データは生成的な AI の差別化要因であり、成功の鍵となります。 generative AI 実装は、包括的なデータを組み込んだ堅牢なデータ戦略に依存します。 データガバナンス アプローチ。エンタープライズユースケースで大規模言語モデル (LLM) を扱うには、責任ある AI を推進するために品質とプライバシーに関する考慮事項を実装する必要があります。しかし、サイロ化されたソースから生成されたエンタープライズ データは、データ統合戦略の欠如と相まって、生成 AI アプリケーション用のデータをプロビジョニングする際に課題を生み出します。エンドツーエンドの必要性 データ管理の戦略 データの取り込み、保存、クエリから、人工知能 (AI) や機械学習 (ML) モデルの分析、視覚化、実行に至るまで、あらゆる段階でのデータ ガバナンスは、企業にとって引き続き最も重要です。
この投稿では、生成 AI アプリケーション データ パイプラインのデータ ガバナンスのニーズについて説明します。これは、LLM が使用するデータを管理するための重要な構成要素であり、安全、安心、透明な方法でユーザー プロンプトに対する応答の精度と関連性を向上させます。企業は、取得拡張生成 (RAG)、微調整、基礎モデルによる継続的な事前トレーニングなどのアプローチで独自のデータを使用することでこれを実現しています。
データ ガバナンスは、これらすべてのアプローチにわたる重要な構成要素であり、新たに 2 つの焦点が当てられる領域が見えてきます。まず、LLM のユースケースの多くは、データ ウェアハウスからの構造化データに加えて、文書、トランスクリプト、画像などの非構造化データから引き出す必要があるエンタープライズ ナレッジに依存しています。非構造化データは通常、さまざまな形式でサイロ化されたシステムに保存されており、一般に構造化データと同じレベルの厳密さで管理または管理されていません。第 2 に、生成 AI アプリケーションでは従来のアプリケーションよりも多くのデータ インタラクションが導入されるため、データ セキュリティ、プライバシー、アクセス制御ポリシーを生成 AI ユーザー ワークフローの一部として実装する必要があります。
この投稿では、構造化および非構造化エンタープライズ ナレッジ ソースに焦点を当てて、AWS 上で生成 AI アプリケーションを構築するためのデータ ガバナンスと、ユーザーのリクエストと応答のワークフローにおけるデータ ガバナンスの役割について説明します。
ユースケースの概要
カスタマー サポート AI アシスタントの例を見てみましょう。次の図は、ユーザー プロンプトで開始される一般的な会話型ワークフローを示しています。

ワークフローには、次の主要なデータ ガバナンス手順が含まれます。
- ユーザーのアクセス制御とセキュリティ ポリシーを要求します。
- ポリシーにアクセスして、関連データに基づいて権限を抽出し、プロンプトされたユーザーの役割と権限に基づいて結果をフィルタリングします。
- 個人を特定できる情報 (PII) の編集などのデータ プライバシー ポリシーを適用します。
- きめ細かいアクセス制御を実施します。
- ユーザー ロールに機密情報とコンプライアンス ポリシーに対するアクセス許可を付与します。
エンタープライズ コンテキストを含む応答を提供するには、データ ウェアハウスの構造化データとエンタープライズ データ レイクの非構造化データからの洞察を組み合わせて各ユーザー プロンプトを強化する必要があります。バックエンドでは、エンタープライズ データ レイクを更新するバッチ データ エンジニアリング プロセスを拡張して、非構造化データを取り込み、変換、管理する必要があります。変換の一環として、データのプライバシーを確保するためにオブジェクトを処理する必要があります (PII 編集など)。最後に、アクセス制御ポリシーを非構造化データ オブジェクトにも拡張する必要があります。 ベクター データ ストア.
データ ガバナンスを企業のナレッジ ソース データ パイプラインとユーザーの要求と応答のワークフローにどのように適用できるかを見てみましょう。
エンタープライズナレッジ: データ管理
次の図は、データ パイプラインに関するデータ ガバナンスの考慮事項と、データ ガバナンスを適用するためのワークフローをまとめたものです。
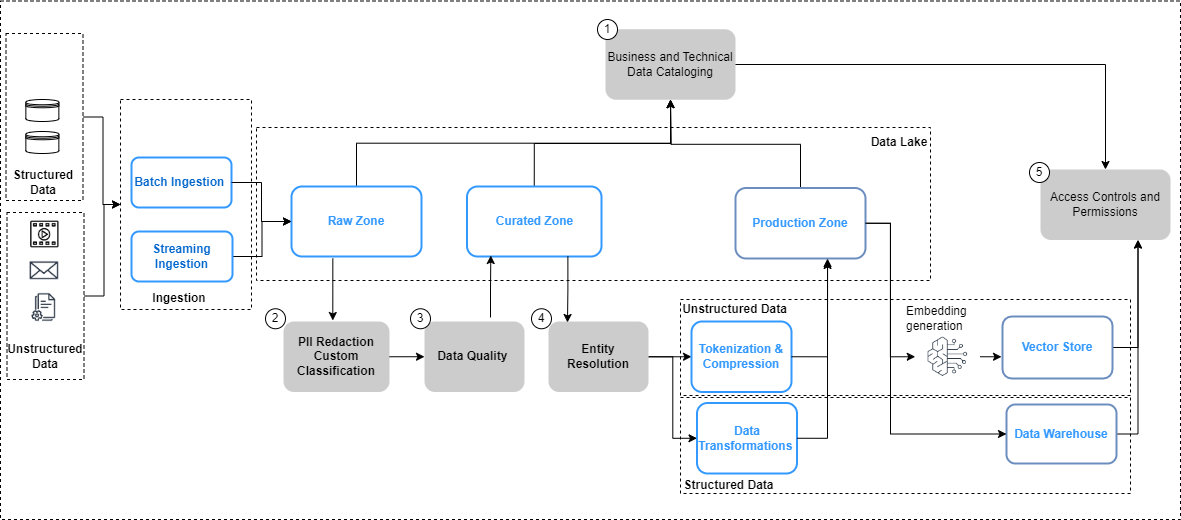
上の図では、データ エンジニアリング パイプラインには次のデータ ガバナンス ステップが含まれています。
- データの進化を通じてカタログを作成および更新します。
- データプライバシーポリシーを実装します。
- データの種類とソースごとにデータ品質を実装します。
- 構造化データセットと非構造化データセットをリンクします。
- 構造化データセットと非構造化データセットに対して、統合されたきめ細かいアクセス制御を実装します。
データ パイプラインの主な変更点、つまりデータ カタログ化、データ品質、ベクトル埋め込みセキュリティについて詳しく見てみましょう。
データの発見可能性
明確に定義された行と列で管理される構造化データとは異なり、非構造化データはオブジェクトとして保存されます。ユーザーがデータを発見して理解できるようにするための最初のステップは、ソース システムで生成およびキャプチャされたメタデータを使用して包括的なカタログを構築することです。これは、オブジェクト (ドキュメントやトランスクリプト ファイルなど) が関連するソース システムから raw ゾーンに取り込まれることから始まります。 データレイク in Amazon シンプル ストレージ サービス (Amazon S3) をそれぞれのネイティブ形式で保存します (上の図を参照)。ここから、オブジェクトのメタデータ (ファイル所有者、作成日、機密レベルなど) が 抽出され、 Amazon S3 機能を使用してクエリされます。メタデータはデータ ソースによって異なる場合があるため、フィールドを調べ、必要に応じて必要なフィールドを導出して、必要なすべてのメタデータを完成させることが重要です。たとえば、コンテンツの機密性などの属性がソース アプリケーションのドキュメント レベルでタグ付けされていない場合、メタデータ抽出プロセスの一部としてこれを取得し、データ カタログに属性として追加する必要がある場合があります。取り込みプロセスでは、新しいオブジェクトに加えてオブジェクトの更新 (変更、削除) を継続的にキャプチャする必要があります。詳細な実装ガイダンスについては、以下を参照してください。 AWS AI/ML および分析サービスを使用した非構造化データの管理とガバナンス。ビジネス用語集と技術データ カタログ間の発見と内省をさらに簡素化するには、次のように使用できます。 アマゾンデータゾーン ビジネス ユーザーがデータ サイロ全体に保存されているデータを発見して共有できるようにします。
データプライバシー
企業のナレッジ ソースには、PII やその他の機密データ (住所や社会保障番号など) が含まれることがよくあります。データ プライバシー ポリシーに基づいて、これらの要素をダウンストリームのユースケースで使用する前に、ソースから処理 (マスク、トークン化、または編集) する必要があります。 Amazon S3 の raw ゾーンからのオブジェクトは、ダウンストリームの生成 AI モデルで使用される前に処理される必要があります。ここでの重要な要件は次のとおりです PII の特定と編集で実装できます。 Amazon Comprehend。データのコンテキストに影響を与えずにすべての機密データを削除することが常に可能であるとは限らないことに留意することが重要です。 意味論的なコンテキスト は、生成 AI モデルの出力の精度と関連性を高める重要な要素の 1 つであり、ユースケースから逆算して、プライバシー制御とモデルのパフォーマンスの間で必要なバランスを取ることが重要です。
データの充実
さらに、追加のメタデータをオブジェクトから抽出する必要がある場合があります。 Amazon Comprehend は以下の機能を提供します エンティティの認識 (たとえば、保険契約番号や保険金請求番号などのドメイン固有のデータの識別) カスタム分類 (たとえば、問題の説明に基づいてカスタマー ケア チャットの記録を分類する)。さらに、非構造化データと構造化データを組み合わせて、顧客などの主要なエンティティの全体像を作成する必要がある場合があります。たとえば、航空会社のロイヤルティ シナリオでは、顧客とのやり取りの非構造化データ キャプチャ (顧客チャット記録や顧客レビューなど) を構造化データ シグナル (航空券購入やマイル交換など) とリンクさせて、より完全な情報を作成することに大きな価値があります。これにより、より適切で関連性の高い旅行の推奨を提供できるようになります。 AWS エンティティ解決 は、レコードの照合とリンクを支援する ML サービスです。このサービスは、関連する情報セットをリンクして、顧客、製品などの主要なエンティティに関するより深く関連したデータを作成するのに役立ち、LLM 出力の品質と関連性をさらに向上させることができます。これは Amazon S3 の変換ゾーンで利用でき、ベクター ストア、微調整、LLM のトレーニングのために下流で使用できるようになります。これらの変換後、Amazon S3 のキュレートされたゾーンでデータを利用できるようになります。
データ品質
生成 AI の可能性を最大限に発揮するための重要な要素は、モデルのトレーニングに使用されるデータと、ユーザー入力に対するモデルの応答を増強および強化するために使用されるデータの品質に依存します。精度、偏り、信頼性の観点からモデルとその結果を理解することは、モデルの構築とトレーニングに使用されるデータの品質に直接比例します。
Amazon SageMakerモデルモニター モデルのデータ品質のドリフトとモデルの品質メトリクスのドリフトの逸脱を事前に検出します。また、モデルの予測と特徴の帰属におけるバイアス ドリフトも監視します。詳細については、以下を参照してください。 Amazon SageMaker ModelMonitorを使用して本番環境のMLモデルを大規模に監視する。モデル内のバイアスを検出することは、責任ある AI の基本的な構成要素であり、 Amazon SageMaker の明確化 マイナスの結果や精度の低い結果を生み出す可能性のある潜在的なバイアスを検出するのに役立ちます。詳細については、を参照してください。 Amazon SageMaker Clarify がバイアスの検出にどのように役立つかを学ぶ.
生成 AI で新たに焦点が当てられているのは、エンタープライズおよび独自のデータ ストアからのプロンプトでのデータの使用と品質です。ここで考慮すべき新たなベスト プラクティスは次のとおりです。 左シフト、早期かつ積極的な品質保証メカニズムに重点を置いています。生成 AI アプリケーション用のデータを処理するように設計されたデータ パイプラインのコンテキストでは、これは、データ品質の問題を上流で早期に特定して解決し、後からデータ品質問題が引き起こす潜在的な影響を軽減することを意味します。 AWS Glue データ品質 データ レイク、データ ウェアハウス、トランザクション データベースに保管されているデータの品質を測定および監視するだけでなく、抽出、変換、ロード (ETL) パイプラインの品質問題を早期に検出して修正し、データを確実に保護することもできます。消費される前に品質基準を満たしていること。詳細については、を参照してください。 AWS Glue データカタログから AWS Glue データ品質を開始する.
ベクターストアのガバナンス
ベクトルデータベースへの埋め込み セマンティック検索や幻覚の軽減などの機能を有効にすることで、生成 AI アプリケーションのインテリジェンスと機能を向上させます。通常、埋め込みにはプライベートな機密データが含まれており、ユーザー入力ワークフローではデータの暗号化が推奨される手順です。 Amazon OpenSearch サーバーレス ベクトル埋め込みを保存および検索し、保存データを暗号化します。 AWSキー管理サービス (AWS KMS)。詳細については、を参照してください。 Amazon OpenSearch サーバーレス用のベクター エンジンの紹介、現在プレビュー中。同様に、AWS 上の追加のベクトル エンジン オプションには、以下が含まれます。 アマゾンケンドラ & アマゾンオーロラ、AWS KMS を使用して保存データを暗号化します。詳細については、以下を参照してください。 保存時の暗号化 & 暗号化を使用したデータの保護.
エンベディングが生成され、ベクター ストアに保存されるため、ロールベースのアクセス制御 (RBAC) を使用してデータへのアクセスを制御することが、全体的なセキュリティを維持するための重要な要件になります。 AmazonOpenSearchサービス は、大阪で きめ細かいアクセス制御 (FGAC) の機能 AWS IDおよびアクセス管理 関連付けることができる (IAM) ルール アマゾンコグニート ユーザー。対応するユーザー アクセス制御メカニズムも、によって提供されます。 OpenSearch サーバーレス, アマゾンケンドラ、オーロラ。詳細については、を参照してください。 Amazon OpenSearch Serverless のデータ アクセス制御, トークンを使用したドキュメントへのユーザー アクセスの制御, Amazon Aurora の ID とアクセス管理それぞれ。
ユーザーのリクエストとレスポンスのワークフロー
データ ガバナンス プレーンのコントロールは、全体の一部として生成 AI アプリケーションに統合する必要があります。 ソリューションの展開 データ セキュリティ (役割ベースのアクセス制御に基づく) およびデータ プライバシー (機密データへの役割ベースのアクセスに基づく) ポリシーへの準拠を確保します。次の図は、データ ガバナンスを適用するためのワークフローを示しています。
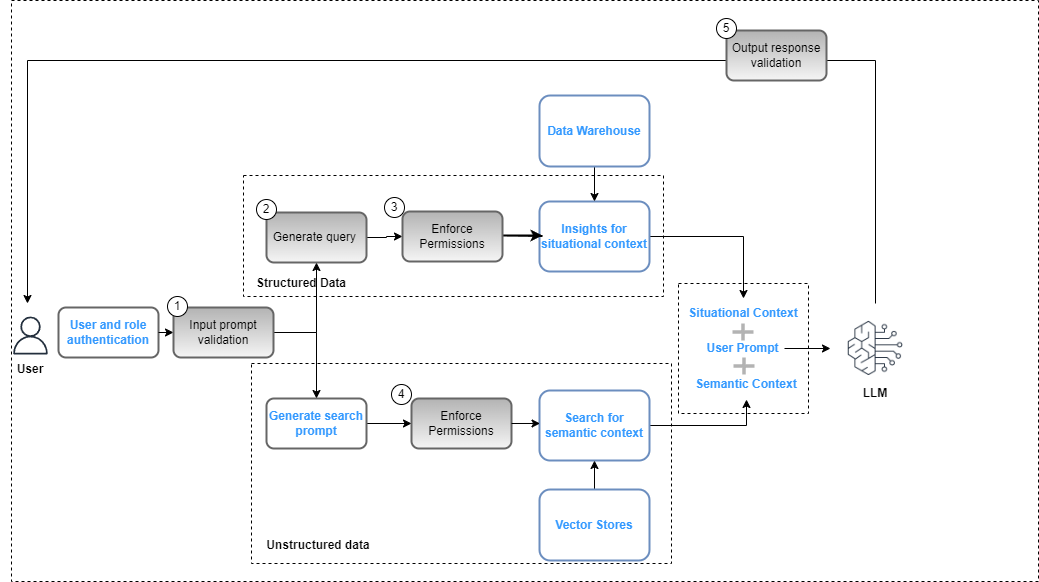
ワークフローには、次の主要なデータ ガバナンス手順が含まれます。
- コンプライアンス ポリシー (バイアスや有害性など) に合わせて有効な入力プロンプトを提供します。
- プロンプトのキーワードをデータ カタログにマッピングしてクエリを生成します。
- ユーザーの役割に基づいて FGAC ポリシーを適用します。
- ユーザーの役割に基づいて RBAC ポリシーを適用します。
- ユーザーの役割の権限とコンプライアンス ポリシーに基づいて、データとコンテンツの編集を応答に適用します。
プロンプト サイクルの一環として、Amazon Comprehend などのサービスを使用してユーザー プロンプトを解析し、キーワードを抽出してコンプライアンス ポリシーとの整合性を確保する必要があります (「Amazon Comprehend」を参照)。 Amazon Comprehend の新機能 – 毒性検出)または Amazon Bedrock のガードレール (プレビュー)。それが検証され、プロンプトで構造化データの抽出が必要な場合は、データ カタログ (ビジネスまたは技術) に対してキーワードを使用して、関連するデータ テーブルとフィールドを抽出し、データ ウェアハウスからクエリを構築できます。ユーザー権限は以下を使用して評価されます。 AWSレイクフォーメーション 関連するデータをフィルタリングします。非構造化データの場合、検索結果は、ベクター ストアに実装されているユーザー権限ポリシーに基づいて制限されます。最後のステップとして、LLM からの出力応答を、ユーザーのアクセス許可 (データのプライバシーとセキュリティを確保するため) および安全性の遵守 (バイアスや有害性のガイドラインなど) に対して評価する必要があります。
このプロセスは RAG 実装に固有であり、他の LLM 実装戦略にも適用できますが、追加の制御があります。
- 迅速なエンジニアリング – 呼び出すプロンプト テンプレートへのアクセスは、以下に基づいて制限する必要があります。 アクセス制御 ビジネス ロジックによって強化されます。
- 微調整モデルとトレーニング基礎モデル – Amazon S3 のキュレートされたゾーンのオブジェクトが基礎モデルを微調整するためのトレーニング データとして使用される場合、アクセス許可ポリシーを次のように設定する必要があります。 Amazon S3 ID とアクセス管理 要件に基づいてバケットまたはオブジェクトレベルで。
まとめ
データ ガバナンスは、組織がエンタープライズ生成 AI アプリケーションを構築できるようにするために重要です。企業のユースケースが進化し続けるにつれて、プライバシー、セキュリティ、品質ポリシーとの整合性を確保するために、新しく多様な非構造化データセットを管理および管理するためのデータ インフラストラクチャを拡張する必要があります。これらのポリシーは、データの取り込み、保存、およびユーザー対話ワークフローとともにエンタープライズ ナレッジ ベースの管理の一部として実装および管理する必要があります。これにより、生成 AI アプリケーションは、不正確または間違った情報を共有するリスクを最小限に抑えるだけでなく、有害または中傷的な結果につながる可能性のある偏見や有害性からも確実に保護します。 AWS でのデータ ガバナンスの詳細については、次を参照してください。 データガバナンスとは何ですか?
今後の投稿では、生成 AI ユースケースをサポートするためにデータ インフラストラクチャのガバナンスを拡張する方法に関する実装ガイダンスを提供します。
著者について
 クリシュナ・ルパナグンタ AWS のデータおよび AI スペシャリストのチームを率いています。彼と彼のチームは顧客と協力して、データ、分析、AI/ML を使用して顧客がより迅速にイノベーションを起こし、より適切な意思決定を行えるよう支援しています。彼には LinkedIn 経由で連絡できます。
クリシュナ・ルパナグンタ AWS のデータおよび AI スペシャリストのチームを率いています。彼と彼のチームは顧客と協力して、データ、分析、AI/ML を使用して顧客がより迅速にイノベーションを起こし、より適切な意思決定を行えるよう支援しています。彼には LinkedIn 経由で連絡できます。
 Imtiaz(Taz)は言った は、AWS の分析部門の WW テクノロジー リーダーです。彼は、データと分析に関するあらゆることに関してコミュニティと関わることを楽しんでいます。彼には LinkedIn 経由で連絡できます。
Imtiaz(Taz)は言った は、AWS の分析部門の WW テクノロジー リーダーです。彼は、データと分析に関するあらゆることに関してコミュニティと関わることを楽しんでいます。彼には LinkedIn 経由で連絡できます。
 ラグベンダー・アルニ (アルニ) AWS 業界内のカスタマー アクセラレーション チーム (CAT) を率いています。 CAT は、顧客対応のクラウド アーキテクト、ソフトウェア エンジニア、データ サイエンティスト、AI/ML の専門家とデザイナーからなるグローバルな部門横断型チームであり、高度なプロトタイピングを通じてイノベーションを推進し、専門的な技術的専門知識を通じてクラウドの運用上の卓越性を推進します。
ラグベンダー・アルニ (アルニ) AWS 業界内のカスタマー アクセラレーション チーム (CAT) を率いています。 CAT は、顧客対応のクラウド アーキテクト、ソフトウェア エンジニア、データ サイエンティスト、AI/ML の専門家とデザイナーからなるグローバルな部門横断型チームであり、高度なプロトタイピングを通じてイノベーションを推進し、専門的な技術的専門知識を通じてクラウドの運用上の卓越性を推進します。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

