次のものが含まれます。
- Python で述語クエリを作成します。
- 提出します アンロード 経由でクエリを実行する Amazon Redshift データ API.
- サンプリングを使用して、AWS SDK for Pandas 経由で AWS Glue データカタログにデータをカタログします。
このアプローチは大規模なデータセットに問題を引き起こし、プラットフォーム チームによる定期的なメンテナンスが必要であり、自動化が複雑でした。
現在のソリューションの概要
Capitec は、機能生成パイプライン内の Apache Spark の Amazon Redshift 統合により、これらの問題を解決することができました。 アーキテクチャは次の図で定義されています。
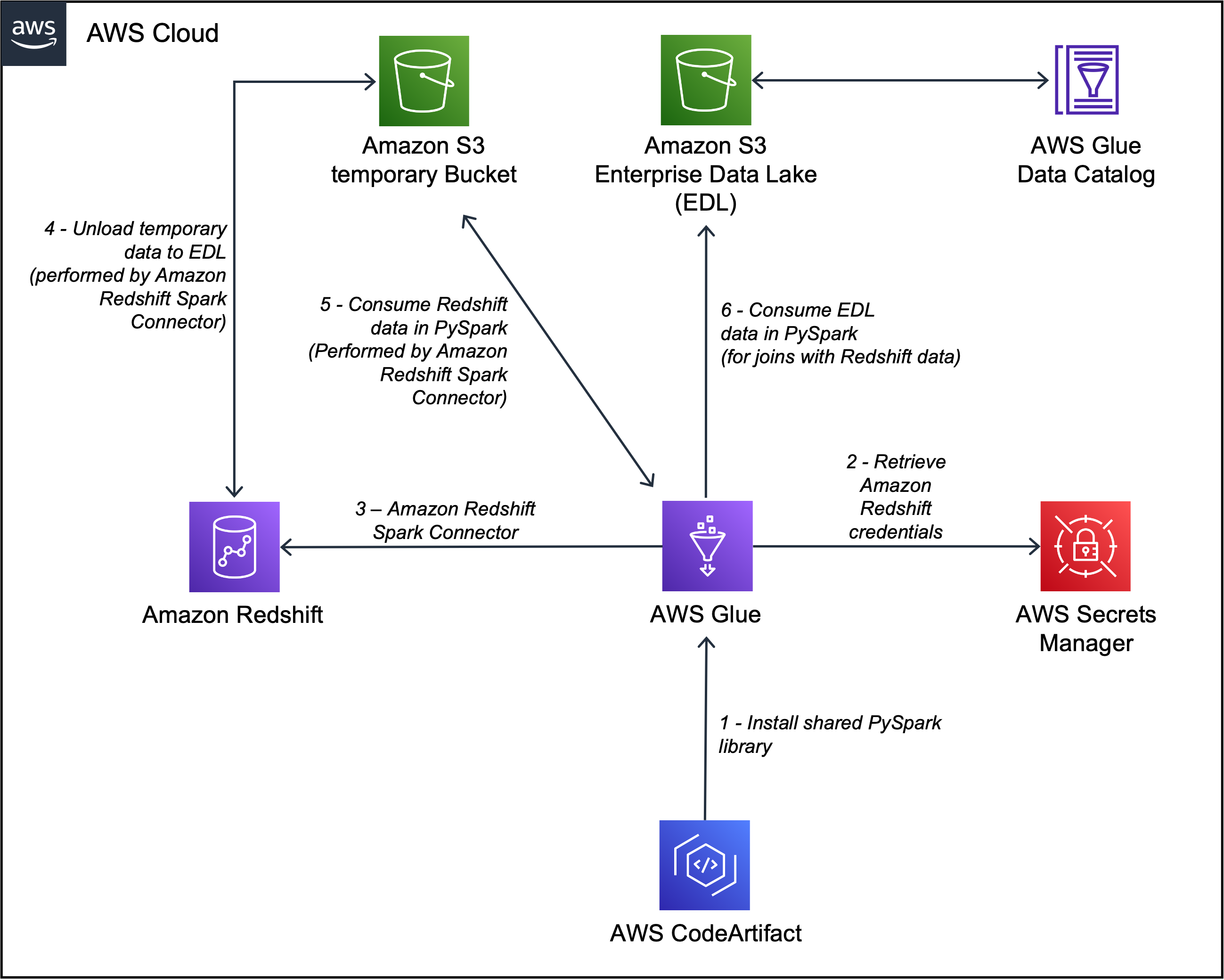
ワークフローには次の手順が含まれます。
- 内部ライブラリは、次の方法で AWS Glue PySpark ジョブにインストールされます。 AWS コードアーティファクト.
- AWS Glue ジョブは、Redshift クラスターの認証情報を取得します。 AWSシークレットマネージャー そして、共有内部ライブラリを介して Amazon Redshift 接続をセットアップします (クラスター認証情報、アンロード場所、ファイル形式を挿入します)。 Apache Spark の Amazon Redshift 統合では、次の使用もサポートされています。 AWS IDおよびアクセス管理 (IAM) に 認証情報を取得して Amazon Redshift に接続します.
- Spark クエリは Amazon Redshift に最適化されたクエリに変換され、EDW に送信されます。 これは、Apache Spark の Amazon Redshift 統合によって実現されます。
- EDW データセットは、 Amazon シンプル ストレージ サービス (Amazon S3)バケット。
- S3 バケットの EDW データセットは、Apache Spark の Amazon Redshift 統合を介して Spark エグゼキューターにロードされます。
- EDL データセットは、AWS Glue データ カタログを介して Spark エグゼキュータにロードされます。
これらのコンポーネントは連携して、データ エンジニアと本番データ パイプラインが Apache Spark の Amazon Redshift 統合を実装し、クエリを実行し、Amazon Redshift から EDL へのデータのアンロードを容易にするために必要なツールを確実に備えられるようにします。
AWS Glue 4.0 での Apache Spark の Amazon Redshift 統合の使用
このセクションでは、S3 データレイクにあるローン申請テーブルを PySpark の Redshift データ ウェアハウスからの顧客情報で強化することにより、Apache Spark に対する Amazon Redshift 統合の有用性を示します。
dimclient Amazon Redshift のテーブルには次の列が含まれます。
- クライアントキー – INT8
- ClientAltKey – VARCHAR50
- 当事者識別番号 – VARCHAR20
- クライアント作成日 - 日付
- キャンセルされました – INT2
- 行は現在です – INT2
loanapplication AWS Glue データカタログのテーブルには次の列が含まれています。
- レコードID – BIGINT
- ログ日付 – タイムスタンプ
- 当事者識別番号 - 弦
Redshift テーブルは、Apache Spark の Amazon Redshift 統合を介して読み取られ、キャッシュされます。 次のコードを参照してください。
ローン申請レコードは S3 データ レイクから読み込まれ、 dimclient Amazon Redshift 情報の表:
その結果、ローン申請記録 (S3 データレイクから) が強化されます。 ClientCreateDate 列 (Amazon Redshift より)。

Apache Spark の Amazon Redshift 統合がデータソーシングの問題を解決する方法
Apache Spark の Amazon Redshift 統合は、次のメカニズムを通じてデータ ソーシングの問題に効果的に対処します。
- ジャストインタイムの読み取り – Apache Spark コネクタ用の Amazon Redshift 統合は、Redshift テーブルをジャストインタイムで読み取り、データとスキーマの一貫性を確保します。 これは特に価値があります。 タイプ 2 ゆっくりと変化する寸法 (SCD) スナップショットの事実を蓄積するタイムスパン。 これらの Redshift テーブルを、本番環境の PySpark パイプライン内の EDL からのソース システムの AWS Glue データ カタログ テーブルと組み合わせることで、コネクタはデータの整合性を維持しながら、複数のソースからのデータをシームレスに統合できます。
- 最適化された Redshift クエリ – Apache Spark の Amazon Redshift 統合は、Spark クエリ プランを最適化された Redshift クエリに変換する上で重要な役割を果たします。 この変換プロセスでは、データの局所性の原則が遵守されるため、製品チームの開発エクスペリエンスが簡素化されます。 最適化されたクエリでは、Amazon Redshift の機能とパフォーマンスの最適化が使用され、PySpark パイプライン向けに Amazon Redshift からの効率的なデータの取得と処理が保証されます。 これにより、開発プロセスが合理化され、データ ソーシング操作の全体的なパフォーマンスが向上します。
最高のパフォーマンスを得るには
Apache Spark の Amazon Redshift 統合では、述語とクエリのプッシュダウンが自動的に適用され、パフォーマンスが最適化されます。 この統合によるアンロードに使用されるデフォルトの Parquet 形式を使用すると、パフォーマンスが向上します。
詳細とコードサンプルについては、以下を参照してください。 新機能 – Amazon Redshift と Apache Spark の統合.
ソリューションの利点
統合の導入により、チームにいくつかの大きなメリットがもたらされました。
- 開発者の生産性の向上 – 統合によって提供される PySpark インターフェイスにより、開発者の生産性が 10 倍向上し、Amazon Redshift とのよりスムーズな対話が可能になりました。
- データの重複の排除 – データレイク内の重複テーブルと AWS Glue カタログ化された Redshift テーブルが排除され、より合理化されたデータ環境が実現しました。
- EDW負荷の軽減 – 統合により、選択的なデータのアンロードが容易になり、必要なデータのみを抽出することで EDW の負荷を最小限に抑えました。
Capitec は、Apache Spark の Amazon Redshift 統合を使用することで、データ処理の改善、生産性の向上、より効率的な機能エンジニアリング エコシステムへの道を切り開きました。
まとめ
この投稿では、Capitec チームが Apache Spark と Amazon Redshift の統合を Apache Spark に実装して、特徴量計算のワークフローを簡素化した方法について説明しました。 彼らは、予測モデル機能を作成するために分散型のモジュール型 PySpark データ パイプラインを利用することの重要性を強調しました。
現在、Apache Spark 用の Amazon Redshift 統合は 7 つの本番データ パイプラインと 20 の開発パイプラインで利用されており、Capitec の環境内でその有効性が実証されています。
今後、Capitec の共有サービス機能プラットフォーム チームは、データ処理機能をさらに強化し、効率的な機能エンジニアリングの実践を促進することを目的として、さまざまなビジネス分野で Apache Spark への Amazon Redshift 統合の採用を拡大する予定です。
Apache Spark の Amazon Redshift 統合の使用に関する詳細については、次のリソースを参照してください。
著者について
 プレシェン グービア Capitec の機能プラットフォームのリード機械学習エンジニアです。 彼は、エンタープライズ向けの Feature Store コンポーネントの設計と構築に重点を置いています。 余暇には、読書と旅行を楽しんでいます。
プレシェン グービア Capitec の機能プラットフォームのリード機械学習エンジニアです。 彼は、エンタープライズ向けの Feature Store コンポーネントの設計と構築に重点を置いています。 余暇には、読書と旅行を楽しんでいます。
 ヨハン・オリヴィエ Capitec のモデル プラットフォームのシニア機械学習エンジニアです。 彼は起業家であり、問題解決の愛好家です。 彼は余暇には音楽と社交を楽しんでいます。
ヨハン・オリヴィエ Capitec のモデル プラットフォームのシニア機械学習エンジニアです。 彼は起業家であり、問題解決の愛好家です。 彼は余暇には音楽と社交を楽しんでいます。
 スディプタ・バグチ アマゾン ウェブ サービスのシニア スペシャリスト ソリューション アーキテクトです。 データと分析において 12 年以上の経験があり、お客様によるスケーラブルで高性能な分析ソリューションの設計と構築を支援します。 仕事以外では、ランニング、旅行、クリケットが大好きです。 で彼とつながりましょう LinkedIn.
スディプタ・バグチ アマゾン ウェブ サービスのシニア スペシャリスト ソリューション アーキテクトです。 データと分析において 12 年以上の経験があり、お客様によるスケーラブルで高性能な分析ソリューションの設計と構築を支援します。 仕事以外では、ランニング、旅行、クリケットが大好きです。 で彼とつながりましょう LinkedIn.
 サイード・ヒューメール アマゾン ウェブ サービス (AWS) のシニア アナリティクス スペシャリスト ソリューション アーキテクトです。 彼は、データと AI/ML に重点を置いたエンタープライズ アーキテクチャで 17 年以上の経験があり、世界中の AWS の顧客がビジネス要件と技術要件に対処できるよう支援しています。 あなたは彼とつながることができます LinkedIn.
サイード・ヒューメール アマゾン ウェブ サービス (AWS) のシニア アナリティクス スペシャリスト ソリューション アーキテクトです。 彼は、データと AI/ML に重点を置いたエンタープライズ アーキテクチャで 17 年以上の経験があり、世界中の AWS の顧客がビジネス要件と技術要件に対処できるよう支援しています。 あなたは彼とつながることができます LinkedIn.
 ブイサ・マスワナ ケープタウンを拠点とする AWS のシニア ソリューション アーキテクトです。 Vuyisa は、顧客がビジネス上の問題を解決するための技術的ソリューションを構築できるよう支援することに重点を置いています。 彼は 2019 年以来、Capitec の AWS への取り組みをサポートしてきました。
ブイサ・マスワナ ケープタウンを拠点とする AWS のシニア ソリューション アーキテクトです。 Vuyisa は、顧客がビジネス上の問題を解決するための技術的ソリューションを構築できるよう支援することに重点を置いています。 彼は 2019 年以来、Capitec の AWS への取り組みをサポートしてきました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/

